(一)Day15继续完成该项目
data = pd.read_csv('foodstruct_nutritional_facts.csv')
print('数据基本信息:')
data
前期准备——读取数据——数据可视化——归一标准化——缺失值填补——绘制热力图
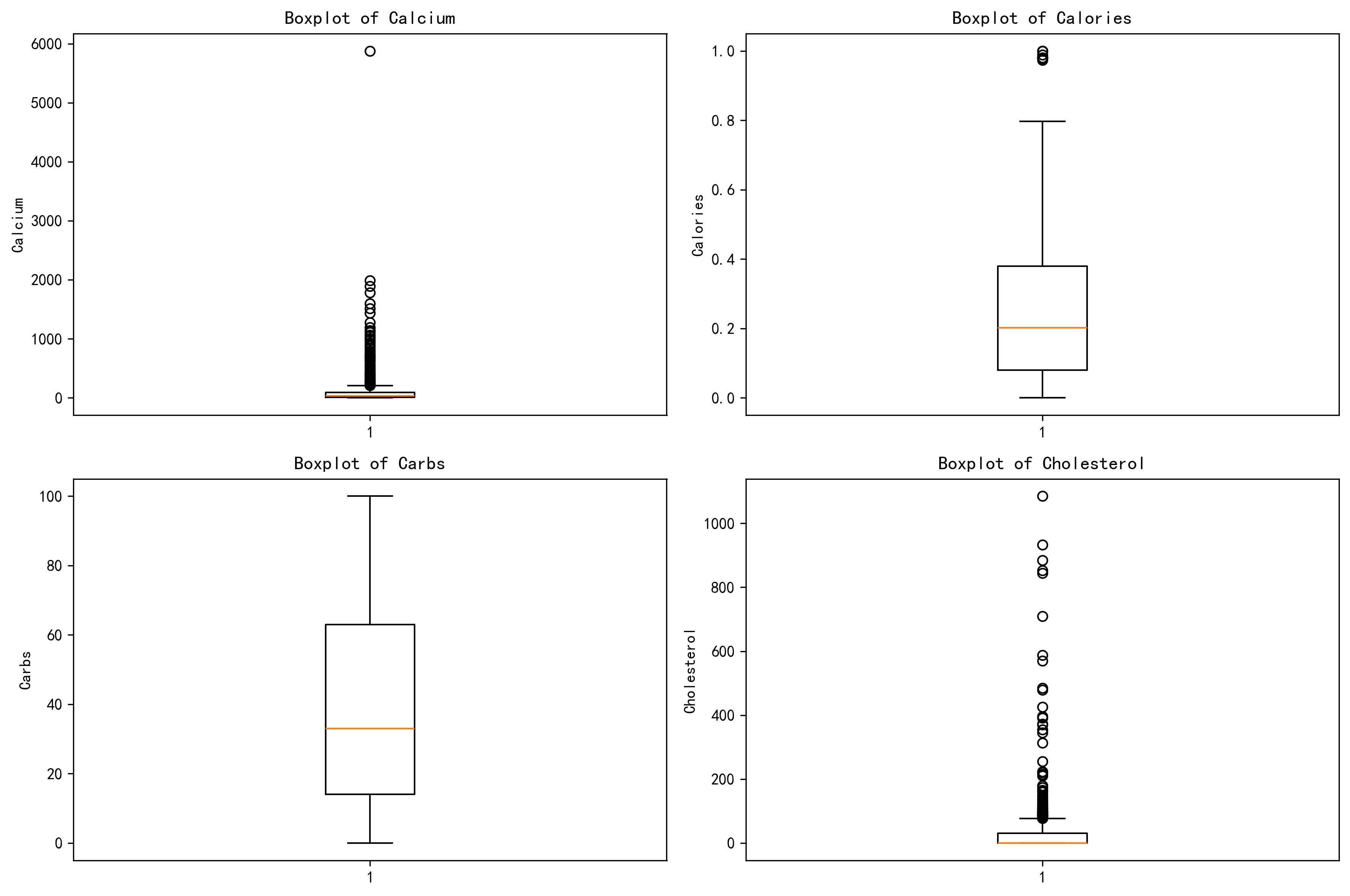
子图
# 定义要绘制的特征
features = ['Calcium', 'Calories', 'Carbs','Cholesterol']
# 设置图片清晰度
plt.rcParams['figure.dpi'] = 300
# 创建一个包含 2 行 2 列的子图布局
fig, axes = plt.subplots(2, 2, figsize=(12, 8))
# 使用 for 循环遍历特征
for i in range(len(features)):
row = i // 2 # 计算当前特征在子图中的行索引,// 是整除,即取整 ,之所以用整除是因为我们要的是行数
# 例如 0//2=0, 1//2=0, 2//2=1, 3//2=1
col = i % 2 # 计算当前特征在子图中的列索引,% 是取余,即取模
# 例如 0%2=0, 1%2=1, 2%2=0, 3%2=1
# 绘制箱线图
feature = features[i]
axes[row, col].boxplot(data[feature].dropna())
axes[row, col].set_title(f'Boxplot of {feature}')
axes[row, col].set_ylabel(feature)
# 调整子图之间的间距
plt.tight_layout()
# 显示图形
plt.show()结果图:
模型训练和评估
# 划分训练集和测试集
from sklearn.model_selection import train_test_split
X = data.drop(['Category Name'], axis=1) # 定义特征列,axis=1表示按列删除
y = data['Category Name'] # 标签
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 划分数据集,20%作为测试集,随机种子为42
# 训练集和测试集的形状
print(f"训练集特征形状: {X_train.shape}, 测试集特征形状: {X_test.shape}") # 打印训练集和测试集的形状
print(f'标签形状{y_train.shape}')
from sklearn.svm import SVC #支持向量机分类器
from sklearn.neighbors import KNeighborsClassifier #K近邻分类器
from sklearn.linear_model import LogisticRegression #逻辑回归分类器
import xgboost as xgb #XGBoost分类器
import lightgbm as lgb #LightGBM分类器
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
from catboost import CatBoostClassifier #CatBoost分类器
from sklearn.tree import DecisionTreeClassifier #决策树分类器
from sklearn.naive_bayes import GaussianNB #高斯朴素贝叶斯分类器
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score # 用于评估分类器性能的指标
from sklearn.metrics import classification_report, confusion_matrix #用于生成分类报告和混淆矩阵
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
#(尝试将category name进行编码,想利用机器学习通过维生素和固醇等含量判断其为什么类别食物,但现在遇到瓶颈,之后不知道怎么编码。。)
SMOTE过采样
# SMOTE过采样
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_train_smote, y_train_smote = smote.fit_resample(X_train, y_train)
print("SMOTE过采样后训练集的形状:", X_train_smote.shape, y_train_smote.shape)
