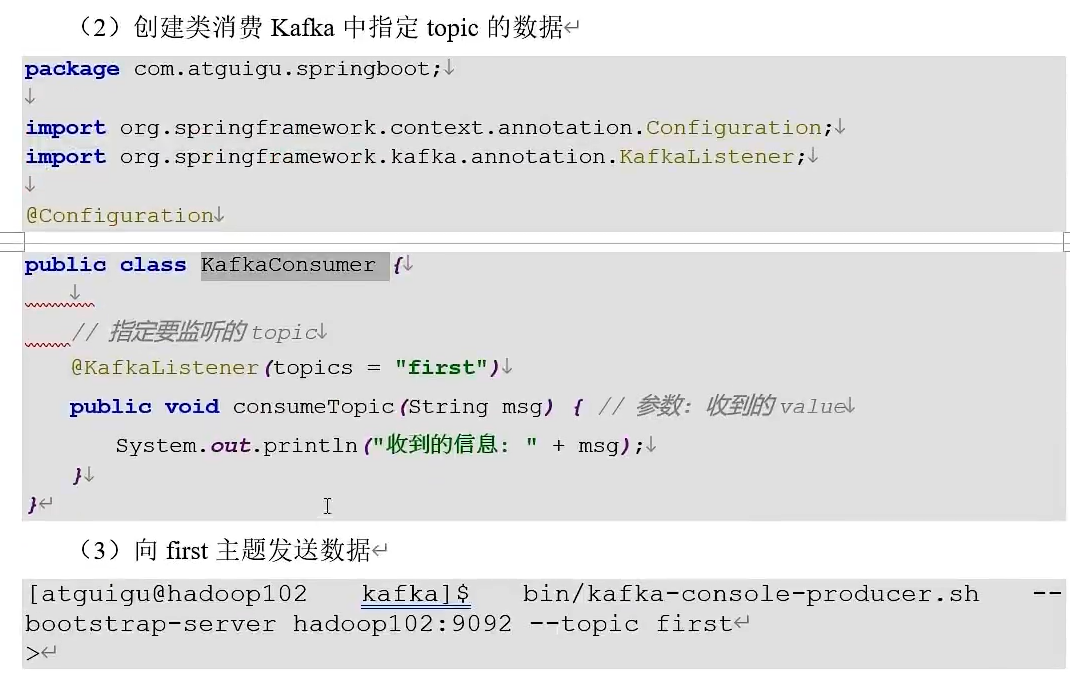
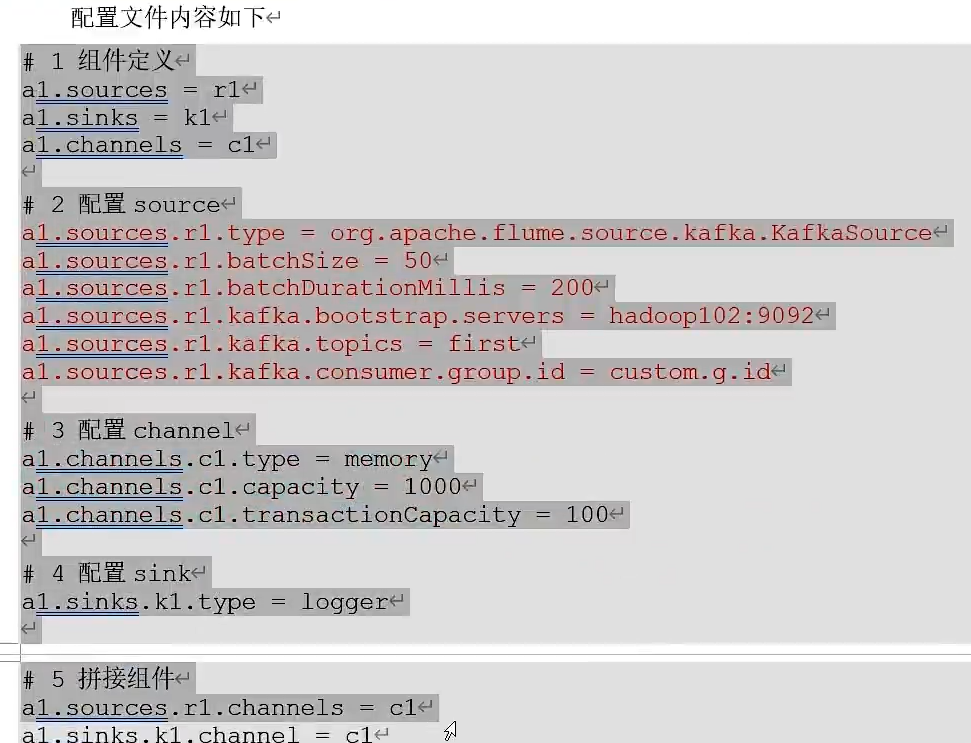
Kafka集成Flume
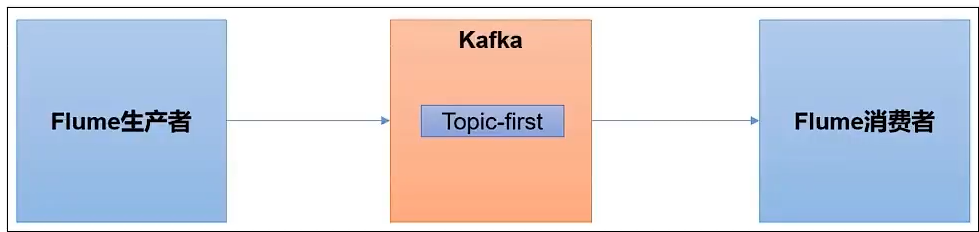
Flume生产者

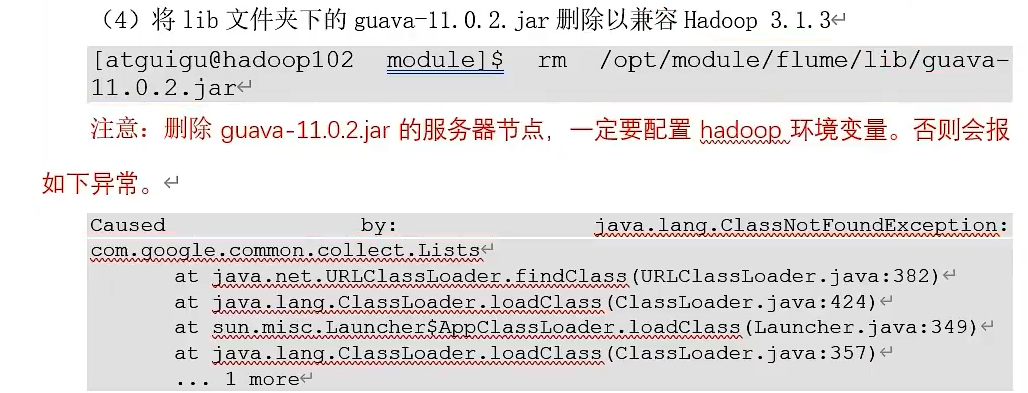
③、安装Flume,上传apache-flume的压缩包.tar.gz到Linux系统的software,并解压到/opt/module目录下,并修改其名称为flume


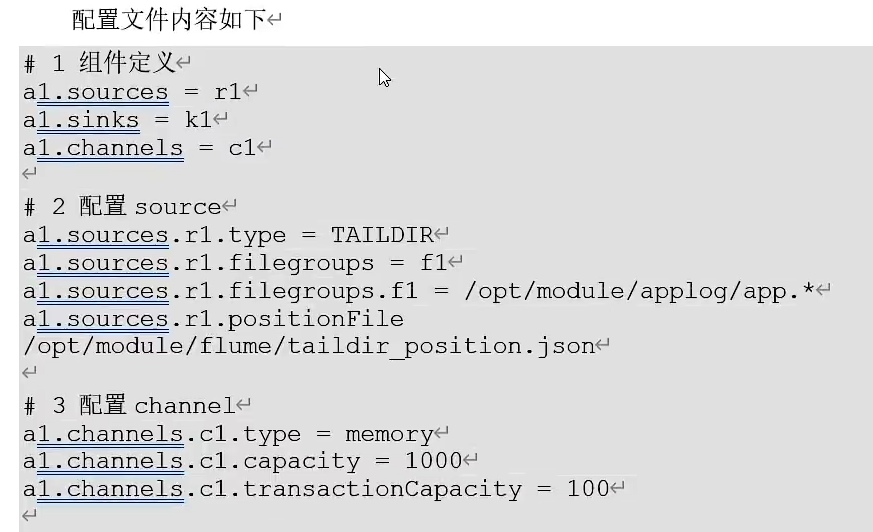
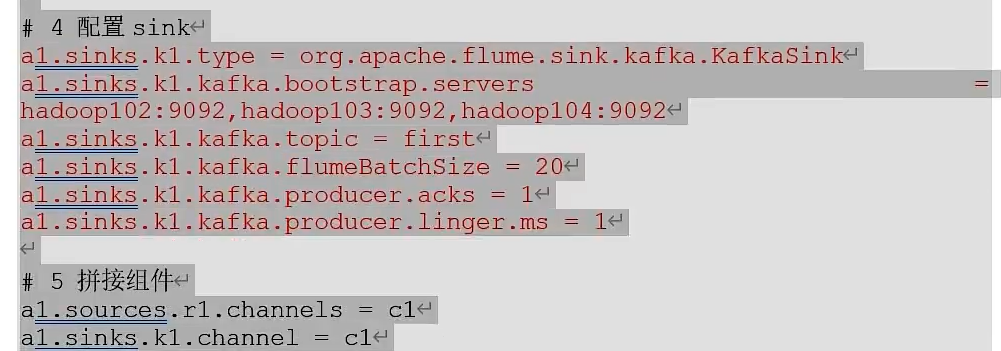




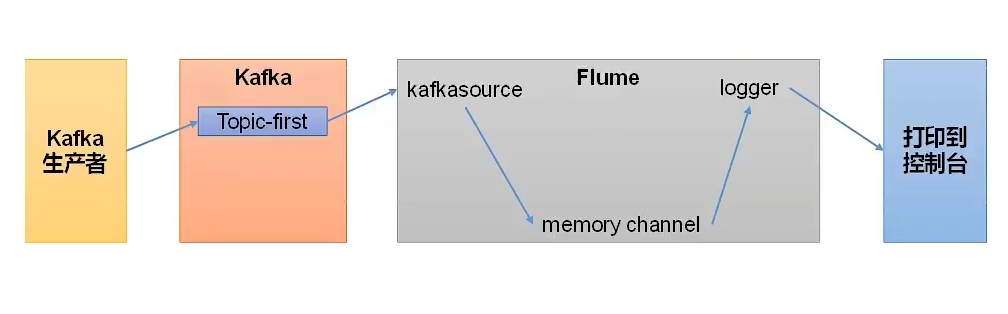
Flume消费者



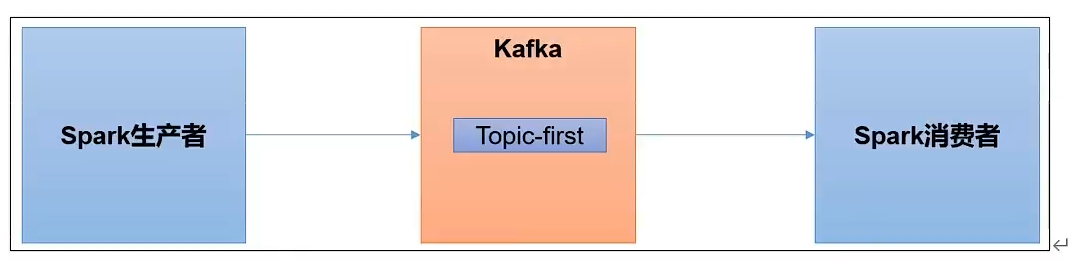
