🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中一起航行,共同成长,探索技术的无限可能。
🚀 探索专栏:学步_技术的首页 —— 持续学习,不断进步,让学习成为我们共同的习惯,让总结成为我们前进的动力。
🔍 技术导航:
- 人工智能:深入探讨人工智能领域核心技术。
- 自动驾驶:分享自动驾驶领域核心技术和实战经验。
- 环境配置:分享Linux环境下相关技术领域环境配置所遇到的问题解决经验。
- 图像生成:分享图像生成领域核心技术和实战经验。
- 虚拟现实技术:分享虚拟现实技术领域核心技术和实战经验。
🌈 非常期待在这个数字世界里与您相遇,一起学习、探讨、成长。不要忘了订阅本专栏,让我们的技术之旅不再孤单!
💖💖💖 ✨✨ 欢迎关注和订阅,一起开启技术探索之旅! ✨✨
1. 背景介绍
Ye J, Lin H, Ou L, et al. Where am I? Cross-View Geo-localization with Natural Language Descriptions[J]. arXiv preprint arXiv:2412.17007, 2024.
🚀以上学术论文翻译由ChatGPT辅助。
跨视角地理定位(Cross-view Geo-localization)旨在通过匹配街景图像与带有地理标签的卫星图像或开放街图(OSM)来确定街景图像的位置。然而,当前大多数研究集中在图像到图像的检索任务上,较少关注文本引导的检索,而后者对于如行人导航、紧急响应等应用场景具有重要意义。
在本研究中,我们引入了一个新的跨视角地理定位任务 —— 基于自然语言描述的跨视角检索,其目标是根据场景文本描述,在卫星图像或 OSM 数据库中检索对应的位置图像。为支持该任务,我们构建了 CVG-Text 数据集:从多个城市收集跨视角图像数据,并通过一种结合大规模多模态模型(Large Multimodal Models, LMMs)标注能力的场景文本生成方法,自动生成包含定位细节的高质量自然语言场景描述。
此外,我们提出了一种新的基于文本的地理检索方法 —— Cross-Text2Loc,其在检索准确率方面提升了 10%,并展现出优越的长文本匹配能力。在可解释性方面,该方法不仅提供相似度得分,还能生成“检索原因”,提升了模型决策过程的透明度。
更多信息可访问项目主页:https://yejy53.github.io/CVG-Text/。
对地面图像进行准确定位对于诸多实际应用至关重要,例如行人导航 [37]、移动机器人定位 [33],以及在城市密集区域中修正GPS噪声 [39]。传统的定位方法通常依赖于3D点云定位 [16, 26] 或基于GPS标签的卫星图像进行跨视角检索 [10, 45, 46]。然而,当前大多数研究聚焦于图像对3D数据或图像对图像的匹配。近年来,一种新兴的基于自然语言文本进行定位的方法逐渐受到关注,该方法在许多实际场景中具有显著价值 [37, 41, 42]。如图1所示,出租车司机可能通过乘客的口头描述判断其位置 [20],或行人在拨打紧急电话时用自然语言描述自己的位置 [7]。
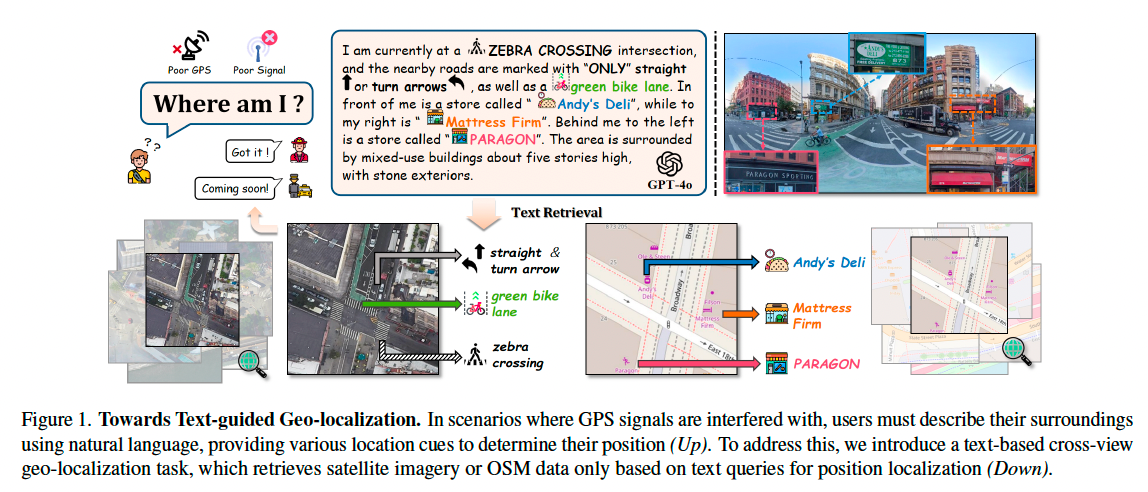
近期自然语言定位方法,如 Text2Pose [20] 与 Text2Loc [42],主要将语言描述用于在点云中定位特定位置。然而,在全球范围内构建3D地图(如使用激光雷达或摄影测量)成本高昂 [1, 13, 28],且3D地图的存储需求极高,常需借助昂贵的云基础设施,不适用于移动设备。而采用开放街图(OSM)或卫星图像的跨视角检索范式 [43, 46, 54],尽管定位精度较为粗略,但在覆盖范围与存储效率方面具有明显优势,足以满足大多数任务需求。
