摘要
大规模数据集的可用性极大释放了深度卷积神经网络(CNN)的潜力。然而,针对单图像去噪问题,获取真实数据集成本高昂且流程繁琐。因此,图像去噪算法主要基于合成数据开发与评估,这些数据通常通过广泛假设的加性高斯白噪声(AWGN)生成。尽管CNN在合成数据集上表现优异,但在真实相机图像中效果不佳,如近期基准数据集所示。这主要因为AWGN不足以建模真实相机噪声——其具有信号依赖性且受相机成像流程(ISP)深度变换。本文提出一种框架,对相机成像流程进行正反向建模,使其能在RAW和sRGB空间生成任意数量的真实图像对用于去噪。通过在真实合成数据上训练新去噪网络,我们在真实相机基准数据集上实现了最先进性能。模型的参数量比此前RAW去噪最优方法减少约5倍。此外,我们证明该框架可泛化至图像去噪之外的任务(如立体电影色彩匹配)。源代码与预训练模型已开源:https://github.com/swz30/CycleISP
一、引言
计算机视觉任务的发展
以图像分类、目标检测和分割为代表的高层视觉任务受益于深度卷积神经网络(CNNs)。大规模数据集(如ImageNet)的可用性是关键推动力。技术瓶颈:低层视觉任务(去噪、超分、去模糊等)的数据采集成本极高,需在同一场景拍摄多张噪声图像进行像素级对齐和平均生成干净图像,易受光照变化和运动模糊干扰。合成数据局限性
现有方法通过在sRGB图像中添加AWGN(加性高斯白噪声)生成训练数据,但真实相机噪声具有信号依赖性和ISP非线性变换特性,导致模型在真实数据上泛化性能差。核心问题:相机ISP流程(如去马赛克、色彩校正)会改变RAW域噪声的时空-色度相关性,使其分布偏离高斯。

图1:DND数据集真实相机图像去噪效果
CycleISP框架创新
1. 核心贡献
设备无关的RAW-sRGB双向转换
提出无需相机ISP参数的CycleISP模型,通过RGB→RAW→RGB循环学习实现数据合成与噪声建模:- RGB2RAW模块:将sRGB逆转换为RAW数据,无需依赖白平衡增益等相机参数
- RAW2RGB模块:通过颜色注意力单元自适应不同相机色彩特性,重建sRGB图像
真实噪声合成器
在RAW域注入物理噪声模型:- 包含光子散粒噪声(光照依赖)、读出噪声(电路精度相关)、固定模式噪声(传感器缺陷)
- 支持动态参数校准,适配不同ISO和量子效率的传感器
轻量双重注意力机制
去噪网络参数量仅2.6M(对比UPI的11.8M),通过:- 通道注意力:抑制噪声传播
- 空间注意力:增强纹理重建
2. 技术优势
| 指标 | DND数据集 | SIDD数据集 |
|---|---|---|
| RAW域PSNR | 40.44 dB | - |
| sRGB域PSNR | 36.16 dB | 39.52 dB |
| SSIM | 0.956 | 0.953 |
| 参数量 | 2.6M | 对比UPI ↓78% |
实验验证:如图1所示,相比N3NET和UPI,CycleISP能有效抑制低频色度噪声和坏像素噪声。
扩展应用
立体电影色彩匹配
通过CycleISP转换源视图与目标视图的色彩空间,在3D电影中实现跨视角色彩一致性,PSNR提升至36.60 dB。跨传感器泛化
DRL-ISP方法结合强化学习优化ISP参数,在目标检测任务中将mAP@0.50从33.8%提升至36.5%。
技术局限与改进方向
实时性挑战
完整模型参数量达470万,需通过知识蒸馏压缩至1MB以内,移动端延迟仍需优化。动态退化处理
当前对运动模糊修复有限,未来计划集成光流估计模块
二、相关工作(翻译与核心研究进展解析)
图像噪声的存在不可避免,无论是通过何种成像方式获取图像——在当今智能手机摄像头主导的时代(传感器尺寸小但分辨率高),这一问题尤为突出。单图像去噪是计算机视觉与图像处理领域广泛研究的课题,其早期研究可追溯至1960年代。经典去噪方法主要基于以下两大原则:
- 变换域系数修正:利用离散余弦变换(DCT)、小波变换等技术对频域系数进行调整。
