一、buffer
Buffer 是 Node.js 中用于处理二进制数据的核心模块,一个元素的大小为一个字节
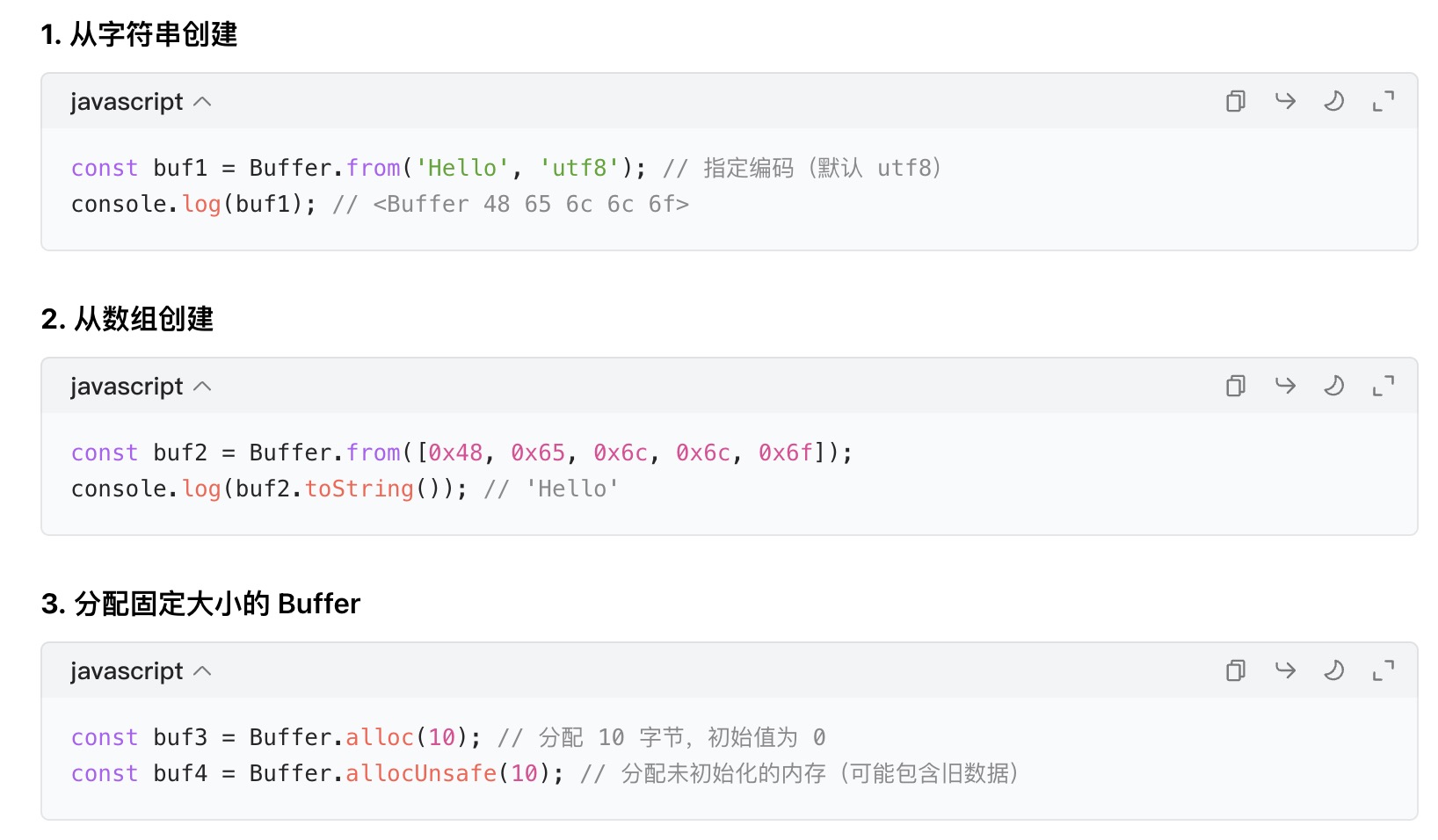
1.创建buffer的方式
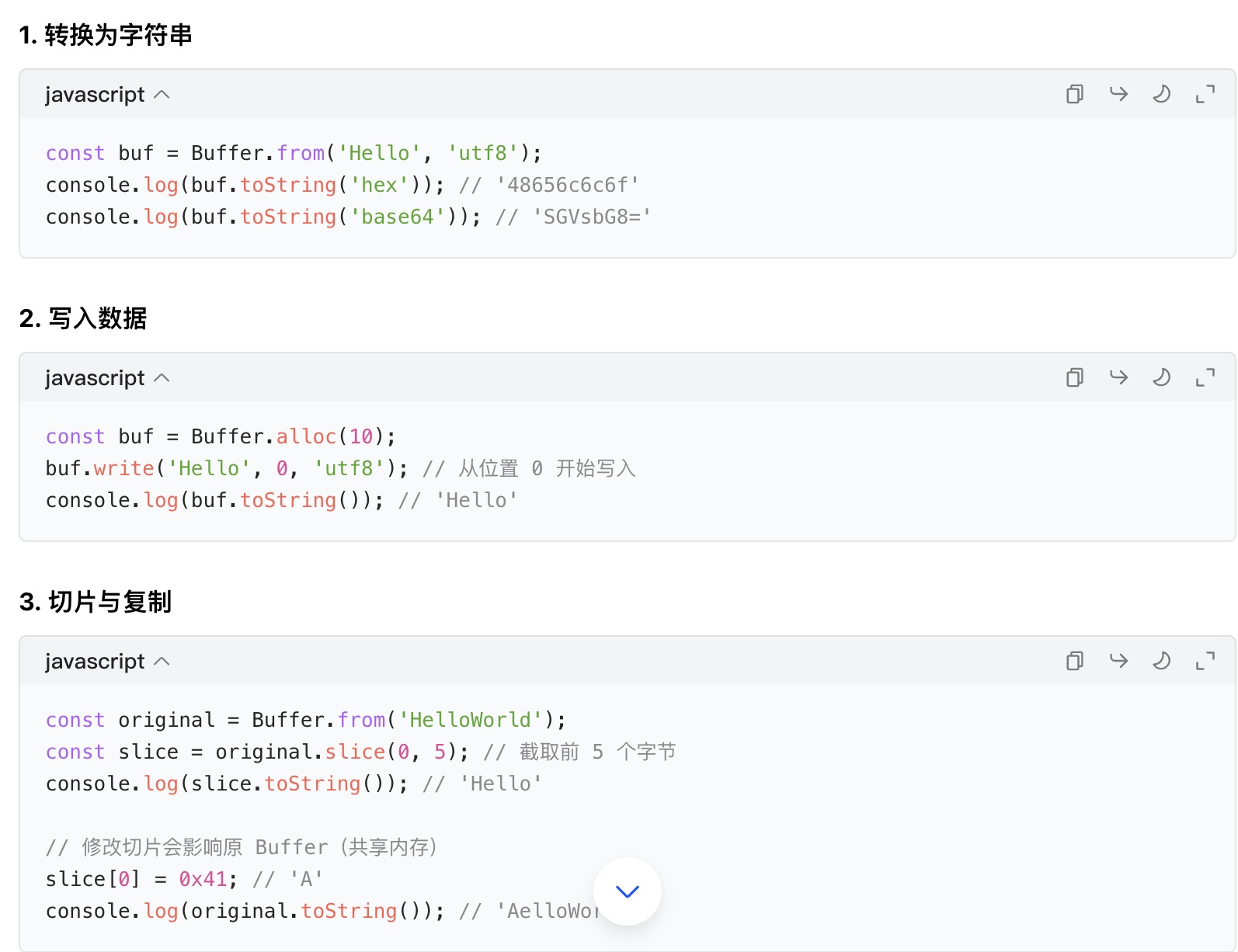
2.常用方法与属性
二、进程与线程
- 进程:程序在操作系统中的一次执行实例,是系统进行资源分配的基本单位(拥有独立内存、文件句柄等)。
- 线程:进程中的一个执行单元,是 CPU调度和分派的基本单位(共享进程资源,仅拥有自己的栈和寄存器)。
进程间通信(IPC)有哪些方式?
