文章目录
AI(学习笔记第二课) 使用langchain进行AI开发
- 创建
python开发环境(pycharm community版)并连接deepseek - 结合
ollama构造知识向量库
学习内容:
- 创建
python开发环境并连接deepseek - 结合
ollama构造知识向量库,进行Retrieval-Augmented Generation (RAG)
1. 使用背景
pycharm已经是非常主流的python IDE,在开发工作是经常使用,这里通过pycharm进行python的AI开发。pycharm community版是开源的开发IDE,所以在开发中选择使用pycharm。ollama也是AI开发的开源大模型,可以从ollama得到很多的大模型,这里大模型采用ollama。知识向量库是RAG Retrieval-Augmented Generation的基础,可以使用知识向量库给AI提供公司内部的数据文件,让其可以拥有AI的分析基础数据。langchain是一个AI开发平台,使用langchain,能够简化和规范AI开发的流程。
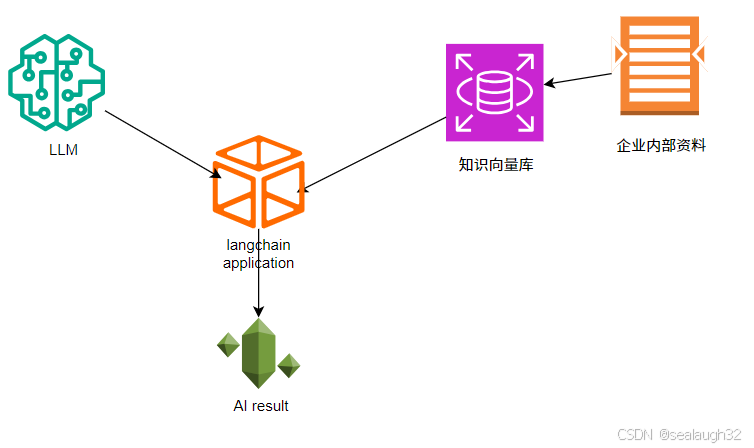
2.创建python(pycharm community版)开发环境并连接deepseek
