1. 广度和深度优先搜索(BFS和DFS)
1.1. Python实现BFS和DFS
from collections import deque
class Graph:
"""
无向图类,支持添加边,并实现了 BFS(广度优先搜索)和 DFS(深度优先搜索)用于查找从一个顶点到另一个顶点的路径。
"""
def __init__(self, v):
self.v = v # 顶点数
self.adj = [[] for _ in range(v)] # 邻接表,初始化为空列表
self.found = False # DFS 中用于标记是否已经找到目标节点
def add_edge(self, s, t):
self.adj[s].append(t)
self.adj[t].append(s) # 因为是无向图,所以两个方向都要添加
def bfs(self, s, t):
if s == t:
print(s)
return
visited = [False] * self.v # 标记每个节点是否访问过
visited[s] = True
queue = deque()
queue.append(s)
prev = [-1] * self.v # 用于记录路径,prev[i] 表示访问 i 节点的前一个节点
while queue:
w = queue.popleft()
for q in self.adj[w]:
if not visited[q]:
prev[q] = w
if q == t:
self._print_path(prev, s, t)
return
visited[q] = True
queue.append(q)
print("No path found.")
def dfs(self, s, t):
self.found = False
visited = [False] * self.v
prev = [-1] * self.v
self._recur_dfs(s, t, visited, prev)
if self.found:
self._print_path(prev, s, t)
else:
print("No path found.")
def _recur_dfs(self, w, t, visited, prev): # DFS的递归辅助函数
if self.found:
return
visited[w] = True
if w == t:
self.found = True
return
for q in self.adj[w]:
if not visited[q]:
prev[q] = w
self._recur_dfs(q, t, visited, prev)
def _print_path(self, prev, s, t): # 打印从 s 到 t 的路径,基于 prev 反向回溯。
if prev[t] != -1 and t != s:
self._print_path(prev, s, prev[t])
print(t, end=' ')
1.2. 广度优先搜索(BFS)
BFS的定义:
广度优先搜索(Breadth-First-Search),简称为 BFS。它其实就是一种“地毯式”层层推进的搜索策略,即先查找离起始顶点最近的,然后是次近的,依次往外搜索。
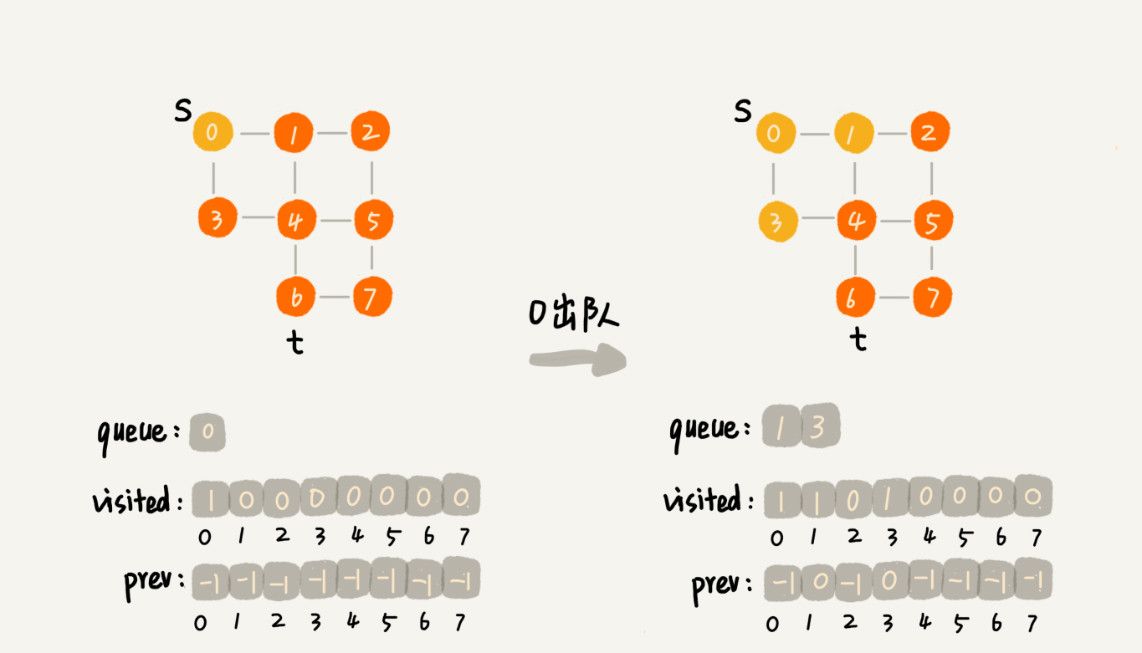
核心辅助变量:
- visited是用来记录已经被访问的顶点,用来避免顶点被重复访问。如果顶点 q 被访问,那相应的 visited[q] 会被设置为 true。
- queue是一个队列,用来存储已经被访问、但相连的顶点还没有被访问的顶点。因为广度优先搜索是逐层访问的,也就是说,我们只有把第 k 层的顶点都访问完成之后,才能访问第 k+1 层的顶点。当我们访问到第 k 层的顶点的时候,我们需要把第 k 层的顶点记录下来,稍后才能通过第 k 层的顶点来找第 k+1 层的顶点。所以,我们用这个队列来实现记录的功能。
- prev用来记录搜索路径。当我们从顶点 s 开始,广度优先搜索到顶点 t 后,prev 数组中存储的就是搜索的路径。不过,这个路径是反向存储的。prev[w] 存储的是,顶点 w 是从哪个前驱顶点遍历过来的。比如,我们通过顶点 2 的邻接表访问到顶点 3,那 prev[3] 就等于 2。为了正向打印出路径,我们需要递归地来打印,你可以看下 print() 函数的实现方式。
时间和空间复杂度:
V 表示顶点的个数,E 表示边的个数。
- 时间复杂度:O(V + E) ,简写为 O(E)
对于一个连通图来说,也就是说一个图中的所有顶点都是连通的,E 肯定要大于等于 V-1,所以,广度优先搜索的时间复杂度也可以简写为 O(E)。
- 空间复杂度:O(V)
1.3. 深度优先搜索(DFS)
DFS的概念:
- 类似“走迷宫”;
- 一路走到底,走不通就回退,再尝试其他路径;
- 非最短路径,但能遍历所有可能路径。
特点:
- 用递归方式实现,体现回溯思想;
- 辅助变量同 BFS,额外用 found 控制递归终止。
时间和空间复杂度:
- 时间复杂度: O(E)
- 空间复杂度:O(V)
BFS vs DFS:
特性 |
BFS |
DFS |
搜索策略 |
按层次,逐层推进 |
一路深入,回退再尝试 |
是否找最短路径 |
✅ 是 |
❌ 不一定 |
实现方式 |
通常用队列实现 |
通常用递归或栈实现 |
时间复杂度 |
O(V + E) |
O(V + E) |
空间复杂度 |
O(V) |
O(V) |
推荐使用场景 |
路径最短查找、三度好友推荐等 |
遍历所有可能路径、连通性检 |