set、map、multiset、multimap
C++STL包含了序列式容器和关联式容器:
序列式容器里面存储的是元素本身,其底层为线性序列的数据结构。比如:vector,list,deque,forward_list(C++11)等。
关联式容器里面存储的是<key, value>结构的pair 键值对,在数据检索时比序列式容器效率更高。比如:set、map、unordered_set、unordered_map等。
根据应用场景的不同,C++STL总共实现了两种不同结构的关联式容器:树型结构和哈希结构。
| 关联式容器 | 容器结构 | 底层实现 |
|---|---|---|
| set、map、multiset、multimap | 树型结构 | 平衡搜索树(红黑树) |
| unordered_set、unordered_map、unordered_multiset、unordered_multimap | 哈希结构 | 哈希表 |
其中,树型结构容器中的元素是一个有序的序列,而哈希结构容器中的元素是一个无序的序列。
set的使用:默认是升序
#include <iostream>
#include <set>
using namespace std;
int main()
{
set<int> s;
//插入元素(去重)
s.insert(1);
s.insert(4);
s.insert(3);
s.insert(3);
s.insert(2);
s.insert(2);
s.insert(3);
//遍历容器方式一(范围for)
for (auto e : s)
{
cout << e << " ";
}
cout << endl; //1 2 3 4
//删除元素方式一
s.erase(3);
//删除元素方式二
set<int>::iterator pos = s.find(1); //查找值为1的元素
if (pos != s.end())
{
s.erase(pos);
}
//遍历容器方式二(正向迭代器)
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
it++;
}
cout << endl; //2 4
//容器中值为2的元素个数
cout << s.count(2) << endl; //1
//容器大小
cout << s.size() << endl; //2
//清空容器
s.clear();
//容器判空
cout << s.empty() << endl; //1
//交换两个容器的数据
set<int> tmp{ 11, 22, 33, 44 };
s.swap(tmp);
//遍历容器方式三(反向迭代器)
set<int>::reverse_iterator rit = s.rbegin();
while (rit != s.rend())
{
cout << *rit << " ";
rit++;
}
cout << endl; //44 33 22 11
return 0;
}
map的使用:
#include <iostream>
#include <string>
#include <map>
using namespace std;
int main()
{
map<int, string> m;
m.insert(make_pair(2, "two"));
m.insert(make_pair(1, "one"));
m.insert(make_pair(3, "three"));
m[2] = "dragon"; //修改key值为2的元素的value为dragon
m[6] = "six"; //插入键值对<6, "six">
for (auto e : m)
{
cout << "<" << e.first << "," << e.second << ">" << " ";
}
cout << endl; //<1,one> <2,dragon> <3,three> <6,six>
return 0;
}
multimap容器允许键值冗余,调用[ ]运算符重载函数时,应该返回键值为key的哪一个元素的value的引用存在歧义,因此在multimap容器当中没有实现[ ]运算符重载函数。
unordered_set、unordered_map
