ISTD-DETR:A deep learning algorithm based on DETR and Super-resolution for infrared small target detection
ISTD-DETR:一种基于DETR与超分辨率技术的红外小目标检测深度学习算法

摘要
红外小目标检测在应急救援、自动驾驶等领域具有重要意义。然而,红外图像的低对比度和高噪声敏感性常导致检测性能不佳。为解决这些局限性,本文提出ISTD-DETR方法,通过将超分辨率预处理与改进的实时检测变换器(RT-DETR)模型相结合实现创新突破。首先,该方法引入EDSR超分辨率技术和多种图像增强手段,显著提升了红外图像的细节信息;其次,采用高效多尺度注意力(EMA)架构和状态空间模型设计ISTD-DETR的主干网络,增强了特征提取与长程依赖建模能力;再者,新增S2特征层与微目标检测编码器头结构,实现更优的特征融合与目标定位,使模型特别适用于红外小目标检测。此外,在特征融合环节引入SPD-EMA模块,进一步强化了模型对低分辨率小尺度目标的检测能力。公开数据集实验表明,ISTD-DETR在保持实时性的同时,显著降低了误检与漏检率,检测性能优于现有方法。
1.引言
红外目标检测作为目标检测领域的专门分支,因其具备穿透云层、烟雾等障碍物的卓越能力[1],不依赖光照条件可实现全天候工作[2,3],以及对电磁干扰的强抗性[4],在可见光与雷达等传统检测方法中展现出显著优势。该技术被广泛应用于军事及自动驾驶领域[5,6]。然而,由于红外小目标尺寸微小、缺乏色彩纹理等细节特征且距探测器距离遥远[7],其检测仍面临重大挑战。此外,在移动端部署此类检测算法时还需解决实时推理这一关键问题[8],进一步增加了小目标检测的难度。
红外小目标检测系统的关键性能指标是准确性与速度,因此需要算法在确保精确度和效率的同时,具备足够的鲁棒性以适应移动端部署。
当代红外小目标检测算法通常分为模型驱动与数据驱动两类方法。近年来,模型驱动方法(包括单帧与多帧技术)取得了显著进展。单帧检测依赖于滤波、局部和全局方法,而多帧方法则通过融合时空信息来预测运动轨迹。根据处理顺序,这些方法可分为"先检测后跟踪"(DBT)[9]与"先跟踪后检测"(TBD)[10]两类。DBT先在每帧中识别候选目标再依据轨迹确认,而TBD则考虑时序依赖性,对所有帧中的目标进行跟踪。然而TBD的高计算与存储需求限制了其实际应用。相比之下,DBT在计算效率与精度之间实现了最优平衡,使其成为红外小目标检测领域的优选方案。DBT的效能取决于稳健的单帧检测能力,因此提升单帧图像中小目标的检测技术至关重要。
计算机视觉领域的进展,尤其是基于卷积神经网络(CNN)的数据驱动检测算法,因其能够从海量数据中自主提取特征并以端到端方式高效泛化,现已获得广泛应用。然而,现有方法主要成功检测大中型目标,而小目标因尺寸微小及复杂背景干扰构成挑战。因此,将复杂背景信息与小尺寸红外目标的独特属性相结合,对提升检测精度至关重要。
为克服当前深度学习方法在目标丢失、误报、边缘模糊及高计算成本等方面的不足,本文提出了一种基于检测的小型红外目标识别创新方法。通过将改进的RT-DETR模型ISTD-DETR与超分辨率技术相结合,所提方法显著提升了全局上下文提取能力,聚焦目标区域注意力,并增强了对微小目标的捕获能力。在公开数据集Anti-UAV[11]和SIRST[12]上的实验结果表明,ISTD-DETR实现了精度与实时效率的最佳平衡,不仅能准确识别不同场景及干扰条件下的红外小目标,同时保持了良好的实时性能。关键贡献概述如下:
- 所提出的方法解决了基于Transformer的模型(如DETR)在实时性能差和小目标检测精度低方面的局限性。通过整合状态空间模型、多尺度融合和高效注意力机制,该模型在保持实时能力的同时显著提升了红外小目标检测的精度;
- 引入了一种以Mamba模型设计的新型骨干网络,利用状态空间模型的线性可扩展性实现更高效的特征提取。该骨干网络增强了长序列处理能力,在计算效率上优于传统Transformer模型,同时结合了Mamba序列处理优势与Transformer全局依赖建模能力,从而提升检测性能;
- 在Neck网络中集成SPD-EMA模块以增强红外小目标检测。通过采用SPD算法和EMA机制替代传统下采样操作,该模块捕获长程依赖关系并优化特征表示,最大限度减少关键空间信息丢失,显著提升对微小及遮挡红外目标的检测能力;
- 预处理阶段引入增强型深度超分辨率网络并结合数据增强技术,将低分辨率红外图像重建为高分辨率图像,提升图像清晰度并丰富小目标的细节特征,使边缘与纹理更鲜明,从而改善后续检测与识别效果;
- 在Neck网络中融入S2特征层以加强多尺度特征融合与特征判别力。通过捕捉不同尺度特征,S2层能更优地表征多尺寸目标,尤其提升小目标检测能力。新设计的DecoderHead则加速训练收敛并优化特征提取(特别是小目标),最终提高检测精度与鲁棒性。
2.相关工作
检测微小红外目标具有固有挑战性,主要原因包括其低信噪比[13]、有限的空间特征[14]以及复杂背景干扰[1]。这些因素导致目标难以与噪声或背景杂波区分。此外,目标尺寸微小往往仅占据图像中少量像素[15],特征提取过程中的降采样操作会进一步加剧这一问题。在移动平台上实现实时性能是另一关键挑战[16],因为计算效率与高检测精度之间的平衡通常难以兼顾。
针对低信噪比与背景杂波问题,传统模型驱动方法如滤波技术[17]和局部对比度增强[2]通过抑制背景噪声提升小目标可见性。然而这些方法在动态背景的复杂环境中表现欠佳,适用性受限。基于深度学习的方法[18,19]利用海量数据自主提取特征,展现出突破传统局限的潜力。部分研究通过张量分解与知识蒸馏平衡精度效率,例如采用双通路架构实现伪造检测[20]和低空航拍目标检测[21],但高计算成本导致实时性难以保证。针对小尺寸目标特征提取不足的问题,研究者深入探索了多尺度特征融合与注意力机制[22]的优化作用。基于Transformer的模型[23,24]利用注意力机制获取全局上下文,虽在小目标检测中表现突出,仍存在实时性差的缺陷。最新状态空间模型[25]以线性计算复杂度捕获长程依赖的特性,结合注意力机制与高效扫描技术,为轻量化实时检测提供了可行方案。
2.1 基于模型驱动的红外小目标检测方法
基于模型的红外小目标检测算法主要分为单帧和多帧两类方法[26]。单帧方法通常聚焦于三种策略:增强目标与背景的对比度、抑制背景噪声或将目标从背景中分离。这类方法包括基于滤波的技术[17,27,28]、基于局部信息的方法[2]以及全局方法[15,29],因其简单性、低计算复杂度和实时性能而受到重视。然而,在检测难度更高的复杂动态环境中,其有效性往往有所下降。
多帧方法通常分为检测前跟踪(DBT)与跟踪前检测(TBD)两类[30]。DBT采用单帧检测后进行轨迹验证的策略,而TBD则通过分析帧间灰度波动实现直接目标检测,例如采用像素灰度时序分析等方法[31]。虽然TBD能提供强健的目标轨迹分析,但其对多帧数据的依赖会影响实时性能。
多帧检测算法主要利用时空信息来检测红外小目标,并预测其在图像序列中的运动轨迹。当视场中存在与真实目标高度相似的干扰(如碎云)时,这些方法通常优于单帧算法。然而,多帧检测算法不可避免地增加了计算复杂度,从而降低了实时性能。相比之下,单帧检测算法具有更优的实时性,但在复杂背景干扰下其检测精度仍需提升。
2.2. 基于深度学习的数据驱动红外小目标检测方法
2.2.1 基于分割的红外目标检测算法
随着深度学习的进步,特别是红外小目标数据集的涌现,大量基于数据驱动的分割网络被提出。这些方法采用逐像素分割技术,通过阈值处理来识别目标[32]。其中MDvsFA算法[33]利用生成对抗网络(GAN),通过为生成器和判别器分配不同角色,实现平衡漏检与误报的目标分割。类似地,IRSTD-GAN[34]应用基于GAN的风格迁移技术生成仅含目标的合成图像,从而提升网络的检测精度。
