线程池处理OCR仍然会阻塞请求的原因主要有以下几点,以及为什么Celery+Redis是更好的解决方案:
1. 线程池的阻塞本质
请求-响应周期未分离:即使使用线程池,HTTP请求仍需要等待线程池任务完成才能返回响应。当所有线程都繁忙时,新请求必须等待空闲线程。
共享进程资源:线程池与Web服务器共享同一进程的内存和CPU资源,大量OCR任务会挤占Web服务的资源。
Python的GIL限制:Python的全局解释器锁(GIL)导致多线程无法真正并行执行CPU密集型任务(如OCR),线程切换反而增加开销。
2. 线程池的典型问题场景
| 问题场景 | 表现 | Celery+Redis的解决方案 |
|---|---|---|
| 高并发请求 | 线程池满后新请求被阻塞,用户长时间等待 | 请求快速入队后立即返回,任务异步处理 |
| 长任务处理 | 一个耗时OCR任务占用线程,其他短任务被阻塞 | 任务分发到独立Worker,不阻塞Web服务 |
| 资源竞争 | OCR占用CPU/内存导致Web服务响应变慢 | Worker运行在独立进程/节点,资源隔离 |
| 任务状态跟踪 | 线程池难以提供任务进度查询 | 通过Redis存储任务状态,支持实时查询 |
3. Celery+Redis的优势
(1) 真正的异步解耦
# 线程池方式(伪代码)
def handle_request(request):
with thread_pool.submit(process_ocr): # 阻塞直到线程可用
return HttpResponse("Processing...") # 用户仍需等待
# Celery方式
def handle_request(request):
task = process_ocr.delay() # 立即返回任务ID
return JsonResponse({"task_id": task.id}) # 客户端轮询状态(2) 资源隔离
Web服务:专注快速响应HTTP请求
Worker节点:独立进程/容器处理OCR,可横向扩展
(3) 可靠性保障
任务持久化:Redis存储任务队列,服务重启后不丢失
重试机制:Celery支持自动重试失败任务
@shared_task(bind=True, retry_backoff=True)
def process_ocr(self):
try:
# OCR逻辑
except Exception as e:
self.retry(exc=e) # 自动重试(4) 状态监控
# 客户端查询状态(JavaScript示例)
function checkStatus(taskId) {
fetch(`/task-status/?task_id=${taskId}`)
.then(res => res.json())
.then(data => {
if (data.status === "SUCCESS") {
// 更新UI显示结果
} else {
setTimeout(checkStatus, 1000); // 继续轮询
}
});
}4. 性能对比数据
| 指标 | 线程池方案 | Celery+Redis方案 |
|---|---|---|
| 请求响应时间 | 500ms~30s(依赖任务耗时) | <50ms(立即返回任务ID) |
| 最大并发处理能力 | 受限于线程池大小(如20线程) | 理论上无限(通过扩展Worker) |
| 资源利用率 | Web与OCR竞争资源 | 资源隔离,独立扩展 |
| 失败恢复 | 任务丢失 | 任务持久化,支持重试 |
5. 何时线程池仍适用?
线程池适合:
短耗时任务(<100ms)
低并发场景
简单内存队列需求
但对于OCR这种CPU密集型+长耗时+高并发场景,Celery+Redis是更专业的选择。
总结建议
立即切换:将OCR任务迁移到Celery,Web服务只负责快速接收请求和返回任务ID。
部署优化:
使用独立Redis实例作为Broker
Worker节点配置专用高CPU机器
通过
