本节重点
- 块、块组、分区的引入
- 块组的构成
- inode与inode Table
- 路径解析与路径缓存机制
- 目录与文件名在文件系统中的存储
- 分区的初始化与挂载
一、ext2文件系统
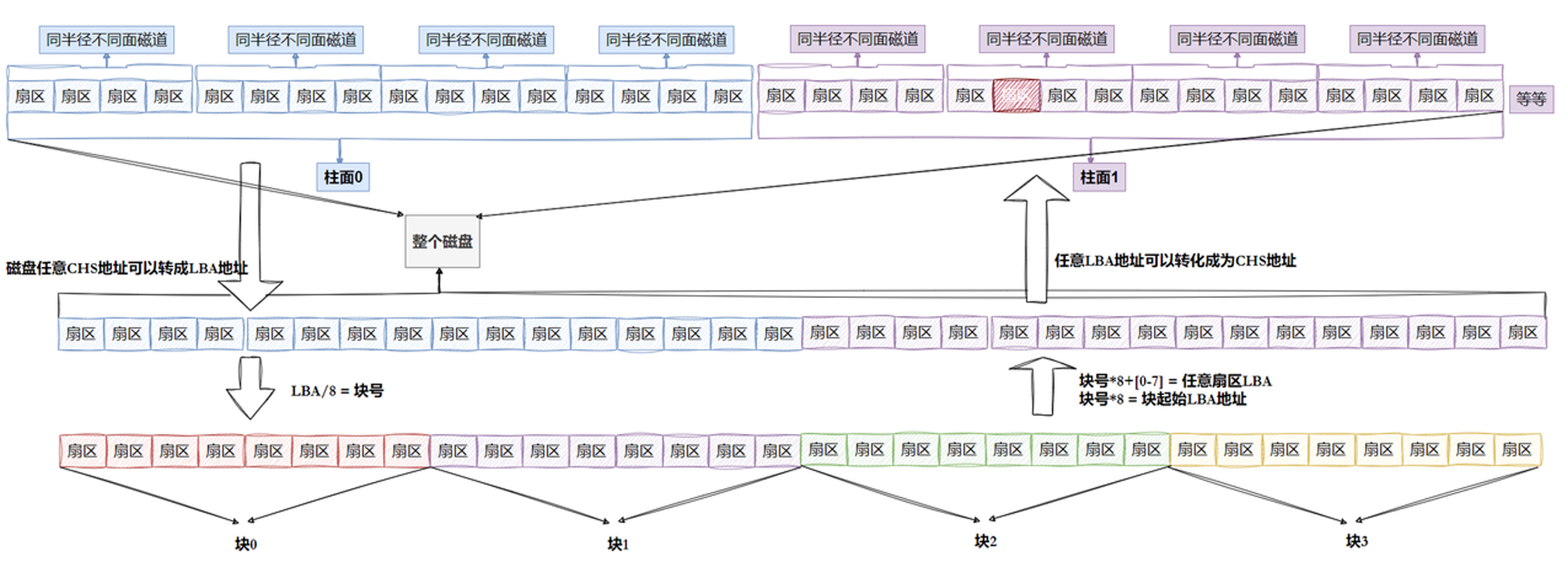
1.1 “块”的引入
在前言部分我们说扇区是磁盘硬件的最小读写单位,通常为512字节,但是在操作系统读取硬盘数据的时候不会通过读取一个一个扇区的方式完成读写操作,单个扇区的读写操作效率较低。现代存储设备如硬盘和固态硬盘(SSD)通常具有较高的延迟和较低的吞吐量。每次读写操作都需要进行寻址、旋转等待和数据传输,这些操作的开销较大。
在读取硬盘数据的时候操作系统会一次性读取多个扇区,即一次性读取一个“块”。一个“块”的大小是初始化的时候就确定的,是不可更改的。
块的大小通常是4kb,即8个扇区组成一个“块”,块是文件存取的最小单位。
1.2 “块组”的引入
在ext2文件系统中,块组(Block Group)是将多个块组合在一起,形成的一个更大的管理单元。每个块组包含一定数量的数据块、inode表、位图等信息。
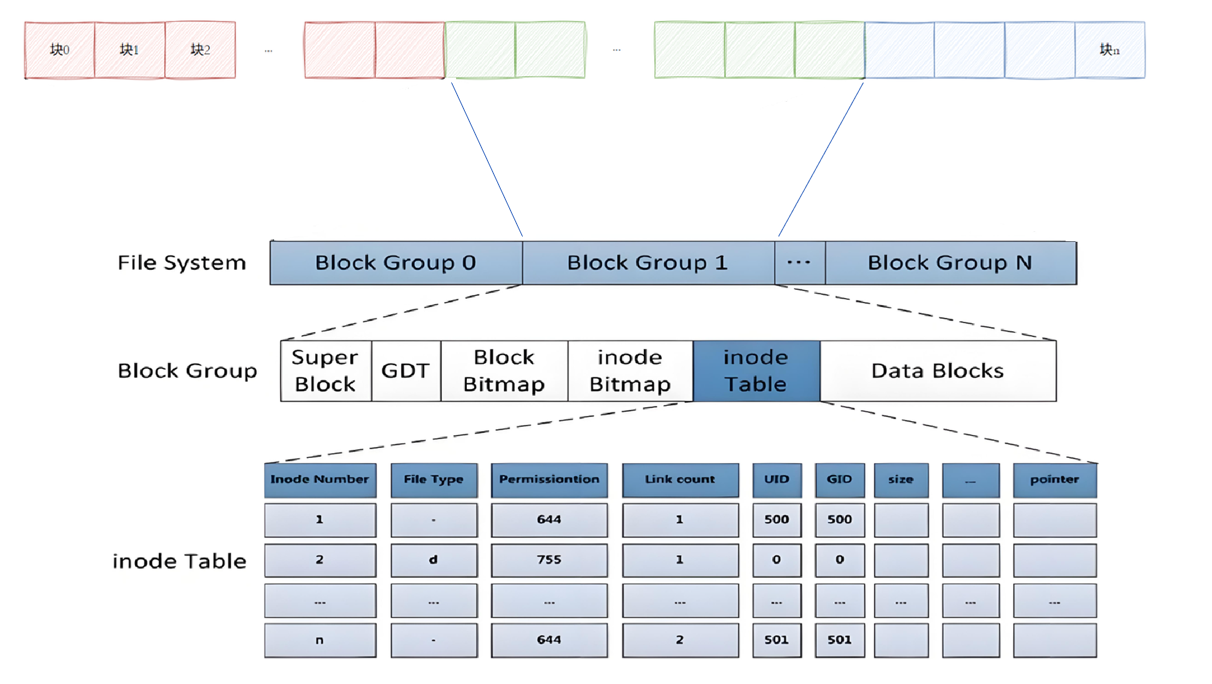
每个块组通常包含以下部分:
- 超级块(Superblock):存储文件系统的全局信息,如块大小、inode数量等。
- 组描述符(Group Descriptor):描述块组的元数据,如块组中空闲块和inode的数量。
- 数据块位图(Block Bitmap):记录块组中哪些数据块已被使用。
- inode位图(inode Bitmap):记录块组中哪些inode已被使用。
- inode表(inode Table):存储文件元数据,如文件大小、权限、所有者等。
- 数据块(Data Blocks):实际存储文件数据的地方。
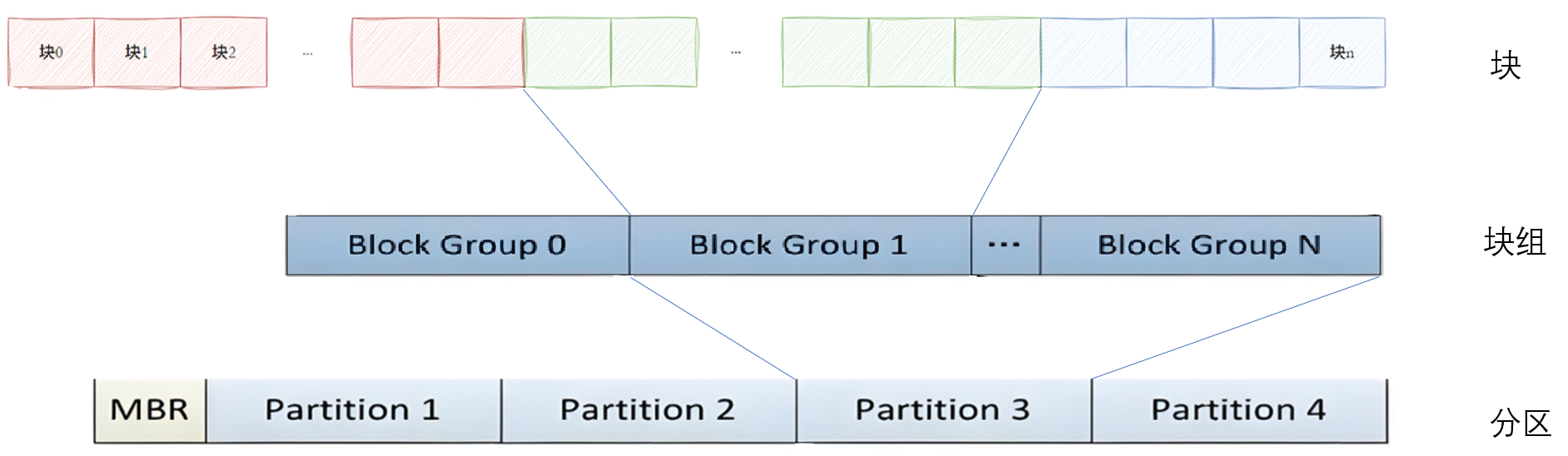
1.3 “分区”的引入
分区是硬盘或存储设备上被逻辑划分的区域,每个分区可以独立管理和使用。每个分区都是由许多个块组构成的。每个分区可以安装不同的操作系统或存储不同类型的数据。
二、详解块组
2.1 inode与inode Table