因此,本文提出一个新的跨视角地理定位任务 —— 使用自然语言描述检索匹配的OSM或卫星图像以完成定位。
为应对该任务的挑战,我们认为需要构建一个具备以下特点的数据集:
- 包含基础的跨视角数据(街景图、OSM 和卫星图)。
- 包含可模拟人类用户描述街景的文本数据,并具备高质量的定位信息。
随着大规模多模态模型(LMMs)的发展,利用其能力进行自动化文本标注成为一种可行解决方案 [4, 8, 14]。然而,LMM生成的文本可能存在表述模糊或幻觉等问题 [15, 32]。为此,我们构建了 CVG-Text 数据集。我们从纽约、布里斯班和东京三个城市的三万多个地点采集街景图像,并基于地理坐标获取匹配的OSM与卫星图像。接着,我们设计了一种渐进式文本描述框架,核心使用 GPT-4o [29],结合 OCR [27] 与开放世界图像分割技术 [30, 51],以生成包含丰富定位信息且减少表述模糊性的高质量场景文本。
尽管上述构造的文本能够提供用户视角的街景描述,但与卫星图像或OSM存在显著的领域差距。同时,为充分捕捉场景细节,生成的文本通常较长,超过了许多图文检索模型的文本编码长度限制。
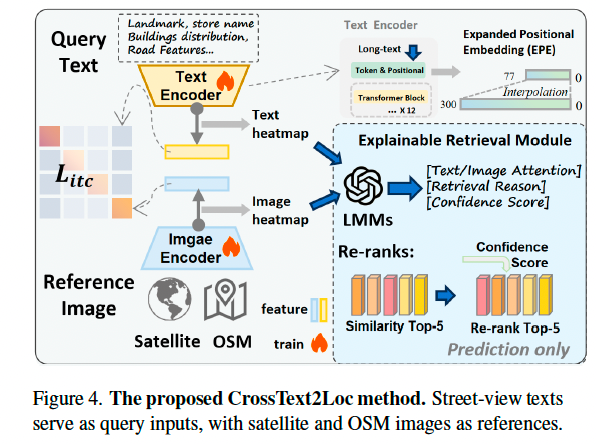
为解决这一问题,我们提出了新的文本驱动跨视角定位方法 —— CrossText2Loc。该方法包括一个 长度扩展文本编码模块(Extended Embedding),充分利用长文本中的复杂信息,并通过对比学习策略,学习跨模态匹配特征。同时引入 可解释检索模块(Explainable Retrieval Module, ERM),不仅提供相似度分数,还能生成自然语言的检索解释,克服了传统方法仅给出相似度缺乏可解释性的问题。
我们在该新任务上评估了主流图文检索方法与我们的 CrossText2Loc,实验结果表明该方法在召回率与可解释性方面均具有显著优势。
我们的主要贡献包括:
- 提出并形式化了基于自然语言描述的跨视角地理定位任务,通过场景文本描述检索对应的OSM或卫星图像以实现定位;
- 构建了CVG-Text数据集,涵盖三个城市三万多个位置的街景图、卫星图、OSM及文本描述,并提出了基于LMM的渐进式文本生成框架,有效提升了文本质量;
- 提出了CrossText2Loc方法,能够有效处理长文本并具备良好的可解释性,在Top-1召回率方面相比现有方法提升超过10%,并能提供超越相似度得分的“检索理由”与置信信息。
2. 相关工作
2.1 跨视角地理定位(Cross-view Geo-localization)
跨视角地理定位旨在通过将街景图像与地理参考的卫星图像数据库或开放街图(OSM)数据库进行匹配,实现粗粒度的地理位置确定 [23, 35, 43, 46]。例如,Sample4G [10] 使用对比学习框架将街景图像特征与卫星图像特征进行匹配,从而实现高精度的卫星图像检索。
然而,现有的跨视角检索与定位任务大多聚焦于图像对图像的匹配,较少考虑自然语言的引导,而这在实际应用中存在一定的局限性。此外,当前方法通常仅提供相似度分数,缺乏对检索定位过程的置信度与可解释性支持。我们所提出的文本驱动检索定位任务,弥补了当前研究在文本引导场景定位方面的空白,并通过自然语言提供更透明、更具解释性的定位方案。