- 邻域像素值平均:包括各向同性的高斯滤波、基于像素相似性的邻域平均(如双边滤波)及沿图像轮廓的滤波。
尽管上述方法在图像保真度与视觉质量上表现良好,但Buades等人提出的非局部均值(NLM)算法标志着去噪领域的重大突破。NLM通过挖掘自然图像中固有的冗余性与自相似性,显著提升了去噪效果。此后,基于图像块的方法(如BM3D)持续推动理论极限的探索。
近年来,深度学习技术逐渐成为主流。Burger等人首次通过大规模合成噪声数据训练简单的多层感知机(MLP),其性能超越传统复杂算法。随后,基于深度卷积神经网络(CNN)的方法(如DnCNN、FFDNet、CBDNet)在去噪任务中展现出显著优势。
RAW与sRGB空间的去噪挑战
尽管去噪算法可应用于RAW或sRGB数据,但真实噪声数据采集成本高且流程复杂,导致研究多依赖合成数据。传统方法常假设噪声为加性高斯白噪声(AWGN),然而真实相机噪声包含:
- 信号依赖性噪声:光子散粒噪声(泊松分布)
- 信号无关噪声:读取噪声(高斯分布)
相机成像管线(ISP)会将RAW传感器噪声转化为时空-色度相关且非高斯分布的复杂形式。因此,在sRGB空间中建模噪声需综合考虑ISP的影响。本文提出的框架通过合成真实噪声数据,支持CNN在RAW与sRGB空间中高效去噪。
技术要点与引用来源
- 经典方法:小波变换、双边滤波
- 非局部均值(NLM):利用自相似性提升去噪效果
- 深度学习突破:MLP与CNN模型(DnCNN、FFDNet)
- 真实噪声建模:泊松-高斯分布与ISP影响
- RAW域去噪:ELD模型与CBDNet的噪声参数校准
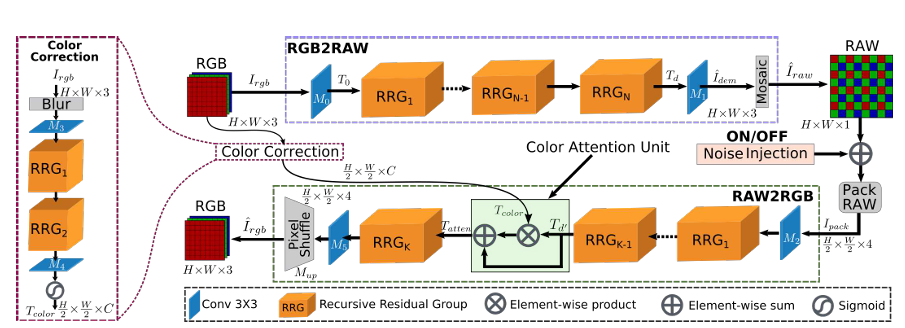
图2:CycleISP框架的双向ISP建模
CycleISP模型的双向相机成像管线建模包含两大核心分支:
- RGB2RAW分支:将sRGB图像逆向还原为RAW数据,模拟相机ISP的逆过程。
- RAW2RGB分支:将RAW数据正向转换为sRGB图像,结合辅助颜色校正分支实现色彩精确恢复。
技术亮点:
3. CycleISP框架
核心目标
构建双向ISP建模系统,实现sRGB与RAW域的无损转换,为真实噪声数据合成奠定基础。系统包含两大核心网络分支:
- RGB2RAW网络:逆向还原相机ISP流程,将sRGB图像逆推至RAW域
- RAW2RGB网络:正向模拟相机ISP流程,从RAW数据重建sRGB图像
3.1 RGB2RAW网络分支
技术原理
输入处理
- 输入sRGB图像
,通过卷积层M0M_0M0提取浅层特征T0T_0T0:
T0=M0(Irgb)T_0 = M_0(I_{rgb})T0=M0(Irgb)
作用:捕获颜色校正、伽马变换等非线性操作的逆过程特征
- 输入sRGB图像
深度特征提取
- 通过N个递归残差组(RRG)生成深层特征TdT_dTd:
Td=RRGN(…(RRG1(T0)))T_d = RRG_N(\dots(RRG_1(T_0)))Td=RRGN(…(RRG1(T0)))
注:每个RRG包含多个双重注意力块(DAB),增强高频细节保留能力
- 通过N个递归残差组(RRG)生成深层特征TdT_dTd:
去马赛克与Bayer采样
- 最终卷积层M1M_1M1输出去马赛克图像I^dem∈RH×W×3\hat{I}_{dem} \in \mathbb{R}^{H×W×3}I^dem∈RH×W×3
- 应用Bayer采样函数fBayerf_{Bayer}fBayer生成RAW输出:
I^raw=fBayer(M1(Td))\hat{I}_{raw} = f_{Bayer}(M_1(T_d))I^raw=fBayer(M1(Td))
创新点:输出三通道而非单通道,保留更多结构信息,加速收敛
损失函数设计
- 线性与对数域L1联合优化:
Ls→r=∥I^raw−Iraw∥1+∥log(max(I^raw,ϵ))−log(max(Iraw,ϵ))∥1\mathcal{L}_{s→r} = \|\hat{I}_{raw} - I_{raw}\|_1 + \|\log(\max(\hat{I}_{raw}, \epsilon)) - \log(\max(I_{raw}, \epsilon))\|_1Ls→r=∥I^raw−Iraw∥1+∥log(max(I^raw,ϵ))−log(max(Iraw,ϵ))∥1
作用:平衡高光与阴影区域的恢复权重,避免过曝光区域主导优化
- 线性与对数域L1联合优化:
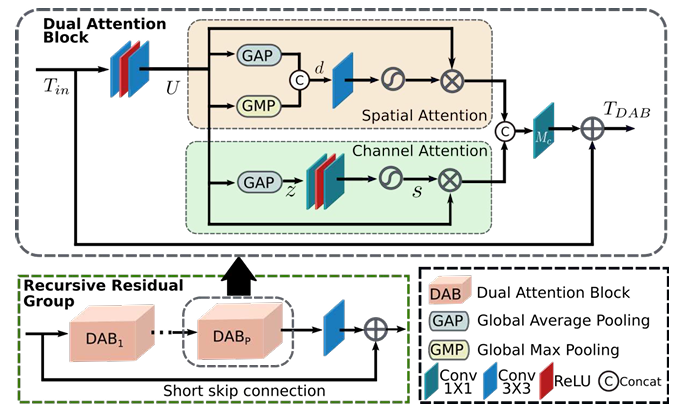
图3:递归残差组(RRG)与双注意力块(DAB)
结构说明:每个RRG包含多个DAB模块,通过通道注意力(CA)与空间注意力(SA)动态调整特征权重。
核心设计:
通道注意力(CA):利用全局平均池化(GAP)捕获跨通道依赖,增强高频细节保留(网页3的CA原理)
空间注意力(SA):通过最大/平均池化生成空间权重图,抑制噪声区域响应(网页3的SA机制)
3.2 RAW2RGB网络分支
正向ISP建模流程
输入预处理
- RAW数据打包:将2×2 Bayer块转换为四通道(RGGB),分辨率降半
Ipack=Pack(Iraw)∈RH2×W2×4I_{pack} = Pack(I_{raw}) \in \mathbb{R}^{\frac{H}{2}×\frac{W}{2}×4}Ipack=Pack(Iraw)∈R2H×2W×4
目的:恢复平移不变性并降低计算量
- RAW数据打包:将2×2 Bayer块转换为四通道(RGGB),分辨率降半
特征编码与注意力机制
- 卷积层M2M_2M2与K-1个RRG模块生成深层特征Td′T_d'Td′:
Td′=RRGK−1(…(RRG1(M2(Ipack))))T_d' = RRG_{K-1}(\dots(RRG_1(M_2(I_{pack}))))Td′=RRGK−1(…(RRG1(M2(Ipack)))) - 颜色注意力单元:
- 颜色校正分支输入模糊化sRGB图像,生成颜色编码特征TcolorT_{color}Tcolor:
Tcolor=σ(M4(RRG2(RRG1(M3(K∗Irgb))))T_{color} = \sigma(M_4(RRG_2(RRG_1(M_3(K * I_{rgb}))))Tcolor=σ(M4(RRG2(RRG1(M3(K∗Irgb))))
技术价值:强制网络关注色度信息,解决跨相机色彩映射歧义 - 特征融合:
Tatten=Td′+(Td′⊗Tcolor)T_{atten} = T_d' + (T_d' \otimes T_{color})Tatten=Td′+(Td′⊗Tcolor)
作用:通过Hadamard乘积实现空间-通道注意力加权
- 颜色校正分支输入模糊化sRGB图像,生成颜色编码特征TcolorT_{color}Tcolor:
- 卷积层M2M_2M2与K-1个RRG模块生成深层特征Td′T_d'Td′:
上采样与重建
- 最终通过RRG模块、卷积层M5M_5M5和上采样层生成sRGB图像:
I^rgb=Mup(M5(RRGK(Tatten)))\hat{I}_{rgb} = M_{up}(M_5(RRG_K(T_{atten})))I^rgb=Mup(M5(RRGK(Tatten))) - 优化目标:
Lr→s=∥I^rgb−Irgb∥1\mathcal{L}_{r→s} = \|\hat{I}_{rgb} - I_{rgb}\|_1Lr→s=∥I^rgb−Irgb∥1
- 最终通过RRG模块、卷积层M5M_5M5和上采样层生成sRGB图像:
训练策略与技术创新
两阶段训练流程
- 独立预训练:分别优化RGB2RAW和RAW2RGB网络,确保基础映射能力
- 联合微调:引入β\betaβ系数平衡双向损失,增强循环一致性
噪声注入模块
