
1、自我介绍+项目(省略)
2、为什么存储要从TiDB迁移到Mysql?
TiDB 迁移至 MySQL 核心原因总结:
成本优化
- TiDB 需多节点集群(PD/TiKV/TiDB Server),硬件、运维及学习成本高。
- 中小业务(数据量 <10TB,QPS < 万级)用 MySQL 可降本 30%+,避免资源浪费。
性能适配
- TiDB 跨节点 RPC 通信增加延迟,MySQL 单机执行简单查询更快。
- MySQL 本地事务(InnoDB)强于 TiDB 的分布式事务(2PC),适合高频 OLTP 场景。
生态兼容性
- 老旧系统依赖 MySQL 特有功能(存储过程/视图)或工具(Canal/PHPMyAdmin),TiDB 部分兼容性不足,迁移可减少适配成本。
运维简化
- MySQL 单机监控/备份/恢复流程成熟,运维门槛低;TiDB 需专业团队处理分布式扩缩容、数据均衡等问题。
总结:业务未达分布式规模时,MySQL 在性价比、性能、生态及运维复杂度上更具优势。
3、迁移过程中有遇到过什么问题或者有难度的挑战吗?
TiDB 迁移至 MySQL 的典型问题与解决方案总结:
a. 数据一致性保障(核心挑战)
问题
迁移期间业务持续写入,需保证零停机、零数据丢失。
解决方案
- 双写同步:
- 使用中间件(如 Canal/Debezium)实时同步 TiDB 增量数据到 MySQL。
- 业务层双写:优先写 TiDB,异步写 MySQL(通过事务或消息队列保证最终一致)。
- 数据校验:
- 全量迁移后,用工具(如 pt-table-checksum)对比主键、唯一索引及敏感字段的一致性。
- 多次校验(如业务低峰期),修复差异后逐步切换流量。
示例:
电商订单表迁移时,双写阶段发现因网络抖动导致 MySQL 部分订单号丢失,通过消息队列重试机制补全数据。
b. 查询性能差异
问题
TiDB 的分布式优化器与 MySQL 单机优化器差异导致复杂 SQL(如多表 Join、深度分页)性能下降。
解决方案
- 索引优化:
- 分析 MySQL 执行计划,添加覆盖索引或前缀索引(如
INDEX(col(20)))。
- 分析 MySQL 执行计划,添加覆盖索引或前缀索引(如
- 分页改造:
- 将 TiDB 的
LIMIT 10000,10改写为基于主键范围的分页(如WHERE id > 10000 LIMIT 10)。
- 将 TiDB 的
- 分库聚合:
- 分布式 Join 场景(如跨分片查询用户订单),改为应用层分库查询后合并结果。
示例:
用户行为分析报表的 JOIN 查询在 MySQL 中耗时增加 5 倍,通过拆分子查询并添加联合索引优化至原性能水平。
c. 事务逻辑调整
问题
TiDB 的分布式事务(如跨分片扣库存)迁移后需适配 MySQL 单机事务。
解决方案
- 业务重构:
- 将跨分片事务拆分为单库操作(如按用户 ID 分片,保证同一用户操作在单库内完成)。
- 使用消息队列(如 RocketMQ)实现最终一致性(如订单创建后异步扣减库存)。
- 强一致方案:
- 引入 Seata AT 模式,通过全局事务 ID 和 undo log 协调多库事务。
示例:
原 TiDB 跨库转账业务迁移后,通过 Seata 的 AT 模式实现跨分片账户余额同步更新,事务耗时从 200ms 降至 50ms。
d. 分库分表策略转换
问题
TiDB 自动分片迁移至 MySQL 需手动设计分库分表(如订单表按时间分片)。
解决方案
- 分片键设计:
- 选择高频查询字段(如
user_id)作为分片键,按 Hash 或 Range 分片(如user_id % 64)。
- 选择高频查询字段(如
- 非分片键查询:
- 对全表扫描场景,使用 全局表(如字典表全量同步至所有分库)。
- 通过 ES 或 ClickHouse 构建异构索引,支持复杂查询。
工具选型: - 使用 ShardingSphere 或 MyCat 实现分片路由,屏蔽业务层复杂性。
示例:
物流系统中运单表按 region_id 分片后,查询未带分片键的运单号时,通过 ES 二级索引快速定位分库。
e. 监控体系重建
问题
从 TiDB 的 Prometheus 监控切换至 MySQL 传统监控体系。
解决方案
- 核心监控指标:
- 性能类:QPS、TPS、慢查询率(阈值建议 ≤1%)。
- 资源类:连接数、InnoDB 缓冲池命中率(>95%)、锁等待时间。
- 告警策略:
- 设置慢查询阈值(如 >50ms)、死锁频率(如 1 次/分钟)触发告警。
- 集成企业微信/钉钉,实时通知运维人员。
工具推荐: - 使用 Percona Monitoring and Management (PMM) 或 Prometheus + mysqld_exporter 构建监控。
总结
迁移需从数据流、事务逻辑、查询性能、分片策略、监控五方面系统化处理,核心原则:
渐进式切换:灰度验证 → 双写 → 校验 → 流量切换。
业务适配:根据规模选择分库分表方案,避免过度设计。
自动化工具:利用校验、同步、监控工具降低人工干预风险。
4、rocketMQ是怎么保证不重复的?
