1.什么是3D高斯泼溅(3D Gaussian Splatting)?
目标:从一组稀疏的3D点(比如通过相机或激光雷达采集的点云)重建出高质量的3D场景,并支持实时渲染。
核心思想:用许多“3D高斯分布”(类似椭球形的光滑斑点)来表示场景中的物体表面。这些“斑点”可以灵活变形、旋转或缩放,从而更精准地拟合复杂形状。
类比理解:
想象用一堆“棉花糖”拼成一个3D模型:每个棉花糖可以压扁、拉长或旋转(各向异性),最后所有棉花糖组合起来就能逼真地还原一个物体(比如一只猫或一栋建筑)。
2. 贡献点逐条解析
贡献1:各向异性(anisotropic)的3D高斯分布
- 各向异性:指高斯分布的形状在不同方向上可以不同(比如椭球可以是扁的或长的,而不仅是圆形)。为什么重要? 真实世界的物体表面有各种复杂朝向(比如地面是平的,树干是竖的),各向异性让高斯分布能更贴合这些形状。
- 非结构化辐射场:传统方法(如NeRF)需要规则网格或隐式函数,而高斯泼溅直接用离散的高斯斑点自由表达,更灵活高效。
贡献2:GPU快速可微渲染
可微渲染:渲染过程支持自动求导(即可以通过损失函数反向传播优化高斯参数)。
- 抛雪球(Splatting):将3D高斯投影到2D屏幕上时,像“泼雪球”一样模糊化处理,避免锯齿或空洞。
- GPU加速:利用并行计算实时渲染大量高斯斑点。
“抛雪球”(Splatting) 是计算机图形学中一种 将3D数据投影到2D屏幕 的渲染技术,常用于点云或体素(体积像素)的实时可视化。它的核心思想是:把每个3D点看作一个“柔软的雪球”,投影到2D屏幕上时会像雪球砸到地面一样“摊开”成一个模糊的圆形或椭圆形斑点,从而避免直接渲染离散点导致的空洞或锯齿问题。
贡献3:优化与自适应密度控制
- 优化方法:训练过程中动态调整高斯斑点的位置、形状、透明度等参数,使重建更精准。
- 自适应密度:根据场景复杂度增减高斯斑点(比如细节多的区域自动增加斑点,平坦区域减少)。
3.预备知识
1.一维高斯分布(1D Gaussian Distribution)
概念:一维高斯分布描述的是 单个随机变量 的概率分布,其图像是经典的“钟形曲线”。例如:人的身高、测量误差等通常服从高斯分布。