2.2 视觉语言导航与定位(Visual Language Navigation and Localization)
视觉语言导航(VLN)任务要求智能体根据自然语言指令在特定环境中进行导航 [2, 6]。以往任务主要关注在图像与自然语言基础上的决策过程。近年来,研究逐渐从“视觉语言导航”转向“视觉语言定位”的直接任务。例如,Loc4Plan [37] 和 AnyLoc [17] 强调在导航前进行视觉空间定位的必要性。
Text2Pose [20] 与 Text2Loc [42] 探索了使用自然语言在室外点云地图中定位个体位置的能力。然而,点云检索在处理大规模场景时面临存储与计算成本高昂的问题。相比之下,我们的任务是基于文本查询检索匹配的卫星图像或OSM数据,既可覆盖广阔区域,又能显著降低存储与计算开销。
2.3 基于多模态大模型的数据合成(Data Synthesis via LMMs)
近年来多模态大模型(LMMs)的飞速发展展现了其在生成高质量自然语言描述方面的强大能力 [3, 29, 36]。许多研究利用LMM进行自动化数据标注 [14],如LatteCLIP [4] 使用LMM生成文本以实现无监督CLIP模型微调。
然而,文本检索定位任务对LMM的标注能力提出了更高要求:不仅要准确识别街景图像中的定位关键细节(如店铺招牌等),还需尽量避免幻觉现象 [15, 32]。为提升文本描述的精度,我们在细粒度文本生成中融合了街景图像、OCR [27] 和开放世界分割 [30] 技术,以增强GPT的信息捕捉能力并减少幻觉。同时,我们精心设计系统提示词,引导GPT遵循“渐进式场景分析”的思维链条生成细粒度的文本描述。
2.4 多模态对齐(Multi-modality Alignment)
在本工作中,我们的任务是利用LMM合成的场景文本描述,检索匹配的卫星图像或OSM图像。这可视为文本到图像检索(text-to-image retrieval)任务的一个子任务 [9, 11, 22, 44, 47, 53]。
CLIP [31] 模型首次引入图文对比学习方法,奠定了现代文本检索任务的新范式。然而,CLIP及其衍生模型通常存在最大文本长度限制(如77个token),难以处理包含丰富细节的长场景描述文本。这会导致细粒度信息丢失,进而影响模型性能。
受 Long-CLIP [49] 等工作的启发,我们提出了一种文本拉伸机制,用于扩展模型可接受的文本长度,从而更好地适应复杂环境中长文本的检索需求。
3. CVG-Text 数据集
3.1 总览
我们提出了 CVG-Text,一个面向文本驱动场景定位任务的多模态跨视角检索定位数据集。CVG-Text 涵盖纽约、布里斯班和东京三个城市,共包含超过 30,000 个场景数据点。其中,纽约与东京的数据偏向于城市街景,而布里斯班则更体现郊区特征。每个数据点均包含对应的街景图像、OSM 数据、卫星图像及相关场景文本描述。数据集按照 5:1 的比例随机划分为训练集和测试集。更多细节见补充材料。
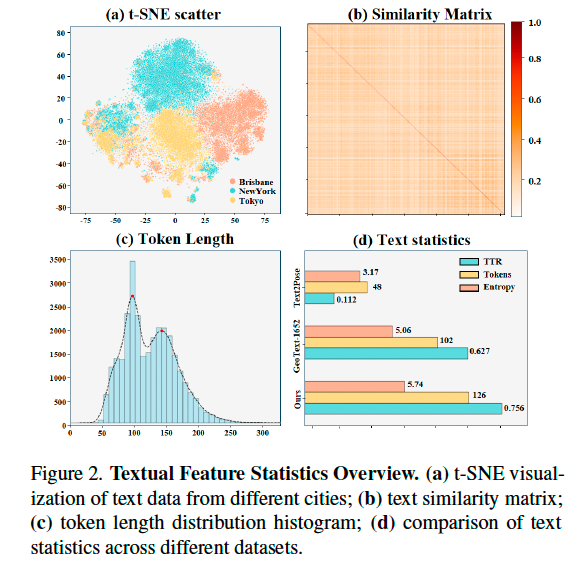
文本数据统计概览: 图 2 展示了场景文本的统计特征。t-SNE 降维可视化显示文本数据分布离散性强,反映出高多样性。同一城市的文本聚类明显,不同城市之间则表现出显著区分性,表明文本特征存在地域风格和文化特性差异。文本相似度矩阵显示整体相似度较低,进一步验证文本具备高度独立性,能够有效刻画场景并避免混淆。多模态大模型 GPT-4o 生成的平均文本长度超过 126 个 token,分布峰值在 100 与 145 之间,分别对应单视角图像与全景图像。与 Text2Pose 与 GeoText-1652 等数据集相比,CVG-Text 在词汇丰富度、token 长度与信息熵方面表现更优,显示出更高文本质量。