RocketMQ 保证消息不重复消费的机制与实现方案
RocketMQ 通过 生产者幂等性 + 消费者去重逻辑 + 业务层容错设计 三者结合实现消息的精准一次消费,具体策略如下:
1. 生产者侧:确保消息唯一性
(1)消息唯一标识设计
- 业务唯一键(Keys):
发送消息时强制设置setKeys("业务唯一键")(如订单号order_id),用于后续消费者去重。Message msg = new Message("Topic", "Tag", "order_12345", "支付成功".getBytes()); - 全局唯一 msgId:
RocketMQ 自动为每条消息生成msgId(Broker 端生成),但 msgId 在生产者重试时可能重复(如网络超时导致重发),需结合业务唯一键使用。
(2)生产者幂等模式
- 启用幂等生产者:设置
enableIdempotent=true,RocketMQ 通过 生产者组 + 消息 sequence 号 保证 同一生产者实例 的消息不重复。 - 限制:仅对同一实例有效,多实例或宕机重启时仍需依赖业务唯一键去重。
示例:
订单支付成功后,生产者发送消息时设置 keys=order_12345,即使因网络抖动重试,Broker 会过滤重复消息(相同 keys 的消息在短时间内仅存储一条)。
2. 消费者侧:消息去重机制
(1)基于唯一标识去重
- 提取标识:消费者从消息中获取
keys(如order_12345)作为去重依据。 - 分布式缓存去重:
- 使用 Redis 记录已处理标识,设置过期时间(如订单处理周期 + 10分钟):
String key = "msg_dedup:" + message.getKeys(); if (redis.setnx(key, "1")) { // 若 key 不存在则处理 processMessage(message); redis.expire(key, 3600); // 过期时间根据业务调整 }- 优化:高并发场景下可改用 Redis Lua 脚本 保证原子性操作。
(2)消息重试策略控制
- 限制重试次数:设置
maxReconsumeTimes=3,超过后消息进入死信队列(无法被正常消费的消息),避免无限重试导致积压。 - 死信处理:监控死信队列,人工介入或自动化修复(如补偿事务)。
3. 业务层:幂等性兜底设计
(1)核心原则
- 所有写操作必须幂等:例如订单状态更新使用
UPDATE order SET status=paid WHERE id=12345 AND status=unpaid。 - 唯一约束兜底:数据库层对关键字段(如
order_id)添加唯一索引,拦截重复提交。
(2)典型场景示例
- 支付回调:
- 支付成功后,根据
out_trade_no(业务唯一键)更新订单状态,即使消息重复,数据库唯一索引或WHERE条件会保证幂等性。
- 支付成功后,根据
- 库存扣减:
- 使用
CAS操作:UPDATE stock SET count=count-1 WHERE product_id=100 AND count>=1,避免超卖。
- 使用
4. 特殊场景优化
(1)全局唯一 ID 生成
- 若业务无天然唯一键,可引入 Snowflake 算法 或 Redis 自增 ID 生成全局唯一标识,作为消息
keys。
(2)事务消息去重
- 事务消息的
Transaction ID由生产者生成,需保证唯一性(如结合业务 ID + 时间戳),避免 Commit 阶段重复提交。
(3)顺序消息处理
- 顺序消息(如订单状态变更)需保证同一
Sharding Key的消息由同一消费者线程处理,避免并发导致状态混乱。
总结
| 环节 | 方案 | 关键点 |
|---|---|---|
| 生产者 | 业务唯一键 + 幂等生产者 | keys 必须唯一,enableIdempotent 减少重试风险 |
| 消费者 | Redis 去重 + 重试次数限制 | 分布式锁防并发,死信队列兜底 |
| 业务层 | 幂等 SQL + 唯一约束 | 所有写操作需支持幂等,数据库唯一索引兜底 |
