1st author: Paul Soulos
paper: Differentiable Tree Operations Promote Compositional Generalization ICML 2023
code: psoulos/dtm: Differentiable Tree Machine
1. 问题与思路
现代深度学习在连续向量空间中取得了巨大成功,然而在处理具有显式结构(Structure),尤其是离散(Discrete) 符号结构的任务时,例如程序合成、逻辑推理、自然语言的句法和语义结构,其组合泛化(Compositional Generalization) 能力常常捉襟见肘。传统的符号系统(GOFAI)天然具备结构处理和组合泛化能力,但其离散性导致难以与基于梯度的端到端学习框架兼容。这篇论文正是试图弥合这一裂痕,其关键是:如何在连续向量空间中实现可微(Differentiable) 的、结构感知(Structure-aware) 的符号操作,从而赋予神经网络强大的组合泛化能力。
1.1. 问题:结构操作的“不可微”
考虑对树结构进行操作的任务,比如句法树转换、逻辑形式生成。这些任务本质上是应用一系列离散的、符号性的树操作(如 Lisp 中的 car, cdr, cons)来转换结构。问题在于,这些离散操作在数学上通常是不可微的,这意味着我们无法直接通过梯度下降来学习执行这些操作的序列或策略。现有的神经网络模型,即使是 Tree-based Transformer 或 LSTM,虽然能编码树结构,但其内部的处理(通常是黑箱的非线性变换)仍然难以显式地执行或学习离散的结构操作序列,导致在面对训练中未见的结构组合时泛化能力差。

car,cdr,cons是 Lisp 对列表的三种操作, 其使用嵌套列表存储树.car表示取左子树,cdr表示取右子树,cons表示创建新树。Fiugre 2 是三个操作的例子, 被操作的是图片中间以 ‘NP’ 为根的一颗句法分析树。
1.2. 思路:重定义操作为可微操作
这篇论文的独特之处在于,它并没有试图去“软化”离散操作本身,而是将离散的符号结构及其操作整体嵌入到一个连续的向量空间中,并在这个空间中定义出与原离散操作等价的可微线性变换。具体来说,他们使用了 张量积表示 (Tensor Product Representation, TPR) 来编码树结构。
TPR 的核心思想是将一个结构分解为角色 (Roles) 和填充物 (Fillers) 的绑定。对于树结构而言,一个节点的位置可以看作一个“角色”,该节点的标签或子结构则是这个“填充物”。一个完整的树结构 T T T 被表示为所有 “角色-填充物” 对的张量积之和:
T = ∑ i f i ⊗ r i T = \sum_i f_i \otimes r_i T=i∑fi⊗ri
其中 f i f_i fi 是第 i i i 个位置的填充物(例如,词汇的向量表示), r i r_i ri 是第 i i i 个位置的角色(表示该位置在树中的结构信息向量)。 ⊗ \otimes ⊗ 是张量积运算。
例如 f 011 f_{011} f011 是从根节点开始以"左右右"路径到达节点的填充物向量 (0表示左, 1表示右),下标从左往右读。 f ϵ f_\epsilon fϵ 表示根节点。
关键来了:如果在向量空间中精心设计角色向量 r i r_i ri,就可以将 car, cdr, cons 这些离散的树操作转化为对这个 TPR 向量 T T T 的线性变换。
2. 可微树操作
2.1. 定义可微操作
关于张量积与张量积表示 TPR的解释可以看这篇文章: 张量积表示 (Tensor Product Representation, TPR)-CSDN博客
我们聚焦于二叉树 ( b = 2 b=2 b=2)。假设树的最大深度为 D D D。树中可能的节点位置总数 N = ( 2 D + 1 − 1 ) / ( 2 − 1 ) = 2 D + 1 − 1 N = (2^{D+1} - 1) / (2-1) = 2^{D+1} - 1 N=(2D+1−1)/(2−1)=2D+1−1。我们可以生成一组 N N N 个标准正交 (Orthonormal) 的角色向量 r i ∈ R d r r_i \in \mathbb{R}^{d_r} ri∈Rdr,其中 d r = N d_r = N dr=N。
对于一个树 T = ∑ i = 1 N f i ⊗ r i T = \sum_{i=1}^N f_i \otimes r_i T=∑i=1Nfi⊗ri,其中 f i f_i fi 是填充物向量。由于角色向量是标准正交的,我们可以通过内积恢复任何位置的填充物: f i = ⟨ T , r i ⟩ f_i = \langle T, r_i \rangle fi=⟨T,ri⟩。或者更一般地,通过与角色向量 r i r_i ri 的对偶空间操作来实现 ( 论文中使用矩阵乘法 T r i Tr_i Tri,如果将 T T T 看作一个高阶张量,这等价于在角色维度上与 r i r_i ri 做张量的收缩)。
现在,如何用矩阵操作实现 car, cdr, cons?