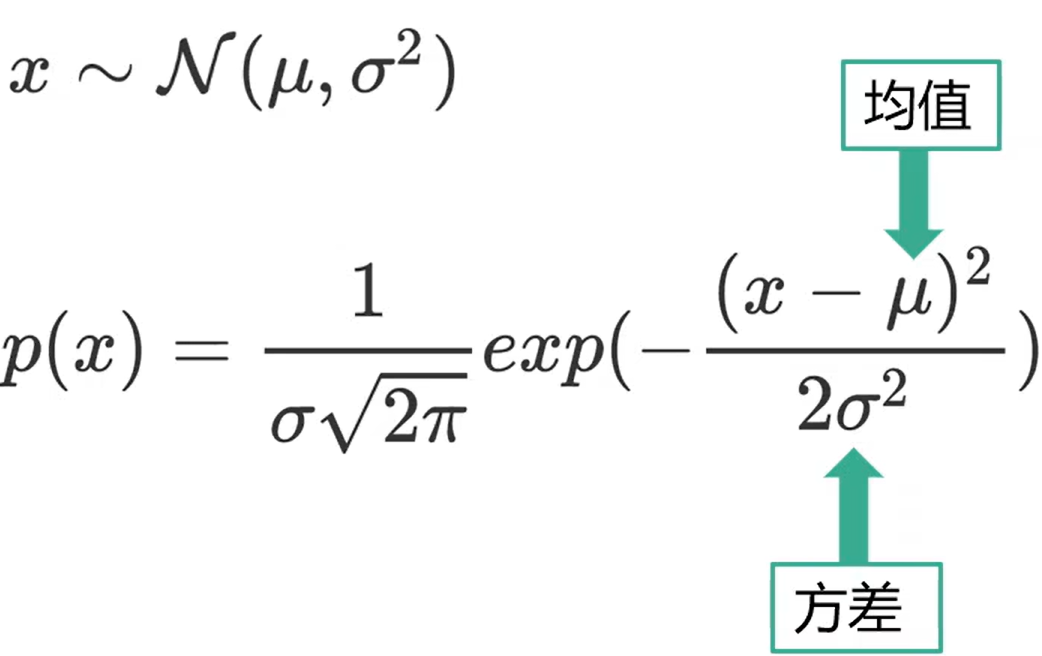
- 𝜇:均值(Mean),决定分布的中心位置。
- 𝜎:标准差(Standard Deviation),控制分布的“宽窄”(𝜎 越大,曲线越扁平)。
- 𝜎2:方差(Variance)
^
| ......
| . .
| . .
f(x) | . .
| . .
|. .
+-----------------------> x
μ-σ μ μ+σ曲线在 𝑥=𝜇处取得最大值。约 68% 的数据落在 (𝜇−𝜎,𝜇+𝜎) 区间内,95% 落在 (𝜇−2𝜎,𝜇+2𝜎) 内。
2.三维高斯分布(3D Gaussian Distribution)
概念:三维高斯分布描述的是 三个变量(如空间中的x, y, z坐标) 的联合分布。在3D高斯泼溅中,每个“高斯斑点”就是一个三维高斯分布,可以旋转、拉伸(各向异性),用来拟合3D物体表面。
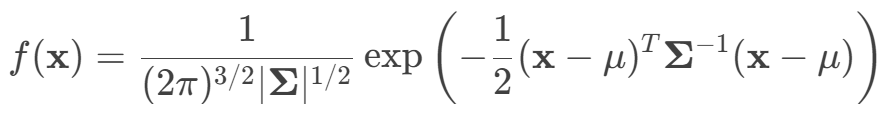
- 𝑥=[𝑥,𝑦,𝑧]𝑇:三维空间中的一个点。
- 𝜇=[𝜇𝑥,𝜇𝑦,𝜇𝑧]𝑇:均值向量,决定分布的中心位置。
- 𝛴:3×3协方差矩阵,控制分布的形状(大小、旋转、拉伸)。
协方差矩阵 𝛴 的作用
协方差矩阵决定了高斯分布的 形状和方向:
- 对角元素(
):控制沿x、y、z轴的缩放(方差)。
- 非对角元素(
):控制不同维度之间的相关性(即旋转或倾斜)。
例子:
- 如果 𝛴 是对角矩阵(非对角元素为0),则高斯分布是轴对齐的椭球。
Σ = [σ_x² 0 0
0 σ_y² 0
0 0 σ_z²]- 如果非对角元素非零,则高斯分布是旋转的椭球(各向异性)。
3.可视化学习
(1)一维高斯分布可视化→ 理解均值和标准差
import numpy as np
import matplotlib.pyplot as plt
# 定义高斯函数
def gaussian_1d(x, mu=0, sigma=1):
return (1 / (sigma * np.sqrt(2 * np.pi))) * np.exp(-0.5 * ((x - mu) / sigma)**2)
