一、数据湖核心概念
1. 数据仓库 vs 数据湖
数据仓库:对数据进行存储管理,主要面向数据分析工作,并且存储的是结构化数据。
数据湖:对数据进行存储管理,主要存储所有的业务数据,包括结构化、非结构化、半结构化的数据,主要面向机器学习、数据分析和实时数据处理等工作。
数据库:对数据进行存储管理,主要面向事务数据,并且存储的是结构化数据。

二、主流数据湖框架对比
Delta Lake:与Spark强绑定,使用其它引擎查询Delta时,底层还要跑一个Spark作业,保证事务处理的ACID特性。
Apache Iceberg:专门为对象存储S3设计,以类似于SQL的形式高性能的处理大型的开放式表。
Apache Hudi:强调对HDFS上的存储对象进行Upsert、Delete、Insert操作,并提供时间轴查询(增量数据处理)等功能。
Apache Paimon:强调流式数据湖存储技术(Streaming Lakehouse),旨在解决数据湖管理的挑战,包括数据质量、元数据管理、数据治理等方面的问题。
怎么选?
Delta Lake:当业务需要与Spark进行强绑定的时候,优先考虑使用。
Iceberg:需要高查询性能和云原生存储,优先考虑使用。
Hudi:需要近实时更新和多引擎支持,与高度兼容HDFS,优先考虑使用。
Paimon:当业务需要与Flink进行强绑定的时候,优先考虑使用。
三、Apache Hudi 深度解析
1. 核心特性
ACID事务:基于时间轴(Timeline)保证原子性提交和版本控制。
增量处理:支持增量拉取(Incremental Pull)和增量提交(Delta Commit)。
多模态存储:提供Copy-on-Write(COW)和Merge-on-Read(MOR)两种表类型。
多引擎支持:兼容Spark、Flink、Hive、Trino等查询引擎。
本质:一个数据管理平台,管理分布式文件系统的数据内容,提供了对数据的增删改查操作。
2. 表类型对比
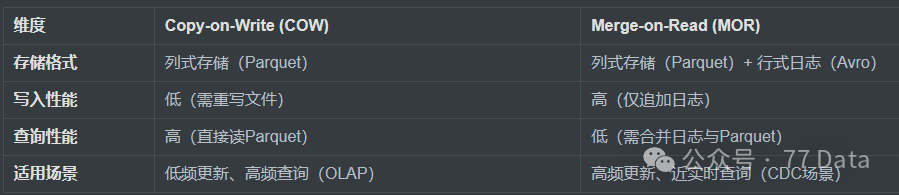
写时复制(Copy on Write):使用列式格式(Parquet)存储数据,适合写少读多的场景。
读时复制(Merge on Read):使用列式+行式文件格式组合(Parquet+Log),适合读多写少的场景。
3. 写入类型详解

Bulk Insert去重说明:默认不处理重复数据,但可通过配置
hoodie.combine.before.insert.enabled=true+write.precombine.field(如时间戳字段)实现去重。
4. Flink集成关键配置
bulk_insert:快速导入快照数据,跳过数据去重。
index bootstrap:确保数据不重复。
changelog mode:保留所有中间变化。
insert mode:每次刷新行为直接写入新的 Parquet 文件。
-- 创建hudi映射表(批)
CREATE TABLE t2(
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/hudi/demo_table',
'table.type' = 'MERGE_ON_READ'
);
-- 创建hudi映射表(流)
CREATE TABLE t2(
)
