目录
1.5 Performance Is Challenging
5.2 Application Performance Techniques
Preface
已知的是已知的;我们知道我们所知道的事情。
我们也知道存在已知的未知;也就是说,我们知道有些事情我们不知道。
但也存在未知的未知——
有些事情我们不知道我们不知道。
—美国国防部长唐纳德·拉姆斯菲尔德(Donald Rumsfeld),2002年2月12日
虽然上述声明引起了出席新闻发布会的人们的笑声,但它总结了一个重要原则,这个原则在复杂的技术系统和地缘政治中同样适用:性能问题可能来自任何地方,包括您不知道且因此未检查的系统领域(未知未知)。本书可能会揭示许多这些领域,同时提供分析它们的方法和工具。
About This Book
欢迎来到《系统性能:企业和云端》!本书关注操作系统和应用程序的性能,从操作系统的角度来讲述,并适用于企业和云计算环境。我的目标是帮助您充分发挥系统的潜力。
当与不断开发的应用软件一起工作时,您可能会认为经过数十年开发和调优的操作系统性能问题已经解决了。但事实并非如此!操作系统是一个复杂的软件体系,管理着各种不断变化的物理设备和新的、不同的应用负载。内核也在不断发展,不断添加功能以提高特定工作负载的性能,并且随着系统的扩展,新遇到的瓶颈也在被消除。分析和改进操作系统的性能是一项持续的任务,应该不断取得性能改进。应用程序的性能也可以在操作系统的上下文中进行分析;我将在这里介绍相关内容。
Operating System Coverage
本书的主要重点是系统性能的研究,以Linux和Solaris操作系统为例介绍了工具、示例和可调参数。除非特别说明,操作系统的具体发行版在示例中并不重要。对于基于Linux的系统,示例来自各种裸金属系统和虚拟化云租户,运行的操作系统可以是Ubuntu、Fedora或CentOS。对于基于Solaris的系统,示例同样可以是裸金属系统或虚拟化系统,可以是Joyent SmartOS或OmniTI OmniOS。SmartOS和OmniOS使用的是开源的illumos内核,这是OpenSolaris内核的活跃分支,而OpenSolaris内核本身则基于最终成为Oracle Solaris 11的开发版本。
对于每个读者群体来说,覆盖两种不同的操作系统提供了额外的视角,深入了解它们的特点,特别是在每个操作系统采取不同的设计路径时。这有助于读者更全面地理解性能,而不局限于单一的操作系统,并以更客观的方式思考操作系统。
从历史上看,针对基于Solaris的系统进行了更多的性能工作,使其成为某些示例的更好选择。Linux的情况已经大大改善。当《系统性能调优》[Musumeci 02]撰写时,十多年前,它也同时涉及到Linux和Solaris,但主要是针对后者。作者指出了这样做的原因:
Solaris机器更注重性能。我怀疑这是因为Sun系统的价格平均比Linux的高。因此,人们对性能要求更高,所以在Solaris上做了更多的工作。如果您的Linux机器性能不够好,您可以购买另一台并分担工作负载 - 这很便宜。但是如果您的几百万美元的Ultra Enterprise 10000性能不佳,您的公司由于此而每分钟损失可观的金额,您会联系Sun Service并开始要求答案。
这可以解释Sun历史上对性能的关注:Solaris的利润与硬件销售密切相关,性能改进常常与真实的资金挂钩。Sun需要并且能够雇佣100多名全职性能工程师(包括我和Musumeci在内)。与Sun的内核工程团队一起,我们在系统性能领域取得了许多进展。
Linux在性能工作和可观察性方面已经取得了长足的进步,特别是现在它被广泛应用于大规模的云计算环境中。本书中包含的许多Linux的性能特性是在过去五年内开发的。
Other Content
书中包含了性能工具的示例屏幕截图,不仅显示数据,还用来说明可用的数据类型。这些工具通常以直观的方式呈现数据,许多工具的风格类似于早期的Unix工具,产生的输出是熟悉且常常不言自明的。这意味着屏幕截图可以是传达这些工具目的的有力方式,有些工具只需要很少的额外解释。(如果一个工具需要费力的解释,那可能是设计上的失败!)
技术的历史可以提供有用的见解,深化您的理解,在书中的一些地方已经提到了。了解一些行业中的关键人物也很有用(这是一个小圈子):在性能和其他环境中,你可能会遇到他们或者他们的工作。附录G中提供了一个"名人堂"列表。
What Isn’t Covered
本书着重于性能。要完成所有示例任务,有时需要进行一些系统管理活动,包括安装或编译软件(这里不涉及)。特别是在Linux上,您需要安装sysstat包,因为本文中使用了许多其工具。内容还概述了操作系统的内部结构,这在专门的文本中有更详细的介绍。高级性能分析主题也进行了总结,以便您了解它们的存在,并在需要时从其他来源进行学习。
How This Book Is Structured
本书包括以下内容:
第1章:介绍。介绍系统性能分析,概述关键概念,并提供性能活动的示例。
第2章:方法论。提供性能分析和优化的背景知识,包括术语、概念、模型、观察和实验的方法、容量规划、分析和统计。
第3章:操作系统。总结了面向性能分析师的内核内部机制。这是解释和理解操作系统正在做什么的必要背景知识。
第4章:可观测性工具。介绍了可用的系统可观测性工具的类型,以及它们构建在哪些接口和框架之上。
第5章:应用程序。讨论应用程序性能相关的主题,并从操作系统的角度观察它们。
第6章:CPU。涵盖处理器、核心、硬件线程、CPU缓存、CPU互联和内核调度。
第7章:内存。介绍虚拟内存、分页、交换、内存架构、总线、地址空间和分配器等内容。
第8章:文件系统。介绍文件系统I/O性能,包括涉及的不同缓存。
第9章:磁盘。涵盖存储设备、磁盘I/O工作负载、存储控制器、RAID和内核I/O子系统。
第10章:网络。介绍网络协议、套接字、接口和物理连接等内容。
第11章:云计算。介绍常用于云计算的基于操作系统和硬件的虚拟化方法以及它们的性能开销、隔离性和可观测性特性。
第12章:基准测试。展示如何进行准确的基准测试,以及如何解释他人的基准测试结果。这是一个令人意外棘手的话题,本章将展示如何避免常见错误,并试图理解其含义。
第13章:案例研究。包含一个系统性能案例研究,展示了如何从头到尾分析一个真实的云客户问题。
第1至第4章提供了必要的背景知识。阅读完它们后,您可以根据需要参考本书的其余部分。
第13章的写作方式不同,采用叙事方式来描绘性能工程师的工作更全面的画像。如果您是新手,可能希望先阅读这一章以获得上下文,然后再在阅读其他章节后返回它。
As a Future Reference
本书旨在通过专注于系统性能分析师的背景和方法论,提供多年的价值。
为了支持这一点,许多章节被分成两个部分。第一部分包括术语、概念和方法论(通常带有这些标题),这些内容应该在未来很多年内仍然相关。第二部分提供了第一部分如何实现的示例:架构、分析工具和可调整参数,虽然它们会过时,但在示例的背景下仍然有用。
Tracing Examples
我们经常需要深入探索操作系统,这可以通过内核追踪工具来实现。在不同的开发阶段有许多这样的工具,例如ftrace、perf、DTrace、SystemTap、LTTng和ktap。其中一个工具在大多数追踪示例中被选中,并在基于Linux和Solaris的系统上进行演示:DTrace。它提供了这些示例所需的功能,并且还有大量关于它的外部资料,包括可以作为高级追踪用例参考的脚本。
您可能需要或希望使用不同的追踪工具,这是可以的。DTrace示例是追踪的示例,展示了您可以向系统提出的问题。通常,这些问题和提出这些问题的方法论是最难掌握的部分。
Intended Audience
本书的目标读者主要是企业和云计算环境的系统管理员和运营人员。它也是开发人员、数据库管理员和Web服务器管理员的参考,他们需要了解操作系统和应用程序的性能。
作为一家云计算服务提供商的首席性能工程师,我经常与支持人员和客户合作,他们承受着巨大的时间压力,需要解决多个性能问题。对于许多人来说,性能不是他们的主要工作,他们只需要了解足够多的知识来解决手头的问题。这促使我尽可能地缩短本书的篇幅,因为我知道你学习的时间可能非常有限。但也不会太短:有很多内容需要涵盖,以确保你准备充分。
另一个预期的读者是学生:本书也适用于支持系统性能课程的教材。在撰写本书时(甚至在开始写作前的许多年),我自己开发和教授过这样的课程,其中包括模拟性能问题供学生解决(但没有提前提供答案!)。这帮助我看到哪些类型的材料最适合引导学生解决性能问题,这指导了我选择本书的内容。
