KIMI-VL TECHNICAL REPORT
原文摘要
核心模型:Kimi-VL
模型架构:基于 MoE 设计,仅激活语言解码器的 2.8B 参数(Kimi-VL-A3B),在保持高效计算的同时实现高性能。
- MoE(Mixture of Experts,混合专家模型): 一种通过动态激活模型中的部分参数来处理任务的架构设计
- 模型由多个小型子网络(专家)组成,每个专家擅长处理特定类型的数据或任务。
- 虽然模型总参数量可能很大(例如千亿级),但实际计算时仅激活少量参数,实现高效推理。
- MoE(Mixture of Experts,混合专家模型): 一种通过动态激活模型中的部分参数来处理任务的架构设计
核心能力:
- 多模态推理:支持图像、视频、OCR、数学推理、多图像理解等复杂任务。
- 长上下文理解:扩展至 128K 上下文窗口,在长视频和长文档任务中表现优异。
- 高分辨率视觉处理:通过 MoonViT 视觉编码器 直接处理原生分辨率图像,在 InfoVQA和 ScreenSpot-Pro等任务中领先,同时计算成本更低。
性能对比
对标模型:与当前高效 VLMs 竞争,包括 GPT-4o-mini、Qwen2.5-VL-7B、Gemma-3-12B-IT,并在部分领域(如长上下文、高分辨率理解)超越 GPT-4o。
通用任务表现:在多轮智能体任务(如 OSWorld)中匹配主流大模型,展现强大的通用性。
- 进阶变体:Kimi-VL-Thinking
训练方法:通过 长链思维(CoT)监督微调(SFT)和强化学习(RL)优化,专注于长程推理能力。
性能亮点:
- 复杂任务得分:MMMU(61.7)、MathVision(36.8)、MathVista(71.3),在仅激活 2.8B 参数的条件下,树立了高效多模态推理模型的新标杆。
- 进阶变体:Kimi-VL-Thinking
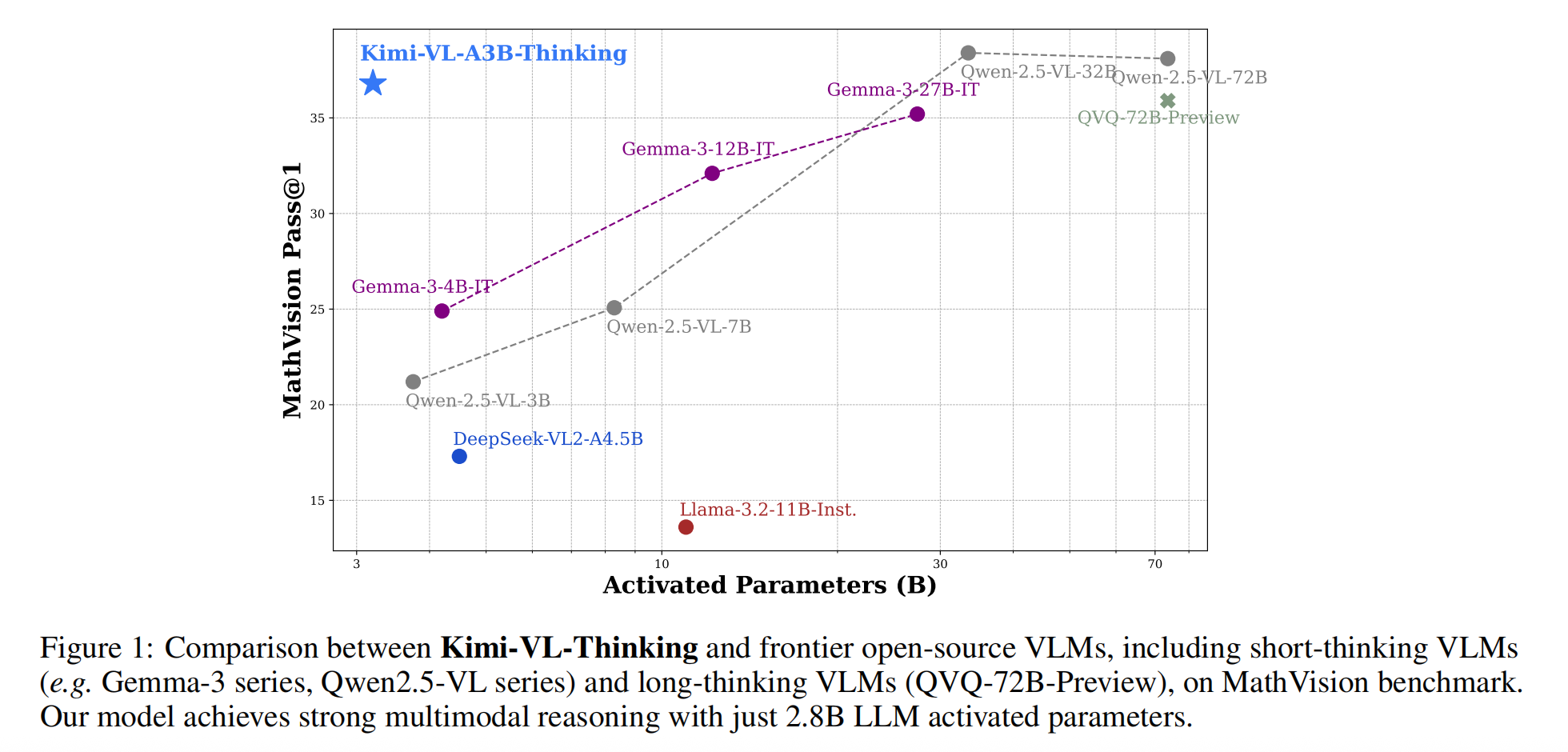
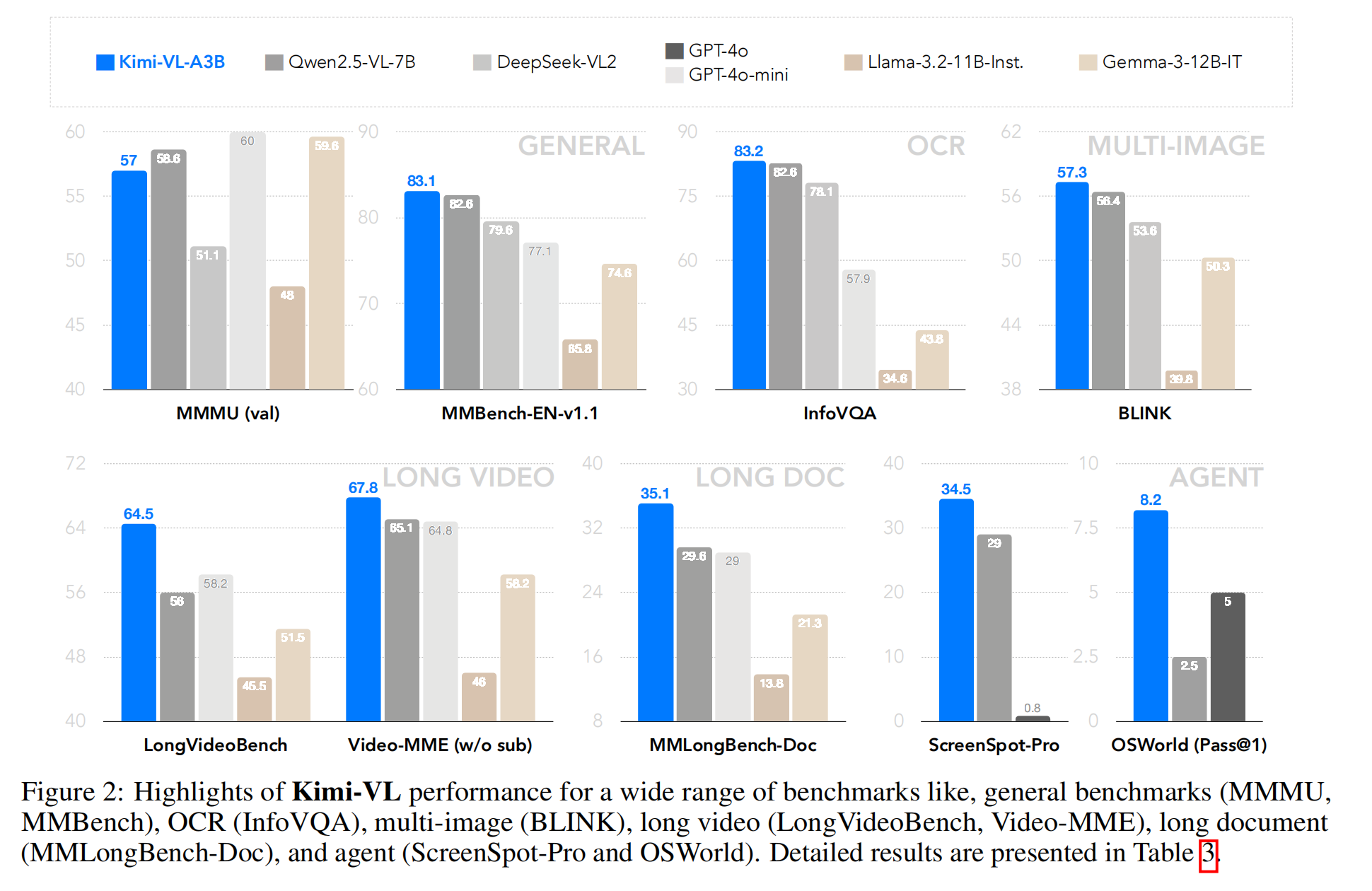
1. Introduction
研究背景与行业趋势
多模态交互成为刚需:
- 人类对AI的期待已超越纯文本交互,转向更自然的多模态理解(如GPT-4o、Gemini)。
- 最新模型(如OpenAI o1、Kimi k1.5)进一步推动 多模态长链推理(long-CoT),解决更复杂问题。
开源VLMs的滞后性:
- 相比纯文本模型(如DeepSeek R1),开源VLMs在可扩展性、计算效率、长链推理上显著落后
- 现有模型(如Qwen2.5-VL、Gemma-3)仍依赖稠密架构,不支持长链推理
- 早期MoE-VLMs(如DeepSeek-VL2、Aria)存在视觉编码器僵化、上下文窗口短(4K)、细粒度视觉任务弱 等问题。
关键问题:
- 开源社区需要一个结构创新、能力稳定、支持长链推理的VLM。
Kimi-VL的核心贡献
架构创新
高效MoE语言模型:
- 基于 Moonlight MoE架构,仅激活 2.8B参数(总量16B),计算成本低。
原生高分辨率视觉编码器:
- MoonViT(400M参数)支持原生分辨率输入,适应多样视觉场景(如OCR、屏幕截图)。
能力突破
Kimi-VL在三大维度表现卓越:
强通用性(Smart):
- 文本能力媲美纯文本LLMs,在多模态推理和智能体任务中竞争力强。
长上下文处理(Long):
- 128K上下文窗口,在长视频和长文档任务中远超同类模型。
细粒度感知(Clear):
- 在视觉感知、OCR、高分辨率截图等任务中优于现有稠密/MoE VLMs。
进阶版本:Kimi-VL-Thinking
