摘要
理解文档图像(例如发票)是一项核心但具有挑战性的任务,因为它需要复杂的功能,例如读取文本和对文档的整体理解。目前的视觉文档理解(VDU)方法将读取文本的任务外包给现成的光学字符识别(OCR)引擎,并专注于使用OCR输出进行理解任务。尽管这种基于OCR的方法表现出了有前景的效果,但它们面临着以下问题:1)使用OCR的计算成本高;2)OCR模型对语言或文档类型的不灵活;3)OCR错误的传播影响后续过程。为了解决这些问题,本文提出了一种新颖的无OCR VDU模型,名为Donut,即文档理解Transformer。作为无OCR VDU研究的第一步,我们提出了一个简单的架构(即Transformer)和一个预训练目标(即交叉熵损失)。Donut在概念上简单但有效。通过广泛的实验和分析,我们证明了一个简单的无OCR VDU模型Donut,在速度和准确性方面都在各种VDU任务上实现了最先进的表现。此外,我们提供了一个合成数据生成器,帮助模型的预训练能够灵活适应各种语言和领域。代码、训练模型和合成数据可在https://github.com/clovaai/donut获取。
关键词:视觉文档理解,文档信息提取,光学字符识别,端到端Transformer
1 引言
文档图像,如商业发票、收据和名片,在现代工作环境中随处可见。要从这些文档图像中提取有用信息,视觉文档理解(VDU)不仅是工业中的一项重要任务,也是研究人员面临的一个挑战性话题,应用包括文档分类[27,1]、信息提取[22,42]和视觉问答[44,57]。
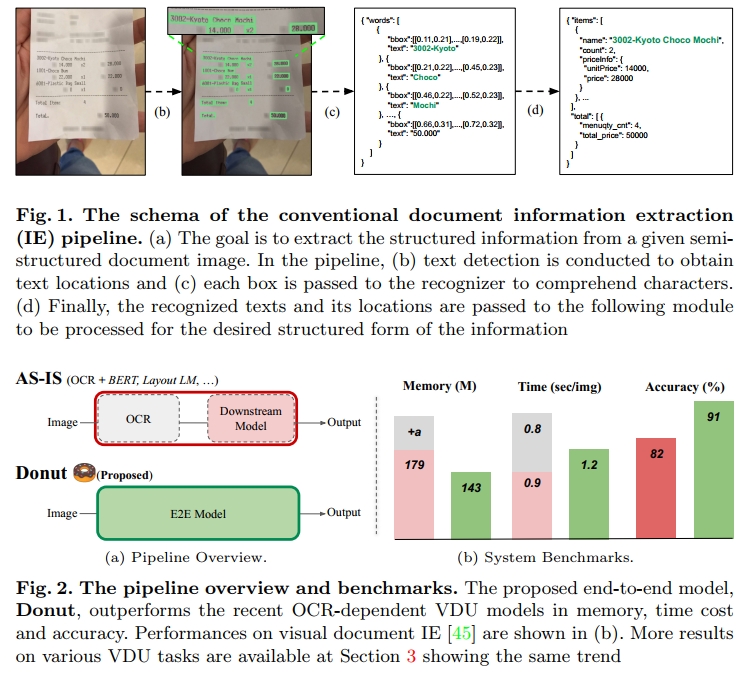
当前的VDU方法[22,24,65,64,18]采用两阶段方式来解决任务:1)读取文档图像中的文本;2)对文档进行整体理解。它们通常依赖基于深度学习的光学字符识别(OCR)[4,3]来执行文本读取任务,并专注于建模理解部分。例如,如图1所示,提取文档结构化信息(即文档解析)的传统流程包含三个独立的模块:文本检测、文本识别和解析[22,24]。然而,依赖OCR的方法存在一些关键问题。首先,使用OCR作为预处理方法是昂贵的。我们可以利用预训练的现成OCR引擎;然而,对于高质量的OCR结果,推理的计算成本会很高。此外,现成的OCR方法在处理不同语言或领域变化时往往缺乏灵活性,这可能导致较差的泛化能力。如果我们自己训练OCR模型,它还需要大量的训练成本和大规模的数据集[4,3,39,46]。另一个问题是,OCR错误会传播到VDU系统并对后续过程产生负面影响[54,23]。在字符集复杂的语言(如韩语或中文)中,这一问题尤为严重,因为OCR的质量相对较低[50]。为了解决这个问题,通常会采用OCR后纠错模块[51,50,10]。然而,这对实际应用环境来说并不是一个可行的解决方案,因为它增加了整个系统的大小和维护成本。
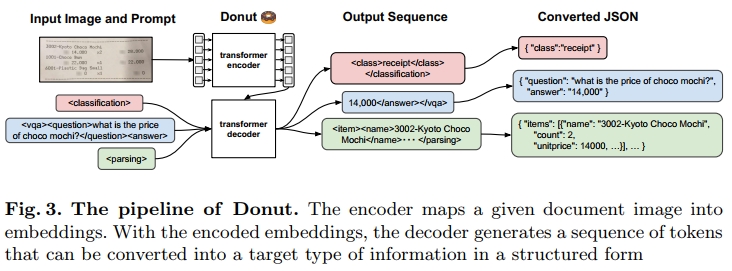
我们超越了传统框架,通过建模从原始输入图像到期望输出的直接映射,而不依赖OCR。我们提出了一种新的无OCR VDU模型,旨在解决OCR依赖带来的问题。我们的模型基于仅使用Transformer架构,称为文档理解Transformer(Donut),这一架构在视觉和语言领域取得了巨大成功[8,9,29]。我们展示了一个简单的基线,包括一个简单的架构和预训练方法。尽管其简单性,Donut在总体性能上与先前的方法相当或更好,如图2所示。