# 训练随机森林模型(使用SMOTE过采样后的训练集)
rf_model_smote = RandomForestClassifier(random_state=42)
start_time_smote = time.time()
rf_model_smote.fit(X_train_smote, y_train_smote)
end_time_smote = time.time()
print(f"SMOTE过采样后训练与预测耗时: {end_time_smote - start_time_smote:.4f} 秒")
# 在测试集上预测
rf_pred_smote = rf_model_smote.predict(X_test)
print("\nSMOTE过采样后随机森林 在测试集上的分类报告:")
print(classification_report(y_test, rf_pred_smote))
print("SMOTE过采样后随机森林 在测试集上的混淆矩阵:")
print(confusion_matrix(y_test, rf_pred_smote))- SHAP可解释性分析
import shap # 初始化 SHAP 解释器 explainer = shap.TreeExplainer(rf_model) shap_values = explainer.shap_values(X_test) print('展示特征维度') print("shap_values 的形状:", shap_values.shape) print("shap_values[0] 的形状:", shap_values[0].shape) print("shap_values[:, :, 0] 的形状:", shap_values[:, :, 0].shape) print("X_test 的形状:", X_test.shape) print("--- SHAP 特征重要性蜂巢图 ---") shap.summary_plot(shap_values[:, :, 0], X_test,plot_type="violin",show=False,max_display=10) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了 plt.title("SHAP Feature Importance (Violin Plot)") plt.show() print("--- SHAP 决策图 ---") shap.decision_plot(explainer.expected_value[0], shap_values[0,:,0], X_test.iloc[0], #feature_order='hclust', show=False) plt.title("SHAP Decision Plot") plt.show()
报错了……代码还有待进一步学习……继续debug
Day16SHAP数据形状尺寸问题
知识点:
- numpy数组的创建:简单创建、随机创建、遍历、运算
- numpy数组的索引:一维、二维、三维
- SHAP值的深入理解
(一) 数组的创建
NumPy 数组基础笔记
1. 理解数组的维度 (Dimensions)
NumPy 数组的维度 (Dimension) 或称为 轴 (Axis)的概念,与我们日常理解的维度非常相似。
直观判断: 数组的维度层数通常可以通过打印输出时中括号 `[]` 的嵌套层数来初步确定:
一层 `[]`: 一维 (1D) 数组。
两层 `[]`: 二维 (2D) 数组。
三层 `[]`: 三维 (3D) 数组,依此类推。
2. 一维数组 (1D Array)
一维数组在结构上与 Python 中的列表(List)非常相似。它们的主要区别在于:
打印输出格式:当使用 `print()` 函数输出时:
NumPy 一维数组的元素之间默认使用空格分隔。
Python 列表的元素之间使用逗号分隔。
示例 (一维数组输出):
```
[7 5 3 9]
```
3. 二维数组 (2D Array)
二维数组可以被看作是“数组的数组”或者一个矩阵。其结构由两个主要维度决定:
行数: 代表整个二维数组中包含多少个一维数组。
列数:代表每个一维数组(也就是每一行)中包含多少个元素。
值得注意的是,二维数组不一定是正方形(即行数等于列数),它可以是任意的 `n * m` 形状,其中 `n` 是行数,`m` 是列数。
4. 数组的创建
NumPy 的 `array()` 函数非常灵活,可以接受各种“序列型”对象作为输入参数来创建数组。这意味着你可以将 Python 的列表 (List)、元组 (Tuple),甚至其他的 NumPy 数组等数据结构直接传递给 `np.array()` 来创建新的 NumPy 数组。
