深度学习是自然语言处理中最核心的技术路径之一。本文将实现三个具有代表性的深度学习应用场景:
- 信息检索系统(
Information Retrieval):利用深度语义匹配模型,实现用户查询与文档之间的精准匹配。 - 文本分类(
Text Classification):使用 CNN、RNN、LSTM 等神经网络架构,对情感、主题、类别等进行自动识别。 - 序列预测(
Next Word Prediction):基于 LSTM 构建智能输入法或邮件自动补全系统。
1 基于词向量的文档信息检索系统
信息检索(Information Retrieval)是 NLP 中应用最广、挑战性极强的领域之一。传统检索依赖关键词匹配,但实际应用中,我们还需要理解上下文与语义 —— 即便查询词与文档词不同,也应能理解其“意思相近”。
目标
通过用户的查询文本,使用 词向量(word embeddings) 实现文档的相关性排序与检索。
解决方案
我们将使用 Word2Vec 的预训练词向量来构建文档表示与查询表示,并利用余弦相似度(cosine similarity)衡量两者之间的语义接近程度,完成检索任务。
步骤
1.导入所需库
import gensim
from gensim.models import Word2Vec
import numpy as np
import nltk
from nltk.tokenize.toktok import ToktokTokenizer
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
import re
import scipy
from scipy import spatial
nltk.download('stopwords')
nltk.download('punkt_tab')
2.准备示例文档与查询
这里我们定义了四段文本(Doc1 到 Doc4),每段都是一个包含一个字符串的列表。然后把所有文档合并在一起,形成一个大的文档列表,准备作为输入语料。
Doc1 = ["With the Union cabinet approving the amendments..."]
Doc2 = ["Natural language processing (NLP) is an area..."]
Doc3 = ["He points out that public transport is very good..."]
Doc4 = ["But the man behind the wickets at the other end..."]
fin = Doc1 + Doc2 + Doc3 + Doc4
query = "cricket"
3.加载预训练词向量模型
需从 Google 下载 Word2Vec 预训练模型:
model = gensim.models.KeyedVectors.load_word2vec_format(
'/GoogleNews-vectors-negative300.bin', binary=True)
4.构建信息检索系统
(1)文本预处理
tokenizer = ToktokTokenizer() # 初始化 Toktok 分词器,用于将文本分割成单词(tokens)
stopword_list = stopwords.words('english') # 获取英文停用词列表,比如 "the", "is", "at" 等常见无意义词
def remove_stopwords(text):
text = re.sub(r'[^a-zA-Z0-9\s]', '', text) # 用正则表达式去除非字母数字和空格的字符(例如标点符号)
tokens = tokenizer.tokenize(text) # 使用 Toktok 分词器将处理后的文本进行分词
# 过滤掉分词结果中的停用词,并将剩下的词重新拼接成一个字符串
return ' '.join([token for token in tokens if token.lower() not in stopword_list])
(2)获取词向量
根据词是否存在于词向量模型中,返回其对应的向量;如果不存在,则返回全零向量(300维)。
def get_embedding(word):
if word in model:
return model[word]
else:
return np.zeros(300)
(3)获取文档平均向量
对每条文本,先移除停用词并分词,再获取所有词的词向量,最后取平均作为整条文本的向量表示。
out_dict = {}
for sen in fin:
avg_vector = np.mean(
np.array([get_embedding(x) for x in nltk.word_tokenize(remove_stopwords(sen))]),
axis=0
)
out_dict[sen] = avg_vector
(4)计算相似度并排序文档
def get_sim(query_embedding, doc_vector):
return [(1 - spatial.distance.cosine(query_embedding, doc_vector))]
def Ranked_documents(query):
query_vector = np.mean(
np.array([get_embedding(x) for x in nltk.word_tokenize(query.lower())]),
axis=0
)