- 答:管道(Pipe)、消息队列(Message Queue)、共享内存(Shared Memory)、套接字(Socket)、信号量(Semaphore)等。

三、同步和异步
同步任务执行的过程中,遇到了异步任务,不会阻塞下面同步任务的进行,异步任务像文件IO会交给另外一个线程(底层系统或内置线程池),这个异步任务完成后将它的回调放入队列,如果同步任务全部执行完了,再将队列里的回调取出执行
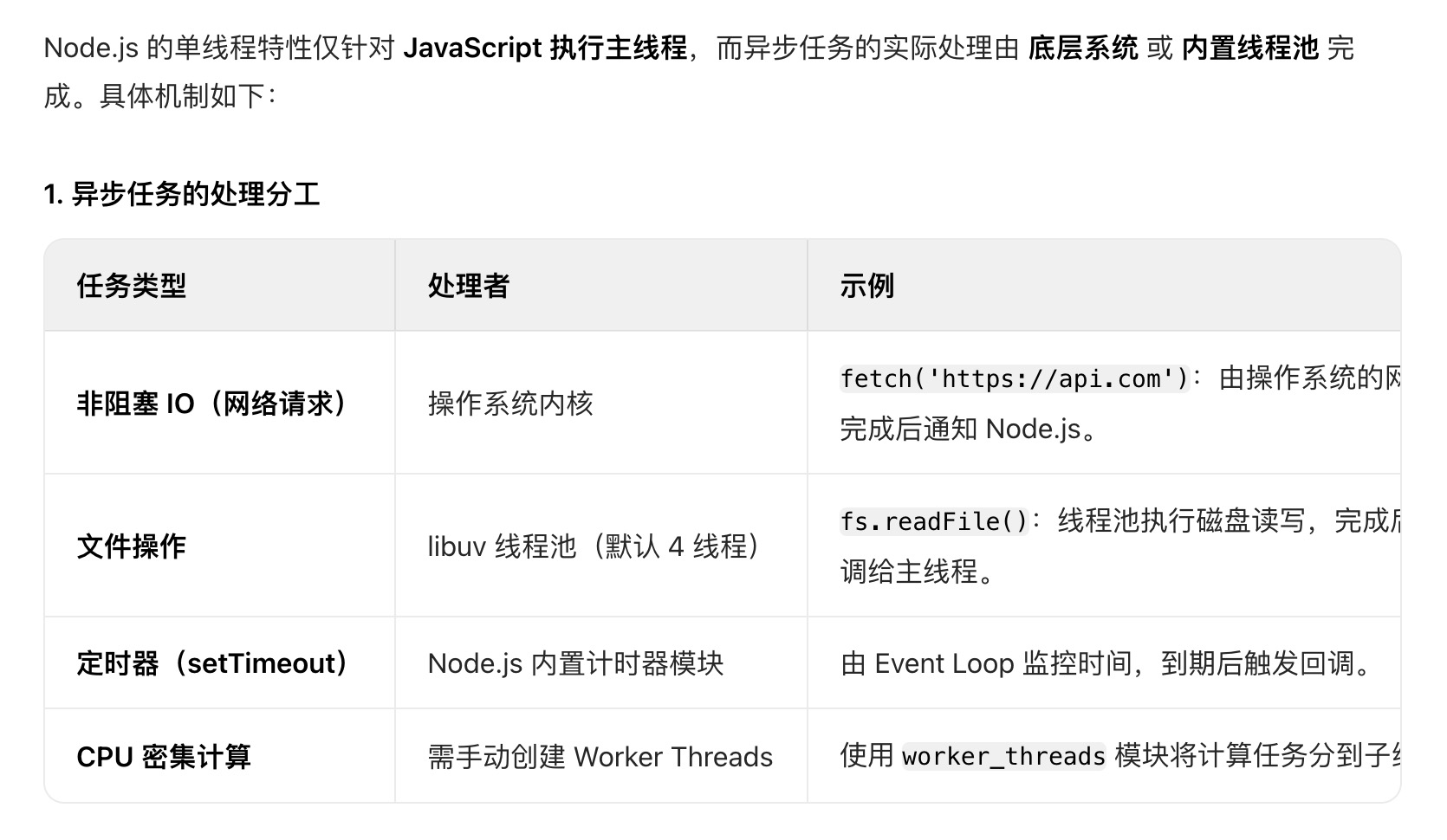
Q1:Node.js 异步任务不阻塞主线程的原理是什么?
A:
- 异步 API(如
fs.readFile)将任务交给 libuv 线程池 或 操作系统。 - 主线程继续执行后续代码,不等待结果。
- 异步操作完成后,结果通过回调放入 任务队列,由 Event Loop 后续处理。
与浏览器异步的区别

相同之处都是异步任务交给其他线程处理,执行完将回调放入队列,然后通过时间循环执行
四、http协议
1.请求报文
HTTP 请求报文由 请求行、请求头、空行、请求体 四部分组成
1. 请求行
请求方法 + 路径 + HTTP版本
GET /index.html HTTP/1.1 - 请求方法:常见的有
GET(获取资源)、POST(提交数据)、PUT(更新资源)、DELETE(删除资源)等。 - 路径:请求的资源地址(如
/api/data)。 - HTTP 版本:如
HTTP/1.1、HTTP/2。
2. 请求头(Headers)
User-Agent:浏览器 / 客户端信息(如Chrome/110)。Accept:客户端支持的响应数据格式(如text/html)。Content-Type:请求体的数据类型(如application/json)。Cookie:携带服务器之前发送的 Cookie。Host:请求的目标域名(如www.example.com)。
User-Agent: Mozilla/5.0 (Windows NT 10.0) Chrome/110
Accept: text/html
Content-Type: application/x-www-form-urlencoded 3. 空行
请求头与请求体之间用 一个空行 分隔,必须存在,用于标识请求头结束。
4. 请求体(Body)
- 非必需:仅当请求方法需要提交数据时存在(如
POST、PUT)。 - 内容:提交的数据,格式由
Content-Type决定(如表单数据、JSON 等)。
2.响应报文
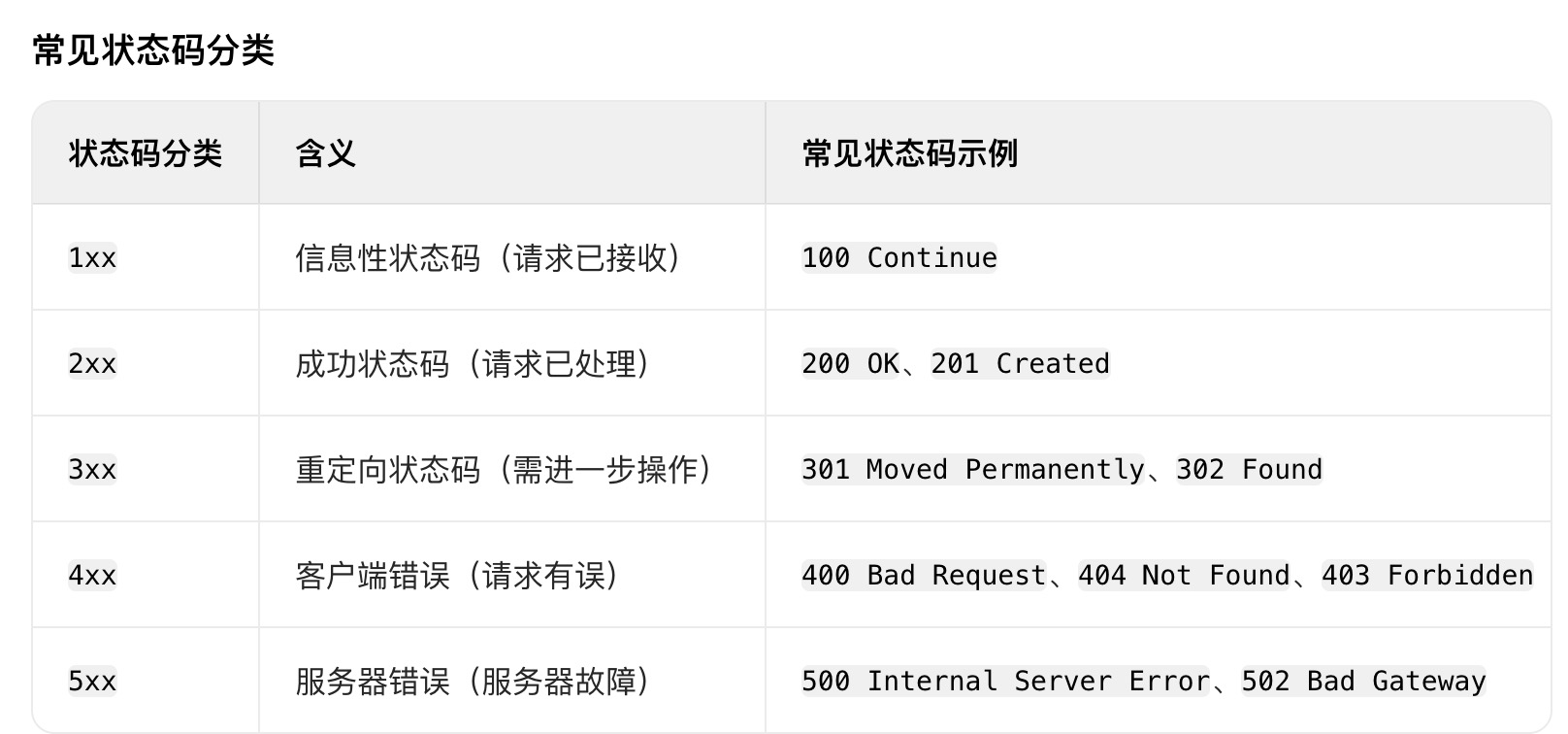
1. 状态行
HTTP版本 + 状态码 + 状态描述
HTTP/1.1 200 OK 2. 响应头(Headers)
