系列文章目录
前言
导航和操作是具身智能的核心能力,然而在现实世界中训练具有这些能力的智能体却面临着高成本和时间复杂性。因此,从模拟到现实的转移已成为一种关键方法,但模拟到现实的差距依然存在。本调查通过分析以往调查中忽略的物理模拟器的特性,探讨物理模拟器如何解决这一差距。我们还分析了它们在导航和操作任务方面的特点以及硬件要求。此外,我们还提供了一个包含基准数据集、衡量标准、模拟平台和前沿方法(如世界模型和几何等差)的资源库,以帮助研究人员在考虑硬件限制的同时选择合适的工具。
具身智能、机器人导航、机器人操作、物理模拟器
一、简介
具身智能(EAI)涉及机器人等智能体通过传感器和行动与物理环境进行交互。对于大多数现代机器人应用来说,导航和操作是 EAI 的核心能力。这些任务需要智能体感知、理解环境并与之互动。人工智能的最新进展使得基于学习的方法--如强化学习(RL)和模仿学习(IL)--在训练导航和机械臂方面大有可为。然而,收集真实世界的数据来训练这些智能体的成本过高,尤其是在考虑到机器人设计或传感器的不同实施方案时。模拟器提供了一种具有成本效益和可扩展性的解决方案来解决这一问题,使机器人能够高效地在大型、多样化的数据集上进行训练。这些智能体通过 “模拟到现实”(sim-to-real transfer)的方式部署到现实世界中,在这一过程中,在模拟中训练好的智能体将适应现实世界的部署(Yang 等人,2023;Zhang 等人,2025b)。然而,模拟到现实的方法会遇到模拟到现实的差距。这种差距源于模拟环境与真实世界环境之间的差异,包括物理动态(如摩擦、碰撞和流体行为)和视觉渲染(包括照明和相机曝光)。先进的模拟器,如可变的、高度逼真的《创世纪》(作者,2024 年),可以缩小这种差距。它们通过精确的物理建模和逼真的渲染实现了这一目标,从而提高了在模拟中训练的智能体向现实世界机器人的转移能力。本调查报告全面概述了最近在具身智能机器人导航和操作方面取得的进展,强调了物理模拟器的作用。它详细介绍了模拟器的功能特性,并分析了相关任务、数据集、评估指标和前沿方法。这为研究人员选择适合其需求的工具提供了真知灼见。
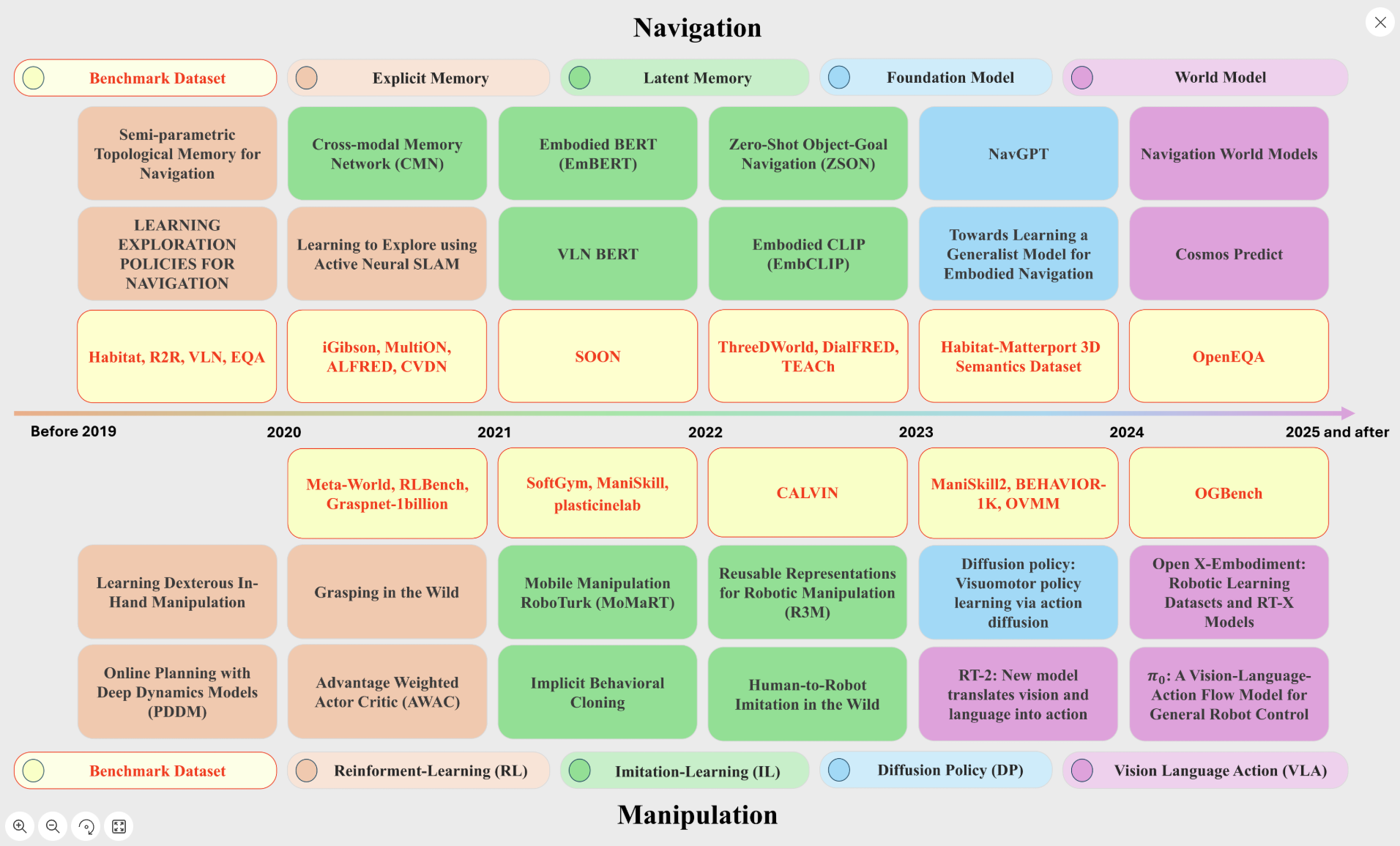
如图 1 所示,自 2019 年以来,导航和操作经历了突飞猛进的发展。在数据驱动方法日益受到关注的推动下,这两个领域都取得了重大进展。2020 年至 2022 年期间,导航和操作领域的演进速度加快。大规模数据集的引入(Fang 等人,2023a,2020;Mu 等人,2021;Lin 等人,2020;Shen 等人,2021;Li 等人,2021b;Shridhar 等人,2020;Yadav 等人,2023),包括那些广泛的数据集、 2023),包括那些拥有大量演示数据的模型,通过模仿学习实现了更好的模型泛化(Nair 等人,2023;Yang 等人,2025b;He 等人,[未注明];Fu 等人,2024b;Li 等人,2024c)。从 2022 年起,基础模型(Zhou 等人,2024b;Zheng 等人,2024a)、世界模型(Bar 等人,2024;Agarwal 等人,2025)和视觉-语言-行动(VLA)模型(Zitkovich 等人,2023;Collaboration 等人,2023;Black 等人,2024)的兴起标志着另一次飞跃。
在导航领域,越来越多的技术采用了隐式记忆,如基于潜在表征的记忆(Zhu 等人,2020;Suglia 等人,2021;Hong 等人,2021;Majumdar 等人,2022;Khandelwal 等人,2022)、基础模型(Zhou 等人,2024b;Zheng 等人,2024a)和世界模型(Bar 等人,2024;Agarwal 等人,2025)。这些进步得到了互联网规模的训练数据和大规模导航数据集的支持,如 iGibson(Shen 等人,2021 年;Li 等人,2021b)、ALFRED(Shridhar 等人,2020 年)和 Habitat-Matterport 3D Semantics(Yadav 等人,2023 年),这些数据集为通用导航智能体奠定了基础,通用导航智能体能够以最小的特定任务调整处理各种环境。
与此同时,操作方法也取得了长足进步,从早期基于强化学习(RL)的方法(OpenAI,2020;Nagabandi 等人,2020;Song 等人,2020;Nair 等人,2020)到模仿学习(IL)(Wong et al、 2022;Florence 等人,2021;Nair 等人,2023;Bahl 等人,2022)、扩散策略(DPs)(Chi 等人,2023)和 VLA 模型(Zitkovich 等人,2023;Collaboration 等人,2023;Black 等人,2024)。2020 年到 2022 年间,大规模数据集的引入,包括 GraspNet-1Billion (Fang 等人,2023a,2020)、ManiSkill (Mu 等人,2021)和 SoftGym (Lin 等人,2020),使得机械臂能够通过在不同任务的大规模数据集上进行预训练,实现更好的泛化。从2023年到2025年,RT-2(Zitkovich等人,2023年)和RT-X(Collaboration等人,2023年)等VLA模型整合了视觉、语言和动作,实现了多模态环境下更复杂的操作。这一演变--从RL到IL、DP和VLA--反映了向数据丰富的多模态策略的发展,支持了通用模型的开发,这些模型可以处理包括语言和图像在内的多模态输入,并适应多样化的操作场景,而无需特定任务的再训练。
Hwang 等人(Hwang 和 Ahuja,1992 年)、Yasuda 等人(Yasuda et al.,2020 年)、Duan 等人(Duan et al.,2022 年)和 Zhu 等人(Zhu et al.,2021 年)等人的早期研究是在大型语言模型 (LLM) 和世界模型出现之前进行的,因此不能反映该领域的最新突破。Liu 等人(Liu et al., 2024a)对 EAI 进行了广泛的概述,然而他们的分析在导航和机械臂任务方面缺乏深度。同样,徐等人(Xu et al., 2024)、马等人(Ma et al., 2024)和杨等人(Cong et al., 2023)的研究侧重于特定的方法论,如基础模型,而没有以这两项核心任务为中心,从 EAI 的角度进行全面、高层次的分析。Zheng 等人(Zheng et al., 2024b)关注操作方法,但忽略了现代模拟器进步的影响,如可微分物理模拟器,它有效地缩小了物理模拟与现实的差距方面,我们的调查对此进行了详细研究。此外,我们还根据三维空间粒度对表征学习进行了分类,将其与任务复杂性和模拟器选择联系起来,并深入探讨了几何等变表征的最新进展。
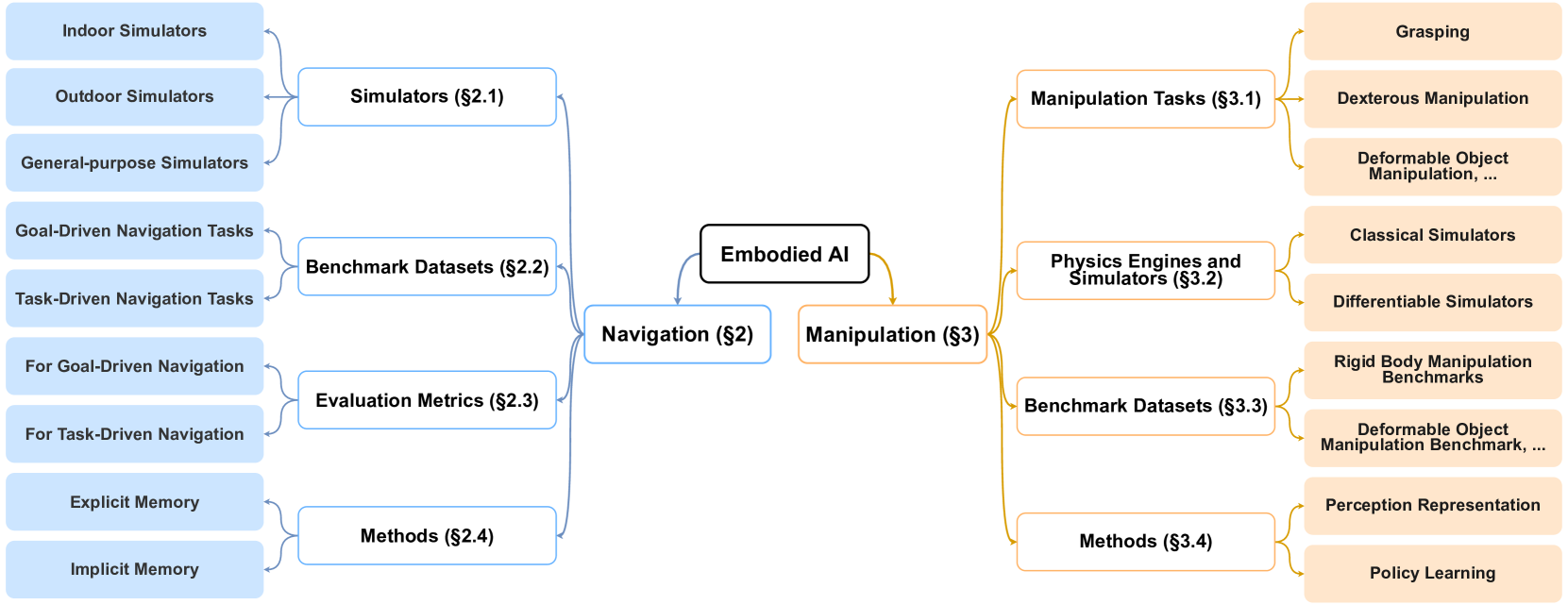
鉴于 EAI 的快速发展,有必要进行一次全面调查,以巩固这些进展并提供一个结构化的概览。本文详细探讨了 EAI,重点是导航、机械臂和为支持它们而设计的物理模拟器,如图 2 所示。我们研究了相关任务、模拟器、数据集、评估指标和方法,为研究人员和工程师创建了一个全面的资源库。这项调查有助于选择符合硬件能力和研究目标的模拟器、基准数据集和方法,从而推动 EAI 中导航和机械臂智能体的发展。
二、导航
导航是具身智能体的一项重要能力,使其能够部署在现实世界的各种应用中,包括自动驾驶汽车(Hu 等人,2023 年)、个人助理(Dai 等人,2024 年)、救援机器人(Zhou 等人,2024a 年)等。然而,直接在真实世界中训练这些智能体面临着巨大的挑战,包括高成本、时间限制、安全风险、设置环境的开销以及收集大规模训练数据的困难。为了克服这些挑战,“模拟到现实”(sim-to-real transfer)已成为一种流行的方法。然而,要成功实现从模拟到真实的转换,需要解决两个关键难题。首先是视觉上的 “模拟到现实 ”差距: 模拟器中的相机传感器必须呈现逼真的图像,以确保在模拟器中训练的智能体的感知模块能够适应真实世界的视觉观察。其次是物理模拟与现实之间的差距: 真实世界的环境中地形凹凸不平,在这些地方导航需要机器人具备强大的运动能力。要在模拟器中开发这些能力,物理引擎必须准确复制碰撞动力学,并向机器人的本体感觉传感器提供真实的反馈。这样才能确保在模拟中训练的运动控制策略能够无缝适应真实世界的物理限制,从而在部署时获得可靠的性能。
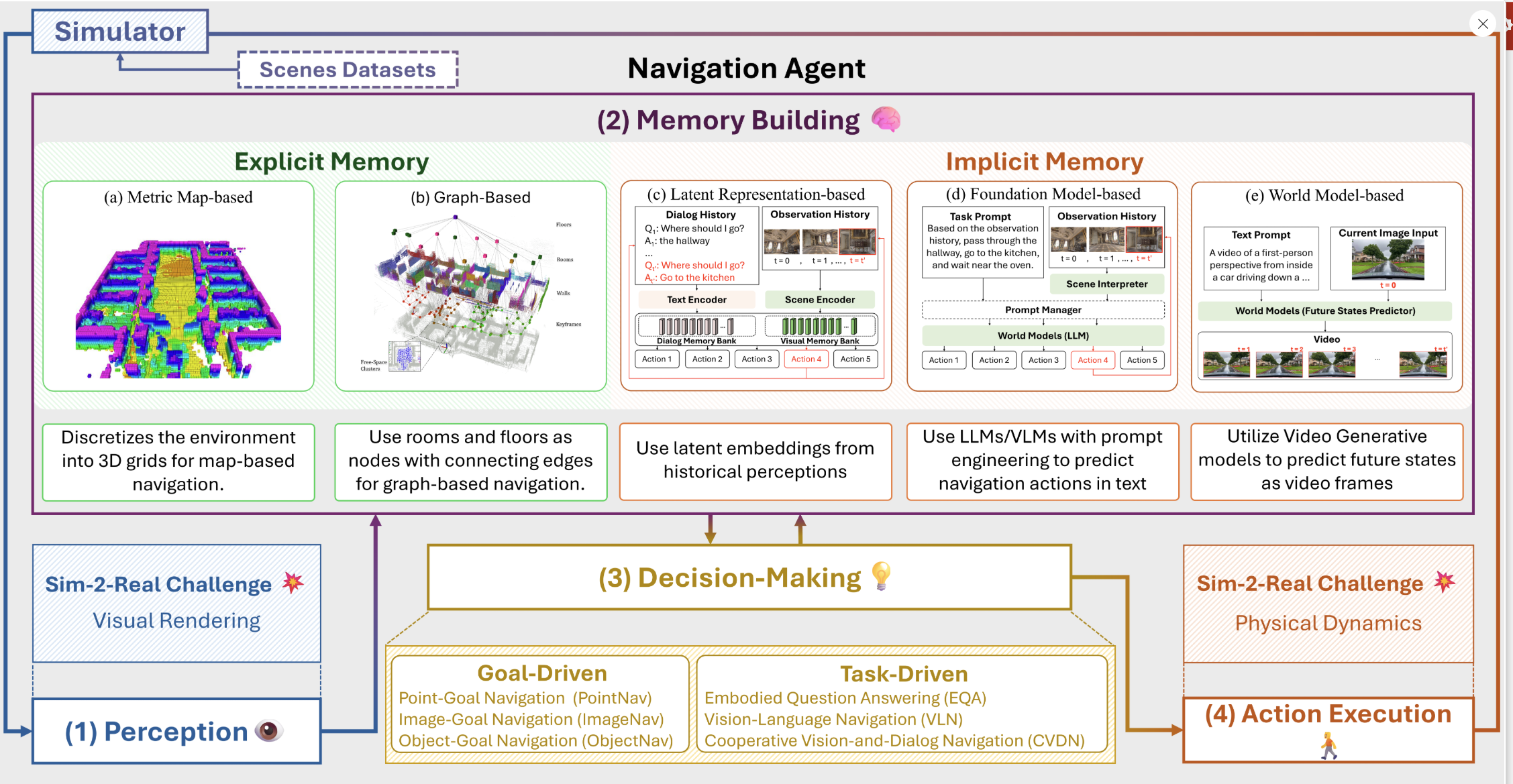
在图 3 中,我们详细分解了智能体在模拟器中的导航过程,强调了四个关键步骤,并展示了模拟到现实的挑战是如何出现的。这些步骤是
- 感知。智能体通过模拟器渲染的图像或点云等感官数据感知周围环境。这一步直接遇到了视觉模拟与现实之间的差距。为了在真实世界中有效部署,模拟传感器的输出应与真实世界的数据紧密匹配。除了视觉模拟与现实之间的差距外,现实世界的导航通常还涉及部分可观测性,这就限制了智能体在每个时间步长内只能感知环境的局部部分,如周围环境。因此,智能体必须随着时间的推移不断探索和积累这些局部观察结果,从而构建出对环境的全局记忆。
- 建立记忆。由于存在局部可观测性,智能体必须构建并维护环境的全局记忆。传统上,这依赖于显式记忆,包括
- 基于全局地图的记忆,为需要细粒度导航行动控制和避障的任务提供精确的空间布局(如图 3 所示的占位网格(Sun 等人,2018 年))。
- 基于图形的记忆,将环境表示为节点和边沿(例如拓扑图(Rosinol 等人,2020 年),如图 3 所示),用于更粗粒度的高级规划。
- 数据驱动方法,如利用大规模专家导航演示数据集进行模仿学习的方法,允许智能体在不维护显式数据结构来存储历史观察结果的情况下进行导航。这些智能体使用内隐记忆(Implicit Memories)来决定行动,内隐记忆可分为三种类型:
- 基于潜在表征(Latent Representation-based),包括存储编码历史观察结果和指令的潜在嵌入,并利用它们来规划未来行动。
- 基于基础模型,包括利用大型预训练模型,如大型语言模型(LLM)或视觉语言模型(VLM),将场景和语言指令编码为标记,并利用其广泛的预训练知识来推理导航步骤(Zhou 等人,2024b;Zheng 等人,2024a)。
- 基于世界模型,包括学习环境动态模型,根据当前状态和行动预测未来状态,如视频序列,并辅助规划和导航指导(Bar 等人,2024 年)。
- 决策。智能体利用其记忆,规划行动以实现特定目标。这一过程分为两种主要类型:
- 目标驱动导航,即智能体以特定位置为目标(例如,点目标导航中的一个点、图像目标导航中的一幅图像或物体目标导航中的一个物体)。
- 任务驱动导航,即智能体按照文本指令进行导航(例如,在 “嵌入式问题解答”(Embodied Question Answering,EQA)(Das 等人,2018)中回答问题,在 “视觉与语言导航”(Vision-and-Language Navigation,VLN)(Anderson 等人,2018b)中执行基于语言的指令,或在 “合作视觉与对话导航”(Cooperative Vision-and-Dialog Navigation,CVDN)(Thomason 等人,2019)中根据对话进行导航)。
- 动作执行。最后,智能体在模拟环境中执行动作。在训练具有运动能力的智能体时,要想成功实现从模拟到现实的转换,就需要模拟器准确复制现实世界的物理特性,确保在模拟中有效的控制指令在现实中也能无缝运行。因此,模拟器必须通过逼真地模拟物理交互来解决物理模拟与现实之间的差距,例如在不平地形上的碰撞,以及在光滑的冰面或粗糙的混凝土等各种表面上的摩擦。
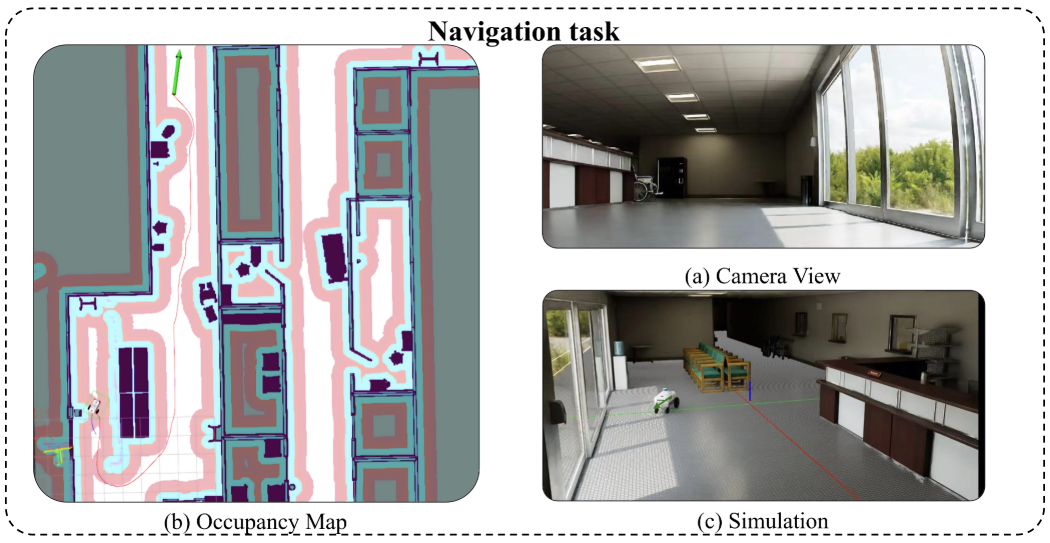
在详细介绍了导航过程之后,图 4 展示了在模拟环境中的这些步骤。具体来说,在(a)中,第一人称相机视图展示了具有逼真渲染效果的感知,例如玻璃门附近逼真的室外光线、精确的相机曝光和细致的室内阴影,从而缩小了视觉模拟与现实之间的差距。该视图还突出了部分可观察性的挑战,因为机器人只能感知其周围的环境,必须逐步建立对环境的全局记忆。在(b)图中,占用地图提供了自由区域和占用区域的空间表示,轮式机器人利用它来规划路径并避开障碍物,从而体现了显式记忆构建。最后,在(c)中,机器人在走廊中执行其规划的路径,展示了 “行动执行”(Action Execution)。
2.1 模拟器
根据所支持环境的可扩展性,现代导航模拟器可大致分为三类: 室内模拟器通常是为家庭等结构化、较小规模的环境定制的,以支持个人助理等应用;室外模拟器是为大规模、动态的室外环境设计的,通常用于自动驾驶汽车;通用模拟器可为室内/室外环境定制。这些模拟器所支持的环境规模会影响导航任务的选择和导航智能体的设计。例如,对于室内模拟器呈现的较小规模室内环境,显式记忆可能就足够了,而对于管理室外模拟器提供的大规模开放世界环境,则可能需要世界模型。此外,如第 2 节所述,模拟器必须解决两个关键的模拟到现实挑战--视觉模拟到现实差距和物理模拟到现实差距--才能实现有效的现实世界部署。因此,本节将对这些模拟器进行深入分析,探讨它们的物理特性以及如何减轻这些模拟到现实的挑战。表 2 提供了导航模拟器的详细功能比较,对物理引擎、渲染方法、支持的动力学以及与强化学习框架的兼容性等关键方面进行了评估。图 5 进一步显示了这些模拟器中的环境,从左到右依次为:Habitat(Manolis Savva* 等人,2019 年;Szot 等人,2021 年;Puig 等人,2023 年)、AI2-THOR(Kolve 等人、 2017)、CARLA(Dosovitskiy 等人,2017)、AirSim(Shah 等人,2018)、ThreeDWorld(Gan 等人,2020)和 Isaac Sim(Nvidia,[n.d.]),突出了它们的视觉渲染能力。这项分析为研究人员提供了一个全面的指南,帮助他们选择适合特定导航任务的模拟器,并评估它们弥合模拟与现实差距的能力。

室内模拟器。室内模拟器适用于结构化、小规模的环境,因此适合开发个人助理机器人在家庭等室内区域导航等应用。现有的室内模拟器通常利用真实世界的环境扫描或高级渲染来尽量缩小视觉模拟与真实环境之间的差距,同时将物理模拟的重点放在更简化的碰撞检测上。Matterport3D 模拟器(Chang 等人,2017 年)利用了 Matterport3D 数据集,该数据集由 10,800 个全景视图组成,这些视图来自真实世界中 90 个不同场景的 194,400 张 RGB-D 图像。通过使用数据集中的真实世界扫描,它实现了高视觉保真度,有效缩小了视觉模拟与真实之间的差距,因为模拟感知反映了实际的相机输出。但是,它不具备物理动态特性--它缺乏物理引擎,只能在预先计算好的视点(平均相距 2.25 米)之间进行离散转换导航,并通过可行走路径进行隐式碰撞检测。这种离散的设计使它不适合训练智能体在不平坦的地形上导航,因为这种运动需要实际的物理交互。
