目录
前言
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。前面也已经提到过,malloc本身就是一种内存池,malloc申请内存资源的方式已经很优秀了。而这个项目的原型tcmalloc就是在高并发场景下更胜一筹。
所以我们的项目主要处理的是在多线程下申请内存资源,我们的线程池需要考虑几个问题:
- 性能问题
- 多线程环境下,锁竞争问题。
- 内存碎片问题
而malloc也是一个内存池,它解决的问题就是1和3,他不考虑在多线程环境下锁的竞争问题 。通俗的讲,就是在多线程下,调用malloc时都是需要加锁的。
一,项目整体框架设计
高并发内存池(Concurrent Memory Pool)主要由以下3部分组成:
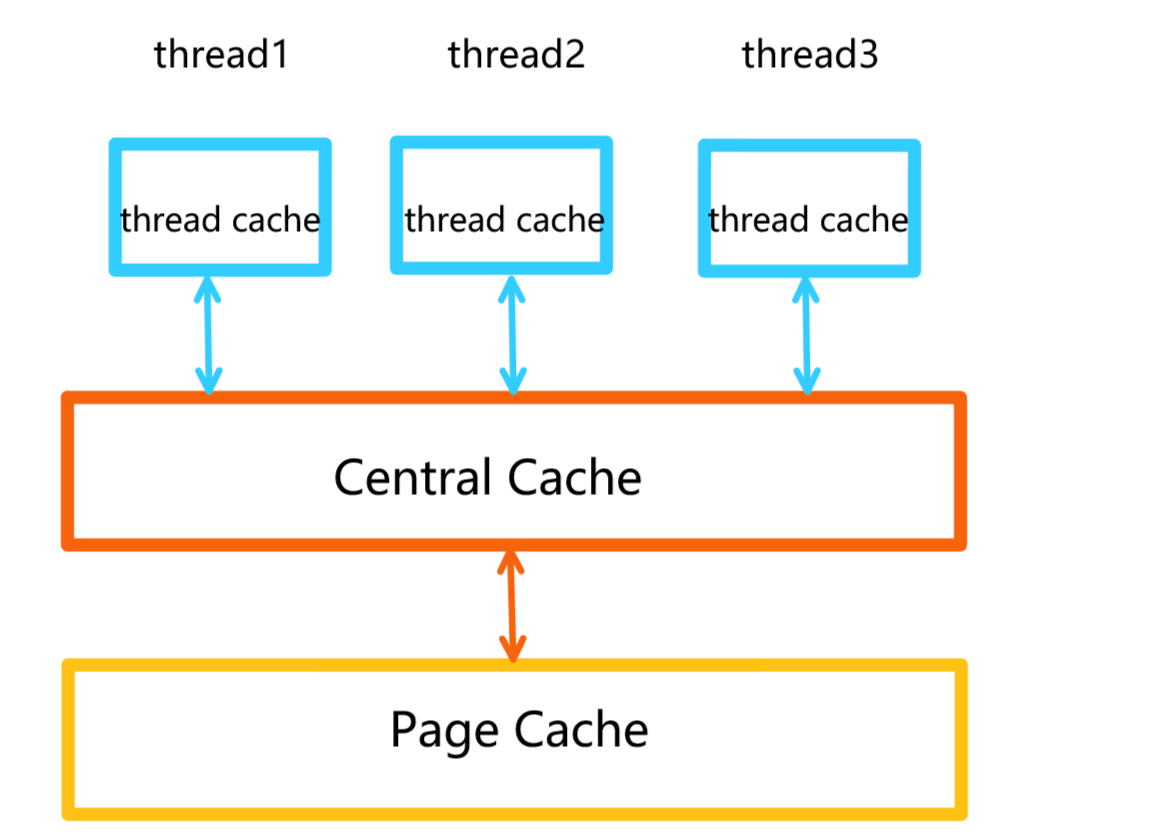
1,thread cache:每个线程独有的,用于小于256KB大小的内存分配。
- 如上图所示,每个线程都有一个自己的thread cache,那么在申请内存时,如果对应的thread cache中有内存,则直接分配,并且该过程是不需要加锁的,因为每个线程 独享一个thread cache。这也就是这个并发线程池高效的地方。
2,Central Cache:中心缓存,该部分是所有线程共享的。
- 当thread cache中没有足够的内存时,会向Central Cache进行申请。如果多个thread cache都需要向Central Cache申请,那么此时就会有多个线程来并发的访问Central Cache,此时就会存在线程安全的问题。所以该部分是需要加锁的。
- 所以在这一层会存在锁竞争的问题,但是后面会讲Central Cache是一个哈希桶的结构,只有当多线程访问同一个桶时,才会需要进行竞争锁的。所以这一层确实会存在锁竞争的问题,但是不会太过激烈,对效率方面影响不大。
- 同时,这一部分还需要完成回收内存的工作。也就是当thread cache中的内存达到一定条件时,会进行回收。这样做就可以避免,有的线程有过剩的内存空间,有的线程申请不到,通俗的说,就是一个人吃的太饱,一个人没得吃,就是为了解决这个问题。