与现有数据集对比: 表 1 对 CVG-Text 与现有数据集进行了比较。相比 CVUSA [40] 和 VIGOR [54] 等常见的跨视角检索数据集,CVG-Text 引入了对齐的文本模态信息,支持文本驱动场景定位任务与跨模态可解释性分析。此外,CVG-Text 在数据完整性方面也表现出色,包含全景街景图像、单视角图像、航空图像与 OSM 数据。
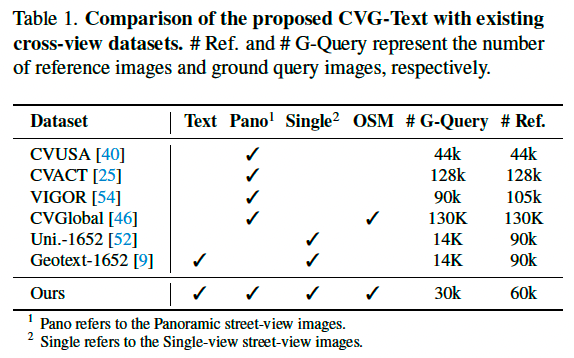
与主要用于无人机导航的 GeoText-1652 [9] 不同,后者文本描述来源于无人机图像,仅用于无人机图像检索;而我们任务面向行人、游客等用户,文本来源于街景图像,用于跨模态检索 OSM 或卫星图像,两者在任务目标与文本来源上差异显著。此外,无人机图像覆盖有限,难以支持大规模地理定位,而 OSM 与卫星图像具有更广泛的覆盖能力。
3.2 数据采集
我们通过 Google Street View 和 Google Places API 获取不同城市区域的全景与单视角街景图像。全景图像分辨率为 2048 × 1024,图像中轴线对准北方方向。单视角图像分辨率不固定,但均为高分辨率。
基于街景图像的经纬度,我们使用 Google Maps API 采集对应位置的卫星图像,图像尺寸为 512 × 512,缩放等级为 20,对应地面分辨率约为 0.12 米,图像中心对齐街景位置。
此外,我们还采集了每个区域的 OSM 数据(矢量格式),包含全球地理与地图信息。OSM 数据涵盖大量兴趣点(POI)标签,例如餐馆名称、公交站点等,对地理定位任务极具价值。我们使用 OSM 官方提供的栅格图块作为检索目标,保留所有 POI 标识。OSM 栅格图尺寸为 512 × 512,与卫星图像在像素大小和地理范围上基本一致。由于 OSM 数据持续更新,我们采集的是近年街景图像,以降低与 OSM 数据之间的时间偏差。考虑到现有数据集多为 2021 年前数据,因此我们选择从头采集而非在旧数据集上添加文本注释。
3.3 文本数据合成
图 3 展示了基于 GPT-4o 的文本生成主流程。我们首先利用 Paddle OCR 从街景图像中提取文本信息,使 GPT 更关注图像中出现的语义文本,从而减少幻觉问题。同时,我们对街景图像执行开放世界语义分割,为后续文本合成提供更丰富的语义细节与位置信息。在语义分割的辅助下,还能过滤掉如车辆等动态目标对应的 OCR 输出。
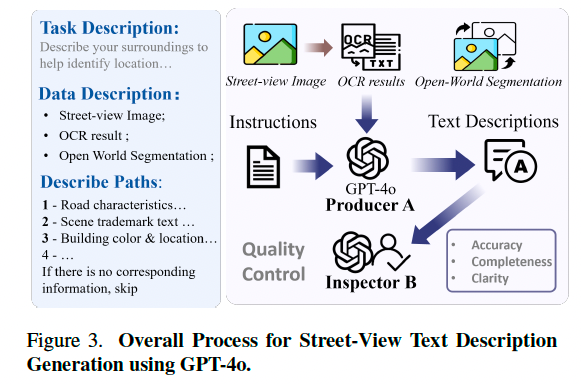
随后,我们设计了一套系统化提示词方案,用于引导 GPT-4o 生成场景文本描述。提示结构包括四部分:任务要求、输入数据介绍、描述路径、响应要求。具体而言,我们采用渐进式场景分析策略,引导 GPT 依次描述道路特征、建筑标识、整体环境(如颜色、材质、分布等)。考虑到实际用户不一定知道精确方位,文本通常使用“前/后/左/右”等自然方向表达场景关系。
质量控制方面: 首先剔除格式错误的样本,然后使用 GPT 自动复审图像与文本描述,确保准确性、一致性、内容完整性、相关性、表达清晰性与描述全面性。不合格样本将重新合成。此外,我们随机抽取了约 20%(约 6000 条)样本进行人工专家复审,由 10 位评审人员花费约 100 小时完成,人工通过率为 77.6%。
