1.前言
之前2025.4.10跑b站up的霹雳吧啦Wz的MASK-RCNN代码, 但是没有写博客记录怎么调整的,现在忘光了,惨痛教训。故这次重新跑,并记录使用流程。
相关原理视频课可看 该up的视频Mask R-CNN源码解析(Pytorch)_哔哩哔哩_bilibili
本文章大概内容包括:
1.如何将自已的实例分割数据集转换为VOC,COCO的 格式 进行训练
2.在跑代码时,需要对代码哪些部分进行改动,以保证训练成功。
2.数据集制作
2.1VOC数据集构建
见之前写的labelme使用博客
使用labelme标注图片,得到 图片及对应json标签

通过labelme官方(在github实例分割部分)提供的代码, 转换为VOC数据集格式,VOC文件夹包含如下内容(具体内容见之前的博客使用labelme进行实例分割标注_labelme实例分割标注-CSDN博客)
现在获得VOC格式数据集,但如果使用实例分割数据集训练MASK-RCNN网络,但是还需要再对该VOC数据集格式进行更改。因为现在获取的VOC数据集包含了语义分割(Class)和实例分割(Object)
参考该博文PASCAL VOC2012数据集介绍_pascal voc 2012-CSDN博客
进行构建实例分割VOC数据集
PASCAL VOC2012数据集格式:
VOCdevkit
└── VOC2012
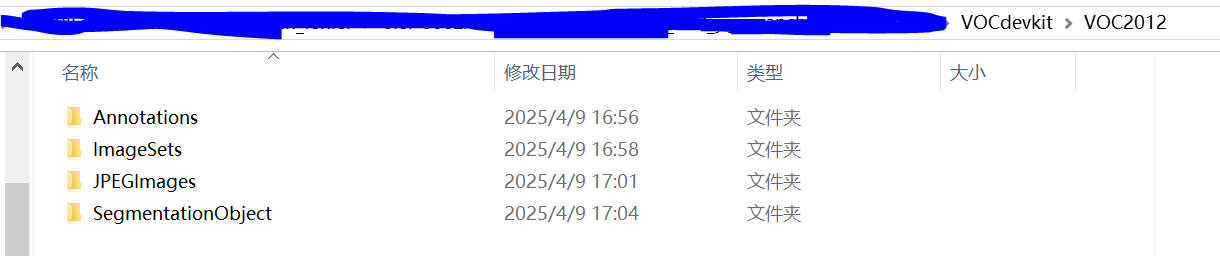
├── Annotations 所有的图像标注信息(XML文件)
├── ImageSets
│ ├── Action 人的行为动作图像信息
│ ├── Layout 人的各个部位图像信息
│ │
│ ├── Main 目标检测分类图像信息
│ │ ├── train.txt 训练集(5717)
│ │ ├── val.txt 验证集(5823)
│ │ └── trainval.txt 训练集+验证集(11540)
│ │
│ └── Segmentation 目标分割图像信息
│ ├── train.txt 训练集(1464)
│ ├── val.txt 验证集(1449)
│ └── trainval.txt 训练集+验证集(2913)
│
├── JPEGImages 所有图像文件
├── SegmentationClass 语义分割png图(基于类别)
└── SegmentationObject 实例分割png图(基于目标)网上下载的VOC2012数据集构造:
Annotations文件夹:
每张图片的xml格式标注信息
2007_000027.xml 文件内容
<annotation>
<folder>VOC2012</folder>
<filename>2007_000027.jpg</filename>
<source>
<database>The VOC2007 Database</database>
<annotation>PASCAL VOC2007</annotation>
<image>flickr</image>
</source>
<size>
<width>486</width>
<height>500</height>
<depth>3</depth>
</size>
<segmented>0</segmented>
<object>
<name>person</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>174</xmin>
<ymin>101</ymin>
<xmax>349</xmax>
<ymax>351</ymax>
</bndbox>
<part>
<name>head</name>
<bndbox>
<xmin>169</xmin>
<ymin>104</ymin>
<xmax>209</xmax>
<ymax>146</ymax>
</bndbox>
</part>
<part>
<name>hand</name>
<bndbox>
<xmin>278</xmin>
<ymin>210</ymin>
<xmax>297</xmax>
<ymax>233</ymax>
</bndbox>
</part>
<part>
<name>foot</name>
<bndbox>
<xmin>273</xmin>
<ymin>333</ymin>
<xmax>297</xmax>
<ymax>354</ymax>
</bndbox>
</part>
<part>
<name>foot</name>
<bndbox>
<xmin>319</xmin>
<ymin>307</ymin>
<xmax>340</xmax>
<ymax>326</ymax>
</bndbox>
</part>
</object>
</annotation>ImageSets文件夹:

里面包含了图片的索引 (图片名的,不包含文件类型名)
如 2007_000032.jpg, 在.txt文件中内容为 2007_000032
由于目前是要用实例分割数据集,所以只看Segmentation文件夹
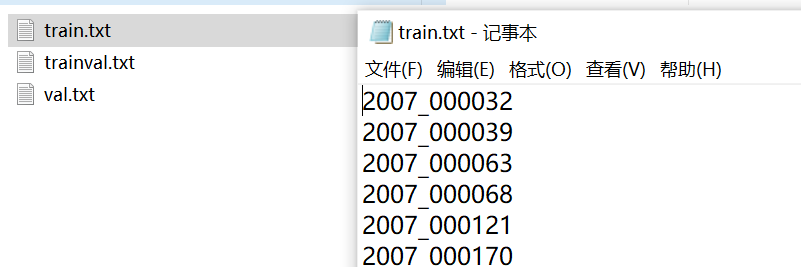 每个txt文件都包含图像的索引,内容如上图, trainval.txt文件内容 包含train.txt和 val.txt文件的内容。
每个txt文件都包含图像的索引,内容如上图, trainval.txt文件内容 包含train.txt和 val.txt文件的内容。
JPEGImages :
SegmentationClass
内容为语义分割标签

SegmentationObject:
实例分割标签

制作mask-rcnn训练所需的个人VOC格式数据集
参考上述PASCAL VOC2012数据集格式,发现使用labelme标注,并经过转换voc格式的数据集还缺失一个xml文件,因此需要将注释信息:json文件转换成xml文件
在网上查找json2xml代码:
参考博客:数据格式转换(labelme、labelimg、yolo格式相互转换)_labelme转yolo-CSDN博客
在json多边形的每个实例标签中所有点 ,找到(xmin,ymin),(xmax,ymax)
原文(支持 json中 ‘rectangle’ 和 ‘polygon’ 两种模式的转换,其中 ‘polygon’ 的转换方式为,替换成最小外接矩形的左上角和右下角坐标。)
代码 json2xml
# -*- coding: utf-8 -*-
import numpy as np
import json
from lxml import etree
import os
from tqdm import tqdm
class ReadJson(object):
'''
读取json文件,获取相应的标签信息
'''
def __init__(self, json_path):
self.json_data = json.load(open(json_path, encoding="utf-8"))
self.filename = self.json_data['imagePath']
self.width = self.json_data['imageWidth']
self.height = self.json_data['imageHeight']
self.coordis = []
# 构建坐标
self.process_shapes()
def process_shapes(self):
for single_shape in self.json_data['shapes']:
if single_shape['shape_type'] == "rectangle":
bbox_class = single_shape['label']
xmin = single_shape['points'][0][0]
ymin = single_shape['points'][0][1]
xmax = single_shape['points'][1][0]
ymax = single_shape['points'][1][1]
self.coordis.append([xmin, ymin, xmax, ymax, bbox_class])
elif single_shape['shape_type'] == 'polygon':
bbox_class = single_shape['label']
temp_points = single_shape['points']
temp_points = np.array(temp_points)
xmin, ymin = temp_points.min(axis=0)
xmax, ymax = temp_points.max(axis=0)
self.coordis.append([xmin, ymin, xmax, ymax, bbox_class])
else:
print("shape type error, shape_type not in ['rectangle', 'polygon']")
def get_width_height(self):
return self.width, self.height
def get_filename(self):
return self.filename
def get_coordis(self):
return self.coordis
class labelimg_Annotations_xml:
def __init__(self, folder_name, filename, path, database="Unknown"):
self.root = etree.Element("annotation")
child1 = etree.SubElement(self.root, "folder")
child1.text = folder_name
child2 = etree.SubElement(self.root, "filename")
child2.text = filename
child3 = etree.SubElement(self.root, "path")
child3.text = path
child4 = etree.SubElement(self.root, "source")
child5 = etree.SubElement(child4, "database")
child5.text = database