2.1 创建python(pycharm community版)开发环境
这里在windows上安装,所以选择windows版。
- pycharm windows
- 选择
pycharm community版
2.2 创建python工程
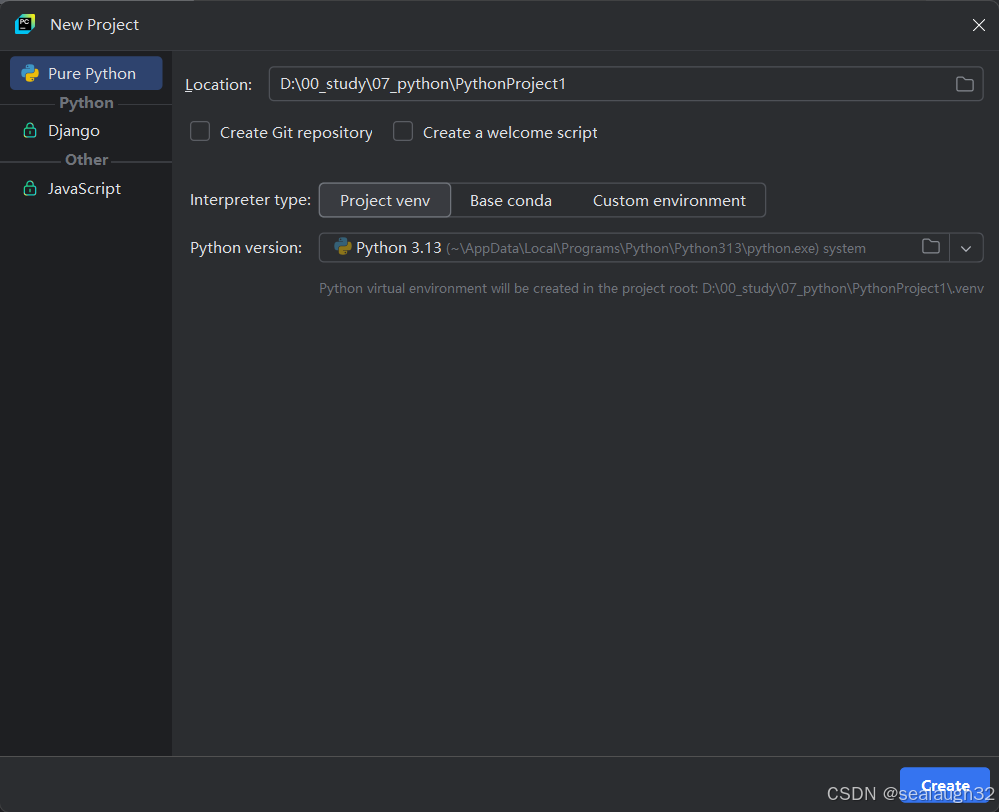
这里,默认使用python venv环境,进行虚拟环境的设定。之后创建src代码文件夹。
同时,创建langchain_deepseek.py文件进行AI的入门测试。
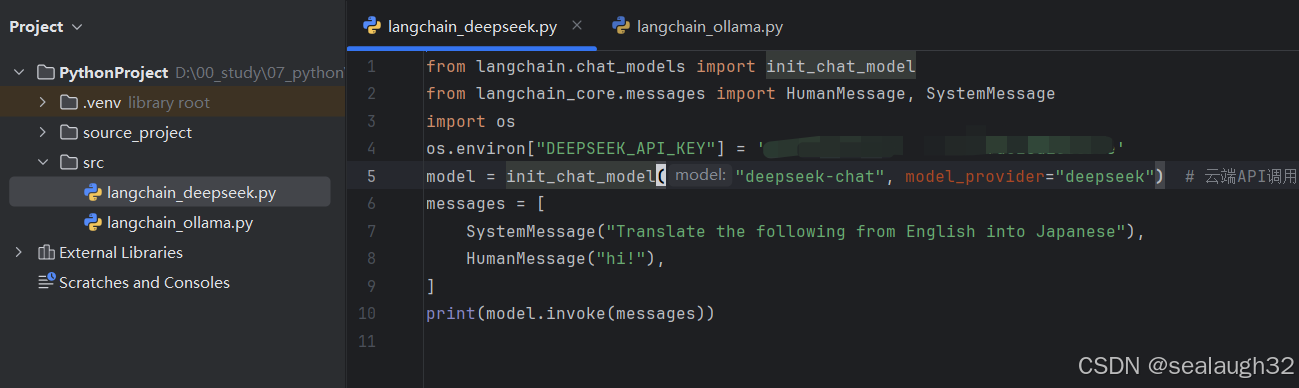
2.3 写入初始python的AI代码
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.schema import HumanMessage
# 配置 DeepSeek API(deepseek 兼容 OpenAI)
llm = ChatOpenAI(
api_key = 'your own deepseek key',
base_url = 'https://api.deepseek.com/v1',
model='deepseek-chat'# 或其他 DeepSeek 模型
)
# 直接调用
response = llm.invoke("你好,DeepSeek!")