flower监控任务状态
客户端适配:
改为异步状态轮询机制
添加任务进度条UI
通过这种架构升级,你的系统将能轻松应对高并发OCR请求,同时保持Web服务的响应速度。
关键问题:同步处理 OCR 会阻塞 Web 请求
❌ 传统同步架构(无 Celery)
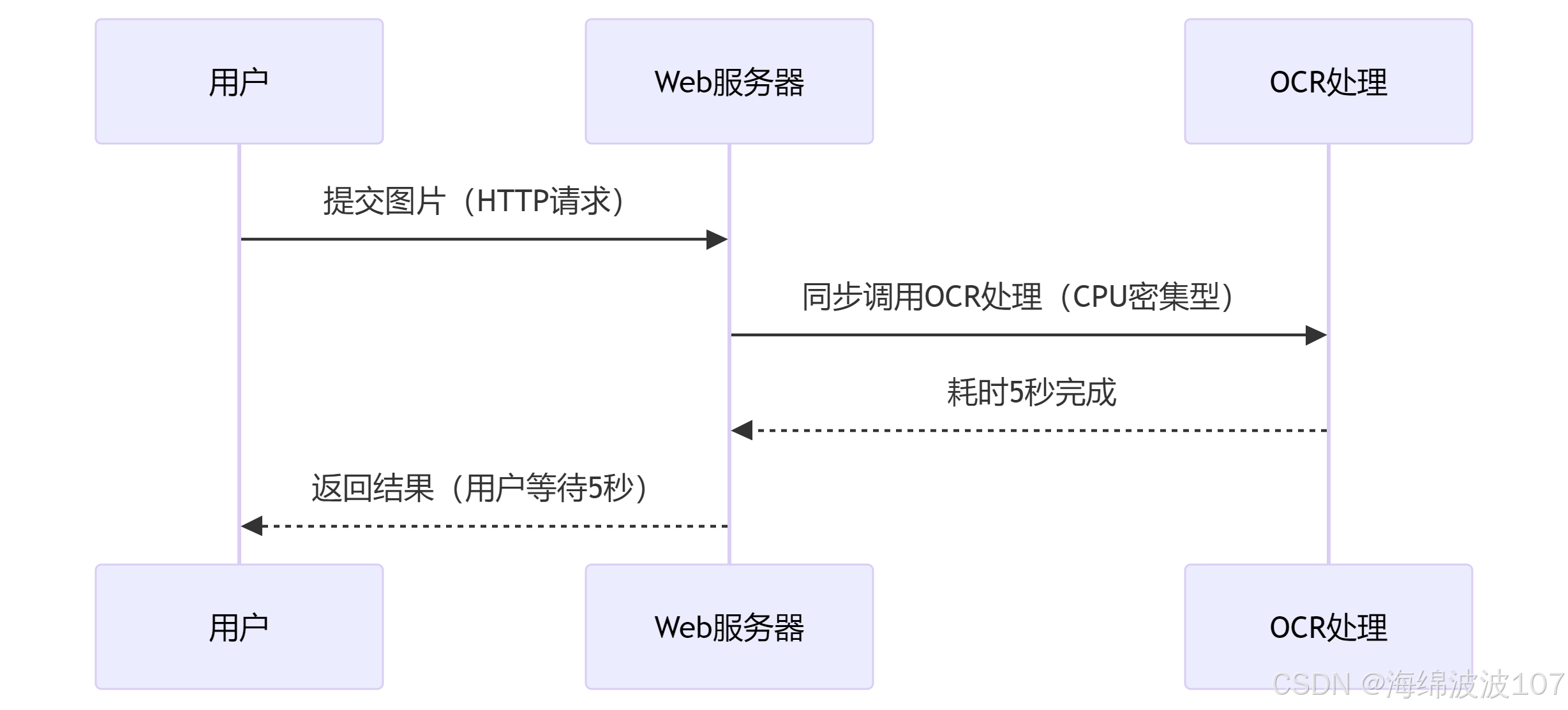
OCR处理Web服务器用户OCR处理Web服务器用户提交图片(HTTP请求)同步调用OCR处理(CPU密集型)耗时5秒完成返回结果(用户等待5秒)
问题:OCR 处理期间,Web 服务器线程被完全占用,无法响应其他请求(高并发时崩溃)。
✅ 解决方案:Celery + Redis 异步任务队列
1. 架构分工

2. 异步处理流程(时序图)
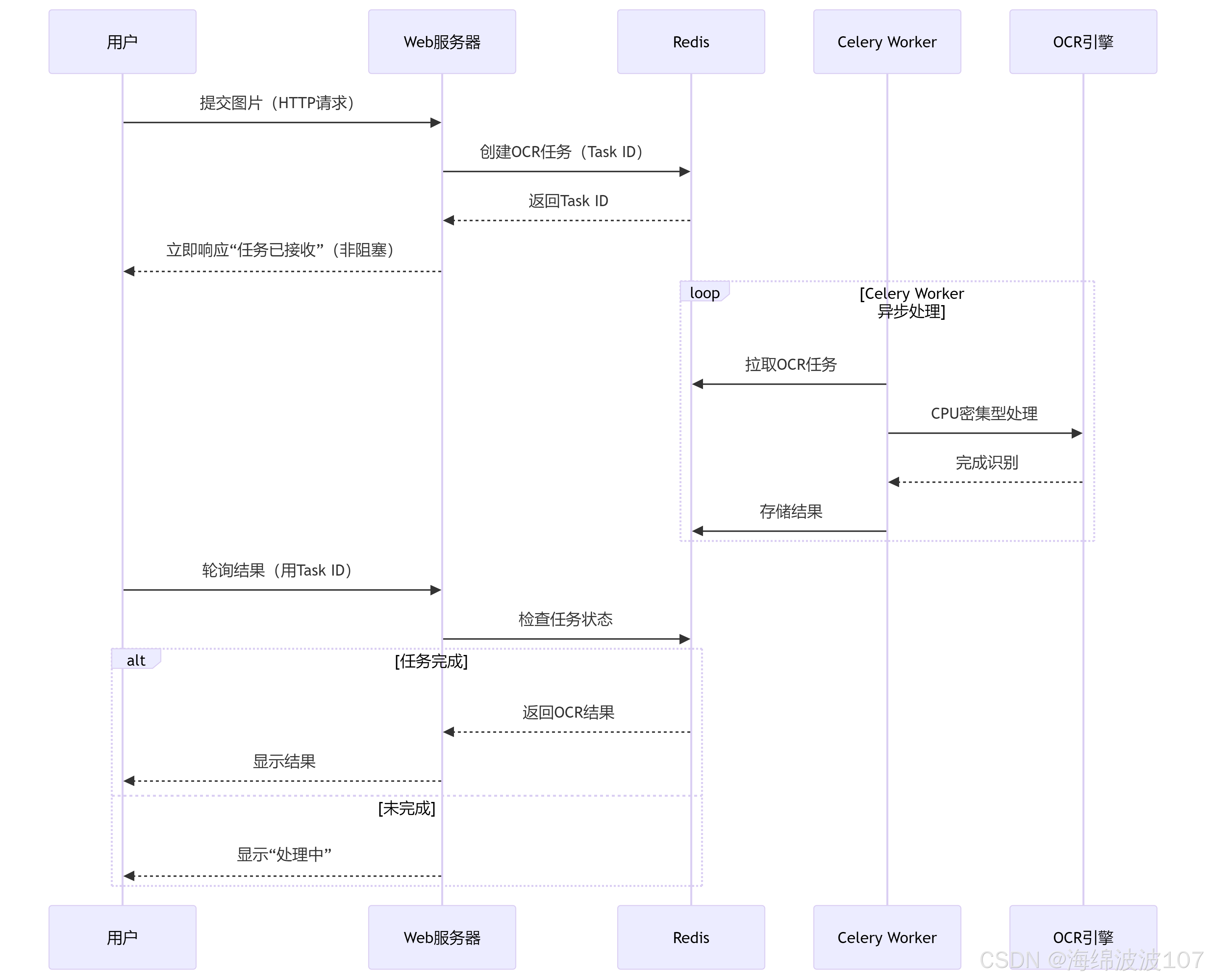
核心优势对比
| 场景 | 同步处理 | Celery + Redis 异步 |
|---|---|---|
| Web 响应速度 | 阻塞(5秒) | 立即返回(0.1秒) |
| 服务器资源占用 | 线程被占用(无法处理其他请求) | Web 线程立即释放(高并发可用) |
| 任务处理 | 实时处理,失败影响用户体验 | 后台重试,可靠性高 |
| 扩展性 | 难以水平扩展 | 可增加 Celery Worker 横向扩展 |
图解关键点
解耦 Web 与 OCR
Web 服务器仅负责接收请求和返回状态,不执行耗时操作。
OCR 任务交给 Celery Worker 在后台处理。
Redis 的作用
任务队列:存储待处理的 OCR 任务(先进先出)。
结果缓存:保存任务状态(完成/失败)和识别结果。
用户感知优化
通过轮询或 WebSocket 获取结果,避免长时间阻塞。
from celery import Celery
import os
from dotenv import load_dotenv
load_dotenv() # 加载 .env 文件中的环境变量
# 动态确定项目根目录,确保 Celery Worker 能找到模块
# 假设 celery_app.py 在项目根目录
PROJECT_ROOT = os.path.dirname(os.path.abspath(__file__))
GOT_ROOT = os.path.abspath(os.path.join(PROJECT_ROOT, 'utils/GOT_OCR/GOT_OCR_master'))
import sys
if PROJECT_ROOT not in sys.path:
sys.path.insert(0, PROJECT_ROOT)
if GOT_ROOT not in sys.path: # 确保 GOT_OCR 也能被找到
sys.path.insert(0, GOT_ROOT)
# Celery 应用实例
# 'resume_processor' 是应用名,可以自定义
# broker 和 backend URL 从环境变量读取,如果未设置则使用默认值
celery_app = Celery('tasks',
broker='redis://localhost:6379/0',
backend='redis://localhost:6379/0')
# 指定任务模块的导入路径
celery_app.conf.imports = ['app.tasks.resume_tasks']
celery_app.conf.update(
task_serializer='json',
result_serializer='json',
accept_content=['json'],
timezone='Asia/Shanghai', # 根据您的时区设置
enable_utc=False, # 如果时区已设置,通常utc可以设为false