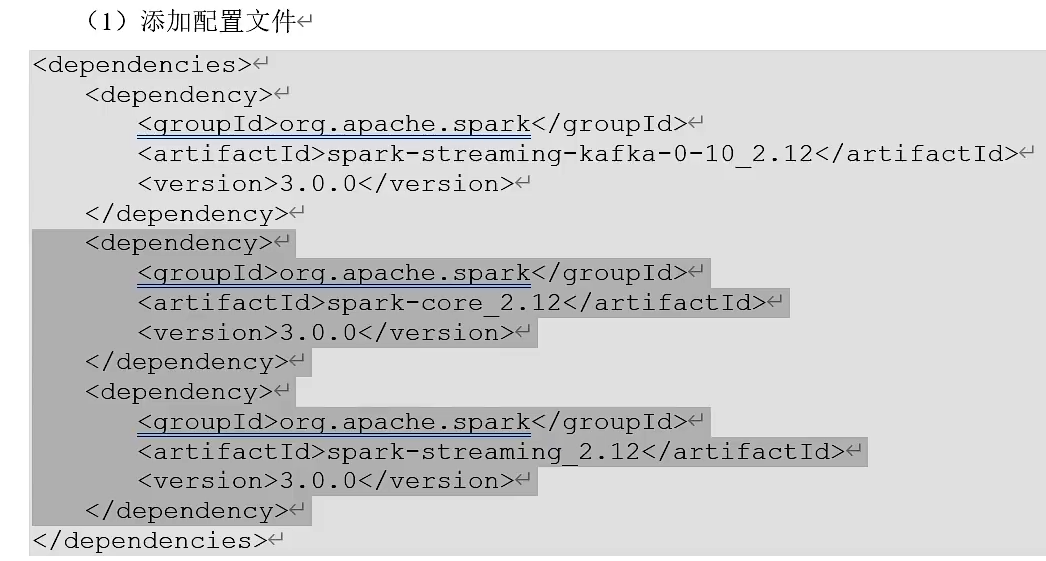
Kafka集成Spark

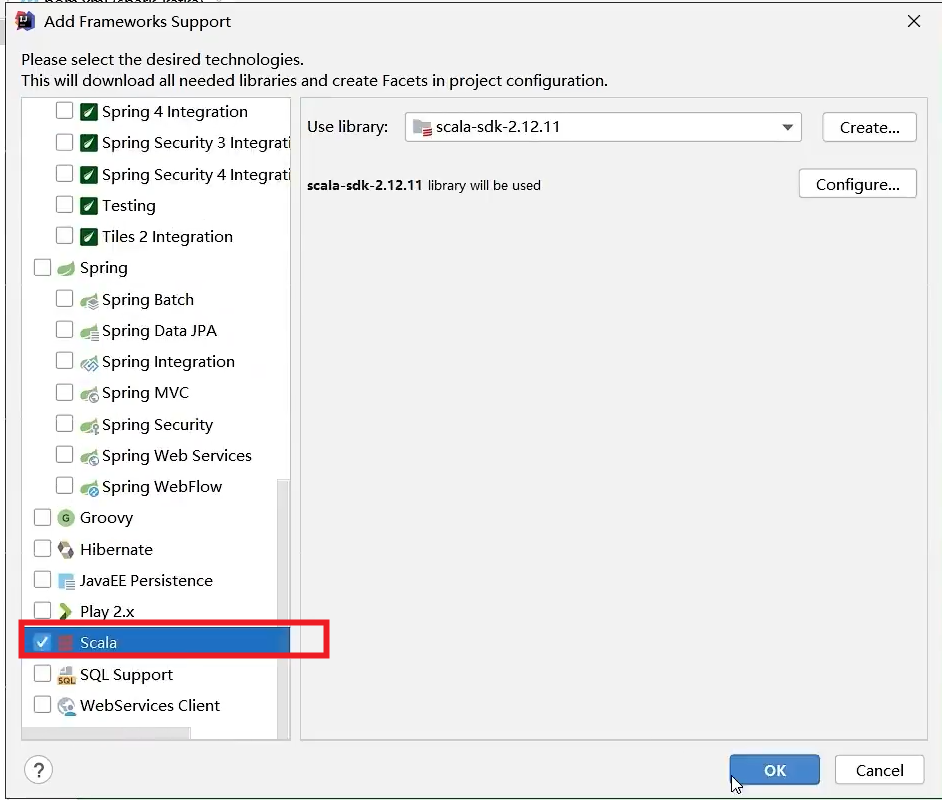
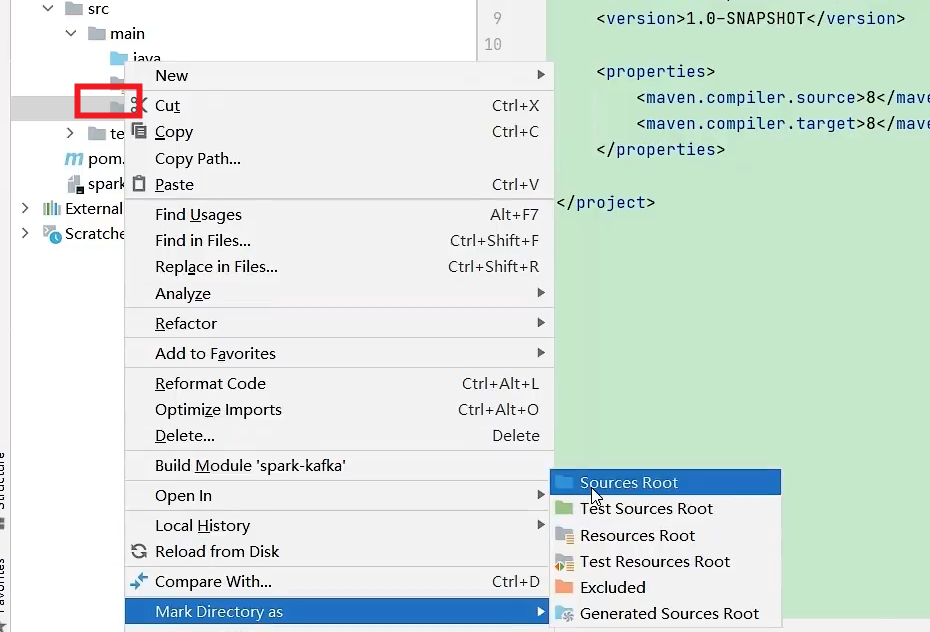

生产者
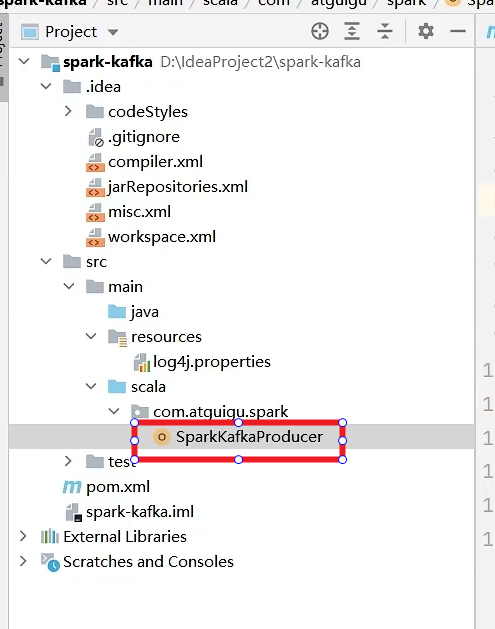

object SparkKafkaProducer{
def main(args:Array[String]):Unit = {
//配置信息
val properties = new Properties()
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092")
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,classOf[StringSerializer])
//创建一个生产者
var producer = new KafkaProducer[String,String](properties)