通过 长链思维(long-CoT)微调 + 强化学习(RL),进一步提升复杂多模态推理能力
小模型大能量:尽管参数量小,性能超越许多更大规模的SOTA VLMs。
2. Approach
2.1 Model Architecture
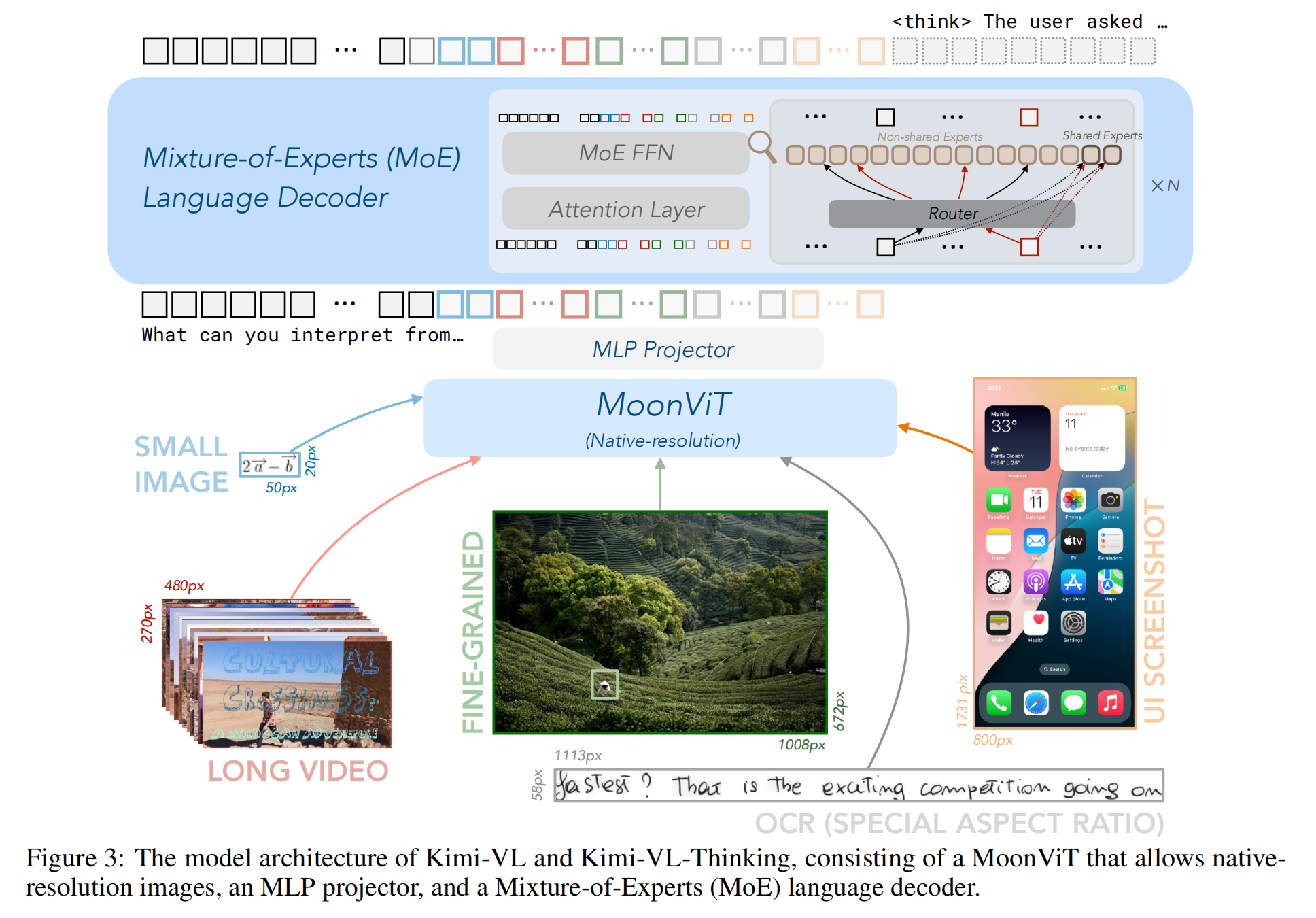
2.1.1 MoonViT: A Native-resolution Vision Encoder
核心设计目标
原生分辨率支持:直接处理不同尺寸的输入,无需强制缩放或裁剪。
计算统一性:与语言模型共享相同的序列化计算机制(如 FlashAttention),优化训练效率。
细粒度空间编码:在超高分辨率下仍能保持精确的 空间位置感知(如 OCR 精确定位)。
关键技术组件
图像序列化:NaViT 的 Patch 打包方法
- 分块(Patchify):将图像划分为可变大小的 patches。
- 展平(Flatten):每个patch线性投影为 1D 向量。
- 序列拼接(Pack):所有patches按顺序拼接为单一 1D 序列(类似文本 token 序列)。
位置编码:双机制协同
MoonViT 结合两种位置编码方法,以平衡预训练知识继承和高分辨率适应性:
- 插值绝对位置编码(Interpolated Absolute PE):
- 继承自 SigLIP-SO-400M视觉编码器的预训练权重,使用可学习的固定大小绝对位置编码。
- SigLIP-SO-400M,是一个由 Google 提出的视觉-语言预训练模型
- 局限性:超高分辨率时插值位置信息可能失真。
- 继承自 SigLIP-SO-400M视觉编码器的预训练权重,使用可学习的固定大小绝对位置编码。
- 插值绝对位置编码(Interpolated Absolute PE):
2D 旋转位置编码(2D Rotary PE, RoPE):
沿图像高度和宽度维度分别应用 RoPE,增强细粒度空间感知。
优势:RoPE 的 距离衰减特性 更适合长序列和高分辨率定位(如屏幕文字检测)。
MoonViT作用:在同一个batch中,支持不同分辨率的输入
2.1.2 MLP Projector
核心功能
输入:MoonViT 提取的 图像特征序列(形状为
[N, L, D_v],其中L是序列长度,D_v是视觉特征维度)。输出:与 LLM 嵌入维度对齐的投影特征(形状为
[N, L', D_m],D_m是语言模型隐藏层维度)。目标:
- 压缩视觉特征的 空间冗余信息(如相邻像素相似性)。
- 将视觉语义映射到语言模型的多模态联合空间。
具体实现
Pixel Shuffle 操作(空间压缩)
作用:降低特征图的空间分辨率,同时增加通道维度,保留更多语义信息。
操作方式:
- 对 MoonViT 输出的图像特征执行 2×2 下采样:
- 将相邻的
2×2区域(共 4 个特征点)拼接为 1 个特征点,通道数扩展为原来的 4 倍。 - 数学表达:输入特征
[N, H, W, D_v]→ 输出[N, H/2, W/2, 4*D_v]。
- 将相邻的
- 对 MoonViT 输出的图像特征执行 2×2 下采样:
优势:
- 减少序列长度(
L = H×W→L' = (H/2)×(W/2)),降低后续计算量。 - 通过通道扩展保留局部细节。
- 减少序列长度(
两层 MLP(维度投影):将特征维度投影到语言模型嵌入维度。
2.1.3 Mixture-of-Experts (MoE) Language Model
模型架构基础
类型:
- Kimi-VL 的语言模型采用 Moonlight 模型,属于 Mixture-of-Experts(MoE)架构。
参数规模:
- 总参数量:16B(160 亿参数)。