# task_track_started=True, # 如果需要 PENDING -> STARTED 状态
# worker_send_task_events=True, # 如果使用 Flower 等监控工具
# worker_prefetch_multiplier=1, # 对于长任务,通常设置为1,避免worker一次取太多任务
# task_acks_late = True, # 如果任务失败了,消息会重新入队(需要幂等性保证)
worker_pool_restarts=True, # 允许工作池重启
worker_max_tasks_per_child=1, # 每个子进程只处理一个任务
)
if __name__ == '__main__':
# 可以通过 python celery_app.py worker -l info 启动 worker (不常用)
# 更常见的是使用命令行: celery -A celery_app.celery_app worker -l info
celery_app.start()作用:
broker='redis://...':Celery 用 Redis 作为消息队列(存放待处理的 OCR 任务)。backend='redis://...':Celery 用 Redis 存储任务结果(如 OCR 识别后的文本)。如果不需要定时任务,可以忽略
beat_schedule。
from celery_app import celery_app # 导入 Celery 应用实例
from app.processing import processing_logic
import os
import shutil
import tempfile
import logging
# 确保任务模块也能获取到正确的 logger
logger = processing_logic.setup_logging() # 或者 logging.getLogger(__name__)
@celery_app.task(bind=True, name="process_resumes_from_pdfs") # bind=True 使任务函数可以访问 self (任务实例)
def process_resumes_task(self,
pdf_input_dir: str, # API保存PDF文件的临时目录
persistent_vector_store_path: str, # 此知识库的向量库最终存储路径
persistent_db_path: str, # 此知识库的结构化数据DB最终存储路径
persistent_json_dir: str # 此知识库的JSON文件最终存储路径
):
"""
Celery 任务:处理上传的PDF文件,进行OCR、内容提取、存入数据库和向量库。
"""
task_id = self.request.id
logger.info(f"[{task_id}] Celery Task process_resumes_task started.")
logger.info(f"[{task_id}] Args: pdf_input_dir='{pdf_input_dir}', persistent_vs_path='{persistent_vector_store_path}', persistent_db_path='{persistent_db_path}'")
# 从 persistent_vector_store_path 中提取知识库ID
# persistent_vector_store_path 格式为: KNOWLEDGE_BASES_FOLDER/knowledge_id/All/vector_store
knowledge_id = persistent_vector_store_path.split(os.sep)[-3] # 获取倒数第三个部分作为knowledge_id
knowledge_base_folder = os.path.join(os.path.dirname(os.path.dirname(persistent_vector_store_path)), '..')