我们在Donut训练过程中采用了预训练和微调方案[8,65]。在预训练阶段,Donut通过在图像和先前文本上下文的联合条件下预测下一个单词,学习如何读取文本。Donut在文档图像及其文本注释上进行预训练。由于我们的预训练目标简单(即读取文本),我们可以通过使用合成数据直接实现领域和语言的灵活性。在微调阶段,Donut根据下游任务学习如何理解整个文档。通过在各种VDU任务和数据集上的广泛评估,我们证明了Donut具有强大的理解能力。实验表明,简单的无OCR VDU模型能够在速度和准确性方面实现最先进的性能。
我们的贡献总结如下:
- 我们提出了一种新颖的无OCR VDU方法。据我们所知,这是第一种基于无OCR Transformer并以端到端方式训练的方法。
- 我们介绍了一个简单的预训练方案,能够利用合成数据。通过使用我们的生成器SynthDoG,我们展示了Donut可以轻松扩展到多语言设置,而传统方法则需要重新训练现成的OCR引擎,这对于多语言环境无法适用。
- 我们在公共基准和私人工业数据集上进行了广泛的实验和分析,证明该方法不仅在基准测试中达到了最先进的性能,而且在现实世界应用中具有许多实际优势(例如,成本效益)。
- 代码库、预训练模型和合成数据可在GitHub上获取。
2 方法
2.1 初步:背景
已有多种视觉文档理解(VDU)方法,用于理解和提取来自半结构化文档(如收据[20,25,18]、发票[49]和表格文档[14,6,43])的关键信息。
早期的VDU尝试使用独立于OCR的视觉骨干网络[27,1,15,12,31],但其性能有限。后来,随着OCR[4,3]和BERT[8]的显著进展,提出了多种通过将它们结合在一起的OCR依赖VDU模型[22,24,23]。近年来,为了获得更通用的VDU,大多数最先进的方法[64,18]使用强大的OCR引擎和大规模真实文档图像数据(例如IIT-CDIP[32])进行模型预训练。尽管近年来取得了显著进展,但使用现成的OCR引擎仍需要额外的努力,以确保整个VDU模型的性能。
2.2 文档理解Transformer
Donut是一个端到端(即自包含的)VDU模型,用于一般文档图像的理解。Donut的架构非常简单,由基于Transformer[58,9]的视觉编码器和文本解码器模块组成。需要注意的是,Donut不依赖于任何与OCR功能相关的模块,而是使用视觉编码器从给定的文档图像中提取特征。接下来的文本解码器将提取的特征映射为一系列子词标记,以构建所需的结构化格式(例如JSON)。每个模型组件都是基于Transformer的,因此模型可以轻松地以端到端的方式进行训练。Donut的整体过程如图3所示。
编码器。视觉编码器将输入的文档图像 x ∈ R H × W × C \mathbf { x } { \in } \mathbb { R } ^ { H \times W \times C } x∈RH×W×C转换为一组嵌入 { z i ∣ z i ∈ R d , 1 ≤ i ≤ n } \{ \mathbf { z } _ { i } | \mathbf { z } _ { i } \in \mathbb { R } ^ { d } , 1 { \leq } i { \leq } n \} {zi∣zi∈Rd,1≤i≤n},其中n是特征图的大小或图像补丁的数量,d是编码器潜在向量的维度。