- 激活参数量:每次推理或训练仅激活 2.8B 参数(约占总量的 17.5%)。
参考架构:
- 其设计与 DeepSeek-V3 相似,采用了类似的 MoE 分层和专家分配策略。
初始化与预训练策略
初始化起点
检查点选择:
- 模型从一个 中间预训练检查点 初始化,该检查点已通过 5.2T纯文本 token 的训练。
初始能力:
- 此时模型已具备较强的文本理解能力。
- 支持的上下文窗口为 8192 token(8k)。
多模态继续预训练
训练数据:
在初始化后,使用 混合数据 继续预训练,包括:
多模态数据(图像-文本对、视频-文本对等)。
纯文本数据(用于保持语言能力)。
总数据量:2.3T token(2.3 万亿)。
2.2 Muon Optimizer
原版 Muon 优化器的基础
一种自适应优化算法,特点包括:
参数更新机制:动态调整学习率,结合动量和梯度二阶矩估计。
数学性质:理论上保证收敛性,适合大规模模型训练。
Kimi-VL 的改进点
新增权重衰减(Weight Decay)
参数级更新尺度调整
分布式实现(ZeRO-1 策略)
基础技术:
参考微软 ZeRO-1,将优化状态(如动量、梯度方差)分片存储在不同设备上。优化目标:
- 内存效率:减少单卡内存占用,支持更大模型或 batch size。
- 通信开销:仅同步必要的梯度信息,避免全量通信瓶颈。
数学性质保留: 分布式实现需严格保证与原算法的数学等价性(如梯度更新一致性)。
在 Kimi-VL 中的应用
- 优化所有参数:包括:
- 视觉编码器(MoonViT)
- 投影层(MLP Projector)
- 语言模型(Moonlight MoE)
- 优化所有参数:包括:
2.3 Pre-training Stages

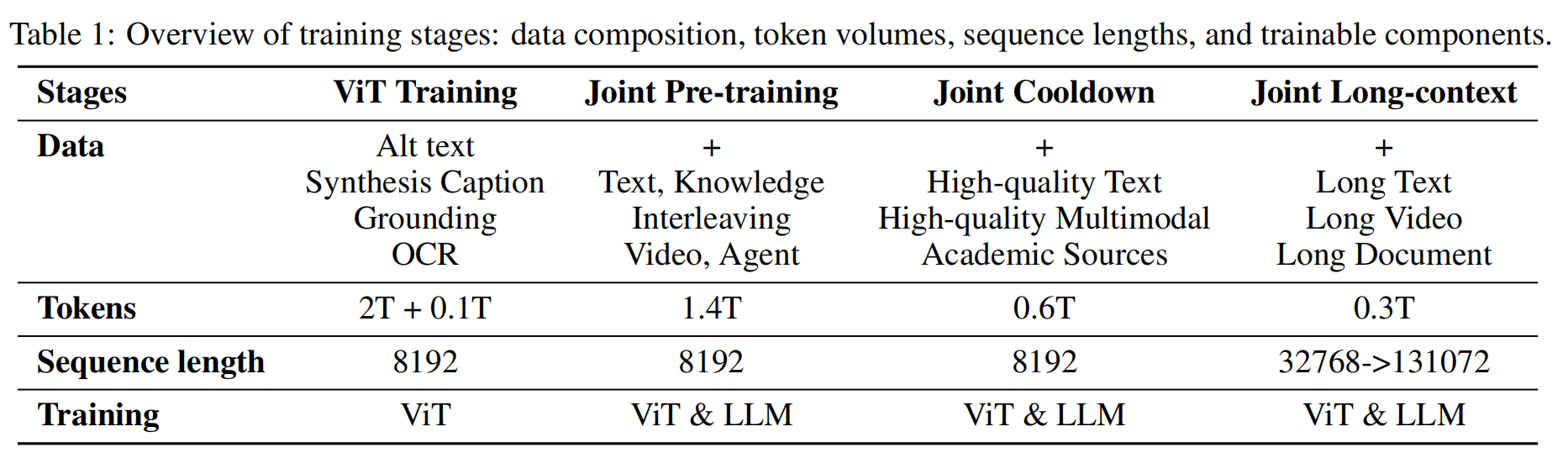
在加载上述中间语言模型后,Kimi-VL的预训练共包含 4个阶段,总计消耗 4.4Ttoken:
独立的ViT训练:
- 首先训练一个独立的视觉编码器(ViT),以建立一个强大的 原生分辨率视觉编码器。
联合训练三阶段:
预训练阶段:同时提升模型的 语言能力 和 多模态能力。
冷却阶段(Cooldown):调整训练策略,优化模型稳定性。
上下文激活阶段:扩展模型上下文窗口,使其支持 128K token 的长序列输入。
2.3.1 ViT Training Stages
训练数据与目标
数据组成: MoonViT 使用 图像-文本对 进行训练,其中文本包含多种形式:
- 图像替代文本(alt texts):描述性文本
- 合成标注(synthetic captions):自动生成的图像描述
- 边界框标注(grounding bboxes):物体定位信息
- OCR 文本:图像中的文字识别结果
训练目标: 联合优化两个损失函数:
- SigLIP 损失: L s i g l i p L_{siglip} Lsiglip
- 基于对比学习(contrastive loss)的变体,拉近匹配图像-文本对的嵌入距离,推开不匹配对。
- 图像编码器和文本编码器共同计算此损失。
- 生成损失: L c a p t i o n L_{caption} Lcaption
- 交叉熵损失(cross-entropy),用于训练文本解码器生成图像描述(caption)。
- 文本解码器基于图像编码器的特征进行 下一词预测(NTP)。
总损失函数:
L = L siglip + λ ⋅ L caption L = L_{\text{siglip}} + \lambda \cdot L_{\text{caption}} L=Lsiglip+λ⋅Lcaption- 生成损失的权重系数 λ = 2 \lambda = 2 λ=2,强调描述生成任务的重要性