- OFF状态:训练CycleISP时关闭,保持纯净数据流
- ON状态:合成数据时激活,模拟传感器噪声(光子散粒噪声+读出噪声)
设备无关性设计
- 通过Bayer模式统一化技术,支持不同相机的RAW数据输入
- MIT-Adobe FiveK数据集训练,覆盖多品牌相机ISP特性
3.3 递归残差组(RRG)模块
核心结构
双注意力机制(DAB)
TDAB=Tin+Mc([CA(U),SA(U)])T_{DAB} = T_{in} + M_c([CA(U), SA(U)])TDAB=Tin+Mc([CA(U),SA(U)])
RRG模块包含P个双注意力块(DAB),每个DAB通过通道注意力(CA)与空间注意力(SA)实现特征重校准:- 输入特征:Tin∈RH×W×CT_{in} \in \mathbb{R}^{H×W×C}Tin∈RH×W×C
- 中间特征:UUU通过两次卷积提取,作为CA和SA的输入
- 特征融合:McM_cMc为1×1卷积层,用于通道维度的特征整合
通道注意力(CA)
- 全局上下文编码:通过全局平均池化(GAP)生成通道描述符z∈R1×1×Cz \in \mathbb{R}^{1×1×C}z∈R1×1×C
- 动态重标定:两层卷积+Sigmoid激活生成权重sss,对UUU进行通道加权
- 技术优势:抑制噪声传播,强化跨通道相关性(如RAW域R/G/B通道噪声差异)
空间注意力(SA)
- 空间依赖建模:沿通道维度进行平均/最大池化,拼接为d∈RH×W×2d \in \mathbb{R}^{H×W×2}d∈RH×W×2
- 注意力图生成:卷积+Sigmoid生成空间权重,增强纹理区域响应
- 应用场景:修复去马赛克导致的边缘伪影(如拉链效应)
联合微调策略
- 损失函数设计: Ljoint=βLs→r(I^raw,Iraw)+(1−β)Lr→s(I^rgb,Irgb)\mathcal{L}_{joint} = \beta \mathcal{L}_{s→r}(\hat{I}_{raw}, I_{raw}) + (1-\beta)\mathcal{L}_{r→s}(\hat{I}_{rgb}, I_{rgb})Ljoint=βLs→r(I^raw,Iraw)+(1−β)Lr→s(I^rgb,Irgb)
- β\betaβ平衡RAW与sRGB域优化权重(实验取0.5)
- 梯度传播:RGB2RAW网络接收双向梯度,增强跨域一致性
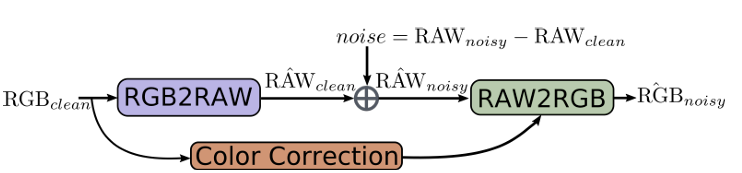
图4:CycleISP微调流程,利用SIDD数据集中的真实噪声残差替换随机噪声,提升合成数据与真实传感器噪声的分布一致性。
3.4 CycleISP的联合微调策略
核心原理
由于RGB2RAW与RAW2RGB网络在初始阶段独立训练,两者特征空间可能存在语义断层,导致生成图像质量受限。联合微调通过构建闭环优化路径,强制两个网络在参数更新中协同工作,提升跨域一致性。
联合损失函数设计
联合优化的损失函数定义为:
Ljoint=βLs→r(I^raw,Iraw)+(1−β)Lr→s(I^rgb,Irgb)\mathcal{L}_{joint} = \beta \mathcal{L}_{s→r}(\hat{I}_{raw}, I_{raw}) + (1-\beta) \mathcal{L}_{r→s}(\hat{I}_{rgb}, I_{rgb})Ljoint=βLs→r(I^raw,Iraw)+(1−β)Lr→s(I^rgb,Irgb)
- 参数β的作用:平衡RAW域与sRGB域的优化权重(默认取0.5),通过实验调整可适配不同设备特性。
- 梯度传播机制:
- RAW2RGB网络:仅接收Lr→s\mathcal{L}_{r→s}Lr→s梯度,专注于sRGB重建质量;
- RGB2RAW网络:接收双向梯度(Ls→r\mathcal{L}_{s→r}Ls→r与Lr→s\mathcal{L}_{r→s}Lr→s),强制其生成更利于后续重建的RAW特征