3,Page Cache:页缓存,是Central Cache的下一级缓存。存储的内存是以页为单位的,并且分配内存的时候也是以页为单位的。在操作系统中,一页代表的内存大小是4KB或者8KB。
- 同理,当Central Cache没有内存时,会向Page Cache申请内存,Page Cache会以页为单位进行内存分配。那么当Page Cache的内存也使用完后,就会向操作系统申请。
- Page Cache同样也会回收 Central Cache的内存,当Page Cache内存达到一定条件时,就会将 这部分内存坏给操作系统。
二,thread cache结构设计
thread cache结构,有点类似于我们实现定长内存池的思路。
thread cahce是哈希桶结构,每个桶上是一个自由链表。每个线程都有一个thread cache对象,这样每个对象在这里申请对象和释放对象时是无锁的。
模拟定长内存池的设计思路
我们之前实现的定长内存池,它是解决固定内存大小的申请,我们在对内存资源进行管理的时候,使用的是一个自由链表,该自由链表管理的内存块是固定大小的,意思是该自由链表上的内存块要么都是 10字节的,要么都是20字节的等等。
而现在我们实现的高并发内存池,是要支持任意内存大小的申请,借鉴定长内存池的设计思路,我们可以使用多个自由链表来管理,说着太抽象,看图理解:
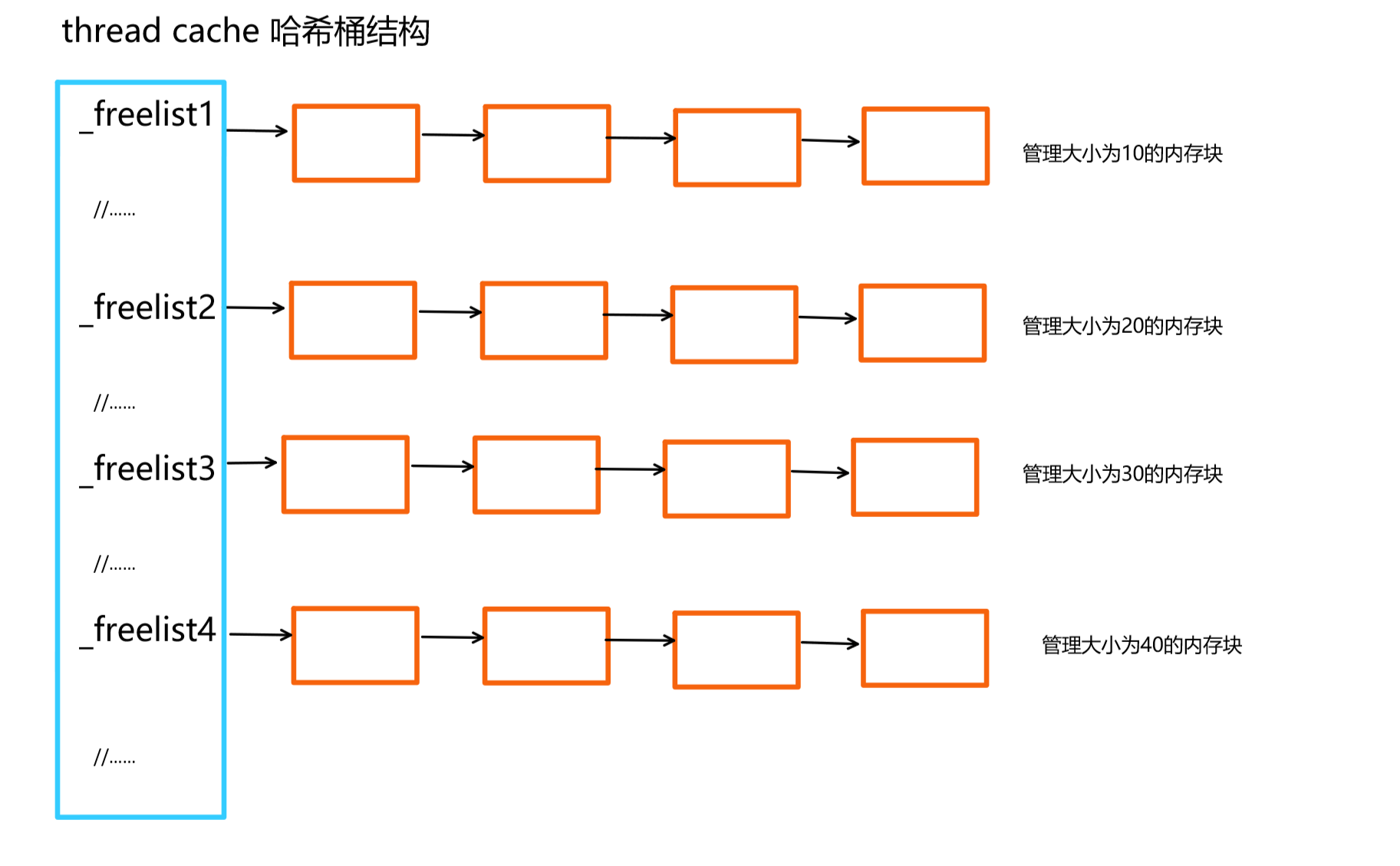
首先在上面提到过,thread cache的内存分配最大是256KB的,也就是256*1024=262114字节,也就是需要创建26万多个自由链表,然后每个链表管理对应内存块大小的管理。这种方法可行,当我想申请任意大小的内存时,都可以给我,但是可行性不高。
采用一定的对齐规则设计
在实现该部分的时候,可以进行一定的空间浪费,采取一定的对齐规则。比如,当申请1-8字节的内存大小时,都分配8字节的内存大小。这样就会存在一定的空间浪费,这种问题叫做内碎片问题。(内存对齐规则会在下面申请资源部分讲解)
对齐规则的定义:数据在内存中的起始地址必须满足特定数值的整数倍要求,这种约束称为对齐规则。
总结一下:
- 内碎片问题:比如由于对齐规则,我申请到了16字节,但是我只用12个字节,就会导致剩下的4个自己浪费,这是内碎片问题。
