图论
题目
代码随想录
Prim 算法,最小生成树是所有节点的最小连通子图,即:以最小的成本(边的权值)将图中所有节点链接到一起。
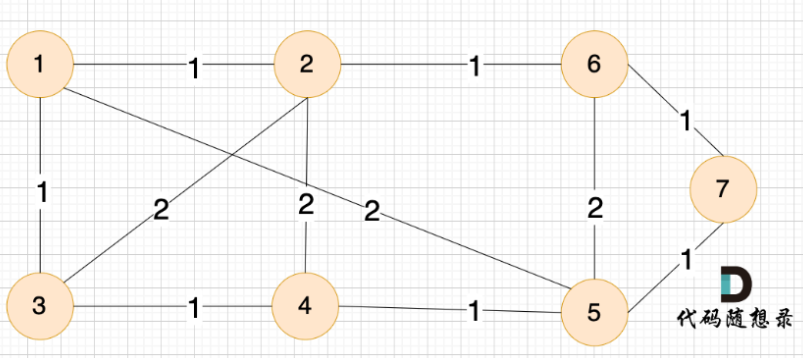
Prime 三部曲
1. 第一步,选距离生成树最近节点
2. 第二步,最近节点加入生成树
3. 第三步,更新非生成树节点到生成树的距离(即更新minDist数组)
在prim算法中,有一个数组特别重要,这里我起名为:minDist
通过 minDist 数组每次寻找距离最小生成树最近的节点并加入到最小生成树中
minDist数组用来记录每一个节点距离最小生成树的最近距离。
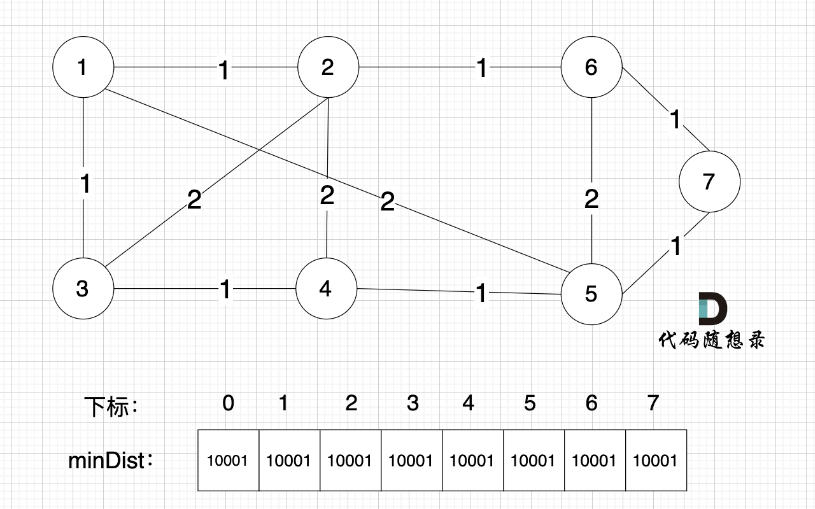 初次构造过程
初次构造过程
1. prim三部曲,第一步:选距离生成树最近节点
选择距离最小生成树最近的节点,加入到最小生成树,刚开始还没有最小生成树,所以随便选一个节点加入就好(因为每一个节点一定会在最小生成树里,所以随便选一个就好),那我们选择节点1(符合遍历数组的习惯,第一个遍历的也是节点1)
2. prim三部曲,第二步:最近节点加入生成树
此时节点1已经算最小生成树的节点。
3. prim三部曲,第三步:更新非生成树节点到生成树的距离(即更新minDist数组)
我们要更新所有节点距离最小生成树的距离 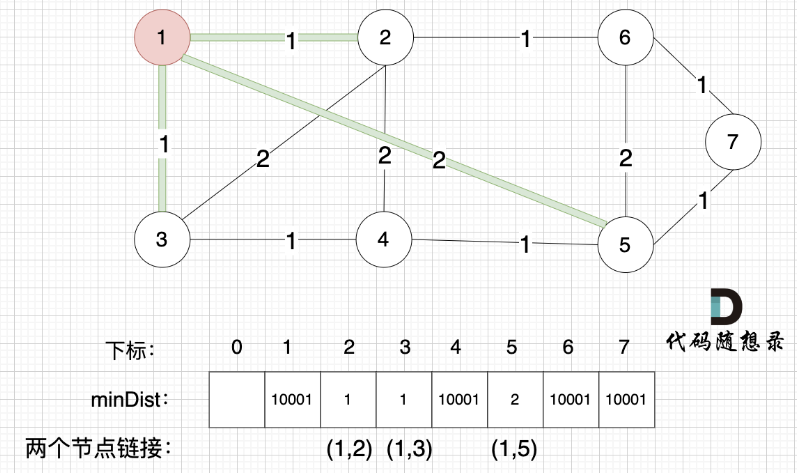
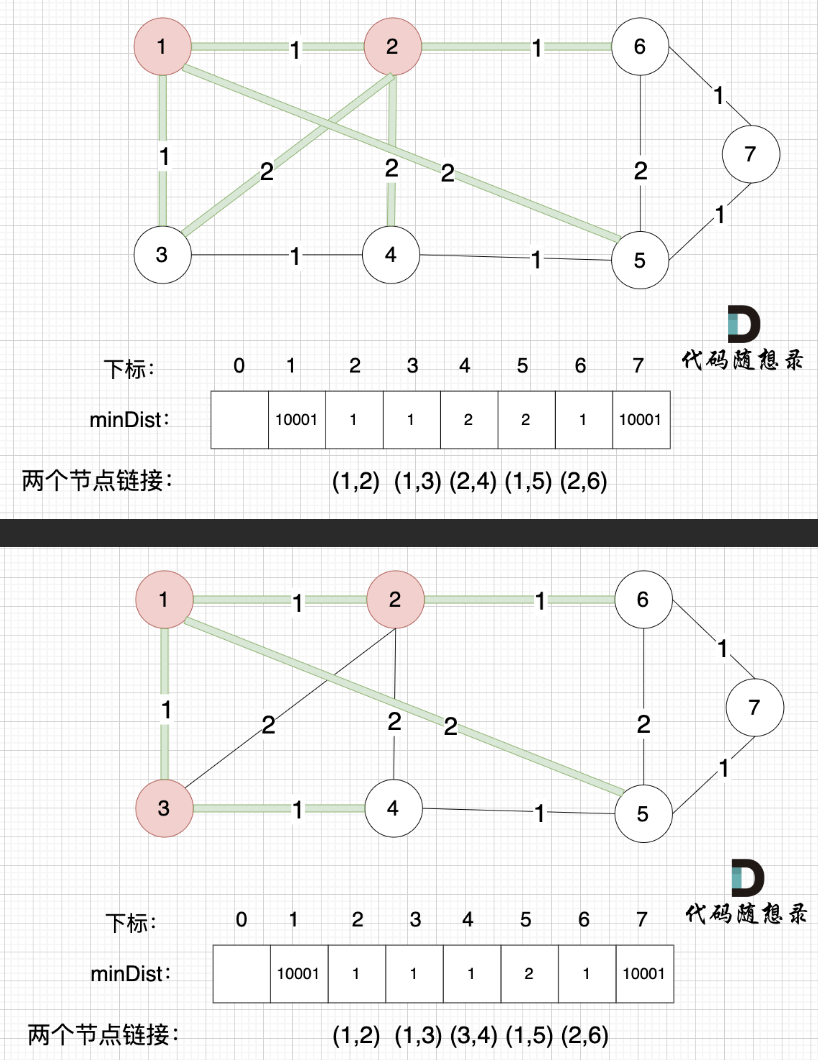
继续构造
