----->更多内容,请移步“鲁班秘笈”!!<-----
通过内存缓冲+轮次压缩解决上下文记忆和效率矛盾,通过外部激活模型实现主动性,是StreamBridge 的关键创新点
传统的视频大语言模型 (Video-LLM)通常一次性处理整个视频,对实时输入支持不足。然而在机器人、无人驾驶等应用中,需要模型具有因果感知和动态反应能力,即能够在视频流不断到来时及时理解新内容并主动输出。
StreamBridge提出了一个简单有效的框架,将现有的离线Video-LLM缝升级为可处理流式视频的系统。它针对流式场景中的两大核心挑战:(1) 多轮实时理解:模型需要持续跟踪最近视频帧,同时结合历史上下文多轮交互;(2) 主动响应生成:模型应当主动监控视频流,在关键时刻生成回应,而不必等待用户明确提问。
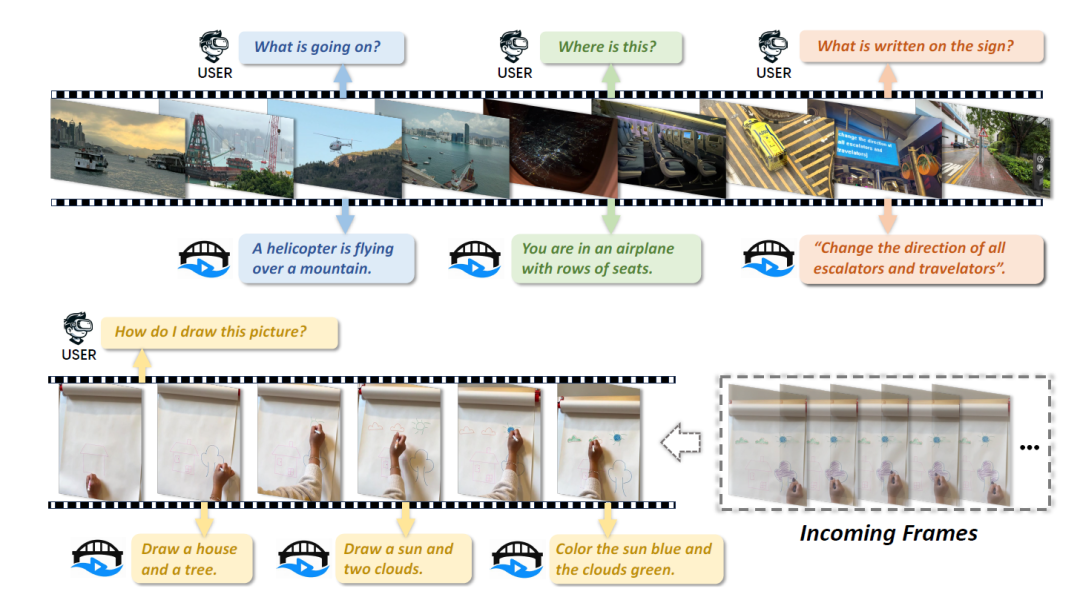
上图为流式视频理解场景示例。上面的部分为多轮交互模式,用户在不同时间点提问;下面展示了主动响应模式,模型根据视频内容主动输出。在上方示例中,用户在视频播放过程中多次提问,每轮关注最近的视频段并结合历史信息进行回答;在下方示例中,助手无需提示,通过绘画过程的展开主动输出指导性反馈。

三大配方
StreamBridge旨在弥合离线与流式之间的鸿沟,使预训练视频模型在上述场景中表现出色。StreamBridge 框架与关键技术: 为实现流式理解,StreamBridge在已有Video-LLM基础上引入了三大组件:
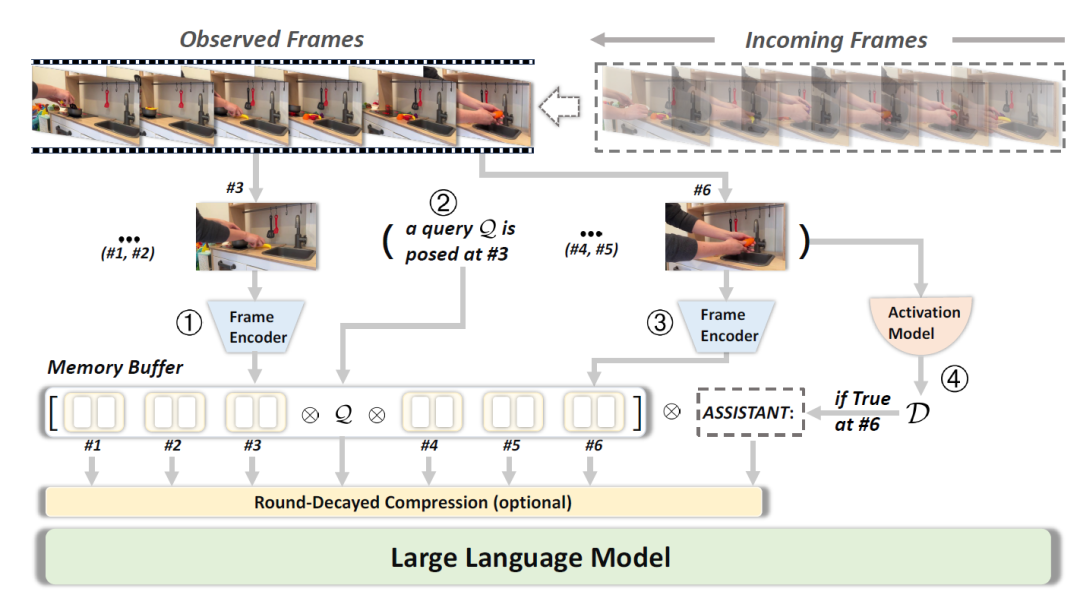
1)内存缓冲 (Memory Buffer): 对每一帧图像,系统首先通过视觉编码器提取嵌入向量,并连同任何生成的文本嵌入向量存入内存缓冲区。当收到用户查询Q且激活模型 (Activation Model)发出明确的触发信号D时,缓冲区中的视觉和文本嵌入被展开成序列输入LLM生成回答。生成的回答R也会追加到缓冲区,以保留完整的多轮交互历史。这样,StreamBridge能够累积上下文,不断扩展对话历史而不丢失前文信息。