进一步的研究将手动特征提取与卷积神经网络相结合。例如,刘俊明等人[35]提出了一种全卷积神经网络(FCN)与视觉显著性相结合的检测算法,通过抑制背景干扰增强目标特征。该算法先使用FCN分割红外图像,再通过视觉显著性降低虚警率,最终采用自适应阈值实现精确目标检测。戴等人[12]提出了SIRST数据集及非对称上下文调制(ACM)机制以优化分割效果。戴团队[18]进一步提出注意力局部对比网络(ALCNet),而李等人[19]则开发了密集嵌套注意力网络,通过嵌套交互模块实现特征融合,并利用注意力机制提升特征提取能力。
2.2.2 基于检测的红外目标检测算法
公开可用的红外小目标数据集通常使用掩码作为标签,这限制了基于锚点和无锚点检测网络的研究。然而,当前的红外检测方法大多是对通用先进目标检测模型的改进,包括两阶段方法(如Faster R-CNN [36,37])和单阶段方法(如YOLO [38–40]、SSD [41,42]以及Vision Transformer [43])。这些模型主要针对较大尺寸的可见光目标。
将这些算法应用于红外目标检测需要进行网络优化。Liu等人[44]率先采用深度神经网络,并在自定义红外数据集上验证了其方法的有效性。Lv[45]通过修改损失函数和网络架构,增强了YOLOv3对红外目标的检测性能。针对实时性限制,Manssor等[46]通过优化网络结构、采用K-means聚类方法、实施预训练以及改进特征提取流程,提升了YOLOv3的实时性能。Zhao[47]将DenseNet与YOLOv5结合,引入SE注意力模块和DenseBlock组件,同时简化BiFPN以实现多分辨率特征提取。Zhou[48]采用带SASE模块的YOLO网络,结合基于SRGAN的图像重建技术以增强模型鲁棒性。Li团队[49]提出YOLOSR-IST算法,通过坐标注意力机制、高分辨率P2特征图及Swin Transformer模块改进YOLOv5,有效降低了红外小目标检测的误报率。
2.3. 基于Transformer的目标检测方法
Transformer模型[23,24]在计算机视觉领域获得了广泛关注,其中检测Transformer(DETR)[50]成为目标检测领域的突破性方法。DETR通过消除大量人工流程、简化锚框生成、利用注意力机制直接生成预测集以及无需非极大值抑制(NMS),显著减少了超参数数量并加速了检测过程,从而革新了目标检测技术。然而,DETR复杂的编码器和二分图匹配算法导致收敛速度缓慢,且由于对不同尺寸目标采用均等计算复杂度,其小目标检测性能欠佳。针对这些局限性,目前已提出多种改进方案。
可变形DETR [51] 提出可变形注意力机制以缓解传统注意力计算成本过高的问题,在加速模型收敛的同时引入多尺度特征提升小目标检测性能。Group DETR [52] 通过利用多对象查询机制,发挥一对多训练优势,从而提升DETR模型性能与收敛速度。DAB-DETR [53] 将查询向量视为4D锚框,通过逐层细化方式促进模型收敛。DN-DETR [54] 引入去噪组策略以缓解二分图匹配不稳定性,显著加快了收敛速度。DINO [55]模型对此进一步优化,通过在Object365数据集上进行预训练,并采用Swin Transformer [56]骨干网络,实现了跨数据集的卓越性能。尽管存在这些改进,这些方法的高计算需求仍阻碍了实时应用。
为解决这一问题,RT-DETR被开发为一种实时解决方案,它继承了DETR的架构,但通过优化实现了更快的性能。RT-DETR通过采用更小的特征图和更少的注意力头数来降低计算成本,同时引入了分组注意力机制。这些改进使RT-DETR在保持与YOLO系列等SOTA方法相媲美的性能的同时,显著提升了速度和训练效率。
本文以RT-DETR为基础模型,针对红外小目标图像的独特特性进行针对性优化,从而实现了精准且实时的识别。
2.4. 状态空间模型
状态空间模型(SSMs)因其能够捕捉长程依赖关系,同时保持与输入大小相关的线性复杂度而受到广泛关注。在自然语言处理等领域,SSMs已展现出优异性能。VMamba[57]和Swin-UMamba[58]等现代改进方案进一步证明了SSMs在各类视觉任务中的有效性。受MambaUNet[59]和EfficientVMamba[25]的启发,本文通过将状态空间模型融入RT-DETR骨干网络,提升了红外小目标检测的性能。
2.5. 注意力模块
注意力机制在深度学习中发挥着关键作用,使模型能够聚焦关键特征。SE网络[22]提出了通道注意力机制,但缺乏空间整合能力。CBAM[60]和ECA[61]通过结合空间与通道注意力解决了这一问题,而CA[62]则通过捕获长程依赖关系进一步推进了这一机制。EMA模块[63]代表了最新进展,能动态聚焦多尺度特征以增强复杂特征提取能力。图1展示了EMA模块中的注意力编码过程
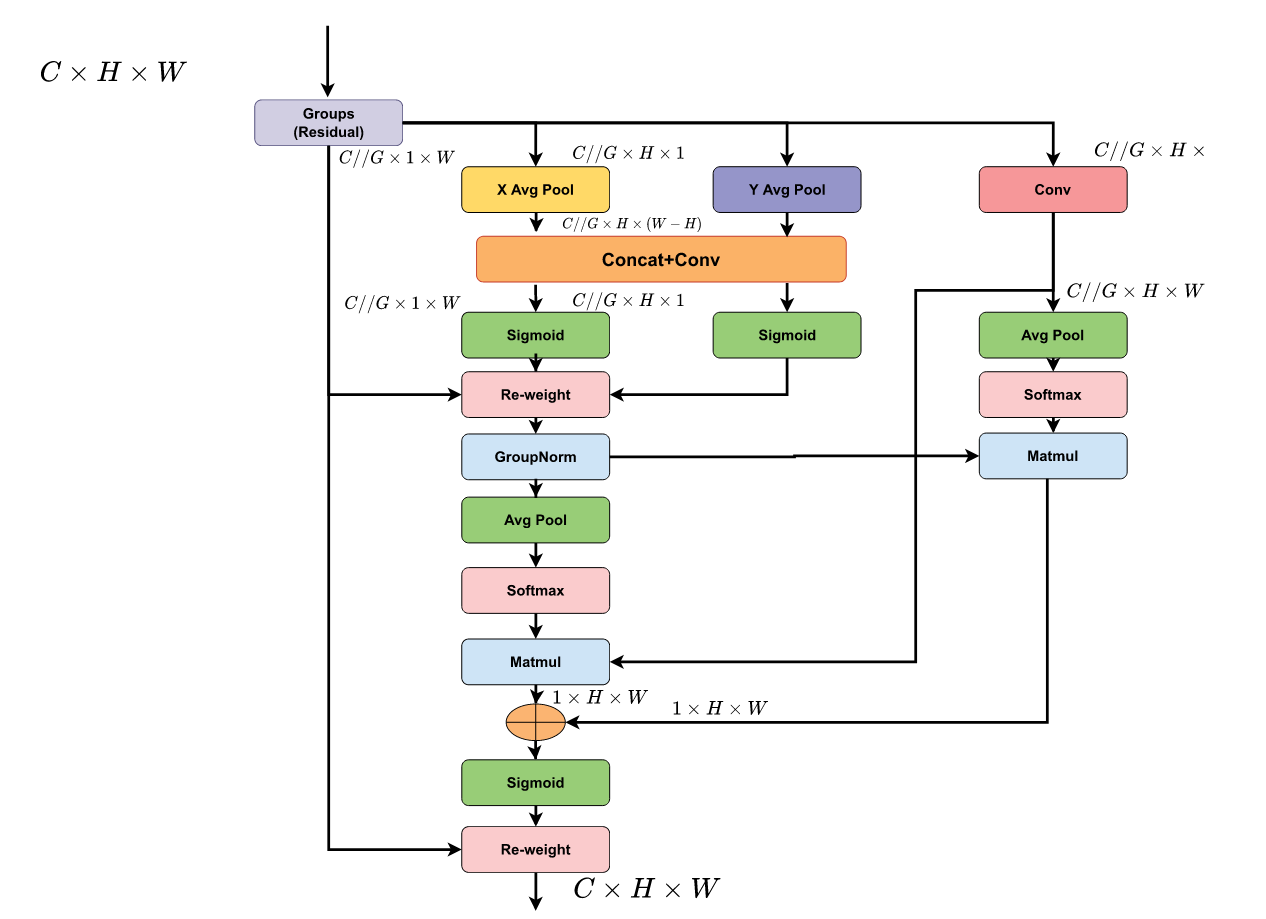
图1. EMA编码流程总览图。
EMA模块由三个独立分支组成。分支1通过减少通道数以实现与其他分支的信息整合。分支2借鉴CA机制,沿水平与垂直方向执行全局平均池化以高效聚合信息,该过程通过二维平均池化运算建模(如公式(1)所示),其中H和W分别表示特征图的高度和宽度, x c ( i , j ) x_c(i, j) xc(i,j)表示特征图第c个通道空间坐标(i, j)处的特征张量。分支3对输入实施卷积运算以捕捉跨维度交互。该设计使三个分支能够共同利用全局通道依赖性与局部空间特征,从而提供跨维度的全面特征表征。第c个通道的特征值如式(1)所示。
Z c = 1 H × W ∑ j H ∑ i W x c ( i , j ) Z_c=\frac{1}{H\times W}\sum_j^H\sum_i^Wx_c(i,j) Zc=H×W1j∑Hi∑Wxc(i,j)
3.方法
图2展示了我们提出算法的完整流程。
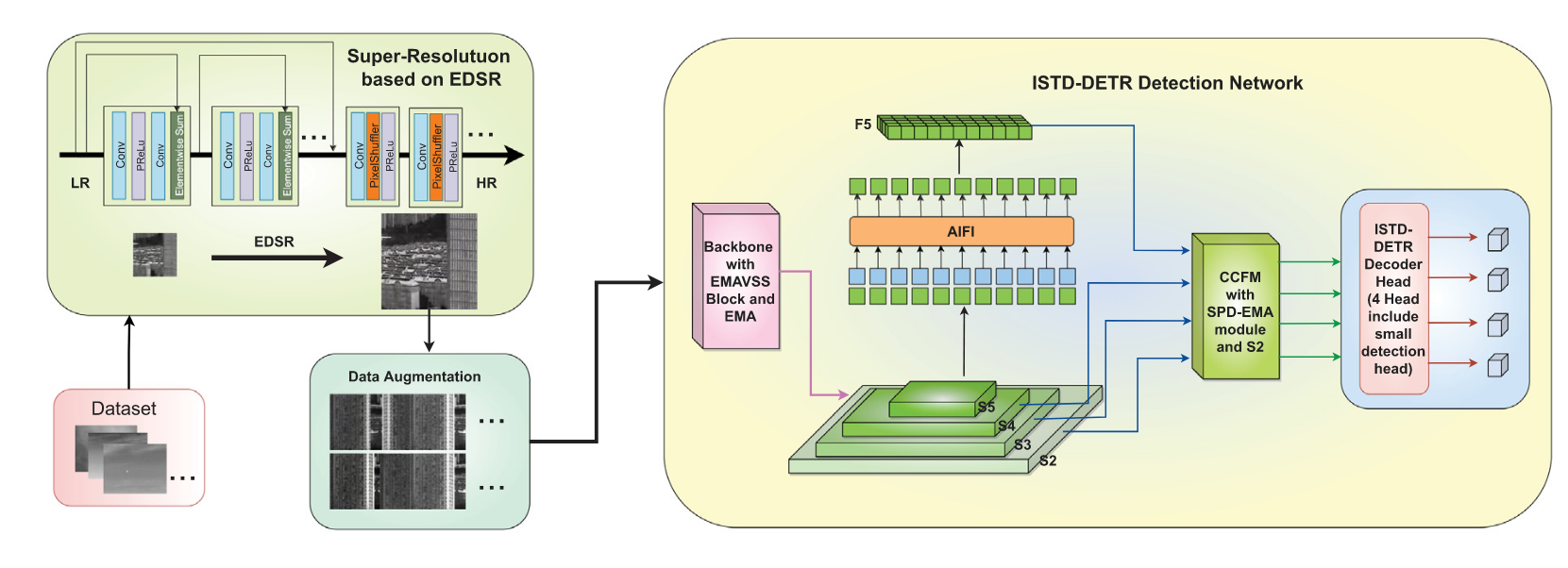
图2. 所提出方法的概述。
在预处理阶段,训练开始前采用了基于增强深度超分辨率网络(EDSR)[64]的超分辨率技术与数据增强方法。超分辨率技术提升了小目标的绝对像素数量并改善图像质量,而数据增强则通过添加噪声、旋转和翻转等手段扩充数据集。训练过程中,骨干网络整合了EfficientVMamba[25]的高效二维选择性扫描技术及EMA模块,以强化小目标检测能力。颈部网络添加了SPD-EMA模块来进一步提升目标识别性能。最终的特征融合过程包含S2特征层与微目标检测头,增强了模型提取红外小目标特征的能力。
在图2中,采用EDSR与数据增强技术的超分辨率重建部分对应第3.1节,ISTD-DETR模型细节则与第3.2节一致。该ISTD-DETR检测网络由三个子模块构成,分别对应第3.2节的三个子章节。
3.1. 超分辨率重建与数据增强
图像超分辨率技术可增强遥感图像,提供更丰富的细节与更高的质量。在红外成像中,微小物体因尺寸极小且信号微弱而难以识别,而卷积层的下采样操作常导致特征丢失。超分辨率技术能提升空间分辨率、清晰呈现目标、降低噪声并增强对比度,从而显著改善识别效果。
EDSR是基于SRResNet[65]构建的超分辨率重建模型,其核心思想是通过残差学习、移除批量归一化(BN)层并结合像素洗牌(Pixel Shuffle)实现高效的图像超分辨率重建。EDSR移除BN层的原因是:虽然BN能加速训练,但会抑制网络对高频细节的敏感性,尤其在需要精确恢复图像细节的超分辨率任务中。取而代之的是,EDSR采用像素洗牌来避免传统上采样方法(如双线性插值)引入的伪影。该技术通过重排通道维度实现空间分辨率的提升,其数学表达如式(2)所示:
I H R ( i , j , c ) = I L R ( ⌊ i s ⌋ , ⌊ j s ⌋ , c ′ ) I_{HR}(i,j,c)=I_{LR}\left(\left\lfloor\frac{i}{s}\right\rfloor,\left\lfloor\frac{j}{s}\right\rfloor,c^{\prime}\right) IHR(i,j,c)=ILR(⌊si⌋,⌊sj⌋,c′)
其中 I H R ( i , j , c ) I_{HR}(i, j, c) IHR(i,j,c)表示高分辨率图像第c通道坐标 ( i , j ) (i, j) (i,j)处的像素值, I L R I_{LR} ILR指代低分辨率输入图像。 ⌊ i / s ⌋ ⌊i/s⌋ ⌊i/s⌋和 ⌊ j / s ⌋ ⌊j/s⌋ ⌊j/s⌋表示经比例因子 s ′ s' s′缩放后的低分辨率图像纵横向位置, c ′ c' c′为通过像素洗牌与通道重排确定的低分辨率图像通道索引。