Content-Type:响应体的数据类型(如text/html、application/json)。Content-Length:响应体的字节长度。Set-Cookie:向客户端发送 Cookie(用于会话管理)。Server:服务器类型(如Nginx、Apache)。Cache-Control:缓存控制策略(如max-age=3600表示缓存 1 小时)。
3. 空行
响应头与响应体之间用 一个空行 分隔,标识响应头结束,是必需的。
4. 响应体(Body)
- 非必需:通常包含服务器返回的具体数据(如 HTML 页面、JSON 结果、图片二进制数据等)。
- 内容:由
Content-Type字段指定格式,例如:text/html:返回 HTML 页面内容。application/json:返回 JSON 格式的数据。image/png:返回图片二进制数据。
示例(JSON 响应体):
{
"status": "success",
"data": { "user": "admin", "id": 123 }
}
端口(应用程序的不同标识)
不同主机之间的应用通信

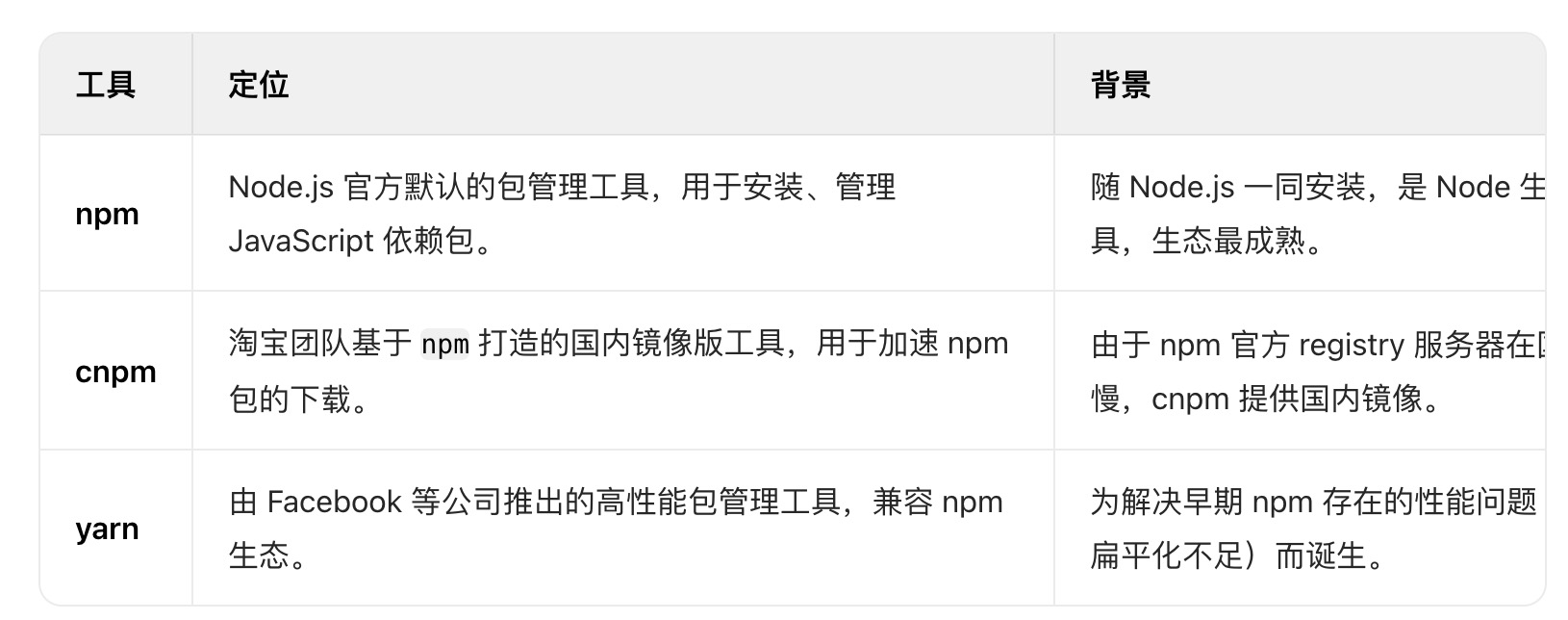
五、包管理工具
五、Koa
1.Context
在 Koa 中,ctx(即 Context 对象)是每个请求的核心容器,封装了 请求(Request) 和 响应(Response) 的所有信息,并提供便捷方法操作它们。
1. 核心作用
- 请求与响应的封装:
ctx.request包含 HTTP 请求信息(如 URL、请求头、查询参数),ctx.response用于设置响应信息(如状态码、响应头、响应体)。 - 中间件间数据传递:
可在中间件中通过ctx存储和共享数据(如用户认证信息、请求处理结果)。
app.use(async (ctx) => {
// 请求相关
ctx.method; // HTTP 方法(GET/POST 等)
ctx.url; // 请求 URL
ctx.query; // 查询参数对象(如 ?id=1 → { id: '1' })
ctx.headers; // 请求头
ctx.request.body; // 请求体(需配合 bodyParser 中间件)
// 响应相关
ctx.status = 200; // 设置状态码
ctx.body = { message: 'Hello' }; // 设置响应体
ctx.set('Content-Type', 'application/json'); // 设置响应头
// 其他
ctx.state.user = { id: 1, name: 'Alice' }; // 在中间件间共享数据
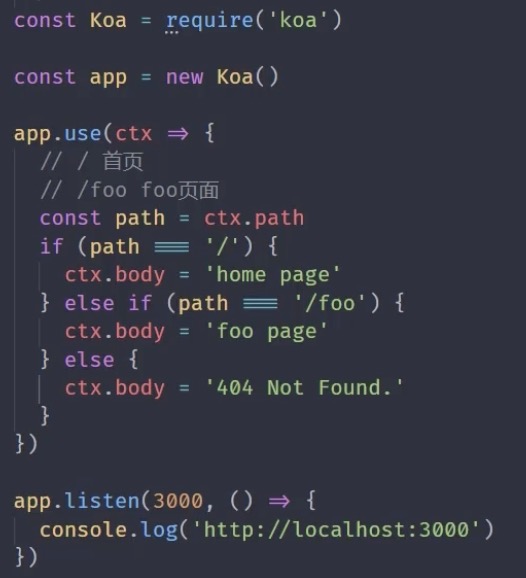
});2.路由
(1)最基础的写法
(2)使用@koa/router
const Koa = require('koa');
const Router = require('@koa/router');
const app = new Koa();
const router = new Router();