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时的效率可达到O ( l o g N ) O(logN)O(logN),即最差情况下需要比较红黑树的高度次,当树中的结点非常多时,查询效率也不理想。最好的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同。
当处理数据量较小时,选用xxx容器与unordered_xxx容器的差异不大;当处理数据量较大时,建议选用对应的unordered_xxx容器。
补充一点: 当需要存储的序列为有序时,应该选用map/set容器。
哈希
构造一种存储结构,该结构能够通过某种函数使元素的存储位置与它的关键码之间能够建立一一映射的关系,那么在查找时就能通过该函数很快找到该元素。
向该结构当中插入和搜索元素的过程如下:
- 插入元素: 根据待插入元素的关键码,用此函数计算出该元素的存储位置,并将元素存放到此位置。
- 搜索元素: 对元素的关键码进行同样的计算,把求得的函数值当作元素的存储位置,在结构中按此位置取元素进行比较,若关键码相等,则搜索成功。
哈希是一种思想,是一种方法,实现了更加快速的查找。实现这种方法的函数叫哈希函数。构造出来的结构称为哈希表(散列表),如下0-9的图就是哈希表。

哈希冲突
不同关键字通过相同哈希函数计算出相同的哈希地址,这种现象称为哈希冲突或哈希碰撞。我们把关键码不同而具有相同哈希地址的数据元素称为“同义词”。
常见的哈希函数如下:
一、直接定址法(常用)
取关键字的某个线性函数为哈希地址:Hash (Key ) = A ∗ K e y + B Hash(Key)=A*Key+BHash(Key)=A∗Key+B。
二、除留余数法(常用)
设散列表中允许的地址数为m,取一个不大于m,但最接近或者等于m的质数p作为除数,按照哈希函数:H a s h ( K e y ) = K e y % p ( p < = m ) Hash(Key)=Key\%p(p<=m)Hash(Key)=Key%p(p<=m),将关键码转换成哈希地址。
哈希冲突解决
解决哈希冲突有两种常见的方法:闭散列和开散列。
闭散列 —— 开放定址法
闭散列,也叫开放定址法,当发生哈希冲突时,如果哈希表未被装满,说明在哈希表种必然还有空位置,那么可以把产生冲突的元素存放到冲突位置的“下一个”空位置中去。
寻找“下一个位置”的方式多种多样,常见的方式有以下两种:线性探测和二次探测。
开散列 —— 链地址法(拉链法、哈希桶)
开散列,又叫链地址法(拉链法),首先对关键码集合用哈希函数计算哈希地址,哈希函数算出相同地址的关键码归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。
当桶当中的元素个数超过一定长度,有些地方就会选择将该桶中的单链表结构换成红黑树结构,比如在JAVA中比较新一点的版本中,当桶当中的数据个数超过8时,就会将该桶当中的单链表结构换成红黑树结构,而当该桶当中的数据个数减少到8或8以下时,又会将该桶当中的红黑树结构换回单链表结构。
//每个哈希桶中存储数据的结构
template<class K, class V>
struct HashNode
{
pair<K, V> _kv;
HashNode<K, V>* _next;
//构造函数
HashNode(const pair<K, V>& kv)
:_kv(kv)
, _next(nullptr)
{}
};
vector<Node*> _table; //哈希表哈希表中存储一个个哈希桶组成的vector,而哈希桶存储的是一个个链表的头节点。
插入过程中哈希表的调整方式如下:
- 若哈希表的大小为0,则将哈希表的初始大小设置为10。
- 若哈希表的负载因子已经等于1了,则先创建一个新的哈希表,该哈希表的大小为原哈希表的两倍,之后遍历原哈希表,将原哈希表中的数据插入到新哈希表,最后将原哈希表与新哈希表交换即可。
查找过程:
通过哈希函数计算出对应的哈希桶编号index,然后通过哈希地址找到对应的哈希桶中的单链表,遍历单链表进行查找即可。
哈希表长度扩容
C++的实现中将哈希表的长度 近似以2倍的形式进行增长,我们就可以将它们用一个数组存储起来。
位图
给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中?
40亿个数,若是我们要将这些数全部加载到内存当中,那么将会占用16G的空间,空间消耗是很大的,无符号整数总共有232个,因此记录这些数字就需要232个比特位,也就是512M的内存空间,内存消耗大大减少。