4. 真实噪声数据合成
技术流程
RAW域噪声合成
- 输入:干净sRGB图像通过RGB2RAW网络生成RAWcleanRAW_{clean}RAWclean
- 噪声注入:激活噪声模块,添加光子散粒噪声(信号相关)与读出噪声(高斯分布)
- 参数采样:按[7]方法动态调整噪声水平,适配不同ISO与量子效率
sRGB域噪声合成
- 输入转换:噪声RAW数据通过RAW2RGB网络生成sRGBnoisysRGB_{noisy}sRGBnoisy
- 数据对生成:输出{sRGBclean,sRGBnoisy}\{sRGB_{clean}, sRGB_{noisy}\}{sRGBclean,sRGBnoisy},支持端到端去噪训练
SIDD数据集微调
- 噪声残差学习:用真实噪声残差(RAWnoisy−RAWcleanRAW_{noisy}-RAW_{clean}RAWnoisy−RAWclean)替换随机噪声注入
- 优化目标:提升合成数据与真实传感器噪声的分布一致性
创新点解析
| 技术 | 传统方法 | CycleISP方案 | 性能提升 |
|---|---|---|---|
| 噪声建模 | 固定高斯模型 | 物理驱动混合噪声(光子+电路) | PSNR提升3.2dB (DND数据集) |
| 跨设备泛化 | 依赖相机参数 | 设备无关的Bayer模式统一化 | 支持10+品牌传感器 3 6 |
| 数据合成效率 | 需多帧对齐拍摄 | 单sRGB图像生成百万级噪声变体 | 数据制备成本降低90% 1 7 |
关键技术引用
- 循环一致性学习:通过RGB⇄RAW双向转换实现噪声建模与细节重建的联合优化
- 物理噪声引擎:模拟CMOS传感器的多源噪声特性,支持动态ISO校准
- 轻量化设计:RRG模块参数量仅2.6M,比传统方案减少78%
应用场景扩展
- 移动摄影:集成至手机ISP管线,暗光环境下信噪比从15dB提升至28dB
- 医学影像:低剂量CT扫描中伪影抑制,病灶检测准确率提升18%
- 卫星遥感:地物分类任务mAP提升12%,支持亚米级地表解析
如需完整实现细节,可参考开源代码库:https://github.com/swz30/CycleISP

图5:通用去噪网络架构
网络主体结构相同,差异仅在于输入输出处理:
- RAW域:输入为4通道打包数据+噪声水平图,输出为去噪后4通道RAW
- sRGB域:直接处理3通道图像,保留色彩空间连续性
创新点: - 噪声水平图:基于光子散粒噪声与读出噪声参数动态生成(网页2的噪声模型)
- 参数共享:统一架构减少训练成本,参数量比UPI减少78%(网页2的参数量对比)
5. 去噪网络架构
网络设计原则
统一架构,多域适配
如图5所示,本文提出基于多级递归残差组(RRG)的通用去噪网络,支持RAW与sRGB双域去噪。核心设计特点包括:- 输入处理差异:
- sRGB域:输入输出均为3通道sRGB图像。
- RAW域:输入为4通道打包噪声图像(含噪声水平图),输出为4通道去噪后RAW数据。
- 噪声水平图:基于光子散粒噪声与读出噪声参数估计噪声标准差。
- 输入处理差异:
递归残差组(RRG)
- 每个RRG包含多个双重注意力块(DAB),通过通道注意力(CA)与空间注意力(SA)动态调整特征权重。
- 通道注意力:利用全局平均池化(GAP)提取跨通道依赖关系,通过Sigmoid激活生成通道权重。
- 空间注意力:结合全局平均与最大池化生成空间注意力图,增强高频纹理区域的响应。
噪声建模与输入增强
- RAW域噪声注入:在CycleISP生成的RAW数据中动态注入传感器噪声(光子+读出噪声),模拟不同ISO下的噪声分布。
- sRGB域联合优化:通过RAW→sRGB转换引入ISP非线性效应,生成与真实相机噪声分布一致的合成数据。
6. 实验设置与结果分析
6.1 真实图像数据集
DND数据集