| 监控 | 死信队列告警 + 重复消息日志 | 实时监控异常,人工介入修复 |
最终建议:生产环境中需结合 RocketMQ 机制 + 业务幂等设计 + 监控告警 三位一体,才能实现可靠的消息精准一次消费。
5、rocketMQ的结构是什么样子的?
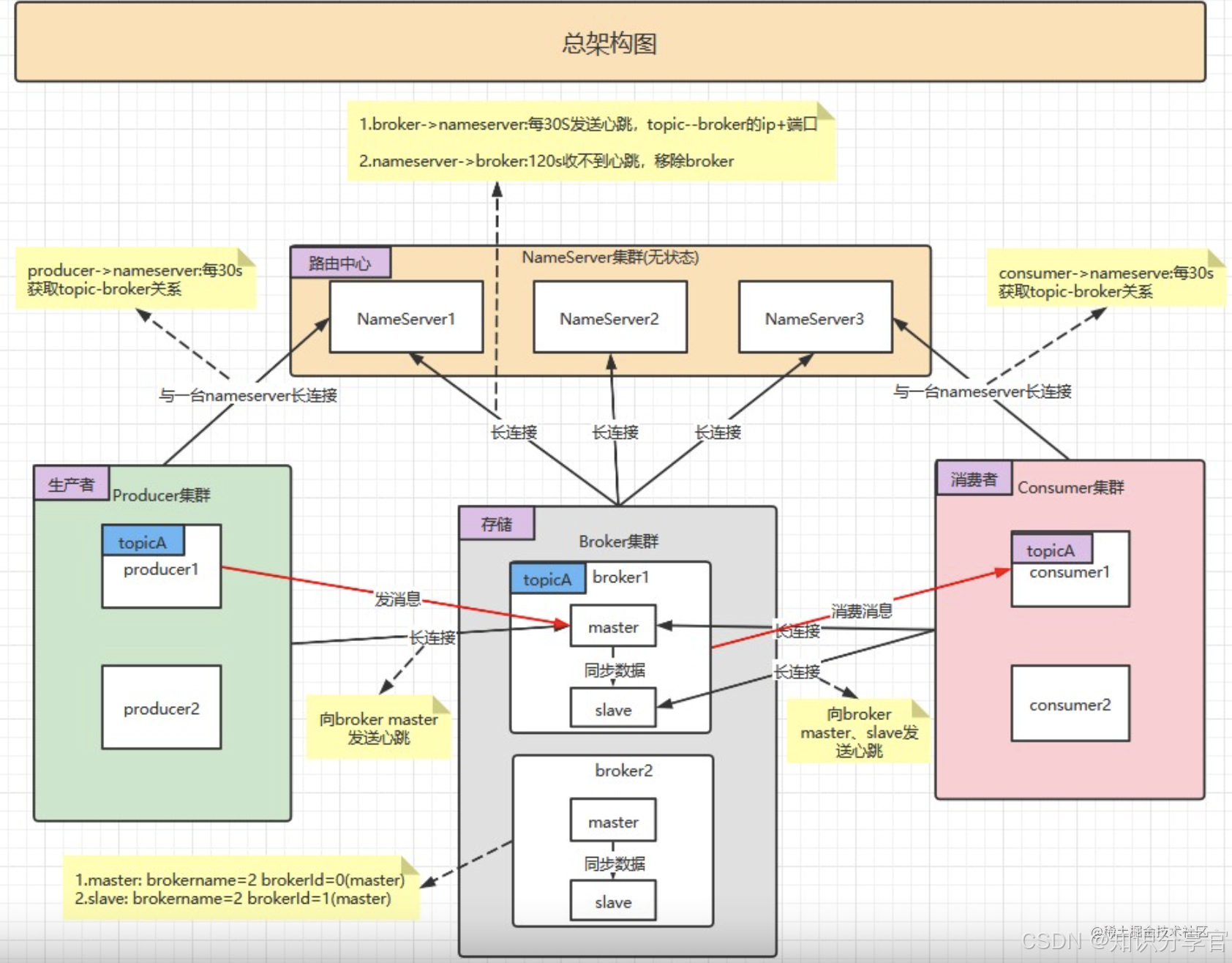 (不是很全)
(不是很全)
- 名称服务(NameServer):
角色:轻量级路由注册中心,无状态(无数据存储,节点间不通信)。
功能:
接收 Broker 注册信息(如 Broker 地址、Topic 路由表)。
为生产者 / 消费者提供动态路由查询(如获取 Topic 对应的 Queue 分布在哪些 Broker 上)。 - 消息代理(Broker):
角色:实际存储消息的节点,支持主从(Master/Slave)架构。
功能:
存储消息:按 Topic + Queue 组织消息,通过 commit log 顺序写入磁盘,提升 IO 效率。
处理读写请求:生产者发送消息至 Broker 的 Master 节点,消费者默认从 Master 拉取(可配置从 Slave 读)。
主从同步:通过异步复制(默认)或同步复制保证数据可靠性,Slave 节点可用于读负载均衡。 - 生产者(Producer):
角色:发送消息至 Broker,支持集群模式或广播模式。
关键特性:
负载均衡:根据 NameServer 返回的路由信息,将消息均匀发送至 Topic 的多个 Queue。
重试机制:消息发送失败时自动重试(默认 3 次),可配置规避特定 Broker(如故障节点)。 - 消费者(Consumer):
角色:从 Broker 拉取或监听消息,支持推模式(Pull + 长轮询模拟 Push)和拉模式。
两种模式:
集群消费:多个消费者实例组成消费组,同一消息仅被组内一个实例消费(通过队列负载均衡实现)。
广播消费:消息会被消费组内所有实例消费。 - 主题与队列(Topic & Queue):
Topic:消息的逻辑分类(如 “order_topic”),一个 Topic 包含多个 Queue(默认 4 个)。
Queue:物理存储单元,一个 Queue 对应 Broker 上的一个文件队列,保证消息有序(单个 Queue 内消息按发送顺序存储)。 - 其他组件:
控制台(RocketMQ-Console):可视化管理界面,用于查看 Topic、消费组、Broker 状态等。
工具模块:如 mqadmin 命令行工具,用于创建 Topic、查询消费进度等。
6、了解分布式id生成器吗?
| 方案 | 核心原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| UUID | 基于 MAC 地址 + 时间戳 + 随机数生成 36 位字符串 | 简单、无中心节点 | 长度长、无序、不适合数据库索引 | 无需排序的唯一标识 |
| 雪花算法 | 时间戳 + 工作节点 ID + 序列号(64bit 长整型) | 高性能、有序、可反查时间 | 依赖时钟同步、节点数受限 | 高并发有序 ID 生成 |
| 数据库自增 | 单库自增主键或分布式主键表(如 MySQL 利用 auto_increment + 分段策略) | 简单直观 | 存在性能瓶颈(需锁表) | 低并发场景 |
| Redis 生成 | 利用 Redis 的 INCR 命令原子性生成 ID(可带时间前缀) | 高性能、可自定义规则 | 依赖 Redis 集群稳定性 | 高并发、需灵活规则场景 |
| 美团 Leaf | 结合雪花算法(Leaf-Snowflake)和号段模式(Leaf-Segment),支持多模式切换 | 灵活、可扩展、兼容旧系统 | 实现复杂 | 大型分布式系统 |
| 百度 UidGenerator | 基于雪花算法,通过 RingBuffer 优化序列号生成,支持高并发 | 低延迟、高吞吐、可动态调整节点 | 需集成框架 | 百度系内部系统 |
7、雪花算法介绍一下?
