前言
Linux 容器的本质,是一个被隔离和限制的进程。
与虚拟机不同,容器无需虚拟化一个完整的操作系统,所以它比虚拟机更轻量级,效率也更高。
Linux 容器通过 namespaces 技术来隔离容器的视图,使得容器进程只能看到当前 namespace 内的 进程PID、网络、挂载、UTS、IPC 和用户等资源;再通过 cgroups 技术限制容器进程的例如 cpu、内存、网络带宽、磁盘 IO 等资源的使用,避免容器间资源占用的相互影响,甚至出现一个容器就耗尽所有资源的极端情况;最后,再通过 pivot_root 系统调用,改变容器进程的根文件系统,使得容器进程只能访问自身的文件系统,避免影响到宿主机。
隔离
Linux 容器的隔离,依赖的是 namespaces 技术。
unshare 是 Linux 中的一个命令,用于在新的命名空间中运行程序。为了方便,本文使用 unshare 命令来实践,而不是直接调用clone 等系统函数。
以隔离 PID 为例,直接带上--pid 参数即可:
> unshare --pid --mount --fork bash
> ps
PID TTY TIME CMD
501089 pts/2 00:00:00 bash
501100 pts/2 00:00:00 unshare
501101 pts/2 00:00:00 bash
501108 pts/2 00:00:00 ps
新的 bash 终端运行在新的 namespace 中,且隔离了 mount 和 pid。但此时ps 命令返回的进程依然和宿主机中是一样的,pid 隔离看似没有生效,因为 ps 命令是依靠读取/proc** 文件系统来工作的**。
重新挂载 /proc,再次执行 ps 会发现,进程看到的是一个全新的 PID 视图,当前 bash 是1号进程,而 ps 是10号进程。
> mount -t proc proc /proc
> ps
PID TTY TIME CMD
1 pts/2 00:00:00 bash
10 pts/2 00:00:00 ps
--mount-proc 参数支持在新的命名空间中挂载独立的 /proc 文件系统,上面的命令可以简化为:
> unshare --mount --mount-proc --pid --fork bash
> ps
PID TTY TIME CMD
1 pts/3 00:00:00 bash
8 pts/3 00:00:00 ps
在新的命名空间中,我们开启一个进程执行 sleep,可以看到,执行 sleep 的进程 ID 是8。
# 新的命名空间内执行
> sleep 99 &
[1] 8
> ps -ef | grep sleep
root 8 1 0 15:34 pts/1 00:00:00 sleep 99
root 13 1 0 15:35 pts/1 00:00:00 grep --color=auto sleep
在宿主机中新开一个终端,发现这个 sleep 进程ID 是 698787。
# 在宿主机中执行
> ps -ef | grep sleep
root 698787 698780 0 15:34 pts/1 00:00:00 sleep 99
root 698794 698699 0 15:35 pts/2 00:00:00 grep --color=auto sleep
这俩就是同一个进程,sleep 进程的真实进程ID是 698787,只不过在新的命名空间内,内核的 namespace 技术给进程施加了“障眼法”,让命名空间内的进程误以为 sleep 进程是 8号进程。
除了 PID 的隔离,Linux Namespaces 技术还支持 UTS、IPC、Network、Mount、User 等资源的隔离。
和虚拟化一个完整的操作系统不同,Linux Namespaces 的隔离机制存在缺陷,那就是资源“隔离的不彻底”。容器本质上和运行在宿主机上的其它进程没有本质区别,依赖的还是操作系统的内核,尽管你可以在容器里通过 Mount Namespace 单独挂载其他不同版本的操作系统文件,比如 CentOS 或者 Ubuntu,但这并不能改变容器共享宿主机内核的事实。