rank = [(k, get_sim(query_vector, v)) for k, v in out_dict.items()]
return sorted(rank, key=lambda x: x[1], reverse=True)
5.测试结果
例:查询 cricket(板球)
Ranked_documents("cricket")
返回结果:

系统根据文本向量与查询向量的相似度对所有文档进行了排序,其中与板球相关的那句(“wickets” 出现)相似度最高(约 0.42),说明向量表示和相似度计算基本合理反映了语义相关性。
应用场景
此方法可以扩展至大规模文档集,适用于以下任务:搜索引擎、文档检索与排序、段落级匹配和问答系统中的上下文定位
总结建议
- 使用特定领域的词向量会获得更好的效果(比如法律、医疗)
- 长查询语效果更佳,短查询容易语义缺失
- 可以结合深度匹配模型(如 DSSM、BERT)进一步增强
2 文本分类(Spam/Ham)
本节我们使用 CNN、RNN、LSTM 和双向 LSTM 来实现电子邮件的垃圾/非垃圾文本分类,预测邮件是 spam(垃圾邮件) 还是 ham(正常邮件)。
- 数据集下载:spam.csv
数据预处理
首先对垃圾邮件数据集进行清洗和预处理,包括去停用词、小写化、去标点,并重新命名列名,为后续文本分类或分析任务做准备。
# 导入处理数据、文本清洗、停用词所需的库
import pandas as pd
import re
from nltk.corpus import stopwords
# 读取数据文件(spam.csv),使用 ISO-8859-1 编码避免编码错误
file_content = pd.read_csv('spam.csv', encoding="ISO-8859-1")
# 加载英文停用词列表,比如 "the", "and", "is" 等
stop = stopwords.words('english')
# 去除邮件文本中的停用词,只保留有意义的词
file_content['v2'] = file_content['v2'].apply(lambda x: " ".join(x for x in x.split() if x not in stop))
# 提取有用的两列:v1 为标签(是否是垃圾邮件),v2 为邮件内容
Email_Data = file_content[['v1', 'v2']]
# 重命名列名为更直观的名称:Target(标签)和 Email(文本)
Email_Data = Email_Data.rename(columns={"v1":"Target", "v2":"Email"})
# 文本统一小写,并用正则表达式去除常见标点符号
Email_Data['Email'] = Email_Data['Email'].apply(lambda x: re.sub('[!@#$:).;,?&]', '', x.lower()))
特征处理
下面我们将预处理后的邮件文本转化为神经网络可以使用的数字序列和标签向量,为后续的文本分类模型训练做好了输入准备。
# 从 sklearn 中导入数据集划分工具
from sklearn.model_selection import train_test_split
# 从 keras 中导入文本处理、序列填充和标签编码相关模块(建议用 tensorflow.keras 替代)
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
from sklearn.preprocessing import LabelEncoder
from keras.utils import to_categorical
# 将清洗后的邮件数据 Email_Data 按 80% 训练集 / 20% 测试集 划分
train, test = train_test_split(Email_Data, test_size=0.2)
# 设置最大序列长度为 300,最多考虑 20000 个词汇(词频排名前 20000)
MAX_SEQUENCE_LENGTH = 300
MAX_NB_WORDS = 20000
# 初始化一个分词器,限制词汇数量在 MAX_NB_WORDS 以内
tokenizer = Tokenizer(num_words=MAX_NB_WORDS)
# 用训练集的文本建立词汇表
tokenizer.fit_on_texts(train.Email)
# 将训练集文本转化为词索引序列
train_seq = tokenizer.texts_to_sequences(train.Email)
# 将测试集文本也转化为词索引序列
test_seq = tokenizer.texts_to_sequences(test.Email)
# 对训练集序列进行填充,使所有序列长度一致(不足补0,超出截断)
train_data = pad_sequences(train_seq, maxlen=MAX_SEQUENCE_LENGTH)
# 同理,对测试集进行序列填充
test_data = pad_sequences(test_seq, maxlen=MAX_SEQUENCE_LENGTH)
# 初始化标签编码器,将文本标签(如 "spam", "ham")转换为数字标签(如 0, 1)
le = LabelEncoder()
# 编码训练集标签
train_labels = le.fit_transform(train['Target'])
# 用相同编码器处理测试集标签
test_labels = le.transform(test['Target'])