# 生成数据
x = np.linspace(-5, 5, 500) # x范围
mu = 0 # 均值
sigma = 1 # 标准差
# 计算概率密度
pdf = gaussian_1d(x, mu, sigma)
# 绘图
plt.figure(figsize=(8, 4))
plt.plot(x, pdf, 'b-', linewidth=2, label=f'μ={mu}, σ={sigma}')
plt.title('1D Gaussian Distribution')
plt.xlabel('x')
plt.ylabel('Probability Density')
plt.legend()
plt.grid(True)
plt.show()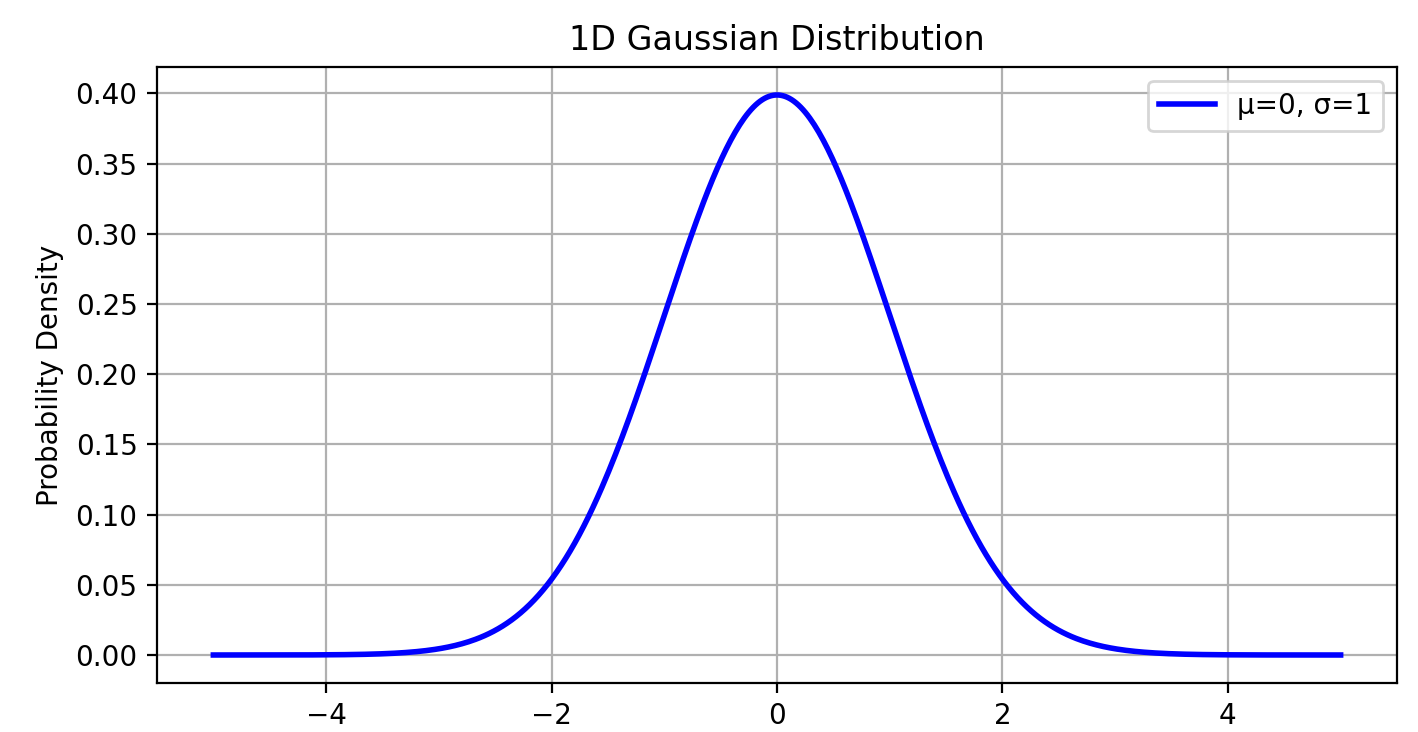
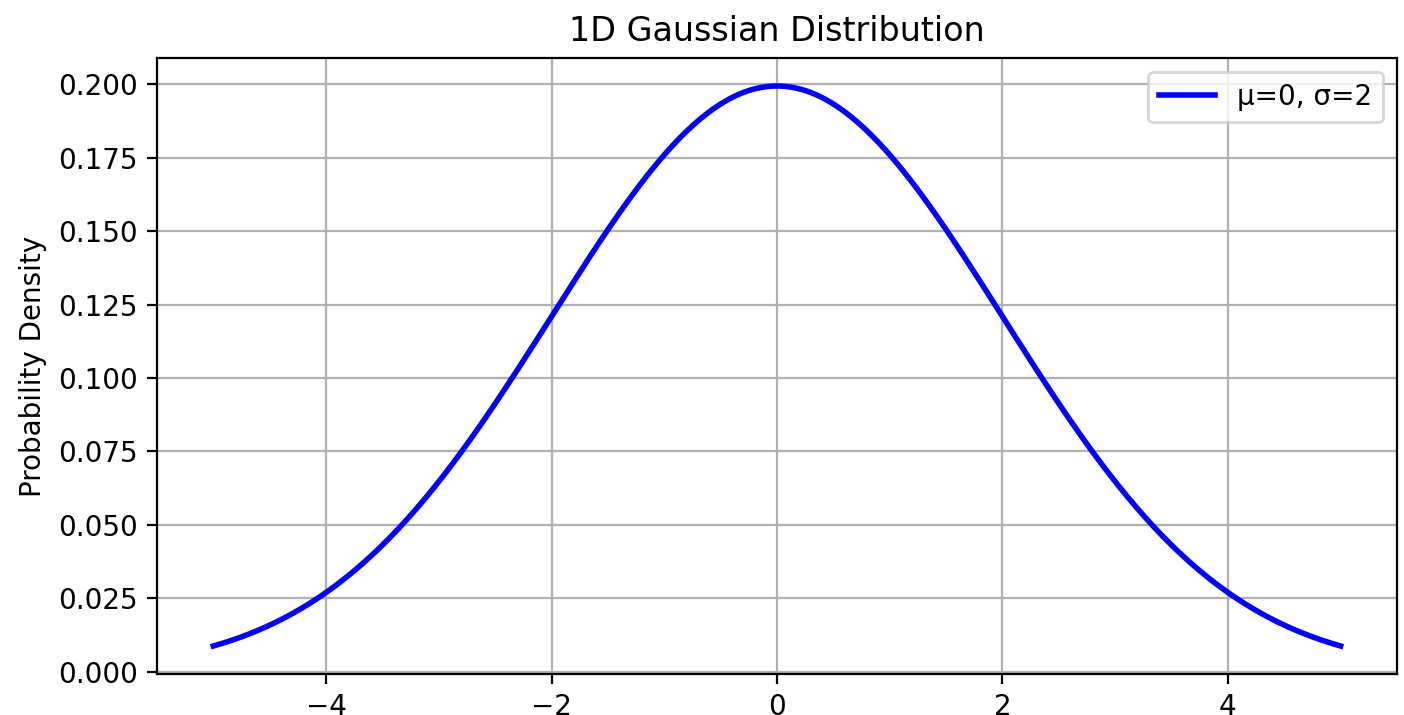
- 改变 𝜇 会平移曲线,改变 𝜎会调整曲线的“胖瘦”。
(2)二维高斯分布可视化→ 理解协方差矩阵控制形状
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 定义二维高斯函数
def gaussian_2d(x, y, mu_x=0, mu_y=0, sigma_x=1, sigma_y=1, rho=0):
"""rho: 相关系数(控制旋转)"""
z = (1 / (2 * np.pi * sigma_x * sigma_y * np.sqrt(1 - rho**2))) * np.exp(
-0.5 / (1 - rho**2) * (
((x - mu_x) / sigma_x)**2 +
((y - mu_y) / sigma_y)**2 -
2 * rho * (x - mu_x) * (y - mu_y) / (sigma_x * sigma_y)
))
return z
# 生成网格
x = np.linspace(-5, 5, 100)
y = np.linspace(-5, 5, 100)