之前我们说过:文件=内容+属性,当我们使用ls -l的时候不仅可以看到文件名,当然也可以看到文件的元数据(属性)。
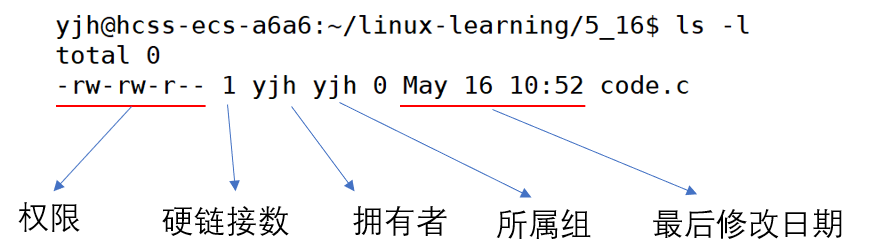
文件的内容与元数据存储在磁盘中,ls -l命令读取存储在磁盘的文件信息然后显示出来:

这种信息除了通过这种方式来获取之外,我们还可以通过stat命令看到更多信息:
 2.1.1 inode
2.1.1 inode
在磁盘中除了存储文件内容也需要存储文件的元数据,这就说明操作系统除了给文件内容分配足够的数据块,也要给文件的元数据分配相应的数据块。
为了高效管理文件的元数据,操作系统在内核中引入了 inode(索引节点)数据结构。inode 本身在底层通常是一个结构体(struct)存储了文件的元数据,包括文件大小、文件权限、文件所有者、文件组、文件类型、文件链接数、文件的时间戳(如创建时间、修改时间、访问时间)以及文件数据块的指针。具体实现可能因操作系统和文件系统的不同而有所差异。
每个Inode的大小通常为128字节或256字节。
在 Linux 内核中,inode 结构体定义在 include/linux/fs.h 文件中。以下是一个简化的示例:
struct inode {
unsigned long i_ino; // inode 编号
umode_t i_mode; // 文件类型和权限
uid_t i_uid; // 所有者用户 ID
gid_t i_gid; // 所有者组 ID
loff_t i_size; // 文件大小
struct timespec i_atime; // 最后访问时间
struct timespec i_mtime; // 最后修改时间
struct timespec i_ctime; // 最后状态改变时间
unsigned long i_blocks; // 文件占用的块数
struct address_space *i_mapping; // 文件数据块的映射
unsigned long i_data[15]; // 数据块指针
};
一个文件只能对应一个inode,在inode中除了存储对应文件的元数据外还存储了inode号,inode号用来确定唯一的一个inode。在命令行中可以通过ls -li来查看到文件信息与其对应的inode号:

注意:inode中不存储文件名
inode号的分配机制:
分区中的inode号是唯一的,inode号的作用范围仅限于其所在的分区,不同分区inode号可能重复。
在同一分区的不同块组中,inode号的分配考虑块组的负载均衡,将文件和目录均匀地分布在不同的块组中。
同一块组中,inode号是唯一的,不可重复的。
2.1.2 inode Table
Inode Table(索引节点表)是文件系统中用于存储文件元数据的数据结构。每个文件或目录在文件系统中都有一个对应的Inode,Inode Table则是这些Inode的集合。
Inode Table通常是一个固定大小的数组,每个数组元素对应一个Inode。每个Inode的大小是固定的,具体大小取决于文件系统的设计,通常为128字节或256字节。
当文件系统需要访问一个文件时,首先会通过文件名找到对应的inode号,然后通过根据inode号通过相关算法确定所在的块组,在该块组中的inode Table找到对应inode号所对应的inode,这样我们就找到了要访问文件的内容与所对应的元数据(属性)。
inode Table的作用
在文件系统中inode Table(索引节点表)主要提供索引的功能,具体来说就是当用户访问某一文件时,操作系统会将该文件inode号与具体inode结构体通过inode Table快速索引。
2.2 Data Blocks
在ext2文件系统中,Data Blocks是用于存储实际文件数据的部分。每个文件或目录的内容都存储在一个或多个Data Blocks中。在ext2文件系统中,Data Blocks(数据块)占据了块组的主要部分,因为文件内容通常比元数据大得多。
Data Blocks表示数据块的集合,这不过这部分数据块用来存储文件内容。
inode与文件内容(data blocks)的映射
在Linux系统中,文件的内容与属性(元数据)是分开存储的。元数据存储在inode中,而文件的内容则存储在数据块中,这些数据块分布在磁盘的不同位置。文件系统通过inode中的指针来映射文件的实际数据块的。
相关数据结构:
#define EXT2_N_BLOCKS 15 struct ext2_inode { // 其他字段... __le32 i_block[EXT2_N_BLOCKS]; // 指向数据块的指针数组 // 其他字段... };这里