- SigLIP 损失: L s i g l i p L_{siglip} Lsiglip
模型初始化与训练策略
初始化方案:
- 图像/文本编码器:从 SigLIP SO-400M加载预训练权重。
- 文本解码器:初始化自一个小型纯文本语言模型(decoder-only)。
渐进式分辨率训练:
- 采用 逐步增大输入图像分辨率 的策略,避免直接训练高分辨率时的计算负担。
训练观察:
- 当增加 OCR 数据比例时,caption loss显著下降,表明文本解码器学习了 OCR 能力
两阶段训练流程
CoCa 式预训练阶段
数据量:消耗 2T token 的图文数据。
训练内容: 对ViT进行训练
对齐阶段(Alignment)
数据量:额外 0.1T token 的图文数据。
训练内容:
- 仅更新 MoonViT 和 MLP 投影器,语言模型参数冻结。
- 目标:将 MoonViT 的视觉嵌入更适配语言模型的输入空间,降低初始困惑度(perplexity)。
效果:
- 对齐后,视觉特征与语言模型的兼容性显著提升,为后续联合预训练(joint pre-training)奠定平滑过渡基础。
2.3.2 Joint Pre-training Stage
训练数据组成
纯文本数据: 采样分布与初始语言模型相同,确保语言能力不退化。
多模态数据: 包含 图像-文本对、视频-文本对 等。
训练策略
- 学习率调度: 沿用初始语言模型 checkpoint 的 相同学习率调度策略,保持训练稳定性。
分阶段数据混合:
- 初始阶段(纯文本): 仅使用纯文本数据训练若干步。
- 渐进引入多模态数据: 逐步增加多模态数据的比例
总数据量:
- 本阶段共消耗 1.4Ttoken 的数据。
2.3.3 Joint Cooldown Stage
核心目标
通过 高质量语言+多模态数据 微调,进一步提升模型在 数学推理、知识问答、代码生成 等复杂任务上的性能。
避免过拟合,确保模型泛化能力。
数据策略
语言数据优化
基础数据源:
- 从预训练语料中精选 高保真(high-fidelity)文本子集。
合成数据增强:
- 数学/知识/代码领域:通过专有语言模型生成 问答对(QA pairs),采用 拒绝采样 控制质量。
- 作用:显著提升模型在数学推理、代码生成等任务的表现。
多模态数据优化
数据来源:
- 学术视觉数据集和视觉-语言数据。
处理方式:
- 过滤与重写:将原始数据转化为 视觉中心问答对(Visual QA pairs)
比例控制:
- QA 对仅占少量比例(例如 <10%),避免模型过度依赖问答模式而丧失泛化性。
训练设计
学习重点:
- 激活特定能力:通过 QA 对针对性强化数学、代码、视觉推理等技能。
- 高质量数据学习:优先学习筛选后的优质样本,而非盲目扩大数据量。
防过拟合措施:
- 限制合成 QA 对的比例。
- 保留大部分数据为自然分布(如原始文本、图像-描述对)。
2.3.4 Joint Long-context Activation Stage
阶段目标与核心挑战
目标:将模型的上下文窗口从 8K扩展至128K,使其能够处理超长文本、视频、多模态文档等输入。
核心挑战:
- 保持短上下文任务性能的同时学习长序列依赖。
- 避免位置编码(RoPE)外推时的性能崩溃。
关键技术实现
RoPE 位置编码调整
- 修改参数:
- 将 RoPE 的 逆频率(inverse frequency)从 50,000 调整至 800,000,以支持更长的位置索引。
- 作用:防止长序列位置编码重复或冲突,确保位置信息唯一性。
- 修改参数:
两阶段渐进式扩展