X, Y = np.meshgrid(x, y)
# 案例1:各向同性(圆形)
Z_iso = gaussian_2d(X, Y, sigma_x=1, sigma_y=1, rho=0)
# 案例2:各向异性(椭圆,旋转45度)
Z_aniso = gaussian_2d(X, Y, sigma_x=2, sigma_y=0.5, rho=0.5)
# 绘制3D图
fig = plt.figure(figsize=(12, 6))
ax1 = fig.add_subplot(121, projection='3d')
ax1.plot_surface(X, Y, Z_iso, cmap='viridis')
ax1.set_title('Isotropic Gaussian (σ_x=σ_y)')
ax2 = fig.add_subplot(122, projection='3d')
ax2.plot_surface(X, Y, Z_aniso, cmap='plasma')
ax2.set_title('Anisotropic Gaussian (σ_x≠σ_y, ρ≠0)')
plt.tight_layout()
plt.show()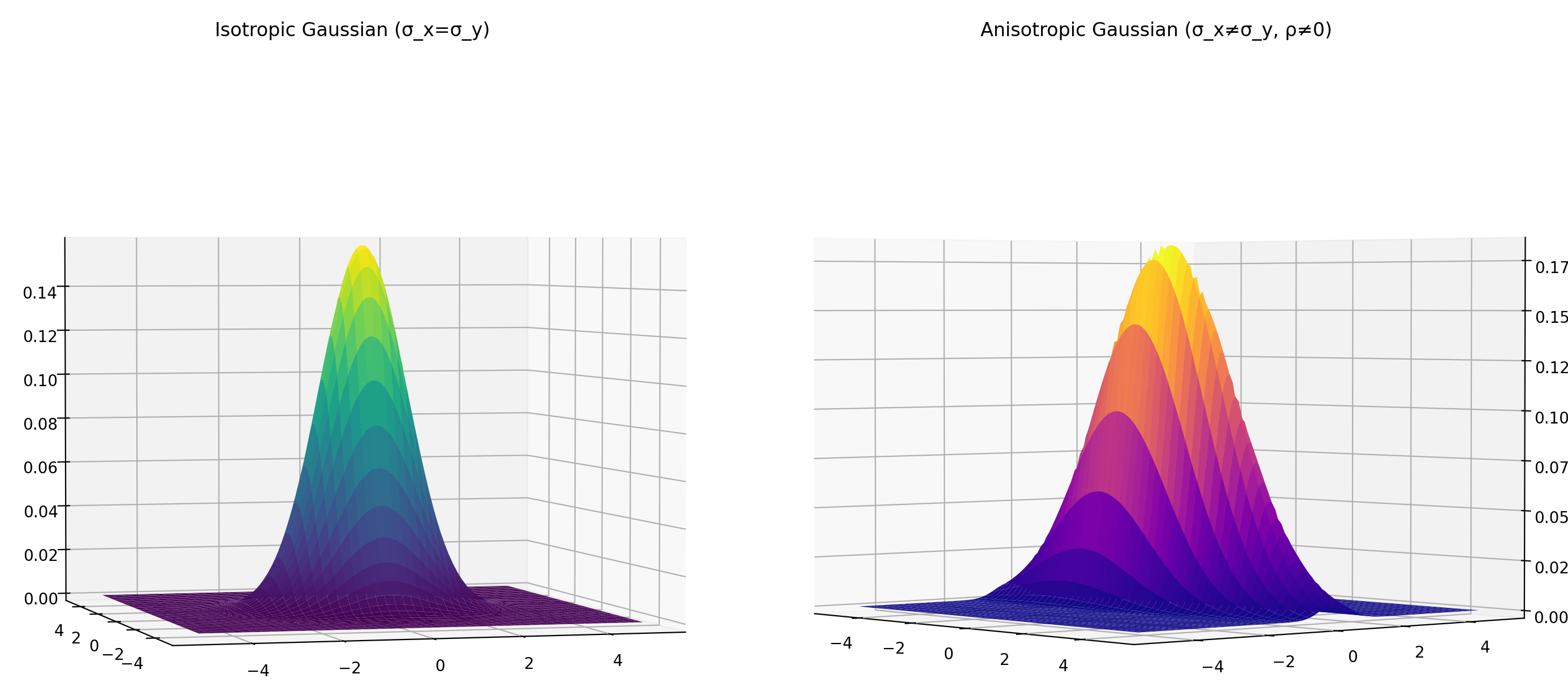
- 各向同性:等高线是圆形(sigma_x = sigma_y)。
- 各向异性:等高线是椭圆(通过 sigma_x、sigma_y 和 rho 控制拉伸和旋转)。
(3)三维高斯分布可视化→ 掌握各向异性椭球的生成
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import pyvista as pv
def generate_3d_gaussian(mu=[0, 0, 0], cov=[[1, 0, 0], [0, 1, 0], [0, 0, 1]], n_points=1000):
"""生成3D高斯分布点云"""
points = np.random.multivariate_normal(mu, cov, size=n_points)
return points