//发送数据
for(i <- 1 to 5){
producer.send(new ProducerRecord[String,String]("first","atguigu"+i))
}
//关闭资源
producer.close()
}
}
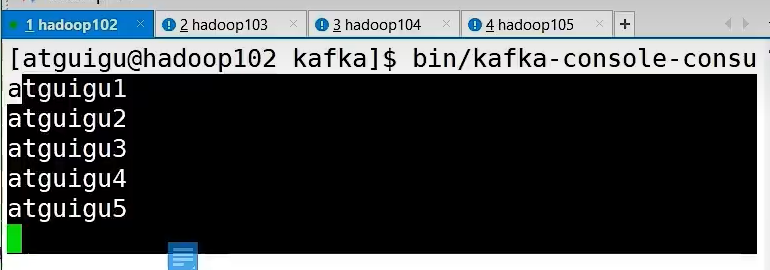
消费者
Object SparkKafkaConsumer{
def main(args:Array[String]):Unit = {
//初始化上下文环境
val conf = new SparkConf().setMaster("local[*]").setAppName("spark-kafka")
val ssc = new StreamingContext(conf,Seconds(3))
//消费数据
val kafkapara = Map[String,Object](
ConsumerConfig.BOOT_STRAP_SERVERS_CONFIG->"hadoop102:9092,hadoop103:9092",