相比之下,Habitat-Sim(Manolis Savva*等人,2019;Szot等人,2021;Puig等人,2023)、AI2-THOR(Kolve等人,2017)和iGibson(Xia等人,2018)等模拟器集成了物理引擎,支持动态交互。例如,Habitat-Sim(Manolis Savva*等人,2019;Szot等人,2021;Puig等人,2023)渲染了来自Matterport3D(Chang等人,2017)、Gibson(Xia等人,2018)、HM3D(Ramakrishnan等人,2021)等数据集以及合成CAD模型的各种三维重建场景,在图形处理器(GPU)上实现了每秒超过10,000帧的渲染速度。为了增强感知的真实性,它集成了 RGB-D 传感器的噪声模型,模拟失真等缺陷,从而提高了感知模型从模拟到现实的可移植性。在物理动力学建模方面,它采用 Bullet 物理引擎进行刚体动力学建模,可在三维环境中进行精确的碰撞检测和运动。与 Habitat-Lab 库集成后,Habitat-Sim 可执行 PointGoal、ObjectNav、ImageNav、VLN 和 EQA 等任务,为导航研究提供了一个灵活的平台。同样,AI2-THOR(Kolve 等人,2017 年)利用 Unity3D 的基于物理的渲染(PBR)技术提供逼真的视觉效果。它支持域随机化技术,如改变材料和光照,以增强视觉模拟到现实的可转换性。AI2-THOR 采用的基于 Unity 的物理引擎支持逼真的碰撞检测和运动。ProcTHOR 扩展程序(Deitke 等人,2022 年)通过程序化生成 10,000 所独特的房屋来增强 AI2-THOR 的可扩展性,从而提供多样化的室内导航环境,实现策略通用化。此外,iGibson(Xia 等人,2018 年)使用带有双向反射分布函数(BRDF)模型的 PBR 来模拟逼真的光相互作用--捕捉到诸如随角度变化的反射率等效果--并结合域随机化来缩小视觉模拟与真实之间的差距。与 Habitat-Sim 一样,它采用 Bullet 物理引擎,确保碰撞和运动的精确动态。它还能在 15 个室内场景中容纳各种智能体(如人形机器人、蚂蚁),并可通过 CubiCasa5K 等数据集进行扩展。
室外模拟器。CARLA(Dosovitskiy 等人,2017 年)和 AirSim(Shah 等人,2018 年)为自动驾驶车辆和机器人提供了城市区域和自然地形的模拟环境。两者都利用虚幻引擎 4 中的 PhysX 技术,通过光线追踪和基于物理的渲染(PBR)提供逼真的渲染效果,同时采用域随机化技术将视觉模拟与真实之间的差距降至最低。然而,这些高级功能需要大量的计算开销。具体来说,为自动驾驶量身定制的开源模拟器 CARLA(Dosovitskiy 等人,2017 年)支持 CARLA2Real 等工具,以进一步增强逼真度,并利用 PhysX 进行物理模拟,管理车辆动力学、碰撞检测和运动。相比之下,AirSim(Shah 等人,2018 年)使用针对速度优化的定制物理引擎来处理碰撞检测和运动,并集成了 IMU 和 GPS 等逼真的传感器模型,以准确复制真实世界的状况。
通用模拟器。通用模拟器支持室内和室外设置,提供高保真的视觉效果和精确的物理效果。然而,这些特性也带来了计算复杂性的增加,通常需要高端 GPU 或高效的训练框架。ThreeDWorld(TDW)(Gan 等人,2020 年)基于 Unity3D 构建,使用 PBR 和高动态范围图像(HDRI)照明进行逼真渲染,最大限度地缩小了视觉模拟与真实之间的差距。它采用了 PhysX 物理引擎,支持布料和流体模拟,并能在真实环境中使用。此外,TDW 还支持像运输挑战赛(Gan 等人,2020 年)这样既需要室内操作又需要室外探索的任务。同时,英伟达公司开发的 Isaac Sim(Nvidia,[n.d.])利用 RTX 技术进行逼真的光线追踪渲染,从而最大限度地缩小了视觉模拟与现实之间的差距。它还利用 PhysX 引擎为碰撞检测和运动提供精确的动态效果。它与 Isaac Lab 集成,支持强化学习和模仿学习,以完成路径规划、从仓库到室外环境的扩展等任务。这些模拟器所支持的高保真模拟可确保所训练的策略建立在逼真的视觉和物理基础之上,从而提高其在真实世界场景中的部署能力。然而,为了满足这些模拟器的高计算要求,通常会使用分层训练框架: RL 或比例派生(PD)控制器管理运动和短程导航,然后是基于深度学习的路径规划器,如航点预测器(Choi 等人,2024 年)。
2.2.基准数据集
如第 2 节所述,具身智能中的导航任务包括目标驱动型导航(如 “点导航”(PointNav)、“图像导航”(ImageNav)和 “物体导航”(ObjectNav))和任务驱动型导航(如 “具身问题解答”(EQA)(Das 等人,2018 年)和 “视觉语言导航”(VLN)(Anderson 等人,2018 年b)),前者是指智能体根据复杂的文本指令进行解释和行动。为了便于在模拟器中对智能体的这些任务进行训练和评估,人们提出了各种基准数据集,每种数据集通常都与特定的模拟平台配对。本节将详细介绍导航基准数据集。我们根据这些数据集所支持的任务将其分为两大类:目标驱动型导航和任务驱动型导航。表 1 总结了这些基准数据集的主要特性,重点介绍了它们的规模、传感器数据和性能指标。HM3D(Ramakrishnan 等人,2021 年)(1,000 个场景)和 DivScene(Wang 等人,2024 年)(4,614 个场景)等数据集提供了广阔的环境,允许智能体在不同场景中进行泛化。值得注意的是,一些数据集提供了专家轨迹(如 VLN-CE(Ku 等人,2020 年;Krantz 等人,2020 年)、VLN-CE-Isaac(Cheng 等人,2024a)、Robo-VLN(Irshad 等人,2021 年)),可用于训练模仿学习策略。深度输入等传感器数据为空间感知提供了线索,而 iGibson(Xia 等人,2020 年;Shen 等人,2021 年;Li 等人,2021b)和 TEACh(Padmakumar 等人,2022 年)等数据集中的分割数据则能训练智能体获得对周围环境的语义理解。表中还列出了应用于每个数据集的基线方法及其成功率(SR),以便比较不同基准任务中的方法性能。
| Dataset | Size | Simulator | Sensor Data | Performance |
|---|---|---|---|---|
| Goal-Driven Navigation Datasets | ||||
| iGibson (Xia et al., 2020; Shen et al., 2021; Li et al., 2021b) | 100+ scenes; 27k object descriptions | iGibson | RGB, Depth, Segmentation | - |
| ION (Li et al., 2021a) | 600 scenes | AI2-Thor | RGB | - |
| HM3D (Ramakrishnan et al., 2021) | 1,000 scenes | Habitat | RGB, Depth | DD-PPO (Wijmans et al., [n. d.]): 97% SR |
| HM3D-OVON (Yokoyama et al., 2024) | 181 scenes | Habitat | RGB, Depth | DAgRL+OD (Ross et al., 2011): 37.1%-39.0% SR |
| MultiON (Gireesh et al., 2023) | 50,000 train episodes | Habitat | RGB, Depth | OracleMap (Gireesh et al., 2023): 94% SR (1-ON), 48% SR (3-ON) |
| DivScene (Wang et al., 2024) | 4,614 scenes; 81 scene types | AI2THOR | RGB | NATVLM (Wang et al., 2024): 54.94% SR |
| Task-Driven Navigation Datasets | ||||
| Room-to-Room (R2R) (Anderson et al., 2018b) | 90 scenes; 21,567 instructions | Matterport3D | RGB | SEQ2SEQ (Sutskever et al., 2014): 20.4% SR |
| VLN-CE (Ku et al., 2020; Krantz et al., 2020) | 90 scenes; 4475 trajectories | Habitat | RGB, Depth | Cross-modal attention model(Ku et al., 2020; Krantz et al., 2020): 33% SR |
| VLN-CE-Isaac (Cheng et al., 2024a) | 90 scenes; 1077 trajectories | Isaac Sim | RGB, LiDAR | NaVILA (Cheng et al., 2024a): 54.0% SR in R2R |
| ALFRED (Shridhar et al., 2020) | 120 scenes; 8k demos; 25k directives; 428k image-action pairs | AI2-Thor | RGB | SEQ2SEQ (Sutskever et al., 2014): 4% SR |
| DialFRED (Gao et al., 2022) | 112 rooms; 34,253 train tasks | AI2-Thor | RGB | Questioner-performer (Gao et al., 2022): 33.6% SR |
| TEACh (Padmakumar et al., 2022) | 120 scenes; 3,047 sessions | AI2-Thor | RGB, segmentation | E.T. (Pashevich et al., 2021): 9% SR |
| VNLA (Nguyen et al., 2019) | 90 scenes; 94,798 train tasks | Matterport3D | RGB | LEARNED (Nguyen et al., 2019): 35% SR |
| REVERIE (Qi et al., 2020) | 90 scenes; 21,702 instructions | Matterport3D | RGB | Interactive Navigator-Pointer (Qi et al., 2020): 11.28% SR |
| A-EQA (Majumdar et al., 2024) | 180+ scenes; 1,600+ questions | Habitat | RGB, Depth | - |
| Robo-VLN (Irshad et al., 2021) | 90 scenes; 3177 trajectories | Habitat | RGB, Depth | HCM (Irshad et al., 2021): 46% SR |
| LHPR-VLN (Song et al., 2024) | 216 scenes; 3,260 tasks | Habitat | RGB | - |
目标驱动导航数据集。目标驱动导航数据集逐步发展,以应对日益复杂的挑战,从基本的空间导航过渡到复杂的物体交互和多目标推理。Matterport3D 数据集(Chang 等人,2017 年)等早期成果提供了三维室内环境,但存在表面缺失等人工痕迹。Habitat-Matterport 3D(HM3D)数据集(Ramakrishnan 等人,2021 年)缓解了这些问题,最大限度地减少了 Matterport3D 数据集中缺失表面或未纹理区域等人工痕迹,为不同建筑布局中的 PointGoal 导航提供了高保真重建,从而缩小了视觉模拟与现实之间的差距。在此基础上,HM3D-OVON 数据集(Yokoyama et al. 同样,实例对象导航(ION)数据集(Li 等人,2021a)根据细粒度的属性描述(如颜色或材料),将重点细化为导航到特定的对象实例。多物体导航(MultiON)数据集(Gireesh 等人,2023 年)进一步增加了任务的复杂性,要求智能体导航一连串有序的物体,从而测试它们的记忆和规划能力。然而,这些数据集利用的是静态环境,不要求智能体在导航过程中与物体互动。真实世界的导航过程应该更加动态。为了解决这一局限性,iGibson 数据集(Xia 等人,2020;Shen 等人,2021;Li 等人,2021b)引入了交互式导航(Interactive Navigation),在这种导航中,智能体必须对物体进行物理操作,例如将物体推出路径,以便在杂乱的室内环境中到达目标。最近,随着大型语言模型的出现,DIVSCENE数据集(Wang等人,2024年)利用基于GPT-4的HOLODECK系统(Yang等人,2024年c)生成大规模、多样化的环境,并通过广度优先搜索(BFS)生成专家轨迹,提供多样化的室内场景,提高智能体在不同环境中的泛化能力。
任务驱动导航数据集。任务驱动导航数据集已经从基础性的指令跟踪基准发展到交互式框架,从而增强了在现实世界中的适用性。房间到房间(R2R)数据集(Anderson 等人,2018b)建立在 Matterport3D 数据集中的室内环境图像扫描基础上,通过要求智能体在离散环境中遵循自然语言指令,建立了视觉语言导航(VLN)。随后的工作,如 VLN-CE 数据集(Ku 等人,2020 年;Krantz 等人,2020 年),通过使用 R2R 扫描中的三维重建环境,将这些环境调整为连续环境。同时,VLN-CE-Isaac(Cheng 等人,2024a)进一步为有腿机器人量身定制了 VLN-CE 数据集,纳入了基于激光雷达的地形适应。然而,这些数据集主要利用低级的分步指令,要求智能体在没有额外辅助的情况下执行命令。相比之下,基于视觉的导航与基于语言的辅助(VNLA)数据集(Nguyen 等人,2019 年)提供了更高级别的指令(例如:(sayFind a towel in the kitchen),并允许智能体请求基于语言的指导,从而将重点转移到有效的求助策略上。此外,ALFRED(Shridhar et al.,2020)、DialFRED(Gao et al.,2022)和 TEACh(Padmakumar et al.,2022)等数据集将导航与物体操作和对话整合在一起。具体来说,ALFRED侧重于根据逐步指示完成家庭任务,而DialFRED和TEACh则与VNLA类似,通过对话进行说明来增强ALFRED。除了这些努力之外,A-EQA 数据集(Majumdar 等人,2024 年)被提议用于解决智能体问题解答(Embodied Question Answering,EQA),要求智能体探索环境以回答开放词汇问题。
2.3.评估指标
每种类型的导航任务都需要根据其不同的目标制定相应的评估指标。目标驱动型导航侧重于高效到达预定义的目标(如坐标、图像或物体),通常使用成功率、路径长度和完成时间等量化指标来衡量。相比之下,任务驱动型导航要求智能体根据文本指令执行动作,或在探索环境后回答问题,因此需要评估动作与指令一致性和回答准确性的指标。本节将分析这些指标,探讨它们在两种任务类型中的特性。此外,我们还将从四个关键角度对这些指标进行评估--规模不变性、顺序不变性、安全合规性和能效,如图 6 所示。这些视角解决了现实世界中的关键问题: 尺度不变性确保了从室内环境到室外景观等不同环境尺度下的度量稳健性;秩序不变性允许智能体通过不同路径实现导航目标,而不是遵循一条地面真实路线,因为现实世界中往往存在多条有效路径;安全合规性评估了智能体避免碰撞和危险区域的能力;能效评估了资源最优化,通常通过路径长度或导航持续时间来近似评估。