论文中给出了基于角色向量的线性变换矩阵。考虑 car 操作,它提取根节点的左子树。这需要将左子树中的每个节点的“角色”向上移动一层。cdr 类似,提取右子树。cons 则根据两个子树构建一个新的父节点树。
定义矩阵 D c D_c Dc 和 E c E_c Ec:
D c D_c Dc 矩阵用于提取第 c c c 个孩子( c = 0 c=0 c=0 为左孩子 car, c = 1 c=1 c=1 为右孩子 cdr),并将其子树的角色向上提升一层。
E c E_c Ec 矩阵用于将一个子树的角色向下推一层,以便将其作为新树的第 c c c 个孩子。
形式上,对于角色空间中的操作,这些矩阵定义为:
D c = I F ⊗ ∑ x ∈ P r x r c x ⊤ E c = I F ⊗ ∑ x ∈ P r c x r x ⊤ D_c = I_F \otimes \sum_{x \in P} r_x r_{cx}^\top\\ E_c = I_F \otimes \sum_{x \in P} r_{cx} r_x^\top Dc=IF⊗x∈P∑rxrcx⊤Ec=IF⊗x∈P∑rcxrx⊤
其中 I F I_F IF 是填充物空间 F F F 上的单位矩阵, P = { r x ∥ ∣ x ∣ < D } P=\{r_x\|\:|x|<D\} P={rx∥∣x∣<D} 是所有深度小于 D D D 的路径对应的角色集合, r x r_x rx 是路径 x x x 的角色向量, r c x r_{cx} rcx 是在路径 x x x 前面加上 c c c 形成新路径的角色向量。这两个公式不太好理解, 可以看下一小节的例子。
这样,可微的 car , cdr 和 cons 操作(将 T 0 T_0 T0 作为左子树, T 1 T_1 T1 作为右子树)可以表示为对 TPR 向量 T T T 的矩阵操作:
car ( T ) = D 0 T cdr ( T ) = D 1 T cons ( T 0 , T 1 ) = E 0 T 0 + E 1 T 1 \text{car}(T) = D_0 T\\ \text{cdr}(T) = D_1 T\\ \text{cons}(T_0, T_1) = E_0 T_0 + E_1 T_1 car(T)=D0Tcdr(T)=D1Tcons(T0,T1)=E0T0+E1T1
注意,cons 还需要指定新创建的根节点的填充物 s s s。也就是将 s ⊗ r r o o t s \otimes r_{root} s⊗rroot 加入到结果中 ( r r o o t r_{root} rroot 是根节点的角色向量)。
所以,在向量空间中,这些原本离散的树操作,就变成了 TPR 向量上的线性变换。整个 DTM 模型的核心操作步骤,就是对输入的 TPR 树进行这些可微的线性操作,并根据学习到的权重进行线性组合。
2.2. 以 cdr 操作为例

如上图, T ′ = car ( T ) T'=\text{car}(T) T′=car(T), 其中 T T T 的 P = { r x ∥ ∣ x ∣ < 3 } = { r ϵ , r 0 , r 1 } P=\{r_x\|\:|x|<3\}=\{r_\epsilon,r_0,r_1\} P={rx∥∣x∣<3}={rϵ,r0,r1}, 我们的目的是: 将节点 B 的位置 r 0 → r ϵ r_0\to r_\epsilon r0→rϵ, 节点 D 的位置 r 00 → r 0 r_{00}\to r_0 r00→r0, 节点 B 的位置 r 01 → r 1 r_{01}\to r_1 r01→r1.
