前言:前面讲述了PyTorch人工神经网络的激活函数、损失函数等内容,今天讲解优化方法。
简单来说,优化方法主要是从两个角度来入手,一个是梯度,一个是学习率。
一、从梯度角度入手
(一)梯度下降算法回顾
梯度下降法简单来说就是一种寻找使损失函数最小化的方法**。
从数学角度来看,梯度的方向是函数增长速度最快的方向,那么梯度的反方向就是函数减少最快的方向,所以有:

其中,η是学习率,如果学习率太小,那么每次训练之后得到的效果都太小,增大训练的时间成本。如果,学习率太大,那就有可能直接跳过最优解,进入无限的训练中。解决的方法就是,学习率也需要随着训练的进行而变化。
(二)常用优化算法
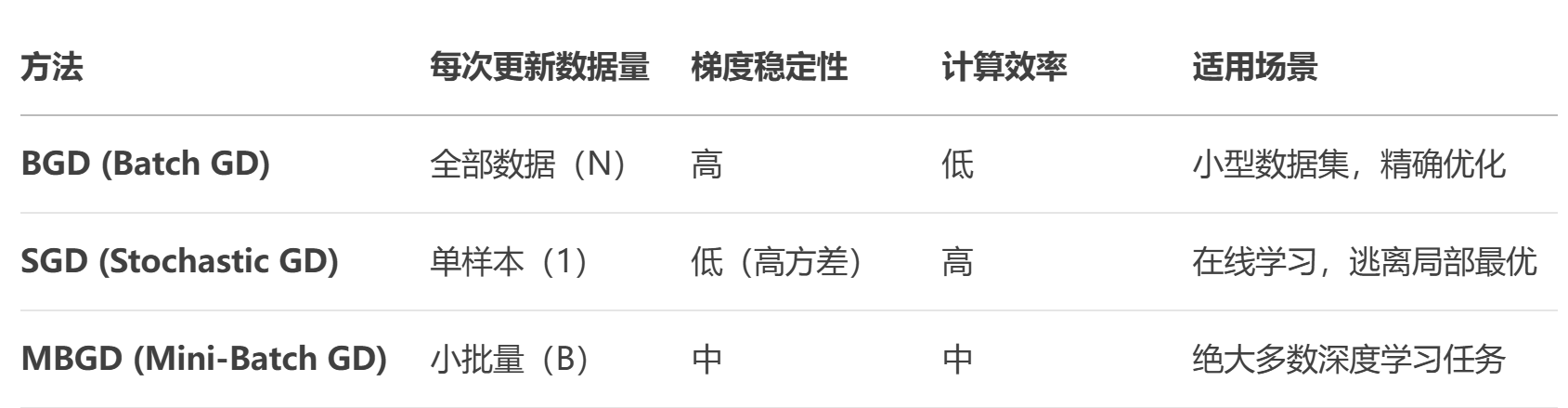
在梯度角度优化算法中,SGD(随机梯度下降)、BGD(批量梯度下降) 和 SBGD(小批量梯度下降) 是三种基础但核心的优化方法,而它们的区别主要在于 每次参数更新时使用的数据量。
1.SGD(Stochastic Gradient Descent)- 随机梯度下降

PyTorch代码实现:将batch_size设为1:
train_loader = DataLoader(dataset, batch_size=1, shuffle=True) # 逐样本加载
2.BGD (Batch Gradient Descent) - 批量梯度下降

PyTorch代码实现:直接对整个数据集计算平均梯度
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(train_inputs) # 全量数据
loss = criterion(outputs, train_labels)
loss.backward() # 计算全量梯度
optimizer.step()
3.MBGD (Mini-Batch Gradient Descent) - 小批量梯度下降

PyTorch代码实现:设置合适的batch_size
train_loader = DataLoader(dataset, batch_size=64, shuffle=True) # 小批量加载
(三)梯度优化算法的不足与革新
梯度下降优化算法中,可能会碰到以下情况:
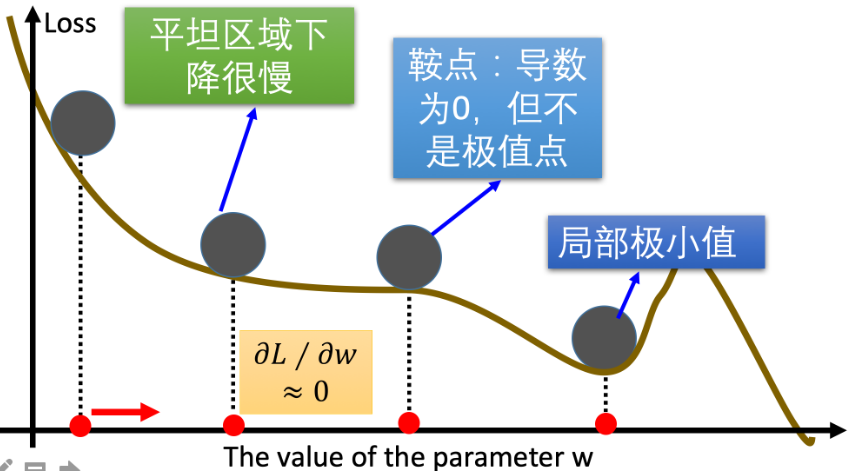
- 碰到平缓区域,梯度值较小,参数优化变慢;
- 碰到 “鞍点” ,梯度为0,参数无法优化;
- 碰到局部最小值,参数不是最优。
对于这些问题, 出现了一些对梯度下降算法的优化方法,例如:动量法
动量法(Momentum)详解:
简单来说,动量法是对SGD算法的改进,它运用了指数加权平均思想,最后起到减少震荡,加速收敛的效果。动量法尤其适用于高曲率、小但一致的梯度或带噪声的梯度场景。
1.指数加权平均
一种用于处理序列数据(如时间序列、梯度下降中的参数更新)的平滑方法,广泛应用于深度学习优化算法(如动量法(Momentum)、Adam、RMSprop等)。其核心思想是对历史数据赋予指数衰减的权重,从而平衡当前值与历史值的贡献。