def set_size(self, width, height, channel):
size = etree.SubElement(self.root, "size")
widthn = etree.SubElement(size, "width")
widthn.text = str(width)
heightn = etree.SubElement(size, "height")
heightn.text = str(height)
channeln = etree.SubElement(size, "channel")
channeln.text = str(channel)
def set_segmented(self, seg_data=0):
segmented = etree.SubElement(self.root, "segmented")
segmented.text = str(seg_data)
def set_object(self, label, x_min, y_min, x_max, y_max,
pose='Unspecified', truncated=0, difficult=0):
object = etree.SubElement(self.root, "object")
namen = etree.SubElement(object, "name")
namen.text = label
posen = etree.SubElement(object, "pose")
posen.text = pose
truncatedn = etree.SubElement(object, "truncated")
truncatedn.text = str(truncated)
difficultn = etree.SubElement(object, "difficult")
difficultn.text = str(difficult)
bndbox = etree.SubElement(object, "bndbox")
xminn = etree.SubElement(bndbox, "xmin")
xminn.text = str(x_min)
yminn = etree.SubElement(bndbox, "ymin")
yminn.text = str(y_min)
xmaxn = etree.SubElement(bndbox, "xmax")
xmaxn.text = str(x_max)
ymaxn = etree.SubElement(bndbox, "ymax")
ymaxn.text = str(y_max)
def savefile(self, filename):
tree = etree.ElementTree(self.root)
tree.write(filename, pretty_print=True, xml_declaration=False, encoding='utf-8')
def json_transform_xml(json_path, xml_path):
json_anno = ReadJson(json_path)
width, height = json_anno.get_width_height()
channel = 3
filename = json_anno.get_filename()
coordis = json_anno.get_coordis()
anno = labelimg_Annotations_xml('JPEGImages', filename, 'JPEGImages')
anno.set_size(width, height, channel)
anno.set_segmented()
for data in coordis:
x_min, y_min, x_max, y_max, label = data
anno.set_object(label, int(x_min), int(y_min), int(x_max), int(y_max))
anno.savefile(xml_path)
if __name__ == "__main__":
'''
目前只能支持 json中 rectangle 和 polygon 两种模式的转换,其中 polygon 的转换方式为,替换成最小外接矩形的左上角和右下角坐标
'''
root_json_dir = r"source_path"
root_save_xml_dir = r"target_path"
#root_save_xml_dir = root_json_dir
for json_filename in tqdm(os.listdir(root_json_dir)):
if not json_filename.endswith(".json"):
continue
json_path = os.path.join(root_json_dir, json_filename)
save_xml_path = os.path.join(root_save_xml_dir, json_filename.replace(".json", ".xml"))
json_transform_xml(json_path, save_xml_path)
2.2制作个人实例分割voc格式数据集 :
经过上一节,将json标签转换为xml格式的标签,开始按照实例分割VOC数据集要求格式进行划分
1.创建文件夹VOCdevkit,然后再创建文件夹VOC2012

2.按照2.1节所示,在VOC2012创建如下4个文件夹,分别填充内容
Annotations文件夹
 Segmentation文件夹
Segmentation文件夹