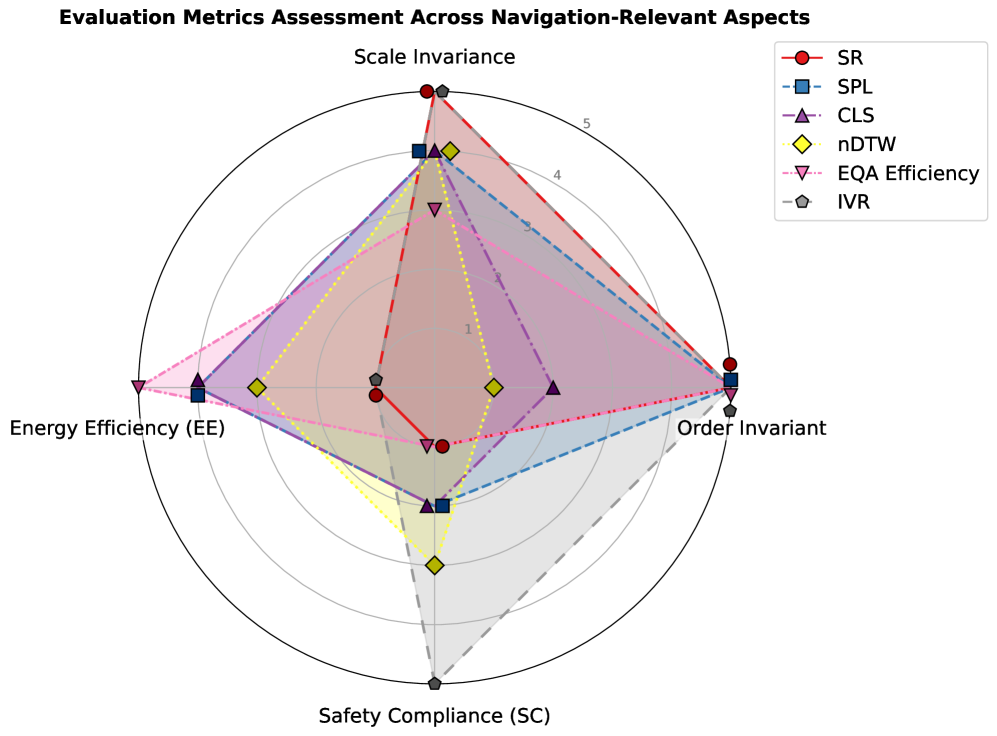
目标驱动导航任务的衡量标准。在目标驱动型导航中,智能体的目标是到达坐标、图像或物体等特定目标,因此评估指标优先考虑任务完成度和效率。成功率(SR)衡量的是智能体成功到达目标的事件比例,是衡量性能的基本指标。对于物体目标导航,智能体定位成功率(ILSR)(Li 等人,2021a)对成功率进行了扩展,要求智能体不仅要接近目标物体,还要在其他可见物体中正确识别目标物体--例如,在杂乱的房间中区分红色椅子和蓝色椅子--从而评估定位和识别能力。为了纳入路径效率,成功加权路径长度(SPL)(Anderson 等人,2018a)定义为
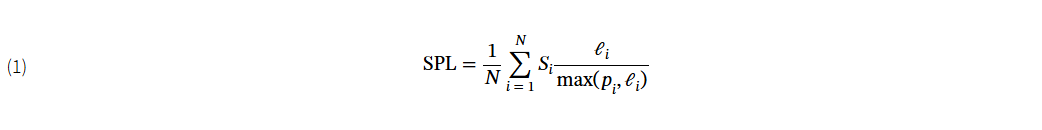
其中,N 是事件集数,Si 是成功指标,ℓi 是最短路径长度,pi 是实际路径长度。
任务驱动型导航任务的衡量标准。任务驱动型导航包括遵循文本指示或在探索后回答问题等任务。视觉语言导航(VLN)等任务可能需要智能体按照一步一步的指令导航特定路径。因此,这些任务需要将预测路径与参考路径进行比较的指标。例如,覆盖率加权长度得分(CLS)(Jain 等人,2019 年)可评估路径与参考路径的一致性。其定义为:CLS(P,R)=PC(P,R)⋅LS(P,R),其中路径覆盖率 PC(P,R) 衡量预测路径 P 和参考路径 R 的空间覆盖率,长度得分 (LS) 衡量预测路径长度与参考路径长度的匹配程度。此外,归一化动态时间扭曲(nDTW)(Ilharco 等人,2019 年)通过考虑空间排列和所采取的行动顺序对其进行了扩展。它生成的相似度得分范围在 0 到 1 之间,得分越高,说明在位置和顺序方面与参考路径的一致性越高。CLS(Jain 等人,2019 年)和 nDTW(Ilharco 等人,2019 年)都是通过参考路径长度对分数进行归一化来确保规模不变性。此外,Song 等人(Song et al., 2024)将 VLN 任务中的分步指令分解为多个子任务,并提出了独立成功率(ISR)(Song et al., 2024)指标来独立评估每个子任务的完成情况,从而实现了对 “左转,找门 ”等复杂指令的细粒度评估。在嵌入式问题解答(EQA)中,EQA 效率(Majumdar 等人,2024 年)表述为
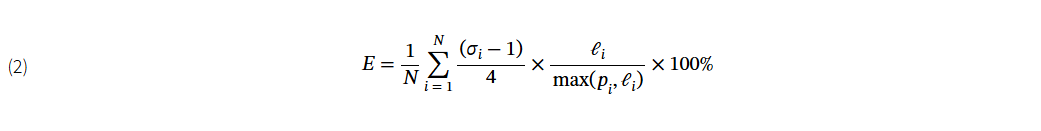
,将答案正确性(通过从 1 到 5 的 LLM 匹配得分 σi)与探索效率相结合,鼓励智能体通过更短的路径收集准确信息。最后,指令违反率(IVR)(Choi 等人,2024 年)的计算公式为:IVR=违反指令的情节数T情节总数,它量化了违反常理约束(如乱穿马路)的情况,直接解决了智能体遵守人类设定的安全规则的问题。
2.4.方法
如图 3 所示,在导航过程中,智能体会遇到部分可观测性,因此,需要建立历史观测和行动记忆,指导行动执行。本部分将通过两种记忆来探讨导航方法: 显式记忆和隐式记忆。
2.4.1 显性记忆
显式记忆构建涉及以结构化格式存储环境信息,以支持导航。这种方法分为两大类--基于度量映射(Metric Map-Based)和基于图形(Graph-Based)--它们的粒度和可扩展性各不相同。它们之间的选择取决于低级操作所需的精度和环境规模。全局地图擅长细粒度空间表示,可在小规模环境中进行精确控制,而图形则将环境抽象为拓扑关系,可在大规模环境中进行高效规划。
基于全局地图的方法。这些方法将环境离散化为网格、点云、体素或网格,以构建地图,从而简化路径查找等下游任务。例如,图 3(a) 显示了三维度量地图(Sun 等人,2018 年),它将环境表示为用于导航的三维网格。有几项研究使用二维占位图进行导航(Fu 等人,2022 年;Chaplot 等人,2020 年)。具体来说,Fu 等人(Fu et al., 2022)采用占位网格地图来计算到目标位置的大地测量距离,利用最陡下降法优化最短路径。此外,地图还可以结合语义线索(Kang 和 Yuan,2019;Chen 等人,2019;Huang 等人,2023a)。例如,Chen 等人(Chen et al., 2019)通过卷积神经网络(CNNs)融合从占位图和 RGB 图像中提取的语义特征,然后再通过递归神经网络(RNNs)整合时间信息,以提高探索性能。同时,Huang 等人(Huang et al., 2023a)通过基于深度的反向投影,将 RGB 图像中的对比语言图像预训练(CLIP)(Radford et al., 2021b)嵌入整合到网格中,从而构建语义网格图。通过网格嵌入和 CLIP 文本查询之间的余弦相似性评分,这种表示方法可实现开放词汇地标定位。在导航过程中,目标对象(如 \saysofa)可通过将其文本描述与网格特征相匹配来定位。虽然基于地图的方法可以通过将历史观测数据汇总到全局地图中来有效捕捉细粒度空间信息,但由于维护和更新大规模地图需要大量计算资源,因此这些方法在广阔的环境中表现出有限的可扩展性。
基于图的方法。图作为一种抽象结构,可以捕捉环境拓扑结构或物体的空间关系。对于较大的环境,拓扑图提供了一种可扩展的解决方案,它将观察到的关键地标(如门口、十字路口)表示为节点,将它们之间的可穿越路径表示为边。图 3(b) 显示了一个分层图(Bavle 等人,2023 年),将房间和楼层作为节点突出显示,并将连接边作为基于图的导航。有几项研究将拓扑图应用于图像目标导航--即要求智能体根据目标图像导航到一个位置。Savinov 等人(Savinov et al., 2018)提出了半参数拓扑记忆法(Semi-Parametric Topological Memory, SPTM),利用 CNN 将当前图像和目标图像编码为节点特征,并根据相似性得分规划路径。同时,Chaplot 等人(Singh Chaplot et al.,2020)提出了神经拓扑 SLAM,它使用全景图像作为图节点,通过比较当前视图中的门道和目标图像来生成探索路线。Beeching 等人(Beeching et al., 2020)通过训练神经规划器来估计图像嵌入节点之间的连接,将概率存储在图边,从而在不确定的环境中实现灵活导航,从而增强了这一功能。此外,知识图谱通过对物体之间的空间和功能关系进行明确建模,增强了物体目标导航功能。例如,Yang 等人(Yang et al., 2018)构建了一个知识图谱,其中的节点代表对象类别(例如,\saymug, \saycoffee machine),而边缘则编码\saynext to 或\sayin 等关系。这些图使智能体能够推断出未见物体的可能位置(例如,预测冰箱中的芒果位于苹果附近),并有效地进行导航。基于图的方法中的路径规划利用了环境的拓扑结构,允许使用经典算法(如 Dijkstra 算法)来寻找最短路径。此外,图形神经网络(GNN)可用于从拓扑图中提取高级特征,从而促进行动规划。
2.4.2.隐式记忆
隐式记忆包括智能体不依赖显式数据结构来表示环境的方法。相反,它们使用学习到的编码、预先训练的知识或预测模型,根据过去的视觉观察和行动做出决策。这种方法在动态或大规模环境中尤其具有优势,因为在这些环境中,传统的显式记忆结构可能并不实用。内隐记忆可分为三种类型: 基于潜在表征: 将历史数据编码为紧凑的潜向量,从而降低记忆需求。基于基础模型: 利用预先训练好的大型模型,利用互联网规模的知识来处理观察结果和指令,但这可能需要大量的计算资源。基于世界模型: 预测未来环境状态,为行动规划提供信息。
基于潜在表征的方法。地图和图形等显式记忆结构本质上是静态的,因此需要频繁更新才能捕捉动态的真实世界环境。这些更新会带来巨大的计算开销。基于潜表征的方法通过将观察和行动序列编码为潜向量,然后直接用于推断导航行动,从而解决了这一局限性。如图 3(c) 所示,这种方法通常将图像视图、指令或过去的对话历史(如问题-答案对)等输入编码为潜在表示。然后,这些表征通常会通过序列模型或转换器等架构纳入时间推理,从而保持动态的内部状态,捕捉相关的历史信息以推断行动。例如,Zhu 等人(Zhu et al., 2020)开发了一种基于对话的导航系统,该系统利用跨模态注意力学习视觉-文字联合嵌入,以整合图像和语言输入。长短期记忆(LSTM)(Hochreiter 和 Schmidhuber,1997 年)会随着时间的推移处理这些嵌入,提取时间信息,从而在没有明确地图的情况下从历史线索中推断行动。同样,Hong 等人(Hong et al.,2021)引入了 VLN-BERT,该模型将视觉语言 BERT 模型(Lu et al.,2019)用于导航,将 \sayClassify 标记作为转换器架构中的状态表示。这样,模型就能通过自我关注来维持和更新动态状态,捕捉指令、历史和当前观察结果,从而进行行动推理。不过,这些方法更容易出现累积错误,因为它们会根据历史观察结果逐步推断行动,通过连续决策传播不准确性。相比之下,Moghaddam 等人(Moghaddam et al., 2021)首先预测成功的未来状态,如目标或关键子目标,然后计划行动来实现它,通过将决策锚定到想象的结果来减少此类错误。基于潜表征的方法通常采用递归或转换器架构,将连续的视觉或文本输入压缩为动态的潜状态。通过整合一段时间内的历史观察结果,这些潜在表征可以缓解单个坐标系中的部分可观察性问题。然而,这种方法在应用于长视距导航任务时面临着局限性。压缩过程不可避免地会丢弃细粒度的空间细节,使得在长轨迹上记忆大规模环境布局具有挑战性,从而可能导致复杂环境中的错误累积。
基于基础模型的方法。基于基础模型的方法通过利用大型预训练模型(如大型语言模型(LLM)或视觉语言模型(VLM)),将场景和语言指令编码为文本标记或潜在嵌入,从而利用隐式记忆。这些模型在互联网规模的数据上进行训练,将预先训练好的知识作为内隐记忆,用于做出导航决策。图 3(d) 展示了这种方法,显示了 LLM 如何根据任务提示和观察历史生成动作。多项研究(Wang 等人,2025b;Zhou 等人,2024b)利用视觉基础模型将视觉观察和导航指令转换为文本描述,并将其输入 LLM,以自回归方式预测下一个导航动作。例如,Zhou 等人提出的 NavGPT(Zhou 等人,2024b)依赖于 LLM(GPT-4)的文本推理能力来解释当前场景,通过文本中总结的历史记录跟踪进展,并从可导航的视点中选择行动,所有这些都以零镜头的方式进行,无需特定任务训练。然而,仅仅依赖文本描述可能会导致细粒度视觉细节的丢失,从而使在实际环境中准确地进行操作面临挑战。为了解决这个问题,视觉语言模型(VLM)通过直接整合视觉和文本信息提供了一种解决方案,从而保留了更多的原始视觉环境。例如,Zheng 等人(Zheng et al., 2024a)介绍了 NaviLLM,它采用 VLM 直接整合历史和当前视觉特征(通过视觉转换器提取)与文本指令,从而为视觉语言导航(VLN)和嵌入式问题解答(EQA)等任务生成动作。然而,由于这些方法依赖于没有精确空间背景的隐含知识,因此容易产生幻觉。Zhang 等人最近完成的一项名为 MapNav 的研究(Zhang et al. 具体来说,MapNav 将 VLM 与一种度量地图--注释语义地图(ASM)相结合,使 VLM 能够将其预先训练的隐式知识与显式空间信息相结合,从而实现更精确、更可靠的导航。
基于世界模型的方法。另一类内隐记忆方法是基于世界模型的方法,这种方法通过学习预测未来的环境状态,如视觉观察(如图 3 (e))或潜在动态来指导导航。这些方法还能生成大规模合成数据集,从而解决具身智能中机器人数据集稀缺的关键难题。具体来说,通过模拟不同的环境场景,这些方法为导航策略提供了大量训练数据,增强了导航策略在各种情况下的泛化能力,甚至包括自动驾驶中复杂的开放世界场景。此外,世界模型的预测能力有助于轨迹优化,通过模拟未来状态规划最优行动序列。例如,巴尔等人(Bar et al., 2024)训练了一个导航世界模型(NWM),这是一个视频扩散模型,用于生成潜在的未来坐标系,以评估导航路径。在新奇的环境中,它利用先前的视觉经验从单个图像中推断出未见过的路线。同样,X-Mobility(Liu 等人,2024f)采用潜在世界模型预测环境动态,并模拟潜在空间中潜在的未来结果。最近,英伟达公司推出了 Cosmos Predict(Agarwal 等人,2025 年),这是一个在 Omniverse 平台内的大规模机器人和驾驶数据集上训练出来的世界模型。它可以通过文本和图像输入预测未来的视频状态。Cosmos Predict 与 Cosmos Reason(一个思维链(CoT)推理模型)配对使用,后者将 Cosmos Predict 的预测解释为文本,以指导导航决策--例如,如果 Cosmos Predict 预测有行人横穿马路,则建议降低驾驶速度。
三、机械臂操作
通过 “模拟-现实”(sim-to-real)技术训练机械臂,既需要了解机械臂感知系统中的精确几何细节,也需要使用能够模拟现实物理动态的模拟器。假设一个机器人正在模拟环境中学习拧开瓶盖:它必须感知并准确理解瓶盖及其末端效应器的形状和姿势。此外,模拟器还必须模拟逼真的物理交互,包括多点接触、摩擦和碰撞力,以便成功实现从模拟到现实的任务转移。因此,当前的操作研究涉及推进感知建模、开发模拟器和物理引擎。值得注意的是,可微分模拟器近来备受瞩目:这些模拟器提供了有关物理状态的梯度,用于训练策略,具有更好的模拟到现实的转换能力(见第3.2节)。
此外,操作任务的复杂程度也各不相同。随着任务变得越来越复杂,智能体需要更先进的感知方法和硬件。较简单的任务,如平面抓取,通常可以使用 2D 传感器(如 RGB 摄像头)和基本的抓手来完成。然而,灵巧的手部操作需要三维感知--利用点云或体素等表征--以及多指手。这突出表明,对感知、表征、模拟器和硬件的要求随任务难度的不同而变化。
因此,为了深入分析操作研究,本节内容安排如下: 我们首先对关键操作任务进行分类和分析,评估其复杂性和相关硬件要求(§3.1)。然后,我们探讨物理引擎和模拟器,强调为操作而设计的经典平台和可微分平台(§3.2)。接下来,我们调查了基准数据集,强调了它们在不同任务和机器人平台上扩展通用性的重点和作用(§3.3)。最后,我们研究了用于感知表征和策略学习的核心操作方法(§3.4)。
3.1.操作任务
为了更好地理解与操作相关的挑战,我们首先按照复杂程度和所需自由度(DoFs)对关键操作任务及其相关硬件进行分类,如图 7 所示。下面,我们将详细探讨每项任务:
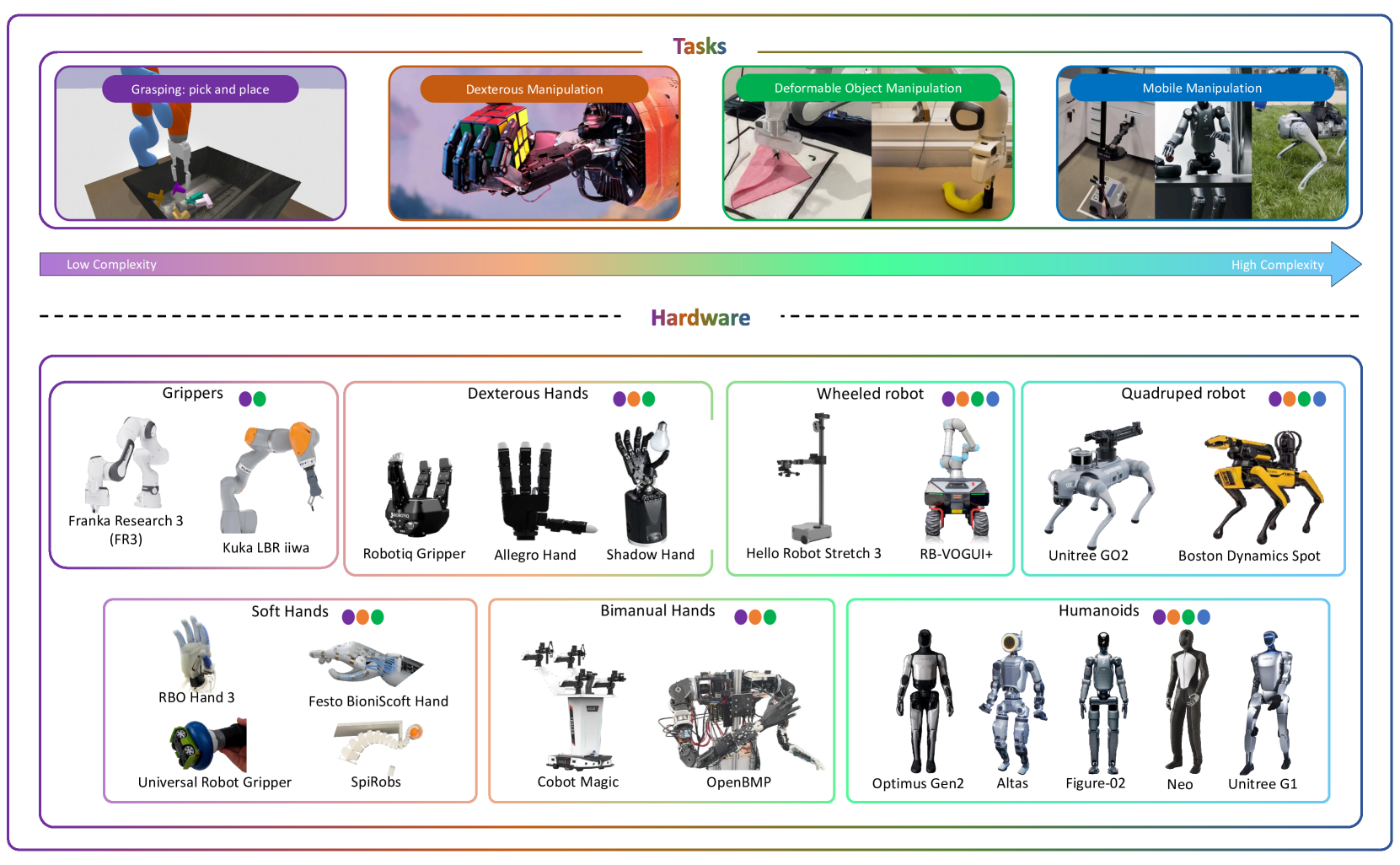
- 抓取是机器人技术中的一项基本任务,通常坐标系为 “拾放操作”,即机器人必须抓住一个物体并将其放置到一个新的位置。平面抓取涉及三个自由度(DoF),通常用于抓取平面上的物体。与此同时,全三维抓取需要六个自由度(x、y、z、滚动、俯仰和偏航)来处理任意姿势的物体,这就要求机器人手臂具有更高的自由度,以实现有效的协调。
- 灵巧操作是指使用多指手(通常有三个或更多手指)进行手部操作。这项任务采用手指步态、滚动或旋转等技术(Han 和 Trinkle,1998 年;OpenAI,2020 年)来控制手中物体的方向(例如,扭转魔方和旋转钢笔)。这项任务要求手指之间精确协调,以处理移动物体时涉及的复杂接触动态。对于形状复杂的物体,精确模拟手指与物体之间的摩擦力和多点接触至关重要--MuJoCo(Todorov 等人,2012 年)等模拟器有效地提供了这种能力。
- 可变形物体的操作涉及到对布料或绳索等软性材料的处理,这些材料在受到外力时会弯曲、挠曲或变形。与形状固定的刚性物体不同,软体物体中各点的相对距离并不固定,因此会产生高度动态和复杂的物体状态空间。打结或折叠衣服等任务需要实时监控物体的几何变形,并根据弹性和摩擦力等材料特性进行精确控制。