进一步地,我们基于重新训练的 CLIP 模型进行街景图像检索实验,文本到街景图像的 Top-1 召回率超过 85.5%,验证了文本描述的高质量。
4. 方法
4.1 总览
问题定义。 本文提出一种基于自然语言的跨视角地理定位新任务,其目标是利用自然语言描述从开放街图(OSM)或卫星图像中检索出对应位置的图像(这些图像通常具备位置信息)。该任务的输入是描述街景的文本 Q - T e x t Q\text{-}Text Q-Text。在实际应用中,用户通常拥有粗略位置先验(例如知道自己位于纽约市的某一城区),但不清楚精确位置。因此,检索模型会结合此类位置先验信息,将搜索范围限制为较小的区域 M M M,并从中检索候选的卫星图像集 R s a t R_{sat} Rsat 和 OSM 图像集 R O S M R_{OSM} ROSM。
模型结构。 为解决上述任务,我们提出了 CrossText2Loc 架构(见图4),其核心是通过增强型文本编码模块和对比学习损失 L i t c \mathcal{L}_{itc} Litc 实现图像与文本域的对齐,以支持高效的文本检索任务。同时,在推理过程中引入可选的可解释检索模块 ERM,以提供自然语言分析,提升模型的可解释性和用户对结果的信心。
4.2 图文对比学习
CrossText2Loc 采用双流架构,分别包含文本编码器和视觉编码器,分别用于提取文本查询与卫星图像或 OSM 图像的特征。由于文本通常描述的是街景视角,而参考图像为鸟瞰图(卫星图或 OSM),两者存在明显域差异,因此需要在训练阶段通过对比学习联合优化图像和文本编码器,从而在特征空间中实现跨模态对齐。
我们设训练批大小为 n n n,将所有全景和单视角文本编码为 t t t,所有图像编码为 v v v,通过最小化对比损失 L i t c \mathcal{L}_{itc} Litc 来训练,公式如下:
L i t c = ∑ i = 1 n ∑ j = 1 n − log exp ( sim ( v i , t j ) / τ ) ∑ k = 1 n exp ( sim ( v i , t k ) / τ ) \mathcal{L}_{itc} = \sum_{i=1}^{n} \sum_{j=1}^{n} -\log \frac{\exp(\text{sim}(v_i, t_j) / \tau)}{\sum_{k=1}^{n} \exp(\text{sim}(v_i, t_k) / \tau)} Litc=i=1∑nj=1∑n−log∑k=1nexp(sim(vi,tk)/τ)exp(sim(vi,tj)/τ)
其中, v i v_i vi 和 t j t_j tj 分别表示第 i i i 张图像和第 j j j 条文本的嵌入向量, τ \tau τ 为可学习的温度参数,用于控制 softmax 分布的平滑程度。
在本任务中,文本通常较长、语义复杂,其与图像的匹配依赖于深层语义理解而非表面词汇对齐。传统编码器(如 CLIP [31])由于位置编码长度限制,往往存在文本截断与全局表示不充分的问题。为此,我们引入扩展位置编码(Expanded Positional Embedding, EPE)机制,将文本位置编码拓展至 N = 300 N = 300 N=300 的 token 长度,并通过线性插值方式生成扩展位置编码 P ∗ P^\ast P∗,具体计算如下:
P ∗ ( x ) = ( 1 − ( x − ⌊ x ⌋ ) ) ⋅ P ( ⌊ x ⌋ ) + ( x − ⌊ x ⌋ ) ⋅ P ( ⌈ x ⌉ ) P^\ast(x) = (1 - (x - \lfloor x \rfloor)) \cdot P(\lfloor x \rfloor) + (x - \lfloor x \rfloor) \cdot P(\lceil x \rceil) P∗(x)=(1−(x−⌊x⌋))⋅P(⌊x⌋)+(x−⌊x⌋)⋅P(⌈x⌉)
其中, P ∗ ( x ) P^\ast(x) P∗(x) 为扩展后位置 x x x 的位置编码, P ( ⌊ x ⌋ ) P(\lfloor x \rfloor) P(⌊x⌋) 和 P ( ⌈ x ⌉ ) P(\lceil x \rceil) P(⌈x⌉) 分别为原始编码在向下取整与向上取整位置的值。由于我们使用 GPT 生成文本模拟用户场景,文本通常不包含需要保留位置的短标题,因此不同于 LongCLIP [49] 使用知识保持拉伸(Knowledge Preserving Stretching),我们采用完全插值策略。
4.3 可解释检索模块(ERM)
我们进一步提出可选的可解释检索模块(Explainable Retrieval Module, ERM),用于通过自然语言增强地理定位检索任务的可解释性与可信度。
注意力热力图生成。 受 [5] 启发,我们生成注意力热力图来揭示模型在检索过程中的关注区域。首先,初始化起始层 s s s 的相关性矩阵 R ( s − 1 ) R^{(s-1)} R(s−1) 为单位矩阵 I I I,然后依次处理从第 s s s 层到输出层 L L L 的每一层注意力机制。在每层中,我们累计非负梯度贡献,得到图像或文本的关注热力图 R R R,其计算公式为:
R ( l ) = R ( l − 1 ) + 1 H ∑ h = 1 H max ( 0 , ∇ A h ( l ) ⊙ A h ( l ) ) ⋅ R ( l − 1 ) R^{(l)} = R^{(l-1)} + \frac{1}{H} \sum_{h=1}^{H} \max(0, \nabla A^{(l)}_h \odot A^{(l)}_h) \cdot R^{(l-1)} R(l)=R(l−1)+H1h=1∑Hmax(0,∇Ah(l)⊙Ah(l))⋅R(l−1)
其中, A h ( l ) A^{(l)}_h Ah(l) 表示第 l l l 层第 h h h 个注意力头的权重, ∇ A h ( l ) \nabla A^{(l)}_h ∇Ah(l) 为其梯度, ⊙ \odot ⊙ 表示 Hadamard 乘积, H H H 为注意力头数量。
LMM 解释生成。 生成图文热力图后,我们将其输入 LMM(GPT-4o),通过精心设计的提示词(Prompt)引导其识别检索中模型关注的关键线索,如地标、建筑物名称等。接着,LMM 对图文中被高亮的区域进行对比与推理,输出模型为何进行此类匹配的解释(即匹配依据)。最终,LMM 还会给出检索理由的置信度,模拟用户的决策过程。LMM 不仅提供语义相似性评分,更能用自然语言解释模型行为,从而显著增强定位模型的可解释性。
置信度重排序。 基于上述解释模块产生的置信度评分,可对 Top-5 的原始相似度排名进行重排。我们设定:若 Top-1 检索结果置信度低于 0.5,则对原始相似度和置信度归一化后求和,得到新的 Top-5 排序结果。后续实验中将展示该重排序策略能有效模拟用户的选择行为,并提升召回性能。
5. 实验
5.1 实验设置