需要注意的是,可以使用基于CNN的模型[17]或基于Transformer的模型[9,40]作为编码器网络。在这项研究中,我们使用Swin Transformer[40],因为它在我们对文档解析的初步研究中表现最好。Swin Transformer首先将输入图像x拆分为不重叠的补丁。Swin Transformer模块由一个基于窗口位移的多头自注意力模块和一个两层的MLP组成,这些模块被应用于补丁。然后,在每个阶段应用补丁合并层,将补丁token合并。最终Swin Transformer模块的输出{z}被送入下一个文本解码器。
解码器。给定{z},文本解码器生成一个标记序列 ( y i ) i = 1 m ( \mathbf { y } _ { i } ) _ { i = 1 } ^ { m } (yi)i=1m,其中 y i ∈ R v \mathbf { y } _ { i } \! \in \! \mathbb { R } ^ { v } yi∈Rv是第i个标记的独热向量,v是标记词汇表的大小,m是超参数。我们使用BART[33]作为解码器架构。具体来说,我们使用来自公开可用的预训练多语言BART模型[38]的解码器模型权重进行初始化。
模型输入。遵循原始Transformer[58],我们使用教师强制(teacher-forcing)方案[62],这是一种训练策略,使用地面真相作为输入,而不是使用来自前一个时间步的模型输出。在测试阶段,受到GPT-3[5]的启发,模型根据提示生成标记序列。我们为每个下游任务添加了新的特殊标记作为提示。在我们的实验中,使用的提示和期望的输出序列如图3所示。教师强制策略和解码器输出格式的说明可在附录A.4中找到。
输出转换。输出的标记序列被转换为所需的结构化格式。我们采用JSON格式,因为它具有很高的表示能力。如图3所示,标记序列可以一一可逆地映射到JSON数据。我们简单地添加两个特殊标记[START ∗]和[END ∗],其中∗表示每个要提取的字段。如果输出的标记序列结构错误,我们将字段视为丢失。例如,如果只有[START name]而没有[END name],我们假设模型未能提取“name”字段。这个算法可以通过简单的正则表达式[11]轻松实现。
2.3 预训练
任务。模型的训练目标是按阅读顺序(从左上角到右下角)读取图像中的所有文本。其目标是通过联合条件化图像和先前的上下文,最小化下一个标记预测的交叉熵损失。这个任务可以解释为一个伪OCR任务。模型作为视觉语言模型在视觉语料库(即文档图像)上进行训练。
视觉语料库。我们使用IIT-CDIP [32],它是一个包含1100万个扫描的英文文档图像的数据集。我们应用了一个商业CLOVA OCR API来获取伪文本标签。然而,如前所述,这种数据集并不总是可用,特别是对于除英语之外的其他语言。为了解决这一依赖问题,我们构建了一个可扩展的合成文档生成器,称为SynthDoG。使用SynthDoG和中文、日文、韩文及英文维基百科,我们为每种语言生成了50万个样本。
