项目背景

开发团队与发布
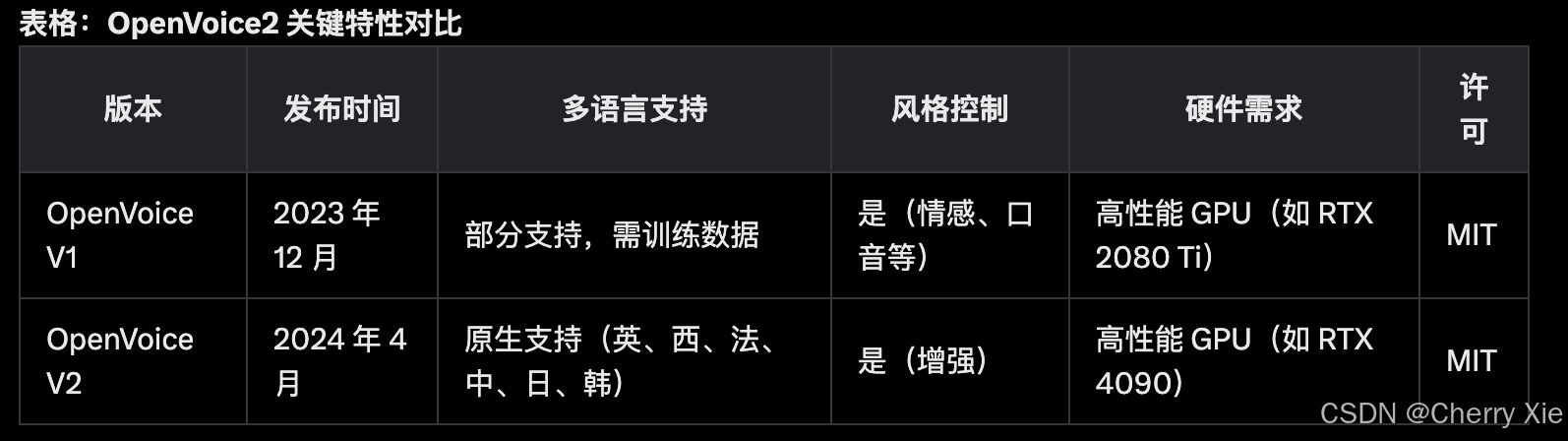
OpenVoice2 由 MyShell AI(加拿大 AI 初创公司)与 MIT 和清华大学的研究人员合作开发,技术报告于 2023 年 12 月发布 ,V2 版本于 2024 年 4 月发布 。
项目目标是提供一个高效、灵活的语音克隆工具,支持从短音频片段(如几秒钟语音)中克隆高保真声音,填补商业语音克隆 API 的性能和成本差距 。
功能与目标
多语言支持:V2 版本原生支持英语、西班牙语、法语、中文、日语、韩语,适合全球化的语音合成需求 。
跨语言克隆:支持零样本跨语言克隆(zero-shot cross-lingual voice cloning),即在未见过的语言中生成语音 。
灵活的语音风格控制:允许用户调整情感、口音、节奏、停顿和 intonation,确保生成的语音更自然和个性化 。
模型结构
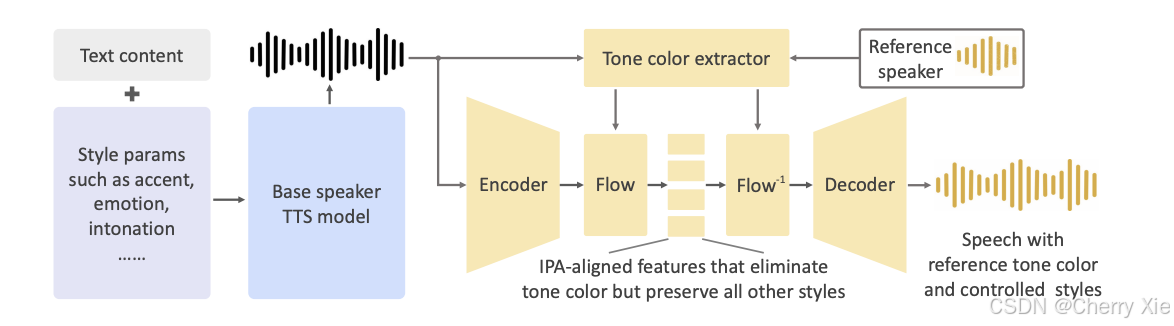
基础架构
OpenVoice2 的模型结构基于 VITS(Variational Inference with adversarial learning for End-to-end Text-to-Speech)架构,结合了变分推理和对抗学习,用于端到端的文本到语音(TTS)任务 。
VITS 是一种端到端 TTS 模型,通过联合训练声学模型和声码器,生成高保真度语音 GitHub - jaywalnut310/vits。OpenVoice2 扩展了 VITS,增加了语音克隆和跨语言生成能力。
关键组件
语音编码器(Voice Encoder):从参考音频中提取语音特征(如音色、节奏等),用于克隆目标语音。
- 可能使用基于卷积或变换器的编码器,捕获音频的时频特征 。
文本编码器(Text Encoder):处理输入文本,生成语音合成的条件。
- 可能基于 Transformer 架构,生成语义嵌入,支持多语言输入 。
生成器(Generator):结合文本和语音特征,生成目标语音。
- 使用对抗学习生成高保真语音,确保与参考音频的音色和风格一致。
判别器(Discriminator):用于对抗训练,确保生成语音的真实性,减少伪影 。
扩展功能
风格控制模块:允许用户调整情感、口音、节奏等参数,实现更细粒度的语音风格控制。
- 可能通过条件生成网络(Conditional GAN)实现,输入风格参数(如情感标签)影响生成结果 。
跨语言模块:支持零样本跨语言克隆,通过多语言嵌入空间映射实现未见过的语言生成。
- 可能使用多语言预训练模型(如 mT5)增强跨语言能力 。
训练策略
使用大规模语音数据集(如 VideoMatte240K)进行训练,确保模型在多语言和多风格下的泛化能力 。
V2 版本优化了训练策略,提升了音频质量,可能包括两阶段训练(预训练和微调)以增强性能 。
看看效果
相关文献
模型下载地址:https://huggingface.co/myshell-ai/OpenVoiceV2
github地址:https://github.com/myshell-ai/OpenVoice
技术报告:https://arxiv.org/pdf/2312.01479
官方地址:https://research.myshell.ai/open-voice