- 外碎片问题:是一段连续的空间,被切成好多块分出去,只有部分还回来了,但是它们不连续。导致下次再申请的时候,可能申请不成功。
thread cache大致框架
thread cache是一个哈希桶结构,每个桶是一个自由链表。
- 当一个线程申请内存时,假设申请的内存大小是n字节,首先找到对应 的thread cache,然后根据申请的内存大小n找到对应的哈希桶,也就是找到了对应的自由链表,如果自由链表不为空,头删即可;如果为空,找下一层Central Cache申请;
- 同理,当释放内存时,根据内存大小找到对应的哈希桶,也就是对应的自由链表,头插即可,当该自由链表的长度达到一定条件时,将这部分还给Central Cache;
对于自由链表会频繁的进行头删和头插 ,我们可以先封装一下,提供push和pop接口,封装好后下一层Central Cache也会使用。
//封装一下
//求一个内存块的前4个或者8个字节
void*& NextObj(void* obj)
{
return *(void**)obj;
}
//自由链表
class FreeList
{
public:
//头插
void push(void* obj)
{
//让 obj的前4个或者8个字节指向_freelist
/**(void**)obj = _freelist;*/
NextObj(obj) = _freelist;
_freelist = obj;
}
//头删
void* pop()
{
void* obj = nullptr;
//void* next = *(void**)_freelist;//保存_freelist的下一个内存块地址
void* next = NextObj(_freelist);
obj = _freelist;
_freelist = next;
return obj;
}
private:
void* _freelist=nullptr;
};thread cache大致框架
//thread_cache设计
class threadCache
{
public:
//申请空间
void* Allocate(size_t size);
//释放obj,大小为size
void Deallocate(void* obj, size_t size);
//......