注意·:通过调整 β,可以灵活平衡近期数据与历史数据的权重。
指数加权思想代码实现:
例:
from matplotlib import pyplot as plt
import torch
x=torch.arange(1,31)
torch.manual_seed(1)
y=torch.randn(30)*10
y_ewa=[]
beta=0.9
for idx,t in enumerate(y,1):
if idx==1:
y_ewa.append(t)
else:
y_ewa.append(beta*y_ewa[idx-2]+(1-beta)*t)
plt.scatter(x,y_ewa)
plt.show()
2.动量算法(Momentum)
首先,梯度计算公式(指数加权平均): s t = β s t − 1 + ( 1 − β ) g t s_t=βs_{t−1}+(1−β)g_t st=βst−1+(1−β)gt
参数更新公式: w t = w t − 1 − η s t w_t=w_{t−1}−ηs_t wt=wt−1−ηst
公式参数说明:
s t s_t st是当前时刻指数加权平均梯度值
s t − 1 s_{t-1} st−1是历史指数加权平均梯度值
g t g_t gt是当前时刻的梯度值
β 是调节权重系数,通常取 0.9 或 0.99
η是学习率
w t w_t wt是当前时刻模型权重参数
PyTroch中编程实践如下:
例:
def test01():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
loss = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:SGD 指定参数beta=0.9
optimizer = torch.optim.SGD([w], lr=0.01, momentum=0.9)
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
3.动量法(Momentum)有效克服 “平缓”、”鞍点”、”峡谷” 的问题

- 当处于鞍点位置时,由于当前的梯度为 0,参数无法更新。但是 Momentum 动量梯度下降算法已经在先前积累了一些梯度值,很有可能使得跨过鞍点;
- mini-batch 每次选取少数的样本梯度确定前进方向,可能会出现震荡,使得训练时间变长,而Momentum 使用指数加权平均,平滑了梯度的变化,使得前进方向更加平缓,有利于加快训练过程,一定程度上也降低了 “峡谷” 问题的影响。

二、从自适应学习率角度入手
(一)自适应梯度算法(AdaGrad)
1.概念
一种梯度下降算法,通过自适应调整每个参数的学习率。
其核心思想是:对频繁更新的参数降低学习率,对不频繁更新的参数保持较大的学习率。
AdaGrad主要用于稀疏矩阵:对于稀疏特征(如NLP中的one-hot编码),其对应的参数更新频率低,梯度多为零或极小值,因此 G t,ii增长缓慢,使得自适应学习率 保持较大。而密集特征的参数因频繁更新导致 G t,ii快速增大,学习率显著下降。

2.更新过程


PyTroch中编程实践如下:
例:
def test02():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
loss = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:adagrad优化方法
optimizer = torch.optim.Adagrad([w], lr=0.01)
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
结果显示:
第1次: 梯度w.grad: 1.000000, 更新后的权重:0.990000
第2次: 梯度w.grad: 0.990000, 更新后的权重:0.982965
(二)RMSProp优化算法
1.概念
**RMSProp 优化算法由Geoffrey Hinton提出,是对 AdaGrad 的优化:缓解AdaGrad的平方算法可能会使得学习率过早、过量的降低,导致模型训练后期学习率太小,较难找到最优解的情况。
其使用指数加权平均梯度替换历史梯度的平方和。
相比AdaGrad有如下优势:1.因使得梯度平方和不再无限增长,从而避免了学习率持续下降;2.因近期梯度对学习率的影响更大,避免了快速适应最新梯度。
2.更新过程


RMSProp特点:

PyTroch中编程实践如下:
例:
def test03():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True, dtype=torch.float32)
loss = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:RMSprop算法,其中alpha对应beta
optimizer = torch.optim.RMSprop([w], lr=0.01, alpha=0.9)
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
结果显示:
第1次: 梯度w.grad: 1.000000, 更新后的权重:0.968377
第2次: 梯度w.grad: 0.968377, 更新后的权重:0.945788
三、自适应矩估计(Adam)
(一)概念
深度学习中最常用的优化算法之一,它结合了动量法(Momentum)和RMSProp的优点,通过自适应调整每个参数的学习率,并利用梯度的一阶矩(均值)和二阶矩(方差)估计,实现了高效、稳定的参数更新。
主要有以下特点:

(二)Adam的更新过程



PyTroch中编程实践如下:
def test04():
# 1 初始化权重参数
w = torch.tensor([1.0], requires_grad=True)
loss = ((w ** 2) / 2.0).sum()
# 2 实例化优化方法:Adam算法,其中betas是指数加权的系数
optimizer = torch.optim.Adam([w], lr=0.01, betas=[0.9, 0.99])
# 3 第1次更新 计算梯度,并对参数进行更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第1次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
# 4 第2次更新 计算梯度,并对参数进行更新
# 使用更新后的参数机选输出结果
loss = ((w ** 2) / 2.0).sum()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print('第2次: 梯度w.grad: %f, 更新后的权重:%f' % (w.grad.numpy(), w.detach().numpy()))
结果显示:
第1次: 梯度w.grad: 1.000000, 更新后的权重:0.990000
第2次: 梯度w.grad: 0.990000, 更新后的权重:0.980003
附赠:
1.BGD/SGD/MBGD三种梯度优化方法对比
2.普通SGD与动量法(Momentum)的对比

3.AdaGrad、RMSProp、Adam 优缺点对比

今日的分享到此结束,下篇文章继续分享优化方法,敬请期待。