核心设计(64bit 长整型):
┌─────────────┬──────────┬──────────────┐
│ 41bit 时间戳 │ 10bit 工作节点ID │ 12bit 序列号 │
└─────────────┴──────────┴──────────────┘
各部分含义:
41bit 时间戳:
单位为毫秒,可表示 (2^41 - 1) / (1000606024365) ≈ 69年(从某个起始时间点开始计算,如 2023-01-01)。
作用:保证 ID 按时间有序,且不同时间戳段的 ID 天然不重复。
10bit 工作节点 ID:
可支持 2^10 = 1024 个节点,通常划分为 5bit 数据中心ID + 5bit 机器ID,便于集群管理。
示例:数据中心 ID 范围 0-31,机器 ID 范围 0-31,共支持 32×32=1024 个节点。
12bit 序列号:
同一节点同一毫秒内可生成 2^12 = 4096 个 ID,通过原子递增保证唯一性。
生成流程:
获取当前时间戳,若与上一次生成时间相同,序列号递增;若不同,序列号重置为 0。
检查工作节点 ID 是否合法(如是否在 0-1023 范围内)。
组合三部分生成 64bit ID。
优点:
** 高性能:** 纯内存计算,无网络 IO 或数据库依赖,单机 QPS 可达数万。
** 有序性:** ID 按时间戳排序,适合数据库索引(如主键自增)。
** 可反查:** 通过时间戳可解析出 ID 生成的大致时间。
缺点:
时钟回退问题:若节点时钟回退到之前某一时刻,可能生成重复 ID。
解决方案:
检测到时钟回退时,等待至回退的时间结束再生成 ID。
记录回退的时间戳,通过序列号补偿(如增加额外的偏移量)。
节点数限制:10bit 最多支持 1024 个节点,若集群规模超过需扩展为 11bit(牺牲序列号位数)。
8、雪花算法如何保证workid不重复?提示用 zookeeper
基于 ZooKeeper 实现雪花算法 WorkId 唯一性的方案
以下是通过 ZooKeeper 分布式协调服务为雪花算法(Snowflake)分配唯一 workId 的完整设计,结合临时节点、顺序节点与异常处理机制,确保分布式环境下节点 ID 不冲突。
1. 核心实现流程
步骤 1:创建 ZooKeeper 父节点
在 ZooKeeper 中预先创建持久化父节点 /snowflake/workers(若不存在则自动创建):
[zk: localhost:2181(CONNECTED) 0] create /snowflake/workers "snowflake_work_ids"
步骤 2:实例启动时注册临时顺序节点
每个雪花算法实例启动时,在父节点下注册一个 临时顺序节点:
// 连接 ZooKeeper(需处理连接超时、重试等异常)
ZooKeeper zk = new ZooKeeper("zk-host:2181", 5000, watchedEvent -> {
// 监听连接状态变化
});
// 创建临时顺序节点,节点名称示例:/snowflake/workers/worker-0000000001
String nodePath = zk.create(
"/snowflake/workers/worker-", // 节点前缀
new byte[0], // 数据内容(无需存储)
ZooDefs.Ids.OPEN_ACL_UNSAFE, // 开放权限
CreateMode.EPHEMERAL_SEQUENTIAL // 临时顺序节点
);
步骤 3:提取 WorkId
从节点路径中提取顺序号,转换为整数并限制范围(如 10bit 对应 0~1023):
// 示例路径:/snowflake/workers/worker-0000000001 → 后缀为 0000000001
String sequenceStr = nodePath.substring(nodePath.lastIndexOf("-") + 1);
long sequence = Long.parseLong(sequenceStr);
int workId = (int) (sequence % 1024); // 控制 WorkId 在 10bit 范围内
步骤 4:异常处理与容错
- 节点已存在:若节点创建冲突(极小概率),重试创建。
- ZooKeeper 连接中断:
- 启动时 ZooKeeper 不可用:启用本地缓存的上次有效
workId(需持久化到磁盘)。 - 运行中断开:维持当前
workId,但需监听会话状态,尝试重连后重新注册。
- 启动时 ZooKeeper 不可用:启用本地缓存的上次有效
2. 关键设计原理
(1)临时顺序节点的优势
| 特性 | 作用 |
|---|---|
| 临时性 | 实例宕机或断开时,节点自动删除,避免僵尸节点占用 workId。 |
| 顺序性 | ZooKeeper 自动生成全局唯一递增序号,保证节点名称不重复。 |
| 自动清理 | 无需手动维护节点列表,依赖 ZooKeeper 的会话机制自动释放资源。 |
(2)WorkId 分配逻辑
- 范围控制:通过
sequence % 1024强制限制workId在 10bit 范围内(0~1023)。 - 冲突风险:当节点数超过 1024 时,取模会导致
workId重复,需人工干预(如扩容位数或拆分业务)。
3. 完整代码示例(含容错)
public class SnowflakeWorkIdGenerator {
private static final String ZK_PATH = "/snowflake/workers";
private static final int MAX_WORKER_ID = 1023; // 10bit 上限
public int generateWorkId(ZooKeeper zk) throws Exception {
// 1. 创建临时顺序节点
String nodePath = zk.create(
ZK_PATH + "/worker-",
new byte[0],
ZooDefs.Ids.OPEN_ACL_UNSAFE,
CreateMode.EPHEMERAL_SEQUENTIAL
);
// 2. 提取序号并计算 workId
String sequenceStr = nodePath.substring(nodePath.lastIndexOf("-") + 1);
long sequence = Long.parseLong(sequenceStr);
int workId = (int) (sequence % (MAX_WORKER_ID + 1));
// 3. 检查是否超出上限
if (workId > MAX_WORKER_ID) {
throw new IllegalStateException("Workers exceed maximum limit: " + MAX_WORKER_ID);
}
return workId;
}
// 容错:尝试从本地缓存读取 workId
public int getWorkIdWithFallback(ZooKeeper zk, String localCachePath) {
try {
int workId = generateWorkId(zk);
// 写入本地缓存
Files.write(Paths.get(localCachePath), String.valueOf(workId).getBytes());
return workId;
} catch (Exception e) {
// ZooKeeper 不可用时使用本地缓存
try {
String cachedId = Files.readAllLines(Paths.get(localCachePath)).get(0);
return Integer.parseInt(cachedId);
} catch (IOException ex) {
throw new RuntimeException("Failed to get workId from cache", ex);
}
}
}
}
4. 注意事项与优化建议
- ZooKeeper 集群部署:至少部署 3 节点集群,避免单点故障。
- WorkId 回收机制:
- 依赖临时节点自动删除特性,无需手动回收。
- 若实例需主动释放
workId(如优雅停机),可手动删除节点:zk.delete(nodePath, -1); // -1 表示忽略版本检查
- 监控与告警:
- 监控
/snowflake/workers下节点数量,接近 1024 时触发告警。 - 监控 ZooKeeper 会话状态,确保连接稳定性。
- 监控
- 历史节点清理:
- 定期检查父节点下的残留持久节点(异常情况遗留),手动清理。
5. 方案对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| ZooKeeper 临时节点 | 自动回收 ID,强一致性 | 依赖 ZooKeeper 可用性 |
| 数据库分配 | 无第三方依赖 | 需手动清理,存在僵尸 ID 风险 |
| 配置文件硬编码 | 简单快速 | 不适用于动态扩缩容场景 |
总结:通过 ZooKeeper 的 临时顺序节点 特性,结合业务逻辑的 workId 取模限制,可高效、可靠地实现雪花算法的节点 ID 唯一性分配。需额外处理 ZooKeeper 连接异常和节点数超限问题,确保分布式环境下的稳定性。
9、为什么说hashmap是线程不安全的?桶数组的概念?