EDSR采用L1损失函数作为重建的优化目标,如公式(3)所示。与L2损失(均方误差,MSE)相比,L1损失对异常值较不敏感,更适用于图像重建任务。
L = 1 N ∑ i = 1 N ∣ I H R ( i ) − I r e c ( i ) ∣ \mathcal{L}=\frac{1}{N}\sum_{i=1}^N\left|I_{HR}(i)-I_{\mathrm{rec}}(i)\right| L=N1i=1∑N∣IHR(i)−Irec(i)∣
在训练过程中,EDSR采用多尺度训练策略,使网络学习不同放大倍数下的映射关系以适应多种分辨率的输入图像。为更平滑地从低分辨率图像生成高分辨率图像,需考虑像素间的连续变化。EDSR保留了低分辨率图像的分数坐标,通过插值实现低分辨率像素间的平滑过渡。输入低分辨率图像 I L R I_{LR} ILR与对应高分辨率图像 I H R I_{HR} IHR的关系被重新表述为
I H R ( i , j , c ) = I L R ( i s , j s , c ) I_{HR}(i,j,c)=I_{LR}\left(\frac{i}{s},\frac{j}{s},c\right) IHR(i,j,c)=ILR(si,sj,c)
在我们的研究中,采用的EDSR模型由一系列深度残差块构成,具体包含32个残差块和1个亚像素卷积层用于图像上采样。我们将缩放因子设置为4,使训练后的EDSR模型能够将图像分辨率提升四倍(见图3)。选择EDSR进行红外图像增强,源于其架构优势能直接应对红外小目标检测的挑战:通过移除批归一化层保留红外图像的关键强度变化;采用具有增强宽激活的残差学习结构,有效处理红外图像固有的低信噪比特性;同时利用像素洗牌进行上采样,在保持关键空间信息的同时最大限度减少可能干扰目标检测的伪影。这些特性使EDSR特别适合在保留小目标检测关键细微特征的同时增强红外图像质量。
图3. 超分辨率工作流程概述
为缓解样本数量有限及数据集中噪声干扰的问题,鉴于红外小目标检测极易受到强烈噪声和成像背景中像素颜色波动的影响,本研究采用添加噪声、几何变换、CutMix及随机颜色抖动等数据增强技术组合处理训练样本,以丰富小目标样本数量。具体而言,在原始数据集中引入椒盐噪声与高斯噪声,这些噪声的加入有助于模型更好地识别各类含噪图像,提升其泛化能力。原始数据集中的图像经过水平与垂直变换,使模型能更好地识别不同角度和方向的输入图像,从而增强其鲁棒性。此外,对原始数据集中的图像施加随机对比度与亮度抖动,使图像更鲜明多样,有助于模型更好地适应各种光照条件。
3.2. 提出的ISTD-DETR检测模型
在复杂环境中快速准确地检测小型红外目标需要提取并融合多层特征。这一过程有助于网络更有效地识别目标,即使目标以不同尺度出现。通过对比基于回归的检测方法性能后,我们选择当前最先进的端到端方法RT-DETR网络作为基础框架。
遵循目标检测模型的传统架构,RTDETR包含骨干网络(Backbone)、颈部网络(Neck)和解码头(Head)三部分。骨干网络负责从输入图像中提取基础特征,通常采用ResNet等架构;颈部网络执行额外的特征处理与特征融合,主要包括自适应尺度内特征交互模块(AIFI)和跨尺度特征融合模块(CCFM);解码头作为模型的最终阶段,根据颈部网络处理后的特征生成精确预测结果,包括边界框位置、目标类别及置信度。在RT-DETR中,解码头主要由Transformer解码器构成,通过IoU感知查询选择机制和迭代优化过程输出最终检测结果。针对红外目标的特性,我们对网络进行了显著改进,并提出新型检测框架ISTD-DETR,如图4所示。
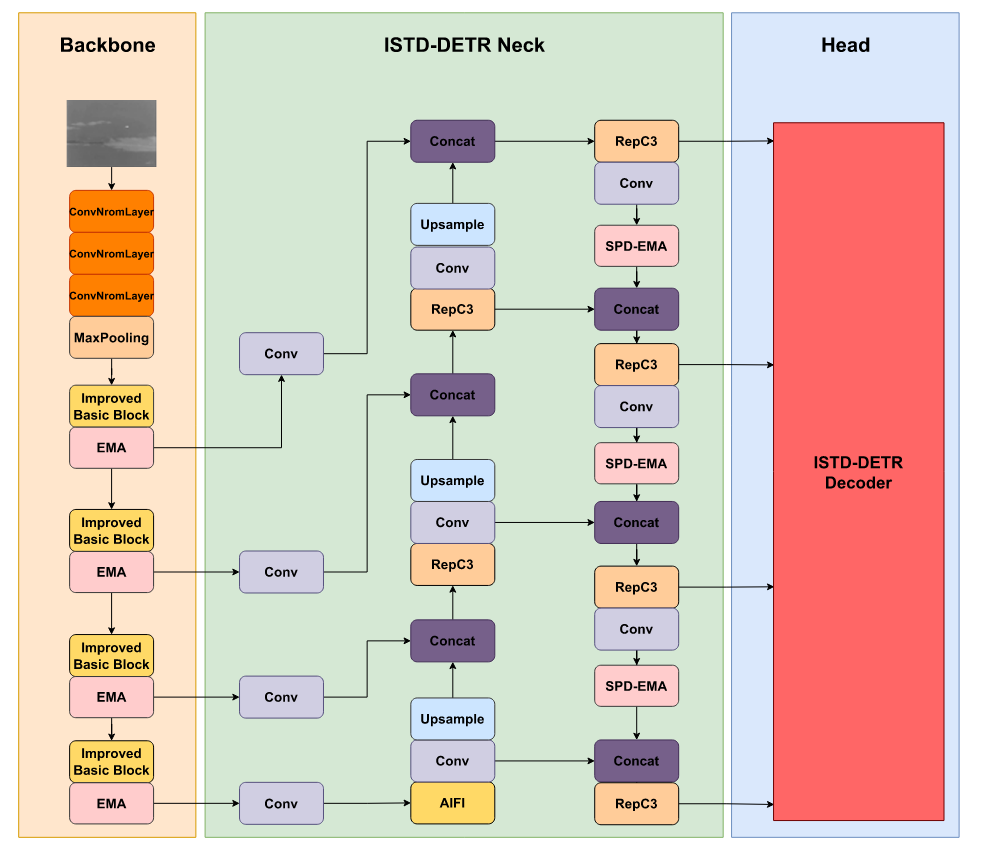
图4. ISTD-DETR网络结构概览图。
3.2.1. 基于ES2D与EMA模块的主干网络改进
主干网络结构基于ResNet18架构,由批归一化层、卷积模块、激活层和基础块模块组成。卷积模块执行卷积运算、批归一化及非线性变换,而基础块则包含两个采用跳跃连接的卷积层级结构,可直接传递特征。批归一化加速训练并提升泛化能力,激活函数则引入非线性以提高模型表达能力。我们利用ES2D设计EMAVSS模块并优化基础模块,从而以线性计算复杂度增强模型提取深层语义特征及远距离空间依赖关系的能力。
状态空间模型(SSM)通常用于描述时变系统,通过可学习状态 h ( t ) ∈ R N × D h(t) ∈ R^{N×D} h(t)∈RN×D将D维系统输入 x ( t ) ∈ R L × D x(t) ∈ R^{L×D} x(t)∈RL×D映射至系统响应 y ( t ) ∈ R L × D y(t) ∈ R^{L×D} y(t)∈RL×D。其数学表达如式(5)所示微分方程形式:
h ′ ( t ) = A h ( t ) + B x ( t ) h^{\prime}(t)=Ah(t)+Bx(t) h′(t)=Ah(t)+Bx(t)
y ( t ) = C h ( t ) + D x ( t ) y(t)=Ch(t)+Dx(t) y(t)=Ch(t)+Dx(t)
其中 A ∈ C N × N A ∈ C^{N×N} A∈CN×N, B 、 C ∈ C D × N B、C ∈ C^{D×N} B、C∈CD×N,且N为状态空间中的变量数量。
为适应深度学习中的离散数据,我们采用零阶保持方法对状态方程进行离散化处理,其中 Δ ∈ R D Δ∈R^D Δ∈RD。随后上述微分方程可离散化为如下形式的方程(6):
h k = A ‾ h k − 1 + B ‾ x k h_k=\overline{A}h_{k-1}+\overline{B}x_k hk=Ahk−1+Bxk
y k = C ‾ h k + D ‾ x k y_k=\overline{C}h_k+\overline{D}x_k yk=Chk+Dxk
A ‾ = e Δ A \overline{A}=e^{\Delta A} A=eΔA
B ‾ = ( e Δ A − I ) A − 1 B \overline{B}=(e^{\Delta A}-I)A^{-1}B B=(eΔA−I)A−1B
C ‾ = C \overline{C}=C C=C
其中 A ˉ ∈ R N × N , B ˉ , C ˉ ∈ R D × N , Δ ∈ R D \bar{A} ∈ R^{N×N},\bar{B}, \bar{C} ∈ R^{D×N},Δ ∈ R^D Aˉ∈RN×N,Bˉ,Cˉ∈RD×N,Δ∈RD为给定的样本时间尺度。实际计算中,常采用一阶泰勒展开对B进行线性近似求解,其表达式如式(7)所示:
B ‾ = ( e Δ A − I ) A − 1 B ≈ ( Δ A ) ( Δ A ) − 1 Δ B = Δ B \overline{B}=(e^{\Delta A}-I)A^{-1}B\approx(\Delta A)(\Delta A)^{-1}\Delta B=\Delta B B=(eΔA−I)A−1B≈(ΔA)(ΔA)−1ΔB=ΔB
SSM指状态转移中的元素 B 、 C ∈ R B × L × N B、C∈R^{B×L×N} B、C∈RB×L×N和 Δ ∈ R B × L × D Δ∈R^{B×L×D} Δ∈RB×L×D均源自输入数据 x ∈ R B × L × D x∈R^{B×L×D} x∈RB×L×D的场景。采用离散化状态空间模型可实现更高效的输入信号处理,如式(8)所示,通过卷积运算优化SSM的计算。
y = x ∗ K ‾ y=x*\overline{K} y=x∗K
K ‾ = ( C B ‾ , C A B ‾ , . . . , C A L − 1 ‾ B ‾ ) \overline{K}=(C\overline{B},C\overline{AB},...,C\overline{A^{L-1}}\overline{B}) K=(CB,CAB,...,CAL−1B)