无论你是否是学生,章节练习都给了你回顾和应用材料的机会。这些练习包括一些可选的高级练习题(来自审稿人的建议),你不需要解决它们(它们可能是不可能解决的;但至少应该引起思考)。
关于公司规模,本书应包含足够的详细信息,以满足从小型到大型环境,包括拥有数十名专门的性能工作人员的公司。对于许多较小的公司,本书可能只在需要时作为参考资料,每天只使用其中的一部分。
1 Introduction
性能是一个令人兴奋、多样且具有挑战性的领域。本章介绍了性能领域,特别是系统性能,描述了其中的角色、活动、视角和挑战。它还介绍了延迟,这是一个关键的性能指标,并介绍了计算领域的一些新发展:动态跟踪和云计算。还包括一些性能活动的示例,以提供背景信息。
1.1 Systems Performance
系统性能是对整个系统进行研究,包括所有物理组件和完整的软件栈。任何在数据路径中的软件或硬件都应被纳入考虑,因为它们会影响性能。对于分布式系统,这意味着多个服务器和应用程序。如果您没有显示数据路径的环境图表,请找到一个或自己画一个;它将帮助您理解组件之间的关系,并确保您不会忽略整个区域。
图1.1显示了单个服务器上通用系统软件栈,包括操作系统(OS)内核,以及示例数据库和应用程序层。术语“整个栈”有时用来描述仅包含应用程序环境的情况,包括数据库、应用程序和 Web 服务器。然而,在谈到系统性能时,我们使用“整个栈”来表示包括系统库和内核在内的所有内容。

这个栈在第3章《操作系统》中进行了讨论,并在后面的章节中进行了更详细的研究。以下几节将描述系统性能和性能的一般情况。
1.2 Roles
系统性能作为一项活动,可以由各种角色来完成,包括系统管理员、支持人员、应用程序开发人员、数据库管理员和 Web 管理员。对于其中许多人来说,性能是一项兼职活动,并且可能倾向于仅在自己负责的领域内探索性能问题(网络团队检查网络,数据库团队检查数据库等)。然而,对于一些性能问题,要找到根本原因需要这些团队的合作努力。
一些公司雇佣了性能工程师,他们的主要工作是系统性能。他们可以与多个团队合作,并对环境进行全面研究,这种方法在解决复杂性能问题时可能至关重要。他们还可以识别机会,为跨环境的系统级分析和容量规划开发更好的工具和指标。
在性能领域还有专门的应用程序职业,例如针对Java性能和MySQL性能的职业。这些通常会从对系统性能的有限检查开始,然后转向特定于应用程序的工具。
1.3 Activities
性能领域包括以下活动,按照理想的执行顺序列出:
1. 设定性能目标和性能建模
2. 原型软件或硬件的性能特性分析
3. 开发代码的性能分析,在集成之前
4. 对软件构建进行非回归测试,在发布前或发布后
5. 为软件发布进行基准测试
6. 在目标环境中进行概念验证测试
7. 针对生产部署进行配置优化
8. 监控正在运行的生产软件
9. 对性能问题进行性能分析。
步骤1到5是传统软件产品开发的一部分。然后产品被推出市场,随后进行在客户环境中的概念验证测试或部署和配置。如果在客户环境中遇到问题(步骤6到9),意味着在开发阶段未能检测或修复该问题。
性能工程理想情况下应在选择硬件或编写软件之前开始。这可以是第一步,涉及设定目标和创建性能模型。然而,通常产品在没有经过这一步的情况下进行开发,将性能工程工作推迟到出现问题时再进行。然而,随着开发过程的每个步骤,由于之前做出的架构决策,修复性能问题可能会越来越困难。
容量规划这个术语可以指前面提到的一系列活动。在设计阶段,它包括研究开发软件的资源占用情况,以评估设计是否能满足目标需求。在部署后,它包括监控资源使用情况,以预测问题的发生。
本书介绍了一些方法和工具,用于执行这些活动。
不同公司和产品之间的环境和活动各不相同,在许多情况下,并不会执行所有九个步骤。你的工作可能也只专注于其中一些或只有一个活动。
1.4 Perspectives
除了专注于不同的活动外,性能角色可以从不同的角度进行考虑。性能分析的两个视角在图1.2中标记为工作负载分析和资源分析,它们从不同的方向来接近软件堆栈。

资源分析的视角通常由系统管理员所采用,他们负责系统资源。而负责工作负载的交付性能的应用程序开发人员通常会专注于工作负载分析的视角。每个视角都有其自身的优势,在第2章“方法论”中进行了详细讨论。对于具有挑战性的问题,尝试从两个视角进行分析可能会有所帮助。
1.5 Performance Is Challenging
系统性能工程是一个具有挑战性的领域,原因包括它具有主观性,复杂性,并且通常涉及多个问题。
1.5.1 Performance Is Subjective //主观
技术学科往往是客观的,以至于行业内的人们以黑白分明而著称。这对软件故障排除来说可能是正确的,因为错误要么存在,要么不存在,要么已经被修复,要么没有被修复。这些错误通常表现为容易被解释和理解的错误消息,表示存在错误。
另一方面,性能问题往往是主观的。在性能问题上,是否存在问题并不清楚,如果存在问题,何时已经被解决也不清楚。对于一个用户而言,可能被认为是“糟糕”的性能,因此是一个问题,但对于另一个用户来说,可能被认为是“良好”的性能。
考虑以下信息:
平均磁盘I/O响应时间为1毫秒。
这是“好”还是“坏”?虽然响应时间或延迟是可用的最佳指标之一,但解释延迟信息是困难的。在一定程度上,一个给定的度量是否“好”或“坏”,可能取决于应用程序开发人员和最终用户的性能期望。
通过定义明确的目标,例如设置目标平均响应时间,或要求某个百分比的请求在特定延迟范围内完成,可以使主观性变为客观性。在第2章“方法论”中介绍了其他处理这种主观性的方法,包括通过延迟分析将问题表达为其操作延迟的比率。
1.5.2 Systems Are Complex
除了主观性外,性能问题可能由于系统的复杂性和缺乏清晰的分析起点而成为一门具有挑战性的学科。有时我们从一个猜测开始,比如责备网络,而性能分析师必须弄清楚这是否是正确的方向。
性能问题也可能源于子系统之间的复杂相互作用,在单独分析时它们表现良好。这可能是由于级联故障,当一个组件发生故障时会导致其他组件的性能问题。要理解所产生的问题,您必须解开组件之间的关系,并理解它们的贡献方式。
瓶颈也可能是复杂的,并以意想不到的方式相关;修复一个瓶颈可能只会将瓶颈转移到系统中的其他地方,整体性能并没有如期望的那样得到改善。
除了系统的复杂性外,性能问题可能是由生产工作负载的复杂特性引起的。在这些情况下,它们可能永远无法在实验室环境中重现,或者只会间歇性地重现。
解决复杂的性能问题通常需要采用整体方法。整个系统——包括其内部和外部交互——可能都需要被调查。这需要一系列技能,通常一个人很难具备,这使得性能工程成为一项多样化且具有智力挑战的工作。
不同的方法可以指导我们应对这些复杂性,就像在第2章中介绍的那样;第6至10章包括了特定的方法论,针对系统资源如CPU、内存、文件系统、磁盘和网络进行了介绍。
1.5.3 There Can Be Multiple Performance Issues
通常情况下,找到一个性能问题并不是问题;在复杂的软件中通常存在很多问题。为了说明这一点,试着找到你操作系统或应用程序的错误数据库,然后搜索关键词"性能"。你可能会感到惊讶!通常情况下,即使在被认为具有高性能的成熟软件中,也会存在一些已知但尚未修复的性能问题。这在分析性能时又带来了另一个困难:真正的任务不是找到一个问题,而是辨别出最重要的问题或问题。
为了做到这一点,性能分析师必须量化问题的严重程度。有些性能问题可能与您的工作负载无关,或者只适用于很小的程度。理想情况下,您不仅要量化问题,还要估计每个问题修复后的加速效果。当管理层寻求为工程或运营资源开支提供合理性时,这些信息是有价值的。
当可用时,一个非常适合性能量化的指标是延迟。
1.6 Latency
延迟是等待所花费的时间的度量。广泛地使用时,它可以表示任何操作完成所需的时间,例如应用程序请求、数据库查询、文件系统操作等。例如,延迟可以表示一个网站从链接点击到完全加载所花费的时间。这对于客户和网站提供者都是重要的指标:高延迟可能导致沮丧,客户可能会选择其他地方进行业务。

作为一个指标,延迟可以用来估计最大的加速效果。例如,图1.3描述了一个数据库查询需要100毫秒(即延迟),其中有80毫秒被阻塞等待磁盘读取。通过消除磁盘读取(例如通过缓存),可以计算出最大的性能提升:最多可以提升五倍(5倍)。这就是估计的加速效果,该计算还量化了性能问题:磁盘读取导致查询运行速度最多慢了5倍。
使用其他指标进行这样的计算是不可能的。例如,每秒I/O操作次数(IOPS)取决于I/O的类型,并且通常不能直接进行比较。如果某个更改将IOPS速率降低80%,很难知道性能影响会是什么样。可能会减少5倍的IOPS,但如果每个I/O的大小(字节)增加了10倍呢?