- 移动操作涉及安装在具有导航功能的移动平台上的机械臂,如轮式、四足机器人或人形机器人。例如,机器人可能会导航到厨房,打开抽屉,拿起杯子,这就要求机器人既要在环境中导航,又要操作物体。
- 开放世界操作(Open-world manipulation)可以解决无限变异问题(Tedrake, 2024)。它要求机器人在非结构化的动态环境中处理新奇的物体,例如在杂乱的空间中拾取未见过的物品。这些环境的不可预测性要求机器人从有限的训练数据中进行归纳,并适应新的物体、材料或条件。
- 易碎物品操作涉及易碎物品的处理,需要精确的力控制和小心的操作,以防止损坏物品。一种常见的方法是使用由橡胶、硅胶或碳纤维等材料制成的软机器人抓手。这些机械手采用气动(Su 等人,2022 年)、液压(Zhou 等人,2025 年)或腱驱动(Wang 等人,2025a 年)系统等致动器来控制手指运动,确保压力分布均匀,从而实现更安全的操作。精确的力控制是避免损坏的关键,因此需要针对不同的易碎程度(如蛋壳和浆果)制定实时反馈和自适应控制策略。准确模拟物体特性对于有效训练这项任务至关重要。此外,通过视觉线索(如几何形状、纹理)或触觉反馈检测脆性对于适当调整握力也至关重要。
- 双机械臂操作采用双臂系统,如 ALOHA(Zhao 等人,2023 年),来执行需要协调性超出单臂能力的任务,如组装乐高积木。
3.2 物理引擎和仿真器
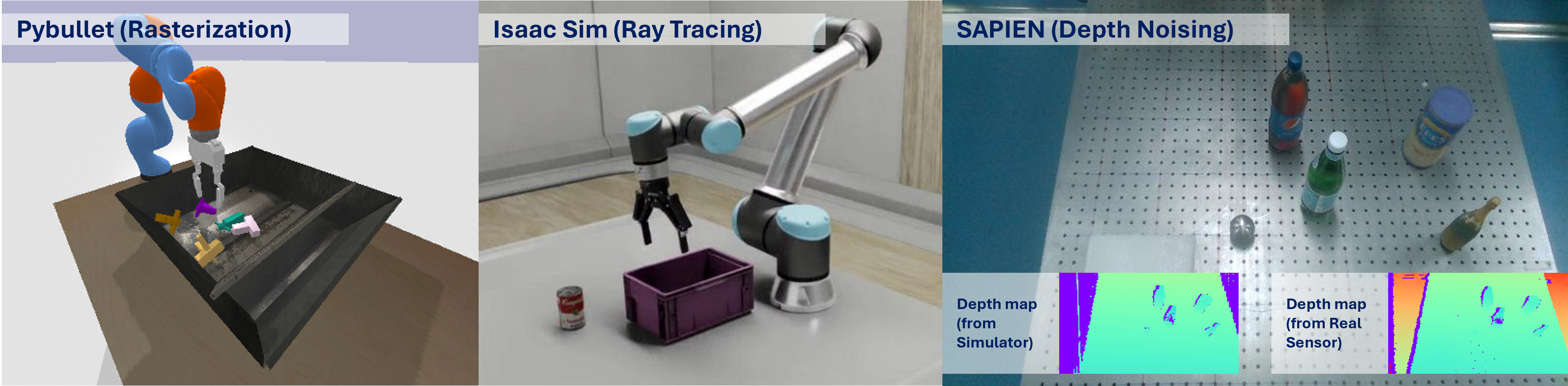
与导航模拟器类似,操作模拟器必须同时解决物理和视觉模拟与真实之间的差距,以确保机器人智能体的有效培训和部署。然而,缩小物理仿真与真实之间的差距对于操作任务尤为重要,因为操作涉及与物体的更多交互。模拟操作任务涉及对复杂的物理交互(如多点接触)、特定材料摩擦(如石头或冰)和碰撞力进行建模,随着任务复杂性的增加(灵巧操作比平面抓取涉及更多的碰撞),这些因素也变得越来越复杂。要想开发出能无缝转换到真实世界场景中的控制策略,对这些动力学进行精确模拟至关重要。最近,像 Genesis 这样的可微分模拟器通过提供物理状态的梯度推进了这一能力,从而缩小了物理模拟与现实之间的差距,实现了操作策略的精确优化。对于视觉模拟与现实之间的差距,模拟器采用了先进的渲染技术,如光线跟踪和逼真的深度噪声,来创建逼真的环境,以接近真实世界的条件,如图 8 所示。在本节中,我们将探讨专为机械臂操作任务设计的各种物理引擎和模拟器。我们将把 MuJoCo 和 Isaac Sim 等经典引擎与 Dojo 和 Genesis 等可微分引擎进行比较,评估它们在物理动态建模和视觉保真度方面的能力。此外,我们还将重点介绍这些引擎开发过程中的重要里程碑,并对不同的仿真平台进行详细比较,如图 9 和表 2 所示。

经典物理引擎和模拟器。经典模拟器依靠传统力学模拟物理动力学和接触建模,多年来一直是机器人模拟的基础。下面,我们将讨论几种主要的经典模拟器及其应对这些物理和视觉模拟到现实挑战的方法。Gazebo(Koenig 和 Howard,2004 年)与机器人操作系统(ROS)紧密集成,支持多种物理引擎,如动态动画和机器人工具包(DART)、开放动力学引擎(ODE)和用于刚体动力学的 Bullet。这些物理引擎主要用于刚体仿真。在视觉方面,它利用了开源三维图形引擎(OGRE),该引擎支持 GPU 加速着色,但缺乏光线跟踪或逼真功能。同时,PyBullet(Coumans 和 Bai,2016 年)注重速度和效率。PyBullet 基于 Bullet 物理引擎构建,提供 GPU 加速和连续碰撞检测,以提高仿真速度。它使用线性互补问题(LCP)接触模型进行物理仿真,该模型计算量大,可能会不准确地近似接触点的摩擦锥,从而影响物理仿真与现实之间的差距。PyBullet 的渲染仅限于通过 OpenGL 进行光栅化,不支持光线跟踪或深度噪声模拟,因此限制了其缩小视觉模拟与真实差距的能力。相比之下,MuJoCo(Todorov 等人,2012 年)将接触动力学的精确性放在首位,使其适用于灵巧的机械臂操作。它在多关节系统仿真方面表现出色,具有精确的接触建模,能使用广义坐标捕捉机械臂动态,并实现稳定、摩擦力丰富的交互。不过,它的软接触模型可能会在撞击时导致相互渗透。在视觉上,它通过 OpenGL 使用基于光栅化的渲染,缺乏硬件加速的实时光线跟踪,限制了视觉保真度,扩大了视觉模拟与真实之间的差距。不过,它支持多线程,可加快强化学习速度。在逼真渲染方面,Isaac Sim(Nvidia,[n.d.])和 SAPIEN(Xiang 等,2020;Mo 等,2019;Chang 等,2015)脱颖而出。它们利用 GPU 加速光栅化和实时光线追踪技术,创建具有精确光照和反射的逼真环境,有效缩小了视觉模拟与现实之间的差距。SAPIEN 还支持内置的高级深度噪点模拟,可根据距离、物体边缘和材料属性生成带有噪点的逼真深度图,从而增强视觉保真度,显著提高模拟到现实的转换能力。它们使用 Nvidia PhysX 引擎进行物理仿真,支持强大的刚性、柔性和流体动力学物理仿真。最后,CoppeliaSim(Rohmer 等人,2013 年)通过支持多个物理引擎(MuJoCo、Bullet、ODE、Newton、Vortex)提供了灵活性,从而实现了对刚性、柔性和布动力学的模拟。这种适应性有助于根据特定任务定制物理仿真,尽管其缺乏 GPU 加速功能限制了效率。与 Isaac Sim 和 SAPIEN 相比,它的渲染主要是通过 OpenGL 进行光栅化处理,并支持部分光线追踪,在逼真度方面还有所欠缺。
| Manipulation Simulator | ROS | PE | Rendering | Dynamics | RL | URDF | GPU | OS |
|---|---|---|---|---|---|---|---|---|
| SAPIEN (Xiang et al., 2020; Mo et al., 2019; Chang et al., 2015) | ✓ | PhysX 5 | Rast; RT⋆ | R; S; F | ✓ | ✓ | ✓ | ✓ |
| Isaac Sim (Nvidia, [n. d.]) | ✓ | PhysX 5 | Rast; RT | R; S; C; F | ✓ | ✓ | ✓ | |
| PyBullet (Coumans and Bai, 2016) | ✓ | Bullet | Rast | R; S; C | ✓ | ✓ | ✓ | |
| MuJoCo (Todorov et al., 2012) | ✓ | MuJoCo | Rast | R; S; C | ✓ | ✓ | ✓† | ✓ |
| CoppeliaSim (Rohmer et al., 2013) | ✓ | MuJoCo; Bullet; ODE; Newton; Vortex | Rast; RT‡ | R; S; C | ✓ | ✓ | ✓ | |
| Gazebo (Koenig and Howard, 2004) | ✓ | Bullet; ODE; DART; Simbody | Rast | R; S; C | ✓ | ✓ | ✓ | |
| Genesis (Authors, 2024) | Genesis (based on DiffTaichi) | Rast; RT | R; S; C; F | ✓ | ✓ | ✓ | ✓ | |
| Navigation Simulator | ||||||||
| Matterport3D (Chang et al., 2017) | ✓ | ✓ | ✓ | |||||
| Habitat (Manolis Savva* et al., 2019; Szot et al., 2021; Puig et al., 2023) | ✓⋄ | Bullet | Rast | R | ✓ | ✓ | ✓ | ✓ |
| AI2-THOR (Kolve et al., 2017) | PhysX | Rast | R; S; C; F | ✓ | ✓ | ✓ | ||
| iGibson (Xia et al., 2018; Li et al., 2021b) | ✓ | Bullet | Rast | R; S; C | ✓ | ✓ | ✓ | ✓ |
| CARLA (Dosovitskiy et al., 2017) | ✓ | PhysX | Rast | R∘ | ✓ | ✓ | ✓ | |
| AirSim (Shah et al., 2018) | ✓ | PhysX | Rast | R∘ | ✓ | ✓ | ✓ | |
| ThreeDWorld (Gan et al., 2020) | PhysX | Rast | R; S; C; F | ✓ | ✓ | ✓ | ✓ |
可微分物理引擎和模拟器。可微分物理引擎可计算模拟状态相对于输入(如动作或物体姿态)的梯度,允许通过物理交互(包括碰撞和变形)进行反向传播。通过用可微分函数模拟真实世界的物理现象,这些引擎可以直接在仿真中根据基本物理原理对策略进行优化,以适应真实世界的性能。这种方法增强了训练有素的策略在现实世界应用中的适应性和可移植性。Dojo(Howell 等人,2022 年)是一个以最优化为首要原则设计的物理引擎。它通过将接触模拟表述为一个最优化问题,改进了接触建模并为操作目标的运动学提供梯度信息。通过应用隐函数定理,Dojo 提供了平滑、可微分的梯度。同时,DiffTaichi(Hu 等人,2020 年,2019 年)是一种可微分模拟器编程语言。它采用巨核方法,将多个计算阶段合并到一个 CUDA 内核中,以最大限度地利用 GPU 并加速仿真。建立在 DiffTaichi 基础上的 Genesis(作者,2024 年)是一款开源模拟器,针对可微模拟进行了全面优化。它支持基于梯度的神经网络控制器最优化,仿真速度比现有的 GPU 加速仿真器快 10 到 80 倍,且不影响物理保真度。此外,Genesis 还包括一个用于逼真渲染的光线追踪系统和一个生成数据引擎,可将自然语言转化为多模态数据,用于生成自主训练环境。
3.3.基准数据集
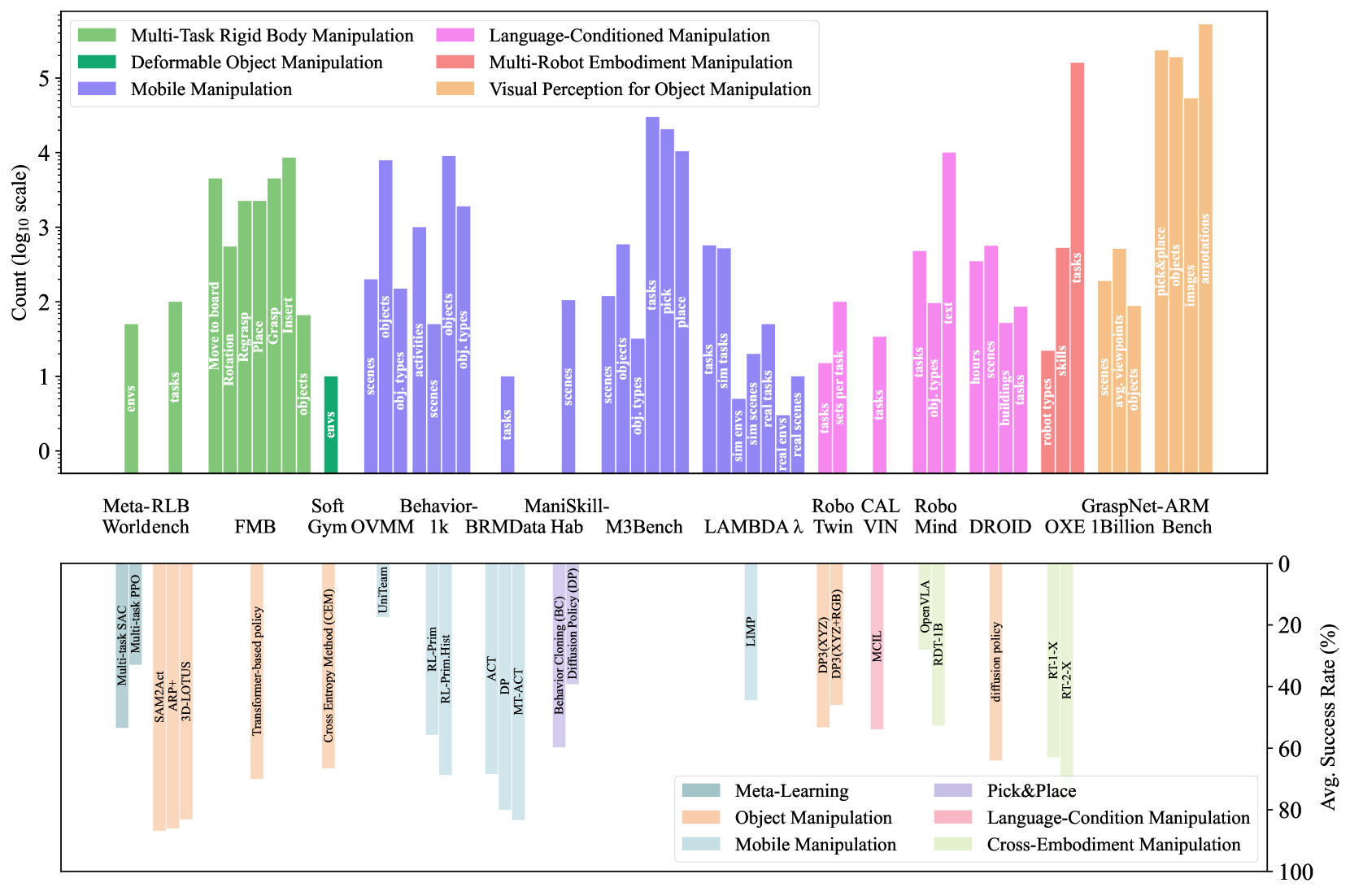
本节概述了为推进各种操作任务而开发的基准数据集。这些数据集对于提高智能体在不同任务、环境和机器人平台上的通用性至关重要。我们根据这些基准数据集所支持的操作任务对其进行分类,从简单的刚性体操作到更复杂的移动操作场景,并延伸到要求智能体整合多模态输入的语言条件操作。此外,我们还探讨了专门用于训练智能体视觉感知模块的数据集。这种分类有助于研究人员识别符合其特定研究需求的数据集。图 10 展示了这些操作基准数据集的比较。顶部的子图显示了数据集内容的规模和多样性。下面的子图显示了各种方法在这些基准中的表现。这一部分总结了不同操作任务的现有数据集和相应方法的性能状态,有助于研究人员了解数据可用性和不同任务的基准性能。
- 机械臂操作基准。有几个基准旨在探索开发智能体来处理刚体操作任务。例如,Meta-World(Yu 等人,2020 年)提供了 50 个不同的机械臂操作环境,而 RLBench(James 等人,2020 年)则包含 100 个任务。两者都旨在训练智能体掌握多种基本技能,并在测试过程中评估其对新任务的通用性。
- 可变形物体操作基准。SoftGym(Lin等人,2020年)和Plasticinelab(Huang等人,2021年)推进了对流体、绳索和软材料等可变形物体的操作研究。SoftGym 包括 10 个模拟环境(如倒水、折布、拉直绳子),而 Plasticinelab 则利用 DiffTaichi 系统(Hu 等人,2020 年)进行可微分软体模拟。然而,这些基准往往受限于对单一类型可变形材料和简单任务的关注,缺乏更广泛应用或涉及多模态指令的场景所需的多样性。此外,它们主要使用刚性机械臂,忽视了软机械臂在精细操作可变形物体方面的潜力。为了克服这些局限性,GRIP 数据集(Ma 等人,2025 年)引入了一个综合基准,其中包括软爪和硬爪与 1200 个不同物体(包括可变形物体)的交互。它建立在基于增量势能接触(IPC)的高保真并行模拟器上,可提供有关变形和应力分布的详细模拟数据。
- 机械臂操作基准。移动操作基准评估智能体执行需要导航和操作的任务,这些任务通常需要进行远距离规划,例如在操作物体之前先导航到远处。OVMM(Yenamandra 等人,2023 年)基准测试的重点是在人工智能栖息地模拟器中将物体从起始位置移动到目标位置的任务,该模拟器包含 200 个由人类撰写的交互式 3D 场景,其中有跨越 150 个类别的 7892 个物体。同时,Behavior-1k(Li 等人,2022 年)建立在 Omnigibson 模拟器上,由 Nvidia PhysX 5 支持,引入了更广泛、更多样的挑战。它包括多达 1,000 项需要综合导航和操作策略的家居活动。该基准测试提供了 50 个完全交互的场景,涵盖了倒酒和清洗浴缸等任务,包含 1,900 多种物体类型和 9,000 多个物体模型,其中包括液体、可变形和透明物体。同样,ManiSkill-Hab(Shukla 等人,2024 年)专注于 ManiSkill3 平台(Tao 等人,2024 年)上的三个长视距家庭任务--\sayTidy House(整理房间)、\sayPrepare Groceries(准备杂货)和\saySet Table(设置餐桌),该平台以超过 30,000 FPS 的速度提供逼真的模拟。最后,为了应对双臂移动操作的挑战,BRMData(Zhang等人,2024年)提供了10种不同的家居任务,智能体必须使用安装在移动平台上的双臂完成这些任务。
- 语言条件操纵基准。语言条件操作基准数据集评估机器人解释和执行自然语言指令的能力,从多步骤任务的模拟数据集到大规模真实世界演示数据集。CALVIN(Mees等人,2022年)提供了34个长视距任务,每个任务都配有特定的多步骤指令,如(说抓住抽屉把手并打开它)或(说按下按钮关灯)。它要求智能体遵循详细的指令。RoboTwin(Mu等人,2024年)利用大型语言模型(LLM)生成操作环境和任务,并通过演示视频重构对象,以可扩展的方法推进这项任务。该基准在数据集创建方面具有灵活性和可扩展性。RoboMind(Wu等人,2024年)和DROID(Khazatsky等人,2024年)进一步提供了广泛的真实演示数据,可用于训练模仿学习策略。RoboMind 提供了横跨 279 项任务和 61 个对象的 55,000 条真实演示轨迹,并辅以 10,000 条语言注释,可在厨房、办公室和零售环境等不同环境中使用多个机器人。同样,DROID 提供了一个大型数据集,其中包含 76,000 条真实演示轨迹--相当于 350 小时的交互数据--横跨 564 个场景和 86 项任务,每条轨迹都配有指令,例如 (sayPut the ball in the bowl)。
- 多机器人体现集合数据集。最近的基准测试强调可跨硬件和环境转移的通用策略。例如,Open X-Embodiment(Collaboration 等人,2023 年)使用来自 22 种机器人类型的数据训练 X 机器人策略,在 160,266 项任务中展示了 527 种技能。这是最大的开源真实机器人数据集,拥有超过 100 万条任务演示轨迹。
- 视觉感知数据集。Graspnet-1 千亿国际娱乐(Fang 等人,2023a)旨在增强抓取和感知任务,如 6D 姿势估计和分割。它包括 97,280 张图像,每张图像都注有精确的 6D 物体姿势和抓取点,涵盖 88 个物体,提供超过 11 亿个抓取姿势。