bitset<2*32> bs1; //0000000000000000000000....
有方法set,unset,test。
#include <iostream>
#include <bitset>
using namespace std;
int main()
{
bitset<8> bs;
bs.set(2); //设置第2位
bs.set(4); //设置第4位
cout << bs << endl; //00010100
bs.flip(); //反转所有位
cout << bs << endl; //11101011
cout << bs.count() << endl; //6
cout << bs.test(3) << endl; //1
bs.reset(0); //清空第0位
cout << bs << endl; //11101010
bs.flip(7); //反转第7位
cout << bs << endl; //01101010
cout << bs.size() << endl; //8
bs.reset(); //清空所有位
cout << bs.none() << endl; //1
bs.set(); //设置所有位
cout << bs.all() << endl; //1
return 0;
}
位图的实现:内部采用vector
//构造函数
bitset()
{
_bits.resize(N / 32 + 1, 0);
}
布隆过滤器的概念
布隆过滤器是由布隆(Burton Howard Bloom)在1970年提出的一种紧凑型的、比较巧妙的概率型数据结构,特点是高效地插入和查询。布隆过滤器是位图和哈希的结合。
- 布隆过滤器其实就是位图的一个变形和延申,虽然无法避免存在哈希冲突,但我们可以想办法降低误判的概率。
- 当一个数据映射到位图中时,布隆过滤器会用多个哈希函数将其映射到多个比特位,当判断一个数据是否在位图当中时,需要分别根据这些哈希函数计算出对应的比特位,如果这些比特位都被设置为1则判定为该数据存在,否则则判定为该数据不存在。
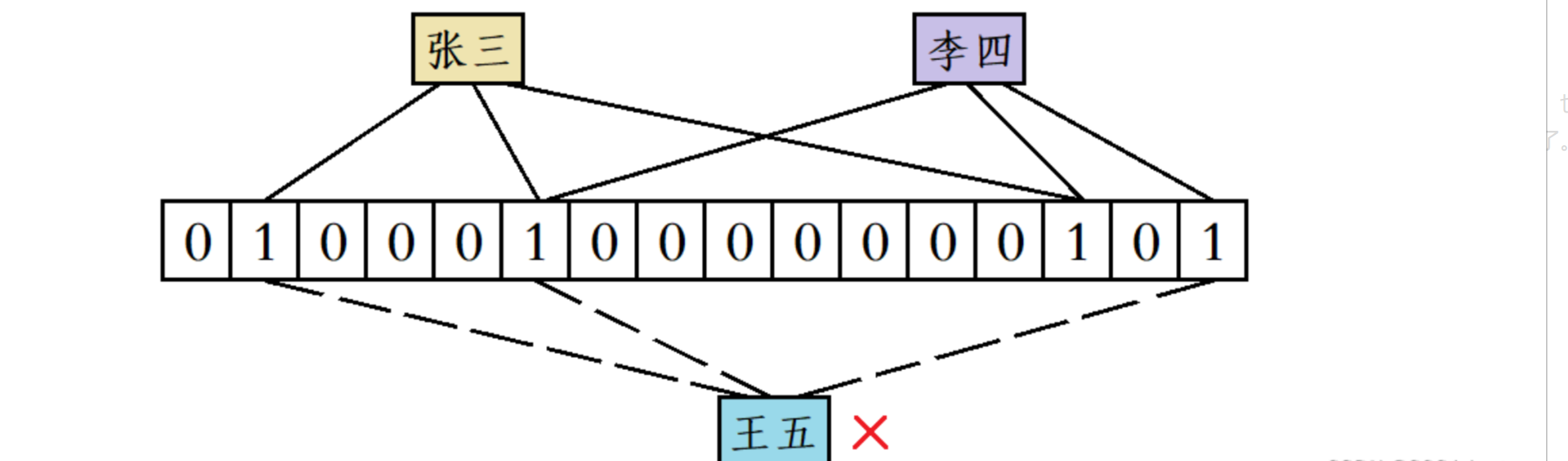
以下就是布隆过滤器,布隆过滤器当中需要提供一个Set接口,用于插入元素到布隆过滤器当中。插入元素时,需要通过三个哈希函数分别计算出该元素对应的三个比特位,然后将位图中的这三个比特位设置为1即可。
//布隆过滤器
template<size_t N, class K = string, class Hash1 = BKDRHash, class Hash2 = APHash, class Hash3 = DJBHash>
class BloomFilter
{
public:
//...
private:
bitset<N> _bs;
};
字符串转成整型的哈希函数(还要%N的),经过测试后综合评分最高的BKDRHash、APHash和DJBHash,这三种哈希算法在多种场景下产生哈希冲突的概率是最小的。
比如当我们首次访问某个网站时需要用手机号注册账号,而用户的各种数据实际都是存储在数据库当中的,也就是磁盘上面。如果在布隆过滤器中查找后发现该手机号不存在,则说明该手机号没有被注册过,此时就可以让用户进行注册,并且避免了磁盘IO。如果在布隆过滤器中查找后发现该手机号存在,此时还需要进一步访问磁盘进行复核,确认该手机号是否真的被注册过,因为布隆过滤器在判断元素存在时可能会误判。
海量数据处理
海量数据处理是指基于海量数据的存储和处理,正因为数据量太大,所以导致要么无法在短时间内迅速处理,要么无法一次性装入内存。
- 对于时间问题,就可以采用位图、布隆过滤器等数据结构来解决。
- 对于空间问题,就可以采用哈希切割等方法,将大规模的数据转换成小规模的数据逐个击破。
题目一:给定100亿个整数,设计算法找到只出现一次的整数。
双位图解决
#include <iostream>
#include <vector>
#include <assert.h>
#include <bitset>
using namespace std;
int main()
{
//此处应该从文件中读取100亿个整数
vector<int> v{ 12, 33, 4, 2, 7, 3, 32, 3, 3, 12, 21 };
//在堆上申请空间
bitset<4294967295>* bs1 = new bitset<4294967295>;