i_block是一个数组,用于存储指向数据块的指针。EXT2_N_BLOCKS是一个常量,通常定义为 15,表示i_block数组的大小。这个数组用于管理文件的数据块。其中i_block数组前12个元素是直接块指针,指向文件的实际数据块。接下来的 3 个元素分别是一级间接块指针、二级间接块指针和三级间接块指针。
这些间接块指针不会直接指向数据块,而是指向一个指针的集合,这个集合中的指针都指向实际数据块或者另一个间接块指针(如果还需要数据块来存储文件内容)。
- 一级间接指针:指向一个包含数据块指针的块。
- 二级间接指针:指向一个包含一级间接指针的块。
- 三级间接指针:指向一个包含二级间接指针的块。
通过这种方式,文件系统可以有效地管理非常大的文件,而不需要为每个文件存储大量的直接指针。
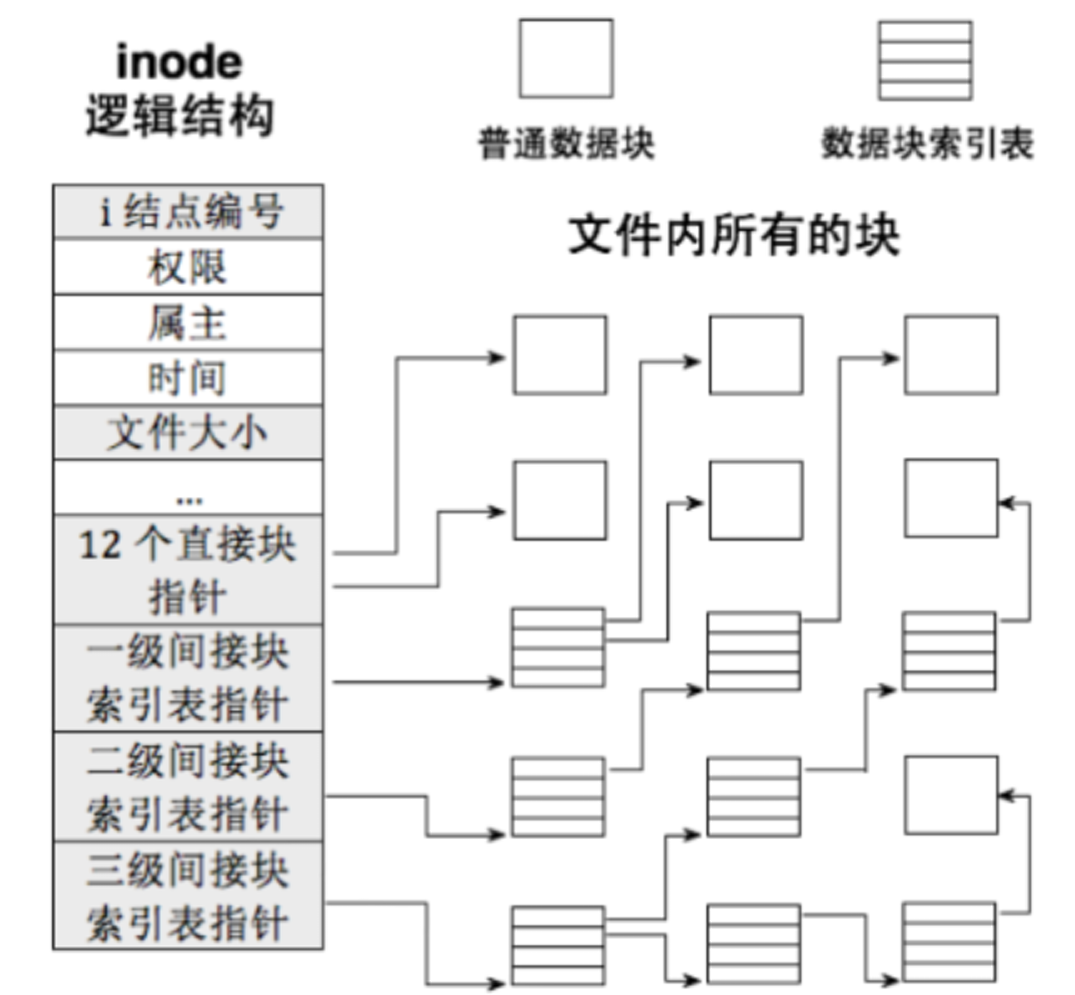
通过inode与文件内容(data blocks)的映射,我们发现当我们拿到一个文件具体的inode时文件内容与文件属性就已经确定了。
2.3 inode Bitmap 与 Block Bitmap
在文件系统中,inode Bitmap和 inode Bitmap是用于管理存储资源的重要数据结构。它们分别用于跟踪 inode和数据块的使用情况。通过 inode Bitmap 和 inode Bitmap,文件系统能够高效地管理存储资源,确保数据的快速存取和存储空间的合理利用。
2.3.1 inode Bitmap
inode Bitmap是一个位图结构,用于表示inode Bitmap的使用状态。每个位对应一个inode,如果该位为 1,表示对应的inode已被使用;如果为 0,则表示该 inode空闲。
作用:inode Bitmap用于快速查找和分配空闲的inode,从而提高文件系统的效率。
示例:假设一个文件系统有 1024 个 inode,那么 inode Bitmap将包含 1024 位,每个位对应一个 inode的状态。
2.3.2 Block Bitmap
Block Bitmap 同样是一个位图结构,用于表示数据块的使用状态。每个位对应一个数据块,如果该位为 1,表示对应的数据块已被使用;如果为 0,则表示该数据块空闲。
