传统选路策略为何难以满足AI网络需求?
在现代大规模 AI 训练集群中,网络性能的细微波动,如带宽瓶颈、毫秒级延迟增加或纳秒级抖动,都会直接转化为昂贵的算力资源浪费。特别是对于 RDMA(如 RoCEv2)流量和大规模参数同步(如 All-Reduce)操作,网络不仅需要高带宽,更需要极致的、可预测的低延迟与低抖动。
传统的网络交换设备的方案无法感知路径的实时时延与抖动,更无法针对微秒级波动动态优化,同时缺乏对链路实时带宽利用率与队列深度的感知能力,无法规避拥塞热点。
智能选路的路径质量关键影响因子
实时带宽利用率:精确测量路径上关键链路的当前可用带宽。避免将高吞吐量的AI流量(如梯度同步)引导至已接近饱和的链路,防止拥塞崩溃和PFC反压风暴。
- 队列深度/使用情况: 直接监控网络设备(交换机)出口队列的瞬时和平均深度。队列深度是拥塞的先行指标,深度过大意味着数据包排队等待时间(Bufferbloat)增加,直接导致传输延迟上升和抖动加剧,这对依赖确定性的RDMA和集合通信操作是致命的。
- 转发时延/延迟变化: 不仅测量路径的基础传播延迟,更关键的是持续监测数据包转发处理延迟及其变化(抖动)。这反映了设备本身的处理能力和当前负载状态,高或波动的处理时延会破坏AI流量的同步性。
智能选路的动态路径质量引擎
带宽利用率与队列深度这两大关键指标的采集直接依赖于网络设备的ASIC硬件级能力
| 监测指标 | 实现方式 | 精度 |
价值 |
|---|---|---|---|
| 实时带宽利用率 | 端口Byte Counter原子累加 | 百毫秒级 | 规避饱和链路拥塞崩溃 |
| 队列深度 | Queue Depth Counter硬件寄存器直读 | 亚秒级同步 | 预判Bufferbloat风险 |
| 转发时延 | INT Shim头部注入+纳秒级时间戳 |
≤10ns | 消除RDMA同步误差 |
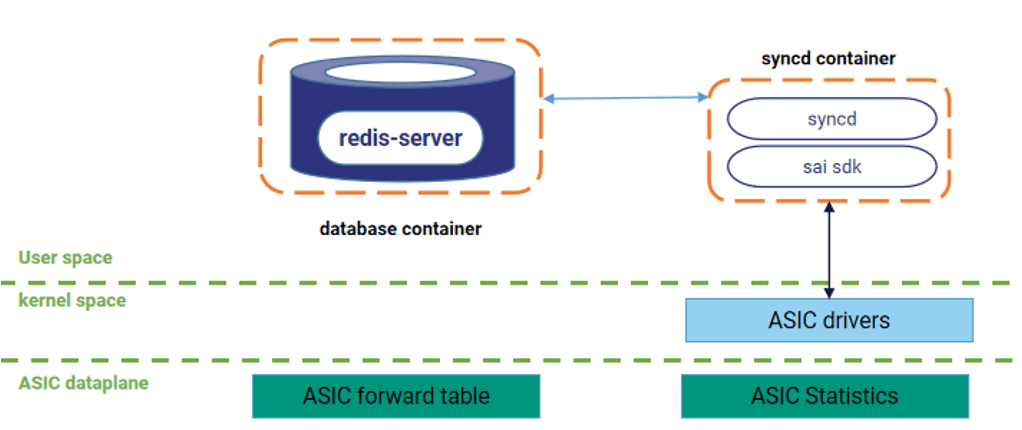
硬件级数据采集层
ASIC芯片内置的硬件寄存器持续执行线速统计,对每个端口的字节转发计数(Byte Counter) 和各优先级队列的缓存占用计数(Queue Depth Counter) 进行原子级累加。这种基于硅片级电路的计数机制摆脱了软件轮询的延迟与性能开销,可实现百毫秒级精度的数据捕获,精准反映瞬时网络拥塞状态。
动态决策层(SONiC控制面)