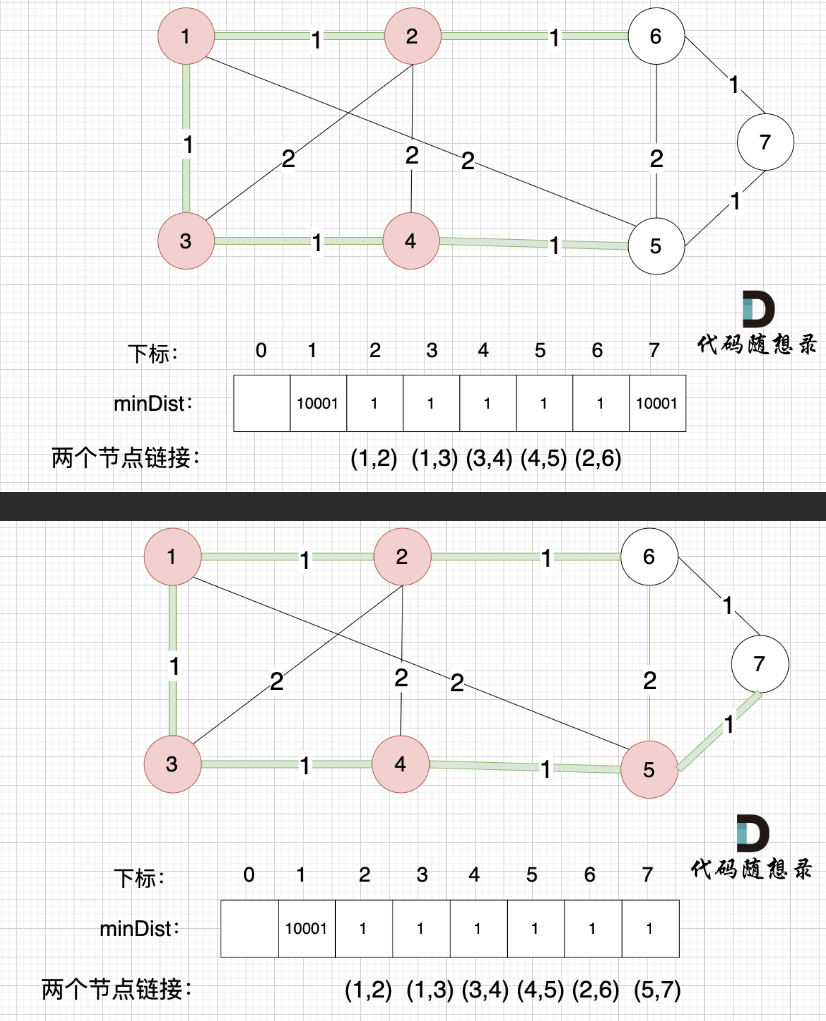
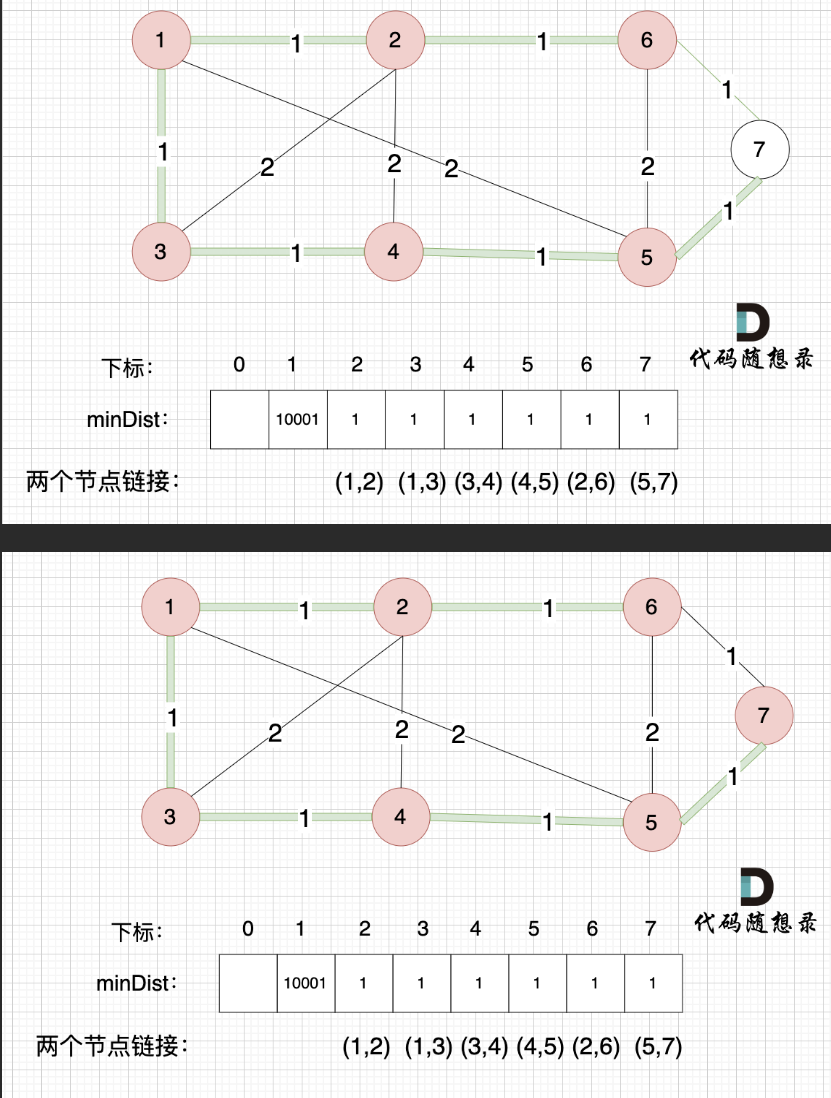
#include <iostream>
#include <vector>
#include <climits>
using namespace std;
int main() {
// 构造图
int v, e;
cin >> v >> e;
int x, y, k;
// 构造最大值10001
vector<vector<int>> grid(v+1, vector<int>(v+1, 10001));
for (int i = 0; i < e; ++i) {
cin >> x >> y >> k;
grid[x][y] = k;
grid[y][x] = k;
}
// 所有节点到最小生成树的距离
vector<int> minDist(v+1, 10001);
// 节点是否在最小生成树中
vector<bool> isTree(v+1, false);
// 最小生成树只需要v-1条边就可以链接n个顶点 序号从1开始
for (int i = 1; i < v; ++i) {
// prim 三部曲 1 选择距离生成树最近的节点
int cur = -1;
int minVal = INT_MAX;
// 遍历当前顶点 寻找 1.不在生成树内 2.最近生成树的节点
for (int j = 1; j <= v; ++j) {
if (!isTree[j] && minDist[j] < minVal) {