# 案例1:各向同性(球体)
points_iso = generate_3d_gaussian(cov=np.eye(3))
# 案例2:各向异性(椭球,拉伸和旋转)
cov_aniso = [[2, 1, 0], [1, 1, 0], [0, 0, 0.5]] # 协方差矩阵
points_aniso = generate_3d_gaussian(cov=cov_aniso)
# 可视化
plotter = pv.Plotter(shape=(1, 2))
plotter.subplot(0, 0)
plotter.add_points(points_iso, color='blue', point_size=5)
plotter.add_title('Isotropic 3D Gaussian')
plotter.subplot(0, 1)
plotter.add_points(points_aniso, color='red', point_size=5)
plotter.add_title('Anisotropic 3D Gaussian')
plotter.show()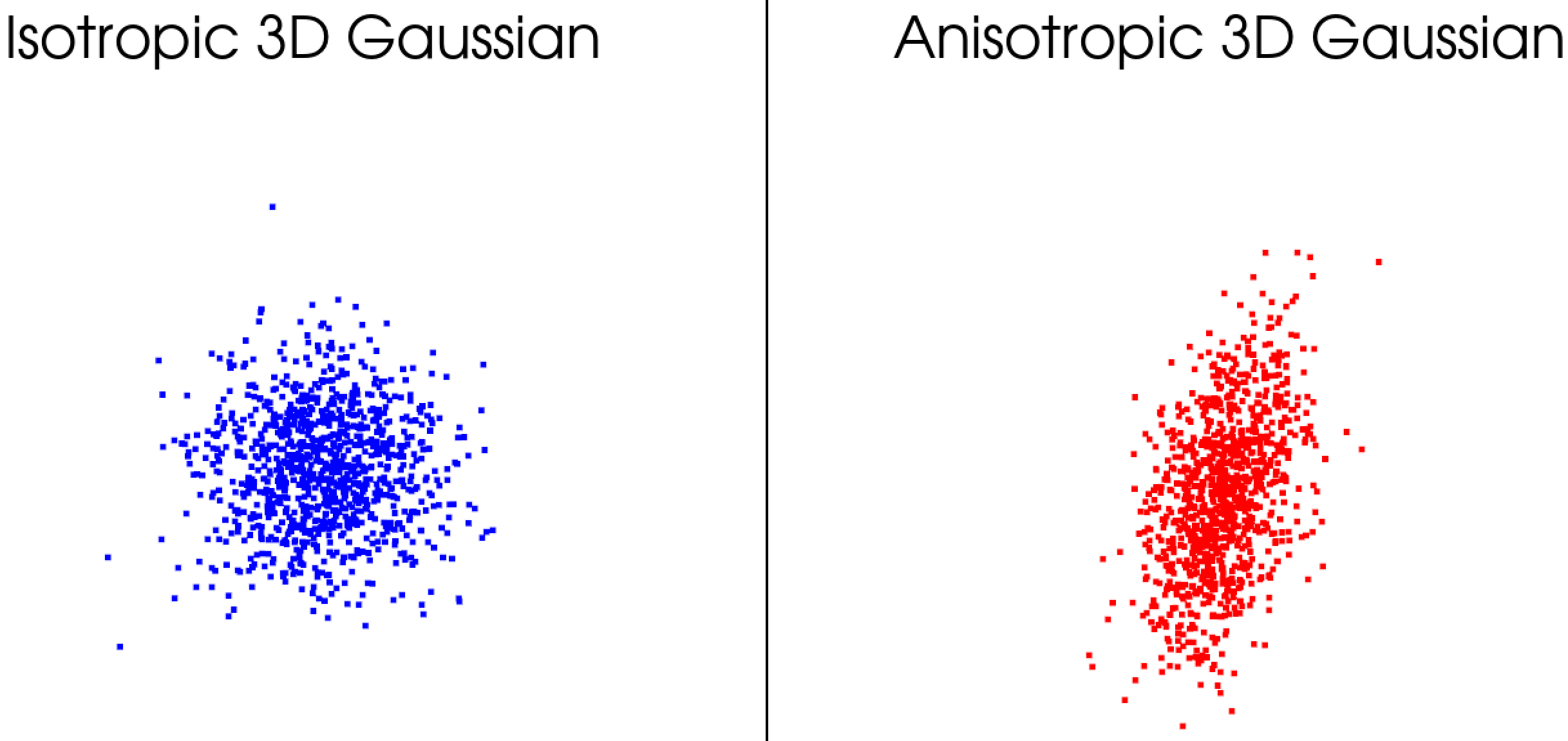
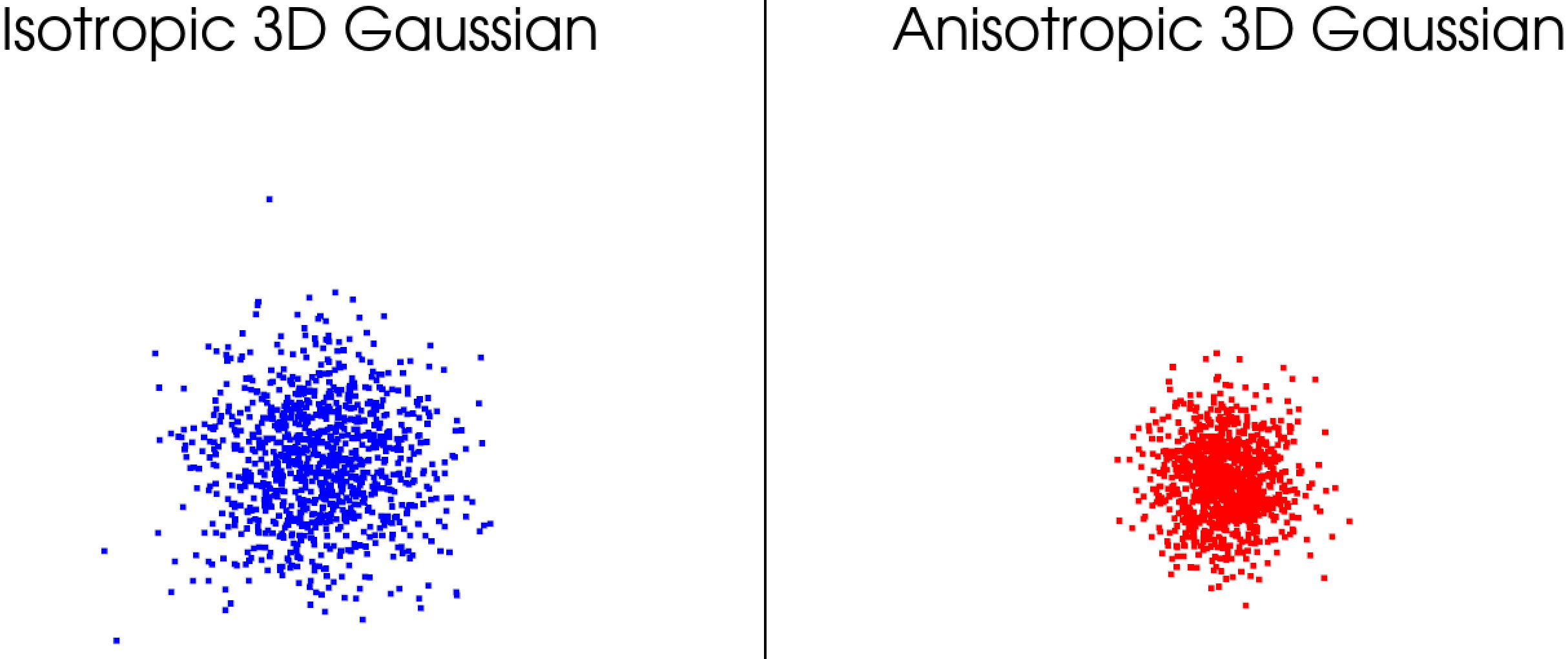
(4)3D泼溅 → 理解投影和渲染逻辑。
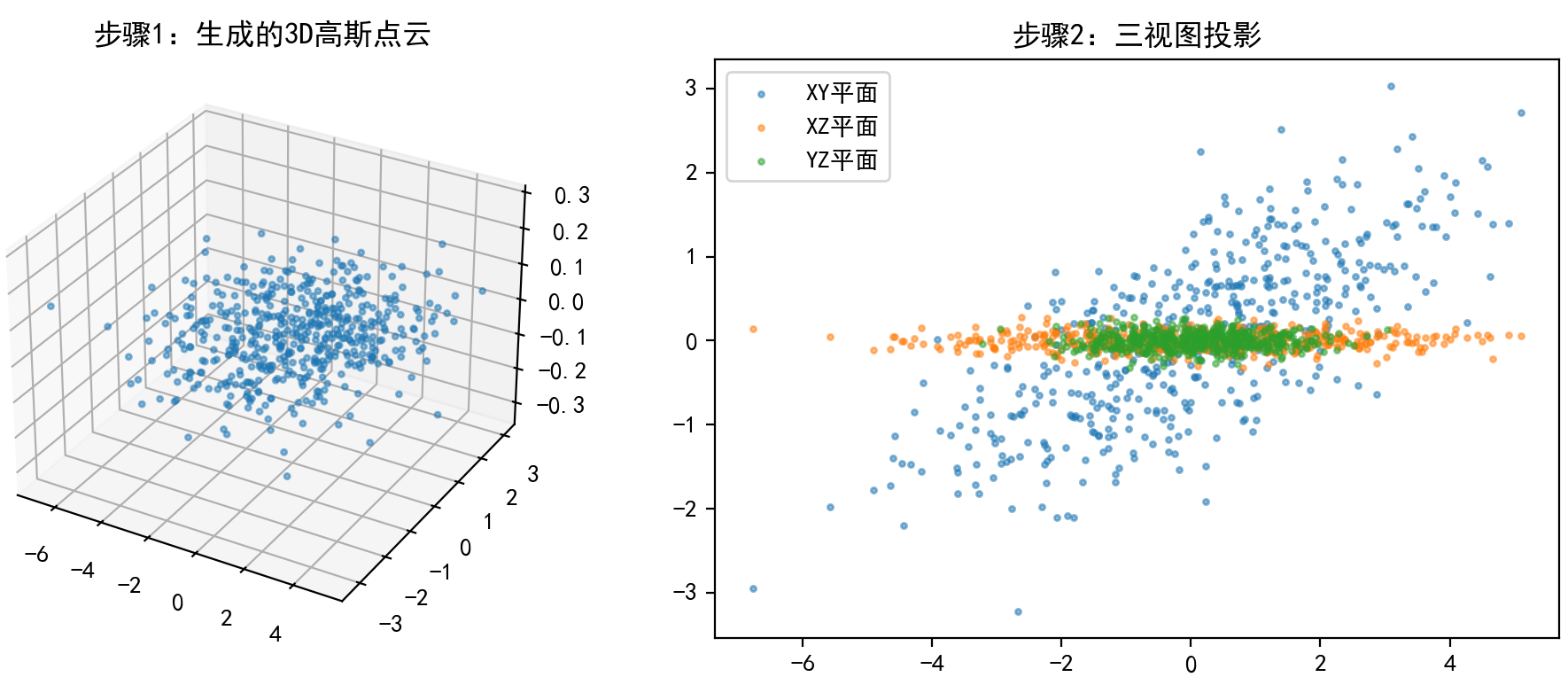
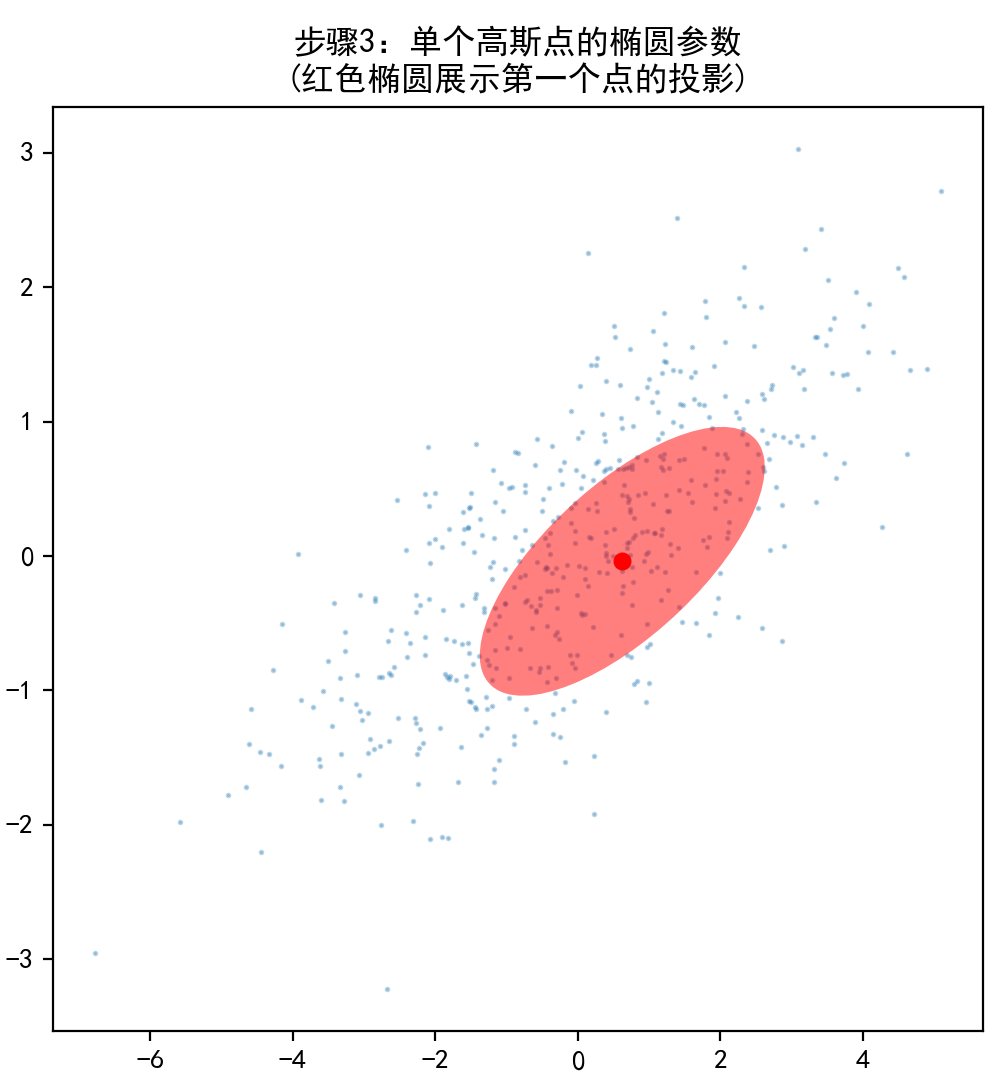
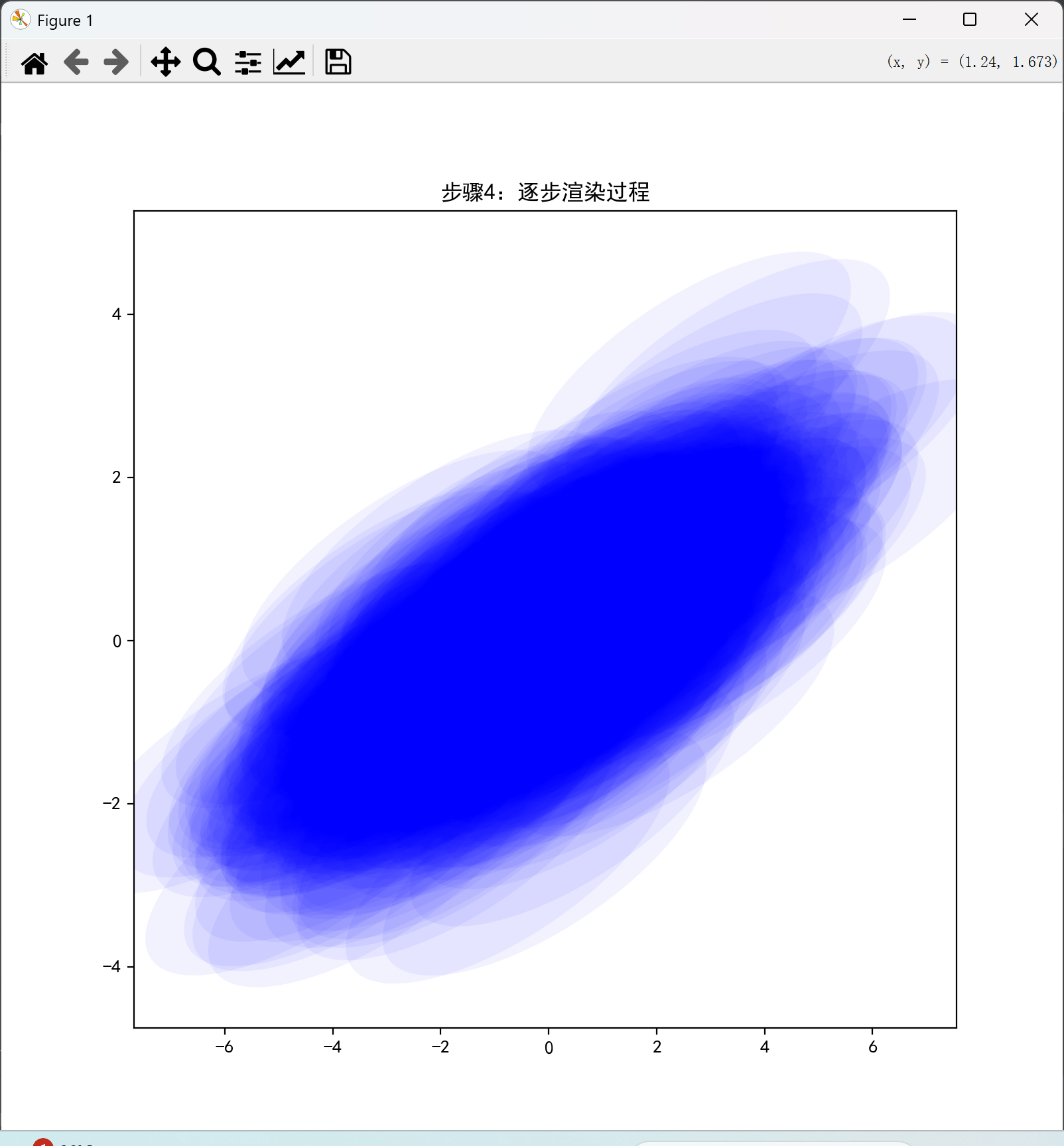
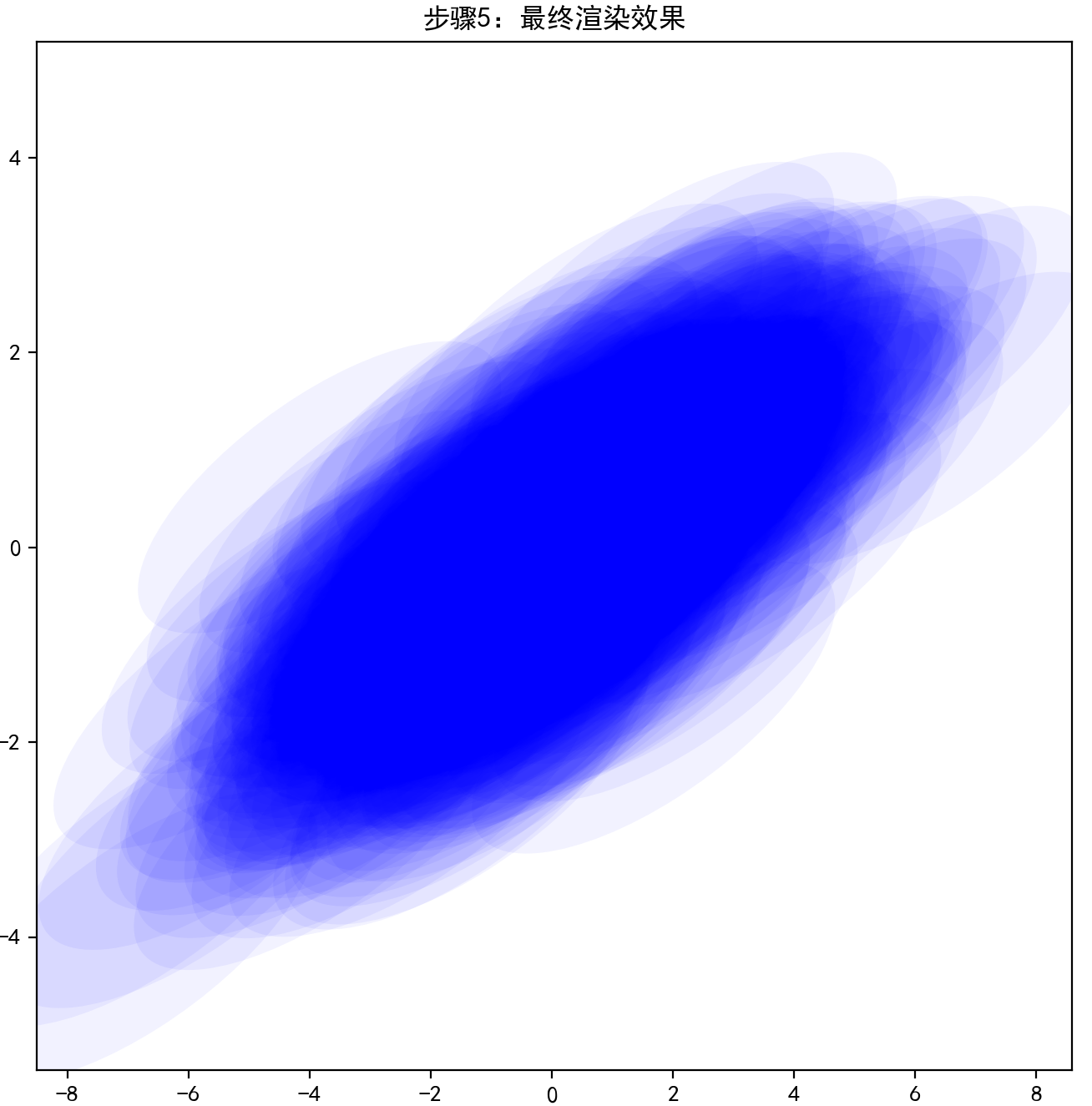
4.3D 几何与坐标变换
在 3D Gaussian Splatting 中,我们需要将一个在三维空间中表示的高斯分布(点)投影到图像平面上。这一过程涉及多个坐标系之间的转换:世界坐标系、相机坐标系、图像坐标系。为了理解这个过程,首先要掌握基本的三维几何与坐标变换知识。
三维坐标系的种类
| 坐标系名称 | 说明 |
|---|---|