另外,在 Linux 中很多资源和对象,是无法被 Namespaces 隔离的,最典型的就是“时间”。如果某个容器进程修改了系统时间,那么宿主机的时间就会被修改,所有的容器读取系统时间都会受到影响,牵一发而动全身。所以,使用容器部署应用,“什么能做,什么不能做”是开发者必须要考虑的。
限制
容器的隔离技术,更多的是“障眼法”,它只是改变了容器进程看待系统的“视图”,如果不对容器加以限制,就可能出现下面这种局面:
在操作系统看来,容器进程和其它进程没有区别,它们在抢夺资源时是平等的竞争关系,如果某个容器进程直接把内存或 cpu 等资源耗尽,就会导致宿主机上的其它容器或进程无法工作,甚至整个操作系统崩溃,这显然不应该是“容器”具备的破坏力。
Linux 内核提供了 cgroups(Linux Control Group)技术,它可以限制、记录和隔离进程组的资源使用,它允许系统管理员和开发者对系统资源进行精细的控制。
cgroups 功能概览:
- 限制进程 CPU、内存、磁盘 I/O 和网络带宽等资源的使用
- 为不同的进程组分配不同的资源优先级,确保关键任务获得足够的资源
- 将进程分组,可以实现资源的隔离,防止一个进程组的资源消耗影响到其他进程组
- 监控进程组的资源使用情况,帮助进行性能分析和调优
- 动态地将进程加入或移出 cgroups,灵活管理进程的资源使用
以 CPU 资源限制为例,演示一个限制进程占用 0.5 个 CPU 核心的示例。
cgroups 通过一个特殊的虚拟文件系统来管理和操作,文件系统挂载在/sys/fs/cgroup 目录下,创建一个文件夹,内核会自动创建 cgroup 所需的文件。
> mkdir /sys/fs/cgroup/mygroup
> cd /sys/fs/cgroup/mygroup
> ls
cgroup.controllers hugetlb.2MB.events
cgroup.events hugetlb.2MB.events.local
cgroup.freeze hugetlb.2MB.max
cgroup.kill hugetlb.2MB.rsvd.current
cgroup.max.depth hugetlb.2MB.rsvd.max
cgroup.max.descendants io.max
cgroup.procs io.pressure
cgroup.stat io.prio.class
cgroup.subtree_control io.stat
cgroup.threads io.weight
cgroup.type memory.current
cpu.idle memory.events
cpu.max memory.events.local
cpu.max.burst memory.high
cpu.pressure memory.low
cpu.stat memory.max
cpu.uclamp.max memory.min
cpu.uclamp.min memory.numa_stat
cpu.weight memory.oom.group
cpu.weight.nice memory.pressure
cpuset.cpus memory.stat
cpuset.cpus.effective memory.swap.current
cpuset.cpus.partition memory.swap.events
cpuset.mems memory.swap.high
cpuset.mems.effective memory.swap.max
hugetlb.1GB.current misc.current
hugetlb.1GB.events misc.max
hugetlb.1GB.events.local pids.current
hugetlb.1GB.max pids.events
hugetlb.1GB.rsvd.current pids.max
hugetlb.1GB.rsvd.max rdma.current
hugetlb.2MB.current rdma.max