minVal = minDist[j];
cur = j;
}
}
// prim 三部曲 2 最近节点加入生成树
isTree[cur] = true;
// prim 三部曲 3 更新非生成树到生成树的距离 即更新 minDist数组
for (int j = 1; j <= v; ++j) {
// 更新条件 1.不在生成树中 2.与cur相连的某节点的权值 比 该某节点距离最小生成树的距离小
if (!isTree[j] && grid[cur][j] < minDist[j]) {
minDist[j] = grid[cur][j];
}
}
}
// 统计总距离
int res = 0;
for (int i = 2; i <= v; ++i) {
res += minDist[i];
}
cout << res << endl;
}
53. 寻宝(第七期模拟笔试)
kruskal 最小生成树算法
prim 算法是维护节点的集合,而 Kruskal 是维护边的集合。
kruscal的思路:
- 边的权值排序,因为要优先选最小的边加入到生成树里
- 遍历排序后的边
- 如果边首尾的两个节点在同一个集合,说明如果连上这条边图中会出现环
- 如果边首尾的两个节点不在同一个集合,加入到最小生成树,并把两个节点加入同一个集合
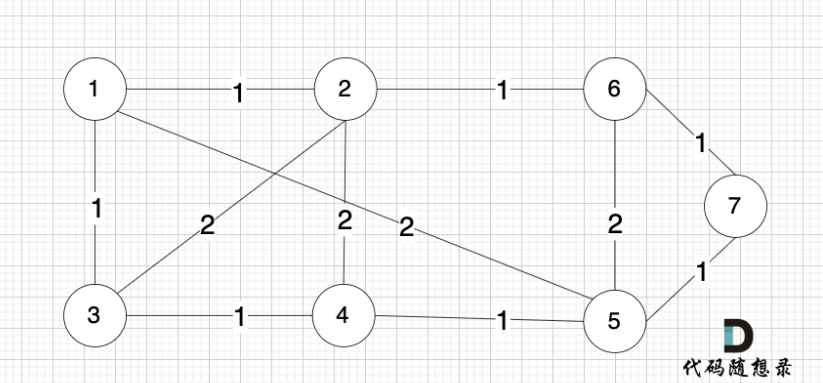
将图中的边按照权值有小到大排序,优先选 权值小的边加入到 最小生成树中