每个txt文件内容
train用于训练,val用于验证



JPEGImages
SegmentationObject
VOC格式---实例分割数据集制作-----小结
至此,可以获得用于训练up霹雳创建的MASK-RCNN的 VOC数据集 VOCdevkit
3.使用MASK-RCNN进行训练
在进行训练前还需要对代码路径进行修改,并创建json类别文件
3.1创建json类别索引标签
参考从github下载up霹雳的mask-rcnn代码, 借鉴
文件pascal_voc_indices.json,coco91_indices.json
pascal_voc_indices.json内容如下:
{
"1": "aeroplane",
"2": "bicycle",
"3": "bird",
"4": "boat",
"5": "bottle",
"6": "bus",
"7": "car",
"8": "cat",
"9": "chair",
"10": "cow",
"11": "diningtable",
"12": "dog",
"13": "horse",
"14": "motorbike",
"15": "person",
"16": "pottedplant",
"17": "sheep",
"18": "sofa",
"19": "train",
"20": "tvmonitor"
}创建个人的类别索引标签,由于本数据集只有一个物体-mushroom,所以写为:
{
"1": "mushroom"
}3.2租用服务器进行训练
3.2.1修改文件train.py文件
/root/mask_rcnn/train.py
修改1:
是否添加resnet50预训练权重