// 定义 GET 路由
router.get('/users', async (ctx) => {
ctx.body = [{ id: 1, name: 'Alice' }];
});
// 定义带参数的路由
router.get('/users/:id', async (ctx) => {
const userId = ctx.params.id; // 获取 URL 参数
ctx.body = { id: userId, name: 'User' };
});
// 定义 POST 路由
router.post('/users', async (ctx) => {
const newUser = ctx.request.body; // 获取请求体(需配合 bodyParser 中间件)
ctx.body = newUser;
});
// 使用路由中间件
app.use(router.routes());
app.use(router.allowedMethods()); // 处理 OPTIONS 请求(自动响应 405/501)
app.listen(3000);
(3)路由重定向
const Koa = require('koa');
const Router = require('@koa/router');
const app = new Koa();
const router = new Router();
// 示例 1:永久重定向(301)
router.get('/old-path', (ctx) => {
ctx.redirect('/new-path'); // 默认 302 临时重定向
});
// 示例 2:指定状态码
router.get('/temporary', (ctx) => {
ctx.redirect('/permanent', 301); // 301 永久重定向
});
// 示例 3:重定向到外部 URL
router.get('/google', (ctx) => {
ctx.redirect('https://www.google.com');
});
app.use(router.routes());
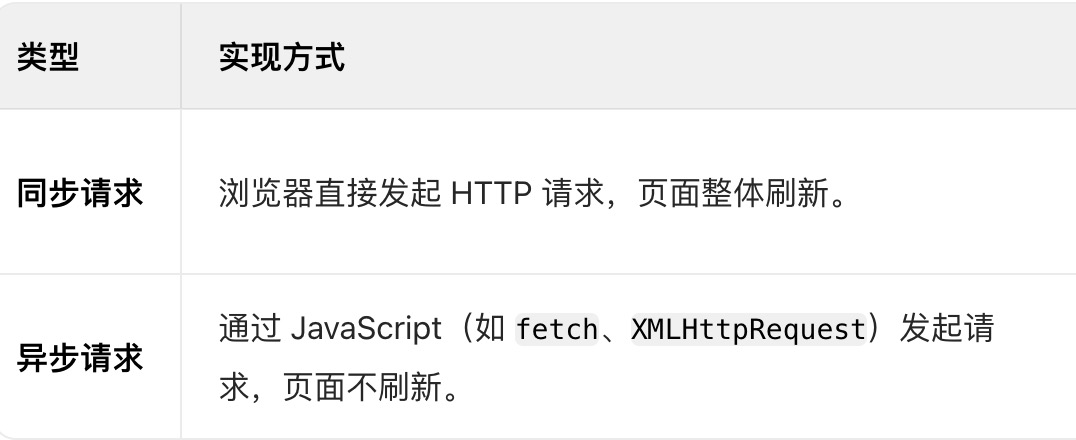
app.listen(3000);默认302重定向
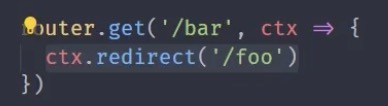
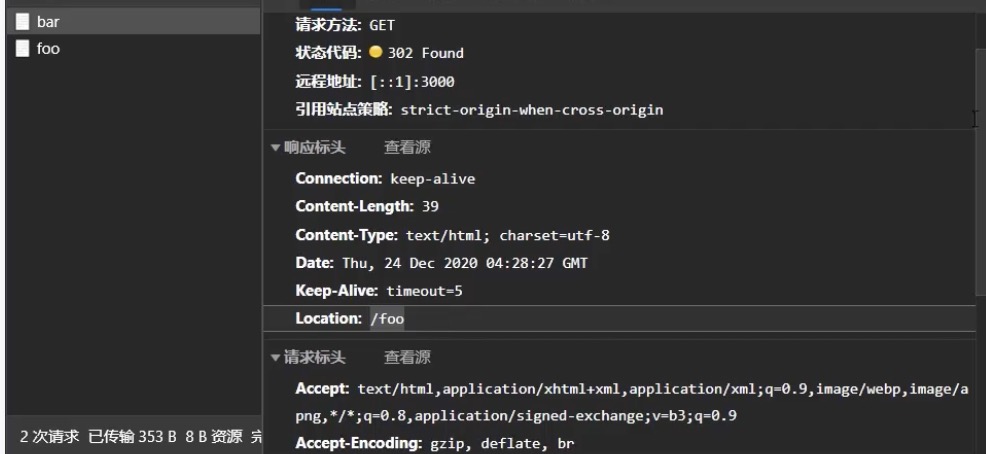
响应报文状态码302,并携带location表明重定向哪里
在 Web 开发中,重定向(Redirect)是服务器向客户端返回特定状态码(如 301/302)和 Location 头,告诉客户端 “请重新请求另一个 URL” 的过程。
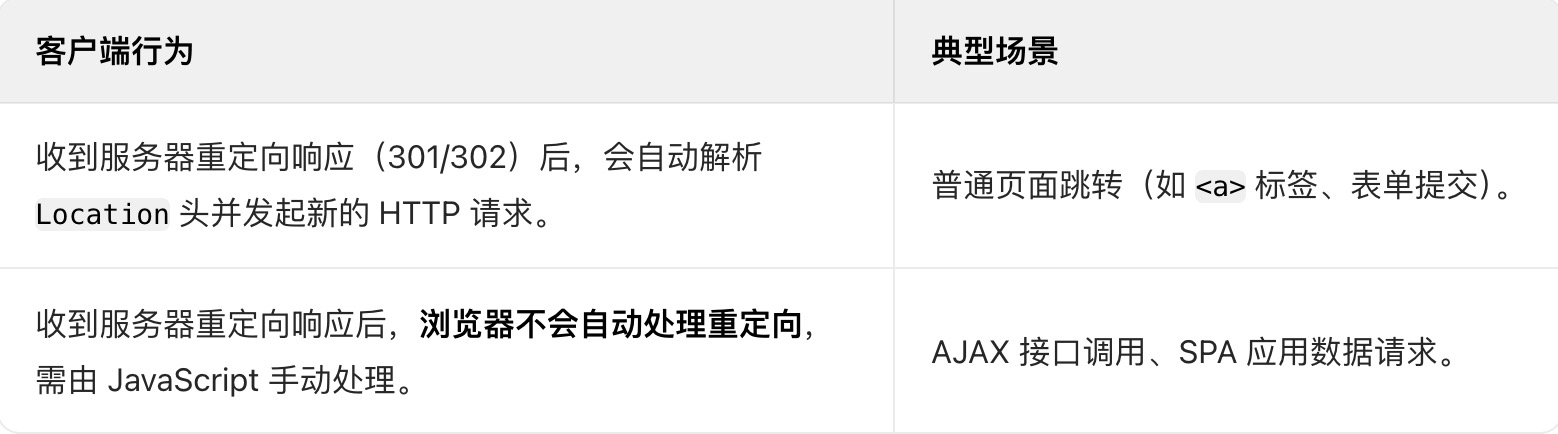
为什么重定向对异步请求无效?