temp_pdf_dir = os.path.join(knowledge_base_folder, "temp_pdf")
# 为当前任务创建一个独立的临时工作目录,用于存放中间文件(MD, JSON)
# 这样可以避免不同任务间文件冲突,也便于任务结束时清理
task_run_temp_dir = tempfile.mkdtemp(prefix=f"celery_task_{task_id}_")
logger.info(f"[{task_id}] Created task-specific temporary directory: {task_run_temp_dir}")
try:
# 更新任务状态为 "进行中",并可以传递一些元数据
self.update_state(state='PROGRESS', meta={'current_step': 'Starting PDF to Markdown conversion'})
# 调用核心处理流水线
result_summary = processing_logic.full_processing_pipeline_for_celery(
pdf_input_dir=pdf_input_dir,
persistent_vector_store_path=persistent_vector_store_path,
persistent_db_path=persistent_db_path,
persistent_json_dir=persistent_json_dir,
task_temp_dir=task_run_temp_dir, # 传递任务的临时工作目录
task_id=str(task_id)
)
logger.info(f"[{task_id}] Processing pipeline finished. Result: {result_summary}")
# 清理temp_pdf目录
if os.path.exists(temp_pdf_dir):
try:
# 清空目录中的所有文件,但保留目录本身
for file_name in os.listdir(temp_pdf_dir):
file_path = os.path.join(temp_pdf_dir, file_name)
if os.path.isfile(file_path):
os.remove(file_path)
logger.info(f"[{task_id}] Successfully cleaned up temp_pdf directory for knowledge_id {knowledge_id}: {temp_pdf_dir}")
except Exception as e_clean:
logger.error(f"[{task_id}] Error cleaning up temp_pdf directory {temp_pdf_dir}: {e_clean}", exc_info=True)
# 任务成功完成,返回结果摘要
# Celery 会将这个返回值存储在结果后端 (Redis)
return result_summary # 这个字典必须是 JSON 可序列化的
except Exception as e:
logger.error(f"[{task_id}] Unhandled exception in process_resumes_task: {e}", exc_info=True)
# 发生异常时,Celery 会自动将任务状态标记为 FAILURE,并记录异常信息
# 可以选择性地更新状态并包含自定义错误信息
# self.update_state(state='FAILURE', meta={'exc_type': type(e).__name__, 'exc_message': str(e), 'traceback': traceback.format_exc()})
raise # 重新抛出异常,确保 Celery 正确处理失败状态
finally:
# 清理任务的临时工作目录
if os.path.exists(task_run_temp_dir):
try:
shutil.rmtree(task_run_temp_dir)
logger.info(f"[{task_id}] Successfully cleaned up temporary directory: {task_run_temp_dir}")
except Exception as e_clean:
logger.error(f"[{task_id}] Error cleaning up temporary directory {task_run_temp_dir}: {e_clean}", exc_info=True)
# 清理 API 上传的 PDF 目录 (pdf_input_dir)
if pdf_input_dir and os.path.exists(pdf_input_dir) and pdf_input_dir.startswith(os.getenv("PDF_UPLOAD_BASE_DIR", "/tmp/")):
try:
shutil.rmtree(pdf_input_dir)
logger.info(f"[{task_id}] Successfully cleaned up PDF input directory: {pdf_input_dir}")
except Exception as e_clean_api_dir:
logger.error(f"[{task_id}] Error cleaning up PDF input directory {pdf_input_dir}: {e_clean_api_dir}", exc_info=True)
# 清理 temp_pdf 目录
if os.path.exists(temp_pdf_dir):