3.4.方法
稳健和可推广的机械臂操作依赖于准确的环境感知和有效的控制策略。该领域的研究主要集中在两个方向:感知表征和策略学习。感知表征包括从场景中提取丰富的三维或多模态信息来指导操作。策略学习侧重于为任务执行生成精确的控制指令。
3.4.1 感知表征
| REPRESENTATION LEARNING | ||
|---|---|---|
| Category | Formula | References |
| Voxel-Map | V(x,y,z)={1if V[x,y,z] is occupied0if V[x,y,z] is unoccupied(3) | (Huang et al., 2023b; Liu et al., 2024b) |
| Pose Estimation | p^=argmaxp∈PLpose(p)(4) | (Park et al., 2019; Bowen Wen, 2024) |
| Grasp Proposal | g^=argmaxg∈GLgrasp(g)(5) | (Kerr et al., 2023; Shen et al., 2023; Ji et al., 2024) |
| 𝐒𝐎(3)-equivariant | f(Rx;θ)=Rf(x;θ),∀R∈𝐒𝐎(3)(6) | (Deng et al., 2021; Pan et al., 2022; Esteves et al., 2018) |
| 𝐒𝐄(3)-equivariant | f(Rx+t;θ)=Rf(x;θ)+t,∀(R,t)∈𝐒𝐄(3)(7) | (Deng et al., 2021; Simeonov et al., 2022; Ryu et al., 2023; Xue et al., 2023; Wu et al., 2022) |
| 𝐒𝐈𝐌(3)-equivariant | f(αRx+t;θ)=αRf(x;θ)+t,∀(α,R,t)∈𝐒𝐈𝐌(3)(8) | (Lei et al., 2023; Yang et al., 2024b, a) |
感知是机械臂操作的基础,所需的三维空间细节水平因任务复杂程度而异。感知表征方法可按粒度分类:较粗的对象级表征,如 6D 姿态,足以完成拾放等基本任务,而较细的基于体素的表征或视觉触觉感知则是复杂的灵巧操作所必需的(Suresh 等人,2024b)。此外,为确保跨变换的通用性,可以将表征设计为𝐒𝐎(3)-、𝐒𝐄(3)-或𝐒𝐈𝐌(3)-等变体。
体素地图表示法。基于体素的表示法将三维空间离散为占用网格,每个体素反映相应坐标(x、y、z)是否被占用(等式 3)。例如,VoxPoser(Huang 等人,2023b)和 VoxAct-B(Liu 等人,2024b)整合了体素网格和视觉语言模型(VLM),以支持操作任务。VoxPoser 使用视觉语言模型来解释语言指令,生成的体素图可突出与任务相关的区域(例如,应抓取物体的位置)。与此同时,VoxAct-B 将这种方法应用于双臂机械操作。这些方法擅长在场景级上下文中识别特定任务的兴趣区域(ROI),增强空间理解和物体定位,从而实现有效操作。例如,在 “拾放 ”任务中,体素图会突出显示要抓取的物体手柄,让机器人专注于此,而忽略其他部分。
物体级表征。多项研究都侧重于学习物体级表征,如 6D 姿势估计(等式 4)和基于能力的抓取建议(等式 5)。6D 姿势估计涉及预测场景中物体的位置和方向。例如,Pix2Pose(Park 等人,2019 年)采用像素坐标回归法从 RGB 图像中估计 3D 坐标,而无需在训练过程中使用纹理 3D 模型。此外,FoundationPose(Bowen Wen,2024 年)为 6D 姿势估计和物体跟踪提供了一个统一的框架。它还可同时采用基于模型的方法(使用 CAD 模型)和神经隐式表示法进行新颖的视图合成。此外,Language-embedded radiance fields(LERF)(Kerr 等人,2023 年)将 VLM 与 3D 场景表征相结合,生成零镜头任务特定抓取建议。LERF-TOGO(Rashid等人,2023年)在此基础上进行了扩展,利用自然语言提示(例如,\saymug handle)来查询任务特定的物体区域以进行抓取。F3RM(Shen等人,2023年)将CLIP(Radford等人,2021年a)中的语义特征提炼为三维表征,实现了对未见物体的抓取和放置任务的少量学习。GraspSPlats(Ji等人,2024年)利用显式高斯拼接技术进一步提高了抓取选择的效率和准确性,从而实现实时建议。
𝐒𝐎(3)-、𝐒𝐄(3)-和𝐒𝐈𝐌(3)-等变表征。等变表征允许操作智能体的感知模块在各种变换下泛化到不同的输入(如物体或场景)。𝐒𝐎(3)-等差数列确保当输入的三维点云旋转时,学习到的表征也会发生同样的旋转。𝐒𝐄(3)-等差数列包括旋转和平移变换,从而使模型能够适应场景中物体的不同位置和方向。𝐒𝐈𝐌(3)-等差数列进一步考虑了比例变换,从而可以操作不同大小的物体。
𝐒𝐎(3)-等变表示。矢量神经元网络(VNNs)(Deng 等人,2021 年)支持三维点云的𝐒𝐎(3)-等变量表示学习,定义为方程 6。VNN 的关键机制是保留输入的旋转信息。具体来说,VNN 将神经元扩展为三维向量,并在线性层中应用线性变换,对于任意旋转组 R,线性变换满足 W(xR)=(Wx)R。具体来说,除了线性变换特征 q=WV 外,VNN 还会学习第二个权重 U,从而产生一个方向向量 k=UV。非线性层的输出为
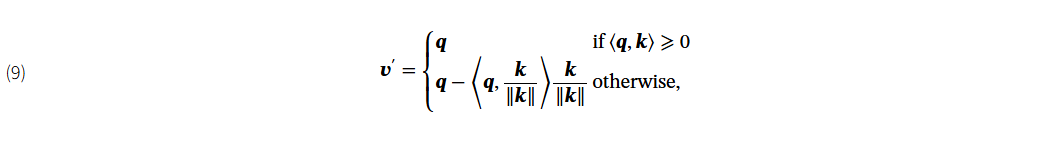
由于⟨qR,kR⟩=⟨q,k⟩,内积是旋转不变的,这使得整个剪切操作是旋转不变的。池化层和批量归一化也是为了保留输入的方向信息,确保输出在整个模型中保持旋转不变。
𝐒𝐄(3)-Equivariant Representation。神经描述场(NDFs)(Simeonov 等人,2022 年)产生从三维物体坐标到描述符(也称为特征向量)的连续𝐒𝐄(3) 映射,用于下游操作任务。这些描述符在任何刚性变换(旋转和平移)下都保持一致。从形式上看,描述符函数 f 满足等式 7,其中 (R,t) 是𝐒𝐄(3) 组的一个元素,𝐱 是对象点云 P 中的一个 3D 查询点。NDF 使用矢量神经元来确保𝐒𝐎(3)-等价性,它们通过平均中心移动 xn-(1N∑i=1Nxi),i={0,...,N}将 VNN 与平移相结合来实现𝐒𝐄(3)-等价性,确保函数只考虑点云的相对变换,而对于刚体变换保持不变。相关工作,如等变描述域(EDFs)(Ryu 等人,2023 年)将 NDFs 扩展为 \saybi-equivariant 以处理抓取物体和放置目标在三维空间中独立移动的情况。此外,Useek(Xue 等人,2023 年)通过检测 SE(3)-equivalent keypoints,实现了在任意 6-DoF 姿态下对物体的操作。此外,Equi-GSPR(Kang 等人,2024a)和 SURFELREG(Kang 等人,2024b)将 SE(3)-equivariant 特征应用于点云注册,进一步提高了三维感知的鲁棒性。
3.4.2.策略学习
| POLICY LEARNING | |||
|---|---|---|---|
| Category | Formula | References | |
| RL | Model-Free RL | Q(𝐬t,𝐚t)←Q(𝐬t,𝐚t)+α[rt+1+γmax𝐚′Q(𝐬t+1,𝐚′)−Q(𝐬t,𝐚t)](10) | (OpenAI, 2020; Schulman et al., 2017; Yang et al., 2025a) |
| Model-Based RL | V(𝐬)=max𝐚[R(𝐬,𝐚)+γ∑𝐬′P(𝐬′∣𝐬,𝐚)V(𝐬′)](11) | (Nagabandi et al., 2020; Janner et al., 2019; Hafner et al., 2019; Chua et al., 2018; Ha and Schmidhuber, 2018) | |
| IL | Behavior Cloning (BC) | θ∗=argminθ1N∑i=1N‖πθ(𝐨i)−𝐚i‖2(12) | (Wong et al., 2022; Torabi et al., 2018; Florence et al., 2021) |
| Action Chunking with Transformer (ACT) | 𝐚t=∑i=0k−1wi⋅𝐚^t(i)∑i=0k−1wi,wi=exp(−m⋅i)(13) | (Zhao et al., 2023; Fu et al., 2024a; Cheng et al., 2024b) | |
| Learning from human video | 𝐚=fretarget(fpose(𝐨))(14) | (Nair et al., 2023; Yang et al., 2025b; He et al., [n. d.]; Fu et al., 2024b; Li et al., 2024c) | |
| Diffusion Policy | 𝐚t−1=1αt(𝐚t−1−αt1−α¯tϵθ(𝐚t,t,𝐨))+σt𝐳,𝐳∼𝒩(0,I)(15) | (Chi et al., 2023; Liu et al., 2024e; Ze et al., 2024b, a; Huang et al., 2024; Ren et al., 2024) | |
| VLMs | π(lact∣𝐨,lins)(16) | (Yang et al., 2024d; Driess et al., 2023; Liu et al., 2024d; Zhaxizhuoma et al., 2024) | |
| VLAs | π(𝐚∣𝐨,lins)(17) | (Brohan et al., 2022; Zitkovich et al., 2023; Pan et al., 2024; Wen et al., 2024; Black et al., 2024; Kim et al., 2024; Bjorck et al., 2025) | |
四、未来方向
- 高效学习。虽然 Lin 等人(Lin et al., 2024 年)证明了缩放数据可以使单一任务策略普遍适用于新环境和新对象,但这种方法与生物系统的效率形成了鲜明对比,在生物系统中,人类和动物只需极少的经验就能迅速适应新任务。未来研究的一个前景广阔的途径在于开发算法和系统创新,以提高学习效率,例如持续学习,这种方法最近已显示出使机器人不断从演示中学习的前景,从而减少了对每项任务大量数据的需求(Auddy 等人,2023 年;Zheng 等人,2025a)。
- 持续学习。持续学习(Van de Ven 和 Tolias,2019;Chen 等人,2018a)对于智能体学习适应动态环境同时保留先前知识至关重要,尤其是在灾难性遗忘构成挑战的 VLN 中(Li 等人,2024b)。新出现的方法涉及重放机制(如弹性加权巩固(EWC)(Kirkpatrick等人,2017年)、元学习(Finn等人,2017年))和记忆架构(如泰坦神经长期记忆模块(Behrouz等人,2024年))。最近的研究进一步推动了这一领域的发展: NeSyC (Choi 等人,2025 年)介绍了一种神经符号持续学习器,它集成了神经推理和符号推理,可用于开放领域的复杂任务;而 Zheng 等人(Zheng 等人,2025b)则为基于 LLM 的智能体的终身学习提供了路线图,强调感知、记忆和行动模块,以增强适应性并减轻遗忘。
- 神经 ODE。具身智能任务(如倒液体)需要连续的动力学建模,这对离散方法来说具有挑战性。神经 ODE(Chen 等人,2018b)可实现连续状态演化,改善物体质量等变量下的轨迹预测和控制。液体网络(Hasani 等人,2021 年)可处理不规则输入(如摄像头),实现实时适应。虽然精确操作前景广阔,但经验验证仍然必不可少。
- 评估指标。目前的评估指标过于以目标为导向(如成功率、路径长度)。我们主张采用受人类任务执行启发的程序质量指标,如能效(最小化能量消耗)和平滑度(量化轨迹的突然变化)。最近的基准,如 Jiang 等人的探索感知具身问题解答框架(Jiang 等人,2025 年),通过强调任务评估中的探索,扩大了这一范围,为具身智能性能提供了更全面的评估。
五、结论
在本调查报告中,我们以导航和机械臂任务为重点,全面探讨了具身智能。通过整合方法论、模拟器、数据集和评估指标方面的进展,我们为 EAI 社区提供了一个结构化的详细资源。我们的分析强调了基于物理的模拟器的关键作用,它使智能体能够学习可微分的物理规则,并通过精确的物理建模和逼真的渲染弥合模拟与现实之间的差距。我们追溯了导航和机械臂操作方法的演变,强调了向数据驱动的基础方法(如世界模型和视觉-语言-动作模型)的明显转变,反映了向多功能、数据丰富的策略转变的大趋势。此外,通过分析模拟器的特点和硬件要求,我们的调查使研究人员能够根据自己的计算限制和研究目标选择合适的工具。
References
- (1)↑
- Achiam et al. (2023)↑Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023.Gpt-4 technical report.arXiv preprint arXiv:2303.08774 (2023).
- Agarwal et al. (2025)↑Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. 2025.Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575 (2025).
- Anderson et al. (2018a)↑Peter Anderson, Angel Chang, Devendra Singh Chaplot, Alexey Dosovitskiy, Saurabh Gupta, Vladlen Koltun, Jana Kosecka, et al. 2018a.On evaluation of embodied navigation agents.arXiv preprint arXiv:1807.06757 (2018).
- Anderson et al. (2018b)↑Peter Anderson, Qi Wu, Damien Teney, Jake Bruce, Mark Johnson, Niko Sünderhauf, Ian Reid, Stephen Gould, and Anton van den Hengel. 2018b.Vision-and-Language Navigation: Interpreting visually-grounded navigation instructions in real environments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Auddy et al. (2023)↑Sayantan Auddy, Jakob Hollenstein, Matteo Saveriano, Antonio Rodríguez-Sánchez, and Justus Piater. 2023.Continual learning from demonstration of robotics skills.Robotics and Autonomous Systems 165 (2023), 104427.