- 当浏览器通过
fetch或XMLHttpRequest发起异步请求时,服务器返回的重定向状态码(301/302)会被浏览器识别,但不会自动触发页面跳转。 - JavaScript 代码必须显式处理响应

异步请求的目标是获取数据,而非页面跳转
- 异步请求通常用于获取数据(如 JSON 格式的响应),而非加载新页面。如果服务器返回重定向响应,前端需要额外逻辑判断是否需要跳转,否则会导致以下问题:
- 数据丢失:重定向会中断当前异步请求的响应解析,无法获取预期数据。
- 用户体验问题:若未手动处理重定向,页面不会刷新,用户可能感知不到跳转(如登录成功后仍停留在登录页)。
3.静态资源托管
const Koa = require('koa');
const serve = require('koa-static');
const app = new Koa();
// 托管 public 目录下的所有静态资源
app.use(serve('./public'));
// 访问 http://localhost:3000/index.html 即可加载 public/index.html
app.listen(3000);
4.Koa中间件
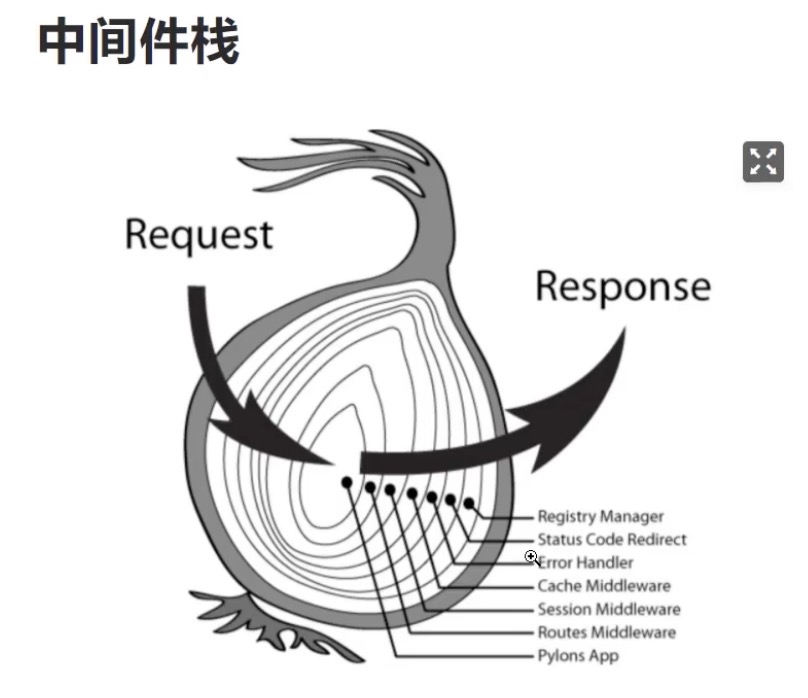
- 多个中间件会形成一个栈结构(middle stack),以 “先进后出”(first - in - last - out)的顺序执行。
- 最外层的中间件首先执行。
- 调用 next 函数,把执行权交给下一个中间件。
- ……
- 最内层的中间件最后执行。
- 执行结束后,把执行权交回上一层的中间件。
- .......
- 最外层的中间件收回执行权后,执行next()函数后面的代码
如果没有调用next函数,那么执行权不会往下传递
异步中间件
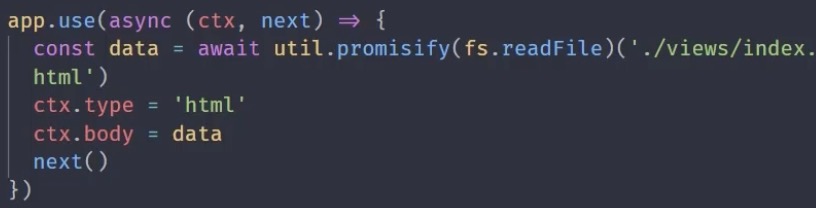
合并中间件
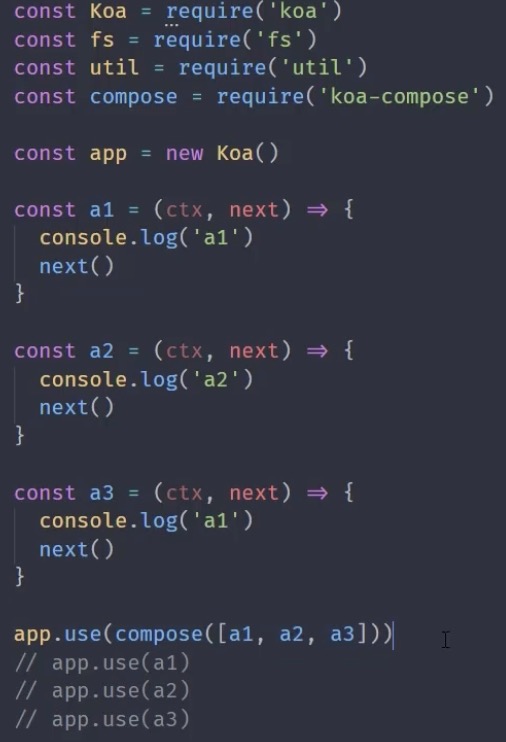
中间件异常处理

在洋葱模型最外层定义一个捕获异常的中间件,避免每个中间件都写try...catch

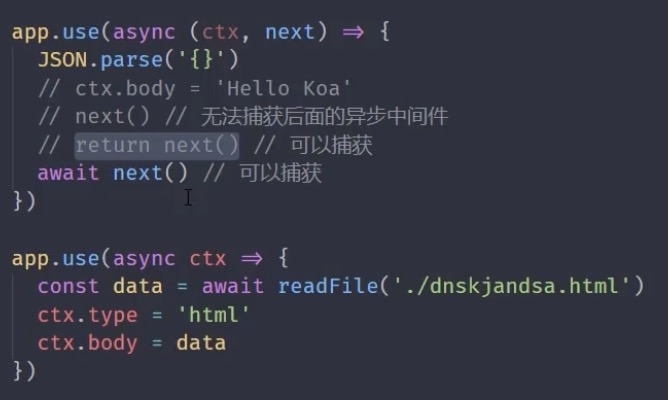
捕获promise异常必须在next前面加await,建议所有next都加上await
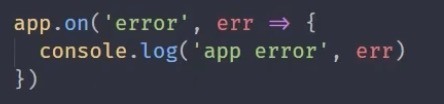
用这个方法也能捕获全局异常
六、express
1.中间件
(1)全局中间件
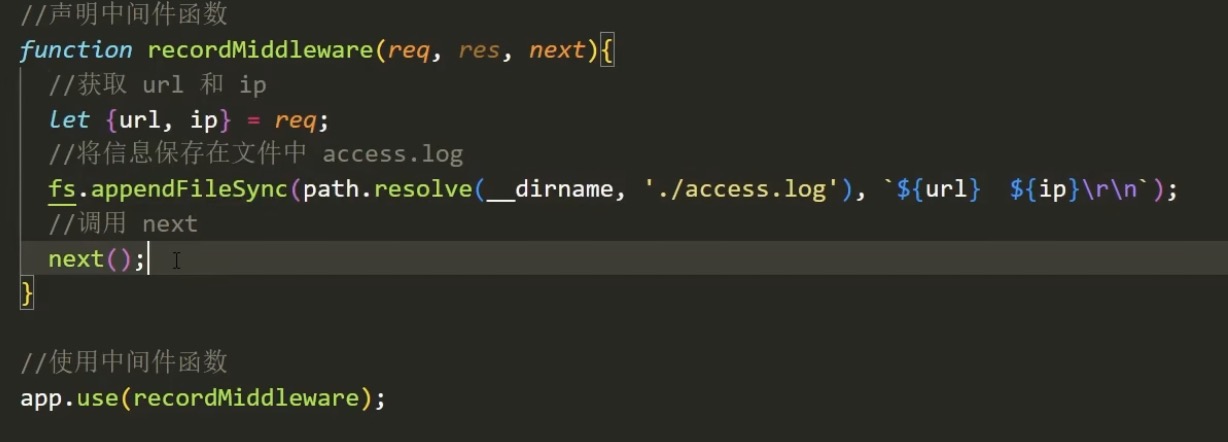
(2)路由中间件
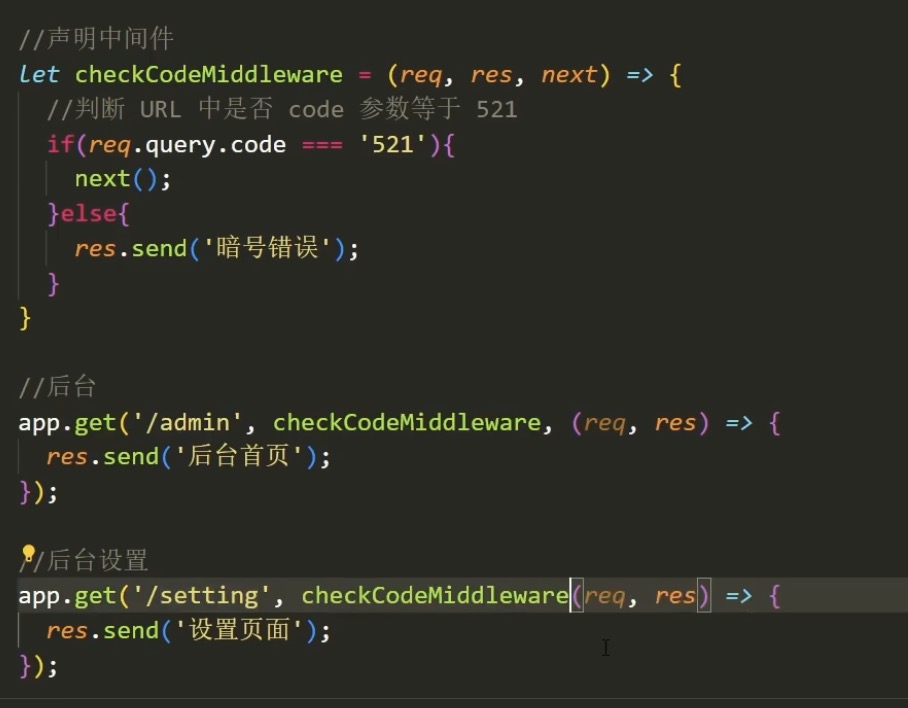
(3)静态资源中间件

express.static 中间件的工作原理是:当你指定一个目录(如 public 目录)作为静态资源目录后,它会自动处理对该目录下文件的请求。例如执行 app.use(express.static('public')); 后,只要客户端请求的路径与 public 目录下的文件路径匹配,Express 就会自动将对应的文件发送给客户端,无需再编写额外的路由处理函数。比如 public 目录下有 index.html 文件,客户端访问 http://localhost:3000/index.html 就能直接获取该文件 。