合成文档生成器。图像渲染的管道基本遵循Yim等人[67]的方案。如图4所示,生成的样本包含多个组成部分:背景、文档、文本和布局。背景图像从ImageNet[7]中采样,文档的纹理从收集的纸张照片中采样。单词和短语从维基百科中采样。布局通过一个简单的基于规则的算法生成,随机堆叠网格。此外,还应用了几种图像渲染技术[13,41,67]来模仿真实文档。生成的示例如图4所示。SynthDoG的更多细节可在代码和附录A.2中找到。

2.4 微调
在模型学习如何读取后,在应用阶段(即微调阶段),我们教模型如何理解文档图像。如图3所示,我们将所有下游任务解释为JSON预测问题。
解码器被训练生成一个可以转换为JSON的标记序列,该JSON表示所需的输出信息。例如,在文档分类任务中,解码器被训练生成一个标记序列[START class][memo][END class],该序列可以一对一地反转为JSON {“class”: “memo”}。我们引入了一些特殊标记(例如,[memo]用于表示类别“memo”),如果目标任务中有这样的替代标记。
3 实验与分析
在本节中,我们展示了Donut在三个VDU应用上的微调结果,涵盖了六个不同的数据集,包括公共基准数据集和私有工业服务数据集。样本如图5所示。
3.1 下游任务与数据集
文档分类。为了验证模型是否能够区分不同类型的文档,我们测试了一个分类任务。与其他通过对编码嵌入进行softmax预测类别标签的模型不同,Donut生成一个包含类别信息的JSON,以保持任务求解方法的一致性。我们报告了测试集上的整体分类准确率。
RVL-CDIP。RVL-CDIP数据集[16]包含16个类别的40万张图像,每个类别25K张图像。类别包括信件、备忘录、电子邮件等。数据集包含320K张训练图像、40K张验证图像和40K张测试图像。

文档信息提取。为了验证模型是否完全理解文档中的复杂布局和上下文,我们在各种真实文档图像上测试了文档信息提取(IE)任务,包括公共基准和真实工业数据集。在这个任务中,模型的目标是将每个文档映射到与目标本体或数据库模式一致的结构化信息形式。见图1中的示例。模型不仅需要准确读取字符,还需要理解布局和语义,推断文本之间的分组和嵌套层级。
我们使用两个指标来评估模型:字段级别的F1分数[22,65,18]和基于树编辑距离(TED)的准确度[68,70,23]。F1检查提取的字段信息是否与地面真值一致。即使漏掉了一个字符,分数也会认为字段提取失败。尽管F1指标简单易懂,但也存在一些局限性。首先,它没有考虑部分重叠。其次,它无法衡量预测结构(例如,分组和嵌套层级)。为了评估整体准确度,我们还使用基于TED的另一个指标[68],该指标可用于任何表示为树的文档。它的计算公式为:max(0, 1−TED(pr, gt)/TED(ϕ, gt)),其中gt、pr和ϕ分别表示地面真值、预测结果和空树。类似的指标在最近的文档信息提取工作中也有使用[70,23]。
我们使用两个公共基准数据集和两个来自我们活跃的真实世界服务产品的私有工业数据集。每个数据集的介绍如下:
CORD。统一收据数据集(CORD)3[45]是一个公共基准数据集,包含0.8K训练集、0.1K验证集和0.1K测试集收据图像。收据上的文字采用拉丁字母。共有30个独特字段,包括菜单名称、数量、总价等。信息中包含复杂的结构(即嵌套的分组和层级,例如:items>item>{name, count, price})。更多细节请参见图1。