car ( T ) = D 0 T = ( I F ⊗ ∑ x ∈ P r x r c x ⊤ ) ( ∑ i f i ⊗ r i ) = ( I F ⊗ ( ( r ϵ r 0 ϵ ⊤ ) + ( r 0 r 00 ⊤ ) + ( r 1 r 01 ⊤ ) ) ⏟ let = R ) ( ∑ i f i ⊗ r i ) = ( I F ⊗ R ) ( ( f ϵ ⊗ r ϵ ) + ( f 0 ⊗ r 0 ) + ( f 1 ⊗ r 1 ) + ( f 00 ⊗ r 00 ) + ( f 01 ⊗ r 01 ) + ( f 10 ⊗ r 10 ) ) = ( I F ⊗ R ) ( f ϵ ⊗ r ϵ ) + ( I F ⊗ R ) ( f 0 ⊗ r 0 ) + ⋯ + ( I F ⊗ R ) ( f 10 ⊗ r 10 ) = ( I F f ϵ ) ⊗ ( R r ϵ ) + ( I F f 0 ) ⊗ ( R r 0 ) + ⋯ + ( I F f 10 ) ⊗ ( R r 10 ) = f ϵ ⊗ ( [ ( r ϵ r 0 ϵ ⊤ ) + ( r 0 r 00 ⊤ ) + ( r 1 r 01 ⊤ ) ] r ϵ ) + ⋯ + f 10 ⊗ ( [ ( r ϵ r 0 ϵ ⊤ ) + ( r 0 r 00 ⊤ ) + ( r 1 r 01 ⊤ ) ] r 10 ) = 0 + f 0 ⊗ ( r ϵ r 0 ϵ ⊤ r 0 ) + 0 + f 00 ⊗ ( r 0 r 00 ⊤ r 00 ) + f 01 ⊗ ( r 1 r 01 ⊤ r 01 ) + 0 = f 0 ⊗ r ϵ + f 00 ⊗ r 0 + f 01 ⊗ r 1 \begin{align} \text{car}(T)&=D_0T\\ &= \bigg( I_F \otimes \sum_{x \in P} r_x r_{cx}^\top \bigg)\bigg (\sum_i f_i \otimes r_i \bigg)\\ &= \bigg( I_F \otimes \underbrace{\big((r_\epsilon r_{0\epsilon}^\top)+(r_0 r_{00}^\top)+(r_1 r_{01}^\top)\big)}_{\text{let}=R} \bigg)\bigg (\sum_i f_i \otimes r_i \bigg) \\ &= \left (I_F \otimes R\right )\big( (f_{\epsilon}\otimes r_\epsilon)+(f_0\otimes r_0)+(f_1\otimes r_1)+(f_{00}\otimes r_{00})+(f_{01}\otimes r_{01})+(f_{10}\otimes r_{10})\big)\\ &= (I_F \otimes R) (f_{\epsilon}\otimes r_\epsilon)+(I_F \otimes R) (f_{0}\otimes r_0)+\dots+(I_F \otimes R)(f_{10}\otimes r_{10})\\ &= (I_Ff_\epsilon)\otimes (Rr_\epsilon)+(I_Ff_0)\otimes (Rr_0)+\dots+(I_Ff_{10})\otimes (Rr_{10})\\ &= f_\epsilon\otimes (\textcolor{green}{\big[(r_\epsilon r_{0\epsilon}^\top)+(r_0 r_{00}^\top)+(r_1 r_{01}^\top)\big]}r_\epsilon)+\dots+f_{10}\otimes (\textcolor{green}{\big[(r_\epsilon r_{0\epsilon}^\top)+(r_0 r_{00}^\top)+(r_1 r_{01}^\top)\big]}r_{10})\\ &= 0+f_0\otimes (r_\epsilon r_{0\epsilon}^\top r_0)+0+f_{00}\otimes (r_0 r_{00}^\top r_{00})+f_{01}\otimes (r_1 r_{01}^\top r_{01})+0\\ &= f_0\otimes r_\epsilon+f_{00}\otimes r_0+f_{01}\otimes r_1\\ \end{align} car(T)=D0T=(IF⊗x∈P∑rxrcx⊤)(i∑fi⊗ri)=(IF⊗let=R
((rϵr0ϵ⊤)+(r0r00⊤)+(r1r01⊤)))(i∑fi⊗ri)=(IF⊗R)((fϵ⊗rϵ)+(f0⊗r0)+(f1⊗r1)+(f00⊗r00)+(f01⊗r01)+(f10⊗r10))=(IF⊗R)(fϵ⊗rϵ)+(IF⊗R)(f0⊗r0)+⋯+(IF⊗R)(f10⊗r10)=(IFfϵ)⊗(Rrϵ)+(IFf0)⊗(Rr0)+⋯+(IFf10)⊗(Rr10)=fϵ⊗([(rϵr0ϵ⊤)+(r0r00⊤)+(r1r01⊤)]rϵ)+⋯+f10⊗([(rϵr0ϵ⊤)+(r0r00⊤)+(r1r01⊤)]r10)=0+f0⊗(rϵr0ϵ⊤r0)+0+f00⊗(r0r00⊤r00)+f01⊗(r1r01⊤r01)+0=f0⊗rϵ+f00⊗r0+f01⊗r1
上方推导过程中:
- 第 4 到第 5 步, 使用了线性性质的分配律. A ( B + C ) = A B + C D A(B+C)=AB+CD A(B+C)=AB+CD.
- 第 5 到 第 6步, 使用了张量积性质, ( A ⊗ B ) ( v ⊗ w ) = ( A v ) ⊗ ( B w ) (A\otimes B)(v\otimes w)=(Av)\otimes(Bw) (A⊗B)(v⊗w)=(Av)⊗(Bw).
- 第 7 步中, 由于 r i r_i ri 正交, 则 r i ⊤ r i = 1 , r i ⊤ r ≠ i = 0 r_i^\top r_i = 1, r_i^\top r_{\neq i} = 0 ri⊤ri=1,ri⊤r=i=0.