作用:Block Bitmap 用于快速查找和分配空闲的数据块,确保文件系统能够高效地管理存储空间。
示例:假设一个文件系统有 4096 个数据块,那么 Block Bitmap 将包含 4096 位,每个位对应一个数据块的状态。
2.4 GDT
GDT用于存储块组的描述信息,包括块组的起始块、块组的空闲块数、块组的inode表位置等。GDT的存在使得文件系统能够高效地管理和分配磁盘空间。
GDT通常是一个数组,每个元素描述一个块组的信息。在ext文件系统中,GDT的每个条目包含以下信息:
- 块组的起始块号
- 块组的空闲块数
- 块组的inode表位置
- 块组的位图位置
查看GDT信息:
在Linux系统中,可以使用
dumpe2fs命令查看ext文件系统的GDT信息。以下是一个示例命令:dumpe2fs /dev/sda1 | grep -i "group descriptors"该命令会输出文件系统中所有块组的描述符信息,包括每个块组的起始块号、空闲块数等。
总的来看,GDT中主要存储整个所在块组的描述信息,包括块组中inode Table,inode Bitmap,Block Bitmap等区域的起始与终止位置,整个块组中数据块的使用情况等信息。
2.5 Super Block
前面我们讲过,文件系统的基本单位是分区,一块磁盘上会被划分为多个分区。每个分区可以独立格式化并使用不同的文件系统。
Super Block 是文件系统中的一个关键数据结构,用于存储文件系统的元数据。它通常位于文件系统的开头,包含文件系统的整体信息,如大小、块大小、inode 数量等。Super Block 是文件系统管理和维护的基础。
Super Block 通常包含以下信息:
- 文件系统类型:标识文件系统的类型,如 ext2、ext3、ext4 等。
- 块大小:文件系统中每个块的大小,通常为 1KB、2KB、4KB 等。
- 总块数:文件系统中总的块数。
- 空闲块数:当前可用的空闲块数。
- inode 数量:文件系统中 inode 的总数。
- 空闲 inode 数:当前可用的空闲 inode 数。
- 挂载信息:文件系统的挂载状态、挂载时间等。
- 文件系统状态:文件系统的状态信息,如是否干净关闭、是否需要检查等。