Ticket。这是一个公共基准数据集[12],包含1.5K训练集和0.4K测试集中文火车票图像。我们将训练集的10%拆分为验证集。共有8个字段,包括票号、出发站、列车号等。信息结构简单,所有字段都保证仅出现一次,且每个字段的位置固定。
名片(在服务数据)。该数据集来自我们正在部署的活跃产品。数据集包含20K训练集、0.3K验证集和0.3K测试集日语名片。共有11个字段,包括姓名、公司、地址等。信息结构类似于Ticket数据集。
收据(在服务数据)。该数据集也来自我们的一款真实产品。数据集包含40K训练集、1K验证集和1K测试集韩语收据图像。共有81个独特字段,包括商店信息、支付信息、价格信息等。每个样本相比上述数据集具有更复杂的结构。由于工业政策,部分样本无法公开。图5和附加材料中展示了一些真实高质量的样本。
文档视觉问答。为了验证模型的进一步能力,我们进行了一项文档视觉问答任务(DocVQA)。在这个任务中,给定一个文档图像和问题对,模型通过捕捉图像中的视觉和文本信息来预测问题的答案。我们让解码器生成答案,并将问题设置为起始提示,以保持方法的一致性(见图3)。
DocVQA。该数据集来自文档视觉问答竞赛4,包含50K个问题,定义于12K多文档上[44]。共有40K训练集、5K验证集和5K测试集问题。评估指标为ANLS(平均标准化莱文斯坦相似度),该指标基于编辑距离。测试集上的分数通过评估网站进行测量。
3.2 设置
我们使用了稍作修改的Swin-B[40]作为Donut的视觉编码器。我们设置了层数和窗口大小为{2, 2, 14, 2}和10。进一步考虑到速度和精度的权衡,我们使用BART的前四层作为解码器。如第2.3节所述,我们使用2M合成数据和11M IIT-CDIP扫描文档图像训练了多语言版本的Donut。我们在64个A100 GPU上进行200K步的预训练,迷你批量大小为196。我们使用Adam优化器[30],学习率采用预定调度,初始学习率从1e-5到1e-4之间选择。输入分辨率设置为2560×1920,解码器中的最大长度设置为1536。所有微调结果都是基于预训练的多语言模型开始的。在微调和消融研究中,我们调整了一些超参数。对于Train Tickets和Business Card解析任务,我们使用960×1280的分辨率。在微调过程中,我们监控了token 序列的编辑距离。
Donut的速度是在P40 GPU上测量的,相较于A100要慢得多。对于基于OCR的基准,我们使用了最先进的OCR引擎,包括[64]中使用的MS OCR API和[24,23]中使用的CLOVA OCR API5。关于OCR引擎的分析可以在第3.4节找到。OCR和训练设置的更多细节请见附录A.1和A.5。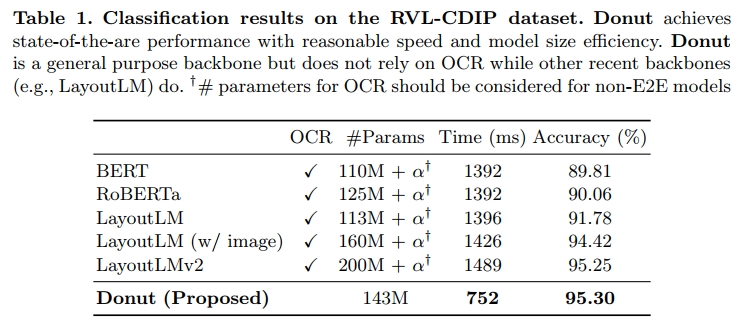
3.3 实验结果
文档分类
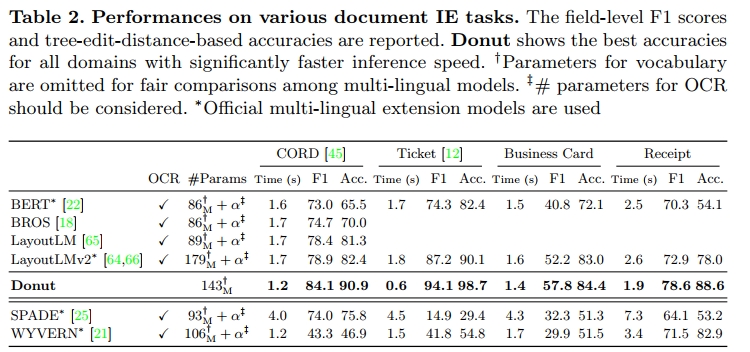
结果如表1所示。在不依赖任何其他资源(例如现成的OCR引擎)的情况下,Donut在通用VDU模型(如LayoutLM [65]和LayoutLMv2 [64])中表现出领先的性能。特别地,Donut在准确度上超过了[64]中报告的LayoutLMv2,同时使用的参数更少,速度也快了2倍。值得注意的是,基于OCR的模型必须考虑额外的模型参数和整个OCR框架的速度,这通常不是很小的。举例来说,最近的一些先进OCR模型[4,3]需要超过80M的参数。此外,训练和维护OCR系统的成本较高[23],这也导致了对像Donut这样的端到端方法的需求。