- r x r c x ⊤ r_x r_{cx}^\top rxrcx⊤: 这是一个外积,得到一个矩阵。当这个矩阵作用于一个角色向量 r y r_y ry 时,如果 y = c x y = cx y=cx,结果是 r x r_x rx;否则结果是零向量(因为角色向量是正交的)。这实现了一个“将子节点位置的角色映射到父节点位置的角色”的操作。
- ∑ x ∈ P r x r c x ⊤ \sum_{x \in P} r_x r_{cx}^\top ∑x∈Prxrcx⊤: 这个求和构建了一个总的矩阵,它将所有可能的“子节点位置 c x cx cx 的角色”映射到对应的“父节点位置 x x x 的角色”。
I F ⊗ ( ∑ x ∈ P r x r c x ⊤ ) I_F \otimes (\sum_{x \in P} r_x r_{cx}^\top) IF⊗(∑x∈Prxrcx⊤)整个算子 D c D_c Dc 作用于一个树的 TPR 表示 T = ∑ i f i ⊗ r i T = \sum_{i} f_i \otimes r_i T=∑ifi⊗ri 时,由于张量积的性质 ( A ⊗ B ) ( v ⊗ w ) = ( A v ) ⊗ ( B w ) (A \otimes B)(v \otimes w) = (Av) \otimes (Bw) (A⊗B)(v⊗w)=(Av)⊗(Bw),它会独立地作用于填充物向量和角色向量。 I F I_F IF 作用于 f i f_i fi 保持不变,$ (\sum r_x r_{cx}^\top)$ 作用于 r i r_i ri。如果 r i r_i ri 是某个 r c x r_{cx} rcx,它就会被映射到 r x r_x rx;如果 r i r_i ri 是其他角色,它会被映射到零向量。
3. DTM 架构与运作机制
基于上一部分提到的向量空间中的可微树操作,论文构建了可微树机器(Differentiable Tree Machine, DTM) 这一架构。DTM 的核心思想是,将离散的符号操作逻辑与连续的神经网络决策过程解耦。
3.1. DTM 架构
DTM 主要由三个核心组件构成(如论文 Figure 1 所示):
- 神经树 Agent (Neural Tree Agent): 一个学习组件,负责在每一步决策要执行什么操作 (car, cdr, cons) 以及操作作用在记忆中的哪些树上。
- 可微树解释器 (Differentiable Tree Interpreter): 非学习组件,根据神经树 Agent 的指令,执行上一节描述的、预定义的可微线性树操作。
- 树记忆 (Tree Memory): 一个外部记忆单元,用于存储中间计算过程中产生的树的 TPR 表示。
DTM 是个很有意思的设计:将复杂的、黑箱的非线性学习能力被封装在神经树 Agent 中,而对树结构的显式、结构感知操作则通过可微树解释器以透明、可微的方式实现。
3.1.1. 神经树 Agent
神经树 Agent 是 DTM 中唯一包含可学习参数的部分。它被实现为一个标准的 Transformer 层(包含多头自注意力、前馈网络等)。
在每个计算步骤(timestep l l l),神经树 Agent (Neural Tree Agent) 会接收一个输入序列。这个序列包括以下编码:
- 操作编码 (Operation Encoding)
- 根符号编码 (Root Symbol Encoding)
- 树记忆 (Tree Memory) 中所有树的编码。被读取时,会从 TPR 维度 d t p r d_{tpr} dtpr 被压缩到 Transformer 输入维度 d m o d e l d_{model} dmodel,这通过一个可学习的线性变换 W s h r i n k ∈ R d t p r × d m o d e l W_{shrink}\in\mathbb{R}^{d_{tpr}\times d_{model}} Wshrink∈Rdtpr×dmodel 实现。
Transformer 的输入序列长度会随着每个步骤的进行而增长,每一步包含前一步骤新产生的树的编码 (如论文 Fiuger 4)。
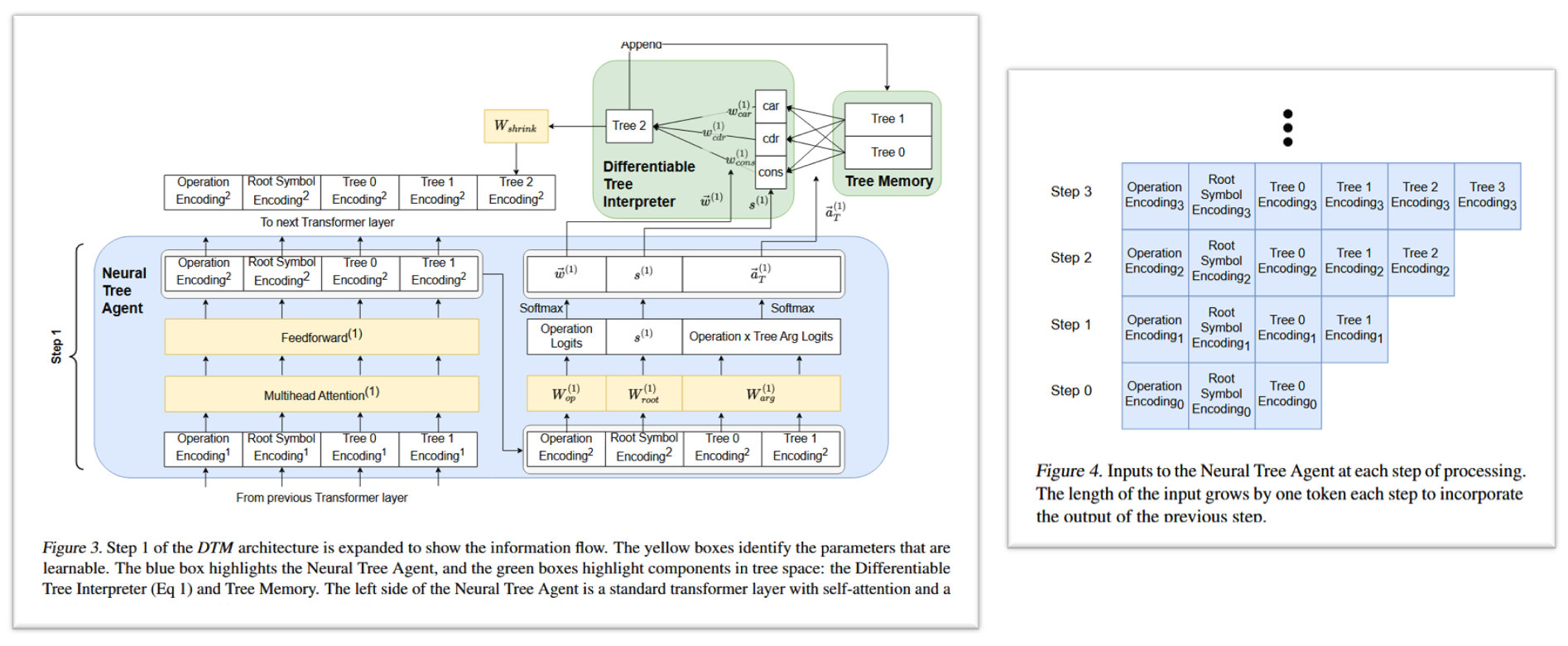
在每个计算步骤 l l l,神经树 Agent 的输出被用来做以下决策:
操作选择 ( w ( l ) w^{(l)} w(l)): 决定 car, cdr, cons 三种操作各自的权重。通过将一个特殊 token 的输出投影到 3 维向量,再经过 softmax 得到 w ⃗ ( l ) = ( w c a r ( l ) , w c d r ( l ) , w c o n s ( l ) ) \vec{w}^{(l)} = (w_{car}^{(l)}, w_{cdr}^{(l)}, w_{cons}^{(l)}) w(l)=(wcar(l),wcdr(l),wcons(l)),其中 ∑ w i ( l ) = 1 \sum w_i^{(l)} = 1 ∑wi(l)=1。
参数选择 ( a T ( l ) a_T^{(l)} aT(l)): 决定每种操作的输入应该“读取”记忆中的哪些树,以及它们的权重。例如,对于 car 操作,它需要一个被操作树 T c a r ( l ) T_{car}^{(l)} Tcar(l) (输入树)。神经树 Agent 会为记忆中的每一棵树计算一个权重,然后通过 softmax 归一化。最终 T c a r ( l ) T_{car}^{(l)} Tcar(l) 是记忆中所有树的加权和 (blended tree)。Cons 操作需要两个输入树 T c o n s 0 ( l ) T_{cons0}^{(l)} Tcons0(l) 和 T c o n s 1 ( l ) T_{cons1}^{(l)} Tcons1(l),同样通过加权求和获得。这组用于选择参数的权重记为 a ⃗ T ( l ) \vec{a}_{T}^{(l)} aT(l)。
新根符号选择 ( s ( l ) s^{(l)} s(l)): 如果 w ( l ) w^{(l)} w(l) 选择了 cons 操作,还需要确定新创建的根节点的符号。神经树 Agent 通过另一个特殊 token 的输出预测一个符号向量 s ( l ) s^{(l)} s(l)。
这 3 个输出是 Transformer 最后一层通过三个线性投影 W o p ∈ R d m o d e l × 3 ; W r o o t ∈ R d m o d e l × d s y m b o l ; W a r a ∈ R d m o d e l × 4 W_{op}\in\mathbb{R}^{d_{model}\times3};\ W_{root}\in\mathbb{R}^{d_{model}\times d_{symbol}};\ W_{ara}\in\mathbb{R}^{d_{model}\times4} Wop∈Rdmodel×3; Wroot∈Rdmodel×dsymbol; Wara∈Rdmodel×4 得到 ( Figure 3 蓝块的右侧)。
值得注意的是,Agent 的这些选择(操作权重 w ( l ) w^{(l)} w(l) 和参数权重 a T ( l ) a_T^{(l)} aT(l))都是通过 softmax 产生的软选择(Soft Selection),这意味着在训练初期,DTM 会在不同的操作和不同的输入树之间进行“混合”(blending)。论文的实验表明,这种混合对于学习至关重要,尽管在训练收敛后,权重通常会趋向于 one-hot 分布,退化为离散的操作序列。
3.1.2. 树记忆
树记忆是一个简单的外部存储,按顺序存放每个计算步骤产生的 TPR 树。在步骤 l l l 计算时,步骤 0 0 0 到 l − 1 l-1 l−1 生成的所有树都在记忆中,可以被神经树 Agent 读取并作为操作的参数。新的计算结果会被写入下一个可用的记忆槽位。我们用 M ( l − 1 ) \mathcal{M}^{(l-1)} M(l−1) 表示在步骤 l l l 时被操作的记忆树。
3.1.3. 可微树解释器
将神经树 Agent 的决策 (输出) 与可微树解释器结合,(可微树解释器就是一个预定义的公式, 以产生输出 O O O), DTM 的单步计算可以描述如下:
在计算步骤 l l l,神经树 Agent 根据记忆中的树(TPR 向量集合 M ( l − 1 ) \mathcal{M}^{(l-1)} M(l−1))计算出操作权重 w ⃗ ( l ) \vec{w}^{(l)} w(l)、参数选择权重 a ⃗ T ( l ) \vec{a}_{T}^{(l)} aT(l) 以及新的根符号 s ( l ) s^{(l)} s(l)。
参数选择权重 a ⃗ ∗ T ( l ) \vec{a}*{T}^{(l)} a∗T(l) 定义了每种操作的输入树。假设记忆中有 K K K 棵树 M 1 , … , M K M_1, \dots, M_K M1,…,MK,则:
T c a r ( l ) = ∑ k = 1 K a c a r , k ( l ) M k T c d r ( l ) = ∑ k = 1 K a c d r , k ( l ) M k T c o n s 0 ( l ) = ∑ k = 1 K a c o n s 0 , k ( l ) M k ; T c o n s 1 ( l ) = ∑ k = 1 K a c o n s 1 , k ( l ) M k T_{car}^{(l)} = \sum_{k=1}^K a_{car,k}^{(l)} M_k\\ T_{cdr}^{(l)} = \sum_{k=1}^K a_{cdr,k}^{(l)} M_k\\ T_{cons0}^{(l)} = \sum_{k=1}^K a_{cons0,k}^{(l)} M_k;\ \ T_{cons1}^{(l)} = \sum_{k=1}^K a_{cons1,k}^{(l)} M_k Tcar(l)=k=1∑Kacar,k(l)MkTcdr(l)=k=1∑Kacdr,k(l)MkTcons0(l)=k=1∑Kacons0,k(l)Mk; Tcons1(l)=k=1∑Kacons1,k(l)Mk
然后,可微树解释器根据操作权重 w ⃗ ( l ) \vec{w}^{(l)} w(l) 对这些输入树应用对应的可微操作,并进行加权求和,得到本步骤的输出树 O ( l ) O^{(l)} O(l) 的 TPR 表示:
O ( l ) = w c a r ( l ) car ( T c a r ( l ) ) + w c d r ( l ) cdr ( T c d r ( l ) ) + w c o n s ( l ) ( cons ( T c o n s 0 ( l ) , T c o n s 1 ( l ) ) + s ( l ) ⊗ r r o o t ) O^{(l)} = w_{car}^{(l)} \text{car}(T_{car}^{(l)}) + w_{cdr}^{(l)} \text{cdr}(T_{cdr}^{(l)}) + w_{cons}^{(l)} \big(\text{cons}(T_{cons0}^{(l)}, T_{cons1}^{(l)}) + s^{(l)} \otimes r_{root}\big) O(l)=wcar(l)car(Tcar(l))+wcdr(l)cdr(Tcdr(l))+wcons(l)(cons(Tcons0(l),Tcons1(l))+s(l)⊗rroot)
最后,这个输出 TPR 向量 O ( l ) O^{(l)} O(l) 被写入树记忆的下一个顺序槽位,成为下一步计算的可用输入之一。整个过程持续固定的步数 L L L。最终,最后一步产生的树 O ( L ) O^{(L)} O(L) 被视为模型的预测输出树。
3.2. 端到端训练
DTM 是一个完全可微的模型,因此可以通过标准的反向传播进行端到端的训练。损失函数定义为预测输出树与目标树之间的均方误差(MSE)。具体来说,是对预测树和目标树中每个节点位置上的符号(填充物向量)计算 MSE。同时,对预测树中目标树为空的位置上的非零填充物进行 L2 惩罚,鼓励生成稀疏、明确的树结构。
L ( T p r e d , T t a r g e t ) = ∑ i ∈ Nodes ∥ recover ( T p r e d , r i ) − recover ( T t a r g e t , r i ) ∥ 2 + λ ∑ i : target node i is empty ∥ recover ( T p r e d , r i ) ∥ 2 \mathcal{L}(T_{pred}, T_{target}) = \sum_{i \in \text{Nodes}} \left\| \text{recover}(T_{pred}, r_i) - \text{recover}(T_{target}, r_i) \right\|^2 + \lambda \sum_{i: \text{target node } i \text{ is empty}} \left\| \text{recover}(T_{pred}, r_i) \right\|^2 L(Tpred,Ttarget)=i∈Nodes∑∥recover(Tpred,ri)−recover(Ttarget,ri)∥2+λi:target node i is empty∑∥recover(Tpred,ri)∥2
其中 recover ( T , r i ) \text{recover}(T, r_i) recover(T,ri) 是从 TPR 向量 T T T 中恢复位置 i i i 的填充物向量的操作(例如 T r i Tr_i Tri), λ \lambda λ 是惩罚系数。