其中卷积核 K ˉ ∈ R L \bar{K} ∈ R^L Kˉ∈RL。
然而,在二维图像中,方向敏感性可能导致全局感受野的丢失。SS2D模块通过采用四向扫描策略对图像切片进行处理,随后将扫描结果序列化并融合为单一图像,从而将复杂度从二次方降至线性(如图5(a)所示)。本文基于EfficientVMamba[25]的核心思想,采用高效二维扫描(ES2D)方法,通过跳跃采样和空洞卷积策略提取图像的全局信息(如图5(b)所示)。跳跃采样在降低计算开销的同时保持了全局特征的完整性。给定特征图 X ∈ R C × H × W X∈R^{C×H×W} X∈RC×H×W,ES2D将其分割为若干小尺寸块:
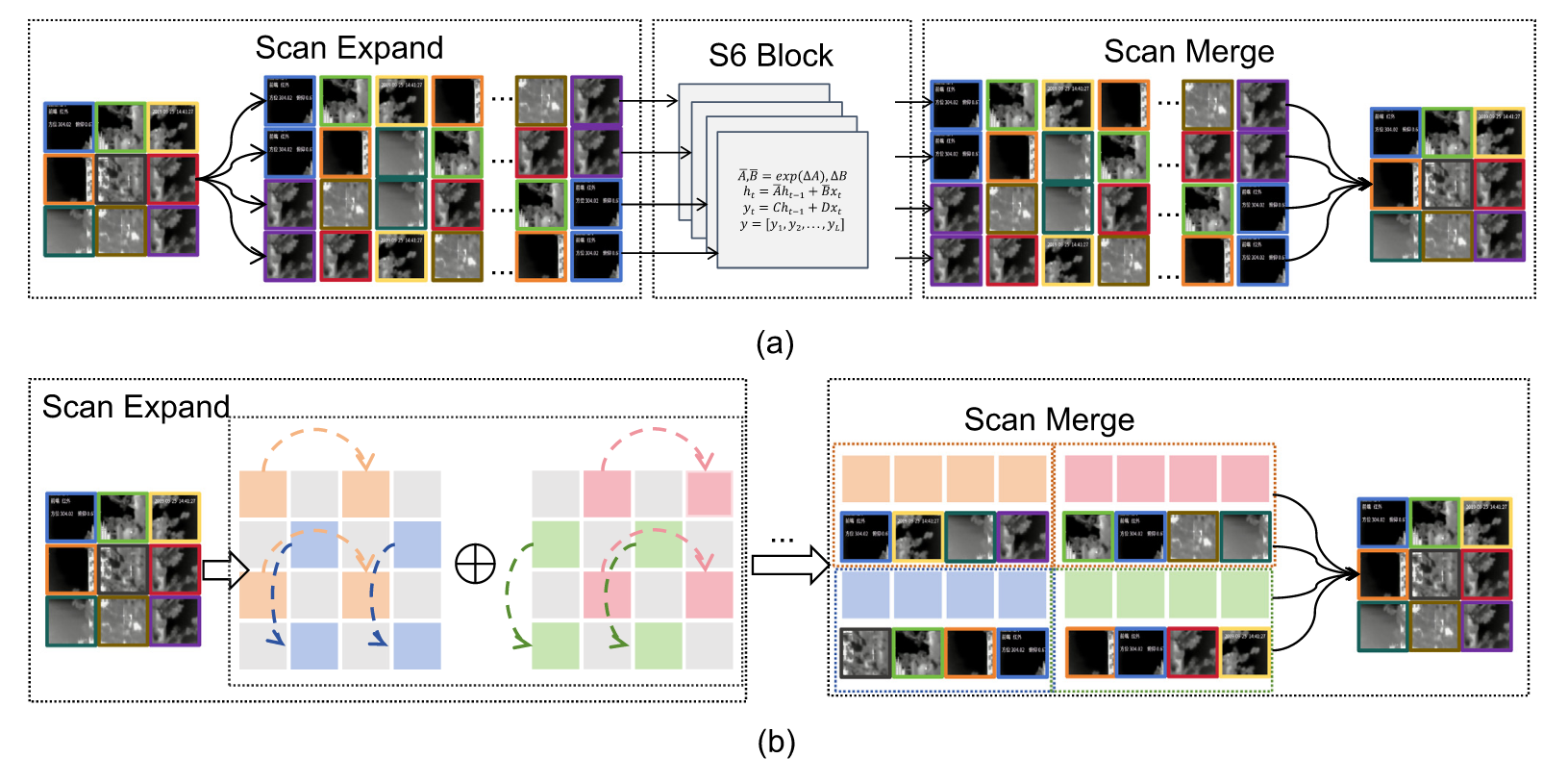
图5. SS2D与ES2D的工作示意图:(a) SS2D,(b) ES2D。
O i s c a n = X [ : , m : : p , n : : p ] O_i^{\mathrm{scan}}=X[:,m::p,n::p] Oiscan=X[:,m::p,n::p]
所选空间特征 { O i } i = 1 4 \{O_i\}_{i=1}^4 {Oi}i=14通过SS2D方法进行处理:
{ O ^ i } i = 1 4 ← S S 2 D ( { O i } i = 1 4 ) \{\hat{O}_i\}_{i=1}^4\leftarrow\mathrm{SS2D}(\{O_i\}_{i=1}^4) {O^i}i=14←SS2D({Oi}i=14)
合并后的最终输出为:
Y [ : , m : : p , n : : p ] = m e r g e ( O ^ i ) Y[:,m::p,n::p]=\mathrm{merge}\left(\hat{O}_i\right) Y[:,m::p,n::p]=merge(O^i)
权重矩阵:
( m , n ) = ( 1 2 + 1 2 sin ( π 2 ( i − 2 ) ) , 1 2 + 1 2 cos ( π 2 ( i − 2 ) ) ) (m,n)=\left(\frac{1}{2}+\frac{1}{2}\sin\left(\frac{\pi}{2}(i-2)\right),\frac{1}{2}+\frac{1}{2}\cos\left(\frac{\pi}{2}(i-2)\right)\right) (m,n)=(21+21sin(2π(i−2)),21+21cos(2π(i−2)))
此处, O i 、 O ^ i ∈ R C × H / p × W / p O_i、\hat{O}_i ∈ R^{C×H/p×W/p} Oi、O^i∈RC×H/p×W/p,选择性扫描 [ m ∷ p , n ∷ p ] [m∷p, n∷p] [m::p,n::p]以步长p跳过各通道的计算。此举将令牌数量从N降至 N / p 2 N/p^2 N/p2,在保持全局空间关系的同时提升了特征提取效率。通过融合局部与全局特征,该方法确保了沿空间轴的全面特征提取。
基于ES2D方法,我们开发了EMAVSS模块以增强ResNet的基础模块。该模块在保证计算效率的同时整合了全局与局部特征表征:ES2D负责捕获全局信息,而专用卷积分支则提取关键局部特征。两个分支均通过EMA模块进行处理。ES2D模块通过四向选择性扫描特征图,在保持全局在空间维度中的上下文信息质量的同时有效降低冗余。与此同时,采用步长为1的3×3卷积的卷积分支擅长捕捉精细的局部细节。随后,EMA模块会对这些特征进行重新校准,动态平衡局部与全局视野(见图6)。
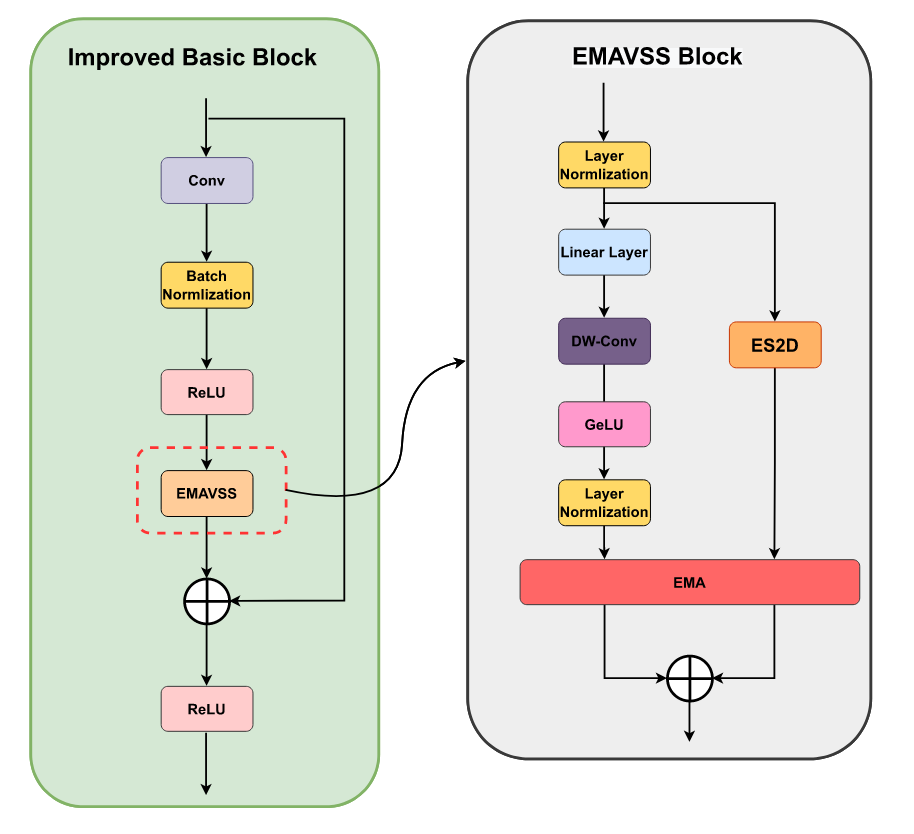
图6. EMAVSS模块结构示意图概述。
每个EMA模块的输出通过逐元素求和合并,形成EMAVSS的输出。这种双路径架构可表示为式(14):
X l = 1 = E M A ( E S 2 D ( X l ) ) + E M A ( L N ( G e L U ( D W C o n v ( L N ( X l ) ) ) ) ) \begin{aligned}X^{l=1}=&EMA(ES2D(X^l))\\&+EMA(LN(GeLU(DWConv(LN(X^l)))))\end{aligned} Xl=1=EMA(ES2D(Xl))+EMA(LN(GeLU(DWConv(LN(Xl)))))
此处, X l + 1 X^{l+1} Xl+1表示第l层的特征图,EMA(-)代表增强型多尺度注意力机制。通过在双路径中嵌入EMA模块,EMAVSS实现了全局与局部信息的动态平衡,既保留了宏观的全局上下文,又维持了精细的局部特征,这对实现精准检测至关重要。
所提出的EMAVSS实施方案在捕捉全局依赖性的同时保持了线性复杂度。公式(6)中的离散状态方程实现了对时空信息的高效处理,这对检测移动红外目标至关重要。此外,状态转移矩阵本身具有时间平滑特性,可在保留目标特征的同时滤除热噪声。公式(7)的近似计算进一步确保了不牺牲检测精度的运算效率。通过采用ES2D方法的四向扫描策略,该模型在保持计算效率的同时有效捕捉了空间关系。
在红外成像中,小目标通常呈现微弱信号特征,极易被背景噪声和热力变化所掩盖。EMA通过专门的多尺度注意力机制解决这一问题。针对低对比度目标,EMA采用双通路架构并行处理局部与全局特征:局部通路通过3×3卷积核捕捉细粒度目标细节,全局通路则通过选择性扫描聚合上下文信息。这种双重处理能有效区分目标细微特征与相似背景模式。在噪声环境中,EMA的自适应特征重校准机制发挥关键作用——该模块基于特征重要性动态调整注意力权重。
EMA模块由三个并行分支组成,各分支分别处理输入特征以捕获全面的空间与通道关联。分支1负责初始降维:
F r ( X ) = C o n v 1 ( X ) F_r(X)=Conv_1(X) Fr(X)=Conv1(X)
其中 X ∈ R C × H × W X ∈ R^{C×H×W} X∈RC×H×W为输入特征图,Conv1将通道维度降至 C ∕ r C∕r C∕r,r为缩减比例。
分支2通过双向平均池化捕获全局上下文信息:
F c t x ( X ) = σ ( C o n v 2 ( [ P o o l h ( X ) , P o o l w ( X ) ] ) ) F_{ctx}(X)=\sigma(Conv_2([Pool_h(X),Pool_w(X)])) Fctx(X)=σ(Conv2([Poolh(X),Poolw(X)]))
其中, P o o l h Pool_h Poolh和 P o o l w Pool_w Poolw分别代表水平与垂直平均池化操作,Conv2对聚合后的池化特征进行卷积处理,σ表示sigmoid激活函数。
分支3专注于局部模式提取:
F l ( X ) = C o n v 3 ( X ) F_l(X)=Conv_3(X) Fl(X)=Conv3(X)
其中Conv3是一种深度可分离卷积,能在保持空间信息的同时实现高效计算。
在多尺度特征处理中,EMA的三个分支通过加权融合机制进行整合:
Y = X ⊙ ( α ⋅ F r ( X ) + β ⋅ F c t x ( X ) + γ ⋅ F l ( X ) ) Y=X\odot(\alpha\cdot F_r(X)+\beta\cdot F_{ctx}(X)+\gamma\cdot F_l(X)) Y=X⊙(α⋅Fr(X)+β⋅Fctx(X)+γ⋅Fl(X))
其中α、β和γ是可学习的权重,用于平衡各分支的贡献。
该模块能够在抑制背景干扰的同时捕获不同尺度的目标特征。与红外目标检测中的传统注意力机制(如SE、CBAM和CA模块)相比,增强型多尺度注意力(EMA)机制通过其独特的三分支架构展现出更优性能,可同步解决红外弱小目标检测中的多重挑战。该机制通过双向池化操作实现全局上下文提取,采用深度卷积保持局部特征,并利用动态通道缩减进行高效特征优化,从而在保证计算效率的前提下有效捕获多尺度目标特性。
为进一步减少深层网络中位置信息的损失,在每个EMAVSS模块与后续卷积模块之间引入了额外的EMA模块,用于在特征融合前优化不同分辨率特征图间的注意力分布。
3.2.2. 在颈部添加SPD-EMA