实现细节。 本文采用 OpenAI 预训练的 CLIP-L/14@336px 模型 [31] 作为主干,优化器选用 Adam [19],初始学习率设为 1 × 10 − 5 1\times10^{-5} 1×10−5,并采用 cosine 学习率衰减策略。训练批大小为 128,在四张 NVIDIA A100 GPU 上进行共 40 个 epoch 的训练。图像分辨率设为默认的 336 × 336 336 \times 336 336×336,文本最大长度为 N = 300 N = 300 N=300 个 token。温度参数 τ \tau τ 从模型 checkpoint 中初始化。
此外,考虑到实际应用中用户通常拥有粗略的位置先验(如所处城市或区域),我们在测试阶段将检索范围 M M M 设为 100,表示模型仅从用户附近约 10 km 2 10 \, \text{km}^2 10km2 区域中的 100 个候选图像中进行检索。该参数 M M M 可调,更多设定结果见补充材料。所有对比方法使用其默认最优图像分辨率设定,且统一在我们提出的数据集上训练。
评估指标。 我们采用前人工作 [10, 34] 中常用的 Top-K 图像召回率(Recall@K)作为评估指标。当某条查询文本对应的真实 OSM 或卫星图像出现在 Top-K 检索结果中时,判定为“定位成功”。此外,我们还引入了“地理定位召回率” [20, 42],即被检索结果与真实位置间的地理距离低于某一阈值的比例。
5.2 定位性能评估
我们在不同的图像源(卫星图像与 OSM 图像)下评估了多个基于文本的检索方法,结果如表 2 所示。在现有方法中,BILP 方法具有较强性能,因其不受限于文本编码长度。而我们的方法即使不引入 ERM 模块,依然在所有指标上取得最优结果。相较于基线方法 CLIP,本方法在 Recall@1 上提升了 14.1%,在 Recall@10 上提升了 14.8%,显著优于其他方案。
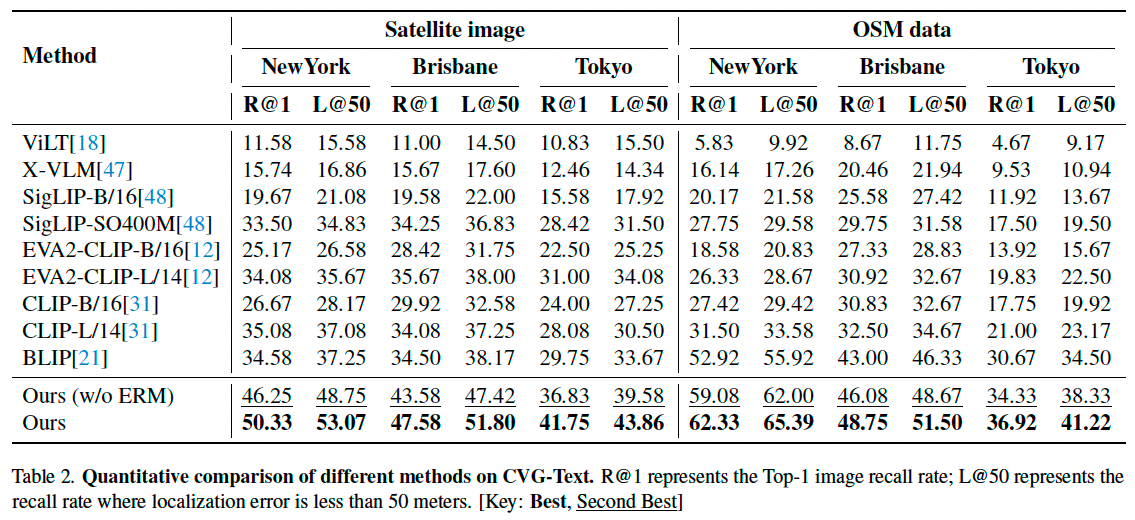
我们还评估了各方法在不同城市和不同图像数据源下的表现。在纽约,OSM 图像由于包含丰富的 POI 信息(如公交站、商铺名称),表现优于卫星图像;而在布里斯班,OSM 数据较为稀疏,因此两类图像的表现相近;在东京,由于 CLIP 模型在日语文本的预训练不足,对街景描述中的日文地名与 OSM 图像响应较弱,表现最差。更多跨城市评估与 OSM+卫星协同检索结果见补充材料。
5.3 可解释检索评估
我们在图 5 中展示了 Explainable Retrieval Module (ERM) 的可视化结果。该方法基于文本和检索图像的注意力响应生成热力图,突出模型在定位时关注的关键区域。
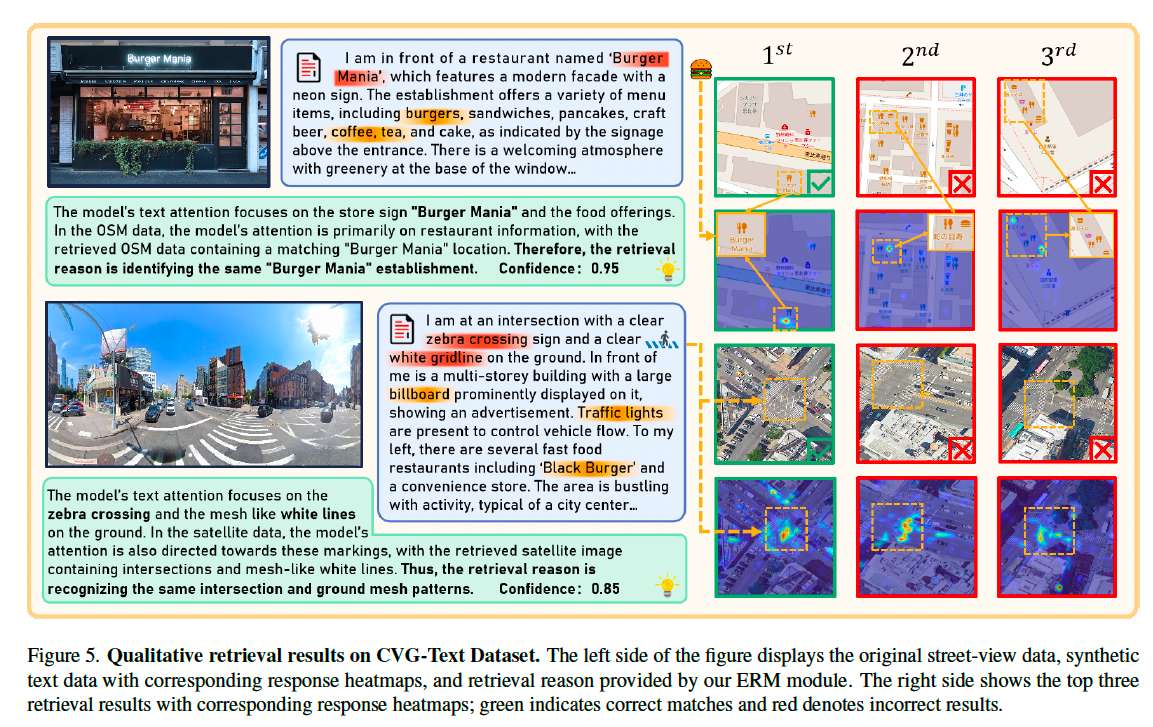
第一个示例中,模型聚焦于 “Burger Mania” 字样,即使在 Top-1 结果之外,模型仍能关注汉堡图标。第二个示例中,模型关注 “斑马线” 与 “白色栅格线”,前三个检索结果均突出了斑马线特征,最佳结果则同时命中两个线索。
我们在补充材料中提供了对 ERM 检索解释合理性的量化评估,包括与人工解释的相似度(使用 CIDEr [38] 和 ROUGE-L [24])以及多维人类打分。
此外,LMM 生成的置信度得分在一定程度上模拟了用户的信任决策过程。当检索结果相似度高但置信度低时,表明该结果虽形式匹配但缺乏说服力。此时,利用重排序策略可获得更符合人类判断的 Top-K 结果(如表 2 所示)。ERM 的实用价值在于:辅助用户理解匹配逻辑,从多个候选中选出最合理的结果,而非机械地选择相似度最高项。若模型解释不够可信,用户还可添加额外文本描述或重新排序。
