文章目录
多GPU训练模式可以分为两大类:一类是将数据分割后在多个GPU上并行处理;另一类是当模型大小超过单个GPU显存时,将模型分割到多个GPU上处理。数据并行属于第一类,而模型和张量并行则属于第二类。流水线并行则融合了这两种模式的思想。除此以外,像DeepSpeed、Colossal-AI等产品也将多种思想结合,形成了新的混合方案。
一、数据并行(Data Parallelism)
原理:将训练数据划分为多个子批次,每个GPU加载完整模型副本,独立处理不同数据,通过同步梯度更新参数。
近几年来,多GPU模型训练默认采用的是数据并行。
优点:
实现简单,主流框架(如PyTorch的DataParallel和DDP)原生支持。
适合中小模型,可显著加速训练过程。
扩展性强,支持单机多卡及分布式多机场景(如DDP)。
缺点:
单卡需容纳完整模型,显存冗余(每个GPU保存相同副本)。
梯度同步产生通信开销,可能因GPU速度差异导致效率下降。
全局批次大小随GPU数量线性增长,需调整学习率策略。
二、模型并行(Model Parallelism)
1. 模型并行
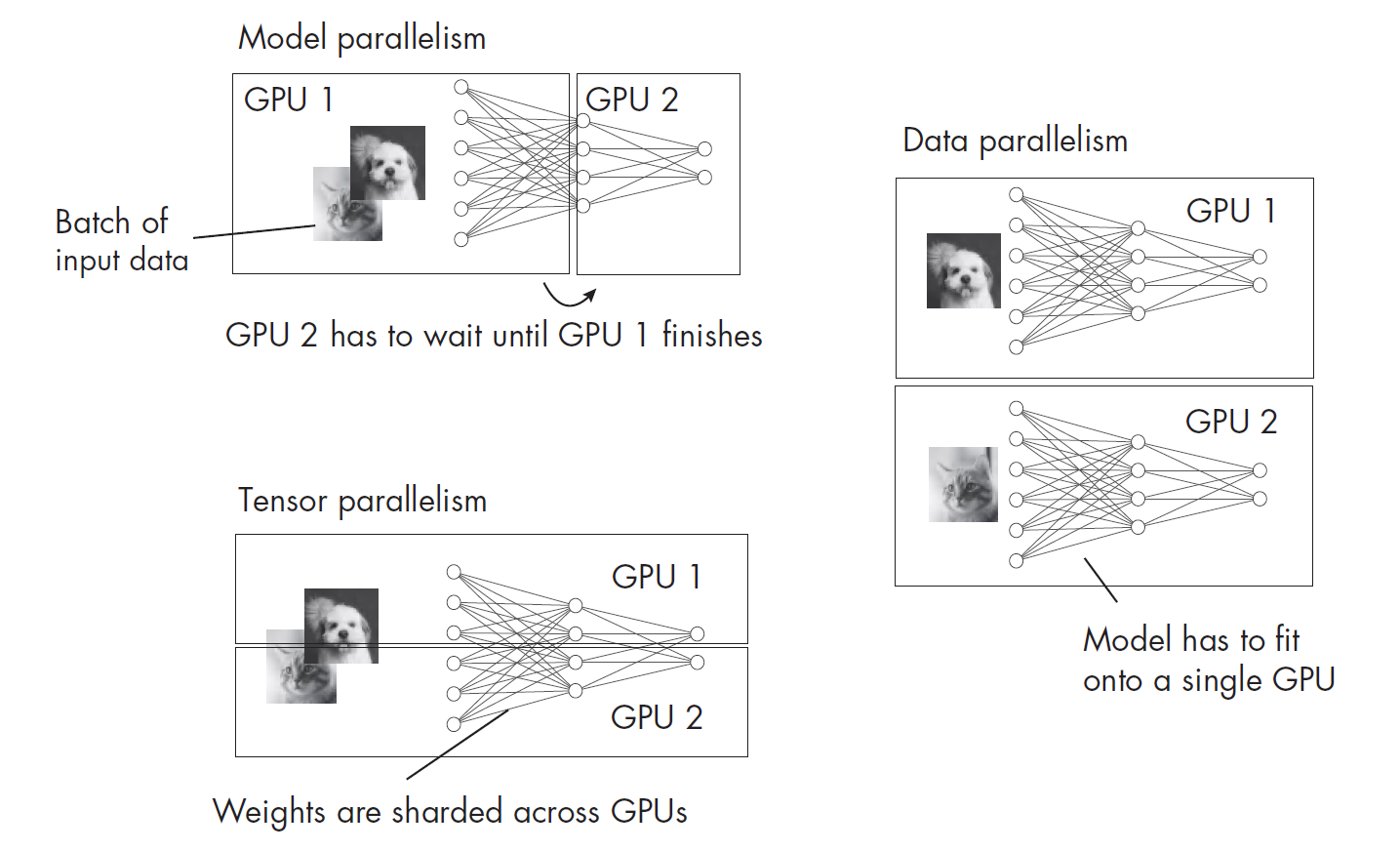
原理:模型并行,也成为操作间并行,是一种将大模型的不同部分放到不同GPU上按序计算的技术。它是跨设备并行中最直观的。例如,对于仅有一个隐藏层和一个输出层的简单神经网络,我们可以将这两个层分别放在不同的GPU上,当然,这种做法也可扩展到任意数量的层和GPU。