在网络的上下文中,延迟可以指连接建立的时间,而不是数据传输时间。在本书中,术语在每章的开始处进行了澄清,以便清楚地了解这种上下文差异。
尽管延迟是一个有用的指标,但并不总是能够在需要的时间和地点获得。一些系统领域只提供平均延迟;有些甚至不提供任何延迟指标。随着动态跟踪技术的出现,可以从任意感兴趣的点测量延迟,并提供显示完整延迟分布的数据。
1.7 Dynamic Tracing
动态跟踪允许所有软件在生产中都可以被检测和测量。它是一种技术,可以在内存中获取CPU指令,并动态地构建仪器。这使得可以从任何正在运行的软件中创建自定义性能统计数据,提供远远超出内置统计数据的可观察性。以前由于缺乏可观察性而无法解决的问题现在可以解决。以前可能可以解决但难度极大的问题现在通常更容易解决。
动态跟踪与传统观察方法有很大不同,因此一开始很难理解其作用。考虑操作系统内核:分析内核内部就像进入一个黑暗的房间,系统统计数据就像放在内核工程师认为需要的地方的蜡烛。动态跟踪就像一个手电筒,你可以把它指向任何地方。
该技术首次以可用于生产的工具形式问世,这个工具就是DTrace,它提供了许多其他功能,包括其自己的编程语言D。DTrace是由Sun Microsystems开发的,并于2005年发布用于Solaris 10操作系统。它也是Solaris中首个作为开源提供的组件,后来被移植到了Mac OS X和FreeBSD,并目前正在被移植到Linux。
在DTrace之前,系统跟踪通常使用静态探测器进行,即在内核和其他软件中放置一小组仪器点。它们的可见性有限,使用它们经常很耗时,需要配置、跟踪、转储数据,然后进行分析的一个周期。
DTrace提供用户级和内核级软件的静态和动态跟踪,并可以实时提供数据。以下是一个简单的示例,跟踪ssh登录期间的进程执行情况。跟踪是系统范围的(不与特定进程ID相关):

在这个示例中,DTrace被指示打印时间戳(纳秒),并显示进程名称和参数。在D语言中可以编写更复杂的脚本,允许我们创建和计算自定义的延迟度量。DTrace和动态跟踪将在第4章《可观察性工具》中进行解释。在后面的章节中,有许多基于Linux和Solaris系统的DTrace单行命令和脚本示例。对于更高级的用法,还有一本单独介绍DTrace的书籍[Gregg 11]。
1.8 Cloud Computing
最近对系统性能产生影响的最新发展是云计算和云常用的虚拟化技术。云计算通过使用一种可以在越来越多的小型系统之间平衡应用程序的架构,实现了快速扩展能力。这种方法还减少了对严格容量规划的需求,因为可以随时从云端添加更多容量。在某些情况下,它还增加了对性能分析的需求:使用更少的资源可以意味着使用更少的系统。由于云使用通常按小时计费,所以通过减少系统数量来提高性能可以立即节省成本。将这种情况与企业客户进行比较,企业客户可能被锁定在数年的固定支持合同中,可能无法在合同结束之前实现成本节约。
云计算和虚拟化带来的新问题包括管理其他租户引起的性能影响(有时称为性能隔离)以及每个租户对物理系统的可观察性。例如,除非系统得到正确管理,否则由于与邻居竞争,磁盘I/O性能可能较差。在某些环境中,每个租户可能无法观测到物理磁盘的真实使用情况,这使得难以识别此问题。
这些主题在第11章《云计算》中进行了详细讨论。
1.9 Case Studies
如果您是系统性能方面的新手,可以通过展示何时以及为什么进行各种活动的案例研究来帮助您将它们与当前环境联系起来。这里总结了两个假想的例子:一个是涉及磁盘I/O的性能问题,另一个是针对软件更改的性能测试。
这些案例研究描述了在本书的其他章节中解释的活动。这里描述的方法旨在展示的不是正确的方法或唯一的方法,而是这些性能活动可以进行的一种方法,供您进行关键考虑。
1.9.1 Slow Disks
Scott是一家中型公司的系统管理员。数据库团队提交了一个支持工单,抱怨他们的一个数据库服务器上的“磁盘速度慢”。Scott的第一个任务是了解更多关于这个问题的情况,收集详细信息来形成一个问题陈述。工单声称磁盘速度慢,但没有解释这是否导致了数据库问题。Scott通过提出以下问题做出回应:
- 目前是否存在数据库性能问题?如何进行衡量?
- 这个问题存在多长时间了?
- 最近数据库有什么变化吗?
- 为什么怀疑是磁盘的问题?
数据库团队回复说:“我们有一个查询时间超过1,000毫秒的日志。通常这种情况不会发生,但在过去一周中每小时都有几十个。AcmeMon显示磁盘在忙碌。”这证实了确实存在一个数据库问题,但也表明磁盘假设很可能是一个猜测。Scott想检查磁盘,但他也想快速检查其他资源,以防那个猜测是错误的。
AcmeMon是公司的基本服务器监控系统,提供基于操作系统工具(mpstat(1)、iostat(1)等)的历史性能图形。Scott登录AcmeMon亲自查看。
Scott从一种称为USE方法的方法开始,快速检查资源瓶颈。如数据库团队所报道的,磁盘的利用率很高,约为80%,而对于其他资源(CPU、网络)的利用率则要低得多。历史数据显示,磁盘利用率在过去一周中稳步增加,而CPU利用率则保持稳定。AcmeMon不提供磁盘饱和度或错误统计信息,因此为了完成USE方法,Scott必须登录到服务器并运行一些命令。
他从/proc中检查磁盘错误计数器,结果为零。他运行iostat命令,间隔为一秒,并随时间观察利用率和饱和度指标。AcmeMon报告显示80%的利用率,但使用了一分钟的间隔。以一秒的粒度,Scott可以看到磁盘利用率波动很大,经常达到100%,导致饱和度水平升高和增加的磁盘I/O延迟。
为了进一步确认这是否阻塞了数据库,而不是与数据库查询异步进行,他使用基于动态跟踪的脚本来捕获每当数据库被内核挂起时的时间戳和数据库堆栈跟踪。这显示数据库经常在文件系统读取期间、查询期间以及持续数毫秒的时间内发生阻塞。这对于Scott来说已经是足够的证据。接下来的问题是为什么会发生这种情况。磁盘性能统计数据似乎与高负载一致。Scott进行工作负载特性分析以进一步了解情况,使用iostat(1)来测量IOPS、吞吐量、平均磁盘I/O延迟以及读/写比。通过这些数据,他还计算了平均I/O大小并估计访问模式:随机还是顺序。如果需要更多细节,Scott可以使用磁盘I/O级别跟踪;然而,他满意地认为这已经指向了高磁盘负载的情况,而不是磁盘的问题。
Scott在工单中增加了更多细节,说明了他所检查的内容,并包括了研究磁盘所使用的命令的屏幕截图。到目前为止,他的总结是磁盘处于高负载状态,这增加了I/O延迟并减慢了查询速度。然而,从负载情况来看,磁盘似乎表现正常。他询问是否有一个简单的解释:数据库的负载是否增加了?