- Authors (2024)↑Genesis Authors. 2024.Genesis: A Universal and Generative Physics Engine for Robotics and Beyond.GitHub - Genesis-Embodied-AI/Genesis: A generative world for general-purpose robotics & embodied AI learning.
- Authors (2025)↑Simulately Authors. 2025.Simulately: A Universal Summary of Current Robotics Simulators.https://simulately.wiki
- Bahl et al. (2022)↑Shikhar Bahl, Abhinav Gupta, and Deepak Pathak. 2022.Human-to-Robot Imitation in the Wild.RSS.
- Bar et al. (2024)↑Amir Bar, Gaoyue Zhou, Danny Tran, Trevor Darrell, and Yann LeCun. 2024.Navigation world models.arXiv preprint arXiv:2412.03572 (2024).
- Bavle et al. (2023)↑Hriday Bavle, Jose Luis Sanchez-Lopez, Muhammad Shaheer, Javier Civera, and Holger Voos. 2023.S-graphs+: Real-time localization and mapping leveraging hierarchical representations.IEEE Robotics and Automation Letters 8, 8 (2023), 4927–4934.
- Beeching et al. (2020)↑Edward Beeching, Jilles Dibangoye, Olivier Simonin, and Christian Wolf. 2020.Learning to plan with uncertain topological maps.. In European Conference on Computer Vision.
- Behrouz et al. (2024)↑Ali Behrouz, Peilin Zhong, and Vahab Mirrokni. 2024.Titans: Learning to memorize at test time.arXiv preprint arXiv:2501.00663 (2024).
- Belkhale et al. (2024)↑Suneel Belkhale, Tianli Ding, Ted Xiao, Pierre Sermanet, Quon Vuong, Jonathan Tompson, Yevgen Chebotar, Debidatta Dwibedi, and Dorsa Sadigh. 2024.Rt-h: Action hierarchies using language.arXiv preprint arXiv:2403.01823 (2024).
- Bjorck et al. (2025)↑Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. 2025.GR00T N1: An Open Foundation Model for Generalist Humanoid Robots.arXiv preprint arXiv:2503.14734 (2025).
- Black et al. (2024)↑Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. 2024.π0: A Vision-Language-Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164 (2024).
- Bowen Wen (2024)↑Jan Kautz Stan Birchfield Bowen Wen, Wei Yang. 2024.FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects. In CVPR.
- Brohan et al. (2022)↑Anthony Brohan, Noah Brown, Justice Carbajal, Yevgen Chebotar, Joseph Dabis, Chelsea Finn, Keerthana Gopalakrishnan, Karol Hausman, et al. 2022.RT-1: Robotics Transformer for Real-World Control at Scale. In arXiv preprint arXiv:2212.06817.
- Chang et al. (2017)↑Angel Chang, Angela Dai, Thomas Funkhouser, Maciej Halber, Matthias Niebner, Manolis Savva, Shuran Song, Andy Zeng, and Yinda Zhang. 2017.Matterport3D: Learning from RGB-D Data in Indoor Environments. In 2017 International Conference on 3D Vision (3DV). IEEE, 667–676.
- Chang et al. (2015)↑Angel X Chang, Thomas Funkhouser, Leonidas Guibas, Pat Hanrahan, Qixing Huang, Zimo Li, Silvio Savarese, Manolis Savva, Shuran Song, Hao Su, et al. 2015.Shapenet: An information-rich 3d model repository.arXiv preprint arXiv:1512.03012 (2015).
- Chaplot et al. (2020)↑Devendra Singh Chaplot, Dhiraj Gandhi, Saurabh Gupta, Abhinav Gupta, and Ruslan Salakhutdinov. 2020.Learning To Explore Using Active Neural SLAM. In International Conference on Learning Representations (ICLR).
- Chen et al. (2018b)↑Ricky TQ Chen, Yulia Rubanova, Jesse Bettencourt, and David K Duvenaud. 2018b.Neural ordinary differential equations.Advances in neural information processing systems 31 (2018).
- Chen et al. (2019)↑Tao Chen, Saurabh Gupta, and Abhinav Gupta. 2019.Learning exploration policies for navigation. In 7th International Conference on Learning Representations, ICLR 2019.
- Chen et al. (2018a)↑Z. Chen, B. Liu, R. Brachman, P. Stone, and F. Rossi. 2018a.Lifelong Machine Learning: Second Edition.Morgan & Claypool Publishers.
- Cheng et al. (2024a)↑An-Chieh Cheng, Yandong Ji, Zhaojing Yang, Xueyan Zou, Jan Kautz, Erdem Biyik, Hongxu Yin, Sifei Liu, and Xiaolong Wang. 2024a.NaVILA: Legged Robot Vision-Language-Action Model for Navigation.arXiv preprint arXiv:2412.04453 (2024).
- Cheng et al. (2024b)↑Xuxin Cheng, Jialong Li, Shiqi Yang, Ge Yang, and Xiaolong Wang. 2024b.Open-TeleVision: Teleoperation with Immersive Active Visual Feedback.arXiv preprint arXiv:2407.01512 (2024).
- Chi et al. (2023)↑Cheng Chi, Siyuan Feng, Yilun Du, Zhenjia Xu, Eric Cousineau, Benjamin Burchfiel, and Shuran Song. 2023.Diffusion Policy: Visuomotor Policy Learning via Action Diffusion. In Proceedings of Robotics: Science and Systems (RSS).
- Chi et al. (2024)↑Cheng Chi, Zhenjia Xu, Chuer Pan, Eric Cousineau, Benjamin Burchfiel, Siyuan Feng, Russ Tedrake, and Shuran Song. 2024.Universal Manipulation Interface: In-The-Wild Robot Teaching Without In-The-Wild Robots. In Proceedings of Robotics: Science and Systems (RSS).
- Choi et al. (2024)↑Suhwan Choi, Yongjun Cho, Minchan Kim, Jaeyoon Jung, Myunchul Joe, Yubeen Park, Minseo Kim, Sungwoong Kim, Sungjae Lee, Hwiseong Park, et al. 2024.CANVAS: Commonsense-Aware Navigation System for Intuitive Human-Robot Interaction.arXiv preprint arXiv:2410.01273 (2024).
- Choi et al. (2025)↑Wonje Choi, Jinwoo Park, Sanghyun Ahn, Daehee Lee, and Honguk Woo. 2025.NeSyC: A Neuro-symbolic Continual Learner For Complex Embodied Tasks In Open Domains.arXiv preprint arXiv:2503.00870 (2025).
- Chua et al. (2018)↑Kurtland Chua, Roberto Calandra, Rowan McAllister, and Sergey Levine. 2018.Deep reinforcement learning in a handful of trials using probabilistic dynamics models.Advances in neural information processing systems 31 (2018).
- Collaboration et al. (2023)↑Open X-Embodiment Collaboration, Abby O’Neill, Abdul Rehman, Abhinav Gupta, and et al. 2023.Open X-Embodiment: Robotic Learning Datasets and RT-X Models.[2310.08864] Open X-Embodiment: Robotic Learning Datasets and RT-X Models.
- Cong et al. (2023)↑Yang Cong, Ronghan Chen, Bingtao Ma, Hongsen Liu, Dongdong Hou, and Chenguang Yang. 2023.A Comprehensive Study of 3-D Vision-Based Robot Manipulation.IEEE Trans. Cybern. 53, 3 (2023), 1682–1698.
- Coumans and Bai (2016)↑Erwin Coumans and Yunfei Bai. 2016.Pybullet, a python module for physics simulation for games, robotics and machine learning.
- Dai et al. (2024)↑Yinpei Dai, Run Peng, Sikai Li, and Joyce Chai. 2024.Think, act, and ask: Open-world interactive personalized robot navigation.ICRA (2024).
- Das et al. (2018)↑Abhishek Das, Samyak Datta, Georgia Gkioxari, Stefan Lee, Devi Parikh, and Dhruv Batra. 2018.Embodied Question Answering. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1–10.
- Deitke et al. (2022)↑Matt Deitke, Eli VanderBilt, Alvaro Herrasti, Luca Weihs, Kiana Ehsani, Jordi Salvador, Winson Han, Eric Kolve, Aniruddha Kembhavi, and Roozbeh Mottaghi. 2022.ProcTHOR: Large-Scale Embodied AI Using Procedural Generation. In Advances in Neural Information Processing Systems, S. Koyejo, S. Mohamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh (Eds.), Vol. 35. Curran Associates, Inc., 5982–5994.
- Deng et al. (2021)↑Congyue Deng, Or Litany, Yueqi Duan, Adrien Poulenard, Andrea Tagliasacchi, et al. 2021.Vector Neurons: A General Framework for SO(3)-Equivariant Networks. In 2021 IEEE/CVF International Conference on Computer Vision (ICCV). 12180–12189.
- Dosovitskiy et al. (2017)↑Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. 2017.CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Annual Conference on Robot Learning. 1–16.
- Driess et al. (2023)↑Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen Chebotar, Pierre Sermanet, Daniel Duckworth, Sergey Levine, Vincent Vanhoucke, Karol Hausman, Marc Toussaint, Klaus Greff, Andy Zeng, Igor Mordatch, and Pete Florence. 2023.PaLM-E: an embodied multimodal language model. In Proceedings of the 40th International Conference on Machine Learning (Honolulu, Hawaii, USA) (ICML’23). JMLR.org, Article 340, 20 pages.
- Duan et al. (2022)↑Jiafei Duan, Samson Yu, Hui Li Tan, Hongyuan Zhu, and Cheston Tan. 2022.A Survey of Embodied AI: From Simulators to Research Tasks.IEEE Transactions on Emerging Topics in Computational Intelligence 6, 2 (2022), 230–244.
- Esteves et al. (2018)↑Carlos Esteves, Christine Allen-Blanchette, Ameesh Makadia, and Kostas Daniilidis. 2018.Learning SO(3) Equivariant Representations with Spherical CNNs. In Computer Vision – ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part XIII (Munich, Germany). Springer-Verlag, Berlin, Heidelberg, 54–70.
- Fang et al. (2023a)↑Hao-Shu Fang, Minghao Gou, Chenxi Wang, and Cewu Lu. 2023a.Robust grasping across diverse sensor qualities: The GraspNet-1Billion dataset.The International Journal of Robotics Research (2023).
- Fang et al. (2023b)↑Hao-Shu Fang, Chenxi Wang, Hongjie Fang, Minghao Gou, Jirong Liu, Hengxu Yan, Wenhai Liu, Yichen Xie, and Cewu Lu. 2023b.AnyGrasp: Robust and Efficient Grasp Perception in Spatial and Temporal Domains.IEEE Transactions on Robotics 39, 5 (2023), 3929–3945.
- Fang et al. (2020)↑Hao-Shu Fang, Chenxi Wang, Minghao Gou, and Cewu Lu. 2020.GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11444–11453.
- Feng et al. (2025)↑Ruoxuan Feng, Di Hu, Wenke Ma, and Xuelong Li. 2025.Play to the Score: Stage-Guided Dynamic Multi-Sensory Fusion for Robotic Manipulation. In Proceedings of The 8th Conference on Robot Learning (Proceedings of Machine Learning Research, Vol. 270), Pulkit Agrawal, Oliver Kroemer, and Wolfram Burgard (Eds.). PMLR, 340–363.
- Finn et al. (2017)↑Chelsea Finn, Pieter Abbeel, and Sergey Levine. 2017.Model-agnostic meta-learning for fast adaptation of deep networks. In International conference on machine learning. PMLR, 1126–1135.
- Florence et al. (2021)↑Pete Florence, Corey Lynch, Andy Zeng, Oscar Ramirez, Ayzaan Wahid, Laura Downs, Adrian Wong, Johnny Lee, Igor Mordatch, and Jonathan Tompson. 2021.Implicit Behavioral Cloning.Conference on Robot Learning (CoRL) (2021).
- Fu et al. (2022)↑Zipeng Fu, Ashish Kumar, Ananye Agarwal, Haozhi Qi, Jitendra Malik, and Deepak Pathak. 2022.Coupling Vision and Proprioception for Navigation of Legged Robots. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 17252–17262.
- Fu et al. (2024b)↑Zipeng Fu, Qingqing Zhao, Qi Wu, Gordon Wetzstein, and Chelsea Finn. 2024b.HumanPlus: Humanoid Shadowing and Imitation from Humans. In Conference on Robot Learning (CoRL).
- Fu et al. (2024a)↑Zipeng Fu, Tony Z. Zhao, and Chelsea Finn. 2024a.Mobile ALOHA: Learning Bimanual Mobile Manipulation with Low-Cost Whole-Body Teleoperation. In Conference on Robot Learning (CoRL).
- Gan et al. (2020)↑Chuang Gan, Jeremy Schwartz, Seth Alter, Damian Mrowca, Martin Schrimpf, James Traer, Julian De Freitas, Jonas Kubilius, Abhishek Bhandwaldar, Nick Haber, et al. 2020.Threedworld: A platform for interactive multi-modal physical simulation.arXiv preprint arXiv:2007.04954 (2020).
- Gao et al. (2022)↑Xiaofeng Gao, Qiaozi Gao, Ran Gong, Kaixiang Lin, Govind Thattai, and Gaurav S. Sukhatme. 2022.DialFRED: Dialogue-Enabled Agents for Embodied Instruction Following.IEEE Robotics and Automation Letters 7, 4 (Oct. 2022), 10049–10056.
- Gireesh et al. (2023)↑Nandiraju Gireesh, Ayush Agrawal, Ahana Datta, Snehasis Banerjee, Mohan Sridharan, Brojeshwar Bhowmick, and Madhava Krishna. 2023.Sequence-Agnostic Multi-Object Navigation. In 2023 IEEE International Conference on Robotics and Automation (ICRA). 9573–9579.
- Ha and Schmidhuber (2018)↑David Ha and Jürgen Schmidhuber. 2018.Recurrent World Models Facilitate Policy Evolution. In Advances in Neural Information Processing Systems, S. Bengio, H. Wallach, H. Larochelle, K. Grauman, N. Cesa-Bianchi, and R. Garnett (Eds.), Vol. 31. Curran Associates, Inc.
- Hafner et al. (2019)↑Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. 2019.Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603 (2019).
- Han and Trinkle (1998)↑L. Han and J.C. Trinkle. 1998.Dextrous manipulation by rolling and finger gaiting. In Proceedings. 1998 IEEE International Conference on Robotics and Automation (Cat. No.98CH36146), Vol. 1. 730–735 vol.1.
- Hasani et al. (2021)↑Ramin Hasani, Mathias Lechner, Alexander Amini, Daniela Rus, and Radu Grosu. 2021.Liquid time-constant networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35. 7657–7666.
- He et al. ([n. d.])↑Tairan He, Zhengyi Luo, Xialin He, Wenli Xiao, Chong Zhang, Weinan Zhang, Kris M Kitani, Changliu Liu, and Guanya Shi. [n. d.].OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning. In 8th Annual Conference on Robot Learning.
- Ho et al. (2020)↑Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020.Denoising diffusion probabilistic models.Advances in neural information processing systems 33 (2020), 6840–6851.
- Hochreiter and Schmidhuber (1997)↑Sepp Hochreiter and Jürgen Schmidhuber. 1997.Long Short-Term Memory.Neural Computation 9, 8 (1997).
- Hong et al. (2021)↑Yicong Hong, Qi Wu, Yuankai Qi, Cristian Rodriguez-Opazo, and Stephen Gould. 2021.VLNBERT: A Recurrent Vision-and-Language BERT for Navigation. In 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 1643–1653.
- Howell et al. (2022)↑Taylor Howell, Simon Le Cleac’h, Jan Bruedigam, Zico Kolter, Mac Schwager, and Zachary Manchester. 2022.Dojo: A Differentiable Physics Engine for Robotics.arXiv preprint arXiv:2203.00806 (2022).
- Hu et al. (2023)↑Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gianluca Corrado. 2023.Gaia-1: A generative world model for autonomous driving.arXiv preprint arXiv:2309.17080 (2023).
- Hu et al. (2020)↑Yuanming Hu, Luke Anderson, Tzu-Mao Li, Qi Sun, Nathan Carr, Jonathan Ragan-Kelley, and Frédo Durand. 2020.DiffTaichi: Differentiable Programming for Physical Simulation.ICLR (2020).
- Hu et al. (2019)↑Yuanming Hu, Tzu-Mao Li, Luke Anderson, Jonathan Ragan-Kelley, and Frédo Durand. 2019.Taichi: a language for high-performance computation on spatially sparse data structures.ACM Transactions on Graphics (TOG) 38, 6 (2019), 201.
- Huang et al. (2024)↑Binghao Huang, Yixuan Wang, Xinyi Yang, Yiyue Luo, and Yunzhu Li. 2024.3D ViTac:Learning Fine-Grained Manipulation with Visuo-Tactile Sensing. In Proceedings of Robotics: Conference on Robot Learning(CoRL).
- Huang et al. (2023a)↑Chenguang Huang, Oier Mees, Andy Zeng, and Wolfram Burgard. 2023a.Visual Language Maps for Robot Navigation. In 2023 IEEE International Conference on Robotics and Automation (ICRA). 10608–10615.
- Huang et al. (2023b)↑Wenlong Huang, Chen Wang, Ruohan Zhang, Yunzhu Li, Jiajun Wu, and Li Fei-Fei. 2023b.Voxposer: Composable 3d value maps for robotic manipulation with language models.arXiv preprint arXiv:2307.05973 (2023).
- Huang et al. (2021)↑Zhiao Huang, Yuanming Hu, Tao Du, Siyuan Zhou, Hao Su, Joshua B. Tenenbaum, and Chuang Gan. 2021.PlasticineLab: A Soft-Body Manipulation Benchmark with Differentiable Physics. In International Conference on Learning Representations.
- Hwang and Ahuja (1992)↑Yong K. Hwang and Narendra Ahuja. 1992.Gross motion planning—a survey.ACM Comput. Surv. 24, 3 (Sept. 1992), 219–291.
- Ilharco et al. (2019)↑Gabriel Ilharco, Vihan Jain, Alexander Ku, Eugene Ie, and Jason Baldridge. 2019.General evaluation for instruction conditioned navigation using dynamic time warping.arXiv preprint arXiv:1907.05446 (2019).
- Irshad et al. (2021)↑Muhammad Zubair Irshad, Chih-Yao Ma, and Zsolt Kira. 2021.Hierarchical Cross-Modal Agent for Robotics Vision-and-Language Navigation. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA).
- Jain et al. (2019)↑Vihan Jain, Gabriel Magalhaes, Alexander Ku, Ashish Vaswani, Eugene Ie, and Jason Baldridge. 2019.Stay on the Path: Instruction Fidelity in Vision-and-Language Navigation. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Anna Korhonen, David Traum, and Lluís Màrquez (Eds.). Association for Computational Linguistics, Florence, Italy, 1862–1872.
- James et al. (2020)↑Stephen James, Zicong Ma, David Rovick Arrojo, and Andrew J. Davison. 2020.RLBench: The Robot Learning Benchmark & Learning Environment.IEEE Robotics and Automation Letters 5, 2 (2020), 3019–3026.
- Janner et al. (2019)↑Michael Janner, Justin Fu, Marvin Zhang, and Sergey Levine. 2019.When to trust your model: Model-based policy optimization.Advances in neural information processing systems 32 (2019).
- Ji et al. (2024)↑Mazeyu Ji, Ri-Zhao Qiu, Xueyan Zou, and Xiaolong Wang. 2024.GraspSplats: Efficient Manipulation with 3D Feature Splatting.arXiv preprint arXiv:2409.02084 (2024).