T t a r g e t T_{target} Ttarget 是目标树(target tree),它来自用于训练模型的数据集。
例如,在 Active ↔ \leftrightarrow ↔ Logical (主动语态转逻辑形式) 任务中,数据集包含源树和对应的目标树。以下是一个来自数据集的例子:

这两个树的转变是从句法结构树 (Syntactic Tree) 到 逻辑形式树 (Logical Form Tree) 的转变。
- Source Tree (句法结构树): 它展示了句子的语法结构,即单词如何组成短语,短语如何组成句子。它反映了句子的表面结构。
S: 表示句子 (Sentence)NP: 表示名词短语 (Noun Phrase)VP: 表示动词短语 (Verb Phrase)DET: 表示限定词 (Determiner)AP: 表示形容词短语 (Adjective Phrase)N: 表示名词 (Noun)V: 表示动词 (Verb)ADJ: 表示形容词 (Adjective)- 树的结构显示了短语的层级关系,例如
( NP ( DET some ) ( AP ( N crocodile ) ) )表示 “some crocodile” 是一个名词短语,其中 “some” 是限定词,“crocodile” 是名词,而 “crocodile” 又被看作是一个形容词短语的头部 (在某些语法标注约定中可能会有这样的表示方式)。- Target Tree (逻辑形式树): 它试图表示句子的语义或意义结构。它关注句子中主要动词及其论元(Arguments),也就是谁做了什么,对谁做了什么。它反映了句子的深层结构或逻辑意义。
LF: 表示逻辑形式 (Logical Form)V: 表示动词 (这里是句子的主要动词)ARGS: 表示论元 (Arguments),也就是动词作用的对象或参与者。- 树的结构显示了动词 “washed” 是逻辑形式的核心,而它的论元是两个名词短语:
( NP ( DET some ) ( AP ( N crocodile ) ) )和( NP ( DET our ) ( AP ( ADJ happy ) ( AP ( ADJ thin ) ( AP ( N donkey ) ) ) ) ) )。这表示 “washed” 这个动作发生在 “some crocodile” 和 “our happy thin donkey” 之间。这种转变是从关注句子的表面语法结构到关注句子的语义关系的抽象过程。
在这个例子中, T t a r g e t T_{target} Ttarget 就是上述的 Target Tree。模型训练的目标是使预测树 T p r e d T_{pred} Tpred 尽可能接近这个目标树 T t a r g e t T_{target} Ttarget。损失函数衡量了预测树在每个节点上与目标树的差异,并惩罚了在目标树中为空但在预测树中被填充的节点。
通过最小化这个损失,神经树 Agent 学会选择合适的操作和参数,从而引导可微树解释器执行一系列有效的树转换步骤,最终生成目标树。这种设计巧妙地结合了神经网络的灵活性和符号操作的结构性。
4. 实验验证
实验是检验模型优劣的唯一标准。这篇论文设计了一系列合成的树到树转换任务,尤其侧重考察模型在分布外(Out-of-Distribution, OOD) 的组合泛化能力。
4.1. 实验结果
论文在合成数据集(Basic Sentence Transforms)上评估了 DTM 与多种基线模型,包括 Transformer、LSTM 及其树结构变体 (Tree2Tree LSTM, Tree Transformer)。这些任务包括根据 Lisp 操作符序列转换树 (CAR-CDR-SEQ),以及主动语态 / 被动语态到逻辑形式的转换 (ACTIVE↔LOGICAL, PASSIVE↔LOGICAL, ACTIVE & PASSIVE→LOGICAL)。数据集精心构造了 OOD 词汇 ( 未见过的词汇出现在训练过的结构位置 ) 和 OOD 结构 ( 未见过的结构组合,例如更深的树或新的子结构组合 ) 划分。
实验结果令人瞩目:在大多数任务的 OOD 词汇和 OOD 结构测试集上,DTM 都取得了接近 100% 的准确率。相比之下,所有基线模型在 OOD 结构泛化上表现惨淡,准确率普遍低于 30%,在一些语言转换任务上甚至接近 0%。