2)轮次衰减压缩 (Round-Decayed Compression):
随着视频流时间增长,缓冲区内嵌入序列长度会不断增加。为避免过长输入带来的计算和延迟问题,StreamBridge 设计了轮次衰减压缩策略。具体来说,系统预设最大允许长度MaxLen,若当前输入超过该阈值,则从最早的对话轮开始,对视觉嵌入逐帧进行平均池化合并,直至序列长度在MaxLen之内。这一策略能减少传递给LLM的信息量,同时保留了与当前回答最相关的近期视觉上下文。
3)激活模型 (Activation Model):
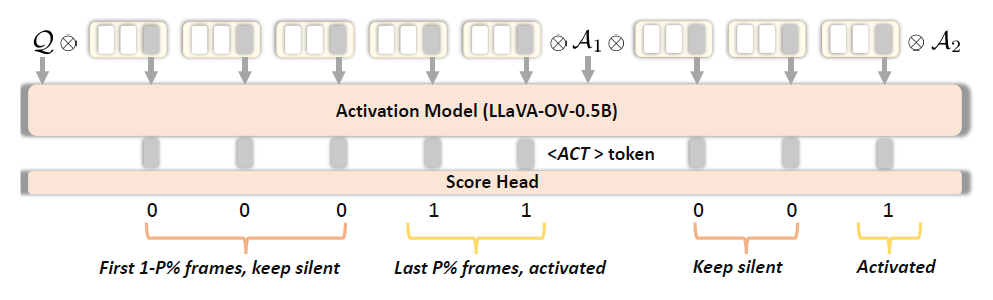
为了实现主动响应,StreamBridge引入了一个解耦的、轻量级的激活子模型。该激活模型本质上是一个独立的小型多模态LLM,它在每个时间步依据当前帧(及可选的查询Q)预测是否需要触发主模型输出。具体地,在训练时向每帧视觉嵌入添加可学习的激活标记,并将该帧的最新激活标记输入激活模型的二分类头预测响应概率。若预测分数超过阈值alpha,则激活信号D为真,主Video-LLM将基于缓冲区内容生成回答。通过这一机制,StreamBridge可以及时响应关键信号,在无需明确提问的情况下主动输出结果,从而体现出类似人类的主动行为。
StreamBridge的本次研究的核心贡献在于一方面它给出了一个通用的解决方案,将任何预训练的离线Video-LLM快速适配到流式理解场景,无需全盘重训,仅需额外添加上述轻量组件即可。原模型的离线视频理解能力得到保留,且同时具备了多轮交互和主动输出的能力。
另一方面,StreamBridge组建了一个大规模流式视频理解数据集Stream-IT。该数据集重新整理了多种公开数据(如密集视频字幕、序列步骤识别、带时标的VideoQA等),并生成了跨越长视频的流水式问答对,涵盖多样的任务类型与指令格式,为流式Video-LLM的训练和评测提供了重要资源。

性能评估