数据库团队回复说没有,而且查询速率(这并未由AcmeMon报告)一直很稳定。这似乎与之前的发现一致,即CPU利用率也一直稳定。
Scott考虑到什么原因会导致磁盘I/O负载增加,而CPU没有明显增加,并与同事进行了快速交流。其中一位同事提出文件系统碎片化的可能性,当文件系统接近100%容量时,这是预期的。但实际上只有30%。
Scott知道他可以进行深入分析以了解磁盘I/O的确切原因,但这可能需要很长时间。他首先尝试想出其他易于检查的简单解释,基于他对内核I/O堆栈的了解。他记得这种磁盘I/O主要是由文件系统缓存(页面缓存)未命中引起的。
Scott检查了文件系统缓存命中率,发现当前为91%。听起来很高(很好),但他没有历史数据可以进行比较。他登录到其他提供类似工作负载的数据库服务器,发现它们的缓存命中率超过97%。他还发现其他服务器的文件系统缓存大小要大得多。
将注意力转向文件系统缓存大小和服务器内存使用情况,他发现了一个被忽视的问题:一个开发项目有一个原型应用程序,即使没有生产负载,也在消耗越来越多的内存。这些内存来自可供文件系统缓存使用的内存,降低了命中率,从而增加了磁盘I/O并影响生产数据库服务器。
Scott联系应用程序开发团队,并要求他们关闭应用程序并将其移动到另一台服务器,引用数据库问题。在他们这样做后,Scott观察到AcmeMon中的磁盘利用率逐渐下降,因为文件系统缓存恢复到原始大小。慢查询数量降为零,他将工单标记为已解决。
1.9.2 Software Change
Pamela是一家小公司的性能和可伸缩性工程师,负责所有与性能相关的工作。应用程序开发人员开发了一个新的核心功能,并不确定其引入是否会影响性能。Pamela决定在将新的应用程序版本部署到生产环境之前进行非回归测试。(非回归测试是用于确认软件或硬件更改不会导致性能退化的活动,因此被称为非回归测试。)
Pamela获取了一台空闲服务器用于测试,并寻找一个客户端工作负载模拟器。应用团队以前写过一个,尽管它有各种限制和已知的bug。她决定尝试使用它,但希望确认它是否充分类似于当前的生产工作负载。
她配置服务器以匹配当前的部署配置,并从不同的系统运行客户端工作负载模拟器到目标系统。通过研究访问日志,可以对客户端工作负载进行特征化,公司已经有一个工具可以做到这一点,她使用了这个工具。她还在不同时间的生产服务器日志上运行了这个工具,比较了工作负载。看起来客户端模拟器应用了一个平均的生产工作负载,但没有考虑变化。她注意到了这一点,并继续她的分析。
Pamela在这个阶段知道几种可以采用的方法。她选择了最简单的方法:从客户端模拟器增加负载,直到达到一个限制(工作负载)。客户端模拟器可以配置为每秒执行一定数量的客户端请求,其默认值为1,000,她之前已经使用过。她决定从100开始增加负载,每次增加100,直到达到一个限制,每个级别测试一分钟。她编写了一个shell脚本来执行测试,并将结果收集到一个文件中,以便由其他工具进行绘图。
在负载运行时,她进行主动基准测试以确定限制因素是什么。服务器资源和服务器线程似乎大部分处于空闲状态。客户端模拟器显示完成的请求大约稳定在每秒700个左右。
她切换到新的软件版本并重复测试。结果也达到了700个请求,并趋于稳定。她还分析了服务器以寻找限制因素,但仍然没有发现任何问题。
她绘制了结果,显示完成请求率与负载之间的关系,以直观地确定可伸缩性特征。两者似乎都达到了一个突然的上限。
尽管看起来软件版本具有类似的性能特征,但Pamela对于未能确定导致可伸缩性上限的限制因素感到失望。她知道自己只检查了服务器资源,而限制因素可能是应用程序逻辑问题。它也可能存在于其他地方:网络或客户端模拟器。
Pamela想知道是否需要采取不同的方法,例如运行固定速率的操作,然后对资源使用情况(CPU、磁盘I/O、网络I/O)进行特征化(资源使用),以便可以从单个客户端请求的角度来表示。她以每秒700个请求的速率运行模拟器,测试当前和新的软件,并测量资源消耗情况。对于给定的负载,当前软件将32个CPU的平均利用率提高到20%。对于同样的负载,新软件将相同的CPU利用率提高到30%。看起来确实存在回归问题,即消耗更多的CPU资源。
为了了解700的限制,Pamela增加了负载,并调查数据路径中的所有组件,包括网络、客户端系统和客户端工作负载生成器。她还对服务器和客户端软件进行了深入分析。她记录了自己所检查的内容,包括截屏,以供参考。
为了调查客户端软件,她进行了线程状态分析,并发现它是单线程的。这一个线程花费100%的时间在CPU上执行。这使她确信这就是测试的限制因素。
作为一项实验,她在不同的客户端系统上并行启动客户端软件。通过这种方式,她让服务器在当前软件和新软件下都达到了100%的CPU利用率。当前版本达到了每秒3,500个请求,而新版本达到了每秒2,300个请求,与先前的资源消耗结果一致。
Pamela通知应用程序开发人员,新软件版本存在回归问题,并开始对其CPU使用情况进行分析以了解原因:哪些代码路径在起作用。她指出进行了平均生产工作负载测试,但未进行各种工作负载测试。她还提交了一个bug,指出客户端工作负载生成器是单线程的,可能成为瓶颈。
1.9.3 More Reading
第13章《案例研究》提供了一个更详细的案例研究,记录了我如何解决一个特定的云性能问题。下一章介绍了用于性能分析的方法论,并且接下来的章节涵盖了必要的背景知识和具体内容。
2 Methodology
在没有数据之前进行理论推测是一个严重的错误。不知不觉中,人们开始扭曲事实以适应理论,而不是调整理论以适应事实。
阿瑟·柯南·道尔爵士的《波西米亚丑闻》中的福尔摩斯警句
当面临性能下降和复杂的系统环境时,首要挑战是确定从哪里开始分析、收集哪些数据以及如何进行分析。正如我在第一章中所说,性能问题可能来自任何地方,包括软件、硬件和数据路径上的任何组件。方法论可以帮助性能分析人员处理复杂的系统,指导他们从何处开始,并采取哪些步骤来定位和分析性能问题。对于初学者,方法论指明了起点并提供了详细的步骤。对于普通用户或专家,它们可以作为检查清单,以确保不会错过细节。它们包括量化和确认发现的方法,识别最重要的性能问题。
本章分为三个部分:
- 背景介绍术语、基本模型、关键性能概念和观点。
- 方法论讨论性能分析方法论,包括观察和实验方法;建模;以及容量规划。
- 指标介绍性能统计、监控和可视化。
这里介绍的许多方法论在后面的章节中会进行更详细的探讨,包括第5到第10章的方法论部分。
2.1 Terminology
以下是系统性能的关键术语。后面的章节提供了更多的术语,并在不同的上下文中对其中一些进行了描述。
- IOPS:每秒输入/输出操作是数据传输操作的速率衡量单位。对于磁盘I/O,IOPS指的是每秒的读取和写入次数。
- 吞吐量:工作执行的速率。特别是在通信中,该术语用于表示数据速率(每秒字节数或每秒比特数)。在某些情况下(例如数据库),吞吐量可以指操作速率(每秒操作次数或每秒事务数)。
- 响应时间:操作完成所需的时间。这包括等待时间和服务时间(服务时间包括传输结果的时间)。
- 延迟:延迟是指一个操作等待服务的时间。在某些情况下,它可以指整个操作所花费的时间,相当于响应时间。有关示例,请参见第2.3节中的概念部分。
- 利用率:对于为请求提供服务的资源,利用率是基于在给定时间间隔内资源处于主动执行工作状态的时间的度量。对于提供存储的资源,利用率可能指已使用的容量(例如内存利用率)。
- 饱和度:资源无法处理的排队工作的程度。
- 瓶颈:在系统性能中,瓶颈是限制系统性能的资源。识别和消除系统性瓶颈是系统性能的关键活动。
- 工作负载:输入到系统或施加的负载即为工作负载。对于数据库而言,工作负载由客户端发送的数据库查询和命令组成。