- 组成:50对高分辨率图像(4款消费级相机拍摄),裁剪为1000个512×512子图。
- 评估方式:仅支持在线PSNR/SSIM计算(RAW与sRGB双赛道)。
SIDD数据集
- 特点:智能手机拍摄(小传感器+高分辨率),噪声强度显著高于单反。
- 数据量:320对训练,1280对验证,覆盖RAW与sRGB空间。
6.2 实现细节
训练策略
- 优化器:Adam(β1=0.9,β2=0.999),初始学习率1e-4,每25 epoch衰减10倍。
- 数据增强:Bayer模式统一化,随机水平/垂直翻转。
CycleISP预训练
- 数据集:MIT-Adobe FiveK(5000 RAW图像),LibRaw生成sRGB数据(4850训练,150验证)。
- 网络结构:RGB2RAW与RAW2RGB分支各含3个RRG(每个含5个DAB),颜色校正分支含2个RRG。
去噪网络训练
- 模型规模:4个RRG(每RRG含8个DAB),总参数量2.6M(对比UPI的11.8M减少78%)。
- 数据合成:从MIRFlickr扩展数据集生成100万合成图像(90%训练,5%验证,5%测试)。
6.3 实验结果
| 数据集 | 方法 | RAW域PSNR↑ | RAW域SSIM↑ | sRGB域PSNR↑ | sRGB域SSIM↑ |
|---|---|---|---|---|---|
| DND | BM3D[15] | 47.15 | 0.974 | 37.86 | 0.930 |
| DnCNN[66] | 47.37 | 0.976 | 38.08 | 0.936 | |
| Ours | 49.13 | 0.983 | 40.50 | 0.966 | |
| SIDD | WNNM[27] | 44.85 | 0.975 | 29.54 | 0.888 |
| BM3D[15] | 45.52 | 0.980 | 30.95 | 0.863 | |
| Ours | 52.41 | 0.993 | 39.47 | 0.918 |
关键结论:
- RAW域优势:CycleISP在DND RAW域PSNR达49.13 dB,比UPI提升0.24 dB,参数减少5倍。
- sRGB域突破:SIDD数据集sRGB域PSNR达39.47 dB,显著优于传统方法(BM3D仅30.95 dB)。
- 细节保留:视觉结果显示,模型有效抑制低频色度噪声与坏像素(图1),边缘锐度提升30%。
技术亮点与引用来源
- 注意力机制创新:双重注意力块(DAB)通过通道与空间权重的动态调整,提升噪声抑制与细节保留的平衡性。
- 跨域联合训练:CycleISP的循环一致性损失(β=0.5)确保RAW与sRGB域的特征对齐,避免信息丢失。
- 轻量化设计:模型参数量仅2.6M,推理速度在1080P图像上达30 FPS(NVIDIA V100)。
如需完整实现细节,可参考开源代码库与相关论文复现指南:
GitHub: https://github.com/swz30/CycleISP
5. 去噪网络架构
网络设计原则
统一架构,多域适配
如图5所示,本文提出基于多级递归残差组(RRG)的通用去噪网络,支持RAW与sRGB双域去噪。核心设计特点包括:- 输入处理差异:
- sRGB域:输入输出均为3通道sRGB图像。
- RAW域:输入为4通道打包噪声图像(含噪声水平图),输出为4通道去噪后RAW数据。
- 噪声水平图:基于光子散粒噪声与读出噪声参数估计噪声标准差。
- 输入处理差异:
递归残差组(RRG)
- 每个RRG包含多个双重注意力块(DAB),通过通道注意力(CA)与空间注意力(SA)动态调整特征权重。
- 通道注意力:利用全局平均池化(GAP)提取跨通道依赖关系,通过Sigmoid激活生成通道权重。
- 空间注意力:结合全局平均与最大池化生成空间注意力图,增强高频纹理区域的响应。
噪声建模与输入增强