1. HashMap 线程不安全的核心原因
(1)多线程扩容导致循环链表(JDK 7 典型问题)
场景:
- 当 HashMap 触发扩容(
resize())时,会创建新桶数组(容量翻倍),并迁移旧数据。 - JDK 7 使用头插法迁移链表:旧链表的节点顺序会被反转插入新链表。
多线程风险:
- 线程 A 和线程 B 同时扩容,可能导致两个线程交替修改链表节点的
next指针。 - 结果:链表形成环状结构(如节点 A → B → A),后续
get()操作遍历链表时陷入死循环。
示例(JDK 7 头插法代码片段):
void transfer(Entry[] newTable) {
for (Entry<K,V> e : table) { // 遍历旧数组
while (e != null) {
Entry<K,V> next = e.next; // 线程切换点
int newIndex = e.hash & (newTable.length - 1);
e.next = newTable[newIndex]; // 头插法反转链表
newTable[newIndex] = e;
e = next;
}
}
}
示意图(线程 A 和 B 并发执行导致循环链表):
初始链表:1 → 2 → 3
线程 A 迁移后:3 → 2 → 1
线程 B 中断后恢复,继续迁移:1 → 3 → 2 → 1(形成环)
(2)JDK 8 的优化与残留风险
- 尾插法替代头插法:JDK 8 在扩容时改为尾插法,避免链表反转,解决了循环链表问题。
- 残留风险:
- 数据覆盖:多线程同时
put()时,若哈希到同一桶位,可能覆盖彼此的键值对。 - 红黑树结构破坏:并发修改红黑树(如插入、删除)可能导致树结构不一致。
- size 计算错误:
size字段未同步,多线程更新后实际元素数与统计值不符。
- 数据覆盖:多线程同时
示例(JDK 8 数据覆盖问题):
// 线程 A 和 B 同时执行 put("a", 1) 和 put("a", 2)
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null); // 若线程 A 和 B 同时判断 p == null,会重复插入
(3)其他线程安全问题
| 问题类型 | 描述 |
|---|---|
| 脏读 | 线程 A 正在扩容,线程 B 读取到未完全迁移的旧数组,导致数据不完整。 |
| 丢失更新 | 两个线程同时调用 put() 插入不同键但哈希冲突的条目,导致其中一个被覆盖。 |
| size 不一致 | size 字段未原子更新,多线程并发插入后实际元素数量与 size 值不符。 |
2. 桶数组(Table)的核心概念
(1)定义与结构
- 底层实现:HashMap 使用
Node<K,V>[] table数组存储键值对(JDK 7 为Entry[])。 - 桶(Bucket):数组的每个元素称为一个桶,存储哈希冲突的键值对集合。
(2)哈希定位机制
- 计算哈希值:
int hash = key.hashCode() ^ (key.hashCode() >>> 16); // 扰动函数减少哈希冲突 - 确定桶索引:
int index = (table.length - 1) & hash; // 等价于 hash % table.length(当 length 为 2^n 时)
(3)解决哈希冲突
| 数据结构 | 触发条件 | 时间复杂度 | JDK 版本 |
|---|---|---|---|
| 链表 | 桶中元素数量 < 8 | O(n) | JDK 7/8 |
| 红黑树 | 桶中元素数量 ≥ 8 且数组容量 ≥ 64 | O(log n) | JDK 8+ |
示例结构(JDK 8 的桶数组与红黑树):
Table: [
null,
Node<K,V>(hash=1, key="a", value=1) → Node<K,V>(hash=9, key="k", value=11),
TreeNode<K,V>(hash=5, key="c", value=3) → ... // 红黑树结构
]
3. 线程安全解决方案
(1)替代方案
| 方案 | 原理 | 适用场景 |
|---|---|---|
| ConcurrentHashMap | 分段锁(JDK 7)或 CAS + synchronized(JDK 8),保证并发安全且高性能。 | 高并发读写 |
| Collections.synchronizedMap | 通过全局锁封装 HashMap,所有操作串行化。 | 低并发或兼容旧代码 |
| Hashtable | 所有方法使用 synchronized 修饰,性能低下。 |
不推荐,仅遗留系统使用 |
(2)代码示例
// 使用 ConcurrentHashMap 保证线程安全
Map<String, Integer> safeMap = new ConcurrentHashMap<>();
// 使用 synchronizedMap 包装
Map<String, Integer> synchronizedMap = Collections.synchronizedMap(new HashMap<>());
总结
| 问题 | JDK 7 表现 | JDK 8 优化 | 线程安全方案 |
|---|---|---|---|
| 循环链表 | 头插法导致死循环 | 尾插法消除循环链表 | 使用 ConcurrentHashMap |
| 数据覆盖 | 存在 | 仍存在 | 同步锁或 CAS 操作 |
| 红黑树结构破坏 | 无红黑树 | 并发修改可能破坏结构 | 分段锁保护树操作 |
结论:HashMap 的线程不安全本质源于 无锁设计 + 共享状态多线程修改,需根据场景选择线程安全的 Map 实现。
10、mysql的隔离级别?