- 缓存:快速存储区域,可以复制或缓冲有限量的数据,以避免直接与较慢的存储层通信,从而提高性能。出于经济原因,缓存的大小小于较慢的存储层。
需要时,附录中包含了基本术语以供参考。
2.2 Models
以下简单模型说明了系统性能的一些基本原理。
2.2.1 System under Test
系统测试下的性能展示如图2.1所示。
//Perturbations:干扰
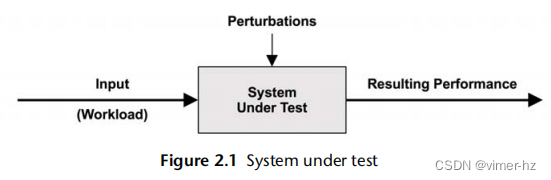
需要意识到,干扰(干涉)可能会影响结果,其中包括由系统定期活动、系统其他用户以及其他工作负载引起的干扰。这些干扰的来源可能不太清晰,可能需要仔细研究系统性能来确定。在一些云环境中,这可能特别困难,因为在客户SUT内部无法观察到物理主机系统上其他租户的活动(由客户租户进行的其他活动)。现代环境的另一个困难在于,它们可能由几个网络化组件组成,用于处理输入工作负载,包括负载均衡器、Web 服务器、数据库服务器、应用服务器和存储系统。仅是对环境进行映射可能有助于揭示先前被忽视的干扰源。该环境也可以被建模为队列系统的网络,进行分析性研究。
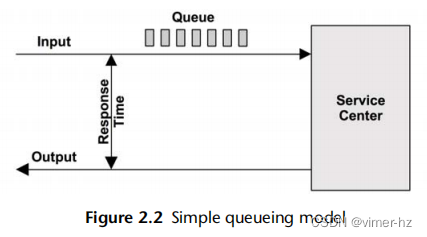
2.2.2 Queueing System
一些组件和资源可以被建模为队列系统。图2.2展示了一个简单的队列系统。
队列论是在第2.6节“建模”中介绍的,它研究队列系统和队列系统网络。
2.3 Concepts
以下是系统性能的重要概念,假设读者在本章和本书的其余部分已经具备相关知识。这些主题以一种通用的方式进行描述,然后在后面章节的架构和分析部分引入具体的实现细节。
2.3.1 Latency
对于某些环境而言,延迟是性能的唯一关注点。对于其他环境,延迟是分析的首要或前两个关键领域之一,与吞吐量一起。
以延迟为例,图2.3展示了一个网络传输的示例,比如一个HTTP GET请求,将时间分为延迟和数据传输组成部分。

延迟是指在执行操作之前花费的等待时间。在这个例子中,该操作是一个网络服务请求,用于传输数据。在进行这个操作之前,系统必须等待建立网络连接,这就是该操作的延迟。响应时间跨越了这个延迟和操作时间。
由于延迟可以从不同的位置进行测量,因此通常会与测量的目标一起表示。例如,网站的加载时间可能由从不同位置测得的三个不同的时间组成:DNS延迟、TCP连接延迟,以及TCP数据传输时间。DNS延迟涉及整个DNS操作。TCP连接延迟仅涉及初始化(TCP握手)。
在更高的层次上,所有这些,包括TCP数据传输时间,都可以被视为其他某种东西的延迟。例如,从用户点击网站链接到结果页面完全加载完成的时间可以称为延迟,其中包括浏览器渲染网页所需的时间。
由于延迟是一种基于时间的度量,可以进行各种计算。通过使用延迟来量化性能问题,然后对其进行排序,因为它们使用相同的单位(时间)进行表示。也可以通过考虑何时可以减少或消除延迟来计算预测的加速比。例如,使用IOPS指标无法准确执行这两种计算。
供参考,时间量级及其缩写列在表2.1中。
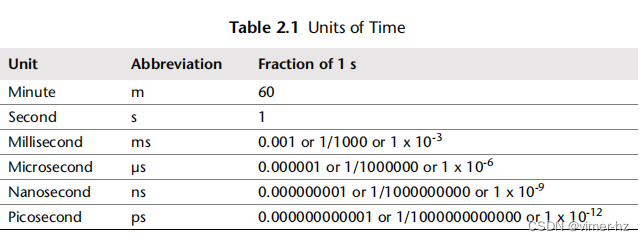
在可能的情况下,可以将其他类型的指标转换为延迟或时间,以便进行比较。如果你必须在100个网络I/O和50个磁盘I/O之间进行选择,你如何知道哪一个性能更好?这将是一个复杂的选择,涉及许多因素:网络跳数、网络丢包和重新传输的速率、I/O大小、随机或顺序I/O、磁盘类型等等。但是,如果你比较总共100毫秒的网络I/O和总共50毫秒的磁盘I/O,差异是明显的。
2.3.2 Time Scales
虽然时间可以通过数字进行比较,但对时间有一种本能感觉,并且对来自不同来源的延迟有期望也很有帮助。系统组件在时间尺度上(数量级)的操作差异巨大,以至于很难理解这些差异有多大。在表2.2中,提供了示例延迟,从3.3 GHz处理器的CPU寄存器访问开始。为了展示我们正在使用的时间尺度之间的差异,该表显示了每个操作可能需要的平均时间,按比例缩放到一个想象中的系统中,在该系统中,寄存器访问(在现实生活中为0.3纳秒,约为十亿分之一秒)需要一秒钟的时间。

正如你所看到的,CPU周期的时间尺度非常小。光线传播0.5米的时间,也许就是从你的眼睛到这个页面的距离,大约是1.7纳秒。在同样的时间内,一颗现代CPU可能已经执行了五个CPU周期并处理了几条指令。
关于CPU周期和延迟的更多信息,请参阅第6章《CPU》,有关磁盘I/O延迟,请参阅第9章《磁盘》。包含的互联网延迟来自第10章《网络》,其中还有更多例子。
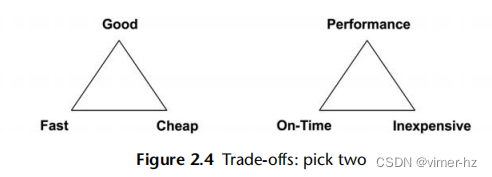
2.3.3 Trade-offs
你应该意识到一些常见的性能权衡。好/快/便宜的“选择两个”权衡如图2.4所示,同时还有为IT项目调整过的术语。
许多IT项目在时间和成本上都把控得很好,但却将性能修复留到后期。当早期的决策阻碍了提高性能时,这个选择可能会变得有问题,比如选择和填充次优的存储架构,或者使用缺乏全面性能分析工具的编程语言或操作系统。
性能调整中常见的权衡是CPU和内存之间的权衡,因为内存可以用于缓存结果,减少CPU使用量。在现代系统中,由于CPU充足,这种权衡可能会反过来:CPU可以用来压缩数据以减少内存使用量。
可调参数通常伴随着权衡。以下是一些例子:
文件系统记录大小(或块大小):接近应用程序I/O大小的小记录大小对于随机I/O工作负载表现更好,并且在应用程序运行时更有效地利用文件系统缓存。大记录大小将改善流式工作负载,包括文件系统备份。
网络缓冲区大小:小缓冲区大小将减少每个连接的内存开销,帮助系统扩展。大尺寸将提高网络吞吐量。
在对系统进行更改时,请寻找这样的权衡。
2.3.4 Tuning Efforts
//调优工作
性能调优最有效的时候是在工作执行的最近位置进行。对于由应用程序驱动的工作负载,这意味着在应用程序本身内部进行调优。表2.3展示了一个软件栈的示例,其中包含了调优的可能性。

通过在应用程序级别进行调优,可能可以消除或减少数据库查询,并将性能大幅提高(例如,20倍)。将调优降至存储设备级别可能会消除或改善存储I/O,但已经执行了较高级别的操作系统堆栈代码,因此这可能仅会将结果应用程序的性能提高百分之几(例如,20%)。
在应用程序级别找到大幅度的性能提升还有另一个原因。如今,许多环境都以快速部署功能和功能为目标。因此,在生产部署之前,应用程序的开发和测试往往集中在正确性上,几乎没有时间进行性能测量或优化。这些活动通常在性能成为问题时才进行。
虽然应用程序可能是最有效的调优级别,但不一定是最有效的观察级别。慢查询可能最好通过它们在 CPU 上花费的时间或它们执行的文件系统和磁盘 I/O 来理解。这些可以通过操作系统工具进行观察。
在许多环境中(尤其是云计算环境),应用程序级别处于不断开发的状态,每周甚至每天都会推送软件更改到生产环境。在应用程序代码发生变化时,通常会找到大的性能优化,包括修复回归问题。在这些环境中,很容易忽视针对操作系统的调优和从操作系统进行观测。
请记住,操作系统性能分析也可以识别应用程序级别的问题,而不仅仅是操作系统级别的问题,在某些情况下比仅从应用程序中更容易识别。
2.3.5 Level of Appropriateness
不同的组织和环境对性能有不同的要求。你可能加入了一个组织,在这个组织中,深度分析的程度超出了你以前见过的范围,甚至是你所知道的可能范围。或者你可能会发现,你认为基本的分析被视为高级分析,并且以前从未执行过(好消息是:很容易获得成果!)。
这并不意味着某些组织做得对,而某些组织做得错。这取决于性能专业知识的投资回报率(ROI)。拥有大型数据中心或云环境的组织可能需要一个性能工程师团队,他们分析一切,包括内核内部和CPU性能计数器,并经常使用动态跟踪。他们还可能正式建模性能,并为未来的增长制定准确的预测。小型初创公司可能只有时间进行表面检查,信任第三方监控解决方案来检查他们的性能并提供警报。