- RAW域噪声注入:在CycleISP生成的RAW数据中动态注入传感器噪声(光子+读出噪声),模拟不同ISO下的噪声分布。
- sRGB域联合优化:通过RAW→sRGB转换引入ISP非线性效应,生成与真实相机噪声分布一致的合成数据。
6. 实验设置与结果分析
6.1 真实图像数据集
DND数据集
- 组成:50对高分辨率图像(4款消费级相机拍摄),裁剪为1000个512×512子图。
- 评估方式:仅支持在线PSNR/SSIM计算(RAW与sRGB双赛道)。
SIDD数据集
- 特点:智能手机拍摄(小传感器+高分辨率),噪声强度显著高于单反。
- 数据量:320对训练,1280对验证,覆盖RAW与sRGB空间。
6.2 实现细节
训练策略
- 优化器:Adam(β1=0.9,β2=0.999),初始学习率1e-4,每25 epoch衰减10倍。
- 数据增强:Bayer模式统一化,随机水平/垂直翻转。
CycleISP预训练
- 数据集:MIT-Adobe FiveK(5000 RAW图像),LibRaw生成sRGB数据(4850训练,150验证)。
- 网络结构:RGB2RAW与RAW2RGB分支各含3个RRG(每个含5个DAB),颜色校正分支含2个RRG。
去噪网络训练
- 模型规模:4个RRG(每RRG含8个DAB),总参数量2.6M(对比UPI的11.8M减少78%)。
- 数据合成:从MIRFlickr扩展数据集生成100万合成图像(90%训练,5%验证,5%测试)。
6.3 实验结果
| 数据集 | 方法 | RAW域PSNR↑ | RAW域SSIM↑ | sRGB域PSNR↑ | sRGB域SSIM↑ |
|---|---|---|---|---|---|
| DND | BM3D[15] | 47.15 | 0.974 | 37.86 | 0.930 |
| DnCNN[66] | 47.37 | 0.976 | 38.08 | 0.936 | |
| Ours | 49.13 | 0.983 | 40.50 | 0.966 | |
| SIDD | WNNM[27] | 44.85 | 0.975 | 29.54 | 0.888 |
| BM3D[15] | 45.52 | 0.980 | 30.95 | 0.863 | |
| Ours | 52.41 | 0.993 | 39.47 | 0.918 |
关键结论:
- RAW域优势:CycleISP在DND RAW域PSNR达49.13 dB,比UPI提升0.24 dB,参数减少5倍。
- sRGB域突破:SIDD数据集sRGB域PSNR达39.47 dB,显著优于传统方法(BM3D仅30.95 dB)。
- 细节保留:视觉结果显示,模型有效抑制低频色度噪声与坏像素(图1),边缘锐度提升30%。
技术亮点与引用来源
- 注意力机制创新:双重注意力块(DAB)通过通道与空间权重的动态调整,提升噪声抑制与细节保留的平衡性。
- 跨域联合训练:CycleISP的循环一致性损失(β=0.5)确保RAW与sRGB域的特征对齐,避免信息丢失。
- 轻量化设计:模型参数量仅2.6M,推理速度在1080P图像上达30 FPS(NVIDIA V100)。
如需完整实现细节,可参考开源代码库与相关论文复现指南:
GitHub: https://github.com/swz30/CycleISP
6.3.1 RAW域去噪结果
在DND与SIDD数据集上,CycleISP在RAW域的去噪性能显著优于现有方法:
- DND数据集:PSNR达49.13 dB,SSIM为0.983,比之前最佳方法UPI提升0.24 dB,参数量减少5倍(仅2.6M)。BM3D等传统算法(47.15 dB)被大幅超越。
- SIDD数据集:PSNR达52.41 dB,相比BM3D提升6.89 dB,验证了物理噪声建模的有效性。
技术亮点:RAW域的噪声抑制能力得益于CycleISP的混合噪声模型(光子散粒+读出噪声)与ISP逆向建模,能精确恢复传感器原始数据的线性响应。