- Jiang et al. (2025)↑Kaixuan Jiang, Yang Liu, Weixing Chen, Jingzhou Luo, Ziliang Chen, Ling Pan, Guanbin Li, and Liang Lin. 2025.Beyond the Destination: A Novel Benchmark for Exploration-Aware Embodied Question Answering.arXiv preprint arXiv:2503.11117 (2025).
- Kang et al. (2024a)↑Xueyang Kang, Zhaoliang Luan, Kourosh Khoshelham, and Bing Wang. 2024a.Equi-GSPR: Equivariant SE (3) Graph Network Model for Sparse Point Cloud Registration. In European Conference on Computer Vision. Springer, 149–167.
- Kang and Yuan (2019)↑Xueyang Kang and Shunying Yuan. 2019.Robust data association for object-level semantic slam.arXiv preprint arXiv:1909.13493 (2019).
- Kang et al. (2024b)↑Xueyang Kang, Hang Zhao, Zhaoliang Luan, Patrick Vandewalle, and Kourosh Khoshelham. 2024b.SurfelReloc: Surfel-based 3D Registration with Equivariant Features. In CVPR 2024 workshop EquiVision proceedings.
- Kerr et al. (2023)↑Justin* Kerr, Chung Min* Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. 2023.LERF: Language Embedded Radiance Fields. In International Conference on Computer Vision (ICCV).
- Khandelwal et al. (2022)↑Apoorv Khandelwal, Luca Weihs, Roozbeh Mottaghi, and Aniruddha Kembhavi. 2022.Simple but Effective: CLIP Embeddings for Embodied AI. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14809–14818.
- Khazatsky et al. (2024)↑Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, Peter David Fagan, Joey Hejna, Masha Itkina, Marion Lepert, et al. 2024.DROID: A large-scale in-the-wild robot manipulation dataset. In Proceedings of Robotics: Science and Systems.Robotics: Science and Systems, R:SS ; Conference date: 15-07-2024 Through 19-07-2024.
- Kim et al. (2024)↑Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, and Chelsea Finn. 2024.OpenVLA: An Open-Source Vision-Language-Action Model.arXiv preprint arXiv:2406.09246 (2024).
- Kirkpatrick et al. (2017)↑James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. 2017.Overcoming catastrophic forgetting in neural networks.Proceedings of the National Academy of Sciences 114, 13 (March 2017), 3521–3526.
- Koenig and Howard (2004)↑N. Koenig and A. Howard. 2004.Design and use paradigms for Gazebo, an open-source multi-robot simulator. In 2004 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (IEEE Cat. No.04CH37566), Vol. 3. 2149–2154 vol.3.
- Kolve et al. (2017)↑Eric Kolve, Roozbeh Mottaghi, Winson Han, Eli VanderBilt, Luca Weihs, Alvaro Herrasti, Matt Deitke, Kiana Ehsani, Daniel Gordon, Yuke Zhu, et al. 2017.Ai2-thor: An interactive 3d environment for visual ai.arXiv preprint arXiv:1712.05474 (2017).
- Krantz et al. (2020)↑Jacob Krantz, Erik Wijmans, Arjun Majundar, Dhruv Batra, and Stefan Lee. 2020.Beyond the Nav-Graph: Vision and Language Navigation in Continuous Environments. In European Conference on Computer Vision (ECCV).
- Ku et al. (2020)↑Alexander Ku, Peter Anderson, Roma Patel, Eugene Ie, and Jason Baldridge. 2020.Room-Across-Room: Multilingual Vision-and-Language Navigation with Dense Spatiotemporal Grounding. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 4392–4412.
- Lambeta et al. (2024)↑Mike Lambeta, Tingfan Wu, Ali Sengul, Victoria Rose Most, Nolan Black, Kevin Sawyer, Romeo Mercado, Haozhi Qi, Alexander Sohn, Byron Taylor, et al. 2024.Digitizing touch with an artificial multimodal fingertip.arXiv preprint arXiv:2411.02479 (2024).
- Lei et al. (2023)↑Jiahui Lei, Congyue Deng, Karl Schmeckpeper, Leonidas Guibas, and Kostas Daniilidis. 2023.EFEM: Equivariant Neural Field Expectation Maximization for 3D Object Segmentation Without Scene Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Li et al. (2021b)↑Chengshu Li, Fei Xia, Roberto Martín-Martín, Michael Lingelbach, Sanjana Srivastava, Bokui Shen, Kent Vainio, Cem Gokmen, et al. 2021b.igibson 2.0: Object-centric simulation for robot learning of everyday household tasks.arXiv preprint arXiv:2108.03272 (2021).
- Li et al. (2022)↑Chengshu Li, Ruohan Zhang, Josiah Wong, Cem Gokmen, Sanjana Srivastava, Roberto Martín-Martín, Chen Wang, Gabrael Levine, Michael Lingelbach, Jiankai Sun, Mona Anvari, et al. 2022.BEHAVIOR-1K: A Benchmark for Embodied AI with 1,000 Everyday Activities and Realistic Simulation. In 6th Annual Conference on Robot Learning.
- Li et al. (2024c)↑Jinhan Li, Yifeng Zhu, Yuqi Xie, Zhenyu Jiang, Mingyo Seo, Georgios Pavlakos, and Yuke Zhu. 2024c.OKAMI: Teaching Humanoid Robots Manipulation Skills through Single Video Imitation. In 8th Annual Conference on Robot Learning (CoRL).
- Li et al. (2024a)↑Shuang Li, Norman Hendrich, Hongzhuo Liang, et al. 2024a.A Dexterous Hand-Arm Teleoperation System Based on Hand Pose Estimation and Active Vision.IEEE Trans. Cybern. 54, 3 (2024), 1417–1428.
- Li et al. (2021a)↑Weijie Li, Xinhang Song, Yubing Bai, Sixian Zhang, and Shuqiang Jiang. 2021a.ION: Instance-level Object Navigation. In Proceedings of the 29th ACM International Conference on Multimedia (Virtual Event, China) (MM ’21). Association for Computing Machinery, New York, NY, USA, 4343–4352.
- Li et al. (2025)↑Zhiqi Li, Guo Chen, Shilong Liu, Shihao Wang, Vibashan VS, Yishen Ji, Shiyi Lan, Hao Zhang, Yilin Zhao, Subhashree Radhakrishnan, et al. 2025.Eagle 2: Building Post-Training Data Strategies from Scratch for Frontier Vision-Language Models.arXiv preprint arXiv:2501.14818 (2025).
- Li et al. (2024b)↑Zhiyuan Li, Yanfeng Lv, Ziqin Tu, Di Shang, and Hong Qiao. 2024b.Vision-Language Navigation with Continual Learning.arXiv preprint arXiv:2409.02561 (2024).
- Lin et al. (2024)↑Fanqi Lin, Yingdong Hu, Pingyue Sheng, Chuan Wen, Jiacheng You, and Yang Gao. 2024.Data scaling laws in imitation learning for robotic manipulation.arXiv preprint arXiv:2410.18647 (2024).
- Lin et al. (2020)↑Xingyu Lin, Yufei Wang, Jake Olkin, and David Held. 2020.SoftGym: Benchmarking Deep Reinforcement Learning for Deformable Object Manipulation. In Conference on Robot Learning.
- Liu et al. (2024c)↑Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. 2024c.Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 26296–26306.
- Liu et al. (2023)↑Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. 2023.Visual Instruction Tuning. In NeurIPS.
- Liu et al. (2024b)↑I-Chun Arthur Liu, Sicheng He, Daniel Seita, and Gaurav S. Sukhatme. 2024b.VoxAct‐B: Voxel‐Based Acting and Stabilizing Policy for Bimanual Manipulation. In Conference on Robot Learning.
- Liu et al. (2024d)↑Peiqi Liu, Yaswanth Orru, Jay Vakil, Chris Paxton, Nur Shafiullah, and Lerrel Pinto. 2024d.Demonstrating OK-Robot: What Really Matters in Integrating Open-Knowledge Models for Robotics. In Robotics: Science and Systems XX (RSS2024). Robotics: Science and Systems Foundation.
- Liu et al. (2024e)↑Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. 2024e.RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation.arXiv preprint arXiv:2410.07864 (2024).
- Liu et al. (2024f)↑Wei Liu, Huihua Zhao, Chenran Li, Joydeep Biswas, Billy Okal, Pulkit Goyal, Yan Chang, and Soha Pouya. 2024f.X-mobility: End-to-end generalizable navigation via world modeling.arXiv preprint arXiv:2410.17491 (2024).
- Liu et al. (2024a)↑Yang Liu, Weixing Chen, Yongjie Bai, Xiaodan Liang, Guanbin Li, Wen Gao, and Liang Lin. 2024a.Aligning cyber space with physical world: A comprehensive survey on embodied ai.arXiv preprint arXiv:2407.06886 (2024).
- Lu et al. (2019)↑Jiasen Lu, Dhruv Batra, Devi Parikh, and Stefan Lee. 2019.Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks.Advances in neural information processing systems 32 (2019).
- Luo et al. (2024)↑Jianlan Luo, Charles Xu, Jeffrey Wu, and Sergey Levine. 2024.Precise and Dexterous Robotic Manipulation via Human-in-the-Loop Reinforcement Learning.arXiv preprint arXiv:2410.21845 (2024).
- Ma et al. (2025)↑Siyu Ma, Wenxin Du, Chang Yu, Ying Jiang, Zeshun Zong, Tianyi Xie, Yunuo Chen, Yin Yang, et al. 2025.GRIP: A General Robotic Incremental Potential Contact Simulation Dataset for Unified Deformable-Rigid Coupled Grasping.arXiv preprint arXiv:2503.05020 (2025).
- Ma et al. (2024)↑Yueen Ma, Zixing Song, Yuzheng Zhuang, Jianye Hao, and Irwin King. 2024.A survey on vision-language-action models for embodied ai.arXiv preprint arXiv:2405.14093 (2024).
- Majumdar et al. (2022)↑Arjun Majumdar, Gunjan Aggarwal, Bhavika Devnani, Judy Hoffman, and Dhruv Batra. 2022.Zson: Zero-shot object-goal navigation using multimodal goal embeddings.Advances in Neural Information Processing Systems 35 (2022), 32340–32352.
- Majumdar et al. (2024)↑Arjun Majumdar, Anurag Ajay, Xiaohan Zhang, Pranav Putta, Sriram Yenamandra, Mikael Henaff, Sneha Silwal, Paul Mcvay, Oleksandr Maksymets, Sergio Arnaud, Karmesh Yadav, et al. 2024.OpenEQA: Embodied Question Answering in the Era of Foundation Models. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 16488–16498.
- Manolis Savva* et al. (2019)↑Manolis Savva*, Abhishek Kadian*, Oleksandr Maksymets*, Yili Zhao, Erik Wijmans, Bhavana Jain, Julian Straub, Jia Liu, Vladlen Koltun, Jitendra Malik, Devi Parikh, and Dhruv Batra. 2019.Habitat: A Platform for Embodied AI Research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
- Mees et al. (2022)↑Oier Mees, Lukas Hermann, Erick Rosete-Beas, and Wolfram Burgard. 2022.CALVIN: A Benchmark for Language-Conditioned Policy Learning for Long-Horizon Robot Manipulation Tasks.IEEE Robotics and Automation Letters (RA-L) 7, 3 (2022), 7327–7334.
- Mo et al. (2019)↑Kaichun Mo, Shilin Zhu, Angel X. Chang, Li Yi, Subarna Tripathi, Leonidas J. Guibas, and Hao Su. 2019.PartNet: A Large-Scale Benchmark for Fine-Grained and Hierarchical Part-Level 3D Object Understanding. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Moghaddam et al. (2021)↑Mahdi Kazemi Moghaddam, Ehsan Abbasnejad, Qi Wu, Javen Shi, and Anton Van Den Hengel. 2021.Learning for visual navigation by imagining the success.arXiv preprint arXiv:2103.00446 (2021).
- Mu et al. (2021)↑Tongzhou Mu, Zhan Ling, Fanbo Xiang, Derek Yang, Xuanlin Li, Stone Tao, Zhiao Huang, Zhiwei Jia, and Hao Su. 2021.Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations.arXiv preprint arXiv:2107.14483 (2021).
- Mu et al. (2024)↑Yao Mu, Tianxing Chen, Shijia Peng, Zanxin Chen, Zeyu Gao, Yude Zou, Lunkai Lin, Zhiqiang Xie, and Ping Luo. 2024.RoboTwin: Dual-Arm Robot Benchmark with Generative Digital Twins (early version).arXiv preprint arXiv:2409.02920 (2024).
- Nagabandi et al. (2020)↑Anusha Nagabandi, Kurt Konolige, Sergey Levine, and Vikash Kumar. 2020.Deep dynamics models for learning dexterous manipulation. In Conference on robot learning. PMLR, 1101–1112.
- Nair et al. (2020)↑Ashvin Nair, Abhishek Gupta, Murtaza Dalal, and Sergey Levine. 2020.Awac: Accelerating online reinforcement learning with offline datasets.arXiv preprint arXiv:2006.09359 (2020).
- Nair et al. (2023)↑Suraj Nair, Aravind Rajeswaran, Vikash Kumar, Chelsea Finn, and Abhinav Gupta. 2023.R3M: A Universal Visual Representation for Robot Manipulation. In Proceedings of The 6th Conference on Robot Learning (Proceedings of Machine Learning Research, Vol. 205), Karen Liu, Dana Kulic, and Jeff Ichnowski (Eds.). PMLR, 892–909.
- Nguyen et al. (2019)↑Khanh Nguyen, Debadeepta Dey, Chris Brockett, and Bill Dolan. 2019.Vision-based navigation with language-based assistance via imitation learning with indirect intervention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12527–12537.
- Nvidia ([n. d.])↑Nvidia. [n. d.].Nvidia isaac sim: Robotics simulation and synthetic data.Isaac Sim - Robotics Simulation and Synthetic Data Generation | NVIDIA Developer
- OpenAI (2020)↑OpenAI. 2020.Learning dexterous in-hand manipulation.The International Journal of Robotics Research 39, 1 (2020), 3–20.arXiv:https://doi.org/10.1177/0278364919887447
- Padmakumar et al. (2022)↑Aishwarya Padmakumar, Jesse Thomason, Ayush Shrivastava, Patrick Lange, Anjali Narayan-Chen, Spandana Gella, Robinson Piramuthu, Gokhan Tur, and Dilek Hakkani-Tur. 2022.TEACh: Task-Driven Embodied Agents That Chat.Proceedings of the AAAI Conference on Artificial Intelligence 36, 2 (Jun. 2022), 2017–2025.
- Pan et al. (2024)↑Cheng Pan, Kai Junge, and Josie Hughes. 2024.Vision-language-action model and diffusion policy switching enables dexterous control of an anthropomorphic hand.arXiv preprint arXiv:2410.14022 (2024).
- Pan et al. (2022)↑Haoran Pan, Jun Zhou, Yuanpeng Liu, Xuequan Lu, Weiming Wang, Xuefeng Yan, and Mingqiang Wei. 2022.SO (3)-Pose: SO (3)-Equivariance Learning for 6D Object Pose Estimation. In Computer Graphics Forum, Vol. 41. Wiley Online Library, 371–381.
- Park et al. (2019)↑Kiru Park, Timothy Patten, and Markus Vincze. 2019.Pix2Pose: Pixel-Wise Coordinate Regression of Objects for 6D Pose Estimation. In 2019 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE, 7667–7676.
- Pashevich et al. (2021)↑Alexander Pashevich, Cordelia Schmid, and Chen Sun. 2021.Episodic Transformer for Vision-and-Language Navigation. In ICCV.
- Peebles and Xie (2023)↑William Peebles and Saining Xie. 2023.Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF international conference on computer vision. 4195–4205.
- Puig et al. (2023)↑Xavier Puig, Eric Undersander, Andrew Szot, Mikael Dallaire Cote, Tsung-Yen Yang, et al. 2023.Habitat 3.0: A co-habitat for humans, avatars and robots.arXiv preprint arXiv:2310.13724 (2023).
- Qi et al. (2020)↑Yuankai Qi, Qi Wu, Peter Anderson, Xin Wang, William Yang Wang, Chunhua Shen, and Anton van den Hengel. 2020.Reverie: Remote embodied visual referring expression in real indoor environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition.
- Radford et al. (2021a)↑Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, et al. 2021a.Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763.
- Radford et al. (2021b)↑Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021b.Learning transferable visual models from natural language supervision. In International conference on machine learning. PmLR, 8748–8763.
- Rajeswaran et al. (2018)↑Aravind Rajeswaran, Vikash Kumar, Abhishek Gupta, Giulia Vezzani, John Schulman, Emanuel Todorov, and Sergey Levine. 2018.Learning Complex Dexterous Manipulation with Deep Reinforcement Learning and Demonstrations. In Proceedings of Robotics: Science and Systems (RSS).
- Ramakrishnan et al. (2021)↑Santhosh Kumar Ramakrishnan, Aaron Gokaslan, Erik Wijmans, Oleksandr Maksymets, Alexander Clegg, John M Turner, Eric Undersander, Wojciech Galuba, Andrew Westbury, Angel X Chang, Manolis Savva, Yili Zhao, and Dhruv Batra. 2021.Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2).
- Rashid et al. (2023)↑Adam Rashid, Satvik Sharma, Chung Min Kim, Justin Kerr, Lawrence Yunliang Chen, et al. 2023.Language Embedded Radiance Fields for Zero-Shot Task-Oriented Grasping. In 7th Annual Conference on Robot Learning.
- Ren et al. (2024)↑Yu Ren, Yang Cong, Ronghan Chen, and Jiahao Long. 2024.Learning Generalizable 3D Manipulation With 10 Demonstrations.arXiv preprint arXiv:2411.10203 (2024).
- Rohmer et al. (2013)↑Eric Rohmer, Surya P. N. Singh, and Marc Freese. 2013.V-REP: A versatile and scalable robot simulation framework. In 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems. 1321–1326.
- Rosinol et al. (2020)↑Antoni Rosinol, Arjun Gupta, Marcus Abate, Jingnan Shi, and Luca Carlone. 2020.3D dynamic scene graphs: Actionable spatial perception with places, objects, and humans.arXiv preprint arXiv:2002.06289 (2020).
- Ross et al. (2011)↑Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. 2011.A reduction of imitation learning and structured prediction to no-regret online learning. In Proceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings.
- Ryu et al. (2023)↑Hyunwoo Ryu, Hong in Lee, Jeong-Hoon Lee, and Jongeun Choi. 2023.Equivariant Descriptor Fields: SE(3)-Equivariant Energy-Based Models for End-to-End Visual Robotic Manipulation Learning. In The Eleventh International Conference on Learning Representations.
- Savinov et al. (2018)↑Nikolay Savinov, Alexey Dosovitskiy, and Vladlen Koltun. 2018.Semi-parametric topological memory for navigation.arXiv preprint arXiv:1803.00653 (2018).
- Schulman et al. (2017)↑John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017.Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347 (2017).
- Shah et al. (2018)↑Shital Shah, Debadeepta Dey, Chris Lovett, and Ashish Kapoor. 2018.Airsim: High-fidelity visual and physical simulation for autonomous vehicles. In Field and Service Robotics: Results of the 11th International Conference. Springer, 621–635.
- Shen et al. (2021)↑Bokui Shen, Fei Xia, Chengshu Li, Roberto Martín-Martín, Linxi Fan, Guanzhi Wang, Claudia Pérez-D’Arpino, Shyamal Buch, Sanjana Srivastava, Lyne Tchapmi, Micael Tchapmi, Kent Vainio, Josiah Wong, Li Fei-Fei, and Silvio Savarese. 2021.iGibson 1.0: A Simulation Environment for Interactive Tasks in Large Realistic Scenes. In 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). 7520–7527.