最极端的环境包括股票交易所和高频交易者,性能和延迟至关重要,并且可以证明需要投入巨大的努力和费用。作为一个例子,目前计划在纽约和伦敦交易所之间建立一条新的跨大西洋电缆,耗资3亿美元,以减少传输延迟6毫秒[1]。
2.3.6 Point-in-Time Recommendations
环境的性能特性随着时间的推移而变化,这是由于增加了更多的用户、更新的硬件和软件或固件所导致的。一个目前受限于1 Gbit / s网络基础设施的环境,在升级到10 Gbit / s后可能会开始感到磁盘或CPU性能不足。
性能建议,特别是可调参数的值,仅在特定时间点有效。一个星期内的性能专家给出的最佳建议,一个星期后可能因软件或硬件升级或添加更多用户而失效。
在互联网上搜索到的可调参数值可以在某些情况下提供快速解决方案。但是,如果它们对于您的系统或工作负载不合适,曾经适用但现在不适用,或者只适用于软件漏洞的临时解决方法,这些参数值也可能会损害性能。这就像搜刮别人的药柜并服用可能不适合您的药物,或者已经过期,或者只应该短期服用一样。
浏览此类建议可以很有用,只是为了了解哪些可调参数存在并且过去需要更改。然后的任务就是看看这些参数是否适合您的系统和工作负载,以及如何调整它们。但是,如果其他人以前没有需要调整该参数,或者已经调整了该参数但没有在任何地方分享他们的经验,您仍然可能会忽略一个重要的参数。
2.3.7 Load versus Architecture
应用程序的性能不佳可能是由于软件配置和运行的硬件(即其架构)存在问题。然而,应用程序也可能由于负载过大而导致排队和延迟过长而表现不佳。负载和架构如图2.5所示。
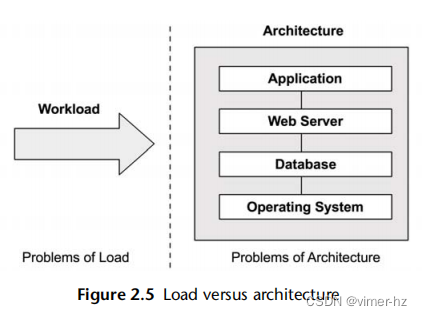
如果架构分析显示工作正在排队,但没有关于工作执行方式的问题,那么问题可能是负载过多。在云计算环境中,这时可以引入更多节点来处理工作。
例如,架构问题可能是一个繁忙的单线程应用程序,请求在排队,而其他CPU可用且空闲。在这种情况下,性能受限于应用程序的单线程架构。
负载问题可能是一个多线程应用程序,它在所有可用的CPU上都很繁忙,但请求仍在排队。在这种情况下,性能受限于可用的CPU容量,或者换句话说,是负载超过了CPU可以处理的负荷。
2.3.8 Scalability
在负载增加的情况下,系统的性能表现为可扩展性。图2.6展示了系统负载增加时的典型吞吐量曲线。
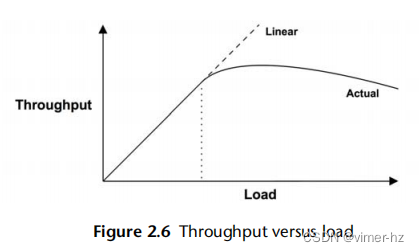
在某个阶段,观察到线性可扩展性。然后达到一个点,用虚线标记,资源争用开始影响性能。这一点可以被描述为拐点,因为它是两个曲线之间的边界。超过这一点,随着资源争用的增加,吞吐量曲线偏离线性可扩展性。最终,由于更多资源争用和一致性导致完成的工作减少,吞吐量减少。
当一个组件达到100%利用率时,即饱和点时,这一点可能会出现。它也可能在一个组件接近100%利用率时发生,排队开始变得频繁和显著。
一个可能表现出这种曲线的系统是一个执行重计算的应用程序,随着线程的增加,负载越来越大。当CPU接近100%利用率时,性能开始下降,因为CPU调度器延迟增加。在达到最高性能后,即100%利用率时,随着添加更多线程,吞吐量开始降低,导致更多的上下文切换,消耗CPU资源并导致完成的实际工作减少。
如果将x轴上的“负载”替换为CPU核心等资源,则可以看到相同的曲线。有关此主题的更多信息,请参见第2.6节,“建模”。
非线性可扩展性的性能退化,以平均响应时间或延迟为基础,可以在图2.7 [Cockcroft 95]中绘制出来。
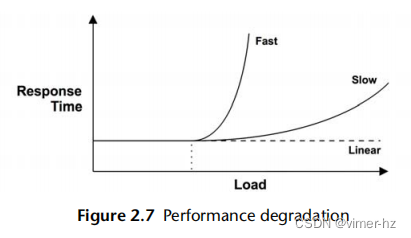
较高的响应时间当然是不好的。当系统开始进行分页(或交换)以补充主内存时,可能会出现"快速"退化的内存负载情况。而对于CPU负载,则可能会出现"缓慢"退化的情况。
另一个"快速"退化的示例是磁盘I/O。随着负载(及其导致的磁盘利用率)的增加,I/O更有可能排队等待其他I/O完成。一个空闲的旋转磁盘可能在大约1毫秒的响应时间内提供I/O服务,但当负载增加时,这个时间可能接近10毫秒。这在第2.6.5节的M/D/1和60%利用率中有所建模。
如果应用程序在资源不可用时开始返回错误而不是将工作排队,那么响应时间的线性可扩展性可能会发生。例如,Web服务器可能会返回503“服务不可用”而不是将请求添加到队列中,以便那些已经得到服务的请求可以以一致的响应时间执行。
2.3.9 Known-Unknowns
在前言中介绍的已知已知、已知未知和未知未知的概念对于性能领域非常重要。以下是分类说明,以系统性能分析为例:
已知已知:这些是你已经知道的事情。你知道你应该检查性能指标,也知道它的当前值。例如,你知道应该检查CPU利用率,并且知道平均值为10%。
已知未知:这些是你知道自己不知道的事情。你知道可以检查指标或子系统的存在,但尚未观察到。例如,你知道可以通过使用剖面来检查使CPU繁忙的原因,但尚未这样做。
未知未知:这些是你不知道自己不知道的事情。例如,你可能不知道设备中断会成为严重的CPU消耗者,因此没有对其进行检查。
性能是一个“你知道得越多,你不知道得就越多”的领域。这是相同的原则:你学到的关于系统的越多,你就会意识到更多的未知未知,然后可以将其作为已知未知进行检查。
2.3.10 Metrics
性能指标是由系统、应用程序或附加工具生成的统计数据,用于测量感兴趣的活动。它们被用于性能分析和监控,可以通过命令行数字或使用可视化图形进行研究。
常见的系统性能指标类型包括:
IOPS:每秒I/O操作次数
吞吐量:每秒操作或每秒传输的容量
利用率
延迟
吞吐量的使用取决于其上下文。数据库吞吐量通常是每秒查询或请求(操作)的衡量标准。网络吞吐量是每秒比特或字节(容量)的衡量标准。
IOPS是一种吞吐量测量,但仅适用于I/O操作(读取和写入)。同样,上下文很重要,定义可能因情况而异。
Overhead
//开销
性能指标并非免费;在某些时候,必须花费CPU周期来收集和存储它们。这会导致开销,可能会对测量目标的性能产生负面影响。这被称为观察效应。(它经常与海森堡的不确定性原理混淆,后者描述了物理属性对,如位置和动量,可以被知道的精度限制。)
Issues
//问题
人们往往会认为软件供应商提供的指标选择得当、没有错误,并提供完整的可见性。实际上,指标可能令人困惑、复杂、不可靠、不准确,甚至完全错误(由于错误)。有时,某个指标在一个软件版本上是正确的,但没有更新以反映新代码和代码路径的添加。
有关指标问题的更多信息,请参见第4章Observability Tools的第4.6节“观察可观性”。
2.3.11 Utilization
术语“利用率”通常用于操作系统中描述设备的使用情况,比如CPU和磁盘设备。利用率可以基于时间或容量来衡量。
Time-Based
基于时间的利用率在排队论中有正式定义。例如 [Gunther 97]:
服务器或资源繁忙的平均时间量
以及比率
U = B/T
其中,U表示利用率,B表示系统在观察期间T内繁忙的总时间。
这也是操作系统性能工具中最常见的“利用率”。磁盘监控工具iostat(1)将此指标称为“%b”,表示百分比繁忙,这个术语更能传达出底层的指标:B/T。
该利用率指标告诉我们组件有多忙:当组件接近100%利用率时,资源争用时性能可能严重下降。可以检查其他指标来确认并查看该组件是否成为系统瓶颈。
某些组件可以并行地处理多个操作。对于它们来说,在100%利用率时性能可能不会严重下降,因为它们可以接受更多的工作负载。