StreamBridge设计中针对延迟和长期记忆做了多项优化。内存缓冲机制确保多轮交互中的历史上下文不丢失,而轮次衰减压缩则在保证近期上下文信息的同时削减不必要的旧帧细节,从而减轻每次推理时的信息量。这些措施联合降低了单步推理的计算延迟。另一方面,激活模型的引入使系统无需对每帧都进行完整推理,而是只在检测到关键帧时才触发模型响应。这意味着系统可以在后台持续观察视频,当有重要视觉变化或用户关注点时才即时输出,避免了不必要的重复计算。综上,StreamBridge通过内存管理和智能触发策略,在流水线处理和时延控制方面取得了良好的平衡。
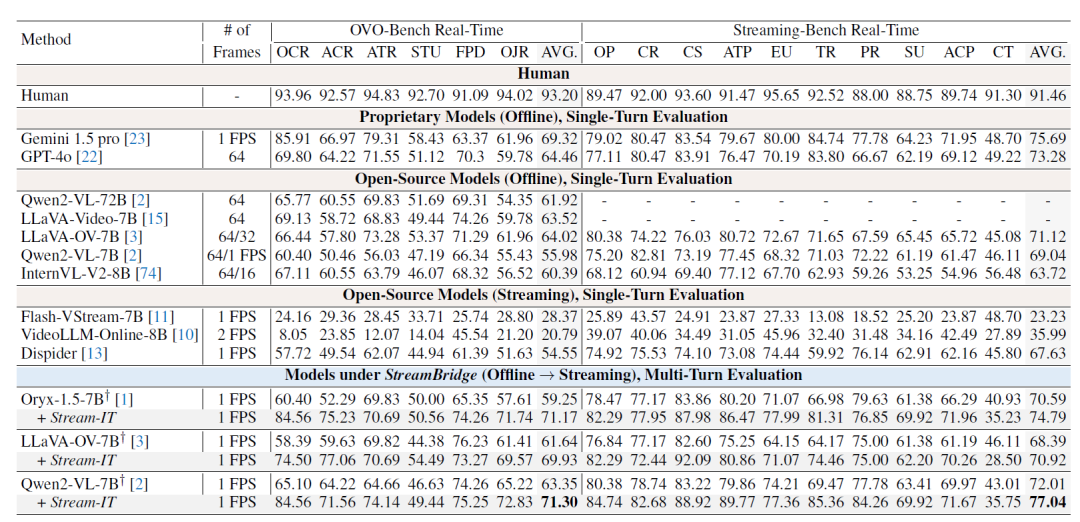
实验设置与对比分析: 为评估StreamBridge的效果,在多个任务和基准上进行了测试。实验中使用了主流Video-LLM模型(如LLaVA-OV-7B、Qwen2-VL-7B、Oryx-1.5-7B),并在构建的Stream-IT数据集(约60万条示例)上进行了微调,增强模型的流式理解能力。测试基准包括多轮实时理解任务(如OVO-Bench、Streaming-Bench)和常规模态视频理解基准(如MVBENCH、VideoQA等)。
结果表明,采用StreamBridge后,各模型在流式任务上表现显著提升:例如,Qwen2-VL模型在OVO-Bench上的平均得分由约55.98提高到63.35,在Streaming-Bench上由69.04提高到72.01。进一步对模型进行Stream-IT数据集微调后,Qwen2-VL分别达到了71.30和77.04,甚至超过了GPT-4o和Gemini 1.5 Pro;Oryx-1.5模型在OVO-Bench上提高了11.92分,Streaming-Bench上提高了4.2分。
StreamBridge 框架为视频多模态大模型的实时应用提供了一种通用可行的解决方案。通过内存缓冲、动态压缩和激活模型三者协同,离线训练的Video-LLM成功具备了实时多轮交互和主动响应的能力。实验验证了其在流式视频理解中的有效性和通用性。