2.会话控制

(1)cookie
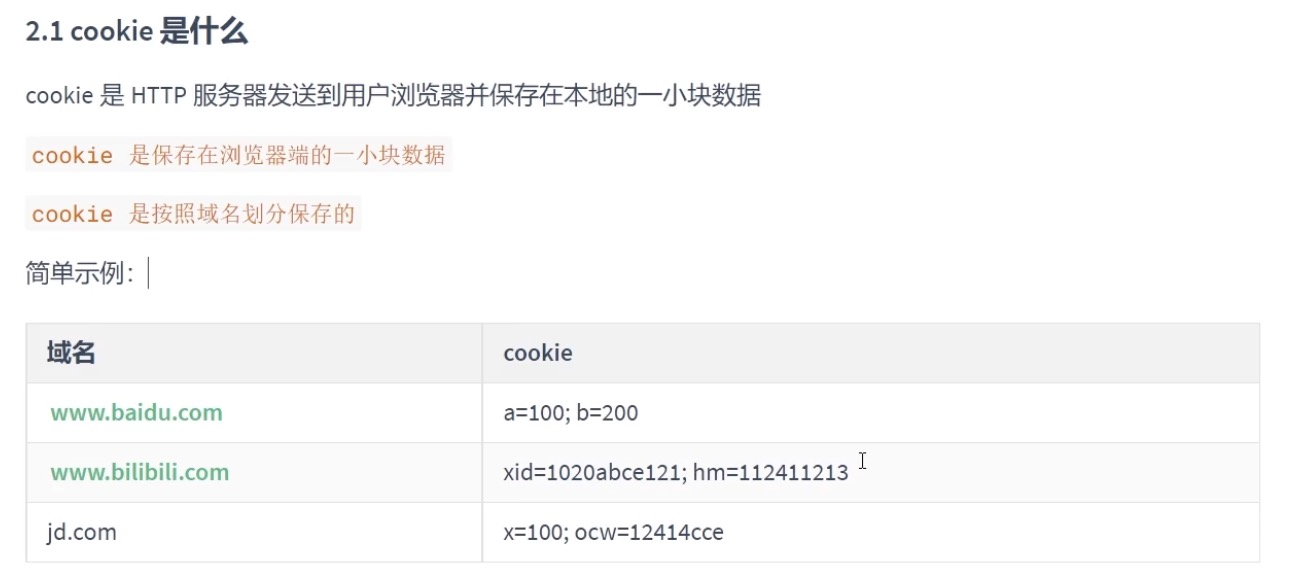

服务器首次响应时设置 Cookie
当用户访问服务器(如登录操作),服务器会在响应头中添加 Set-Cookie 字段,告知浏览器创建 Cookie。

浏览器自动存储并携带 Cookie
浏览器接收到 Set-Cookie 后,会将数据存储在本地。后续每次请求同一域名下的资源时,自动在请求头中添加 Cookie 字段,将数据发送给服务器。
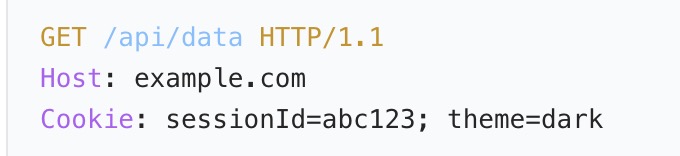
(2)session
关键组成部分
- Session ID:全局唯一标识符(UUID),用于关联客户端与服务器会话数据。
- Session 数据:存储在服务器内存、数据库或缓存中(如用户登录状态、购物车信息)。
- 存储载体:通过 Cookie 或 URL 重写传递 Session ID(默认使用 Cookie)。
基于 Cookie 的 Session 实现
- 用户首次请求服务器,服务器创建 Session 并生成
session_id。 - 服务器通过响应头
Set-Cookie: session_id=xxx将session_id存入客户端 Cookie。 - 后续请求中,客户端自动携带
session_id的 Cookie,服务器通过该 ID 查找对应 Session 数据。
面试题
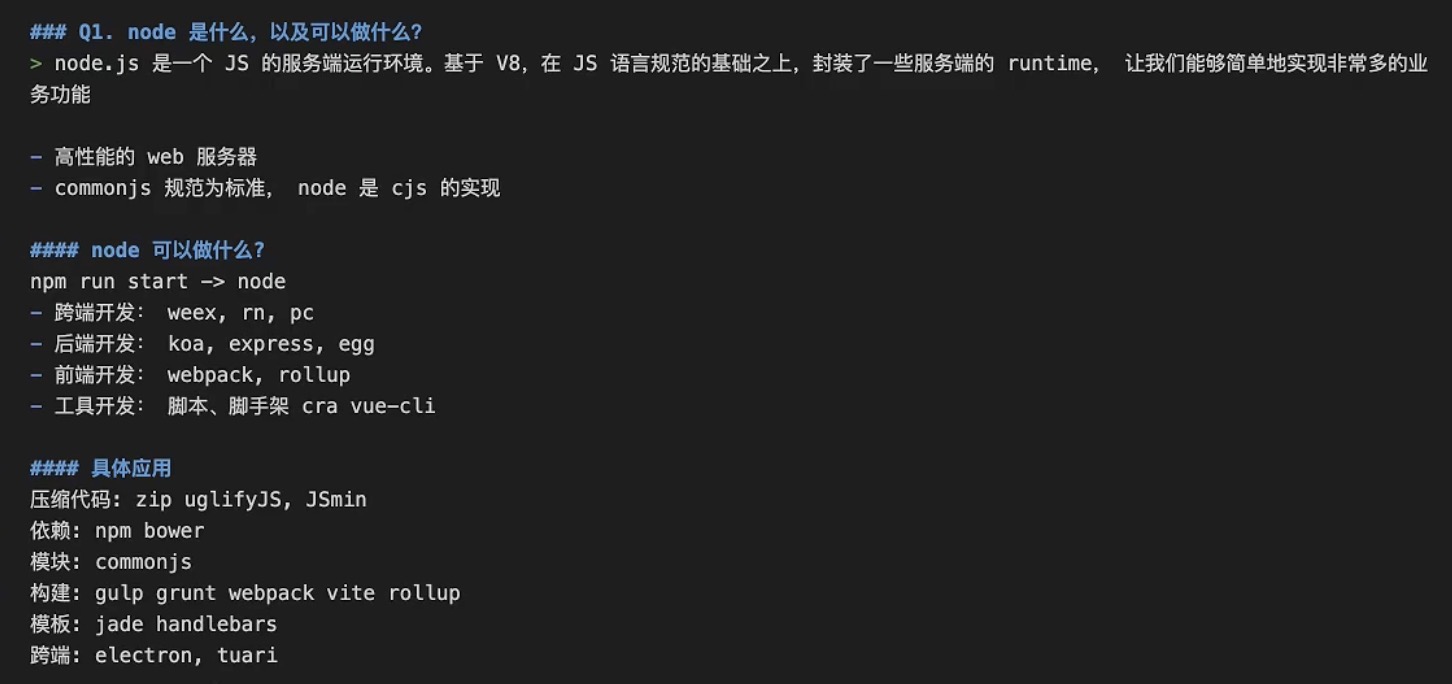
Node 的架构
Native Modules
- 是暴露给开发者使用的接口,通过 JavaScript 实现。常见的有
path(用于处理文件路径) 、fs(文件系统操作) 、http(创建 HTTP 服务器与客户端) 等模块 。开发者可直接调用这些模块提供的方法,便捷地实现各类功能。
Builtin Modules
- 作为中间层,能够让 Node 进行一些更底层的操作。它起到桥梁作用,连接上层应用与底层系统资源,使 Node 具备更强大的能力。
基础组件
- v8:谷歌开源的高性能 JavaScript 引擎,负责解析和执行 JavaScript 代码。它将 JavaScript 代码编译为高效的机器码,极大提升了代码执行效率。
- libuv:一个用 C 编写的高性能、异步非阻塞的 I/O 库 。它实现了 Node 的事件循环机制,处理诸如文件 I/O、网络 I/O 等异步操作,是 Node 实现异步编程的关键基础。
- http - parser:专门用于处理网络报文,解析 HTTP 请求和响应,帮助 Node 高效处理网络通信相关任务。
- openssl:用于处理加密算法,保障网络通信安全,如在 HTTPS 通信中实现数据加密和解密等操作 。