为了理解这一点,考虑一个大楼的电梯。当电梯在楼层之间移动时,它被认为是被利用的;当它处于空闲等待状态时,它被认为是未被利用的。然而,即使电梯在100%的时间里都在忙碌地响应呼叫,它可能仍然能够接受更多的乘客,也就是说,它处于100%的利用率。
一个100%繁忙的磁盘也可能能够接受和处理更多的工作负载,例如通过将写操作缓冲到磁盘缓存中以便稍后完成。存储阵列通常以100%的利用率运行,因为某些磁盘在100%的时间内都很忙,但阵列中有很多空闲磁盘,可以接受更多的工作负载。
Capacity-Based
另一个关于利用率的定义是由 IT 专业人员在容量规划的背景下使用的 [Wong 97]:
一个系统或组件(例如磁盘驱动器)能够提供一定数量的吞吐量。在任何性能水平下,系统或组件都在其容量的某个比例上工作。这个比例被称为利用率。
这种定义是基于容量而不是时间来定义利用率。它意味着100%利用率的磁盘无法接受更多的工作负载。根据基于时间的定义,100%利用率仅表示它在100%的时间内处于繁忙状态。
100%繁忙并不意味着100%容量。
以电梯为例,100%容量可能意味着电梯已达到最大载重量,无法接受更多乘客。
在理想的情况下,我们能够同时测量设备的这两种利用率。例如,你可以知道磁盘是否100%繁忙并且由于争用而性能开始下降,以及它是否已达到100%容量无法接受更多工作。然而,很遗憾,通常情况下这是不可能的。对于磁盘来说,需要了解磁盘上的控制器正在做什么,并对容量进行预测。目前,磁盘并不提供这些信息。
在本书中,利用率通常指的是基于时间的版本。容量版本用于一些基于容量的指标,例如内存使用情况。
Non-Idle Time
在我们公司开发云监控项目期间,定义利用率的问题浮现出来。首席工程师 Dave Pacheco 叫我定义利用率。我照上面的定义给了他。然而,他对可能引起混淆的可能性不满意,因此提出了一个不同的术语,以使其不言自明:非空闲时间。
虽然这更准确,但它目前还没有广泛使用(通常将此指标称为百分比繁忙,就像之前所描述的)。
2.3.12 Saturation
当对资源请求的工作量超过其处理能力时,饱和度就会发生。在100%利用率(基于容量)时开始出现饱和,因为无法处理额外的工作负载并且开始排队。这在图2.8中有所描述。
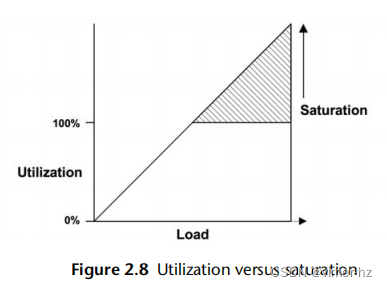
该图显示了饱和度随着负载的增加而线性增加,超过了基于100%容量的利用率标记。任何程度的饱和度都是一个性能问题,因为时间被浪费在等待上(延迟)。对于基于时间的利用率(百分比繁忙),排队和因此饱和可能不会在100%利用率标记处开始,这取决于资源可以并行处理工作的程度。
2.3.13 Profiling
性能剖析构建了一个可以被研究和理解的目标的画像。在计算机性能领域,性能剖析通常通过定时采样系统状态,然后研究采样集来完成。与之前涉及的指标(包括IOPS和吞吐量)不同,采样提供了目标活动的粗略视图,具体取决于采样频率。
例如,通过在频繁间隔采样CPU程序计数器或堆栈回溯,收集消耗CPU资源的代码路径的统计信息,可以相对详细地了解CPU使用情况。这个话题在第6章“CPU”中有所涉及。
2.3.14 Caching
缓存经常被用来提高性能。缓存将较慢存储层的结果存储在更快的存储层中以供参考。一个例子是将磁盘块缓存到主内存(RAM)中。
可以使用多个级别的缓存。CPU通常使用多个硬件缓存来处理主内存(第1、2和3级),从一个非常快速但较小的缓存(第1级)开始,随着存储容量和访问延迟的增加而增加。这是密度和延迟之间的经济权衡;级别和大小是为可用芯片空间的最佳性能而选择的。
系统中还有许多其他缓存,其中许多是使用主内存作为存储器实现的。请参见第3章“操作系统”的3.2.11节“缓存”中的缓存层列表。
了解缓存性能的一种指标是每个缓存的命中率-所需数据在缓存中被找到的次数(命中)与未找到的次数(未命中)之比:
命中率= 命中次数/总访问次数(命中次数+未命中次数)
命中率越高越好,因为更高的比率反映了从更快的媒体中成功访问的数据更多。图2.9显示了随着缓存命中率的增加,性能改善的预期情况。
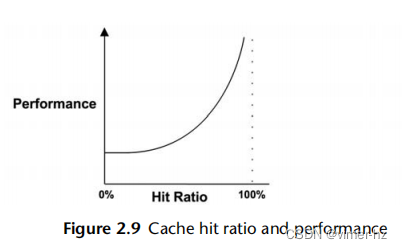
98%和99%之间的性能差异要大于10%和11%之间的差异。这是一个非线性的情况,因为缓存命中和未命中之间的速度差异-两个不同的存储层。差异越大,斜率就越陡。
另一个了解缓存性能的指标是每秒的缓存未命中率。这与每个未命中的性能惩罚成正比(线性关系),并且更容易解释。
例如,工作负载A和B使用不同的算法执行相同的任务,并使用主内存缓存来避免从磁盘读取。工作负载A的缓存命中率为90%,工作负载B的缓存命中率为80%。仅凭这些信息,可以推断工作负载A的性能更好。如果工作负载A的未命中率为200/s,而工作负载B为20/s呢?以这种方式计算,工作负载B的磁盘读取次数要比A少10倍,这可能比A更早完成任务。为确保准确,可以计算每个工作负载的总运行时间:
运行时间=(命中率×命中延迟)+(未命中率×未命中延迟)
该计算使用了平均命中延迟和未命中延迟,并假设工作负载是串行执行的。
Algorithms
缓存管理算法和策略决定了在有限的缓存空间中存储什么内容。
最近最常使用(MRU)是指缓存保留策略,它决定在缓存中保留哪些对象:最近被使用的对象。最不常使用(LRU)可以指等效的缓存驱逐策略,决定在需要更多空间时从缓存中删除哪些对象。还有最常使用(MFU)和最不常使用(LFU)的策略。
您可能会遇到不经常使用(NFU),它可能是LRU的一种廉价但不太彻底的版本。
Hot, Cold, and Warm Caches
以下是描述缓存状态常用的词汇:
冷缓存:一个冷缓存是空的,或者被不需要的数据占据。对于一个冷缓存来说,命中率为零(或者在开始变暖时接近零)。
热缓存:一个热缓存被常请求的数据所占据,并且有很高的命中率,例如超过99%。
温缓存:一个温缓存被有用的数据所占据,但它的命中率不够高以被认为是热缓存。
温度:缓存温度描述了一个缓存是热还是冷的程度。提高缓存命中率的活动被称为提高缓存温度的活动。当缓存首次被初始化时,它们开始冷,然后随着时间的推移变暖。
当缓存很大或下一级存储速度很慢(或两者都是),缓存可能需要很长时间才能被填充和变暖。
例如,我曾经在一个存储设备上工作,该设备有128 G字节的DRAM作为文件系统缓存,600 G字节的闪存作为二级缓存,并使用旋转磁盘进行存储。在随机读取的工作负载下,磁盘的读取速度大约为每秒2,000个。以8 K字节的IO大小计算,这意味着缓存只能以16 M字节/秒(2,000 x 8 K字节)的速度变暖。当两个缓存都开始变冷时,DRAM缓存需要超过2小时才能变暖,闪存缓存需要超过10小时。
2.4 Perspectives
性能分析有两种常见的视角,每种视角都有不同的受众、指标和方法。它们分别是工作负载分析和资源分析。可以将它们看作对操作系统软件栈进行自上而下或自下而上的分析,如图2.10所示。
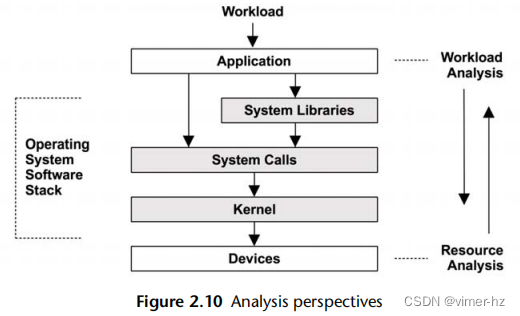
第2.5节"方法论"提供了针对每种视角应用的具体策略。这里更详细地介绍了这些视角。
2.4.1 Resource Analysis
资源分析始于对系统资源的分析:包括CPU、内存、磁盘、网络接口、总线和互连。这通常由系统管理员执行,他们负责物理环境资源。活动包括:
1. 性能问题调查:查看特定类型的资源是否负责性能问题。
2. 容量规划:用于确定新系统的大小,并查看现有系统资源何时可能耗尽。
这个视角侧重于利用率,以确定资源是否达到或接近其限制。某些资源类型,如CPU,具有易于获取的利用率指标。其他资源的利用率可以根据可用指标进行估算,例如,通过比较发送和接收的兆位每秒(吞吐量)与已知的最大带宽来估算网络接口的利用率。