修改2:
是否载入官方mask-rcnn预训练权重

修改3:
训练集选择加载voc格式实例分割数据集 ,而不是coco数据集格式

验证集选择加载voc格式实例分割数据集 ,而不是coco数据集格式
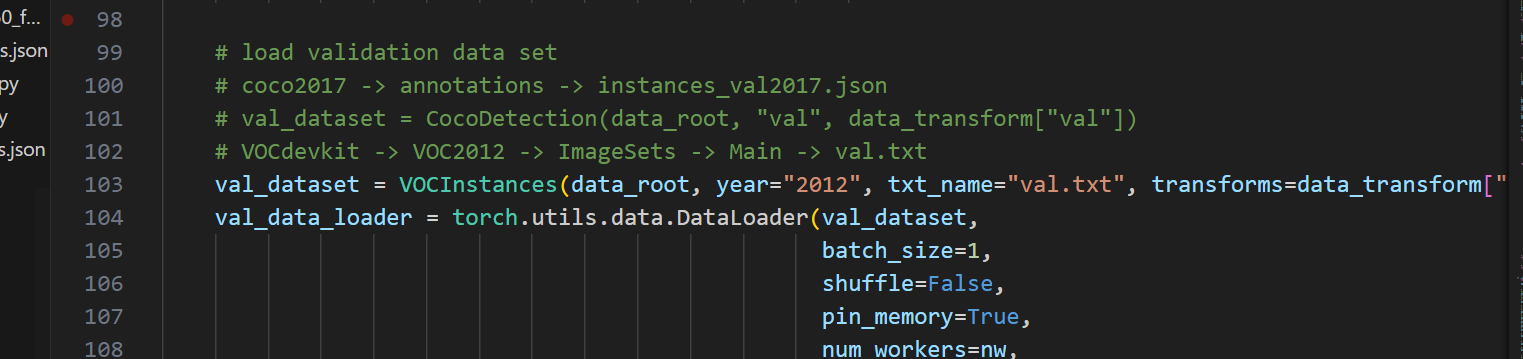
修改4:非常重要,原代码是保存所有轮次训练的权重
如果不指定保存哪一轮次的训练权重,那么该程序就会保存所有轮次的训练权重,那么当代码跑完40epoch,服务器的系统盘内存就会爆满,导致训练失败。
指定保存权重的epoch
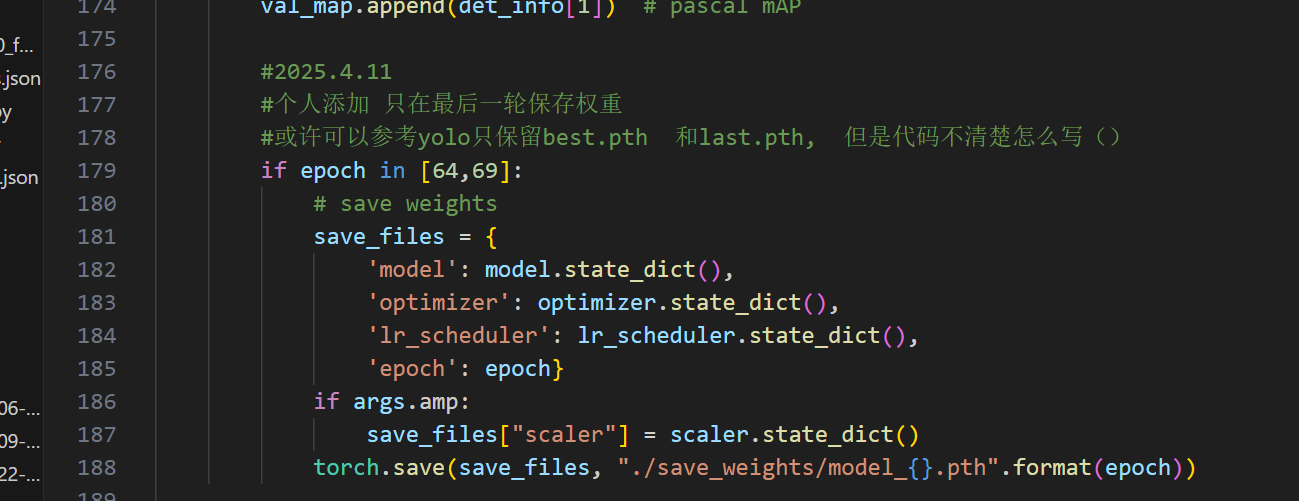
修改5:指定保存权重的路径,
解释:
./los.png 是一个相对路径,表示文件保存在当前工作目录下的位置。
因此如果在租用服务器时,选择直接打开mask_rcnn文件夹,则不用管;如果选择打开/root 文件夹 ,则权重模型文件.pth 则会保存到mask_rcnn文件夹 外部,与mask_rcnn文件夹平级。
因此如果在/root 打开,并使用mask_rcnn文件夹进行训练,则如果想将权重保存在该路径下:/root/mask_rcnn/save_weights/model_64.pth
则需要将代码修改为:
#原始
torch.save(save_files, "./save_weights/model_{}.pth".format(epoch))
#修改
torch.save(save_files,"/root/mask_rcnn/save_weights/save_weights/model_{}.pth".format(epoch))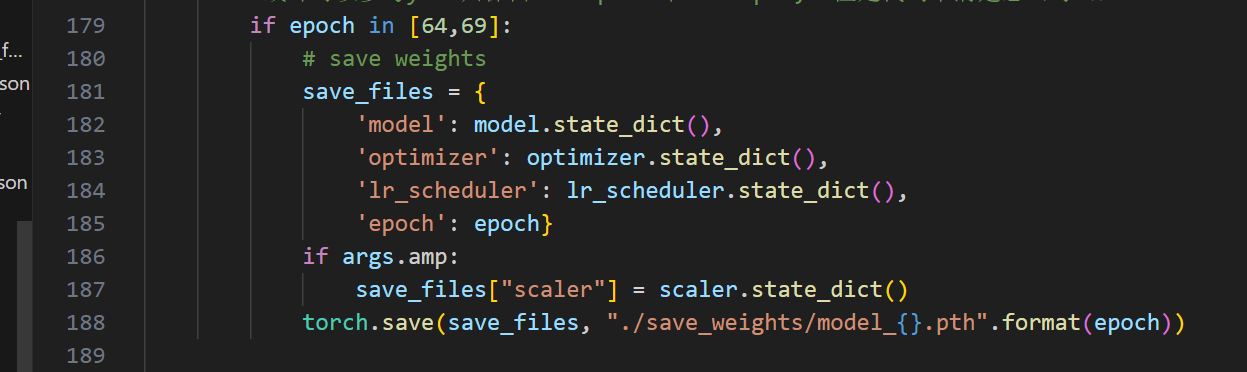
修改6:修改数据集目录,改为自已的voc格式数据集