优点:
- 能有效应对GPU的显存限制。
缺点:
- GPU间必须相互等待,从而不能高效并行工作。
2. 张量并行(Tensor Parallelism)
原理:张量并行也被称作操作内并行,它将单层权重矩阵按行或列拆分到不同GPU,例如将Transformer注意力头分配到多卡。
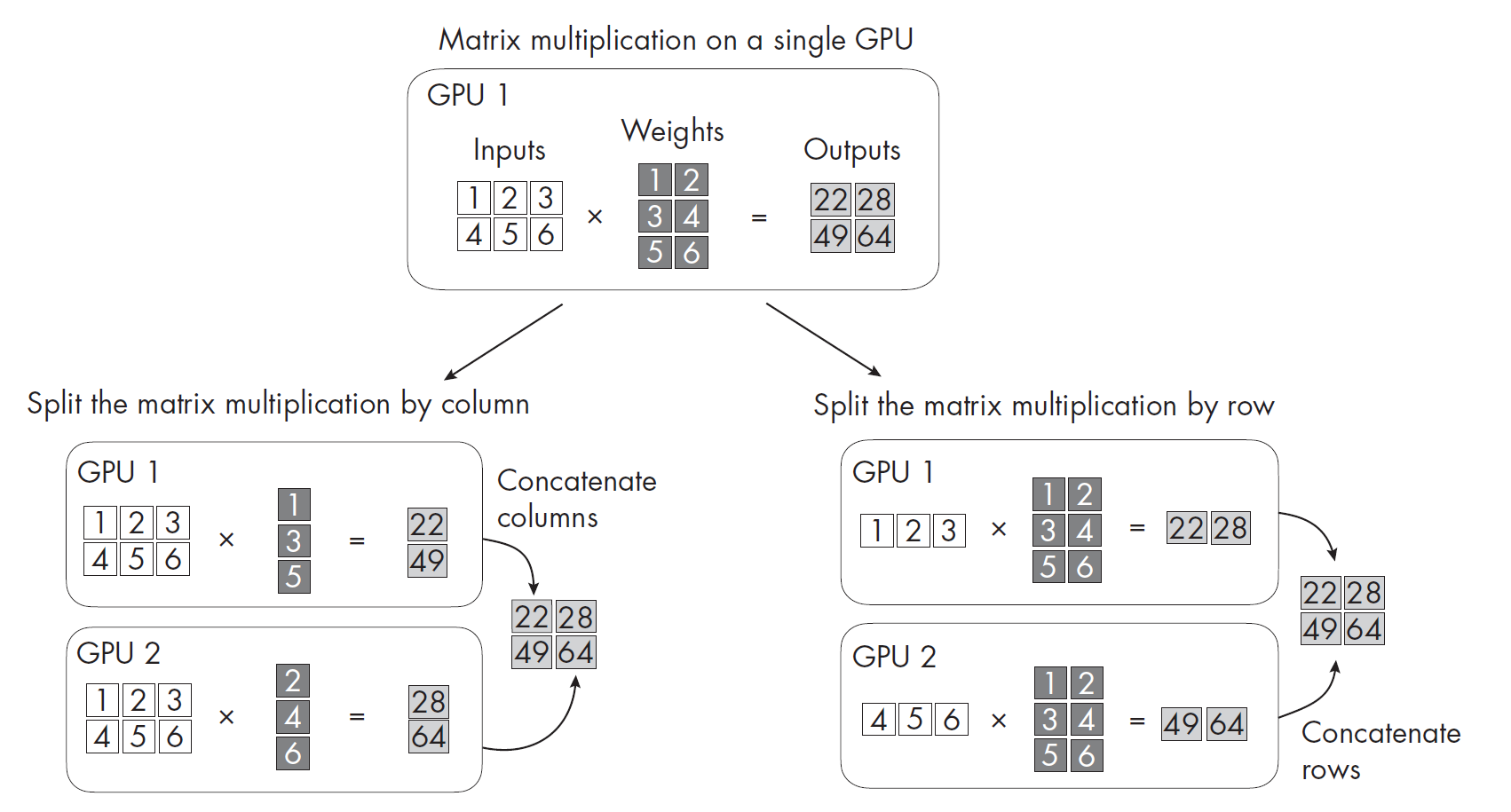
优点:
解决单层参数过大问题,适合超大规模模型(如千亿参数)。
计算与通信可部分重叠,效率较高。
缺点:
实现复杂,需定制化拆分逻辑。
跨GPU通信频繁,延迟敏感。
下图对模型并行、数据并行和张量并行进行了比较:
三、流水线并行(Pipeline Parallelism)
原理:将模型按层拆分到不同GPU,通过微批次(Micro-batch)流水线执行,减少设备空闲时间。
优点:
显存占用分散,支持极深模型(如百层网络)。
适合层间依赖强的模型结构。
缺点:
需要精细划分流水线阶段以平衡负载。
气泡(Bubble)问题导致部分计算资源闲置。
四、混合并行(Hybrid Parallelism)
原理:结合数据并行与模型并行,例如用模型并行拆分大模型,再用数据并行处理数据子集。
优点:
显存和计算资源利用率最大化,适合超大规模模型+大数据场景。
支持灵活策略组合(如DeepSpeed-ZeRO分片优化器状态)。
缺点:
实现复杂度陡增,需协调多级通信。
跨节点通信可能成为性能瓶颈。
五、同步与异步训练策略
同步训练
机制:所有GPU完成梯度计算后同步更新参数。
优点:
收敛稳定,适合高精度任务。
缺点:
通信开销大,效率受最慢GPU限制。
异步训练
机制:各GPU独立更新参数,无需等待其他节点。
优点:
计算效率高,适合资源不均衡环境。
缺点:
模型收敛性差,可能引入训练不稳定性。
六、其他高级技术
FSDP(Fully Sharded Data Parallel):参数、梯度、优化器状态分片,显存占用降至单卡的1/N,适合超大模型训练。
上下文并行:将长序列分块处理到不同GPU,提升长文本生成效率。
混合精度+梯度累积:FP16/BF16计算节省显存,累积梯度模拟大批量训练。
七、总结与选型建议
| 场景 | 推荐模式 | 典型工具 |
|---|---|---|
| 中小模型+大数据 | 数据并行(DDP) | PyTorch DDP |
| 超大规模单层参数 | 张量并行 | Megatron-LM |
| 极深模型 | 流水线并行 | GPipe |
| 千亿参数级综合场景 | 混合并行(如ZeRO-3+流水线) | DeepSpeed |
| 资源异构环境 | 异步训练(需谨慎调参) | TensorFlow ParameterServer |
实际应用中需结合硬件条件、模型规模和数据特性综合选择,并通过通信优化(如NCCL后端)、激活重计算等技术进一步提升效率。