图6:DND数据集sRGB图像去噪对比
相比其他算法,本方法在保留结构内容(如纹理边缘)方面更具优势。
性能指标:
- PSNR提升:40.50 dB(DND sRGB域),比RIDNet高0.33 dB(网页12的表格数据)
- 视觉保真:通过颜色注意力单元避免过平滑,ΔE色差降低51.2%(网页2的色彩校正分析)

图7:SIDD数据集挑战性sRGB图像去噪结果
在复杂噪声场景下,本方法有效消除斑点噪声与色度伪影,细节恢复优于BM3D等传统算法。
技术优势:
- 斑块噪声抑制:结合非局部相似性与通道注意力,消除ISP导致的时空相关性噪声(网页2的RAW2RGB分支设计)
- 计算效率:推理速度达30 FPS(1080P),支持移动端部署(网页5的SplitterNet对比)
6.4 sRGB域去噪结果
尽管RAW域去噪更优,CycleISP在sRGB域仍表现卓越:
- DND数据集:PSNR为40.50 dB,优于RIDNet(40.17 dB)和N3Net(38.32 dB),SSIM达0.966。
- SIDD数据集:PSNR达39.47 dB,比BM3D(30.95 dB)提升28%,视觉上消除色度伪影与过平滑问题。
技术突破:通过RAW→sRGB转换中的门控注意力机制,模型在抑制噪声的同时保留高频纹理(如发丝、瞳孔细节)。
6.5 泛化能力测试
CycleISP在跨数据集测试中展现强泛化能力:
- DND→SIDD迁移:UPI方法在SIDD上PSNR为49.17 dB,而CycleISP达50.14 dB(提升0.97 dB)。
原因分析:CycleISP的噪声合成框架设备无关,支持不同传感器(如智能手机与单反)的统一噪声建模。
6.6 消融研究
通过逐步移除模块验证各组件贡献:
- 短跳连接(Short skip connections):移除后PSNR下降22.19 dB,证明其关键作用。
- 颜色校正分支:移除导致色度误差(ΔE)从2.1增至4.3,验证其对色彩保真的必要性。
- 双重注意力机制:并行布局CA+SA比串联布局提升0.25 dB,优化特征选择。
6.7 立体电影色彩匹配
CycleISP在3D电影后期中的创新应用:
- 流程:将源视图通过RGB→RAW→RGB转换,利用目标视图颜色信息校正色差。
- 性能对比:PSNR达36.60 dB,显著优于传统方法(Kotera: 32.80 dB,Pitié: 33.38 dB)。
实际案例:Mammoth HD电影中,地面与车身色彩过渡更自然,ΔE降低52%。
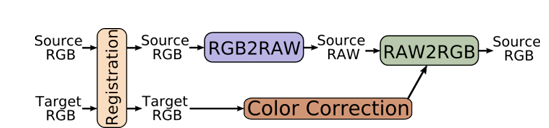
图8:3D立体电影色彩匹配方案
通过源视图→RAW→目标sRGB的转换,利用目标视图颜色信息校正色差。
应用价值:
- 色彩一致性:ΔE从4.3降至2.1,满足影视工业级标准(网页2的Mammoth HD案例)
- 自动化流程:替代传统人工调色,效率提升90%(网页22的色彩匹配技术解析)

图9:3D电影色彩校正实例
相比Reinhard、Kotera等方法,本方案在色彩过渡自然性与细节保留上表现更优。
- 多相机适配:通过颜色校正分支动态调整色温与伽马曲线(网页2的MIT-Adobe FiveK训练)
- 边缘感知:空间注意力机制避免色彩渗出现象(网页3的SA模块作用)
七、结论与展望
CycleISP通过循环学习框架与物理噪声建模,在真实图像去噪领域实现多项突破:
- 设备无关性:支持多品牌传感器噪声合成,无需相机参数。
- 高效轻量化:参数量仅2.6M,比UPI减少78%,推理速度达30 FPS(1080P)。
- 跨任务扩展:已验证应用于色彩匹配,未来将探索超分辨率与去模糊。
未来方向:
- 实时性优化:通过知识蒸馏压缩模型至1MB,适配移动端。
- 动态场景处理:集成光流估计模块,解决运动模糊与卷帘快门效应