1 线性表
1.3 循环链表(Circular Linked List)
循环链表的结构:
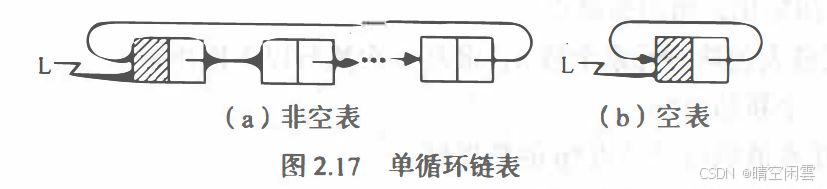
循环链表和单链表的不同在于:当链表遍历时,判别当前指针p是否指向表尾结点的终止条件不同。
- 单链表中,判别条件为
p != NULL或p->next != NULL; - 循环单链表的判别条件为
p != L或p->next != L。
合并循环链表
【前置处理】
书上和课程都有提到合并循环链表,并且是通过尾指针的方式进行合并。根据这个思路,又因为在写这个方法的时候,要构建2个循环链表进行测试,所以我把单链表的尾插法拿过来修改了下,主要改动是两个点:
- 增加尾结点指针参数,在调用这个方法后,可以获取到尾结点指针。
- 尾结点的next指向头结点,形成循环链表。
代码如下:
// 尾插法创建循环链表
Status CreateListTail(LinkList *L, int n, LNode **tailNode)
{
*L = (LinkList)malloc(sizeof(LNode)); // 创建头结点
if (*L == NULL)
{
return OVERFLOW;
}
(*L)->next = NULL; // 初始化头结点的next指针为NULL
// 一开始尾结点指向头节点。每增加一个结点,尾结点就指向新增加的结点。
*tailNode = *L;
LNode *newNode; // 新结点指针
for (int i = 1; i <= n; i++)
{
newNode = (LNode *)malloc(sizeof(LNode)); // 创建新结点
if (newNode == NULL)
{
return OVERFLOW;
}
newNode->data.x = i; // 设置新结点的数据
newNode->next = NULL; // 将新结点的next指针设置为NULL
(*tailNode)->next = newNode; // 将当前尾结点的next指针指向新结点
*tailNode = newNode; // 更新尾结点为新结点
}
/* 这里是新增加的 */
// 上面while循环结束后,tailNode指向最后一个结点,即尾结点
// 尾结点的next指针指向头结点,形成循环链表
(*tailNode)->next = *L;
return OK;
}
[!question]
这里为什么用LNode **tailNode,即指针的指针?在后面结合调用这个方法的时候进行理解。
再增加一个打印链表内所有结点的方法(这个在上一节就已经增加了,不过没有提到这个方法,这节直接拿来用,但是要修改一下):
// 打印链表
void PrintList(LinkList *L)
{
LNode *current = (*L)->next; // 从头结点的下一个结点(首元结点)开始遍历
while (current != *L) // 这行发生改动: current != NULl 调整为 current != *L
{
printf("%d ", current->data.x); // 打印结点数据
current = current->next; // 移动到下一个结点
}
}
调用:
LinkList L1, L2; // 声明两个链表
LNode *tailNode1, *tailNode2; // 声明两个尾结点指针
CreateListTail(&L1, 100, &tailNode1); // 尾插法创建单链表1
CreateListTail(&L2, 30, &tailNode2); // 尾插法创建单链表2
PrintList(&L1); // 打印链表1
printf("\n");
PrintList(&L2); // 打印链表2
printf("\n");
因为这里声明的尾结点是指针类型,所以在声明 CreateListTail 方法时,需要定义为 LNode **tailNode,即指针的指针,这样在方法内部修改 *tailNode 的时候,才会修改到这里定义的 *tailNode1 和 *tailNode2 。
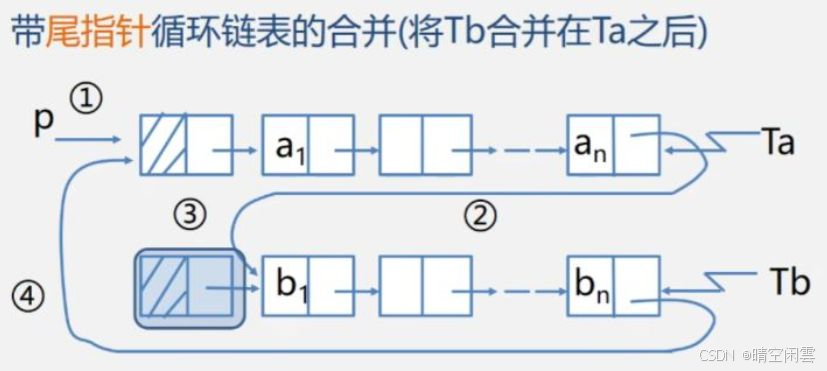
【算法步骤】
有了尾指针之后,方法就变得非常简单。
- 用临时变量
L1保存第一个链表的头节点。 - 将第一个链表的尾结点指向第二个链表的首元结点。
- 释放第二个链表的头结点内存。
- 将第二个链表的尾结点指向第一个链表的头结点。
步骤参考如下:
【代码实现】
// 根据两个链表的尾结点合并两个循环链表
Status MergeList(LNode **tailNode1, LNode **tailNode2)
{
LinkList L1 = (*tailNode1)->next; // 获取第一个链表的头结点
(*tailNode1)->next = (*tailNode2)->next->next; // 将第一个链表的尾结点指向第二个链表的首元结点
free((*tailNode2)->next); // 释放第二个链表的头结点
(*tailNode2)->next = L1; // 将第二个链表的尾结点指向第一个链表的头结点
return OK;
}
【算法分析】
可以看到在循环链表种,有了尾结点指针后,合并操作变得非常简单,修改几个指针就可以了,时间复杂度是 O(1) 。