MySQL 的隔离级别详解
1. 四种隔离级别及特性
MySQL 支持 SQL 标准定义的四种隔离级别,隔离性由低到高如下:
| 隔离级别 | 脏读(Dirty Read) | 不可重复读(Non-Repeatable Read) | 幻读(Phantom Read) | MySQL 默认 |
|---|---|---|---|---|
| 读未提交(Read Uncommitted) | 允许 | 允许 | 允许 | 否 |
| 读已提交(Read Committed) | 禁止 | 允许 | 允许 | 否(Oracle 默认) |
| 可重复读(Repeatable Read) | 禁止 | 禁止 | 部分禁止 | 是(InnoDB 引擎默认) |
| 串行化(Serializable) | 禁止 | 禁止 | 禁止 | 否 |
2. 关键问题定义
脏读:事务 A 读取到事务 B 未提交的修改,若 B 回滚,A 读取的数据无效。
示例:事务 B 更新balance=200但未提交,事务 A 读到balance=200,B 回滚后,A 的数据与实际不一致。不可重复读:事务 A 多次读取同一行,因事务 B 提交了修改,导致前后结果不一致。
示例:事务 A 第一次读到balance=100,事务 B 提交balance=150,事务 A 第二次读到balance=150。幻读:事务 A 多次查询同一条件,因事务 B 插入或删除符合条件的数据并提交,导致前后结果集不同。
示例:事务 A 查询age>20得 5 条记录,事务 B 插入一条age=25并提交,事务 A 再次查询得 6 条记录。
3. InnoDB 的实现机制
(1)读已提交(Read Committed)
- 实现原理:通过 MVCC(多版本并发控制),每次查询生成最新的
Read View,只读取已提交的数据版本。 - 特点:
- 禁止脏读,但允许不可重复读和幻读。
- 适合对数据实时性要求较高的场景。
(2)可重复读(Repeatable Read)
- 实现原理:
- 快照读:事务启动时生成一致性快照(
Read View),整个事务期间读取同一快照,避免不可重复读。 - 当前读:通过 Next-Key Locks(行锁 + 间隙锁) 防止其他事务插入新数据,抑制幻读。
- 快照读:事务启动时生成一致性快照(
- 特点:
- 禁止脏读和不可重复读。
- 幻读的“部分禁止”:
- 快照读(普通
SELECT)不会出现幻读(基于一致性视图)。 - 当前读(如
SELECT ... FOR UPDATE)可能触发幻读检测,通过间隙锁阻塞其他事务的插入操作。
- 快照读(普通
示例:
-- 事务 A
BEGIN;
SELECT * FROM users WHERE age > 20; -- 快照读,返回 5 条记录(其他事务插入不影响)
-- 事务 B
INSERT INTO users (age) VALUES (25); -- 提交后,事务 A 的普通 SELECT 仍返回 5 条
-- 事务 A
SELECT * FROM users WHERE age > 20 FOR UPDATE; -- 当前读,触发间隙锁,阻塞事务 B 的插入
(3)串行化(Serializable)
- 实现原理:所有操作加锁(读加共享锁,写加排他锁),事务串行执行。
- 特点:
- 完全禁止脏读、不可重复读和幻读。
- 性能极差,仅用于强一致性场景(如金融交易)。
4. 隔离级别选择建议
| 场景 | 推荐隔离级别 | 原因 |
|---|---|---|
| 高并发读写,允许短暂不一致 | 读已提交 | 平衡性能与一致性,避免脏读。 |
| 事务需多次读取一致性数据 | 可重复读 | 默认级别,通过 MVCC 和间隙锁保证可重复读,抑制幻读。 |
| 强一致性,低并发 | 串行化 | 牺牲性能,确保绝对一致性(如账户余额更新)。 |
5. 总结
- InnoDB 默认隔离级别为可重复读,通过 MVCC + Next-Key Locks 实现高效并发控制。
- 幻读的“部分禁止”:
- 普通查询(快照读)不会出现幻读。
- 当前读(加锁操作)通过间隙锁阻止其他事务插入,避免幻读。
- 隔离级别越高,并发性能越低,需根据业务场景权衡选择。
11、undo log,redolog,bin log分别介绍一下?