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer],
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG->classOf[StringDeserializer],
ConsumerConfig.GROUP_ID_CONFIG->"test"
)
val kafkaDStream = KafkaUtils.createDirectStream(ssc,LocationStrategies.PreFerConsistent
,ConsumerStrategies.Subscribe[String,String](Set("first"),kafkapara))
val valueDStream = kafkaDStream.map(record=>record.value())
valueDStream.print()
//执行代码,并阻塞
ssc.start()
ssc.awaitTermination()
}
}
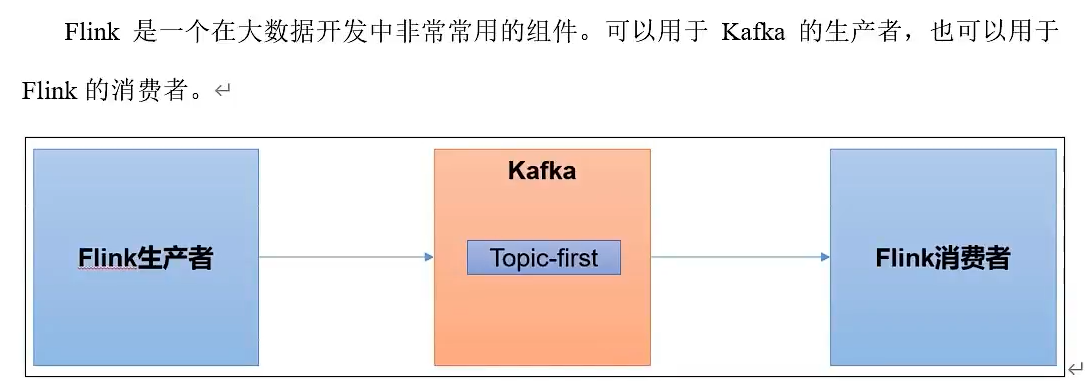
Kafka集成Flink
创建maven项目,导入以下依赖

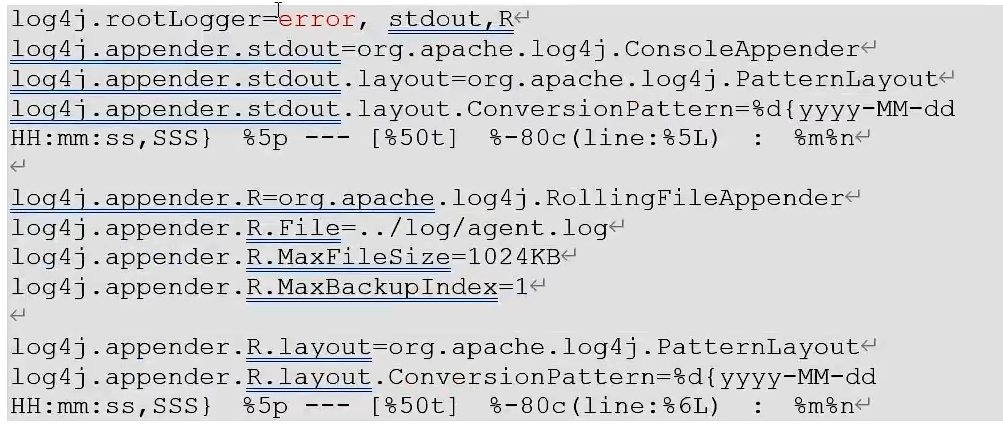
resources里面添加log4j.properties文件,可以更改打印日志的级别为error
Flink生产者
public class FlinkafkaProducer1{
public static void main(String[] args){
//获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
//准备数据源
ArrayList<String> wordList = new ArrayList<>();
wordList.add("hello");
wordList.add("atguigu");
DataStreamSource<String> stream = env.fromCollection();