在 Linux 的 ext2/ext3/ext4 文件系统中,Super Block 的结构可能如下所示:
struct ext2_super_block {
uint32_t s_inodes_count; // 文件系统中 inode 的总数
uint32_t s_blocks_count; // 文件系统中块的总数
uint32_t s_r_blocks_count; // 保留块数
uint32_t s_free_blocks_count; // 空闲块数
uint32_t s_free_inodes_count; // 空闲 inode 数
uint32_t s_first_data_block; // 第一个数据块的块号
uint32_t s_log_block_size; // 块大小的对数
uint32_t s_log_frag_size; // 片段大小的对数
uint32_t s_blocks_per_group; // 每个块组中的块数
uint32_t s_frags_per_group; // 每个块组中的片段数
uint32_t s_inodes_per_group; // 每个块组中的 inode 数
uint32_t s_mtime; // 最后一次挂载时间
uint32_t s_wtime; // 最后一次写入时间
uint16_t s_mnt_count; // 挂载次数
uint16_t s_max_mnt_count; // 最大挂载次数
uint16_t s_magic; // 文件系统魔数
uint16_t s_state; // 文件系统状态
uint16_t s_errors; // 错误处理方式
uint16_t s_minor_rev_level; // 次版本号
uint32_t s_lastcheck; // 最后一次检查时间
uint32_t s_checkinterval; // 检查间隔时间
uint32_t s_creator_os; // 创建文件系统的操作系统
uint32_t s_rev_level; // 版本号
uint16_t s_def_resuid; // 默认保留用户 ID
uint16_t s_def_resgid; // 默认保留组 ID
// 其他字段...