文档信息提取
表2展示了四种不同文档信息提取(IE)任务的结果。第一组使用了传统的BIO标记方法的IE方法[22]。我们遵循了IE中的约定[65,18]。OCR从图像中提取文本和边界框,然后序列化模块按几何信息对框内的所有文本进行排序。基于BIO标记的命名实体识别任务在排序后的文本上执行令牌级标记分类,以生成结构化形式。我们测试了三种通用VDU骨干网络:BERT [8]、BROS [18]、LayoutLM [65]和LayoutLMv2 [64,66]。
我们还测试了最近提出的两种信息提取(IE)模型,SPADE [24]和WYVERN [23]。SPADE是一种基于图的方法,预测边界框之间的关系。WYVERN是一个Transformer编码器-解码器模型,直接根据OCR输出生成具有结构的实体。与Donut不同,WYVERN将OCR输出作为输入。
在所有领域,包括公共和私人服务中的数据集,Donut在比较模型中表现出最佳的得分。通过测量F1和基于TED的准确性,我们观察到Donut不仅能够提取关键信息,还能预测字段信息之间的复杂结构。我们还发现,大的输入分辨率能提供稳定的准确率,但会使模型变慢。例如,使用1280×960的分辨率在CORD数据集上的表现为0.7秒/图像,准确率为91.1。然而,较大的分辨率在低资源的情况下表现得更好。详细分析见3.4节。与其他基准模型不同,Donut在数据集大小和任务复杂度方面表现稳定(见图5)。这一点尤其重要,因为目标任务在工业界已经得到了广泛应用。
文档视觉问答
表3展示了DocVQA数据集的结果。第一组是通用VDU骨干网络,其得分来自LayoutLMv2论文[64]。我们使用[64]中的MS OCR API来测量运行时间。第三组是LayoutLMv2的DocVQA专用微调模型,其推理结果可以在官方排行榜中找到。
如所示,Donut在依赖外部OCR引擎的基准模型中取得了竞争力的分数。特别是,Donut表明它对于手写文档具有较强的鲁棒性,而手写文档通常是处理中的一个挑战。在传统方法中,添加一个后处理模块来修正OCR错误是强化管道的一种选择[51,50,10],或者在OCR输出上采用编码器-解码器架构可以缓解OCR错误的问题[23]。然而,这类方法往往会增加整个系统的规模和维护成本。Donut则展示了一个完全不同的方向。图6展示了一些推理结果。样本展示了Donut当前的优势,同时也揭示了Donut端到端方法中的一些挑战。更多的分析和消融研究见3.4节。
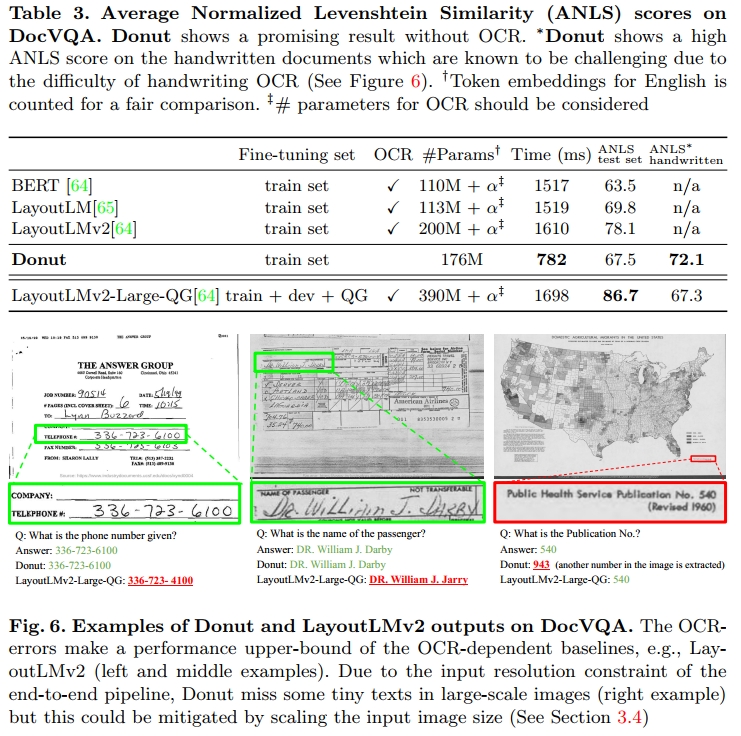
3.4 深入研究
在本节中,我们研究了一些有助于理解 Donut 的要素。我们通过实验和可视化展示了 Donut 的一些显著特性。
关于预训练策略
我们测试了多种用于视觉文档理解(VDU)的预训练任务。图 7(a) 表明,Donut 所采用的预训练任务(即文本阅读)是一种最简单却最有效的方法。其他任务,如图像描述等,虽然能为模型引入图文通用知识,但在微调任务中几乎没有带来额外收益。