//创建一个kafka生产者
Properties properteis = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
FlinkKafkaProducer<String> kafkaProducer = new FlinkKafkaProducer<>("first",new SimpleStringSchema(),properties);
//添加数据源Kafka生产者
stream.addSink(kafkaProducer);
//执行
env.execute();
}
}
Flink消费者
public class FlinkafkaConsumer1{
public static void main(String[] args){
//获取环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);
//创建一个消费者
Properties properties = new Properties();
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop102:9092,hadoop103:9092");
properties.put(ConsumerConfig.GROUP_ID_CONFIG,"test");
FlinkKafkaConsumer<String> kafkaConsumer = new FlinkKafkaConsumer<>("first",new SimpleSStringSchema(),properties);
//关联消费者和flink流
env.addSource(kafkaConsumer).print();
//执行
env.execute();
}
}
Kafka集成SpringBoot
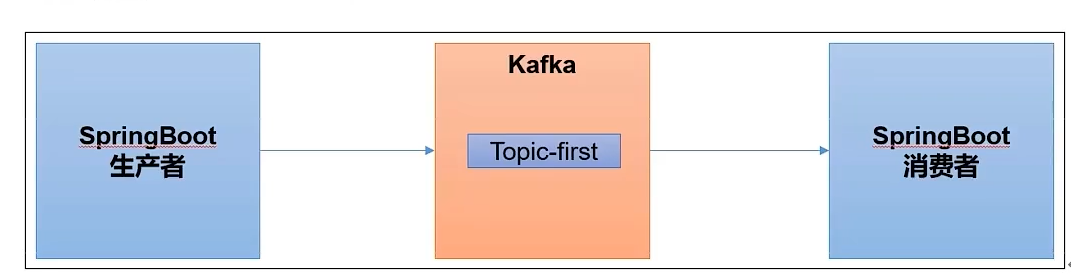
生产者


通过浏览器发送
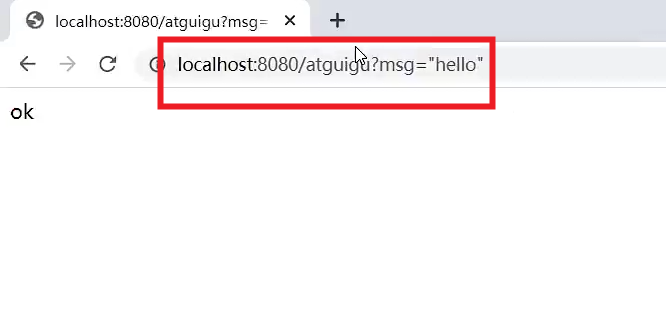
消费者