};
这里需要注意的是,Super Block保存整个文件系统的描述信息,而GDT保存所在块组的描述信息
***为什么描述整个文件系统的Super Block会存在于块组中呢?
关键1:Super Block对于整个文件系统至关重要
Super Block 是文件系统的核心数据结构,记录了整个文件系统的关键信息,如文件系统的大小、块大小、空闲块的数量、inode 的数量等。这些信息对于文件系统的初始化和运行至关重要。
如果 Super Block 只存在于文件系统的开头,一旦该区域损坏,整个文件系统将无法访问。
关键2:通过备份提高可靠性和恢复能力
这里我们需要明白的是,不是所有块组中都包含了Super Block。
当整个文件系统遭到损坏和数据丢失时,通过在多个块组中复制 Super Block,即使某个块组的 Super Block 损坏,其他块组中的备份仍可确保文件系统的正常访问。
三、目录与文件名
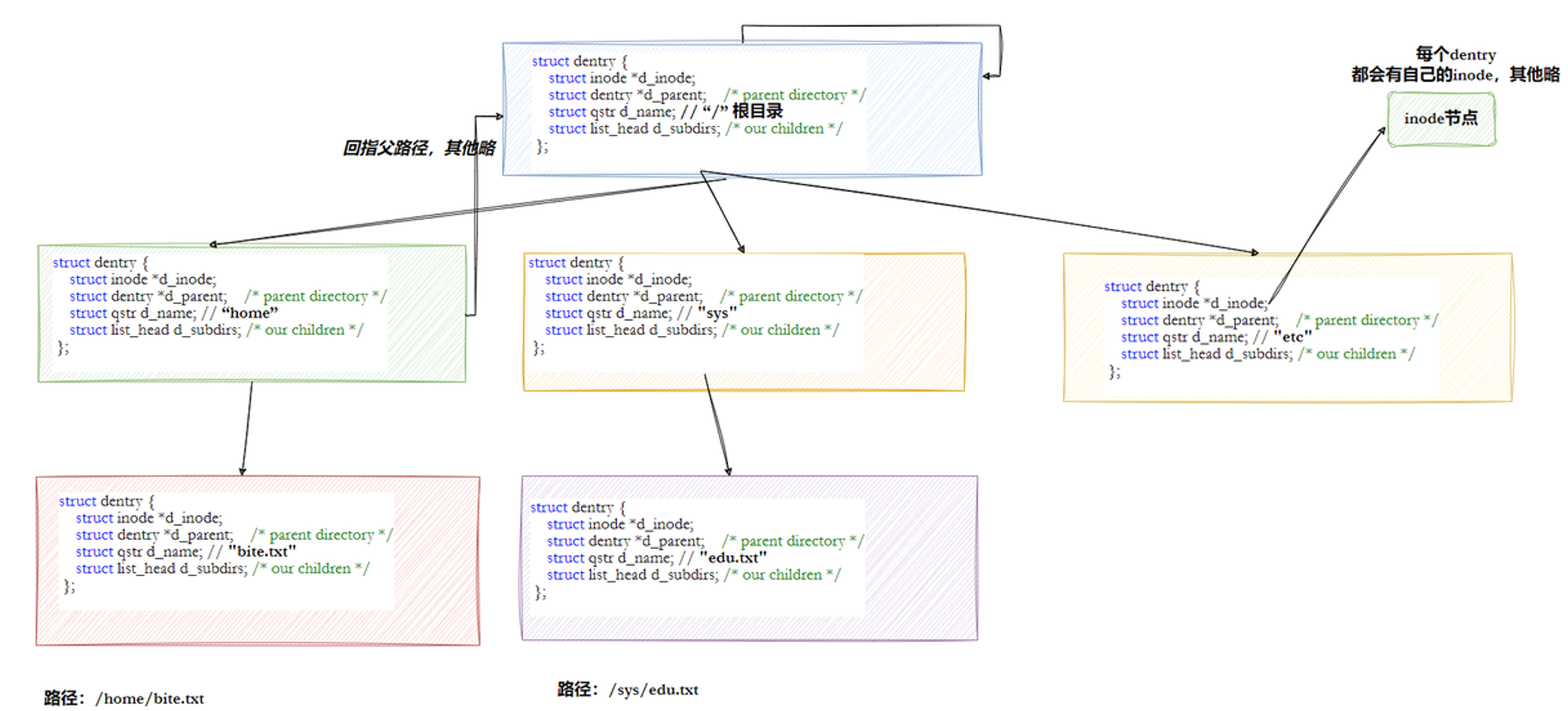
在之前我们了解到,操作系统只要找到对应文件的inode就可以确定文件的属性和内容。但是在实际上用户只会给提供文件名并不会提供inode号。
目录也是文件,在磁盘中没有目录的概念只有文件属性+文件内容的概念。而目录的元数据保存在对应的inode中,目录的文件内容就是:文件名与inode号的映射关系。
所以访问文件的时候,当用户(进程)提供了一个文件名时操作系统就会打开当前目录,根据文件名查找对应的inode号,然后进行后续文件访问。
比如我们通过:
ls -li code.cc打印所在目录中code.cc的属性信息时,操作系统首先会打开当前工作目录,查找code.cc对应的inode号进而对文件进行访问。
3.1 路径解析

当我们需要打印/home/yjh/linux-learning/5_17/code.cc文件的属性信息时,操作系统并非直接访问5_17目录的内容来获取code.cc的inode号。由于5_17本身也是一个文件名,系统需要先确定其对应的inode号。这一过程需要逐级回溯:首先访问linux-learning目录的内容以获取5_17的inode号,接着访问yjh目录的内容以获取linux-learning的inode号,然后访问home目录的内容以获取yjh的inode号,最终通过打开根目录/来获取home的inode号
最终结论:任何文件都有路径,访问目标文件都要从/(更)目录开始,依次访问每个目录下指定的目录直到访问到目标文件(目录),这个过程就叫做路径解析。
3.2 路径缓存
在实际上并不是每次访问目标文件都会从/(根目录)开始进行路径解析,操作系统通过路径缓存缓存已经解析过的路径信息,加速文件路径查找的机制,减少重复查找目录项(dentry)的开销,从而提高文件系统的访问效率。
在Linux系统,在内核中维护树状路径结构的内核结构体叫做:struct dentry