private:
FreeList _freelists[];
};申请内存Allocate方法
1,thread cache 哈希桶的内存对齐规则
所谓内存对齐,就是当我申请一个大小为n的空间时,实际分配给我的是空间大小为m,这就是按照m字节对齐。
首先,这个项目最低的内存对齐规则是8,因为我们使用自由链表管理的时候,需要在内存块的头上 填充一个指针的大小,指针的大小在32位环境下是4字节,在64位环境下是8字节,所以最低是按照8字节对齐的。
- 按照8字节对齐的thread cache,如下图。当我想申请的内存小于等于8Byte时,就从第一个桶中获取。如果大于8字节小于等于16字节,就从第二个桶中获取。如果大于16,小于等于24,就从第三个 桶中获取。依次类推......
- 这种方案需要的哈希桶总数:总的字节数256*1024=262114,哈希桶个数262114/8=32768。一共需要3万多个哈希桶,还是太多了。
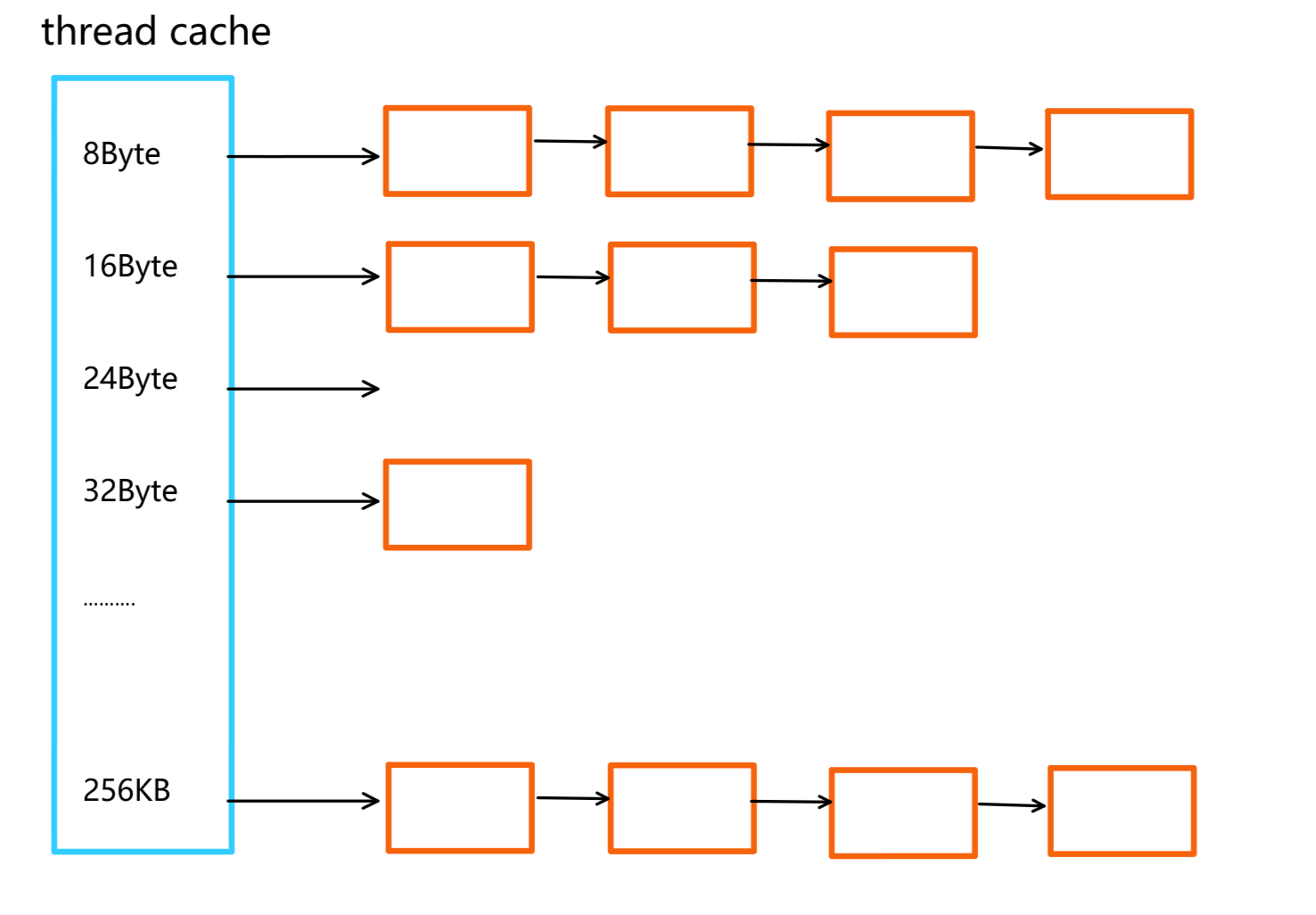
上面的方案,当申请一块大小为n的内存时,我们是无脑的按照8字节的对齐规则。
为了减少哈希桶的个数,对于申请的内存块大小n,我们可以根据n的范围,按照不同的内存对齐规则。n在某一个区间,采用这个区间的对齐规则。
对齐规则如下:
申请的空间大小 对齐规则
【1,128】 8Byte对齐
【128+1,1024】 16Byte对齐
【1024+1,8*1024】 128Byte对齐
【8*1024+1,64*1024】 1024Byte对齐
【64*1024+1,256*1024】 8*1024Byte对齐
申请的空间大小为n,n在[1,128]范围时,采用8字节对齐规则。在[128+1,1024]范围时采用16Byte对齐规则。 依次类推......
哈希桶个数的计算:
【1,128】,按照8字节对齐,需要的哈希桶个数128/8=16
【128+1,1024】,按照16字节对齐,需要的哈希桶个数(1024-128)/16=56
【1024+1,8*1024】,按照128字节对齐,需要的哈希桶个数(8*1024-1024)/128=56
【8*1024+1,64*1024】,按照1024字节对齐,需要的哈希桶个数(64*1024-8*1024)/1024=56
【64*1024+1,256*1024】,按照8*1024字节对齐,需要的哈希桶个数(256*1024-64*1024)/(8*1024)=24
综上一共需要16+56+56+56+24=208,只需要208个哈希桶。