try:
# 清空目录中的所有文件,但保留目录本身
for file_name in os.listdir(temp_pdf_dir):
file_path = os.path.join(temp_pdf_dir, file_name)
if os.path.isfile(file_path):
os.remove(file_path)
logger.info(f"[{task_id}] Successfully cleaned up temp_pdf directory for knowledge_id {knowledge_id}: {temp_pdf_dir}")
except Exception as e_clean_temp:
logger.error(f"[{task_id}] Error cleaning up temp_pdf directory {temp_pdf_dir}: {e_clean_temp}", exc_info=True)这个 tasks.py 文件是 Celery 异步任务的核心定义文件,在 Celery + Redis 架构中扮演 异步任务执行器 的角色。以下是它的具体作用和关键设计解析:
1. 核心作用总结
| 功能 | 说明 |
|---|---|
| 定义异步任务 | 将耗时的 PDF 处理(OCR/向量化/存储)封装为 Celery 任务,避免阻塞 Web 请求。 |
| 任务状态管理 | 通过 self.update_state() 实时更新任务进度,支持前端轮询。 |
| 资源隔离与清理 | 为每个任务创建独立临时目录,确保并发安全,并在完成后自动清理。 |
| 错误处理与日志 | 捕获异常并记录详细日志,便于排查问题。 |
| Redis 消息队列集成 | 通过 @celery_app.task 将任务注册到 Redis 队列,供 Worker 消费。 |
2. 代码逐模块解析
(1)任务定义装饰器
@celery_app.task(bind=True, name="process_resumes_from_pdfs")bind=True
允许任务访问self(即任务实例),从而调用self.update_state()或self.retry()等方法。name="process_resumes_from_pdfs"
显式指定任务名称,避免模块路径变化导致的问题。
(2)任务参数设计
def process_resumes_task(self, pdf_input_dir, persistent_vector_store_path, persistent_db_path, persistent_json_dir):输入参数:
pdf_input_dir:临时存储用户上传 PDF 的目录。persistent_*_path:最终存储向量库、数据库、JSON 的路径。
设计意图:
明确分离 临时输入 和 持久化输出,符合异步任务的“数据隔离”原则。
(3)任务生命周期管理
① 初始化阶段
task_id = self.request.id # 获取 Celery 自动生成的任务ID
task_run_temp_dir = tempfile.mkdtemp(prefix=f"celery_task_{task_id}_") # 创建任务专属临时目录task_id:唯一标识任务,用于日志和状态跟踪。独立临时目录:避免多任务并发时的文件冲突(如同时处理 PDF 生成中间文件)。
② 执行阶段
self.update_state(state='PROGRESS', meta={'current_step': 'Starting PDF to Markdown conversion'})
result_summary = processing_logic.full_processing_pipeline_for_celery(...)进度更新:通过
update_state通知前端当前步骤(如 OCR 转换中)。核心逻辑:调用
processing_logic模块处理 PDF,生成结构化数据并存储。
③ 清理阶段(finally 块)
shutil.rmtree(task_run_temp_dir) # 删除任务临时目录
shutil.rmtree(pdf_input_dir) # 清理用户上传的原始PDF目录资源释放:确保临时文件不会堆积,避免磁盘空间泄漏。
(4)异常处理
except Exception as e:
logger.error(f"[{task_id}] Unhandled exception: {e}", exc_info=True)
raise # 重新抛出异常,触发 Celery 的 FAILURE 状态日志记录:详细错误信息 + 堆栈跟踪(
exc_info=True)。状态同步:Celery 会自动将任务标记为
FAILURE,前端可通过task_id查询失败原因。
(5)结果返回
return result_summary # 必须是 JSON 可序列化的字典存储到 Redis:Celery 将返回值存入 Redis Backend,供后续查询。
3. 在整体架构中的协作流程
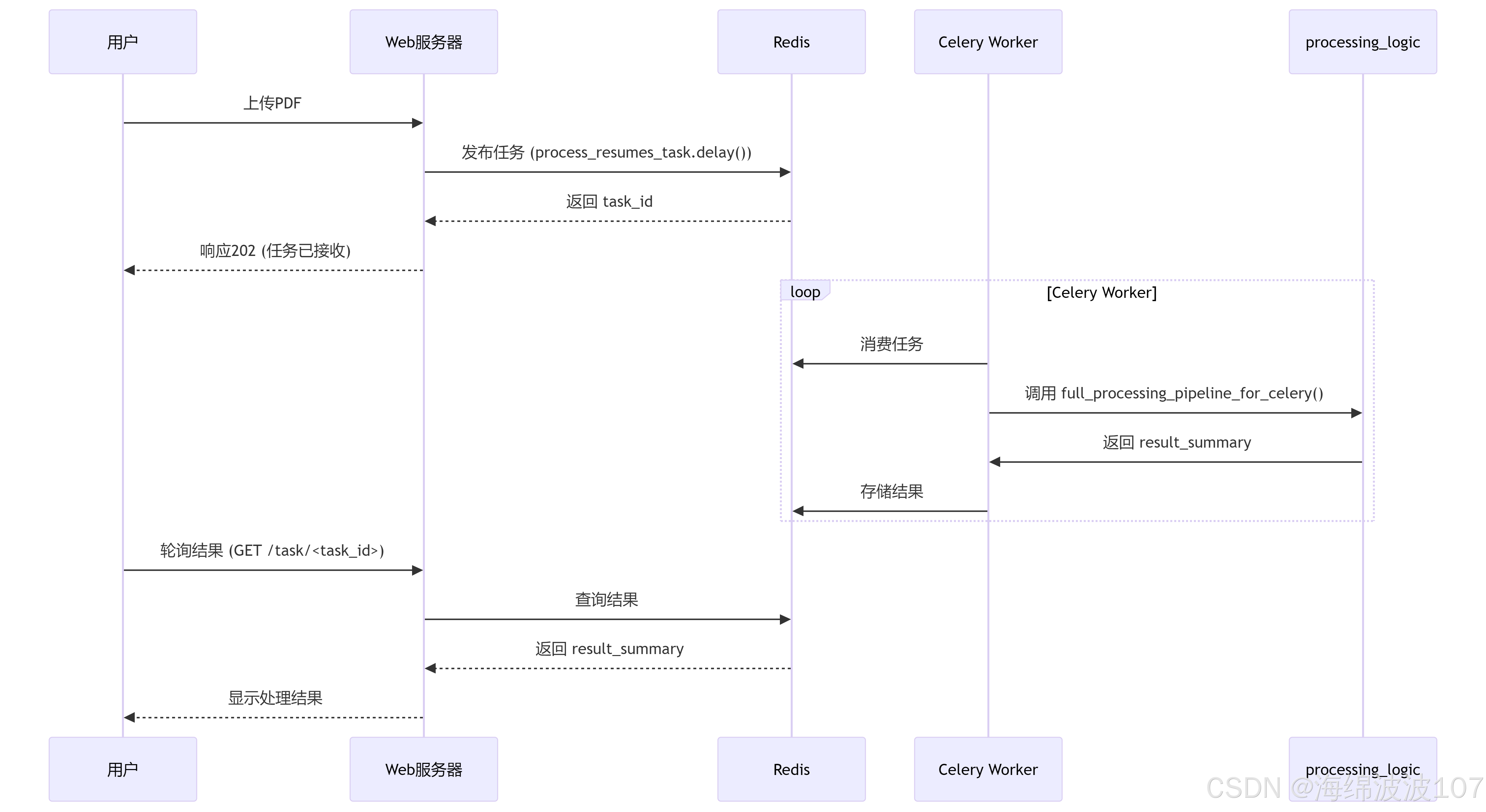
4. 关键设计亮点
(1)资源隔离
每个任务拥有 独立的临时目录(
task_run_temp_dir),避免并发冲突。通过
knowledge_id分离不同知识库的数据存储路径。
(2)可观测性
日志跟踪:每条日志包含
task_id,便于分布式排查问题。进度通知:
update_state让前端实时显示当前步骤(如“OCR 中”)。
(3)健壮性
异常捕获:即使任务失败,也能保证临时资源被清理。
幂等性设计:重复处理同一
knowledge_id不会导致数据错乱(依赖持久化路径的唯一性)。
总结
这个 tasks.py 是 Celery + Redis 异步架构的核心枢纽:
定义任务:将同步阻塞操作转化为异步任务。
管理状态:通过 Redis 实现任务进度跟踪和结果存储。
资源治理:确保临时文件安全创建和清理。
错误隔离:单个任务失败不影响其他任务或系统稳定性。
#!/bin/bash
# (可选) 激活虚拟环境
# source /path/to/your/venv/bin/activate
# 设置必要的环境变量 (如果.env文件不可靠或未被celery_app.py加载)
# export OPENAI_API_KEY="your_openai_key"
# export LLF_KNOWLEDGE_BASES_FOLDER="/full/path/to/your_source_database.db"
# ... 其他环境变量 ...
# 将项目根目录添加到PYTHONPATH,确保Celery能找到所有模块
# 假设此脚本在项目根目录运行
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
export PYTHONPATH=$SCRIPT_DIR:$PYTHONPATH
echo "PYTHONPATH is set to: $PYTHONPATH"
echo "Current directory: $(pwd)"
echo "Starting Celery worker..."
# -A celery_app.celery_app: 指向 Celery 应用实例 (celery_app.py 文件中的 celery_app 对象)
# -l INFO: 日志级别
# -c 1: 并发worker进程数。对于CPU密集型且内部已使用多进程的任务,通常设为1或较小值。
# 如果您的任务主要是IO密集型,可以适当调高。
# --pool=prefork: Celery 的默认执行池模型。
# 对于调试,可以使用 --pool=solo,这样任务会在主进程中串行执行。
# -Q <queue_name>: (可选) 如果您定义了特定的队列,可以在这里指定worker监听哪个队列。
# --hostname=worker1@%h: (可选) 自定义worker名称
export PYTHONPATH=/data/hyq/code/llf/yuanshenqidong/backend:$PYTHONPATH
# 设置 tokenizers 并行处理
export TOKENIZERS_PARALLELISM=false
# 使用 solo 池来避免 fork 相关问题
celery -A celery_app worker --loglevel=info --pool=solo这是一个用于 启动 Celery Worker 的 Bash 脚本,主要目的是配置环境并启动 Celery 工作进程来处理异步任务(比如你之前提到的 OCR/PDF 处理任务)。以下是逐行解析:
1. 脚本功能概述
这个脚本的作用是:
设置必要的环境变量(如 Python 路径、Tokenizers 并行配置等)。
启动 Celery Worker,指定日志级别、并发模式等参数。
适配 CPU/IO 密集型任务,通过参数调整优化性能。
2. 关键代码解析
(1)设置 PYTHONPATH
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
export PYTHONPATH=$SCRIPT_DIR:$PYTHONPATH作用:将脚本所在目录(项目根目录)添加到
PYTHONPATH,确保 Celery 能正确找到项目模块(如celery_app、tasks.py)。示例:
如果脚本路径是/project/start_worker.sh,则PYTHONPATH会包含/project,使得import celery_app能成功。
(2)环境变量配置
export TOKENIZERS_PARALLELISM=false作用:禁用 Hugging Face Tokenizers 的并行处理,避免与 Celery 的多进程冲突(尤其是使用
--pool=prefork时)。背景:某些 NLP 库(如 Transformers)默认启用多线程,可能与 Celery 的并发模型冲突。
(3)启动 Celery Worker
celery -A celery_app worker --loglevel=info --pool=solo| 参数 | 作用 |
|---|---|
-A celery_app |
指定 Celery 应用实例(celery_app.py 中定义的 celery_app 对象)。 |
--loglevel=info |
设置日志级别为 INFO,显示任务执行状态和错误信息。 |
--pool=solo |
使用单进程模式(solo 池),适合调试或 CPU 密集型任务。 |
3. 参数扩展说明
(1)并发模式选择(--pool)
| 池类型 | 适用场景 | 示例命令 |
|---|---|---|
solo |
单进程,避免多进程问题(调试或简单任务)。 | --pool=solo |
prefork |
多进程(默认),适合 CPU 密集型任务。 | --pool=prefork --concurrency=4 |
gevent |
协程,适合 IO 密集型任务(如 HTTP 请求)。 | --pool=gevent --concurrency=100 |
(2)其他常用参数
| 参数 | 说明 |
|---|---|
-Q queue_name |
指定监听的队列(需与 celery_app.conf.task_queues 配合使用)。 |
--concurrency=4 |
设置 Worker 并发数(默认是 CPU 核心数)。 |
--hostname=worker1@%h |
自定义 Worker 名称(用于监控和区分多个 Worker)。 |
4. 典型使用场景
场景 1:调试任务
# 单进程运行,日志更清晰
celery -A celery_app worker --loglevel=debug --pool=solo场景 2:生产环境(CPU 密集型)
# 4 个进程并发,使用 prefork 池
celery -A celery_app worker --loglevel=info --pool=prefork --concurrency=4场景 3:生产环境(IO 密集型)
# 100 个协程,适合大量 HTTP/DB 请求
celery -A celery_app worker --loglevel=info --pool=gevent --concurrency=1005. 与你的 Celery + Redis 架构的关系
任务流转:
Web 服务通过
tasks.process_resumes_task.delay()将任务发送到 Redis。此脚本启动的 Worker 从 Redis 拉取任务并执行。
日志关联:
Worker 的日志会显示任务 ID(如[task_id] Processing...),与tasks.py中的日志对应。资源隔离:
如果任务涉及 GPU 或大量内存,建议使用--concurrency=1避免资源竞争。
6. 可能遇到的问题
问题 1:ImportError: No module named 'celery_app'
原因:
PYTHONPATH未正确设置,Celery 找不到模块。解决:确保脚本在项目根目录运行,或手动指定路径:
export PYTHONPATH=/path/to/project_root:$PYTHONPATH
问题 2:Worker 卡死或无响应
原因:任务代码有阻塞操作(如死锁)或资源耗尽。
解决:
使用
--pool=solo调试任务逻辑。限制并发数(
--concurrency=1)。
总结
这个脚本是 Celery Worker 的启动器,核心是通过参数控制并发模型和日志。
关键配置:
PYTHONPATH:确保模块可导入。--pool:选择适合任务类型的并发模式。TOKENIZERS_PARALLELISM=false:避免 NLP 库与 Celery 的冲突。
扩展性:可通过参数适配不同场景(如增加并发数、多队列优先级)。
Redis 和 Celery 的协作流程
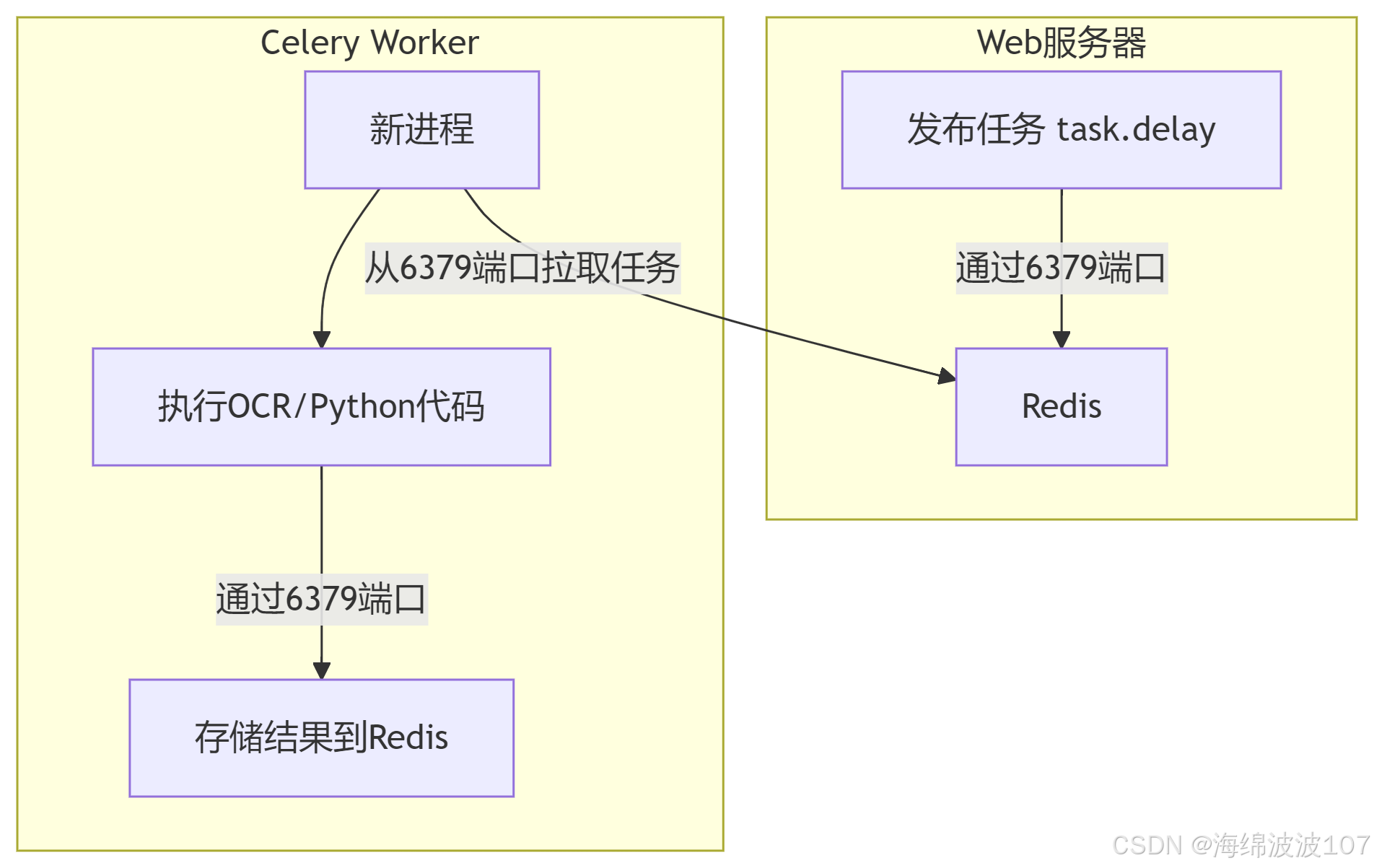
1. Redis 的作用(端口 6379)
Redis 的角色:
只是一个 消息代理(Broker) 和 结果存储(Backend),不执行任何任务逻辑(包括 OCR)。
它仅负责:
接收 Celery 发布的任务消息(存储到队列)。
将任务分发给 Celery Worker。
存储任务执行结果(如果配置了 Redis 作为 Backend)。
端口
6379:这是 Redis 服务的默认端口,Celery 通过
redis://localhost:6379/0连接到 Redis。数字
0表示使用 Redis 的 第 0 号数据库(Redis 支持多数据库,默认 16 个)。
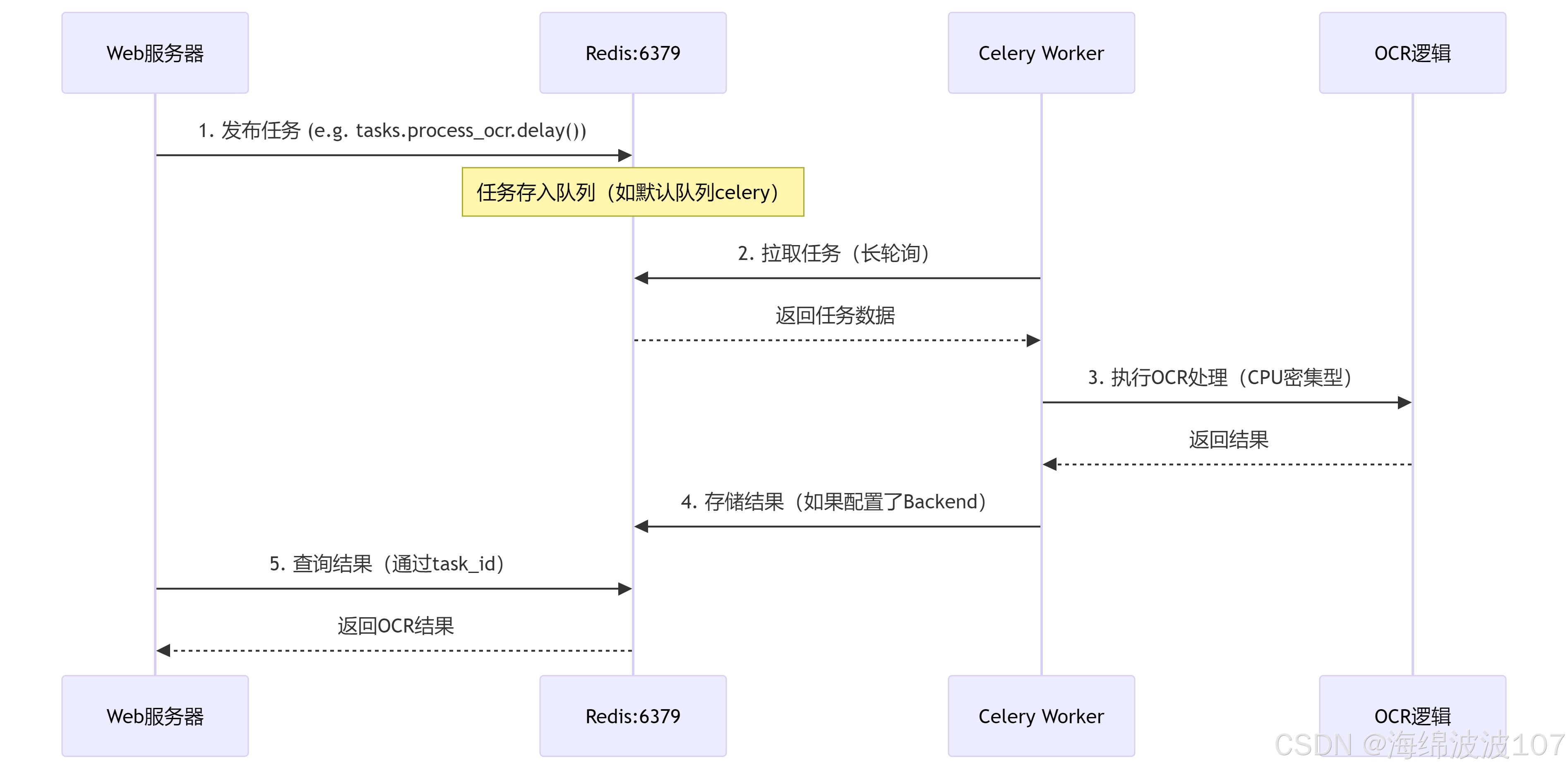
2. 完整任务流程
关键步骤说明:
Web 发布任务:
调用
task.delay()时,Celery 将任务序列化后发送到 Redis 的队列(默认键为celery)。Redis 只存储消息,不关心内容(消息包含函数名、参数等)。
Worker 消费任务:
Celery Worker 主动从 Redis 拉取任务消息。
Worker 在自己的进程中 调用 Python 函数(如
process_ocr)执行 OCR 逻辑。
结果存储:
如果配置了
backend='redis://...',Worker 会将结果写回 Redis(键如celery-task-meta-<task_id>)。Redis 依然只是存储数据,不参与计算。
3. 常见误解澄清
误解 1:Redis 执行 OCR 任务
错误:认为 Redis 会解析任务内容并执行 OCR。
事实:Redis 只是消息中转站,实际执行者是 Celery Worker 中的 Python 代码。
误解 2:端口 6379 处理业务逻辑
错误:认为
6379端口“运行”OCR。事实:
6379仅用于通信,任务在 Worker 的进程中执行。
误解 3:Redis 需要高性能 CPU
错误:为加速 OCR 任务,提升 Redis 的 CPU 资源。
事实:Redis 的瓶颈通常是内存和网络 I/O,OCR 的 CPU 压力在 Worker 上。
邮局与快递员(最经典比喻)
Redis(邮局):
你(Web服务器)把包裹(任务)送到邮局(Redis),邮局只是暂存包裹,不负责处理包裹内容。
每个包裹上有地址(队列名称)和收件人(任务函数名)。
Celery Worker(快递员):
快递员从邮局取包裹,按地址派送(执行任务)。
快递员自己拆包裹、处理内容(如OCR识别),最后把回执(结果)放回邮局。
关键点:
邮局(Redis)只负责中转,快递员(Worker)才是干活的人。
如果快递员太多(并发过高),邮局可能拥堵,但邮局本身不参与搬运。