对于文本阅读任务,我们验证了三种数据组合选项:仅使用 SynthDoG、仅使用 IIT-CDIP、以及两者结合。分析表明,仅使用合成图像对文档信息抽取任务来说已经足够。然而,在 DocVQA 任务中,使用真实图像则显得更为重要。这可能是因为 IIT-CDIP 和 DocVQA 在图像分布上较为接近 [44]。
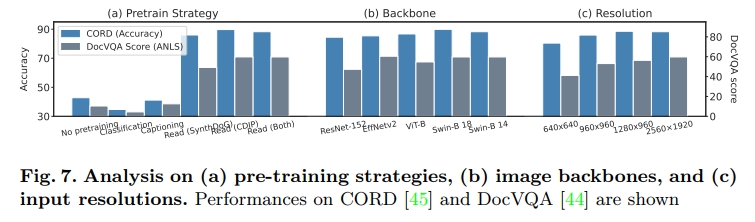
关于编码器主干网络(Encoder Backbone)
我们研究了一些在传统视觉任务中表现优越的图像分类主干网络,并测试它们在视觉文档理解(VDU)任务中的表现。图 7(b) 展示了对比结果。我们使用了所有在 ImageNet [7] 上预训练的主干网络。结果表明,EfficientNetV2 [55] 和 Swin Transformer [40] 在两个数据集上都优于其他架构。我们认为,这归功于它们较高的表达能力,这一点也体现在它们在多个下游任务中的优异表现。
最终,我们选择了 Swin Transformer,原因是:
- Transformer 架构具备良好的可扩展性;
- 在我们的实验中 Swin 的性能超过了 EfficientNetV2。
关于输入分辨率(Input Resolution)
图 7© 表明,Donut 的性能随着输入图像尺寸的增大而显著提升。尤其是在 DocVQA 任务中,由于图像往往更大、包含许多细小文本,分辨率的提升带来的性能增长更加明显。
但更高的分辨率意味着更大的计算开销。虽然可以通过采用高效注意力机制(如 [60])在架构设计上减轻这一负担,但本文为追求架构的简洁性,仍然采用了原始的 Transformer [58]。
关于文本定位(Text Localization)
为了观察模型在实际推理时的行为,我们可视化了 decoder 在处理未见文档图像时的 cross-attention 映射。如图 8 所示,模型展示出具有语义意义的注意力区域,能够聚焦于图像中目标内容的位置。这种注意力图还可以作为辅助解释模型行为的指标。
关于 OCR 系统(OCR System)
我们评估了四个被广泛使用的公共 OCR 引擎(详见图 9)。结果表明,传统基于 OCR 的方法在性能(速度和准确率)上极度依赖于所用的 OCR 引擎。这种依赖不仅影响系统整体精度,也可能在更换引擎时带来不可控的变数。
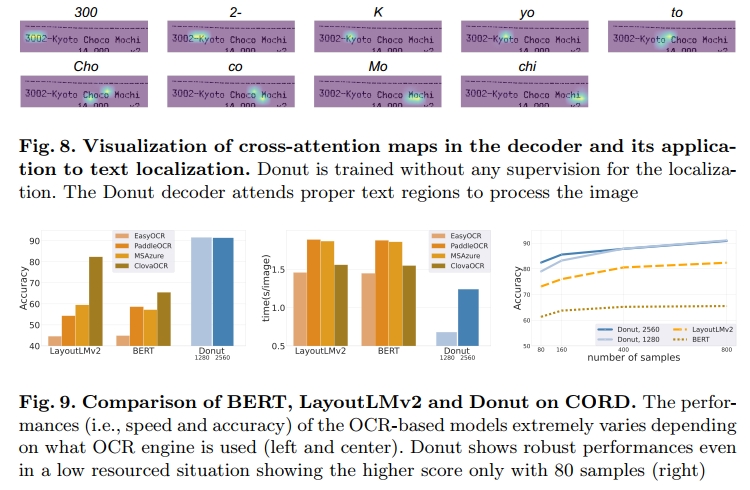
在低资源场景下。我们通过限制 CORD [45] 数据集的训练集规模来评估各模型的表现。性能曲线如图 9 右侧所示。Donut 展现出稳健的性能。我们还观察到,当输入分辨率增大至 2560×1920 时,在极端低资源的情况下(例如仅有 80 个样本),模型的表现更加稳定。如图所示,Donut 在仅使用 10% 的数据(即仅 80 个样本)时,其准确率已经超过了 LayoutLMv2 的表现。
4 相关工作
4.1 光学字符识别(OCR)
近年来,OCR研究的趋势是利用深度学习模型来处理其两个子步骤:1)通过检测器预测文本区域;2)文本识别器对裁剪出的图像实例中的所有字符进行识别。这两个步骤通常使用大规模数据集进行训练,包括合成图像 [26,13] 和真实图像 [28,47]。