undo log(回滚日志)
作用 :
- 事务回滚 :当事务进行修改操作(如 INSERT、UPDATE、DELETE)时,undo log 会记录修改前的数据状态。如果事务需要回滚(ROLLBACK),就可以利用 undo log 中的信息将数据恢复到事务修改之前的状态。例如,一个事务执行了 UPDATE 操作将某个字段的值从 10 改为 20,在 undo log 中会记录该字段原来的值 10。如果事务回滚,就可以通过这个记录把值改回 10。
- MVCC(多版本并发控制) :在数据库的可重复读隔离级别下,InnoDB 存储引擎利用 undo log 来实现 MVCC。它可以为不同事务提供数据的快照,使得事务能够读取到数据的一致性版本。比如,事务 A 在读取数据时,事务 B 对同一数据进行了修改。通过 undo log,事务 A 可以读取到数据在事务 B 修改之前的版本,从而保证事务 A 的一致性读。
格式与存储 :
- undo log 是逻辑日志,它记录的是操作的反向步骤。对于 INSERT 操作,其反向操作是 DELETE;对于 UPDATE 操作,是将数据还原为旧值。它存储在 undo 表空间中,可以是 ibdata1 文件(当使用默认的表空间配置时)或者独立的表空间。数据库系统通过 purge 线程定期清理过期的 undo log,判断 undo log 是否过期的标准是当没有事务需要访问旧版本数据时。
与事务的关系 :
- 每个事务启动时,会分配 undo log segment。事务提交后,undo log 不会立即被删除,而是被标记为可回收。这是因为 MVCC 机制可能还需要这些 undo log 来提供数据的旧版本给其他事务读取。只有当没有事务需要这些旧版本数据时,purge 线程才会真正清理这些 undo log。
redo log(重做日志)
作用 :
- 实现事务的持久性(Durability) :根据 Write - Ahead Logging(WAL)机制,先写 redo log 再更新数据页。这样即使在数据库系统崩溃后,通过 redo log 也可以恢复数据,确保事务的修改最终能够持久地保存到磁盘上。例如,当事务对数据进行修改并提交后,即使在数据尚未完全写入磁盘时系统崩溃,重启后可以通过 redo log 将修改后的数据恢复到磁盘上。
- 加速数据修改 :数据修改时,先在内存(Buffer Pool)中进行操作,然后将修改记录到 redo log,最后异步地将内存中的数据刷盘。这种方式可以减少磁盘 I/O 操作,提高数据修改的效率。因为写 redo log 的操作相对简单且快速,而数据在内存中的操作速度也很快,同步数据到磁盘的操作可以延迟进行。
格式与存储 :
- redo log 是物理日志,它记录的是数据页的物理修改情况,比如某个数据页的某个偏移量写入了新的值。它存储在 ib_logfile0 和 ib_logfile1 文件中(默认情况下,每个文件大小为 48MB,可以通过 innodb_log_file_size 参数进行配置),并且是循环写入的,类似环形缓冲区的模式。
关键流程 :
- 当事务修改数据时,首先在内存中的数据页(称为脏页)上进行修改,同时将修改记录写入 redo log buffer。事务提交时,根据 innodb_flush_log_at_trx_commit 参数的配置来决定 redo log 的刷盘时机。如果设置为 1,表示每次事务提交时都同步刷盘;设置为 0,每秒刷盘一次;设置为 2,提交时将 redo log 刷到操作系统缓存。在 MySQL 重启时,系统会通过 redo log 恢复未刷盘的脏页数据,以保证数据的一致性。
bin log(二进制日志)
作用 :
- 主从复制 :在主从复制架构中,主库将 bin log 传输给从库,从库解析 bin log 中的语句或数据变更,然后在本地执行这些操作,从而实现主从数据的同步。例如,主库上执行了一个 INSERT 语句插入了一条数据,主库会将这个操作记录在 bin log 中。从库通过读取这个 bin log,也在自己的数据库中执行这个 INSERT 操作,使得主从库的数据保持一致。
- 数据恢复 :可用于基于时间点(Point - In - Time Recovery)的恢复。如果因为误操作(如误删表)等情况,可以通过 bin log 回滚到之前的状态。比如,管理员在某个时间点错误地删除了一张表,可以通过 bin log 找到删除操作之前的状态,将数据恢复。
格式与存储 :
bin log 是逻辑日志,记录的是对数据的修改操作,如 INSERT、UPDATE、DELETE 等语句。它支持三种格式:
- ROW 格式 :记录每行数据的具体变更,包括旧值和新值。这种格式安全性高,可以避免因为使用 SELECT * 等可能导致主从不一致的问题,但日志体积相对较大。
- STATEMENT 格式 :记录 SQL 语句本身,如 INSERT INTO t VALUES (1, ‘a’)。日志体积小,但如果语句中包含不确定性的函数(如 NOW())或存储过程等,可能会导致主从不一致。
- MIXED 格式 :会根据情况自动在 ROW 格式和 STATEMENT 格式之间切换,是默认的格式。
bin log 存储在文件系统中,文件名通常为 mysql - bin.000001 等。可以通过 expire_logs_days 参数配置自动清理过期的 bin log,以避免磁盘空间被占满。
与 InnoDB 的交互 :
- 事务提交时,遵循两阶段提交的规则。首先是 redo log 的 prepare 阶段,然后写 bin log,最后 commit redo log。这种机制可以保证 redo log 和 bin log 的一致性,避免在主从复制过程中出现主从数据不一致的情况。例如,如果在 redo log 写入完成但 bin log 写入失败的情况下,通过两阶段提交,可以保证事务要么在主库和从库都成功,要么都失败,从而保证主从复制的正确性。
12、灰度引擎的过程中如何保证数据一致性?