在路径解析的过程中,操作系统会将遇到的文件inode创建dentry结构并链入树形结构,同时该dentry还属于一个LRU链表和哈希表。前者提供淘汰机制移除最久未使用的数据来管理缓存空间,后者方便快速查找:
struct dentry {
atomic_t d_count; // 引用计数
unsigned int d_flags; // 目录项的标志
spinlock_t d_lock; // 自旋锁,用于保护该结构
struct inode *d_inode; // 关联的 inode
struct hlist_node d_hash; // 哈希表节点
struct dentry *d_parent; // 父目录项
struct qstr d_name; // 目录项的名称
struct list_head d_lru; // LRU 链表
struct list_head d_child; // 子目录项链表
struct list_head d_subdirs; // 子目录项链表
struct dentry_operations *d_op; // 目录项操作函数指针
struct super_block *d_sb; // 所属的超级块
void *d_fsdata; // 文件系统私有数据
unsigned char d_iname[DNAME_INLINE_LEN]; // 内联名称
};
这个由struct dentry节点组成的树形结构,整体组成了Linux的路径缓存机制,打开或访问任何文件都在先在这棵树下根据路径进行查找,找到就返回属性inode和内容,没找到就从磁盘加载路径,添加dentry节点,缓存新路径。
四、分区的初始化与挂载
分区创建后,磁盘空间被划分为独立的区域,但这些区域尚未包含任何文件系统。操作系统无法识别或访问这些分区中的数据,因为它们没有文件系统来管理数据的存储和检索。
在使用分区之前,需要为其创建文件系统。文件系统是用于管理文件和目录的结构,常见的文件系统包括 ext4、NTFS、FAT32 等。通过格式化分区,可以为其初始化文件系统。
mkfs.ext4 /dev/sdX1
文件系统初始化后,需要将分区挂载到操作系统的目录树中,才能访问和使用。挂载是将分区与特定目录关联的过程,使得该目录成为分区的访问点。通过挂载,操作系统可以访问和管理该分区上的文件和目录。
挂载的方法:
在 Linux 系统中,挂载分区通常使用 mount 命令。以下是一个示例:
sudo mount /dev/sdb1 /mnt/data
上述命令将/dev/sdb1分区挂载到/mnt/data目录。
挂载使得存储设备的内容可以被操作系统识别和访问。将一个硬盘分区挂载到 /mnt/data 目录后,所有对该目录的访问实际上是对该分区内容的访问。
注意事项
挂载时需确保挂载点目录存在且为空,否则可能会导致数据冲突或丢失。