# 将训练集标签转为独热编码格式,用于神经网络分类任务(例如 [0,1]、[1,0])
labels_train = to_categorical(train_labels)
# 同样地对测试集标签进行独热编码
labels_test = to_categorical(test_labels)
CNN 模型构建与训练
from keras.models import Sequential
from keras.layers import Embedding, Conv1D, MaxPooling1D, Flatten, Dense, Dropout, BatchNormalization
model = Sequential()
model.add(Embedding(MAX_NB_WORDS, 100, input_length=MAX_SEQUENCE_LENGTH))
model.add(Dropout(0.5))
model.add(Conv1D(128, 5, activation='relu'))
model.add(MaxPooling1D(5))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Conv1D(128, 5, activation='relu'))
model.add(MaxPooling1D(5))
model.add(Dropout(0.5))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(2, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['acc'])
model.fit(train_data, labels_train, batch_size=64, epochs=5, validation_data=(test_data, labels_test))
RNN 模型训练
from keras.layers import SimpleRNN
model = Sequential()
model.add(Embedding(MAX_NB_WORDS, 100, input_length=MAX_SEQUENCE_LENGTH))
model.add(SimpleRNN(2))
model.add(Dense(2, activation='softmax'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(train_data, labels_train, batch_size=16, epochs=5, validation_data=(test_data, labels_test))
LSTM 模型训练
from keras.layers import LSTM
model = Sequential()
model.add(Embedding(MAX_NB_WORDS, 100, input_length=MAX_SEQUENCE_LENGTH))
model.add(LSTM(16, activation='relu', return_sequences=True))
model.add(Dropout(0.2))
model.add(BatchNormalization())
model.add(Flatten())
model.add(Dense(2, activation='softmax'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(train_data, labels_train, batch_size=16, epochs=5, validation_data=(test_data, labels_test))
Bidirectional LSTM 模型
from keras.layers import Bidirectional, GlobalMaxPool1D
model = Sequential()
model.add(Embedding(MAX_NB_WORDS, 100, input_length=MAX_SEQUENCE_LENGTH))
model.add(Bidirectional(LSTM(16, return_sequences=True, dropout=0.1, recurrent_dropout=0.1)))
model.add(Conv1D(16, kernel_size=3, padding="valid", kernel_initializer="glorot_uniform"))
model.add(GlobalMaxPool1D())
model.add(Dense(50, activation="relu"))
model.add(Dropout(0.1))
model.add(Dense(2, activation='softmax'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(train_data, labels_train, batch_size=16, epochs=3, validation_data=(test_data, labels_test))
模型评估
from sklearn.metrics import precision_recall_fscore_support, classification_report
pred = model.predict(test_data)
precision, recall, fscore, support = precision_recall_fscore_support(labels_test, pred.round())