print(response.content)
# 使用 PromptTemplate
prompt = ChatPromptTemplate.from_messages([
("system", "你是一个专业的AI助手"),
("user", "{question}")
])
chain = prompt | llm
result = chain.invoke({"question": '请解释机器学习的基本概念'})
print(result.content)
- 这里
langchain没有直接专用deepseek的包,所以使用langchain_openai。 - 这里,调用
ChatPromptTemplate.from_messages的时候,有两种prompt。system--系统提示词一般指在整个AI应用中不变化的部分,作为系统提示词。user--用户提示词一般指在整个AI应用中根据用户提示的,变化的提示词。
2.4 使用pycharm导入必要的包进入venv
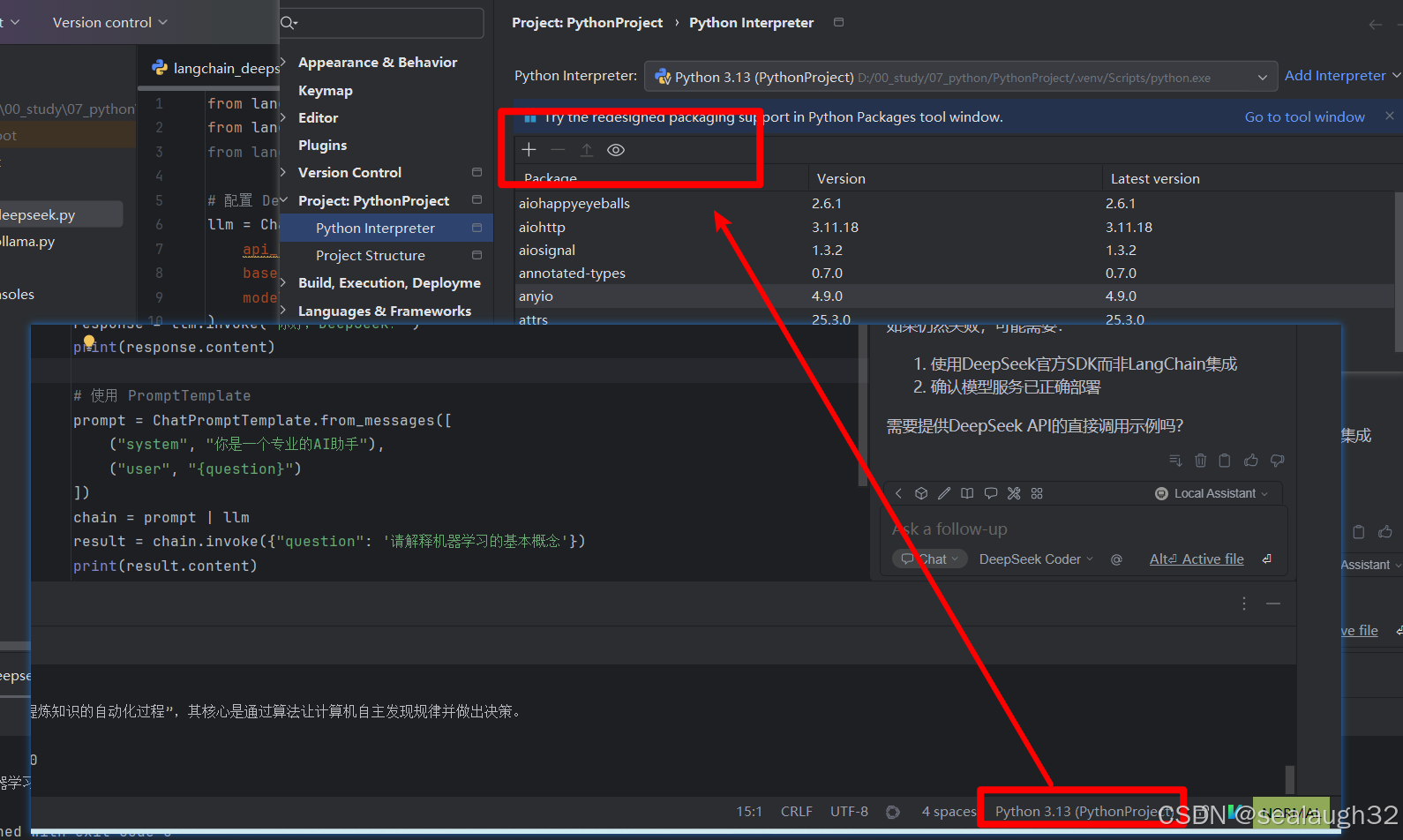
2.5 使用langchain导入必要的包
python -m pip install langchain-openai langchain langchain-core
2.6 执行AI的langchain代码
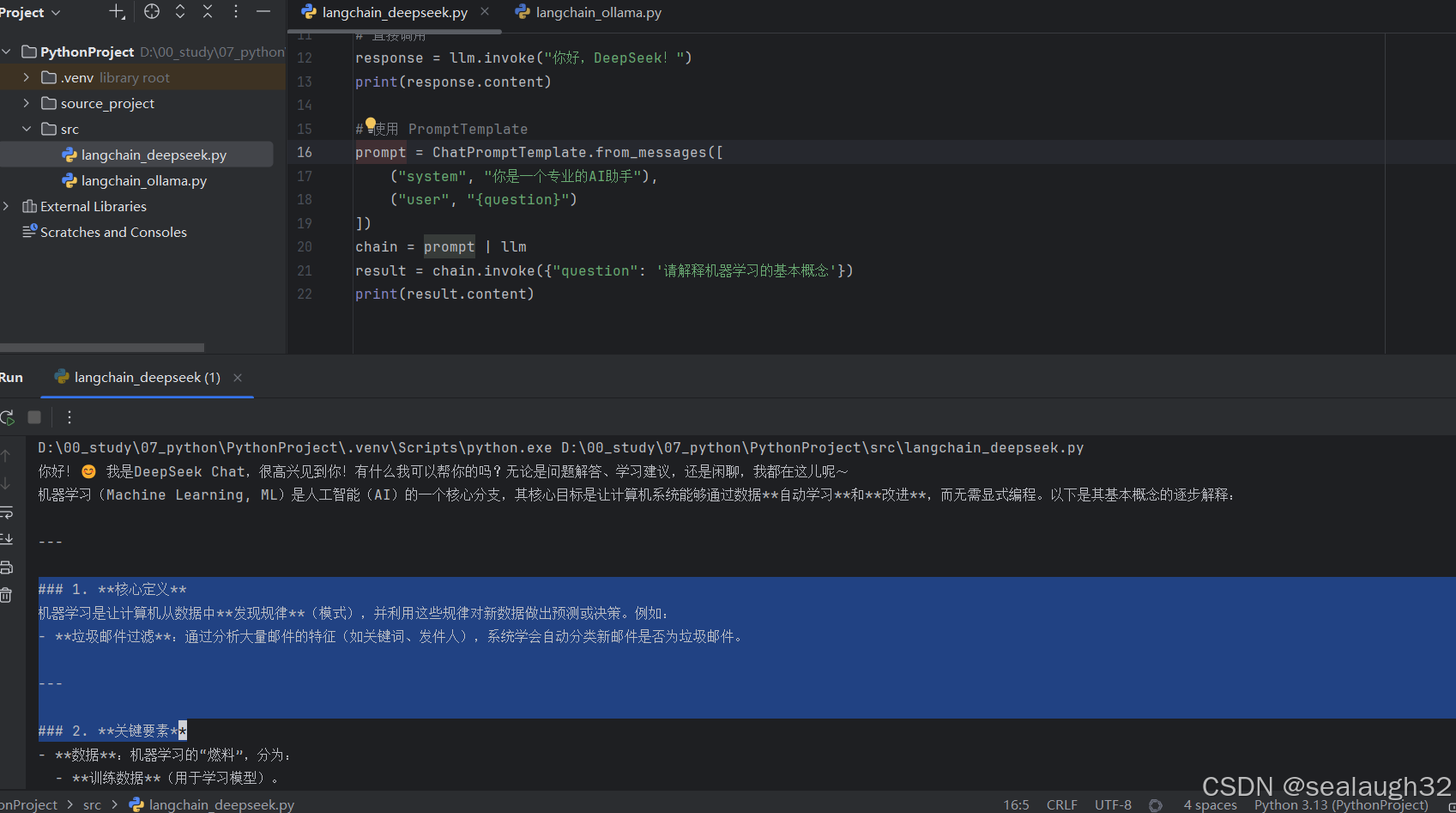
可以看出,这里已经采用langchain连接上deepseek进行AI对话了。
3. 结合ollama构造知识向量库并进行RAG
3.1 构建本地的ollama服务
3.1.1 构建ollama的LLM大模型完全通过deepseek.com就可以查询到。
- http://deepseek.com
如何在windows上安装ollama使用自然语言进行AI对话
3.1.2 在 Windows 上安装 Ollama 的步骤如下:
-
- 下载 Ollama
- 访问 Ollama 的官方 GitHub 发布页面:Ollama Releases
- 找到最新的 Windows 版本(通常是