PARTITIONED BY (`partition`)
WITH (
'connector' = 'hudi',
'path' = 'hdfs://node1:8020/hudi/demo_table',
'table.type' = 'MERGE_ON_READ',
'read.streaming.enabled' = 'true',
'read.start-commit' = '20210316134557',
'read.streaming.check-interval' = '4'
);
5. 核心组件
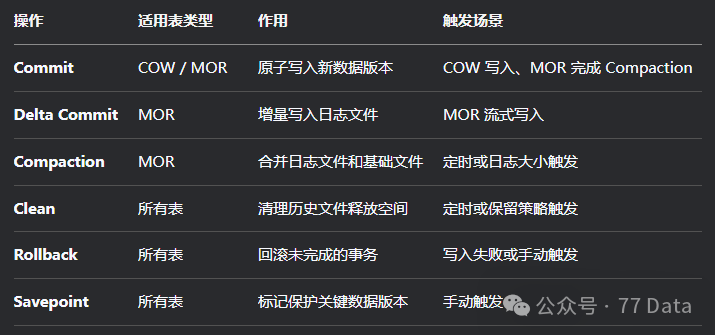
时间轴(Timeline):记录所有操作(Commit、Compaction、Clean)的元数据,提供ACID保障。
文件管理:
分区目录:存储Parquet文件和增量Log文件。
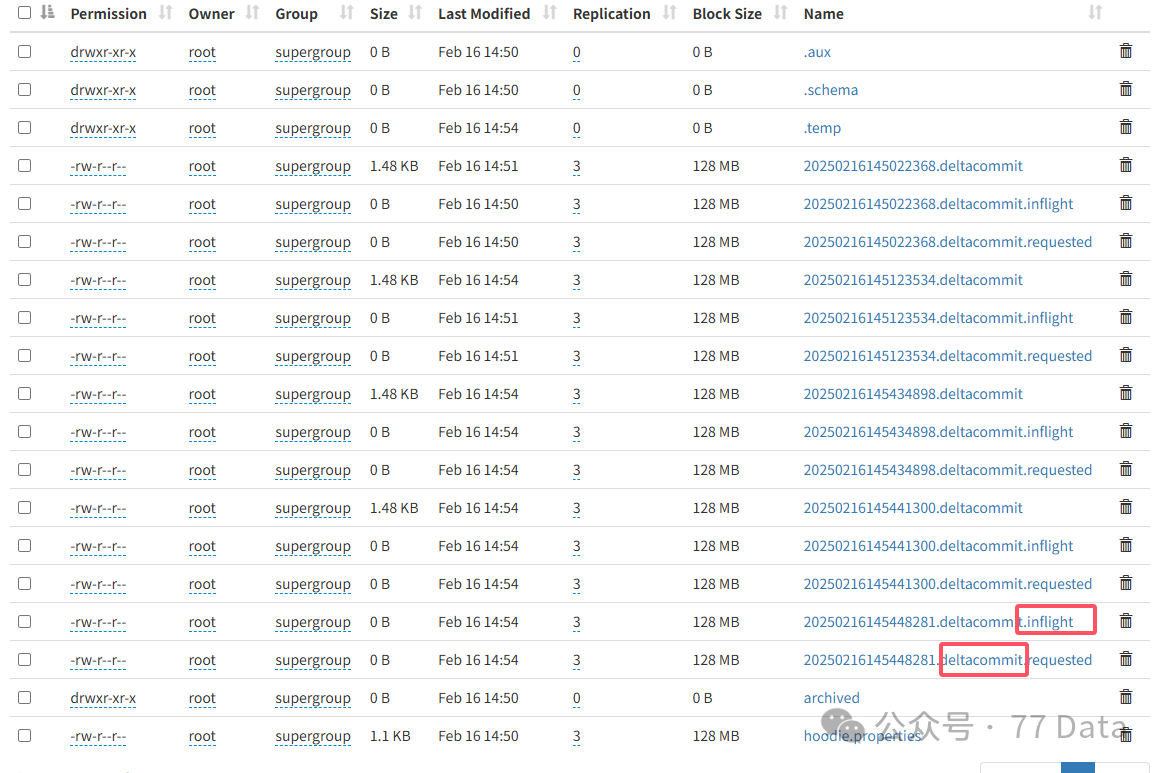
.hoodie目录:记录Instant状态(REQUESTED/INFLIGHT/COMPLETED)。
元数据表(Metadata Table):加速文件索引(如统计文件大小、记录数)。
6.查询类型
快照查询:查询最新快照,动态合并基本文件和增量文件。
增量查询:查询新写入的数据集。
读优化查询:直接查询基本文件。
7.Hudi On Hive
官网链接:Hudi 官方文档
四、Hudi快问快答
基础篇
Hudi的两种表类型(COW和MOR)有什么区别?适用哪些场景?
COW写时复制,使用列式存储,在写入数据的时候,会重新复制一个文件进行写入,适合写少读多的场景,例如历史数据分析。
MOR读时合并,使用行+列式存储,在读取数据的时候,会将行式文件合并到parquet中,动态合并形成列式文件,适合读少写多的场景,例如实时数仓。
1.Bulk Insert和普通Insert的区别是什么?Bulk Insert是否会去重?
Bulk Insert用于海量数据初始化更新,跳过索引检查,性能高,但不会去重
Insert逐条处理,会触发索引去重。
2.Hudi如何实现ACID事务?时间轴(Timeline)的作用是什么?
Hudi会通过将文件操作写入.commit文件和日志WAL文件保证事务的ACID
Timeline将会按时间序列,记录对文件的所有操作,形成元数据,实现版本回溯和增量查询
3.Hudi如何处理小文件问题?Compaction的触发机制是什么?
Hudi会自动合并小文件,也就是archive归档
Compaction会定时触发或基于日志文件大小完成触发
4.时间轴(Timeline)包括哪些核心组件?
Instant Action:commits(提交)、cleans(清理旧文件)、delta_commit(增量提交更新和删除)、compaction(MOR特有的操作,将日志文件.log合并到基础文件parquet中)、rollback(回滚)、savepoint(手动创建保存点,防止Clean操作删除该版本之前的数据)
Instant Time:操作时间
Instant State:操作状态,REQUESTED(已提交)、INFLIGHT(正在执行)、COMPLETED(已完成)
进阶篇
1.Hudi的索引机制有哪些?Bloom索引和HBase索引的优缺点是什么?