卷积操作通常采用步长大于1的卷积或最大池化进行下采样,这能在增大感受野的同时持续降低图像分辨率。红外图像本身有限的分辨率及目标纹理特征的模糊性,常导致细粒度特征丢失。为此,本文提出名为SPD-EMA的模块以增强目标特征。SPD-EMA主要由空间深度转换(SPD)模块和高效多尺度注意力(EMA)模块构成。
SPD[66]算法基于深度神经网络,通过重组特征图来替代传统的下采样和上采样方法,在降低空间维度的同时增加通道维度。这种重组增强了所提取特征的区分度,并提升了模型对外部环境的稳定性。SPD通过将输入特征图划分为较小的子特征图,对这些子特征进行下采样后沿通道维度拼接,从而生成富含判别性信息的中间特征图。具体流程如图7所示:
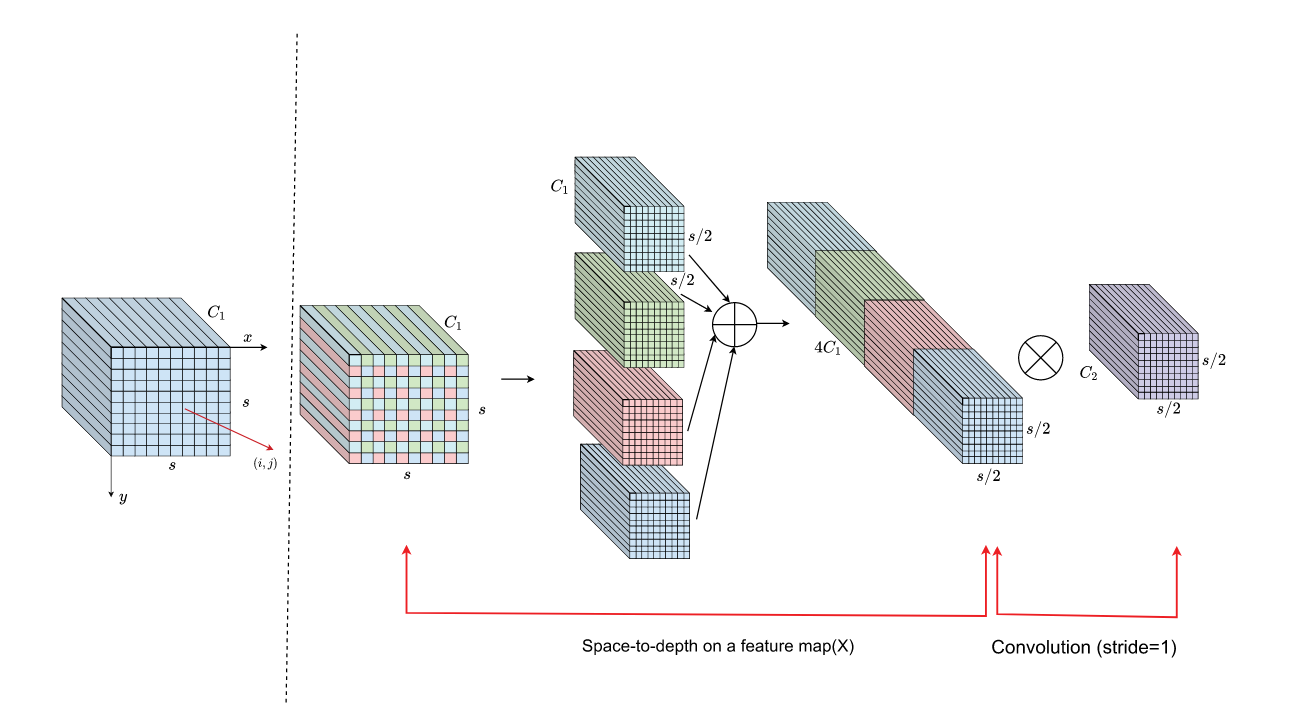
图7. SPD-Conv的工作流程图。
输入特征图X根据划分比例scale被细分为多个子特征图f,这一操作在保持深度不变的同时降低了空间维度。这些子特征图的拼接结果生成一个维度为 s / 2 × s / 2 × 4 C 1 s/2×s/2×4C_1 s/2×s/2×4C1的中间特征图 X ′ X' X′。该过程将原始特征图转换为更适于捕捉小目标检测所需细粒度细节的形式。子特征图拼接的数学逻辑如公式(19)所示:
f 0 , 0 = X [ 0 : s : s c a l e , 0 : s : s c a l e ] , f 1 , 0 , … , f_{0,0}=X[0:s:scale,0:s:scale],f_{1,0},\ldots, f0,0=X[0:s:scale,0:s:scale],f1,0,…,
f s c a l e − 1 , 0 = X [ 1 : s : s c a l e , 0 : s : s c a l e ] f_{scale-1,0}=X[1:s:scale,0:s:scale] fscale−1,0=X[1:s:scale,0:s:scale]
f 0 , 1 = X [ 0 : s : s c a l e , 1 : s : s c a l e ] , f 1 , 1 , … , f_{0,1}=X[0:s:scale,1:s:scale],f_{1,1},\ldots, f0,1=X[0:s:scale,1:s:scale],f1,1,…,
f s c a l e − 1 , 1 = X [ 1 : s : s c a l e , 1 : s : s c a l e ] f_{scale-1,1}=X[1:s:scale,1:s:scale] fscale−1,1=X[1:s:scale,1:s:scale]
… \ldots …
f 0 , s c a l e − 1 = X [ 0 : s : s c a l e , s c a l e − 1 : s : s c a l e ] , f 1 , s c a l e − 1 , … , f_{0,scale-1}=X[0:s:scale,scale-1:s:scale],f_{1,scale-1},\ldots, f0,scale−1=X[0:s:scale,scale−1:s:scale],f1,scale−1,…,
f s c a l e − 1 , s c a l e − 1 = X [ 1 : s : s c a l e , s c a l e − 1 : s : s c a l e ] f_{scale-1,scale-1}=X[1:s:scale,scale-1:s:scale] fscale−1,scale−1=X[1:s:scale,scale−1:s:scale]
最终特征图 X ′ ′ X'' X′′通过对中间特征图应用无步长卷积生成,此举有助于保留判别性信息且不再缩减空间维度。该最终特征图定义为:
X ′ ′ = Non-strided Conv ( X ′ ) X^{\prime\prime}=\text{Non-strided Conv}(X^{\prime}) X′′=Non-strided Conv(X′)
将EMA模块整合到SPD结构中,可确保通过动态重新分配不同尺度的注意力来进一步优化特征提取,从而最大限度地减少关键空间信息的损失。EMA在保持通道完整性的同时降低了空间维度。通过采用SPD-EMA而非传统方法在颈部采用步进卷积或下采样操作的同时,我们的模型保留了关键的小目标信息,避免了纹理特征的丢失,并减轻了下采样对特征保留的负面影响。这种组合方法通过高效管理空间与通道信息,提升了模型性能,使其在低分辨率场景下具有更强的鲁棒性。
3.2.3. 添加特征图S2及微型目标编码器头
颈部结构采用两种关键架构——AIFI与CCFM——实现跨尺度特征处理与融合。其中Conv模块负责特征提取,而Concat与上采样模块则对不同尺寸的特征图进行组合。RepC3进一步强化了特征融合能力。原始RT-DETR仅融合S3、S4和S5特征图,未包含浅层的S2特征图。然而由于小目标信息稀疏,多次下采样易导致底层特征的位置信息丢失。具有最小感受野和最高分辨率的S2特征图,对检测难以定位的微弱红外小目标至关重要。为此,我们将S2引入颈部结构,使CCFM能将F2的空间信息传递至F5,从而丰富融合特征。此外,我们新增了较小尺寸的解码头,使解码头总数由原始RT-DETR的3个增至4个。图8展示了引入S2后的特征融合流程。
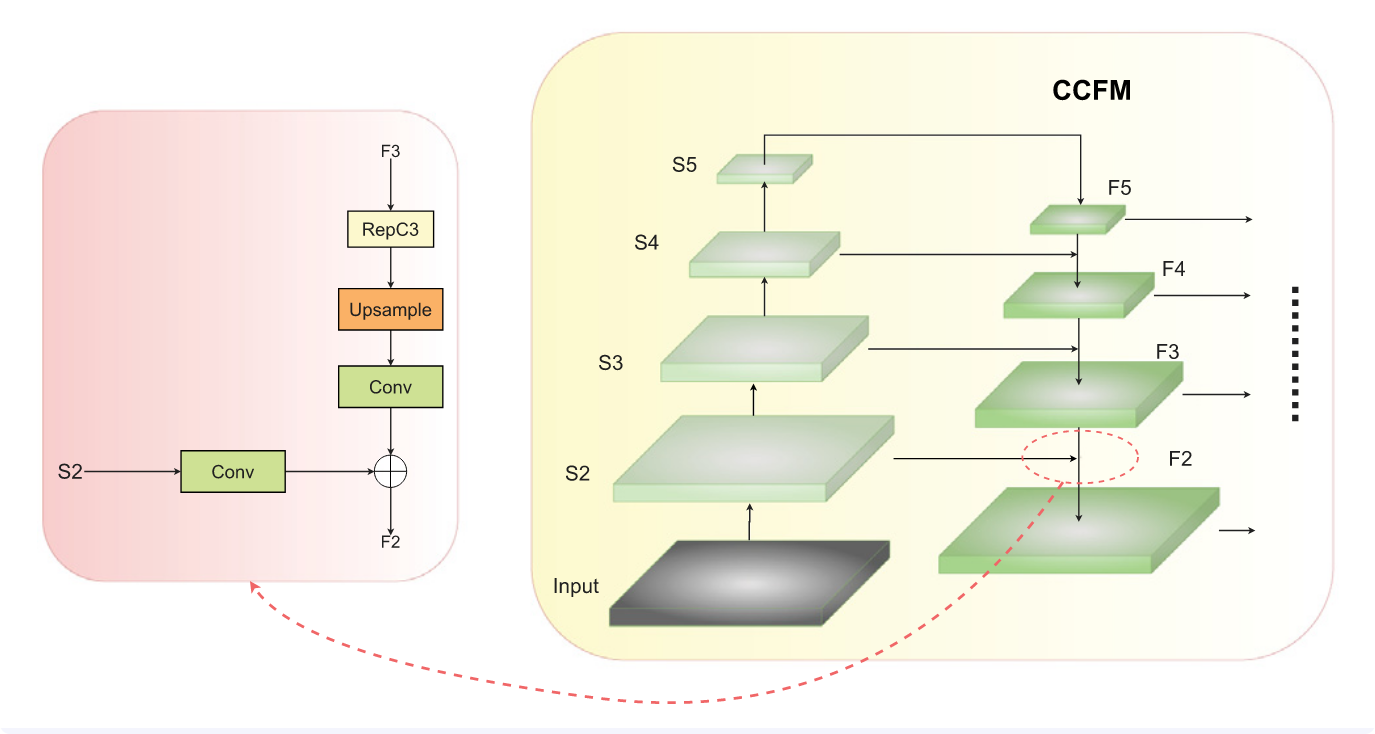
图8. S2的工作流程与特征融合示意图。
计算公式如式(21)所示:
F 2 = C o n c a t ( C o n v ( S 2 ) , C o n v ( U p s a m p l e ( R e p C 3 ( F 3 ) , 1 , 1 ) ) ) \begin{aligned}F2=&Concat(Conv(S2),\\&Conv(Upsample(RepC3(F3),1,1)))\end{aligned} F2=Concat(Conv(S2),Conv(Upsample(RepC3(F3),1,1)))
这些改进增强了模型区分前景与背景的能力,以及检测小目标的能力。
4.实验
4.1 数据集
为评估所提方法的检测效能,我们采用两个公开数据集:用于室外无人机跟踪的Anti-UAV基准数据集与SIRST[12]数据集。由北京理工大学于2023年发布的Anti-UAV数据集包含410段红外视频序列及逾40万条无人机标注。我们从该数据集中提取1842段图像序列,并使用LABELIMG工具人工标注边界框。
由南京航空航天大学(NUAA)于2021年发布的SIRST数据集包含427幅红外图像及480个目标。约90%的图像为单目标场景,10%呈现多目标特征。其中55%的目标仅占据总图像面积的0.02%(在300×300像素图像中为4×4像素区域),35%的目标具有最高亮度值。我们采用掩码标注方法对数据集进行了人工边界框标注。这两个数据集均按训练集+验证集与测试集的比例为9:1,训练集与验证集的比例为9:1。
该算法采用平均精度(AP)和每秒帧数(FPS)进行评估。AP用于衡量检测效能,交并比阈值为0.5时AP值越高表明性能越优。此外,我们还通过精确率与召回率来评估该模型相对于基于分割方法的性能表现。
A P = ∫ 0 1 P ( R ) d R AP=\int_0^1P(R)dR AP=∫01P(R)dR
F P S = λ N t FPS=\lambda\frac{N}{t} FPS=λtN
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP
R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP
其中真正例(TP)指正确识别出的目标数量,假正例(FP)表示将非目标错误识别为目标的误报情况,而假反例(FN)指真实目标被错误归类为非目标的漏报情形。
4.2. 训练环境与详细设置