- zlib:主要用于文件压缩与解压缩,可有效减少数据传输量,提升网络传输效率。
硬件与操作系统层面
Node 的运行依赖于 CPU、GPU、RAM、DISK 等硬件资源,并且与操作系统(OS)紧密交互,实现对底层资源的合理利用。
存在的问题
线程与稳定性方面
- JavaScript 在 Node 中是单线程运行。这意味着在同一时间只能处理一个任务,虽然避免了多线程编程中的复杂同步问题,但也使得 Node 应用相对脆弱。例如,当某个任务耗时过长(如复杂计算或长时间的 I/O 操作),会阻塞整个线程,导致应用无法响应其他请求。为解决这个问题,常采用
cluster模块实现多进程并发处理,或者使用pm2这类进程管理工具,来管理多个 Node 进程,提高应用的性能和稳定性。
数据库支持方面
- Node 对 MongoDB、MySQL 等常见数据库有较好的支持,有丰富的驱动和成熟的生态,方便开发者进行数据存储与读取操作。然而,对于 Elasticsearch(es) 、neo4j、tigerGraph 等数据库,支持程度相对一般,相关的驱动和工具在功能完善度、易用性等方面可能存在不足,开发者在使用时可能需要花费更多精力进行适配和调试。
Node 环境与浏览器环境的区别
运行引擎与宿主环境
- 运行引擎:Node 和浏览器(以 Chrome 为例 )都使用 V8 引擎解析和执行 JavaScript 代码。
- 宿主环境:
- Node:宿主环境是服务器端,提供了一系列与服务器操作相关的 API ,如
fs(文件系统操作 )、path(处理文件路径 )、http(创建 HTTP 服务器与客户端 )等 。这些 API 用于处理服务器上的文件、网络通信等任务。 - 浏览器:宿主环境是客户端,提供浏览器相关 API ,用于操作 DOM(文档对象模型 )和 BOM(浏览器对象模型 )。DOM 用于对网页内容进行增删改查,BOM 用于访问浏览器窗口、导航等功能。
- Node:宿主环境是服务器端,提供了一系列与服务器操作相关的 API ,如
事件循环机制
- 浏览器:事件循环涉及微任务、宏任务,还有
requestAnimationFrame(raf ,用于高效实现动画 )、layout(页面布局更新 )、requestIdleCallback(在浏览器空闲时执行任务 ) 等。其事件循环主要围绕页面渲染、用户交互等浏览器特定场景进行调度。 - Node:事件循环机制与浏览器不同,主要基于
libuv库实现,采用不同的阶段处理任务,虽然也有类似宏任务和微任务的概念,但具体细节和执行顺序有差异。
模块规范
- Node:一般遵循 CommonJS 规范。在 CommonJS 中,使用
require()方法引入模块,使用exports或module.exports导出模块内容,方便在服务器端进行模块化开发。 - 浏览器:目前正逐步采用 ECMAScript 模块(ESM)标准。在 ESM 中,使用
import语句引入模块,export语句导出模块内容,这种方式更符合现代 JavaScript 语言的发展趋势,并且支持静态分析等特性。
Node的事件循环机制
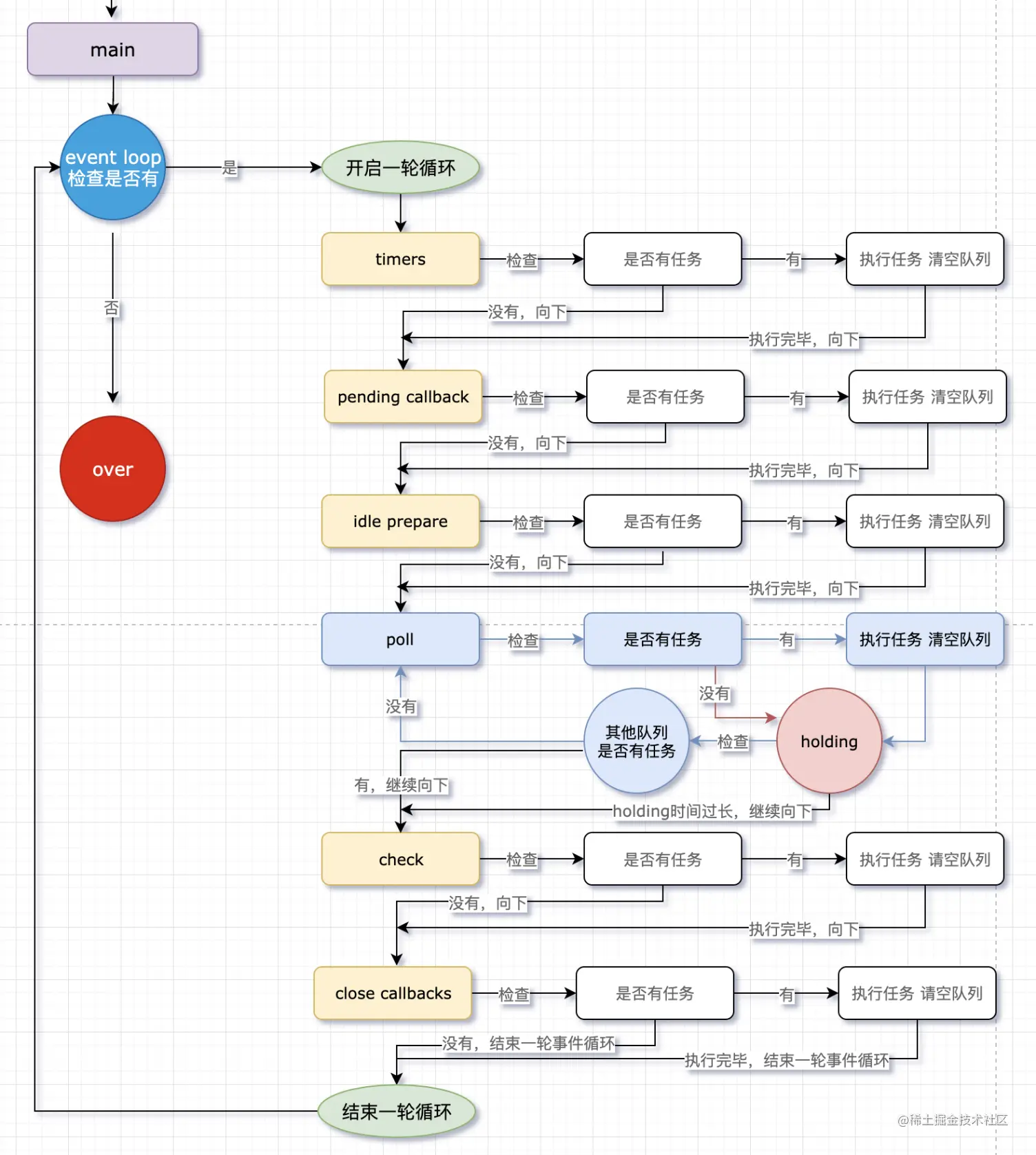