这样设计的好处还有一个,就是可以将内存资源的浪费占比控制在10%左右。因为采取一定的对齐规则,就会不可避免的造成内碎片问题,产生内存资源浪费的问题。
浪费占比=浪费的字节数/实际申请的字节数
证明:
对于第一个哈希桶而言,浪费占比肯定很大,但是从第二个桶开始,可以将浪费占比控制在10%左右。
就比如对于【128+1,1024】区间,采用16字节对齐。假设现在想申请129的字节,按照16字节对齐规则,实际会分配144字节,此时会浪费15个字节,那么此时的浪费占比就是15/144=0.10416666,接近10%。
这种情况浪费的字节数是15,是最多的,同时申请的字节数是129,是这个区间最小的一个。意味着如果是其他情况,申请的字节数肯定更多(大于129),浪费的字节数肯定小于等于15,带到公式里就是分子变小,分母变大,那么结果会更小,所以可以将浪费占比控制在10%左右。
所以最终可以得到如下数据,这也就是我们的thread cache的设计规则:
申请的空间大小 对齐规则 对应的哈希桶
【1,128】 8Byte对齐 _freelist[0,16)
【128+1,1024】 16Byte对齐 _freelist[16,72)
【1024+1,8*1024】 128Byte对齐 _freelist[72,128)
【8*1024+1,64*1024】 1024Byte对齐 _freelist[128,184)
【64*1024+1,256*1024】 8*1024Byte对齐 _freelist[184,208)
2,内存对齐规则代码实现
了解到上述的内存对齐规则后,那么我们现在就需要实现两个方法。
当申请size大小的内存时,我们需要知道该size大小对应的对齐数,以及对应是thread cache的第几个哈希桶。
注意:这里的对齐数不是上面讲的对齐规则。对齐数是实际对齐的字节数。比如我现在想申请大小为12字节的内存,对齐规则是8Byte,实际分配到的是16Byte,对齐数是16字节。以一张图搞定:
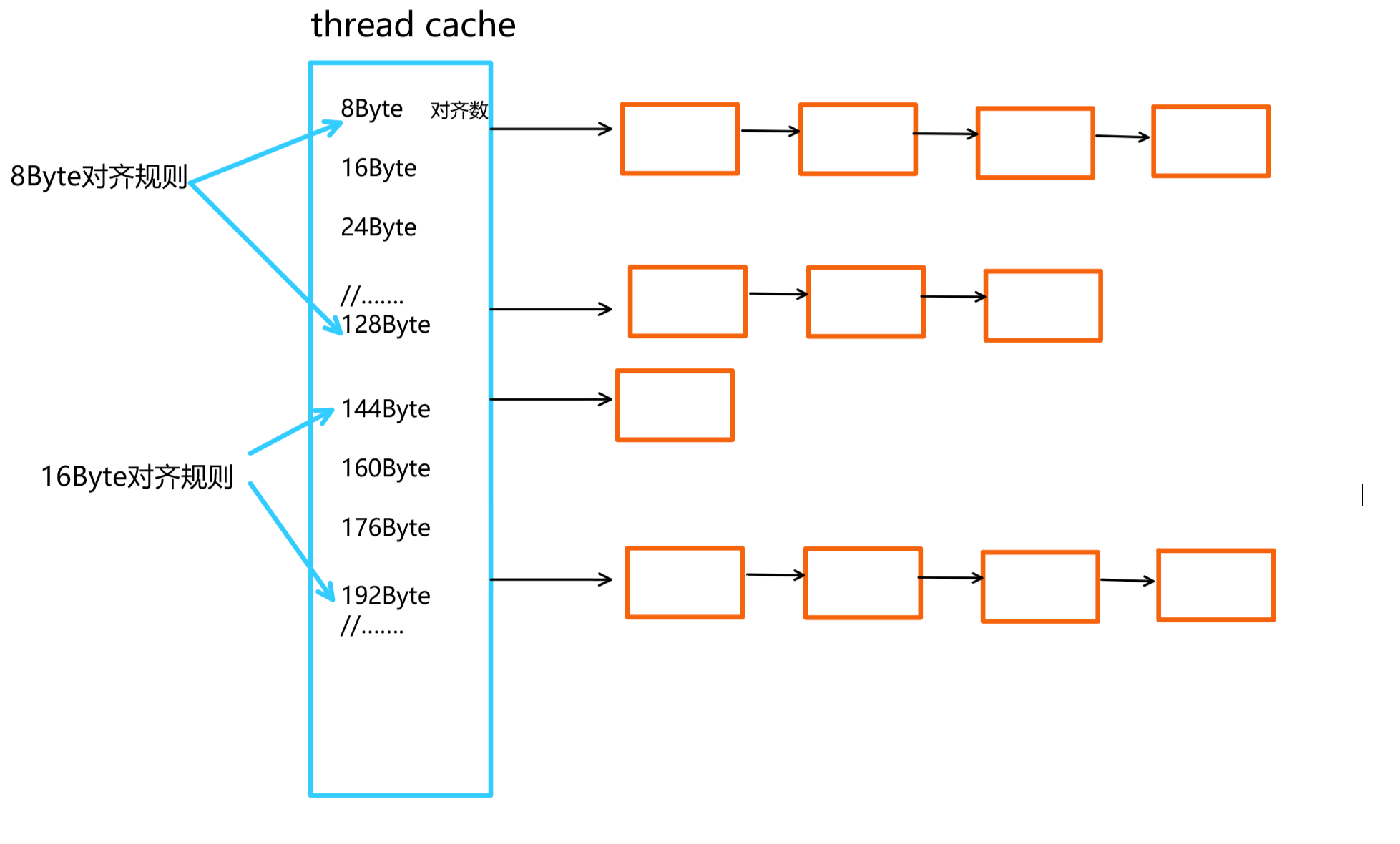
实现思路:

//计算对齐数以及第几个哈希桶
struct SizeClass
{
//计算对齐数的辅助函数
//第一个参数是申请内存的大小
//第二个参数是对应的对齐规则
static inline size_t _RoundUp(size_t bytes, size_t alginNum)
{
return ((bytes + alginNum - 1) & ~(alginNum - 1));