.exe安装文件),例如OllamaSetup.exe,然后下载。
-
- 运行安装程序
- 双击下载的
OllamaSetup.exe文件。 - 按照安装向导的提示完成安装(通常只需点击“下一步”即可)。
-
- 验证安装
- 安装完成后,Ollama 应该会自动启动。
- 打开 命令提示符(CMD) 或 PowerShell,运行以下命令检查是否安装成功:
如果返回版本号,说明安装成功。**ollama --version
-
- 运行 Ollama
- 在终端运行:
这会下载并运行ollama run llama2llama2模型(首次运行需要下载模型,可能需要一些时间)。
-
- (可选)设置环境变量
- 如果
ollama命令无法识别,可能需要手动将 Ollama 的安装路径添加到系统环境变量PATH中:- 右键“此电脑” > “属性” > “高级系统设置” > “环境变量”。
- 在
PATH变量中添加 Ollama 的安装路径(默认可能是C:\Program Files\Ollama)。
-
- 更新 Ollama
- 如果有新版本,可以重新下载安装包覆盖安装,或运行:
ollama update
常见问题
权限问题:如果安装失败,尝试以管理员身份运行安装程序。
防火墙阻止:确保 Ollama 可以访问网络(下载模型需要联网)。
GPU 支持:Ollama 默认使用 CPU,如需 GPU 加速,确保已安装 NVIDIA 驱动并支持 CUDA。
现在你应该可以在 Windows 上使用 Ollama 运行各种大语言模型了! 🎉
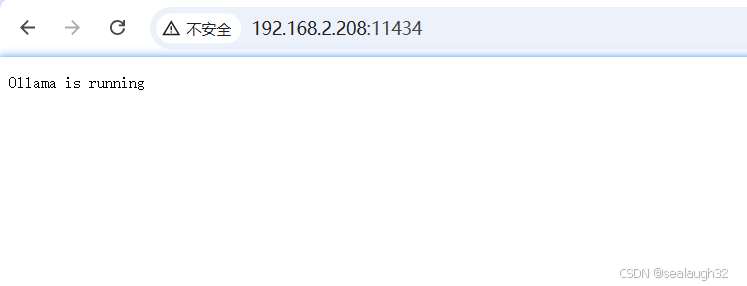
3.1.3 验证ollama的启动情况
这里,使用mac机器进行安装,IP为192.168.2.208。http://192.168.2.208:11434
出现下图,就表示正常已经LLM大模型在本地进行正常动作了。
3.2 使用langchain测试本地的ollama服务
3.2.1 测试代码
from langchain_community.llms import Ollama