存在timers, pending callback, idle prepare, poll, check, close callbacks, 依次检查每个队列中是否有回调任务,有的话取出来执行并清空队列,并到下一个列队中间进行检查,对于poll队列,会进行等待,如果其他队列中有任务了则继续进入下一个队列,如果没有的话一直循环等待,直到到达一定时间后才进入下一个队列检查。
Node 中的 process.nextTick,这个函数其实是独立于 Event Loop 之外的,它有一个自己的队列,当每个阶段完成后,如果存在 nextTick 队列,就会清空队列中的所有回调函数,并且优先于其他 microtask 执行。
V8垃圾回收机制
V8将堆内存分为新生代和老生代
1.新生代
新生代中对象存活时间比较短。对于新生代,有from和to两个空间,在这两个空间中必定有一个是空闲的,一个是使用的。新分配的对象会被放到from空间,当from空间被占满的时候,新生代GC算法被启动,算法检查from中存活的对象并把它们复制到to空间中,如果有失活的对象就销毁,当复制完成后,清空from空间,再交换from和to空间。
2.老生代
老生代中的对象一般存活时间较长且数量也多,使用了两个算法,分别是标记清除算法和标记压缩算法。
- 新生代中的对象是否已经经历过一次 Scavenge 算法,如果经历过的话,会将对象从新生代空间移到老生代空间中。
- To 空间的对象占比大小超过 25 %。在这种情况下,为了不影响到内存分配,会将对象从新生代空间移到老生代空间中。
在老生代中,以下情况会先启动标记清除算法:
- 某一个空间没有分块的时候
- 空间中被对象超过一定限制
- 空间不能保证新生代中的对象移动到老生代中
清除对象后会造成堆内存出现碎片的情况,当碎片超过一定限制后会启动压缩算法。在压缩过程中,将活的对象向一端移动,直到所有对象都移动完成然后清理掉不需要的内存。

标记清除法
从GC root通过递归遍历所有对象,将访问到的对象标记为可达,没标记到的被认定为不再使用。标记完成后,垃圾回收器遍历堆内存中的所有对象,将那些没有被标记为 “可达” 的对象视为 “垃圾” ,释放它们所占用的内存空间
缺点
- 产生内存碎片:清除阶段只是简单释放未标记对象的内存,不会对剩余内存进行整理,长时间运行会出现大量不连续的内存碎片,影响后续大对象的内存分配。
- 暂停应用程序:执行过程中往往需要暂停整个应用程序(即 “stop - the - world”) ,会导致应用程序短暂无响应,在对实时性要求高的场景(如动画、游戏等)中,可能造成用户体验下降。
优化策略
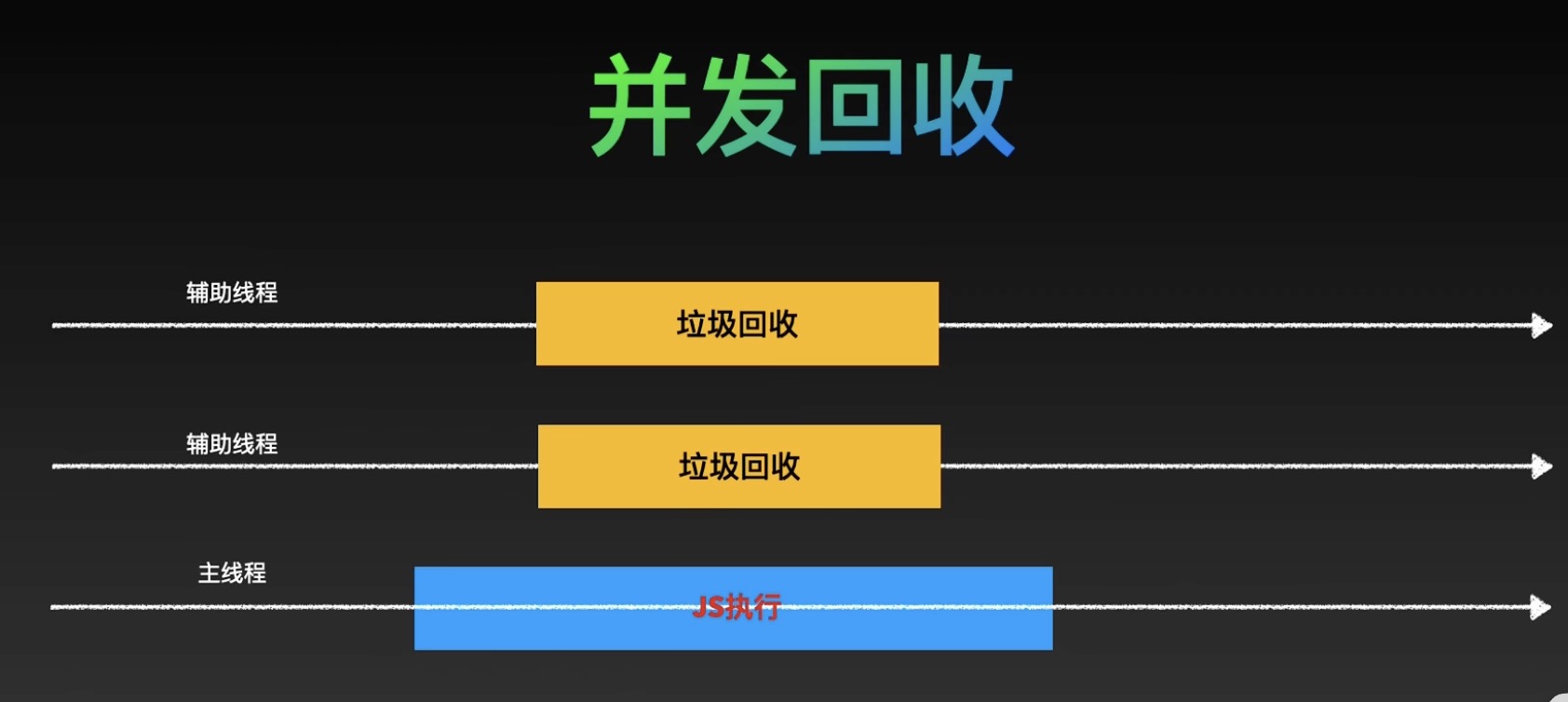
- 增量标记:将标记过程拆分成多个小步骤,穿插在程序运行过程中,避免一次性长时间暂停应用程序。
- 并行标记:利用多核 CPU 的优势,开启多个线程同时进行标记工作,缩短标记阶段的时间,减少对应用程序的影响。
- 结合其他算法:与标记整理算法、复制算法等结合使用,弥补自身产生内存碎片等不足,更高效地管理内存。