所有实验均在配备Ubuntu 22.04.1 LTS操作系统、64.0 GB内存的Intel® Xeon® Gold 5218 CPU上完成。使用的深度学习模型均基于PyTorch框架(版本torch 2.1.1+cu118)实现,训练加速采用NVIDIA Corporation GA 102GL [RTX A5000]显卡(CUDA版本12.1)。训练阶段采用AdamW优化器进行损失函数最小化。EDSR模型在COCO数据集上进行了预训练,训练完成后用于提升图像质量。根据原始图像标注规范,超分辨率图像使用LABELIMG工具进行人工标注。测试阶段中,测试图像在预测前均经过EDSR超分辨率预处理。图9展示了超分辨率预处理示例,原始图像尺寸为256×256,图中真实目标区域经放大显示。图10呈现了预处理阶段实施的数据增强效果。

图9. 超分辨率预处理与原始图片对比示例:(a, c) 原始图片;(b, d) EDSR超分辨率处理后的图片。

图10. 数据增强预处理与原始图片对比示例:(a) 原始图像;(b) 亮度抖动;© 对比度抖动;(d) 高斯噪声;(e) 水平翻转;(f) 椒盐噪声。
在Anti-UAV数据集上的训练包含300次迭代,批次大小为8。SIRST数据集亦采用相同设置。表1展示了实验配置细节,图11则呈现两个数据集的训练结果,包含四项评估指标的曲线图。针对Anti-UAV数据集,ISTD-DETR模型迅速达到了收敛状态。具有优异的曲线拟合能力。在SIRST数据集上,ISTD-DETR的精确率、召回率及mAP曲线经过预热阶段后出现了短暂的不稳定调整期,但通过余弦退火调度算法持续调整学习率等参数,最终在300个训练周期前收敛至稳定状态。
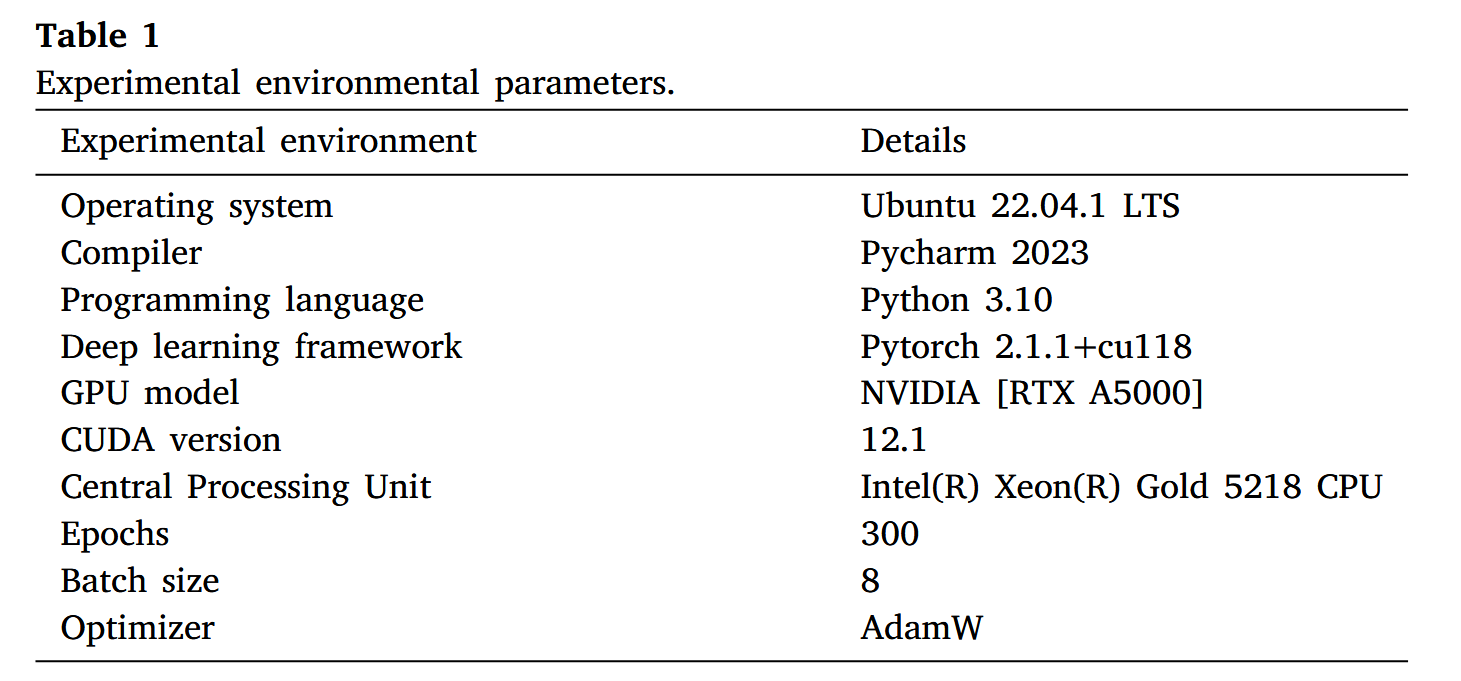
图11. 两个数据集的训练结果,包括精确率(Precision)、召回率(Recall)、mAP@0.5及mAP@0.5:0.95曲线:(a) 反无人机数据集;(b) 红外小目标数据集。
4.3. 与SOTA方法的对比实验
所提出的方法在多个公开数据集上针对各类先进技术进行了测试。对比方法包括通用的基于深度学习的目标检测技术,以及过去两年专为红外小目标检测任务开发的新方法。这些方法涵盖了基于检测和基于分割的两类技术路线。实验结果表明,在两种数据集的红外目标检测任务中,ISTD-DETR模型在检测和分割两种范式下的性能均优于当前最优方法。表2和表3呈现了两个数据集的测试结果对比。
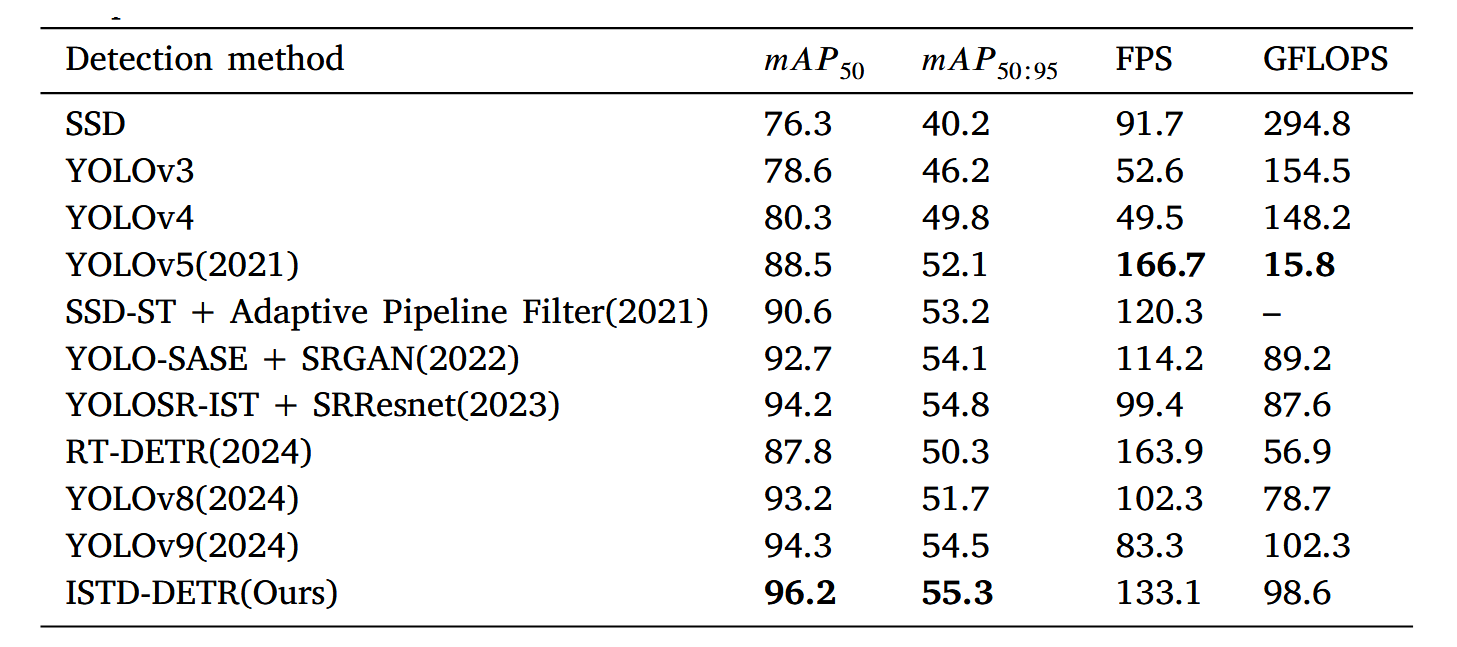
表2 Anti-UAV数据集上与其他经典及SOTA方法的对比结果。
请注意,mAP 50和mAP 50∶95均为百分比数值,最佳数据以粗体标出。
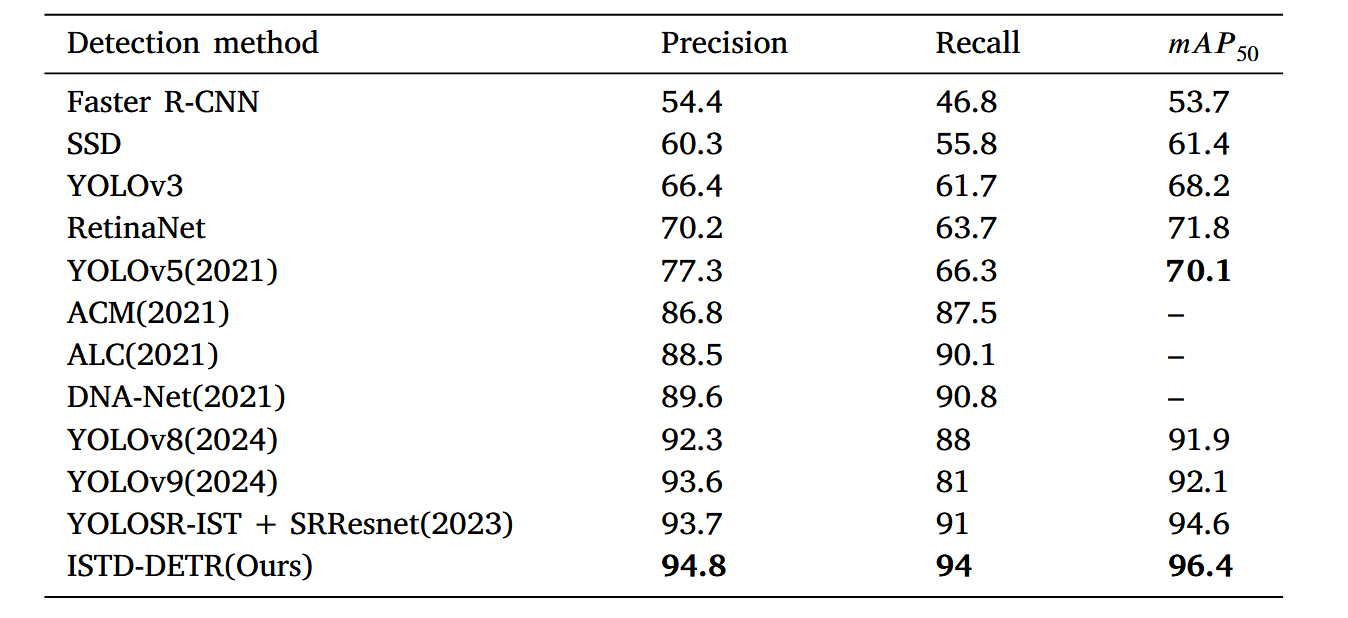
表3 SIRST数据集上与其他经典及SOTA方法的对比结果
请注意,我们模型的数值以粗体突出显示。表中用短横线(“–”)标记的部分表示基于分割范式进行检测的模型。这些模型的评估指标主要关注精确率和召回率,不包含mAP。
在Anti-UAV数据集上,ISTD-DETR以96.2%的mAP@50达到所有方法中的最高水平,展现出卓越的综合检测性能。同时其以133.1 FPS的帧率位列实时效率第二名,仅次于YOLOv5。这表明ISTD-DETR在精度与速度之间实现了显著平衡。
在SIRST数据集上,ISTD-DETR模型的mAP@50达到96.4%,并在所有检测与分割模型中取得了最高的精确率和召回率表现。YOLOSR-IST + SRResnet和YOLOv9代表了当前基于检测的领先方法,而DNANet和ALC则是最优秀的分割方法。ISTD-DETR不仅能有效捕捉正样本,还显著降低了误检与漏检率,展现了其精准检测微小目标的能力。该模型在两类数据集上对不同尺度目标均表现出强劲性能,进一步凸显了其鲁棒性。值得注意的是,我们的模型甚至超越了DNA-Net、ALC和ACM等最新基于分割的方法。这一成功归功于微目标检测编码器头的设计——如第3.2.3节所述,该设计通过S2特征层整合,在保持高分辨率特征图的同时,有效融合了多尺度特征信息。
该显著改进可归因于模型的三项关键贡献:首先,在骨干网络中引入EMAVSS模块和EMA注意力机制,通过双路径架构实现了更高效的特征提取。该设计将ES2D路径的全局上下文信息与卷积路径的局部特征相结合,从而更全面地理解目标特性。相较于仅依赖传统卷积特征提取的YOLOv9或基于Transformer的RT-DETR等方法,其优越性能印证了这一点。其次,SPD-EMA模块在增强特征判别力的同时保留空间信息的有效性,体现于mAP@(50:95)指标的提升。这一改进符合我们关于SPD-EMA通过空间深度变换和注意力机制保持关键空间信息的理论分析,这对小目标检测尤为关键。第三,所提模型的实时性能验证了线性复杂度状态空间模型集成的效率。尽管略低于YOLOv5,但该权衡被显著的精度提升所证明,体现了我们均衡网络设计的有效性。
4.4. 消融实验
ISTD-DETR的消融研究结果如表4所示,实验基于Anti-UAV数据集进行。该模型将原始RT-DETR的mAP@0.5提升了8.4%,mAP@0.5:0.95提升了5%。尽管推理时间和GFLOPS有所增加,ISTD-DETR仍满足实时检测需求。

表4 ISTD-DETR的消融测试结果。
请注意,SR代表超分辨率(Super Resolution),DA指数据增强(Data Augmentation),BI为骨干网络改进(Backbone Improvement),S2MEH是S2与微编码器头(S2 and Micro EncoderHead)的缩写。mAP 50和mAP 50∶95的数值均为百分比形式。
超分辨率预处理步骤显著提升了检测性能,使mAP@0.5和mAP@0.5:0.95指标均提高了3.8%。实践证明,超分辨率技术对提升检测精度至关重要,通过调用预加载的超分辨率模型可实现这一优化。在多推理任务中,整体推理速度仍能满足实时应用需求。这些结果表明超分辨率是ISTD-DETR性能的关键因素。BI模块的贡献(mAP@50提升2.4%)与我们对EMAVSS块效用的理论分析直接相关。如第3.2.1节所述,ES2D与EMA机制的整合在保持计算效率的同时实现了全局与局部特征增强。S2MEH模块的效果(mAP@50提升1.4%)验证了我们关于特征保持与增强的理论框架。虽然计算成本有所增加(帧率降至135.1 FPS),但检测精度的提升(尤其是对小目标)证明其合理性。最终整合的SPD-EMA模块(mAP@50提升0.2%,mAP@(50:95)提升0.7%)证明了我们空间信息保持策略的有效性。
消融实验结果表明,每个组件均对检测性能提升有所贡献,每增加一个模块都能提高mAP值。这些发现验证了所提检测方法的可解释性。
4.5. 定性可视化实验
4.5.1. 检测结果的定性可视化
ISTD-DETR模型在小目标红外检测中的定性结果如图12所示。我们从Anti-UAV和SIRST测试集中随机选取了四幅图像,这些图像呈现了不同场景下从多方向接近的小目标物体,同时包含大量干扰物(如星体与起重机吊钩)。检测环境涵盖陆地、城市、天空、海洋等复杂场景以及海天交界区域。该模型在各类红外小目标数据集上均表现出稳定的强健性能。

图12. 不同数据集上的可视化结果示例,涵盖复杂成像背景:(a∼d) 反无人机数据集;(e∼h) SIRST数据集。
如图12(a)和(d)所示,该模型成功在复杂工业环境中检测并追踪运动目标,此类场景中目标运动与背景杂波会形成显著的检测挑战。图12(a)的检测效果尤为突出,模型在金属结构林立、易产生误报的复杂工业场景中准确识别出了目标。此外,图12(f)和(h)展示了模型在极低信噪比条件下的检测能力,该场景中浓云干扰与大气效应严重降低了目标可见度。图12(f)取得了特别令人印象深刻的结果——即便存在强烈云层干扰,仍能精确检测出微小目标。实验结果证明ISTD-DETR在低信噪比、动态目标等极端条件下具有鲁棒性能。
这些示例代表了两组数据集中广泛测试案例的一小部分,这些数据集包含大量动态目标和低信噪比场景的实例。在这些极具挑战性的条件下持续保持的高性能,验证了ISTD-DETR对极端操作环境的鲁棒性和适应性。图12(b)和©展示了该模型在多变云层天空背景下检测远距离目标的能力。在SIRST数据集示例中(图12(e–h)),该模型展现出对不同环境条件的卓越适应能力。