from langchain.chains import LLMChain
from langchain.prompts import ChatPromptTemplate
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
# 初始化Ollama模型
llm = Ollama(model="deepseek-r1:1.5b",
base_url="http://192.168.2.208:11434")
# 创建提示模板
prompt = ChatPromptTemplate.from_template(
"用简单的语言解释以下概念: {concept}"
)
# 创建链
chain = LLMChain(llm=llm, prompt=prompt)
# 运行链
concept = "llamaIndex"
result = chain.run(concept=concept)
print(result)
注意,同时安装必要的python package
3.2.2 执行代码
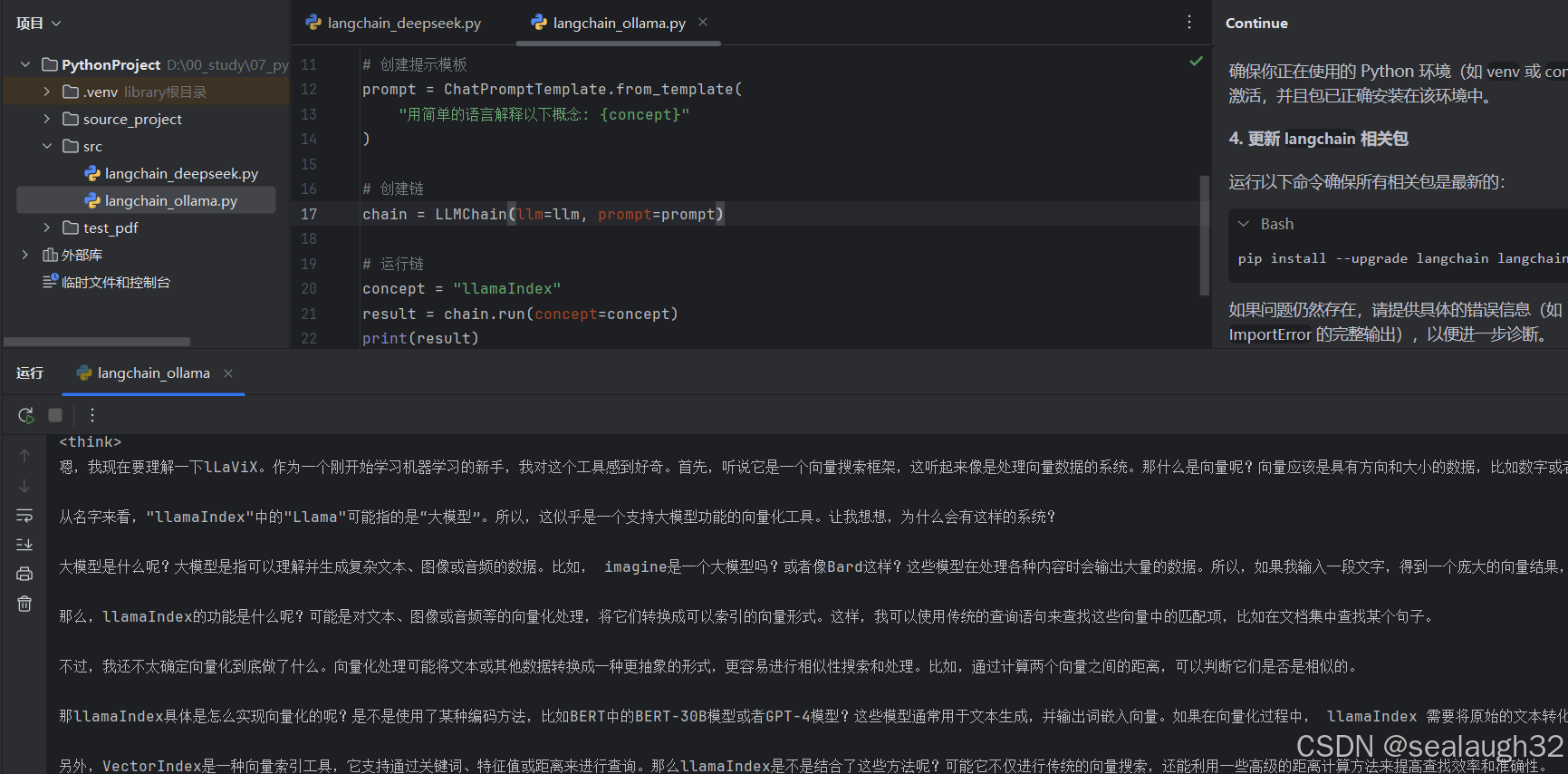
3.3 进行RAG Retrieval Argumented测试
3.3.1 知之为知之,不知AI知
使用LangChain构建向量数据库与Ollama集成@deepseek.com,问问AI会得到你想要的答案。
为什么不用自己构建的ollama,因为自己构建的本地机器性能太差,大模型查询一下耗时太长。
3.3.2 测试代码
import warnings
warnings.filterwarnings("ignore", category=DeprecationWarning)
from langchain.document_loaders.pdf import PyMuPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import OllamaEmbeddings
from langchain.vectorstores import Chroma
from langchain.embeddings import OllamaEmbeddings
from langchain.llms import Ollama
from langchain.chains import RetrievalQA
try:
# 创建文档loader,这里使用pdf loader
# langchain提供了大量的loader
loader = PyMuPDFLoader(
file_path="../test_pdf/test.pdf",
mode="single",
pages_delimiter="")
documents = loader.load()
# 对文档进行分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
splits = text_splitter.split_documents(documents)
# 使用Ollama的嵌入模型
embeddings = OllamaEmbeddings(model="llama2")
# 创建向量数据库,文档指定为上面的分割结果splits
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="../chroma/chroma_db"
)
# 使用chat大模型,指定在retriever中回答提问(人类的自然语言)
llm = Ollama(model="llama2")
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type="stuff" # 简单文档拼接方式
)
query = "文档中提到了哪些重要概念?"
result = qa_chain({"query": query})
print(result["result"])
except Exception as e:
error_msg = f"执行错误: {e}"
print(error_msg) # Continue 会捕获控制台输出
3.3.3 执行代码
TODO(继续检证)