我们还基于文本与参考图像生成了注意力热力图,并统计模型最关注的词语子类。最终识别出 8 个主要关注子类,如地标(LandMarker)、招牌(SignName)等,完整词类清单见补充材料。图 6 展示了不同类别在模型注意力中的得分,结果表明模型在检索中主要聚焦地标与道路信息,而对车辆、天空、天气等关注较少,强调了跨视角检索任务中的关键视觉线索。
5.4 消融实验
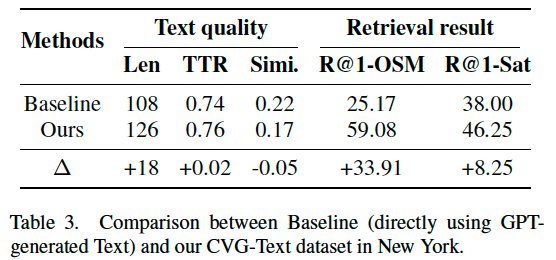
我们分析了使用 CVG-Text 生成的文本与直接由 GPT 生成文本的差异,结果如表 3 所示。CVG-Text 在文本长度与词汇复杂度(TTR)上更高,文本相似度更低,说明其质量更优。OCR 辅助模块有效捕捉街景图像中的文字细节,减少了 GPT 的虚构与模糊描述,提升了 OSM 检索效果;而开放世界分割(Open-World Segmentation)增强了 GPT 对语义与空间布局的理解能力,有助于提升卫星图像检索效果。
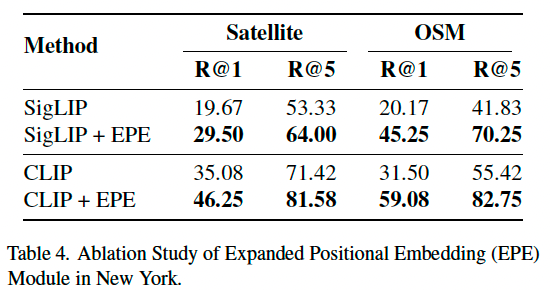
我们还在 CLIP [31] 与 SigLIP [48] 两个架构下测试了扩展位置编码(EPE)模块的有效性。如表 4 所示,EPE 模块显著提升了两种方法在卫星图像与 OSM 上的检索性能,Recall@1 分别提升了 10.5% 与 26.3%,验证了该模块在长文本处理任务中的通用性与有效性。
5.5 跨视角检索任务的进一步探索
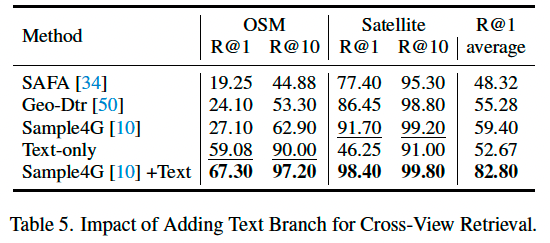
传统跨视角检索任务主要聚焦于图像对图像的匹配。我们基于 CVG-Text 数据集,将该任务扩展为图文联合检索。在最先进方法 Sample4G [10] 的基础上,添加了额外的文本查询分支,通过相似度融合方式构建联合模型。
我们在 CVG-Text 纽约区域上开展了实验,结果如表 5 所示,新增文本分支后,卫星图检索 Top-1 召回率提升 6.7%,而 OSM 图检索 Top-1 召回率提升高达 40.2%,大幅增强了检索精度。这说明文本描述与 OSM 中的 POI 数据具有高度语义一致性,使得 OSM 检索受益更多。
6. 结论
本文提出基于自然语言的跨视角地理定位新任务,并构建包含街景图、卫星图、OSM 图与文本描述对齐的 CVG-Text 数据集。我们设计了 CrossText2Loc 模型,专注于长文本检索与可解释定位任务,在多个评估指标上表现出色。
本研究不仅推动了自然语言定位任务的发展,也拓展了跨视角定位的应用场景,期待能为后续研究提供有价值的启示与创新方向。
🌟 在这篇博文的旅程中,感谢您的陪伴与阅读。如果内容对您有所启发或帮助,请不要吝啬您的点赞 👍🏻,这是对我最大的鼓励和支持。
📚 本人虽致力于提供准确且深入的技术分享,但学识有限,难免会有疏漏之处。如有不足或错误,恳请各位业界同仁在评论区留下宝贵意见,您的批评指正是我不断进步的动力!😄😄😄
💖💖💖 如果您发现这篇博文对您的研究或工作有所裨益,请不吝点赞、收藏,或分享给更多需要的朋友,让知识的力量传播得更远。
🔥🔥🔥 “Stay Hungry, Stay Foolish” —— 求知的道路永无止境,让我们保持渴望与初心,面对挑战,勇往直前。无论前路多么漫长,只要我们坚持不懈,终将抵达目的地。🌙🌙🌙
👋🏻 在此,我也邀请您加入我的技术交流社区,共同探讨、学习和成长。让我们携手并进,共创辉煌!