| 世界坐标系(World Coordinate System) | 场景中所有物体的统一参考坐标系。 |
| 相机坐标系(Camera Coordinate System) | 以相机为原点的坐标系,Z轴朝向视线方向。 |
| 图像坐标系(Image Coordinate System) | 图像上的像素位置(通常是 2D 坐标)。 |
高斯点最初位于世界坐标系,但为了在屏幕上正确绘制它,我们必须将其转换到图像坐标系。
坐标变换流程
世界坐标 P_world
→ 相机坐标 P_camera = [R | t] * P_world(外参矩阵)
→ NDC(标准设备坐标) → 图像坐标(像素位置)
解释:
R是旋转矩阵(3×3)t是平移向量(3×1)[R | t]组成了 外参矩阵,将世界坐标变换到相机坐标然后乘上 投影矩阵(内参),将相机坐标转换到图像平面
齐次坐标与变换矩阵
为统一表达旋转、平移等操作,我们使用齐次坐标(Homogeneous Coordinates):
一个三维点
P = [x, y, z]→ 齐次形式为[x, y, z, 1]^T
坐标变换统一用 4×4 矩阵表示:
P_camera = T_view * P_world
T_view = | R t |
| 0 1 |
继续投影到图像空间:
P_image = K * T_view * P_world
其中:
K是相机内参矩阵,包含焦距、主点等;P_image是图像平面上的点。
应用于 Gaussian Splatting 的场景
在 Gaussian Splatting 中,每个三维高斯分布点都有其位置(中心点)、方向(协方差矩阵)等参数。这些点需要经过上述变换,从世界空间转换到相机空间,并最终以一种“模糊点”(splat)的方式渲染到图像上。因此,理解坐标变换过程是后续理解高斯渲染公式、遮挡处理、深度排序等机制的基础。
5.相机模型与投影过程
在 Gaussian Splatting 中,我们需要将三维空间中的高斯点“投影”到二维图像平面上,就像真实相机将三维世界成像到一张照片上一样。这个过程依赖于相机模型,它描述了从 3D 点到 2D 像素的转换方式。
什么是相机模型?