bitset<4294967295>* bs2 = new bitset<4294967295>;
for (auto e : v)
{
if (!bs1->test(e) && !bs2->test(e)) //00->01
{
bs2->set(e);
}
else if (!bs1->test(e) && bs2->test(e)) //01->10
{
bs1->set(e);
bs2->reset(e);
}
else if (bs1->test(e) && !bs2->test(e)) //10->10
{
//不做处理
}
else //11(理论上不会出现该情况)
{
assert(false);
}
}
for (size_t i = 0; i < 4294967295; i++)
{
if (!bs1->test(i) && bs2->test(i)) //01
cout << i << endl;
}
return 0;
}
给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件的交集?给出近似算法。(如果是整数则用位图实现)
题目要求给出近视算法,也就是允许存在一些误判,那么我们就可以用布隆过滤器。
- 先读取其中一个文件当中的query,将其全部映射到一个布隆过滤器当中。
- 然后读取另一个文件当中的query,依次判断每个query是否在布隆过滤器当中,如果在则是交集,不在则不是交集。
给两个文件A和B,分别有100亿个query,我们只有1G内存,如何找到两个文件的交集?给出精确算法。
还是刚才那道题目,但现在要求给出精确算法,那么就不能使用布隆过滤器了,此时需要用到哈希切分。
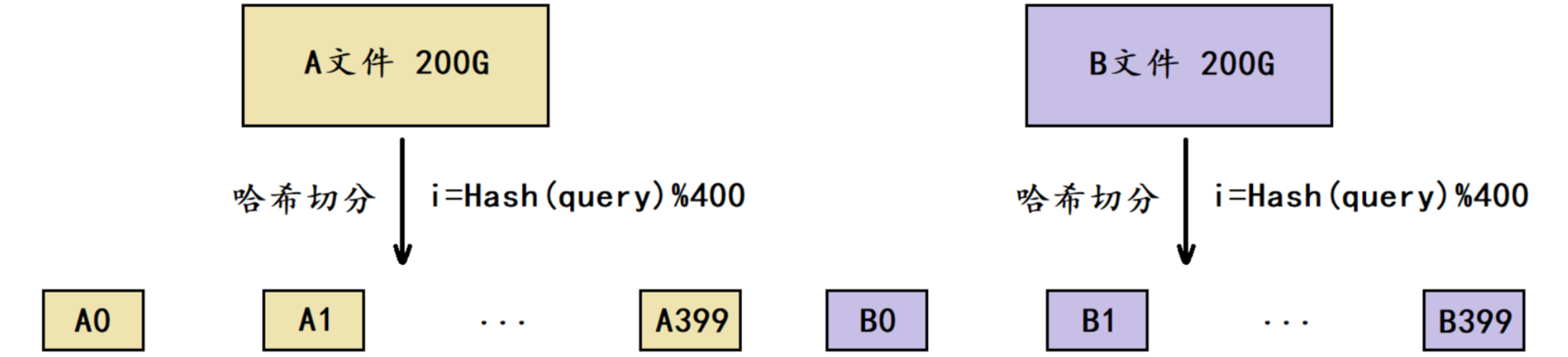
那各个小文件之间又应该如何找交集呢?(不使用布隆过滤器哦)
经过切分后理论上每个小文件的平均大小是512M,因此我们可以将其中一个小文件加载到内存,并放到一个set容器中,再遍历另一个小文件当中的query,依次判断每个query是否在set容器中,如果在则是交集,不在则不是交集。
单例模式
单例模式有两种实现方式,分别是饿汉模式和懒汉模式:
饿汉模式
饿汉模式在程序入口之前完成单例对象的初始化,单例模式的饿汉实现方式如下:
class Singleton
{
public:
//3、提供一个全局访问点获取单例对象
static Singleton* GetInstance()
{
return _inst;
}
private:
//1、将构造函数设置为私有,并防拷贝
Singleton()
{}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
//2、提供一个指向单例对象的static指针
static Singleton* _inst;
};
//在程序入口之前完成单例对象的初始化
Singleton* Singleton::_inst = new Singleton;
懒汉模式的 GetInstance函数第一次调用时需要对static指针进行写入操作,这个过程不是线程安全的,因为多个线程可能同时调用GetInstance函数,如果不对这个过程进行保护双检查加锁,会产生线程安全问题,我们也可以static创建(C++11后支持)。
class Singleton
{
public:
//3、提供一个全局访问点获取单例对象
static Singleton* GetInstance()
{
//双检查
if (_inst == nullptr)
{
_mtx.lock();
if (_inst == nullptr)
{
_inst = new Singleton;
}
_mtx.unlock();
}
return _inst;
}
private:
//1、将构造函数设置为私有,并防拷贝
Singleton()
{}
Singleton(const Singleton&) = delete;
Singleton& operator=(const Singleton&) = delete;
//2、提供一个指向单例对象的static指针
static Singleton* _inst;
static mutex _mtx; //互斥锁
};
//在程序入口之前先将static指针初始化为空
Singleton* Singleton::_inst = nullptr;
mutex Singleton::_mtx; //初始化互斥锁