(二)数组随机化创建

import numpy as np
np.random.seed(42) # 设置随机种子以确保结果可重复
# 生成10个语文成绩(正态分布,均值75,标准差10)
chinese_scores = np.random.normal(75, 10, 10).round(1)
# 找出最高分和最低分及其索引
max_score = np.max(chinese_scores)
max_index = np.argmax(chinese_scores)
min_score = np.min(chinese_scores)
min_index = np.argmin(chinese_scores)
print(f"所有成绩: {chinese_scores}")
print(f"最高分: {max_score} (第{max_index}个学生)")
print(f"最低分: {min_score} (第{min_index}个学生)")(三)数组遍历、运算、索引
- 遍历
import numpy as np
scores = np.array([5, 9, 9, 11, 11, 13, 15, 19])
# 等价于 scores = scores + 1
scores += 1
sum = 0
for i in scores: # 遍历数组中的每个元素
sum += i
print(sum)100
- 运算
1. 矩阵乘法:需要满足第一个矩阵的列数等于第二个矩阵的行数,和线代的矩阵乘法算法相同。
2. 矩阵点乘:需要满足两个矩阵的行数和列数相同,然后两个矩阵对应位置的元素相乘。
3. 矩阵转置:将矩阵的行和列互换。
4. 矩阵求逆:需要满足矩阵是方阵且行列式不为0,然后使用伴随矩阵除以行列式得到逆矩阵。
5. 矩阵求行列式:需要满足矩阵是方阵,然后使用代数余子式展开计算行列式。
import numpy as np
a = np.array([[1, 2], [3, 4], [5, 6]])
b = np.array([[7, 8], [9, 10], [11, 12]])
print(a)
print(b)
a @ b.T # 矩阵乘法,3*2的矩阵和2*3的矩阵相乘,得到3*3的矩阵- 索引
- 一维
print("\n一维数组索引:") print(arr1[0]) # 第一个元素 print(arr1[-1]) # 最后一个元素一维数组索引: 1 5 - 二维
print("\n二维数组索引:") print(arr2[0, 1]) # 第一行第二列 print(arr2[:, 1]) # 所有行的第二列二维数组索引: 2 [2 5] - 三维
print("\n三维数组索引:") print(arr3[0, 1, 0]) # 第一个矩阵的第二行第一列 print(arr3[1, :, 0]) # 第二个矩阵的所有行的第一列三维数组索引: 3 [5 7]
- SHAP深入分析
shap_values是一个numpy数组,表示每个特征对每个样本的贡献值。对于以下代码:
shap_values[0,:,:].shape
输出:
(31,2)
#这个对应的是(特征数,类别数目)----每个特征对2个目标类别的shap值贡献
#所以这个值对应的就是这个样本对应的这个特征对2个目标类别的shap值贡献# 三个维度
# 第一个维度是样本数
# 第二个维度是特征数
# 第三个维度是类别数
shap_values.shape输出:(1500, 31, 2)
所以我们对于以下代码就有了更清晰的认识
--- 1. SHAP 特征重要性条形图 (Summary Plot - Bar) ---
print("--- 1. SHAP 特征重要性条形图 ---")
shap.summary_plot(shap_values[:, :, 0], X_test, plot_type="bar",show=False) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()shap.summary_plot中第一个参数是所有样本对预测类别的shap值。
传入的 SHAP 值 (shap_values[:, :, 0]) 和特征数据 (X_test) 在维度上需要高度一致和对应。
- shap_values[:, :, 0] 的每一行代表的是 一个特定样本每个特征对于预测类别的贡献值(SHAP 值),缺乏特征本身的值
- X_test 的每一行代表的也是同一个特定样本的特征值。
这二者组合后,就可以组合(特征数,特征值,shap值)构成shap图的基本元素