相机模型是一种数学模型,模拟真实相机是如何拍摄一张照片的。它包括两个主要部分:
| 类型 | 描述 | 关键内容 |
|---|---|---|
| 外参(Extrinsic Parameters) | 描述相机在世界中的位置和朝向 | 用旋转矩阵 R 和位移向量 t 表示 |
| 内参(Intrinsic Parameters) | 描述相机的内部结构与成像方式 | 焦距、主点、图像尺寸、像素间距等 |
相机投影原理
我们可以类比真实世界:
📸 相机就像一个小孔,把三维空间的光线投射到一个二维图像平面上。
数学表达为:
P_image = K × [R | t] × P_world
其中:
P_world是世界坐标中的 3D 点[R | t]是外参矩阵,将世界坐标转换为相机坐标K是内参矩阵,将相机坐标转换为图像平面坐标(像素)
相机坐标 → 图像坐标的步骤
第一步:世界坐标 → 相机坐标
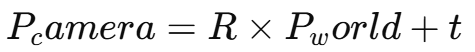
这个变换告诉我们:相机看到的点在它本地坐标系中长什么样。
第二步:相机坐标 → 归一化图像坐标(投影)
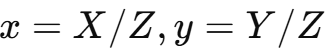
这是“透视投影”的核心思想 —— 离相机越远的点,看起来越小。
第三步:归一化 → 像素坐标(通过内参矩阵)
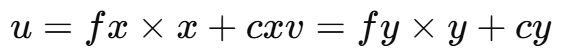
(u, v)是图像上的像素位置;fx, fy是像素方向上的焦距(单位:像素);(cx, cy)是图像中心点(principal point)。
实际意义:从 3D 到 2D 的投影
整个流程可以形象理解为:
真实世界中的3D点(例如树的一片叶子)
→ 相机观察它的视角(R, t)
→ 计算它落在图像哪个像素位置(通过K)
6.体积渲染与透明度混合
在 Gaussian Splatting 和 NeRF 等技术中,传统的“绘制网格三角形”的方式被替代为“模拟光穿过一个透明体积的过程”,这就是体积渲染。它的目标是:从一个视角出发,计算每条光线穿过空间时,最终在图像像素上看到的颜色。
什么是体积渲染?
体积渲染是通过对光线在三维空间中的“穿行过程”建模,计算出最终像素颜色的技术。
我们可以想象,视线(光线)从相机发出,穿过一段“有颜色和透明度”的雾状体积,最终到达我们的眼睛。在这段路径上,颜色不断“叠加”,这就是体积渲染的基本思想。
核心思想:光线积分
体积渲染的本质是:在一条光线上积分所有位置的颜色和不透明度,决定最终的像素颜色。
设想我们沿光线采样许多点,每个点有:
颜色值
c_i(RGB)密度值
σ_i(表示该点“多不透明”)
每个点的**不透明度(透明度补数)**记作:
![]()
其中 δ_i 是采样点之间的距离。
透明度混合(Alpha Blending)
每个点对最终像素颜色的贡献由其前面的透明度控制。这个过程叫做 前向透明度混合(front-to-back alpha compositing)。
假设有 N 个采样点,每个点颜色为 c_i,不透明度为 α_i,权重(可视度)为 T_i,则最终像素颜色为:
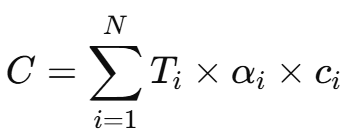
其中:
![]()
意思是:前面所有点“透明”才能看到当前第 i 个点的颜色。
示例类比:多层玻璃窗
我们看向远方,面前有好几块半透明玻璃,每块玻璃都上了一点颜色。
第一块玻璃影响最多;
第二块玻璃的颜色只有在第一块足够透明时才能显现;
第三块玻璃受到前两块的遮挡;
最终我们看到的颜色,是所有玻璃“混合”的结果。
在 Gaussian Splatting 中的作用
在 Gaussian Splatting 中:
每个高斯就像一个有颜色和透明度的模糊斑点;
从一个视角出发,对所有高斯进行深度排序;
按顺序进行透明度混合,叠加颜色;
得到最终像素颜色,就像体积渲染中的“光线积分”。
但与 NeRF 不同,Gaussian Splatting 是一种点级别的近似快速渲染,不是连续空间积分,而是基于稀疏高斯点进行快速 alpha 混合。
7.NeRF 原理简介:神经体积渲染的基准模型(可与 Gaussian Splatting 对比)
什么是 NeRF?
NeRF(Neural Radiance Fields) 是 2020 年由 Google 提出的新型 3D 表示方法,它使用一个神经网络来拟合一个场景的体积颜色与密度函数,然后利用体积渲染技术合成新视角图像。
NeRF 是 Gaussian Splatting 出现之前最广泛使用的三维重建方案之一。
NeRF 的核心思想
NeRF 的核心是一个函数:![]()
𝑥 ∈ ℝ³:表示空间中的一个 3D 点𝑑 ∈ ℝ³:表示相机视角方向(单位向量)输出
c ∈ ℝ³:该点在该方向下的 RGB 颜色输出
σ ∈ ℝ⁺:体积密度(用来计算透明度)
也就是说,NeRF 使用一个 MLP 神经网络来表示场景的颜色和体积结构。
渲染方式:体积渲染积分(Volume Rendering)
NeRF 沿着每个像素的视线进行采样,使用神经网络预测每个采样点的颜色和密度,然后通过**体积渲染(参考上一节)**混合得到最终颜色。
NeRF 每条光线都要采样几十到上百个点,并且每个点都要前向一次神经网络 → 渲染非常慢(分钟级)。
优点与缺点
| 优点 | 缺点 |
|---|---|
| 表示能力强:细节丰富、精度高 | 训练和渲染都非常慢 |
| 能表示连续空间(非点云) | 不可实时互动 |
| 适合离线精渲染任务 | 不适合实时应用、游戏等 |
Gaussian Splatting 与 NeRF 的对比
| 项目 | NeRF | Gaussian Splatting |
|---|---|---|
| 表示形式 | MLP(神经网络) | 高斯点分布 |
| 渲染方式 | 连续采样 + 体积渲染 | 离散高斯叠加 |
| 渲染速度 | 慢(需推理 MLP) | 快(GPU 可并行) |
| 实时性 | 不支持 | 支持实时渲染 |
| 内存占用 | 相对较小 | 高斯点云较大 |
| 场景表达能力 | 精度高,细节丰富 | 精度略低,但效率高 |
NeRF 与 Gaussian 的演进路径
NeRF 系列发展出了很多变种(FastNeRF、InstantNGP、MipNeRF、Zip-NeRF),目的都是为了加速渲染、减少训练时间。而 Gaussian Splatting 是直接跳出神经网络,将渲染过程“显式化”为可快速绘制的高斯点云,成为一种新范式。
NeRF 是“隐式渲染”(用网络预测颜色+密度),而 Gaussian Splatting 是“显式渲染”(直接用可见的高斯点+数学公式渲染),这就是“渲染过程显式化”的意思。
Gaussian Splatting 的“显式渲染”机制:
Gaussian Splatting 不再使用黑盒函数表示场景,而是直接生成一堆可见的、有意义的点:
每个点(3D Gaussian)具有:
位置(在世界坐标中)
颜色(RGB)
透明度(α)
空间尺度(决定模糊大小)
方向(协方差矩阵)
屏幕上的外形(经过投影变换)
渲染时:
✅ 不再用神经网络!直接把这些高斯点投影到屏幕 → 进行 α 混合 → 生成图像。
这一过程完全显式、可计算、可并行、可加速,非常适合 GPU 实时处理。
总结
| 特性 | NeRF(隐式) | Gaussian Splatting(显式) |
|---|---|---|
| 表达方式 | 神经网络 MLP(函数) | 高斯点(真实几何+属性) |
| 渲染方式 | 推理+体积渲染 | 投影+α混合 |
| 每次渲染都需要? | 网络推理几十次 | 点→像素变换+混合即可 |
| 渲染速度 | 慢(秒级) | 快(实时) |
| 可视化 | 不可直接看场景结构 | 点云可视化直接看到场景形状 |
8.Gaussian Splatting 的核心思想
核心一句话:
Gaussian Splatting 是一种用“3D 高斯点云”来实时渲染场景的技术,核心思想是:把一个 3D 世界显式表示成许多透明的、有颜色的模糊斑点,然后投影到屏幕上进行混合,生成最终图像。
1️⃣ 从点云到高斯
我们知道,传统的三维重建(如激光扫描)会得到“点云”,每个点有位置和颜色。但这些点是“离散的”,看起来会有锯齿、空洞。
于是,Gaussian Splatting 提出:
🔵 把每个点变成一个 3D 高斯分布,也就是一个模糊的、椭球形的斑点。它有:
位置(在哪儿)
形状(椭球大小方向)
颜色(RGB)
不透明度(α)
这让原本“零散的点”变成了“柔和的、连续的体积”,更像真实世界。
2️⃣ 把高斯“泼”到屏幕上
“Splatting” 是图形学里的术语,意思是“把点在屏幕上铺开/投影出去”。
Gaussian Splatting 的做法是:
📷 把每个 3D 高斯点 根据相机视角投影到屏幕上,变成一个 2D 的椭圆模糊图形。
这个过程考虑了:
相机位置(从哪看)
高斯的方向和大小(变换后是屏幕上的椭圆)
3️⃣ 使用透明度混合生成图像
多个高斯点可能会投影到同一个像素位置。
🧪 所以我们要像 Photoshop 那样,“一层层叠加”,用 alpha 混合公式,得到最终颜色。
叠加规则是:
离相机近的点要先渲染;
每个点的透明度决定它对最终颜色的贡献;
像体积渲染那样累加颜色,越后面的点贡献越小(被遮挡)。
✅ 为什么这很聪明?