print(classification_report(labels_test, pred.round()))
总结
四个模型的评估结果如下:
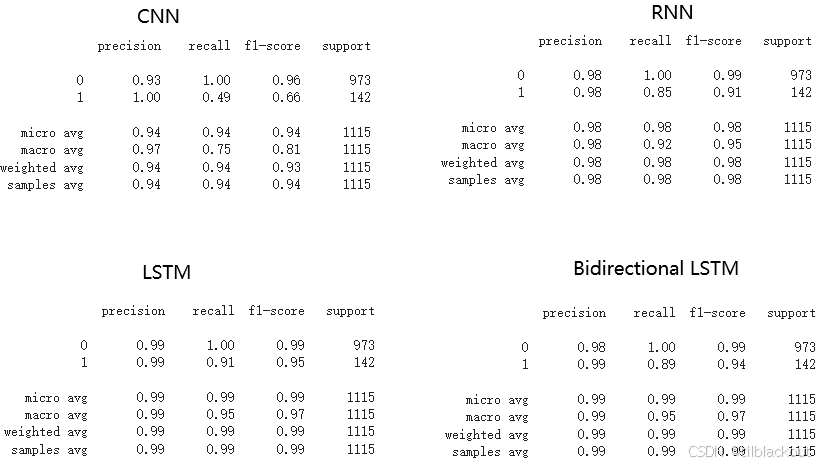
四个模型中,LSTM表现最优,整体精度高且在少数类(垃圾邮件)上的召回率达到 0.91,F1 分数为 0.95,显示出出色的平衡性和识别能力;相比之下,CNN对垃圾类的识别明显不足(召回率仅 0.49),而RNN 和 双向LSTM 表现也很好,但略逊于模型 LSTM,但双向LSTM在这只训练了3个epoch,增加epoch应该还能提高表现。
3 预测下一个词
我们想构建一个模型,根据电子邮件内容预测下一个可能出现的词语。这种功能在自动补全、邮箱建议回复中非常常见。这里我们使用 LSTM 模型学习电子邮件中词语的序列模式,根据已给词序列预测下一个词。
应用场景:自动回复推荐、智能输入法词语联想、聊天机器人生成式对话和搜索补全系统
数据集下载:spam.csv
1.加载并处理原始数据
import pandas as pd
# 返回的内容是一个 DataFrame 类型,存储在 file_content 中
file_content = pd.read_csv('spam.csv', encoding="ISO-8859-1")
# 从读取的数据中提取名为 'v2' 的这一列(邮件正文内容)
# 使用双中括号是为了保持结果为 DataFrame 格式
Email_Data = file_content[['v2']]
# 将 DataFrame 转换为二维列表,每一行是一个包含邮件正文的子列表
list_data = Email_Data.values.tolist()
2.文本预处理
将原始邮件文本数据合并成一个统一的纯文本字符串,然后进行清洗和分词处理,以准备后续的自然语言处理任务,如文本分析或分类。
from nltk.tokenize.toktok import ToktokTokenizer
import re
from collections.abc import Iterable
# 初始化一个 Toktok 分词器实例
tokenizer = ToktokTokenizer()
# 定义一个函数,用于将嵌套列表(如列表中的列表)展开成一维列表
def flatten(items):
for x in items:
# 如果当前元素是可迭代的(但不是字符串或字节类型),继续递归展开
if isinstance(x, Iterable) and not isinstance(x, (str, bytes)):
for sub_x in flatten(x):
yield sub_x
else:
# 否则直接产出当前元素
yield x
# 使用 flatten 函数展开原始的 list_data 列表(它是一个嵌套列表)
TextData = list(flatten(list_data))
# 将列表中的所有文本连接成一个长字符串,并去除换行符、转换为小写
TextData = " ".join(TextData).replace('\n', "").lower()
# 使用正则表达式去除所有非字母、数字和空格的字符(保留字母数字和空格)
TextData = re.sub(r'[^a-zA-Z0-9\s]', "", TextData)
# 使用 Toktok 分词器对清洗后的文本进行分词,并去除每个词的首尾空格
tokens = [token.strip() for token in tokenizer.tokenize(TextData)]
3.建立词典与序列数据
# 导入 collections 模块,用于计数和其他集合操作
import collections
# 使用 Counter 对词语列表 tokens 进行词频统计,结果是一个字典形式,键为词语,值为出现次数
word_counts = collections.Counter(tokens)
# 提取按频率排序后的词语(只取词,不取词频),并按字典序排序,得到不重复的词列表
distinct_words = sorted([x[0] for x in word_counts.most_common()])
# 创建一个词典,将每个词映射为一个唯一的索引值(从0开始编号)
word_index = {x: i for i, x in enumerate(distinct_words)}
# 设置句子的最大长度为 25,用于后续模型训练时统一句子长度
sentence_length = 25
4.构造训练样本
现在将词语序列转换为适用于序列预测模型的输入输出格式,通过滑动窗口构建训练样本,并将数据转为模型可接受的形状与编码方式,为后续训练神经网络做准备。
# 初始化输入数据和输出数据的空列表
InputData = []
OutputData = []
# 获取词汇总数(tokens 中单词的总数)
word_c = len(tokens)
# 遍历 tokens,按步长为1创建长度为 sentence_length 的序列作为输入,
# 下一个词作为对应的输出(即一个滑动窗口模型)
for i in range(0, word_c - sentence_length, 1):
# X 是当前窗口中的词序列,长度为 sentence_length
X = tokens[i:i + sentence_length]
# Y 是当前窗口后面的第一个词,作为预测目标
Y = tokens[i + sentence_length]