排序后的边顺序为[(1,2) (4,5) (1,3) (2,6) (3,4) (6,7) (5,7) (1,5) (3,2) (2,4) (5,6)]
(1,2) 表示节点1 与节点2 之间的边。权值相同的边,先后顺序无所谓。

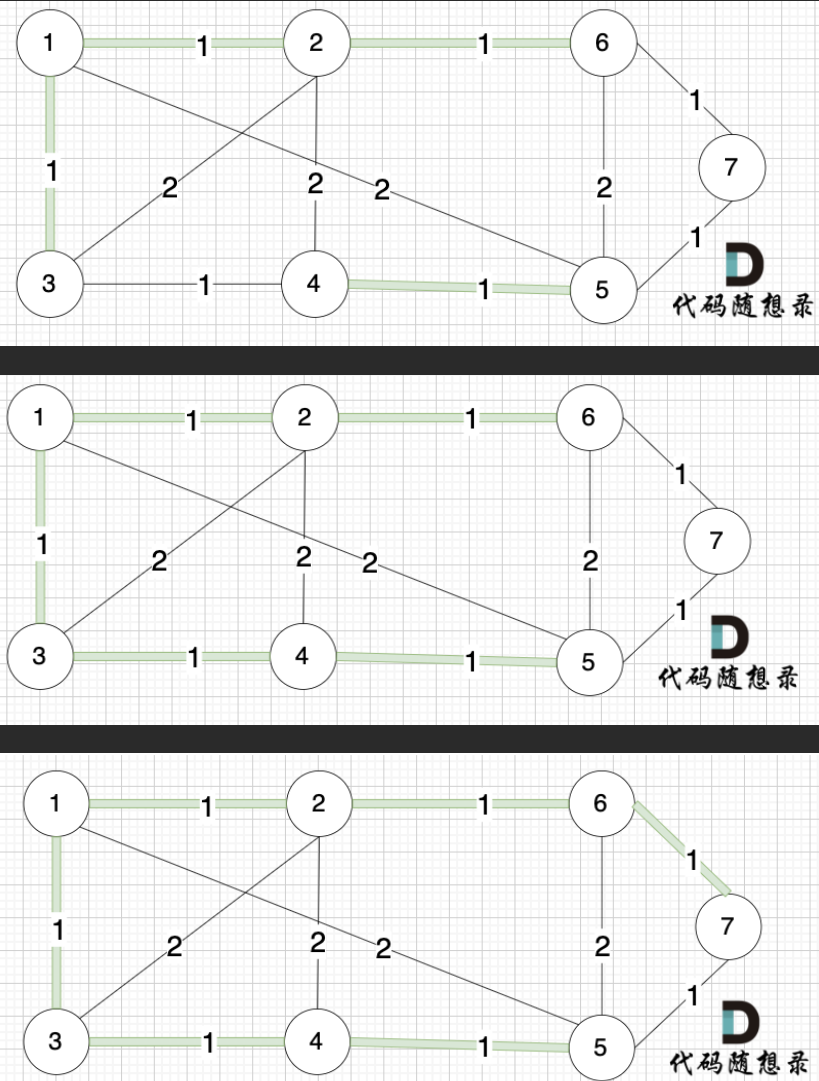
在上面的讲解中,看图的话 大家知道如何判断 两个节点 是否在同一个集合(是否有绿色的线连在一起),以及如何把两个节点加入集合(就在图中把两个节点连上)
但在代码中,如果将两个节点加入同一个集合,又如何判断两个节点是否在同一个集合呢?
这里就涉及到我们之前讲解的并查集。
Kruskal 与 prim 的关键区别在于,prim维护的是节点的集合,而 Kruskal 维护的是边的集合。如果一个图中,节点多,但边相对较少,那么使用Kruskal 更优。
- Prim 算法时间复杂度为 O(n^2),其中 n 为节点数量,它的运行效率和图中边树无关,适用稠密图。
- Kruskal算法时间复杂度为 nlogn,其中n 为边的数量,适用稀疏图。
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
struct Edge {
int l, r, val;
};
// 节点数量
int n = 10001;
vector<int> father(n, -1);
// 并查集
void Init() {
for (int i = 0; i < n; ++i) {
father[i] = i;
}
}
int Find(int u) {
return u == father[u] ? u : father[u] = Find(father[u]);
}
bool IsSame(int u, int v){
u = Find(u);
v = Find(v);
return u == v;
}
void Joint(int u, int v) {
u = Find(u);
v = Find(v);
if (u == v) return;
father[v] = u;
}
int main() {
int res = 0;
int v, e;
int x, y, k;
cin >> v >> e;
vector<Edge> edges;
for (int i = 0; i < e; ++i) {
cin >> x >> y >> k;
edges.push_back({x, y, k});
}
// Kruskal算法核心就是对边权重值排序,然后根据权重值合并到树
// 如果合并之后还是树那就合并,如何合并之后树图就不合并
sort(edges.begin(), edges.end(), [](const Edge& a, const Edge& b) {return a.val < b.val;});
Init();
// 从头遍历边
for (Edge e : edges) {
// 查询边的两个顶点祖先
int p1 = Find(e.l);
int p2 = Find(e.r);
if (p1 != p2) {
res += e.val;
Joint(p1, p2);
}
}
cout << res << endl;
return 0;
}