4.5.2. 实验结果对比可视化
所提出的ISTD-DETR算法使用五幅红外小目标图像与主流方法进行了对比测试。如图13所示,第一行展示了一个复杂的工业环境场景;第二行呈现了存在严重云层干扰和背景强度变化的挑战性场景;第三行显示了云层覆盖下的城市工业环境;第四行展示了大气条件恶劣且目标对比度低的场景;第五行则呈现了目标尺寸极小且背景纹理复杂的案例。
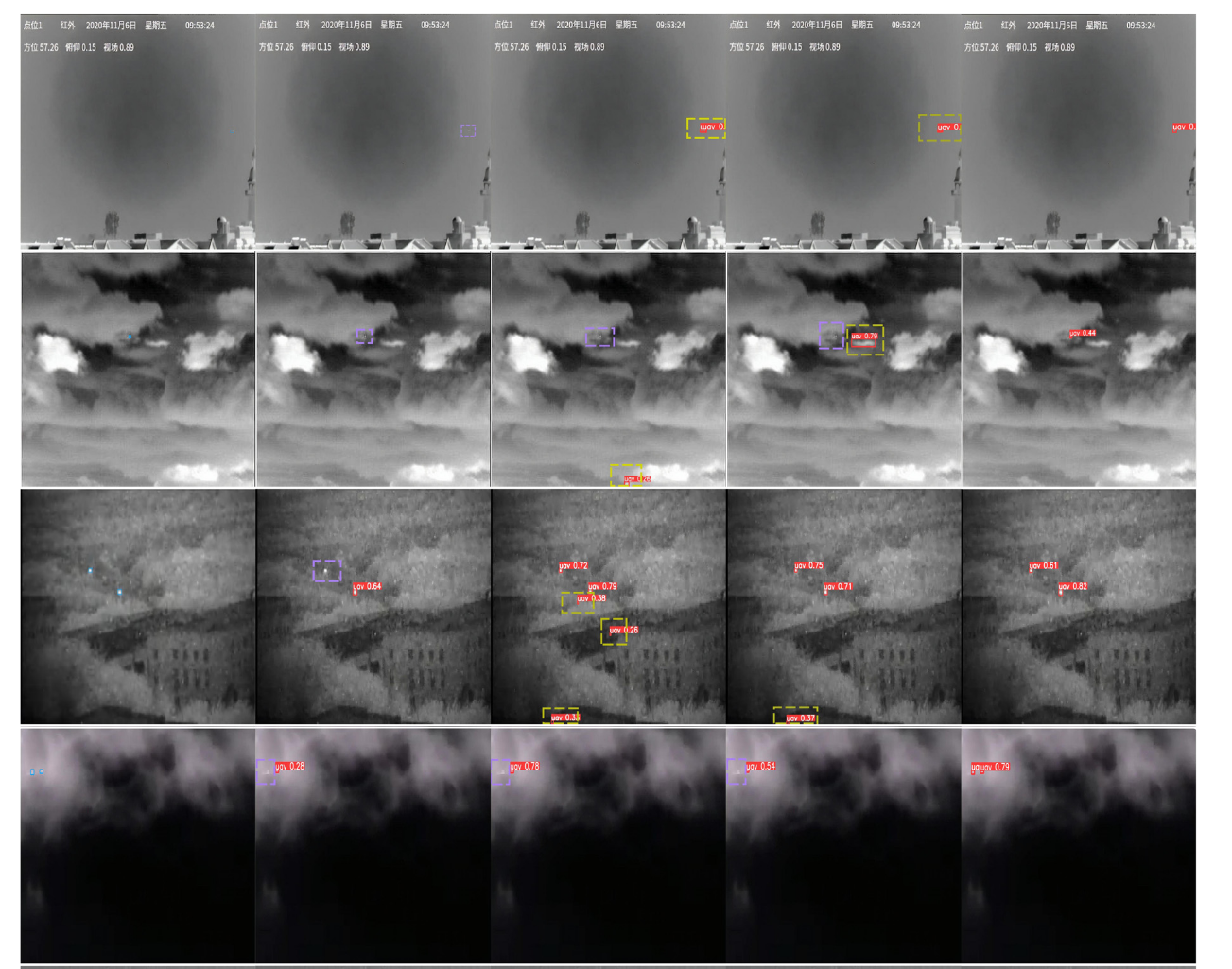

图13. 五种实时检测结果的可视化对比,每列代表不同算法或真实标注的检测结果。从左至右展示的典型案例如下:(a) 真实标注;(b) SSD算法;© YOLOv9算法;(d) RT-DETR算法;(e) ISTD-DETR算法。图中目标预测框以红色实线框标注,漏检目标用紫色虚线框标示,误检目标以黄色虚线框标出。
在这些情况下,SSD模型表现最差。它在复杂场景中频繁产生大量漏检,尤其在工业环境中难以准确区分目标与背景结构。当面临强云层干扰或小目标时,其检测可靠性显著下降,常导致完全检测失败。尽管YOLOv9相较SSD有明显改进,但仍存在显著局限。虽然能检测更多目标,但在处理复杂背景(特别是具有相似红外特征区域)时会产生大量误报。该模型在多目标场景下的检测一致性也有待提升。RT-DETR展现出良好的检测能力,但仍有改进空间。该模型偶现目标定位偏差,且对不同目标的置信度评分存在波动。
这些模型在复杂条件下难以保持准确性,尤其是当红外图像引入噪声和背景干扰时。然而,ISTD-DETR在此类场景中表现卓越,能够针对不同尺寸和方向的目标持续提供精确检测。如图13所示,ISTD-DETR的增强检测能力显而易见——相较于其他方法,其置信度更高且定位显著更优。该模型通过改进的特征提取和上下文理解能力,可有效区分真实目标与背景干扰(如星空或碎片等虚假信号)。此外,其注意力机制能精准聚焦关键区域,确保即使在杂乱场景中也能以高置信度检测微小目标。
4.5.3 注意力热图可视化实验
为展示ISTD-DETR在小目标检测中的有效性,本研究通过生成注意力热力图对输出特征图的聚焦区域进行可视化。图14结果表明,该模型具有持续聚焦红外小目标注意力的能力,即便在复杂环境和各类干扰因素存在的情况下,图中四种案例均证明ISTD-DETR能有效将注意力分配至微小暗淡目标,确保其在挑战性条件下的稳定检测。热力图清晰表明,SPD-Conv与EDSR预处理技术结合EMA注意力机制,显著提升了关键目标特征的提取能力,同时有效抑制无关背景信息。这种聚焦式注意力机制增强了ISTD-DETR在复杂红外场景中的检测性能,大幅降低误检与漏检率,充分体现了其卓越的准确性与鲁棒性。

图14. ISTD-DETR的四种归一化热力图案例。图中红色区域标示了网络模型在图像类型预测过程中的注意力聚焦区域。颜色深浅反映注意力集中程度,色调越深表示关注度越高。
4.6. 注意力机制的补充实验
为探究骨干网络中使用的EMA注意力模块对模型性能的影响,我们在SIRST数据集上进行了不同注意力机制的对比实验。表5汇总了ISTD-DETR框架下EMA、CBAM、SE和CA模块的性能对比分析。在mAP@0.5指标上,采用EMA模块的模型较CBAM、SE和CA分别高出1.6%、0.8%和0.3%;在mAP@0.5:0.95指标上,EMA模块的结果较三者分别领先1.2%、0.9%和0.5%。此外,引入EMA模块仅使模型整体计算量增加1.9 GFLOPS,这对模型轻量化具有显著优势。
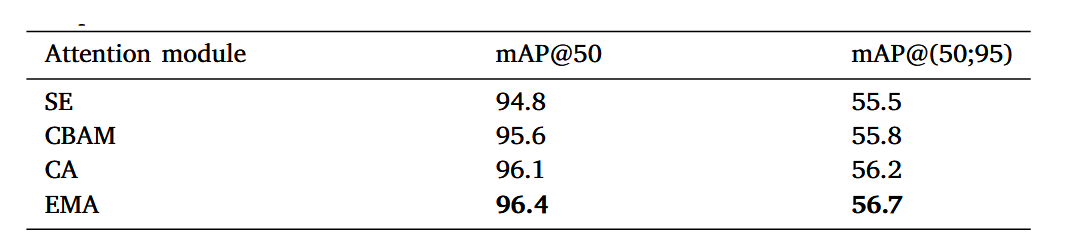
表5 不同注意力模块的对比结果。
结果表明,EMA能够最优地平衡全局与局部特征的提取,从而增强模型对前景的关注度。通过高效管理跨尺度特征表示,EMA确保在不显著增加计算负担的前提下捕获关键细节。该表格展示了EMA的卓越性能如何转化为精度和速度的显著提升。这些发现验证了选择EMA作为最有效注意力模块的合理性,其在性能与复杂度之间实现了最佳平衡。
5.结论与未来工作
本文介绍了一种创新的深度学习方法,用于检测单帧图像中的小型红外目标。首先采用EDSR超分辨率技术进行数据预处理以提升图像分辨率,同时运用多种数据增强策略来扩充和强化训练数据集。随后在RT-DETR框架基础上提出了一种先进的红外小目标检测网络ISTD-DETR:该网络通过引入状态空间模型优化主干网络,对输出特征图应用EMA注意力机制,并在CCFM结构中整合了浅层特征图S2与连接的微目标编码器头模块,以及在颈部的小目标增强模块SPD-EMA。
实验结果表明,通过策略性地提升红外图像质量并设计深度学习模型,所提方法在Anti-UAV数据集上实现了96.2%的mAP@0.5准确率,在SIRST数据集上取得94.8%的准确率及94%的召回率。在两个小型红外目标数据集的对比测试中,所有结果均超越现有最优方法(SOTA)。第4章节的图表数据印证了ISTD-DETR框架的有效性——不仅在原始准确度方面,更体现在对注意力机制管理、特征融合以及多样化复杂环境下的检测性能上。详细分析表明,ISTD-DETR的设计策略(包括注意力机制、SPD-EMA模块和多尺度融合技术)显著提升了其在红外小目标检测任务中的性能表现。
未来研究将主要探索两个方向:一是红外与可见光图像的融合,以实现全天候条件下的精准多模态检测;二是深入研究超分辨率增强技术,显著提升图像质量,从而使模型能够以更高精度检测目标。
6.引用文献
- [1] Q. Hou, Z. Wang, F. Tan, Y. Zhao, H. Zheng, W. Zhang, RISTDnet: Robust infrared small target detection network, IEEE Geosci. Remote Sens. Lett. 19 (2021) 1–5.
- [2] C.P. Chen, H. Li, Y. Wei, T. Xia, Y.Y. Tang, A local contrast method for small infrared target detection, IEEE Trans. Geosci. Remote Sens. 52 (1) (2013) 574–581.
- [3] M. Ju, J. Luo, G. Liu, H. Luo, ISTDet: An efficient end-to-end neural network for infrared small target detection, Infrared Phys. Technol. 114 (2021) 103659.
- [4] Z. Feng, X. Zhang, L. Yuan, J. Wang, Infrared target detection and location for visual surveillance using fusion scheme of visible and infrared images, Math. Probl. Eng. 2013 (1) (2013) 720979.
- [5] S. Wang, Y. Du, S. Zhao, L. Gan, Multi-scale infrared military target detection based on 3X-FPN feature fusion network, IEEE Access (2023).
- [6] X. Dai, X. Yuan, X. Wei, TIRNet: Object detection in thermal infrared images for autonomous driving, Appl. Intell. 51 (3) (2021) 1244–1261.
- [7] Y. Qin, B. Li, Effective infrared small target detection utilizing a novel local contrast method, IEEE Geosci. Remote Sens. Lett. 13 (12) (2016) 1890–1894.