运行于设备控制面的SONiC网络操作系统,通过标准化的SAI(Switch Abstraction Interface)接口以亚秒级周期(通常为500ms) 主动读取ASIC寄存器的统计快照。此设计确保控制面能够近乎实时地感知转发芯片的状态变化,为动态选路提供高时效性数据输入。
 若按ASIC的亚秒级精度(如每100ms)通过BGP宣告路径质量,会导致控制面压力剧增,频繁生成和传输BGP Update消息,占用CPU和带宽资源。微秒级变化也可能触发不必要的路由更新,影响网络稳定性。所以,采用秒级间隔(例如每秒1次)向邻居发送BGP Update消息,携带加权平均后的路径质量值。路径质量通过BGP扩展社区属性(如
若按ASIC的亚秒级精度(如每100ms)通过BGP宣告路径质量,会导致控制面压力剧增,频繁生成和传输BGP Update消息,占用CPU和带宽资源。微秒级变化也可能触发不必要的路由更新,影响网络稳定性。所以,采用秒级间隔(例如每秒1次)向邻居发送BGP Update消息,携带加权平均后的路径质量值。路径质量通过BGP扩展社区属性(如Path Bandwidth Extended Community)传递,格式为浮点数(单位Gb/s)
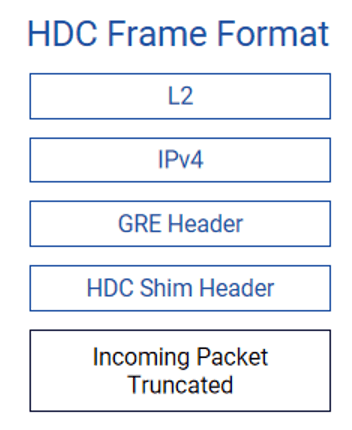
转发时延/抖动的纳秒级捕获 (INT & HDC):
HDC是INT的功能扩展,专为捕捉网络中的尾延迟(Tail Latency) 事件设计。只捕获超过用户预设阈值(如10μs)的异常延迟报文,实现靶向抓包而非全量监控。ASIC硬件实时比对报文时延与阈值——当报文在队列/缓存中的滞留时间超过阈值,立即触发抓取动作。并将原始数据包的前150字节连同INT元数据(包含出入端口、时延等关键信息)作为HDC数据包发送到收集器。
智算中心里AI RoCE交换机上的智能选路
AI RoCE 交换机的独特之处在于,它将上述高性能感知(ASIC 计数器、INT/HDC)与智能调控(实时数据处理、动态路径评分、优化 BGP 宣告)深度集成在硬件和软件架构中。
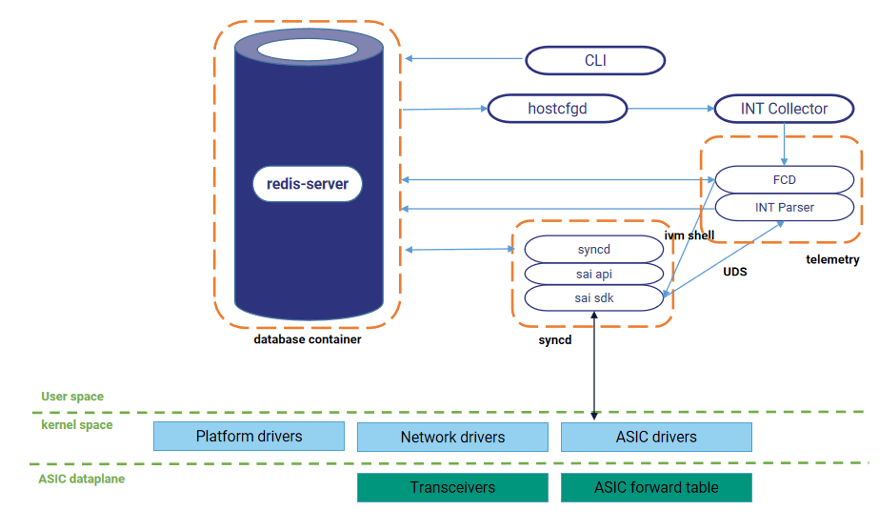
命令行配置HDC功能控制INT进程运行,之后通过socket连接进行收包循环,将收取到的报文进行解析并将关键信息(出入端口、转发时延等)写入数据库。

请关注我们,后续会持续更新更多 智能选路 相关的技术细节
【参考文档】
动态感知+智能决策,一文解读 AI 场景组网下的动态智能选路技术
BGP在数据中心的应用2——BGP如何适应数据中心网络_bgp bestpath as-path multipath-relax-CSDN博客