- 事务提交时,遵循两阶段提交的规则。首先是 redo log 的 prepare 阶段,然后写 bin log,最后 commit redo log。这种机制可以保证 redo log 和 bin log 的一致性,避免在主从复制过程中出现主从数据不一致的情况。例如,如果在 redo log 写入完成但 bin log 写入失败的情况下,通过两阶段提交,可以保证事务要么在主库和从库都成功,要么都失败,从而保证主从复制的正确性。
核心策略:双写与校验
双写阶段(新旧系统并存)
请求路由 :
- 灰度规则是灰度发布的关键部分。通过设定灰度规则,如用户 ID 尾号、白名单等方式,可以将一部分流量引导到新系统,其余流量仍然由旧系统处理。例如,采用用户 ID % 10 == 0 的规则,这样大约有 1/10 的用户请求会进入新系统,其余 9/10 的请求走旧系统。这种分流方式可以让新系统在小规模的流量下进行验证,观察其是否能够正常工作,同时保证大部分流量由稳定的旧系统处理。
数据双写 :
- 对于业务写操作,如创建订单等,需要同时写入新旧系统。以订单创建为例,在伪代码中,首先尝试在新系统中创建订单,然后在旧系统中也创建订单。这里需要注意旧系统写入的数据格式可能与新系统不同,需要进行兼容处理。
- 如果同步双写对性能影响较大,可以通过消息队列实现异步双写。例如,先写新系统,然后发送消息到消息队列,由旧系统消费消息进行写入。但为了保证最终一致性,需要使用事务消息机制,如 RocketMQ 的事务消息。如果新系统写入成功后发送事务消息,旧系统在消费消息时进行写入,若写入失败,可以通过回查等方式进行补偿,确保数据最终在两个系统中都正确写入。
数据校验机制
实时校验 :
- 利用中间件(如 Canal)可以实时同步新旧数据库的数据。然后使用数据校验工具(如 DataSphere Studio)对关键业务表(如订单表、用户表)的关键字段(如主键、金额等)进行对比。例如,对于同步过来的订单数据,检查新旧库中的 order_amount 字段是否一致。如果不一致,及时触发告警,以便开发和运维人员能够快速发现并处理数据不一致的问题。
定时全量校验 :
- 在每天凌晨等业务低谷时段,对核心表进行全量数据对比。可以采用哈希值校验的方法,例如,对表的数据生成 MD5 哈希值,然后对比新旧库中对应表的哈希值。如果发现数据存在差异,可以通过人工核查来确定问题所在,或者采用自动补偿的机制,如从正确的那一方将数据同步到另一方,修复数据不一致的情况。
回滚机制
- 如果在灰度发布过程中发现严重的数据不一致问题,比如金额计算出现错误,这可能会导致数据的错误积累和业务的异常。此时,应立即关闭新系统的流量,将所有流量切换回旧系统。同时,要通过 bin log 或备份等方式,将新系统的数据恢复到灰度发布之前的状态,以保证数据的正确性和业务的正常运行。
13、短暂的数据不一致要怎么办呢?
针对短暂的数据不一致问题,可以采取以下措施来处理:
- 如果在灰度发布过程中发现严重的数据不一致问题,比如金额计算出现错误,这可能会导致数据的错误积累和业务的异常。此时,应立即关闭新系统的流量,将所有流量切换回旧系统。同时,要通过 bin log 或备份等方式,将新系统的数据恢复到灰度发布之前的状态,以保证数据的正确性和业务的正常运行。
一、重试机制
重试策略
- 对于因网络波动、资源竞争等原因导致的短暂不一致,可以设置自动重试机制。例如,当调用下游接口失败时,可以重试3次,每次间隔100毫秒。这样可以在短时间内多次尝试完成操作,有可能在短暂问题消失后成功写入数据,从而恢复数据一致性。
- 重试机制可以应用在多种场景,如数据库连接失败时重试写入操作、微服务之间的接口调用失败时重试请求等。
幂等性保障
- 在重试过程中,必须保证操作是幂等的。幂等性是指对同一个操作请求多次执行和执行一次的效果相同。例如,在支付场景中,根据订单号重复提交支付请求时,要确保只扣款一次。可以通过在数据库中添加唯一约束(如订单号在支付记录表中唯一)、使用分布式锁等方式来实现幂等性。这样可以避免因重试导致数据错误,如重复扣款等问题。
二、补偿机制
异步补偿
- 利用消息队列来发送补偿消息。例如,当订单状态未成功更新时,可以发送一个
order_status_update消息。消费者收到消息后,触发状态修正操作。消息队列可以确保消息的可靠传递,即使消费者暂时不可用,消息也可以在之后被消费并处理。 - 例如,使用 RabbitMQ 等消息队列系统,生产者在发现数据不一致时将补偿消息发送到指定队列,消费者订阅该队列并进行相应的补偿处理。
- 利用消息队列来发送补偿消息。例如,当订单状态未成功更新时,可以发送一个
定时任务修复
- 设计数据修复脚本,定时扫描不一致的数据。例如,每天凌晨可以查询状态为“处理中”且超过24小时的订单,然后调用下游接口确认订单的实际状态。如果发现订单实际已经完成,就将状态更新为“已完成”;如果订单失败,则更新为“失败”。
- 示例SQL语句:
这条语句将超过24小时仍处于“处理中”状态的订单更新为“失败”状态,从而修复数据不一致的问题。UPDATE orders SET status = 'failed' WHERE status = 'processing' AND create_time < NOW() - INTERVAL 1 DAY;
三、最终一致性方案
- 采用 BASE 理论
- 消息队列:通过可靠的消息传递机制来保证跨系统操作的最终一致。例如,使用 RocketMQ 的事务消息。在生产者发送消息时,先发送一个 prepare 消息,当生产者的本地事务完成后,再发送 commit 或 rollback 消费者消息。消费者在收到消息后,进行相应的业务操作,这样可以确保在分布式环境下多个系统操作的一致性。
- 分布式事务中间件:如 Seata 的 AT 模式。它通过在数据库中记录 undo log(数据前镜像),在事务回滚时可以利用 undo log 恢复数据。这种方式可以在分布式事务场景下,保证事务的原子性和一致性。
- 对账系统:对于像支付系统这样的核心业务,定期与银行流水等外部数据进行对账。通过对比支付系统记录的交易数据和银行流水数据,找出差异数据。对于差异数据,可以通过人工审核或者自动规则(如根据银行流水状态更新支付系统状态)进行处理,从而实现最终的数据一致。
四、监控与告警
监控设置
- 对关键业务指标进行监控,如订单创建成功率、库存一致性比率等。可以使用 Prometheus 等监控工具来收集这些指标数据。
- 例如,监控订单创建成功率指标,如果成功率低于正常水平,可能意味着存在数据不一致或其他业务问题。
告警机制
- 当数据不一致率超过设定的阈值(如0.1%)时,触发告警。通过 Grafana 等工具配置告警面板,当监控指标达到告警条件时,实时通知运维和开发团队。
- 例如,设置告警规则,当
gray_data_inconsistency_count(灰度数据不一致数量)指标在1分钟内增长超过100个时,向相关人员发送短信、邮件或在即时通讯工具中发送告警通知。这样可以及时发现问题并进行处理,避免短暂不一致问题积累成严重的问题。