- [8] R. Kou, C. Wang, Y. Yu, Z. Peng, M. Yang, F. Huang, Q. Fu, LWIRSTNet: Lightweight infrared small target segmentation network and application deployment, IEEE Trans. Geosci. Remote Sens. (2023).
- [9] J. Lin, X. Ping, D. Ma, Small target detection method in drift-scanning image based on DBT, Infrared Laser Eng. 42 (12) (2013) 3440–3446.
- [10] L. He, L. Xie, T. Xie, H. Pan, Y. Zheng, An effective TBD algorithm for the detection of infrared dim-small moving target in the sky scene, in: Multimedia and Signal Processing: Second International Conference, CMSP 2012, Shanghai, China, December 7-9, 2012. Proceedings, Springer, 2012, pp. 249–260.
- [11] N. Jiang, K. Wang, X. Peng, X. Yu, Q. Wang, J. Xing, G. Li, J. Zhao, G. Guo, Z. Han, Anti-UAV: A large multi-modal benchmark for UAV tracking, 2021, arXiv preprint arXiv:2101.08466.
- [12] Y. Dai, Y. Wu, F. Zhou, K. Barnard, Asymmetric contextual modulation for infrared small target detection, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 950–959.
- [13] X. Wu, D. Hong, J. Chanussot, UIU-Net: U-Net in U-Net for infrared small object detection, IEEE Trans. Image Process. 32 (2022) 364–376.
- [14] C. Jiang, H. Ren, X. Ye, J. Zhu, H. Zeng, Y. Nan, M. Sun, X. Ren, H. Huo, Object detection from UAV thermal infrared images and videos using YOLO models, Int. J. Appl. Earth Obs. Geoinf. 112 (2022) 102912.
- [15] R. Kou, C. Wang, Z. Peng, Z. Zhao, Y. Chen, J. Han, F. Huang, Y. Yu, Q. Fu, Infrared small target segmentation networks: A survey, Pattern Recognit. 143 (2023) 109788.
- [16] J. Zhou, B. Zhang, X. Yuan, C. Lian, L. Ji, Q. Zhang, J. Yue, YOLO-CIR: The network based on YOLO and ConvNeXt for infrared object detection, Infrared Phys. Technol. 131 (2023) 104703.
- [17] T.-W. Bae, F. Zhang, I.-S. Kweon, Edge directional 2D LMS filter for infrared small target detection, Infrared Phys. Technol. 55 (1) (2012) 137–145.
- [18] Y. Dai, Y. Wu, F. Zhou, K. Barnard, Attentional local contrast networks for infrared small target detection, IEEE Trans. Geosci. Remote Sens. 59 (11) (2021) 9813–9824.
- [19] B. Li, C. Xiao, L. Wang, Y. Wang, Z. Lin, M. Li, W. An, Y. Guo, Dense nested attention network for infrared small target detection, IEEE Trans. Image Process. 32 (2022) 1745–1758.
- [20] N. Zeng, P. Wu, Y. Zhang, H. Li, J. Mao, Z. Wang, DPMSN: A dual-pathway multiscale network for image forgery detection, IEEE Trans. Ind. Inform. (2024).
- [21] N. Zeng, X. Li, P. Wu, H. Li, X. Luo, A novel tensor decomposition-based efficient detector for low-altitude aerial objects with knowledge distillation scheme, IEEE/CAA J. Autom. Sin. 11 (2) (2024) 487–501.
- [22] Z. Zhong, Z.Q. Lin, R. Bidart, X. Hu, I.B. Daya, Z. Li, W.-S. Zheng, J. Li, A. Wong, Squeeze-and-attention networks for semantic segmentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13065–13074.
- [23] K. Zhang, R. Zhou, J. Wang, Y. Xiao, X. Guo, C. Shi, Transmission line component defect detection based on UAV patrol images: A self-supervised HC-ViT method, IEEE Trans. Syst. Man Cybern.: Syst. (2024).
- [24] K. Han, A. Xiao, E. Wu, J. Guo, C. Xu, Y. Wang, Transformer in transformer, Adv. Neural Inf. Process. Syst. 34 (2021) 15908–15919.
- [25] X. Pei, T. Huang, C. Xu, Efficientvmamba: Atrous selective scan for light weight visual mamba, 2024, arXiv preprint arXiv:2403.09977.
- [26] M. Zhao, W. Li, L. Li, J. Hu, P. Ma, R. Tao, Single-frame infrared small-target detection: A survey, IEEE Geosci. Remote Sens. Mag. 10 (2) (2022) 87–119.
- [27] J. Peng, W. Zhou, Infrared background suppression for segmenting and detecting small target, Acta Electron. Sin. 27 (12) (1999) 47–51.
- [28] T.-W. Bae, K.-I. Sohng, Small target detection using bilateral filter based on edge component, J. Infrared Millim. Terahertz Waves 31 (2010) 735–743.
- [29] Z. Li, J. Chen, Q. Hou, H. Fu, Z. Dai, G. Jin, R. Li, C. Liu, Sparse representation for infrared dim target detection via a discriminative over-complete dictionary learned online, Sensors 14 (6) (2014) 9451–9470.
- [30] S.S. Rawat, S.K. Verma, Y. Kumar, Review on recent development in infrared small target detection algorithms, Procedia Comput. Sci. 167 (2020) 2496–2505.
- [31] T.-W. Bae, Small target detection using bilateral filter and temporal cross product in infrared images, Infrared Phys. Technol. 54 (5) (2011) 403–411.
- [32] M. Zhao, L. Cheng, X. Yang, P. Feng, L. Liu, N. Wu, TBC-Net: A real-time detector for infrared small target detection using semantic constraint, 2019, URL: https://arxiv.org/abs/2001.05852. arXiv:2001.05852.
- [33] H. Wang, L. Zhou, L. Wang, Miss detection vs. false alarm: Adversarial learning for small object segmentation in infrared images, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 8509–8518.
- [34] B. Zhao, C. Wang, Q. Fu, Z. Han, A novel pattern for infrared small target detection with generative adversarial network, IEEE Trans. Geosci. Remote Sens. 59 (5) (2020) 4481–4492. [35] J. Liu, Y. Zhao, Y. Feng, Y. Hu, X. Ma, Semalbert: Semantic-based malware detection with bidirectional encoder representations from transformers, J. Inf. Secur. Appl. 80 (2024) 103690.
- [36] H. Huang, H. Zhou, X. Yang, L. Zhang, L. Qi, A.-Y. Zang, Faster R-CNN for marine organisms detection and recognition using data augmentation, Neurocomputing 337 (2019) 372–384.
- [37] D. Yi, J. Su, W.-H. Chen, Probabilistic faster R-CNN with stochastic region proposing: Towards object detection and recognition in remote sensing imagery, Neurocomputing 459 (2021) 290–301.
- [38] H. Yang, J. Wang, J. Wang, Efficient detection of forest fire smoke in UAV aerial imagery based on an improved Yolov5 model and transfer learning, Remote Sens. 15 (23) (2023).
- [39] W.-Y. Hsu, W.-Y. Lin, Ratio-and-scale-aware YOLO for pedestrian detection, IEEE Trans. Image Process. 30 (2020) 934–947.
- [40] Z. Huang, J. Wang, X. Fu, T. Yu, Y. Guo, R. Wang, DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for object detection, Inform. Sci. 522 (2020) 241–258. [41] W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.-Y. Fu, A.C. Berg, Ssd: Single shot multibox detector, in: Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, the Netherlands, October 11–14, 2016, Proceedings, Part I 14, Springer, 2016, pp. 21–37.
- [42] L. Wang, X. Wang, B. Li, Data-driven model SSD-BSP for multi-target coal-gangue detection, Measurement 219 (2023) 113244.
- [43] K. Zhang, W. Lou, J. Wang, R. Zhou, X. Guo, Y. Xiao, C. Shi, Z. Zhao, PADETR: End-to-end visually indistinguishable bolt defects detection method based on transmission line knowledge reasoning, IEEE Trans. Instrum. Meas. 72 (2023) 1–14.
- [44] M. Liu, H. Du, Y. Zhao, L. Dong, M. Hui, S. Wang, Image small target detection based on deep learning with SNR controlled sample generation, Curr. Trends Comput. Sci. Mech. Autom. 1 (211–220) (2017) 1–2.
- [45] H. Lv, D. Jing, W. Zhan, Research on infrared image target detection technology based on YOLOv3 and computer vision, in: Journal of Physics: Conference Series, vol. 2033, IOP Publishing, 2021, 012142.
- [46] S.A. Manssor, S. Sun, M. Abdalmajed, S. Ali, Real-time human detection in thermal infrared imaging at night using enhanced Tiny-yolov3 network, J. Real-Time Image Process. 19 (2) (2022) 261–274.
- [47] H. Zhao, Z. Liang, D. Cai, Y. Wang, An improved method for infrared vehicle and pedestrian detection based on YOLOv5s, in: 2022 International Conference on Machine Learning, Cloud Computing and Intelligent Mining, MLCCIM, IEEE, 2022, pp. 377–383.
- [48] X. Zhou, L. Jiang, C. Hu, S. Lei, T. Zhang, X. Mou, YOLO-SASE: an improved YOLO algorithm for the small targets detection in complex backgrounds, Sensors 22 (12) (2022) 4600.
- [49] R. Li, Y. Shen, YOLOSR-IST: A deep learning method for small target detection in infrared remote sensing images based on super-resolution and YOLO, Signal Process. 208 (2023) 108962.
- [50] Y. Zhao, W. Lv, S. Xu, J. Wei, G. Wang, Q. Dang, Y. Liu, J. Chen, Detrs beat yolos on real-time object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 16965–16974.
- [51] X. Zhu, W. Su, L. Lu, B. Li, X. Wang, J. Dai, Deformable detr: Deformable transformers for end-to-end object detection, 2020, arXiv preprint arXiv:2010. 04159.
- [52] Q. Chen, X. Chen, J. Wang, S. Zhang, K. Yao, H. Feng, J. Han, E. Ding, G. Zeng, J. Wang, Group detr: Fast detr training with group-wise one-to-many assignment, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 6633–6642.
- [53] S. Liu, F. Li, H. Zhang, X. Yang, X. Qi, H. Su, J. Zhu, L. Zhang, Dab-detr: Dynamic anchor boxes are better queries for detr, 2022, arXiv preprint arXiv:2201.12329.
- [54] F. Li, H. Zhang, S. Liu, J. Guo, L.M. Ni, L. Zhang, Dn-detr: Accelerate detr training by introducing query denoising, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 13619–13627.
- [55] H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L.M. Ni, H.-Y. Shum, Dino: Detr with improved denoising anchor boxes for end-to-end object detection, 2022, arXiv preprint arXiv:2203.03605.
- [56] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, B. Guo, Swin transformer: Hierarchical vision transformer using shifted windows, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10012–10022.
- [57] L. Zhu, B. Liao, Q. Zhang, X. Wang, W. Liu, X. Wang, Vision mamba: Efficient visual representation learning with bidirectional state space model, 2024, arXiv preprint arXiv:2401.09417.
- [58] J. Liu, H. Yang, H.-Y. Zhou, Y. Xi, L. Yu, C. Li, Y. Liang, G. Shi, Y. Yu, S. Zhang, et al., Swin-umamba: Mamba-based unet with imagenet-based pretraining, in: International Conference on Medical Image Computing and Computer-Assisted Intervention, Springer, 2024, pp. 615–625.
- [59] Z. Wang, J.-Q. Zheng, Y. Zhang, G. Cui, L. Li, Mamba-unet: Unet-like pure visual mamba for medical image segmentation, 2024, arXiv preprint arXiv:2402.05079.
- [60] S. Woo, J. Park, J.-Y. Lee, I.S. Kweon, Cbam: Convolutional block attention module, in: Proceedings of the European Conference on Computer Vision, ECCV, 2018, pp. 3–19.
- [61] Q. Wang, B. Wu, P. Zhu, P. Li, W. Zuo, Q. Hu, ECA-Net: Efficient channel attention for deep convolutional neural networks, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 11534–11542.
- [62] Q. Hou, D. Zhou, J. Feng, Coordinate attention for efficient mobile network design, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 13713–13722.
- [63] D. Ouyang, S. He, G. Zhang, M. Luo, H. Guo, J. Zhan, Z. Huang, Efficient multiscale attention module with cross-spatial learning, in: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing, ICASSP, IEEE, 2023, pp. 1–5.
- [64] B. Lim, S. Son, H. Kim, S. Nah, K. Mu Lee, Enhanced deep residual networks for single image super-resolution, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, 2017, pp. 136–144.
- [65] C. Ledig, L. Theis, F. Huszár, J. Caballero, A. Cunningham, A. Acosta, A. Aitken, A. Tejani, J. Totz, Z. Wang, et al., Photo-realistic single image super-resolution using a generative adversarial network, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4681–4690.
- [66] R. Sunkara, T. Luo, No more strided convolutions or pooling: A new CNN building block for low-resolution images and small objects, in: Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Springer, 2022, pp. 443–459.