子阶段1:
- 上下文窗口从 8K → 32K(4倍扩展)。
- 数据中 25% 为长序列数据,75% 为短序列数据。
子阶段2:
- 上下文窗口从 32K → 128K(再次4倍扩展)。
- 数据比例同上(25% 长数据,75% 短数据)。
设计动机:
- 渐进扩展避免训练不稳定,同时通过短数据回放(replay)防止能力遗忘。
长数据构成
纯文本长数据
多模态长数据:
- 交错长数据(Interleaved):图文混合的长序列。
- 长视频、长文档
合成QA对增强:
- 生成少量长上下文相关的问答对,提升学习效率。
性能评估
- Needle-in-a-Haystack(NIAH)测试:
- 在超长文本(“Haystack”)中隐藏关键信息(“Needle”),测试模型能否准确召回。
- 同时测试纯文本(如128K长文章)和多模态输入(如1小时长视频)。
- Needle-in-a-Haystack(NIAH)测试:
2.4 Post-Training Stages

2.4.1 Joint Supervised Fine-tuning (SFT)
阶段目标
核心任务:通过指令微调将预训练基础模型转化为 交互式 Kimi-VL 模型,使其具备:
- 多轮对话能力(遵循指令、上下文连贯)。
- 多模态指令理解(图文混合任务处理)。
实现方式:采用 ChatML 格式 统一指令模板,保持与 Kimi-VL 架构的一致性。
关键技术设计
微调范围
- 优化模块:MoE LLM、MLP 投影层、MoonViT
监督信号:
- 仅对答案和特殊 token计算损失,屏蔽系统提示和用户输入部分。
- 目的:避免模型学习无关的指令模板内容,专注优化回答质量。
数据构成
混合数据:
- 多模态指令数据
- 纯文本对话数据
数据格式:
- 使用 ChatML 结构化标记,明确区分对话角色(用户/系统/助手)。
- 视觉嵌入注入:将图像特征通过 MLP 投影后插入指令模板的指定位置,保留跨模态位置关系。
训练策略
两阶段序列长度调整:
- 第一阶段(32K 上下文):
- 训练 1 个 epoch。
- 学习率从 2×10⁻⁵ 衰减至 2×10⁻⁶。
- 第二阶段(128K 上下文):
- 学习率重新升温至 1×10⁻⁵,再衰减至 1×10⁻⁶。
- 进一步强化长上下文指令跟随能力。
- 第一阶段(32K 上下文):
序列打包(Sequence Packing):
- 将多个训练样本拼接为单个长序列(如 3 个 10K 样本 → 1 个 30K 序列),提升训练效率。
- 通过特殊 token 分隔不同样本,避免上下文混淆。
2.4.2 Long-CoT Supervised Fine-Tuning
阶段目标
核心任务:通过高质量的小规模 CoT 数据来微调模型,使其掌握 类人的多模态推理能力,包括:
- Planning、Evaluation、Reflection、Exploration
实现方式:结合 提示工程(Prompt Engineering)和 拒绝采样,构建高精度的长链推理数据集。
关键技术实现
数据集构建
数据生成方法:
- 提示工程引导:设计特定提示模板,要求模型生成包含完整推理链的回答。
- 拒绝采样筛选:仅保留逻辑严密、步骤正确的输出,过滤错误或简化的回答。
数据内容:
- 包含 文本 和 图像输入 的长链推理示例。
- 示例需覆盖 规划→执行→评估→反思→探索 的全流程。
微调策略
- 轻量级 SFT(Supervised Fine-Tuning):
- 在小规模数据集(可能仅数千样本)上微调,避免过拟合。
- 优化目标:让模型学会“模仿”人类推理过程,而非单纯记忆答案。
- 轻量级 SFT(Supervised Fine-Tuning):