}
//计算对齐数
static size_t RoundUp(size_t size)
{
if (size <= 128)
{
return _RoundUp(size, 8);
}
else if(size<=1024)
{
return _RoundUp(size, 16);
}
else if (size <= 8 * 1024)
{
return _RoundUp(size, 128);
}
else if (size <= 64 * 1024)
{
return _RoundUp(size, 1024);
}
else if (size <= 256 * 1024)
{
return _RoundUp(size, 8*1024);
}
else
{
assert(false);
return -1;
}
}
//版本1 辅助函数
//第二个参数是对齐规则
//static inline size_t _Index(size_t bytes, size_t alginNum)
//{
// if (bytes % alginNum == 0)
// {
// //这里-1是因为下标从1开始
// return bytes / alginNum - 1;
// }
// else
// {
// return bytes / alginNum;
// }
//}
//版本2辅助函数
//第二个参数是对齐规则的指数
static inline size_t _Index(size_t bytes, size_t algin_shift)
{
return ((bytes + (1 << algin_shift) - 1) >> algin_shift) - 1;
}
//计算对应的哈希桶
//也就是计算在 _freelist中的下标
//bytes为申请的字节数
static size_t Index(size_t bytes)
{
//每个区间有多少链(多少桶)
//因为在对某一段区间进行计算的时候,求出对应是第几个桶后
//我们求的是下标,需要加上前面区间的长度,所以需要记录前一个区间的长度
static int group_array[4] = { 16,56,56,56};
//第二个参数是对齐规则的指数
if (bytes <= 128)
{
//申请[1,128]字节时,对齐规则是8
return _Index(bytes, 3);
}
else if (bytes <= 1024)
{