- Shen et al. (2023)↑William Shen, Ge Yang, Alan Yu, Jansen Wong, Leslie Pack Kaelbling, and Phillip Isola. 2023.Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation. In 7th Annual Conference on Robot Learning.
- Shridhar et al. (2020)↑Mohit Shridhar, Jesse Thomason, Daniel Gordon, Yonatan Bisk, Winson Han, Roozbeh Mottaghi, Luke Zettlemoyer, and Dieter Fox. 2020.Alfred: A benchmark for interpreting grounded instructions for everyday tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10740–10749.
- Shukla et al. (2024)↑Arth Shukla, Stone Tao, and Hao Su. 2024.ManiSkill-HAB: A Benchmark for Low-Level Manipulation in Home Rearrangement Tasks.CoRR abs/2412.13211 (2024).arXiv:2412.13211
- Simeonov et al. (2022)↑Anthony Simeonov, Yilun Du, Andrea Tagliasacchi, Joshua B. Tenenbaum, Alberto Rodriguez, Pulkit Agrawal, and Vincent Sitzmann. 2022.Neural Descriptor Fields: SE(3)-Equivariant Object Representations for Manipulation. In 2022 International Conference on Robotics and Automation (ICRA). 6394–6400.
- Singh Chaplot et al. (2020)↑Devendra Singh Chaplot, Ruslan Salakhutdinov, Abhinav Gupta, and Saurabh Gupta. 2020.Neural Topological SLAM for Visual Navigation. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12872–12881.
- Song et al. (2020)↑Shuran Song, Andy Zeng, Johnny Lee, and Thomas Funkhouser. 2020.Grasping in the Wild: Learning 6DoF Closed-Loop Grasping From Low-Cost Demonstrations.IEEE Robotics and Automation Letters 5, 3 (2020), 4978–4985.
- Song et al. (2024)↑Xinshuai Song, Weixing Chen, Yang Liu, Vincent Chan, Guanbin Li, and Liang Lin. 2024.Towards long-horizon vision-language navigation: Platform, benchmark and method.arXiv preprint arXiv:2412.09082 (2024).
- Su et al. (2022)↑Hang Su, Xu Hou, Xin Zhang, Wen Qi, Shuting Cai, Xiaoming Xiong, and Jing Guo. 2022.Pneumatic soft robots: Challenges and benefits. In Actuators, Vol. 11. MDPI, 92.
- Suglia et al. (2021)↑Alessandro Suglia, Qiaozi Gao, Jesse Thomason, Govind Thattai, and Gaurav Sukhatme. 2021.Embodied bert: A transformer model for embodied, language-guided visual task completion.arXiv preprint arXiv:2108.04927 (2021).
- Sun et al. (2018)↑Ke Sun, Kelsey Saulnier, Nikolay Atanasov, George J. Pappas, and Vijay Kumar. 2018.Dense 3-D Mapping with Spatial Correlation via Gaussian Filtering. In 2018 Annual American Control Conference (ACC). 4267–4274.
- Suresh et al. (2024a)↑Sudharshan Suresh, Haozhi Qi, Tingfan Wu, Taosha Fan, Luis Pineda, Mike Lambeta, Jitendra Malik, Mrinal Kalakrishnan, Roberto Calandra, Michael Kaess, Joseph Ortiz, and Mustafa Mukadam. 2024a.Neural feels with neural fields: Visuo-tactile perception for in-hand manipulation.Science Robotics (2024), adl0628.
- Suresh et al. (2024b)↑Sudharshan Suresh, Haozhi Qi, Tingfan Wu, Taosha Fan, Luis Pineda, Mike Lambeta, Jitendra Malik, Mrinal Kalakrishnan, Roberto Calandra, Michael Kaess, Joseph Ortiz, and Mustafa Mukadam. 2024b.NeuralFeels with neural fields: Visuotactile perception for in-hand manipulation.Science Robotics 9, 96 (2024), eadl0628.arXiv:https://www.science.org/doi/pdf/10.1126/scirobotics.adl0628
- Sutskever et al. (2014)↑Ilya Sutskever, Oriol Vinyals, and Quoc V Le. 2014.Sequence to sequence learning with neural networks.Advances in neural information processing systems 27 (2014).
- Szot et al. (2021)↑Andrew Szot, Alex Clegg, Eric Undersander, Erik Wijmans, Yili Zhao, John Turner, Noah Maestre, Mustafa Mukadam, et al. 2021.Habitat 2.0: Training Home Assistants to Rearrange their Habitat. In Advances in Neural Information Processing Systems (NeurIPS).
- Tao et al. (2024)↑Stone Tao, Fanbo Xiang, Arth Shukla, Yuzhe Qin, Xander Hinrichsen, Xiaodi Yuan, Chen Bao, Xinsong Lin, et al. 2024.ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI.arXiv preprint arXiv:2410.00425 (2024).
- Tedrake (2024)↑Russ Tedrake. 2024.Robotic Manipulation.MIT 6.421 Robotic Manipulation.http://manipulation.mit.edu
- Thomason et al. (2019)↑Jesse Thomason, Michael Murray, Maya Cakmak, and Luke Zettlemoyer. 2019.Vision-and-Dialog Navigation. In Conference on Robot Learning (CoRL).
- Todorov et al. (2012)↑Emanuel Todorov, Tom Erez, and Yuval Tassa. 2012.MuJoCo: A physics engine for model-based control. In 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems. 5026–5033.
- Torabi et al. (2018)↑Faraz Torabi, Garrett Warnell, and Peter Stone. 2018.Behavioral cloning from observation. In Proceedings of the 27th International Joint Conference on Artificial Intelligence (Stockholm, Sweden) (IJCAI’18). AAAI Press, 4950–4957.
- Van de Ven and Tolias (2019)↑Gido M Van de Ven and Andreas S Tolias. 2019.Three scenarios for continual learning.arXiv preprint arXiv:1904.07734 (2019).
- Wang et al. (2025a)↑Zhanchi Wang, Nikolaos M. Freris, and Xi Wei. 2025a.SpiRobs: Logarithmic spiral-shaped robots for versatile grasping across scales.Device 3, 4 (2025), 100646.doi:10.1016/j.device.2024.100646
- Wang et al. (2024)↑Zhaowei Wang, Hongming Zhang, Tianqing Fang, Ye Tian, Yue Yang, Kaixin Ma, Xiaoman Pan, Yangqiu Song, and Dong Yu. 2024.DivScene: Benchmarking LVLMs for Object Navigation with Diverse Scenes and Objects.arXiv preprint arXiv:2410.02730 (2024).
- Wang et al. (2025b)↑Zihan Wang, Yaohui Zhu, Gim Hee Lee, and Yachun Fan. 2025b.NavRAG: Generating User Demand Instructions for Embodied Navigation through Retrieval-Augmented LLM.arXiv preprint arXiv:2502.11142 (2025).
- Wen et al. (2024)↑Junjie Wen, Minjie Zhu, Yichen Zhu, Zhibin Tang, Jinming Li, Zhongyi Zhou, Chengmeng Li, Xiaoyu Liu, et al. 2024.Diffusion-VLA: Scaling Robot Foundation Models via Unified Diffusion and Autoregression.arXiv preprint arXiv:2412.03293 (2024).
- Wijmans et al. ([n. d.])↑Erik Wijmans, Abhishek Kadian, Ari Morcos, Stefan Lee, Irfan Essa, Devi Parikh, Manolis Savva, and Dhruv Batra. [n. d.].DD-PPO: Learning Near-Perfect PointGoal Navigators from 2.5 Billion Frames. In International Conference on Learning Representations.
- Wong et al. (2022)↑Josiah Wong, Albert Tung, Andrey Kurenkov, Ajay Mandlekar, Li Fei-Fei, Silvio Savarese, and Roberto Martín-Martín. 2022.Error-aware imitation learning from teleoperation data for mobile manipulation. In Conference on Robot Learning. PMLR, 1367–1378.
- Wu et al. (2022)↑Jin Wu, Ming Liu, Yulong Huang, Chi Jin, Yuanxin Wu, and Changbin Yu. 2022.SE(n)++: An Efficient Solution to Multiple Pose Estimation Problems.IEEE Trans. Cybern. 52, 5 (2022), 3829–3840.
- Wu et al. (2024)↑Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, Xiaozhu Ju, Zhuqin Yang, Meng Li, Yinuo Zhao, Zhiyuan Xu, Guang Yang, Zhen Zhao, Guangyu Li, Zhao Jin, et al. 2024.RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation.arXiv preprint arXiv:2412.13877 (2024).
- Xia et al. (2018)↑Fei Xia, Amir R. Zamir, Zhi-Yang He, Alexander Sax, Jitendra Malik, and Silvio Savarese. 2018.Gibson env: real-world perception for embodied agents. In Computer Vision and Pattern Recognition (CVPR), 2018 IEEE Conference on. IEEE.
- Xia et al. (2020)↑Fei Xia, William B. Shen, Chengshu Li, Priya Kasimbeg, Micael Edmond Tchapmi, Alexander Toshev, Roberto Martín-Martín, and Silvio Savarese. 2020.Interactive Gibson Benchmark: A Benchmark for Interactive Navigation in Cluttered Environments.IEEE Robotics and Automation Letters 5, 2 (2020), 713–720.
- Xiang et al. (2020)↑Fanbo Xiang, Yuzhe Qin, Kaichun Mo, Yikuan Xia, Hao Zhu, Fangchen Liu, Minghua Liu, Hanxiao Jiang, Yifu Yuan, He Wang, Li Yi, Angel X. Chang, Leonidas J. Guibas, and Hao Su. 2020.SAPIEN: A SimulAted Part-based Interactive ENvironment. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Xu et al. (2024)↑Zhiyuan Xu, Kun Wu, Junjie Wen, Jinming Li, Ning Liu, Zhengping Che, and Jian Tang. 2024.A survey on robotics with foundation models: toward embodied ai.arXiv preprint arXiv:2402.02385 (2024).
- Xue et al. (2023)↑Zhengrong Xue, Zhecheng Yuan, Jiashun Wang, et al. 2023.USEEK: Unsupervised SE(3)-Equivariant 3D Keypoints for Generalizable Manipulation. In 2023 IEEE International Conference on Robotics and Automation (ICRA). 1715–1722.
- Yadav et al. (2023)↑Karmesh Yadav, Ram Ramrakhya, Santhosh Kumar Ramakrishnan, Theo Gervet, John Turner, Aaron Gokaslan, Noah Maestre, Angel Xuan Chang, Dhruv Batra, Manolis Savva, et al. 2023.Habitat-Matterport 3D Semantics Dataset. In 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 4927–4936.
- Yang et al. (2025a)↑Fan Yang, Wenrui Chen, et al. 2025a.Task-Oriented Tool Manipulation With Robotic Dexterous Hands: A Knowledge Graph Approach From Fingers to Functionality.IEEE Trans. Cybern. 55, 1 (2025), 395–408.
- Yang et al. (2024a)↑Jingyun Yang, Zi-ang Cao, Congyue Deng, Rika Antonova, Shuran Song, and Jeannette Bohg. 2024a.EquiBot: SIM(3)-Equivariant Diffusion Policy for Generalizable and Data Efficient Learning. In 8th Annual Conference on Robot Learning.
- Yang et al. (2024b)↑Jingyun Yang, Congyue Deng, Jimmy Wu, Rika Antonova, et al. 2024b.Equivact: SIM(3)-Equivariant Visuomotor Policies beyond Rigid Object Manipulation. In 2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 9249–9255.
- Yang et al. (2023)↑Max Yang, Yijiong Lin, Alex Church, John Lloyd, Dandan Zhang, et al. 2023.Sim-to-Real Model-Based and Model-Free Deep Reinforcement Learning for Tactile Pushing.IEEE Rob. Autom. Lett. 8, 9 (2023), 5480–5487.
- Yang et al. (2025b)↑Shiqi Yang, Minghuan Liu, Yuzhe Qin, Runyu Ding, Jialong Li, Xuxin Cheng, et al. 2025b.ACE: A Cross-platform and visual-Exoskeletons System for Low-Cost Dexterous Teleoperation. In Proceedings of The 8th Conference on Robot Learning (Proceedings of Machine Learning Research, Vol. 270), Pulkit Agrawal, Oliver Kroemer, and Wolfram Burgard (Eds.). PMLR, 4895–4911.
- Yang et al. (2018)↑Wei Yang, Xiaolong Wang, Ali Farhadi, Abhinav Gupta, and Roozbeh Mottaghi. 2018.Visual semantic navigation using scene priors.arXiv preprint arXiv:1810.06543 (2018).
- Yang et al. (2024c)↑Yue Yang, Fan-Yun Sun, Luca Weihs, Eli VanderBilt, Alvaro Herrasti, Winson Han, Jiajun Wu, Nick Haber, Ranjay Krishna, Lingjie Liu, et al. 2024c.Holodeck: Language Guided Generation of 3D Embodied AI Environments. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 16227–16237.
- Yang et al. (2024d)↑Yijun Yang, Tianyi Zhou, Kanxue Li, Dapeng Tao, Lusong Li, et al. 2024d.Embodied Multi-Modal Agent trained by an LLM from a Parallel TextWorld. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 26265–26275.
- Yasuda et al. (2020)↑Yuri D. V. Yasuda, Luiz Eduardo G. Martins, and Fabio A. M. Cappabianco. 2020.Autonomous Visual Navigation for Mobile Robots: A Systematic Literature Review.ACM Comput. Surv. 53, 1, Article 13 (Feb. 2020), 34 pages.
- Yenamandra et al. (2023)↑Sriram Yenamandra, Arun Ramachandran, Karmesh Yadav, Austin Wang, Mukul Khanna, Theophile Gervet, Tsung-Yen Yang, Vidhi Jain, et al. 2023.Homerobot: Open-vocabulary mobile manipulation.arXiv preprint arXiv:2306.11565 (2023).
- Yokoyama et al. (2024)↑Naoki Yokoyama, Ram Ramrakhya, Abhishek Das, et al. 2024.HM3D-OVON: A dataset and benchmark for open-vocabulary object goal navigation. In 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 5543–5550.
- Yu et al. (2020)↑Tianhe Yu, Deirdre Quillen, Zhanpeng He, Ryan Julian, Karol Hausman, Chelsea Finn, and Sergey Levine. 2020.Meta-world: A benchmark and evaluation for multi-task and meta reinforcement learning. In Conference on robot learning. PMLR, 1094–1100.
- Ze et al. (2024a)↑Yanjie Ze, Zixuan Chen, Wenhao Wang, Tianyi Chen, Xialin He, Ying Yuan, Xue Bin Peng, and Jiajun Wu. 2024a.Generalizable humanoid manipulation with improved 3d diffusion policies.arXiv preprint arXiv:2410.10803 (2024).
- Ze et al. (2024b)↑Yanjie Ze, Gu Zhang, Kangning Zhang, Chenyuan Hu, Muhan Wang, and Huazhe Xu. 2024b.3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations. In Proceedings of Robotics: Science and Systems (RSS).
- Zhang et al. (2025b)↑Hui Zhang, Jianzhi Lyu, Chuangchuang Zhou, Hongzhuo Liang, Yuyang Tu, Fuchun Sun, and Jianwei Zhang. 2025b.ADG-Net: A Sim2Real Multimodal Learning Framework for Adaptive Dexterous Grasping.IEEE Trans. Cybern. 55, 2 (2025), 840–853.
- Zhang et al. (2025a)↑Lingfeng Zhang, Xiaoshuai Hao, Qinwen Xu, Qiang Zhang, Xinyao Zhang, Pengwei Wang, Jing Zhang, Zhongyuan Wang, Shanghang Zhang, and Renjing Xu. 2025a.Mapnav: A novel memory representation via annotated semantic maps for vlm-based vision-and-language navigation.arXiv preprint arXiv:2502.13451 (2025).
- Zhang et al. (2024)↑Tianle Zhang, Dongjiang Li, Yihang Li, Zecui Zeng, Lin Zhao, Lei Sun, Yue Chen, Xuelong Wei, Yibing Zhan, Lusong Li, and Xiaodong He. 2024.Empowering Embodied Manipulation: A Bimanual-Mobile Robot Manipulation Dataset for Household Tasks. In arXiv.
- Zhao et al. (2023)↑Tony Z. Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. 2023.Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. In Proceedings of Robotics: Science and Systems. Daegu, Republic of Korea.
- Zhaxizhuoma et al. (2024)↑Zhaxizhuoma Zhaxizhuoma, Pengan Chen, Ziniu Wu, Jiawei Sun, Dong Wang, Peng Zhou, et al. 2024.AlignBot: Aligning VLM-powered Customized Task Planning with User Reminders Through Fine-Tuning for Household Robots.arXiv preprint arXiv:2409.11905 (2024).
- Zheng et al. (2024a)↑Duo Zheng, Shijia Huang, Lin Zhao, Yiwu Zhong, and Liwei Wang. 2024a.Towards Learning a Generalist Model for Embodied Navigation. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 13624–13634.
- Zheng et al. (2025a)↑Junhao Zheng, Shengjie Qiu, Chengming Shi, and Qianli Ma. 2025a.Towards Lifelong Learning of Large Language Models: A Survey.ACM Comput. Surv. 57, 8, Article 193 (March 2025), 35 pages.
- Zheng et al. (2025b)↑Junhao Zheng, Chengming Shi, Xidi Cai, Qiuke Li, Duzhen Zhang, Chenxing Li, Dong Yu, and Qianli Ma. 2025b.Lifelong Learning of Large Language Model based Agents: A Roadmap.arXiv preprint arXiv:2501.07278 (2025).
- Zheng et al. (2024b)↑Ying Zheng, Lei Yao, Yuejiao Su, Yi Zhang, Yi Wang, Sicheng Zhao, Yiyi Zhang, and Lap-Pui Chau. 2024b.A survey of embodied learning for object-centric robotic manipulation.arXiv preprint arXiv:2408.11537 (2024).
- Zhou et al. (2024b)↑Gengze Zhou, Yicong Hong, and Qi Wu. 2024b.Navgpt: Explicit reasoning in vision-and-language navigation with large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 38. 7641–7649.
- Zhou et al. (2025)↑Jianshu Zhou, Junda Huang, Qi Dou, Pieter Abbeel, and Yunhui Liu. 2025.A Dexterous and Compliant (DexCo) Hand Based on Soft Hydraulic Actuation for Human-Inspired Fine In-Hand Manipulation.IEEE Transactions on Robotics 41 (2025), 666–686.doi:10.1109/TRO.2024.3508932
- Zhou et al. (2024a)↑Qinhong Zhou, Sunli Chen, Yisong Wang, Haozhe Xu, Weihua Du, Hongxin Zhang, Yilun Du, Joshua B Tenenbaum, and Chuang Gan. 2024a.Hazard challenge: Embodied decision making in dynamically changing environments.arXiv preprint arXiv:2401.12975 (2024).
- Zhu et al. (2021)↑Fengda Zhu, Yi Zhu, Vincent Lee, Xiaodan Liang, and Xiaojun Chang. 2021.Deep learning for embodied vision navigation: A survey.arXiv preprint arXiv:2108.04097 (2021).
- Zhu et al. (2020)↑Yi Zhu, Fengda Zhu, Zhaohuan Zhan, Bingqian Lin, Jianbin Jiao, Xiaojun Chang, et al. 2020.Vision-Dialog Navigation by Exploring Cross-Modal Memory. In 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 10727–10736.
- Zitkovich et al. (2023)↑Brianna Zitkovich, Tianhe Yu, Sichun Xu, Peng Xu, Ted Xiao, Fei Xia, Jialin Wu, et al. 2023.RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control. In Proceedings of The 7th Conference on Robot Learning (Proceedings of Machine Learning Research, Vol. 229), Jie Tan, Marc Toussaint, and Kourosh Darvish (Eds.). PMLR, 2165–2183.