2.4.3 Reinforcement Learning
核心目标
通过强化学习进一步优化模型的自主推理能力,使其能够:
自动生成CoT
动态纠错与迭代优化
平衡推理效率与准确性:避免“过度思考”(生成冗余步骤)或“思考不足”(跳过关键步骤)
强化学习算法设计
算法选择:Online Policy Mirror Descent
基础思想:
- 参考 Kimi k1.5,采用 策略镜像下降的变体,通过相对熵(KL散度)正则化稳定策略更新。
优化目标:
max θ E ( x , y ∗ ) ∼ D [ E ( y , z ) ∼ π θ [ r ( x , y , y ∗ ) ] − τ KL ( π θ ( x ) ∥ π θ i ( x ) ) ] \max_{\theta} \mathbb{E}_{(x,y^*)\sim D} \left[ \mathbb{E}_{(y,z)\sim \pi_\theta} [r(x, y, y^*)] - \tau \text{KL}(\pi_\theta(x) \| \pi_{\theta_i}(x)) \right] θmaxE(x,y∗)∼D[E(y,z)∼πθ[r(x,y,y∗)]−τKL(πθ(x)∥πθi(x))]- 公式说明见Kimi-K1.5笔记
训练流程
迭代更新:
- 每轮迭代从数据集 D D D 中采样一批问题 x x x。
- 当前策略 π θ \pi_\theta πθ 生成答案 y y y 和推理链 z z z。
- 根据奖励 r ( x , y , y ∗ ) r(x, y, y^*) r(x,y,y∗) 和KL正则项计算策略梯度,更新参数至 θ i + 1 \theta_{i+1} θi+1。
- 更新后的策略 π θ i + 1 \pi_{\theta_{i+1}} πθi+1 作为下一轮的参考策略。
终止条件: 奖励收敛或达到最大迭代次数。
关键技术优化
奖励设计
基础奖励:二元奖励 r ( x , y , y ∗ ) ∈ { 0 , 1 } r(x, y, y^*) \in \{0,1\} r(x,y,y∗)∈{0,1},仅判断最终答案正确性。
长度惩罚: 对过长的推理链施加负奖励,避免“过度思考”。
课程奖励(Curriculum Reward): 根据问题难度动态调整奖励权重
采样策略
课程采样(Curriculum Sampling):按问题难度标签从易到难逐步采样。
优先级采样(Prioritized Sampling):根据历史成功率动态调整样本权重,聚焦于当前模型易错的样本。
元推理能力提升(Meta-Reasoning)
错误检测与回溯: 模型通过分析完整的推理历史,自主修正错误。
参数化搜索策略: 将规划过程编码到模型参数中,无需外部规划算法。
3. Data Construction
3.1 Pre-training Data
3.1.1 Caption Data
核心作用
模态对齐基础: 为模型提供视觉与语言对齐的基础能力,使其学会将图像内容转化为自然语言描述。
世界知识扩展: 通过海量描述数据,模型高效学习广泛的世界知识
数据来源
开源数据集: 整合中英文开源描述数据集。
内部数据:
自建高质量描述数据,覆盖多样场景(如专业摄影、科学图表、社交媒体图片)。
合成数据限制
- 风险控制: 严格限制合成描述数据的比例,避免因缺乏真实世界知识导致幻觉(hallucination)(如虚构图像细节)。
多分辨率训练
- 动态分辨率调整: 在预训练中随机切换图像分辨率,使视觉编码器能同时处理高/低分辨率图像。
3.1.2 Image-text Interleaving Data
核心价值与作用
多图像理解能力:
- 通过单批次输入多张关联图像(如步骤图),模型学习跨图像的语义关联
长上下文多模态学习:
- 交错数据天然包含长序列图文交替输入(如教科书图文混排),训练模型在长上下文窗口内保持跨模态注意力。
语言能力保护:
- 作者发现图文交错数据可防止纯视觉训练导致的语言能力退化。
数据来源与构建
开源数据集: 采用公开图文交错数据集,覆盖百科、新闻等场景。
自建高质量数据: 教材、网页内容、教程
合成数据: 通过语言模型生成与图像匹配的连贯文本,增强知识一致性。
数据处理关键技术
质量管控流程
标准清洗:
- 去重(Deduplication):移除重复或近似的图文块。
- 过滤(Filtering):剔除低相关性图文对。
顺序校正(Reordering):
- 强制保持原始文档的图文顺序,避免随机打乱破坏逻辑链。
3.1.3 OCR Data
数据来源与覆盖范围
开源数据: 整合通用OCR数据集(如ICDAR、SROIE),涵盖扫描文档、自然场景文本等。
自建高质量数据: 多语言文本、 密集排版 、非结构化文本、多页长文档
数据处理与增强技术
数据多样性扩展
- 图像类型全覆盖:
增强技术: 几何变换、视觉干扰、字体与背景
长文档处理优化
3.1.4 Knowledge Data
多模态知识数据的概念与之前提到的文本预训练数据类似
此处专注于整合来自不同来源的人类知识,以进一步增强模型的能力。
- 例如,数据集中在精心整理的几何数据,其对于开发视觉推理能力至关重要,确保模型能够理解人类创建的抽象图表。
语料库遵循标准化的分类体系,以平衡不同类别的内容,确保数据来源的多样性。
知识语料库有相当一部分来源于互联网材料,信息图(infographics)可能导致模型仅关注基于OCR的信息。
- 在这种情况下,仅依赖基础OCR流程可能会限制训练效果。
- 为此,作者开发了一个额外的处理流程,以更好地提取图像中纯文本信息。
3.1.5 Agent Data
核心目标
增强模型在智能体任务中的两大能力:
环境感知(Grounding)
多步规划(Planning)
数据来源与采集平台
公开数据:整合现有智能体数据集(如桌面操作、移动端交互日志)。
自建虚拟化平台:
- 批量管理虚拟机环境(Ubuntu/Windows),通过启发式方法(Heuristic Methods)自动采集:
- 屏幕截图:记录每个操作步骤的界面状态。
- 动作数据:对应操作的元数据(如点击坐标、键盘输入、滚动行为)。
- 批量管理虚拟机环境(Ubuntu/Windows),通过启发式方法(Heuristic Methods)自动采集:
数据格式化处理
密集 grounding 格式: 将屏幕元素(如按钮、输入框)标注为结构化数据,包含:
- 视觉位置
- 功能语义
连续轨迹格式:
- 将多步操作序列编码为时间轴数据,保留动作之间的依赖关系。
动作空间设计(Action Space)
环境 动作类型 桌面端 鼠标点击、键盘输入、窗口切换、文件拖拽等 移动端 触屏滑动、长按、多指缩放、返回键操作 网页端 表单填写、链接跳转、下拉刷新、弹窗处理 图标数据优化(Icon Data)
收集目标: 强化模型对软件GUI图标语义的理解。
处理方式:
- 标注图标类别与功能描述
- 合成对抗样本(如扭曲/遮挡图标),提升鲁棒性。
多步任务轨迹与思维链(Chain-of-Thought)
人工标注轨迹: 录制人类完成复杂任务的全流程操作(如“配置开发环境”),包含:
- 屏幕录像 + 动作序列
- 合成的思维链: 将每个动作的决策逻辑转化为文本描述
作用: 训练模型模仿人类规划能力,在真实系统中执行多步任务
3.1.6 Video Data
视频数据的作用
- 让模型理解以图像为主的长上下文序列