return _Index(bytes - 128, 4) + group_array[0];
}
else if (bytes <= 8 * 1024)
{
return _Index(bytes - 1024, 7) + group_array[0] + group_array[1];
}
else if (bytes <= 64 * 1024)
{
return _Index(bytes - 8 * 1024, 10) + group_array[0] + group_array[1] + group_array[2];
}
else if (bytes <= 156 * 1024)
{
return _Index(bytes - 64 * 1024, 13) + group_array[0] + group_array[1] + group_array[2] + group_array[3];
}
else
{
assert(false);
return -1;
}
}
};3,申请空间Allocate代码
//申请空间
void* threadCache::Allocate(size_t size)
{
//申请空间的上限是256KB
assert(size <= MAX_BYTES);
//计算对应的对齐数,以及哈希桶的下标
size_t alginSize = SizeClass::RoundUp(size);
size_t index = SizeClass::Index(size);
//如果对应的哈希桶不为空,则直接从该部分获取
if (!_freelists[index].Empty())
{
//头删即可
return _freelists[index].pop();
}
else
{
//对应的哈希桶,需要向下一层申请Central Cache
//这时候,就需要使用到对齐数alginSize
//....
return FetchMemoryFromCental(index, alginSize);
}
}
释放内存,还给thread cache管理
//释放obj,大小为size
void threadCache::Deallocate(void* obj, size_t size)
{
assert(obj);
assert(size >0);
//找到对应的自由链表,插入即可
size_t index = SizeClass::Index(size);
_freelists[index].push(obj);
}本节完!