# 将输入词序列转换为对应的索引序列,并添加到输入数据中
InputData.append([word_index[char] for char in X])
# 将目标词转换为索引,并添加到输出数据中
OutputData.append(word_index[Y])
import numpy as np
from keras.utils import to_categorical
# 将输入数据转换为 NumPy 数组并 reshape 成 (样本数, 序列长度, 特征数=1)
X = np.reshape(InputData, (len(InputData), sentence_length, 1))
# 将输出标签转换为独热编码格式,适用于分类模型的输出
Y = to_categorical(OutputData)
5.定义并训练 LSTM 模型
构建并训练一个基于 LSTM 的文本生成模型,使用交叉熵损失函数和 Adam 优化器,同时通过 checkpoint 机制自动保存训练过程中表现最好的模型。
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
from keras.callbacks import ModelCheckpoint
model = Sequential()
# 添加一个 LSTM 层,包含 256 个单元,输入形状为 (序列长度, 特征数)
model.add(LSTM(256, input_shape=(X.shape[1], X.shape[2])))
model.add(Dropout(0.2))
# 添加全连接输出层,节点数等于词汇表大小,使用 softmax 激活函数进行分类
model.add(Dense(Y.shape[1], activation='softmax'))
# 编译模型,使用交叉熵作为损失函数,adam 作为优化器
model.compile(loss='categorical_crossentropy', optimizer='adam')
# 定义保存模型的文件名模板
filepath = "weights-improvement-{epoch:02d}-{loss:.4f}.weights.h5"
# 设置检查点回调函数,只保存当前 loss 最低的模型
checkpoint = ModelCheckpoint(filepath, monitor='loss', verbose=1, save_best_only=True, mode='min', save_weights_only=True)
# 训练模型,设置训练轮数为 5,每个批次包含 128 个样本,并添加 checkpoint 回调
model.fit(X, Y, epochs=5, batch_size=128, callbacks=[checkpoint])
6.加载模型并预测
# 加载已保存的训练好的模型权重
model.load_weights("weights-improvement-05-6.8213.hdf5")
# 重新编译模型,指定损失函数和优化器(需要在加载权重后进行)
model.compile(loss='categorical_crossentropy', optimizer='adam')
# 从训练数据中随机选取一个输入序列的起始索引
start = np.random.randint(0, len(InputData))
# 获取对应的输入序列(一个长度为 sentence_length 的词索引列表)
input_sent = InputData[start]
# 将选中的输入序列 reshape 为模型可接受的输入形状:(1, 序列长度, 1)
X_input = np.reshape(input_sent, (1, len(input_sent), 1))
# 使用模型进行预测,输出下一个词的概率分布(verbose=0 表示不显示进度条)
predict_word = model.predict(X_input, verbose=0)
# 取概率分布中概率最大的索引,即预测出的词的索引
index = np.argmax(predict_word)
7.查看结果
# 将 index 转为单词
word_index_rev = dict((i, c) for i, c in enumerate(tokens))
sent_in = [word_index_rev[value] for value in input_sent]
result = word_index_rev[index]
print("输入词序列:", sent_in)
print("预测词:", result)
输出:
输入词序列: ['get', 'theres', 'did', 'sorry', 'as', '6months', 'thank', 'handsome', 'hello', 'this', 'standard', 'standard', 'really', 'stock', 'take', 'if', '500', 'haf', 'lor', 'you', 'we', 'again', 'please', 'phone', '6months']
预测词: out
当前数据量较小,预测效果不佳;训练更多轮次和使用更多数据会显著提升效果。
4 总结
这篇文章围绕深度学习在自然语言处理中的实际应用展开,通过具体实现展示了神经网络在理解语义、识别文本类别以及生成语言内容等方面的强大能力,虽然存在如训练数据规模有限、预处理简单、模型尚未充分调优等问题,但模型效果在一定程度上体现了方法的可行性。