在这个子目录在,cpu.max 文件配置的就是 cpu 资源的限制,格式:<max_quota> <max_period> ,max_period 是时间周期,单位是微妙,默认是 100000μs,即 100ms。max_quota 是在这个时间周期内,进程最多可以占用 cpu 的时间,默认是 20000μs,即 20ms。默认配置,意味着进程最多可以占用 1/5 个cpu 核心。
写入我们的自定义配置,在 100ms 内进程最多使用 50ms 的 CPU,即 0.5 个核心。
> echo '50000 100000' > /sys/fs/cgroup/mygroup/cpu.max
把进程 ID 写入cgroup.procs ,交给 cgroups 管理
> echo $$ > /sys/fs/cgroup/mygroup/cgroup.procs
接着,当前进程执行死循环,尝试把 CPU 打满
> while : ; do : ; done
新开一个终端,top 命令查看,会发现死循环进程,最多占用 0.5 颗 CPU。因为笔者的服务器是2核的,所以总的 CPU 负载大约在 25%。
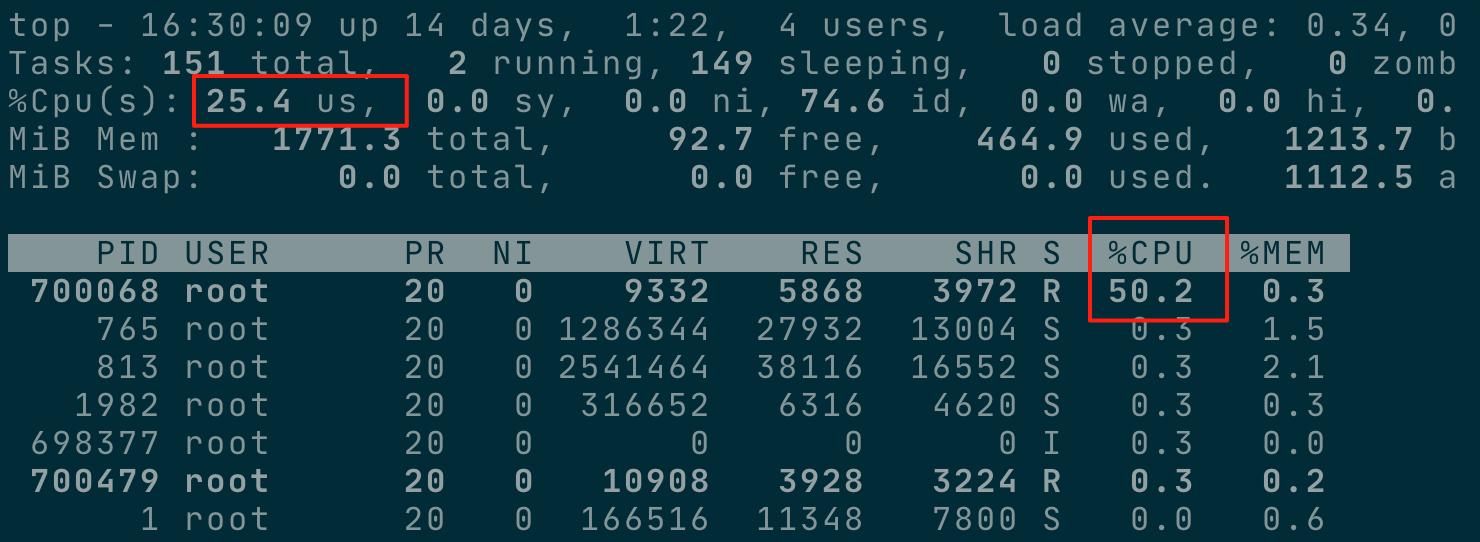
其它类型的资源限制,操作上同理。
切换根文件系统
隔离了容器进程的视图,限制了容器进程资源的占用,最后一步,就是给容器进程切换到一个全新的“根文件系统”,使得每个容器进程都有自己的根文件系统,容器可以在自己的文件系统里面任意折腾,而不会影响到宿主机和其它容器。
在这个全新的根文件系统里,包含容器运行的所有依赖库和用户应用程序,最后把这个文件系统打包,就是我们熟知的“镜像”。有了镜像,就可以一键部署应用,再也不会出现“应用在测试环境部署没问题,到线上就部署失败”的场景,解决了应用程序的环境依赖问题。
pivot_root 是 Linux 内核中的一个系统调用,主要用于改变当前进程的根文件系统。
pivot_root 使用的基本流程:
- 准备一个新的根文件系统(必须包含必要的文件和依赖库)
- 挂载到宿主机的某个目录
- 执行 pivot_root 切换当前进程的根文件系统
- cd / 切换到新的根文件系统
- 卸载旧根文件系统
pivot_root 需要 root 权限,且新根文件系统必须是一个挂载点,旧根必须挂载到新根的子目录下。
示例,/container 目录下有个镜像文件 image.tar,它是基于 BusyBox 构建的 Linux 环境,仅有 4M 大小的根文件系统。执行下面的命令,unshare 进入新的 mount 命名空间,解压文件系统到 /container/rootfs,最后 pivot_root 切换到新的根文件系统。
> unshare --mount --fork -- bash -c '
# 创建新根目录
mkdir -p /container/rootfs
# 挂载
mount -t tmpfs rootfs /container/rootfs
# 解压根文件系统到新根目录,确保新根文件系统有必要的文件
tar -xf /container/image.tar -C /container/rootfs
# 创建旧根目录
mkdir -p /container/rootfs/old_rootfs
# 切换到新根,同时挂载旧根到/container/rootfs/old_rootfs
pivot_root /container/rootfs /container/rootfs/old_rootfs
cd /
exec /bin/sh
'
新的命名空间内的进程切换根文件系统后,列出根目录下的文件,会发现和宿主机是不同的,当前文件系统任意折腾,都不会影响宿主机,确保容器有一个隔离、安全的环境。
> ls /
bin etc lib old_rootfs root tmp var
dev home lib64 proc sys usr
尾巴
Linux 容器的本质就是一个被 Namespaces 隔离视图、被 cgroups 限制资源,以及被 pivot_root 切换了根文件系统的进程而已。相较于虚拟机,容器实现了高效的资源利用和快速的启动时间,同时保持了应用的隔离性和安全性。