索引机制包括Bloom Filter高效内存索引、HBase外部精准索引、Flink状态索引
Bloom高效内存索引:低存储开销,存在假阳性
HBase索引:精准但需维护外部组件
2.如何通过Hudi实现增量查询(Incremental Query)?底层原理是什么?
基于Timeline时间轴记录提交点,查询时过滤commit_time>checkpoint的数据
3.Hudi在Flink中的Exactly-Once语义如何保证?Checkpoint与Hudi提交如何协同?
机制:通过Checkpoint完成时提交事务,保证数据仅提交一次。
协同:通过Checkpoint触发Hudi提交,失败时回滚未完成的任务。Flink Checkpoint驱动Hudi原子提交,通过两阶段表决和状态回滚保证端到端的一致性。
4.Hudi与其它数据湖的核心差异,为什么选择?
Hudi内置索引、支持增量处理(动态更新与删除)、兼容HDFS
实战篇
1.场景题:现有MySQL订单表需要实时同步到Hudi,要求支持订单状态更新和删除,如何设计?
Flink CDC捕捉MySQL binlog日志,Flink Source配置为MySQL订单表,Flink Sink配置为Hudi表。
-- 创建订单表
CREATE TABLE orders (
order_id INT PRIMARY KEY AUTO_INCREMENT, -- 订单ID(自增主键)
user_id INT NOT NULL, -- 用户ID(关联用户表)
order_number VARCHAR(50) NOT NULL UNIQUE, -- 订单号(唯一标识)
order_time DATETIME NOT NULL, -- 下单时间
order_status ENUM('pending', 'paid', 'shipped', 'completed', 'cancelled'), -- 订单状态
total_amount DECIMAL(10, 2) NOT NULL, -- 订单总金额(精确到小数点后两位)
shipping_address TEXT NOT NULL, -- 收货地址
payment_method VARCHAR(20), -- 支付方式(如支付宝、微信、信用卡)
remarks TEXT -- 订单备注(可选)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
-- flink-cdc增量读取MySQL数据
CREATE TABLE mysql_fangpeng_orders_flinkcdc(
order_id INT PRIMARY KEY, -- 主键必须明确指定
user_id INT,
order_number STRING,
order_time TIMESTAMP(0), -- MySQL DATETIME 对应 TIMESTAMP(0)
order_status STRING, -- ENUM 转换为 STRING
total_amount DECIMAL(10,2), -- 金额保持精度
shipping_address STRING, -- TEXT 转换为 STRING
payment_method STRING,
remarks STRING
) WITH (
'connector' = 'mysql-cdc',
'hostname' = '192.168.52.150',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = 'fangpeng',
'table-name' = 'orders',
'scan.startup.mode' = 'initial' -- 可选:首次全量+增量监听
);
-- hudi映射表,同步hive
CREATE TABLE orders_hudi(
order_id INT PRIMARY KEY, -- 主键必须明确指定
user_id INT,
order_number STRING,
order_time TIMESTAMP(0), -- MySQL DATETIME 对应 TIMESTAMP(0)
order_status STRING, -- ENUM 转换为 STRING
total_amount DECIMAL(10,2), -- 金额保持精度
shipping_address STRING, -- TEXT 转换为 STRING
payment_method STRING,
remarks STRING
) WITH (
'connector'='hudi'
,'path'= 'hdfs://node1:8020/hudi/orders'
,'hoodie.datasource.write.recordkey.field'= 'order_id'
,'write.tasks'= '1'
,'compaction.tasks'= '1'
,'write.rate.limit'= '2000'
,'table.type'= 'MERGE_ON_READ'
,'compaction.async.enabled'= 'true'
,'compaction.trigger.strategy'= 'num_commits'
,'compaction.delta_commits'= '1'
,'changelog.enabled'= 'true'
,'read.tasks' = '1'
,'read.streaming.enabled'= 'true'
,'read.start-commit'='earliest'
,'read.streaming.check-interval'= '3'
,'hive_sync.enable'= 'true'
,'hive_sync.mode'= 'hms'
,'hive_sync.metastore.uris'= 'thrift://node1:9083'
,'hive_sync.table'= 'orders_hudi'
,'hive_sync.db'= 'fangpeng'
,'hive_sync.username'= ''
,'hive_sync.password'= ''
,'hive_sync.support_timestamp'= 'true'
);
-- 写入数据
insert into orders_hudi select * from mysql_fangpeng_orders_flinkcdc where total_amount>100;
2.性能优化:Hudi表查询性能下降,可能的原因有哪些?如何排查?
可能原因:小文件数量是否过多、索引是否失效等。
排查机制:检查文件分布、确认Checkpoint状态、验证索引命中率。
3.如何利用Hudi的时间旅行(Time Travel)功能修复错误数据?
查询历史版本(as.of.instant=20230301000000);
定位错误数据,生成修正数据集;
提交覆盖写入(WriteOperationType.INSERT_OVERWRITE)。
欢迎批评指正!!