相比 NeRF,它的优点是:
| 特点 | Gaussian Splatting | NeRF |
|---|---|---|
| 场景表示 | 显式高斯点云 | 黑盒神经网络 |
| 渲染方式 | 投影+透明度混合 | 光线采样+MLP推理 |
| 渲染速度 | 快,可实时 | 慢,需要推理 |
| 显存占用 | 稍大(保存高斯) | 相对较小 |
| 可解释性 | 点是明确可见的 | 不可视,需要解码 |
Gaussian Splatting 是一种将 3D 场景显式表示为高斯点的技术,使用快速投影和透明度混合代替传统 NeRF 的光线采样与 MLP 推理,显著提升了渲染速度并支持实时交互。
9.GS点的参数
在 3D Gaussian Splatting 中,一个点不是简单的“位置 + 颜色”,而是带有空间分布、方向、透明度等信息的可渲染斑点。它的参数大致可以分为三类:
🧩 第一类:几何信息(Geometry)
1️⃣ 位置 μ ∈ ℝ³
这是高斯分布的中心点,定义了这个点在 3D 空间中的位置。
就像传统点云里的一个点的位置。
📌 举例:一个点在 [1.0, 2.0, 3.0] 的位置,它就“漂浮”在这个空间中。
2️⃣ 协方差矩阵 Σ ∈ ℝ³ˣ³(或者参数化形式)
控制这个高斯的形状和朝向,相当于定义了一个椭球体的大小和方向。
可以理解为这个点“在空间中模糊到哪里去”,是细小点还是大斑块。
📌 比如:
如果协方差小,那就是一个“尖的点”;
如果协方差大,那就是一个“模糊的大点”。
📍 实际论文中会使用参数矩阵 Λ 代替协方差 Σ,便于训练(可正定性)。
🎨 第二类:外观信息(Appearance)
3️⃣ 颜色 c ∈ ℝ³ 或 RGB
表示这个点本身的颜色,在渲染时直接作为输出图像的一部分。
有些版本还会加上颜色不确定度,但基本就是颜色本身。
📌 例:[0.2, 0.5, 0.8] → 蓝绿色点。
4️⃣ 不透明度 α 或体积密度 σ
控制这个点对最终图像的贡献有多大,越大越“实”,越小越“透明”。
类似 Photoshop 图层的不透明度,或者 NeRF 中的体积密度。
📌 透明点对结果贡献小;不透明点容易遮挡后方点。
🔧 第三类:渲染辅助信息(Rendering Parameters)
5️⃣ 视角依赖性(View-dependent feature)🔁(可选)
一些版本中引入了方向特征(如 SH spherical harmonics 球谐函数)来模拟表面反射光效果。
这是为了解决:一个点在不同视角看起来颜色不一样的问题(比如镜面反射)。
📌 这部分在论文中可选开启,核心思想是使高斯点在不同角度下显示不同颜色。
6️⃣ 混合优先级 / 深度排序(用于渲染排序)
高斯点需要根据到相机的距离来排序,靠近的先渲染。
虽不是“参数”,但每帧渲染前需要用这个信息进行排序,以正确合成透明度。
🧠 总结表格:一个点的关键参数
| 类别 | 参数 | 描述 | 作用 |
|---|---|---|---|
| 几何 | μ |
空间位置 | 决定点在哪里 |
| 几何 | Σ 或 Λ |
空间形状协方差 | 控制模糊方向和大小 |
| 外观 | c |
颜色 | 决定渲染颜色 |
| 外观 | α |
不透明度 | 控制遮挡和贡献 |
| 渲染 | SH特征(可选) |
视角依赖色 | 表面高光反射等特效 |
| 渲染 | 深度距离 | 相机距离 | 控制前后遮挡顺序 |
10.自适应密度控制
① 通俗比喻:撒网捕鱼
想象你在海上捕鱼,但鱼的分布不均匀:
- 普通方法:你不管三七二十一,在整个海面均匀撒网(就像均匀采样)。结果鱼多的地方网不够密,漏掉很多;鱼少的地方网太密,浪费力气。
- 自适应方法:你聪明了,先快速试探几网,发现鱼群集中在某几个区域。然后你调整策略——在鱼多的地方多撒网(高密度采样),鱼少的地方少撒网(低密度采样)。这样既省力,又捕得多。
这就是自适应密度控制的核心思想:根据目标的重要性动态调整采样密度!
②在光线积分中的应用
在渲染(比如路径追踪)中,我们需要计算光线在场景中的积分(比如光照效果)。但不同区域的光线贡献差异巨大:
- 高贡献区域:比如明亮的光源、锐利的阴影边缘、复杂的反射区域(需要更多采样)。
- 低贡献区域:比如黑暗的角落、平滑的漫反射表面(需要较少采样)。
自适应密度控制会自动识别这些区域,并分配不同的采样密度:
- 先粗采样:快速用少量光线试探整个场景,找出哪些地方对最终画面影响大(比如高光或阴影边界)。
- 再精调:对重要区域发射更多光线(提高采样密度),不重要区域减少光线(节省计算资源)。
- 动态调整:随着渲染进行,持续优化采样分布(类似“边观察边调整撒网位置”)。
③为什么需要它?
- 省时间:避免在无关区域浪费计算资源。
- 降噪声:在复杂光照区域(比如焦散、镜面反射)增加采样,减少画面噪点。
- 自适应性强:适合各种复杂场景,无需人工预设采样规则。
④举个渲染例子
假设渲染一个室内场景:
- 窗户附近:阳光直射+玻璃反射,光线变化剧烈 → 自适应算法会分配更多采样。
- 阴暗墙角:光线简单且微弱 → 减少采样。
- 最终效果:画面噪点少,且计算速度更快!
总结
自适应密度控制就像“智能撒网捕鱼”:先探路:快速找出重要区域。再聚焦:对关键区域集中火力。动态调整:随时优化效率。在光线积分中,它让渲染器更聪明地分配计算资源,用最少的光线达到最好的画面质量。