这有力地证明了 DTM 在处理结构化数据的组合泛化方面具有显著优势。其关键在于,DTM 学习的是如何组合基本的可微结构操作,而不是仅仅学习输入和输出序列或树结构的关联模式。这种学习策略使其能够推广到由已知元素组成但以新方式组合的结构。
4.2. 消融实验
为了理解 DTM 成功的原因,论文进行了一些关键的消融实验:
- 预定义操作 vs. 学习操作: 如果不使用预定义的、基于 TPR 的可微 car, cdr, cons 操作,而是让神经树 Agent 去学习这些结构转换矩阵 D c , E c D_c, E_c Dc,Ec,模型在 OOD 结构泛化上的性能急剧下降。这证明了预定义结构化可微操作的必要性。这些预定义操作提供了正确的归纳偏置,确保了模型学习到的是真正的结构转换逻辑,而不是对特定训练结构的记忆。
- 混合 vs. 离散选择: 前面提到,神经树 Agent 使用 softmax 进行软选择。如果强制使用 Gumbel-Softmax 使选择在训练初期就变得离散,DTM 的性能会完全崩溃。这反直觉地表明,训练初期的连续混合(Blending) 是必要的。它可能允许模型在不同操作和输入树之间进行探索,构建平滑的损失面,从而更容易找到有效的操作序列。最终收敛时,选择趋于离散,恢复了程序的解释性。
这两个消融实验从机制上解释了 DTM 成功的两个策略:提供正确的结构性“积木”(预定义操作)和采用有效的学习策略(训练中的混合)。
4.3. 可解释性
DTM 的另一个重要优势是其可解释性(Interpretability) 。由于最终模型的操作选择权重趋于 one-hot,我们可以将 DTM 的推理过程解释为一系列离散的树操作序列,就像一个程序。
例如,在 CAR-CDR-SEQ 任务中,模型学习到如何根据输入的 Lisp 操作符 token 转化为执行相应的 car/cdr 序列。在语言转换任务中,可以追踪每一步记忆中树的变化以及应用的具体操作。论文中给出了逻辑形式到被动语态转换的例子(论文 Figure 5),清晰地展示了输入树如何通过一系列 car, cdr, cons 操作逐步转换为输出树。

更有趣的是,论文通过追踪这个“程序”执行流,发现了模型emergent operation。在 PASSIVE↔LOGICAL 任务中,目标树需要插入源树中不存在的词(如 “was” 和 “by”)。car, cdr, cons 本身并不能直接插入新节点。但模型学会了一个技巧:通过对一个单子节点树执行 car 得到一个空树(empty tree) 的 TPR 表示,然后将这个空树作为 cons 的子树,并提供新的填充物作为根节点,从而有效地“插入”了一个新节点(如插入 “was”)。这种从基本操作中组合出更复杂行为的能力,以及能够通过追踪中间步骤来发现这种行为,是 DTM 可解释性的体现。
5. 总结/局限/展望
论文的核心思想是将传统的、离散的符号操作(例如树操作)通过张量积表示(TPR)嵌入到一个连续且可微的空间中。这样做并非仅仅是让操作本身连续化,并进一步使得神经网络能够通过基于梯度的学习方法,学会如何智能地组合和应用这些(现在是可微的)符号操作序列,从而学习到解决特定问题的“算法”或“程序”。
这与传统的符号主义方法形成对比,后者通常需要人工专家来设计和编码操作序列(即算法)。DTM 中的神经树代理正是负责学习这个“操纵符号操作”的“算法”。
DTM 的架构可以被形象地理解为给神经网络提供了一个包含特定“符号表示”(TPR编码的树)和“符号操作”(car, cdr, cons 的可微实现)的工具箱。神经网络(神经树代理)的任务就是通过学习,掌握如何有效地使用这个工具箱中的工具(选择合适的操作、作用于记忆中的树)来将输入的树转换成目标的树,从而解决任务。通过在大规模数据上训练,神经网络学会了使用这些基本工具来构建更复杂的结构转换过程。
局限
论文很类似神经图灵机 (Neural Turing Machine, NTM) 模仿图灵机一样,通过引入一个有意的结构偏置,带来了可解释性和泛化能力的优势,但也可能限制了模型能够解决的问题范围和学习到的算法的类型。论文最后也提到了这一点,例如当前模型局限于树结构输入输出、共享词汇表以及预设的最大树深度等,并提出未来可以探索其他树函数或数据结构。
论文中使用的 car, cdr, cons 操作是基于 Lisp 语言的基础操作,并且 TPR 表示的设计也针对二叉树结构。这些工具是基于对符号操作和树结构的理解而人为定义的。虽然这些操作被证明在论文研究的任务上非常有效,特别是在组合泛化方面,但它们可能不足以表达或高效地执行所有可能的树操作或更广义的符号操作。