早期的检测方法使用CNN预测局部片段,并通过启发式方法将其合并 [19,69]。之后提出了基于区域提议和边界框回归的方法 [36]。最近,研究者基于文本的同质性和局部性,提出了基于组件级别的方法 [56,4]。
许多现代文本识别器采用了类似的方法 [37,53,52,59],其结构可解释为多个常见深度学习模块的组合 [3]。在输入裁剪后的文本实例图像后,最新的文本识别模型通常先使用CNN对图像进行编码,映射到特征空间,然后通过解码器从该特征中提取出字符。
4.2 文档视觉理解(Visual Document Understanding)
文档类型的分类是实现自动化文档处理的核心步骤。早期方法将该问题视为通用的图像分类任务,因此尝试了多种CNN模型 [27,1,15]。近年来,随着BERT [8] 的出现,越来越多结合计算机视觉(CV)与自然语言处理(NLP)的方法被提出 [65,34]。一种常见的做法是,先借助OCR引擎提取文本信息;然后将OCR结果序列化为token序列;最后将其与一些可用的视觉特征一起输入到语言模型中(如BERT)。虽然这种思路看似简单,但这些方法在性能上取得了显著提升,并在近年来成为主流趋势 [64,35,2]。
文档信息抽取(Document IE)涵盖了广泛的实际应用场景 [22,42],例如,对于一批原始的收据图像,文档解析器可以自动完成大量收据数字化的工作,而这在传统流程中需要大量人工。最新的大多数模型 [25,23] 将OCR的输出作为输入。OCR结果随后通过一系列通常较为复杂的处理流程转换为最终的解析结果。尽管业界对该类技术有强烈需求,但真正尝试端到端解析的工作仍然较少。最近有研究致力于简化这一复杂的解析流程 [25,23],但这些方法仍然依赖于独立的OCR模块提取文本信息。
文档视觉问答(Visual QA)任务旨在回答针对文档图像提出的问题。该任务需要对图像中的视觉元素进行推理,并结合通用知识来得出正确答案 [44]。目前,大多数最新方法仍采用一个简单的流水线:首先进行OCR,然后使用类似BERT的transformer模型 [65,64]。然而,由于这些方法本质上是抽取式的(extractive),对于那些答案不直接出现在图像中的问题,效果并不理想 [57]。为了解决这一问题,也有研究提出了基于生成的问答方法 [48]。
5. 结论
在本研究中,我们提出了一个新颖的端到端视觉文档理解框架。所提出的方法 Donut 能够将输入的文档图像直接映射为所需的结构化输出。与传统方法不同,Donut 不依赖于OCR系统,且能够轻松地以端到端的方式进行训练。我们还提出了一个合成文档图像生成器 SynthDoG,用以减轻对大规模真实文档图像的依赖,并展示了 Donut 在多语言设置下的易扩展性。我们通过所设计的训练流程,使模型逐步学习从“如何阅读”到“如何理解”。
我们在多个外部公开基准数据集和内部私有服务数据集上进行了大量实验和分析,结果表明所提出的方法在性能与成本效率上均优于现有方案。由于目标任务已被广泛应用于工业实践中,因此本方法具有重要的现实意义。未来的研究方向可以是增强预训练目标。我们相信,本文所提出的工作能够轻松扩展至其他与文档理解相关的领域与任务。
论文名称:
OCR-free Document Understanding Transformer
论文地址:
https://arxiv.org/pdf/2111.15664