- 让模型能够感知短视频片段中细粒度的时空对应关系
数据来源
- 开源数据集
- 网络级视频数据
长视频caption:
- 对于长视频,作者设计了生成密集字幕的流程。
- 与处理描述数据类似,需严格限制合成密集视频描述数据的比例,以降低幻觉风险。
3.1.7 Text Data
- 文本预训练语料直接采用Moonlight的数据,该语料库旨在为大型语言模型训练提供全面且高质量的数据,涵盖五大领域:英语、中文、代码、数学与推理、以及知识。
- 作者对所有预训练数据源进行严格验证,评估其对整体训练效果的贡献,并通过大量实验确定不同文档类型的采样策略。
- 在最终训练语料中提高关键子文档的采样频率,同时保持其他文档类型的适当比例以维护数据多样性和模型泛化能力。
3.2 Instruction Data
- 本阶段数据主要旨在提升模型的对话能力和指令跟随能力。
- 对于非推理类任务:
- 先通过人工标注构建种子数据集训练初始模型,再通过该模型生成多样回答并由人工筛选优化;
- 对于视觉编程、视觉推理和数理问题等推理任务:
- 则采用基于规则和模型的拒绝采样法扩展数据集。
- 最终的标准监督微调(SFT)数据集保持文本token与图像token约1:1的比例平衡。
3.3 Reasoning Data
目标:增强模型在多模态推理方面的能力
数据集构建过程:
- 构建一个带标准答案标注的问答数据集
- 其中包含需要多步推理的问题,例如数学求解和领域特定的视觉问答(VQA)。
- 利用Kimi k1.5,结合精心设计的推理提示,为每个问题生成多条详细的推理路径。
- 在拒绝采样阶段,将真实标签和模型预测输入现成的奖励模型进行评判。
- 错误的思维链响应会根据模型评估和基于规则的奖励机制被过滤掉,从而提升推理数据的质量。
- 构建一个带标准答案标注的问答数据集
4. Evaluation
Benchmarks
Image Benchmark
MMMU (Yue, Ni, et al. 2024)
MMBench-EN-v1.1 (Yuan Liu et al. 2023)
MMStar (Lin Chen et al. 2024)
MMVet (W. Yu et al. 2024)
RealWorldQA (x.ai 2024)
AI2D (Kembhavi et al. 2016)
MathVision (K. Wang et al. 2024)
MathVista (P. Lu et al. 2023)
BLINK (X. Fu et al. 2024)
InfoVQA (Mathew et al. 2022)
OCRBench (Yuliang Liu et al. 2023)
Video and Long Document Benchmark
VideoMMMU (K. Hu et al. 2025)
MMVU (Y. Zhao et al. 2025)
Video-MME (C. Fu et al. 2024)
MLVU (J. Zhou et al. 2024)
LongVideoBench (H. Wu et al. 2024)
EgoSchema (Mangalam et al. 2023)
VSI-Bench (Yang et al. 2024)
TOMATO (Shangguan et al. 2025)
Agent Benchmark
ScreenSpot V2 (Zhiyong Wu et al. 2024)
ScreenSpot Pro (K. Li et al. 2025)
OSWorld (T. Xie et al. 2024)
WindowsAgentArena (Bonatti et al. 2024)