修改7:修改检查目标类别数
官方voc数据集为20,官方coco数据集为90
个人:根据自已数据集情况决定

修改8:这里也根据修改5进行修改,不过一般保存原状

修改9:修改训练epoch数,学习率
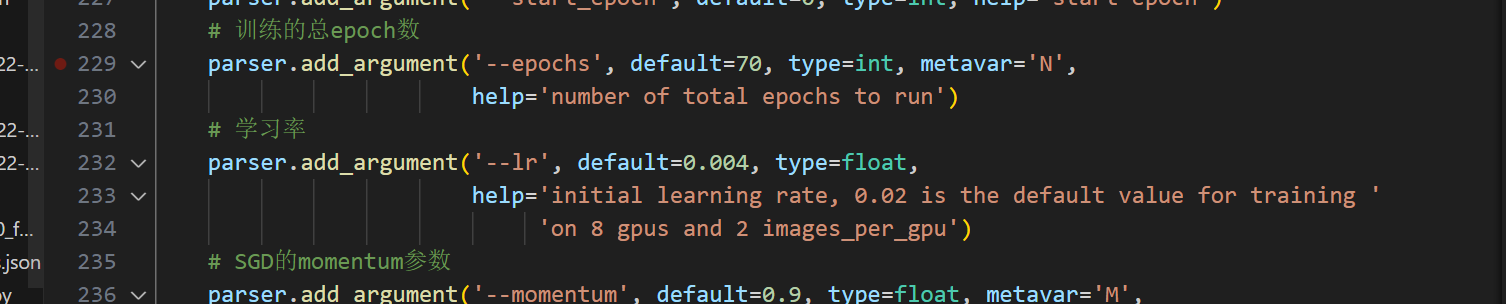
修改10:学习率衰减epoch,学习率衰减因子,batch_size大小
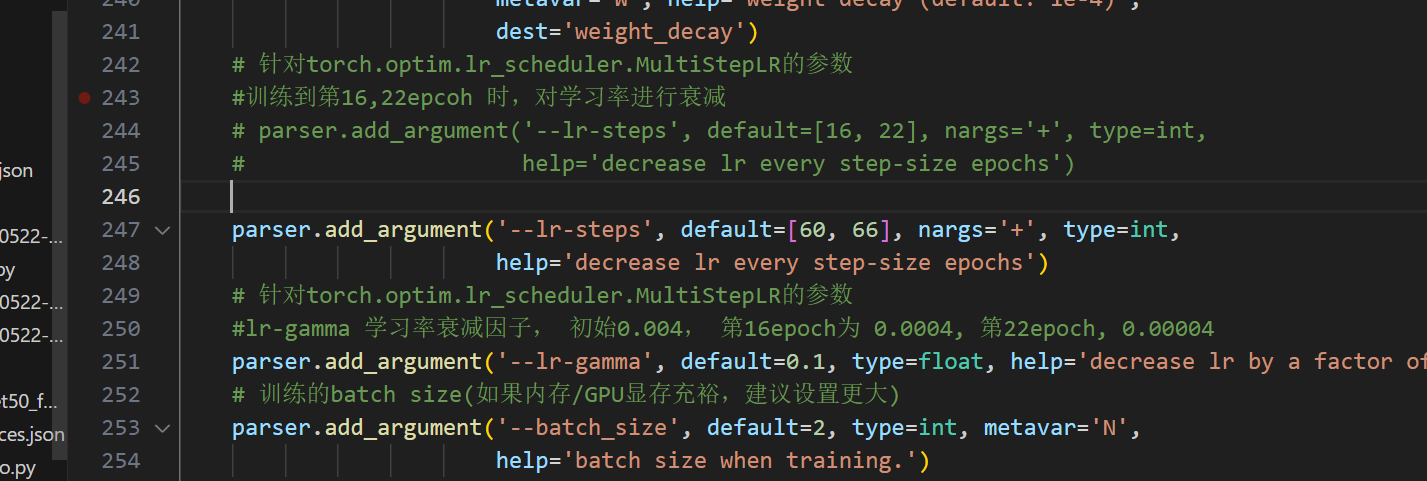
修改11:是否载入官方预训练权重,是否支持amp混合精度训练

3.2.2my_dataset_voc.py.py文件修改
修改1:更改类别json文件的路径,改为自已的数据集类别json文件

参考资料:
1.PASCAL VOC2012数据集介绍_pascal voc 2012-CSDN博客