最适合资源分析的指标包括:
1. IOPS(每秒输入输出操作数)
2. 吞吐量
3. 利用率
4. 饱和度
这些指标衡量了资源被要求执行的任务,以及在给定负载下它的利用率或饱和度。其他类型的指标,包括延迟,也可以用于查看资源在给定工作负载下的响应情况。
资源分析是性能分析的常见方法,部分原因是因为该主题有广泛可用的文档。这样的文档集中在操作系统的“stat”工具上:vmstat(1)、iostat(1)、mpstat(1)。阅读这样的文档时,重要的是要理解这只是一种视角,而不是唯一的视角。
2.4.2 Workload Analysis
工作负载分析(见图2.11)研究应用程序的性能:应用的工作负载以及应用程序的响应情况。它最常由应用程序开发人员和支持人员使用,他们负责应用程序软件和配置。
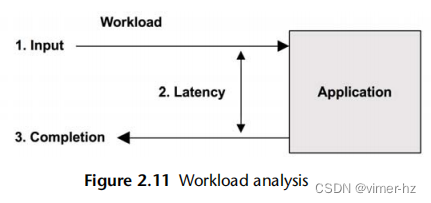
工作负载分析的目标包括:
请求:所应用的工作负载
延迟:应用程序的响应时间
完成:查找错误
研究工作负载请求通常涉及检查和总结其属性,即工作负载表征的过程(在第2.5节的方法论中更详细地描述)。对于数据库而言,这些属性可能包括客户端主机、数据库名称、表格和查询字符串。这些数据可以帮助识别不必要的工作或工作不平衡的情况。虽然工作可能表现良好(延迟低),但通过检查这些属性可能会找到减少或消除所应用工作的方法。(最快的查询是根本不进行查询。)
延迟(响应时间)是表达应用程序性能最重要的指标。对于MySQL数据库来说,它是查询延迟;对于Apache来说,它是HTTP请求延迟;等等。在这些情境中,延迟一词被用来表示与响应时间相同的含义(有关上下文的更多信息,请参阅第2.3.1节“延迟”)。工作负载分析的任务包括识别和确认问题,例如通过查找超出可接受阈值的延迟,然后找到延迟的来源(深入分析),并确认在应用修复后延迟是否得到改善。请注意,起点是应用程序。调查延迟通常涉及更深入地分析应用程序、库和操作系统(内核)。
通过研究与事件完成相关的特征,包括其错误状态,可以确定系统问题。虽然一个请求可能很快完成,但如果以错误状态完成,会导致请求被重试,从而累积延迟。
最适合工作负载分析的指标包括:
吞吐量(每秒事务数)
延迟
这些指标衡量请求的速率和结果性能。
2.5 Methodology
本节介绍了系统性能分析和调优的许多方法论和程序,并引入了一些新的方法,特别是USE方法。还包括了一些反方法论。
为了帮助总结它们的作用,这些方法论被归类为不同类型,例如观察分析和实验分析,如表2.4所示。
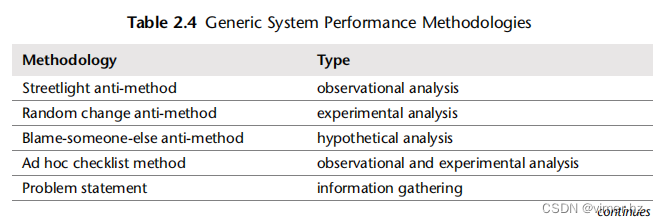
性能监控、排队理论和容量规划将在本章后面进行介绍。后面的章节还将在不同的上下文中重新解释其中一些方法,并提供一些特定于性能分析领域的附加方法。
下面的几节以常用但较弱的方法作为比较的起点,包括反方法论。在进行性能问题分析时,你应该首先尝试使用问题陈述方法,然后再尝试其他方法。
2.5.1 Streetlight Anti-Method
这种方法实际上是缺乏明确方法论的一种做法。用户通过选择熟悉的、在互联网上找到的或随意选择的可观测工具来分析性能,以查看是否有明显的问题。这种方法是凭运气的,可能会忽视许多类型的问题。
类似地,调优性能也可以尝试使用试错的方式,将已知和熟悉的可调参数设置为不同的值,以查看是否有所帮助。
即使这种方法揭示了一个问题,由于工具或调整与问题无关,因为它们是熟悉的,所以可能会很慢。因此,这种方法学被命名为街灯效应,它是以一个寓言来说明的:
一天晚上,一名警察看到一个醉汉在路灯下搜索地面,他问他在找什么。醉汉说他丢了钥匙。警察也找不到,问道:“你确定是在这儿丢的,就在路灯下?”醉汉回答:“不,但这里的光最亮。”
在性能方面,这相当于查看top(1),不是因为它有道理,而是因为用户不知道如何阅读其他工具。
这种方法找到的问题可能是一个问题,但不是真正的问题。其他方法可以对发现进行量化,以便更快地排除错误的结果。
2.5.2 Random Change Anti-Method
这是一种实验性的反方法论。用户随机猜测问题可能出在哪里,然后不断更改事物直到问题消失。为了确定每次更改是否改善了性能,会研究一项指标,例如应用程序运行时间、操作时间、延迟、操作速率(每秒操作数)或吞吐量(每秒字节数)。具体步骤如下:
1. 随机选择一个要更改的项目(例如一个可调参数)。
2. 在一个方向上进行更改。
3. 测量性能。
4. 在另一个方向上进行更改。
5. 测量性能。
6. 步骤3或步骤5的结果是否比基准线好?如果是,保留该更改并返回到步骤1。
尽管这个过程最终可能会发现适用于经过测试工作负载的调整方法,但它非常耗时,而且长期来看可能会留下没有意义的调整。例如,一个应用程序的更改可能会改善性能,因为它规避了数据库或操作系统的错误,而这个错误之后会被修复。但是应用程序仍将保留那个不再有意义的调整,而且一开始没有人正确理解。
另一个风险是,一个没有被正确理解的更改在生产高峰负载期间导致更严重的问题,并在此期间需要撤销该更改。
//即还是要理解业务之前的写法原理
2.5.3 Blame-Someone-Else Anti-Method
这种反方法论按照以下步骤进行:
1. 找到一个你不负责的系统或环境组件。
2. 假设问题出在那个组件上。
3. 将问题转给负责那个组件的团队。
4. 当证明错误时,返回到步骤1。
也许问题出在网络上。你能否向网络团队确认是否有丢包或其他问题?
使用这种方法论时,用户并不会调查性能问题,而是将问题推给其他人,当问题最终证明并非他们的问题时,可能会浪费其他团队的资源。这种反方法论的特征是缺乏数据支持的假设。
为了避免成为责怪他人的受害者,可以要求控告者提供截图,显示运行了哪些工具以及如何解释输出。你可以将这些截图和解释带给其他人进行第二意见。
//在阅读这些方法论时感觉像是自己的职业经历...
2.5.4 Ad Hoc Checklist Method
当被要求检查和调优系统时,通过按照一个预设的检查清单逐步进行是支持专业人员常用的方法论,通常在较短的时间内完成。一个典型的场景涉及将新的服务器或应用程序部署到生产环境中,支持专业人员花费半天时间检查系统在真实负载下的常见问题。这些检查清单是临时性的,根据最近的经验和该类型系统的问题建立起来。
以下是一个检查清单条目的示例:
运行iostat -x 1,并检查等待时间(await)列。如果负载期间该值持续超过10毫秒,则表示磁盘要么速度慢,要么超负荷。
一个检查清单可能包含十几个这样的检查。
尽管这些检查清单可以在最短时间内提供最大价值,但它们只是针对特定时刻的建议(参见第2.3节,概念),需要经常更新以保持最新。它们也倾向于关注已知可以轻松记录的问题的解决方法,如可调参数的设置,而不是源代码或环境的定制修复方法。
如果你管理一个支持专业人员团队,一个临时性的检查清单可以是确保每个人都知道如何检查最严重问题的有效方式,并且已经检查了所有明显的问题。检查清单可以编写得清晰明确,展示如何识别每个问题以及解决方法是什么。但当然,这个清单必须不断更新。
2.5.5 Problem Statement
当支持人员首次响应问题时,定义问题陈述是一项例行任务。这是通过问客户以下问题来完成的:
1. 什么让你觉得有性能问题?
2. 这个系统以前表现良好吗?
3. 最近有什么变化?软件?硬件?负载?
4. 问题可以用延迟或运行时间来表达吗?
5. 问题是否影响其他人或应用程序(还是只有你)?
6. 环境如何?使用了哪些软件和硬件?版本?配置?
只需问这些问题并回答它们通常就能指向一个即时的原因和解决方案。因此,问题陈述被包含在这里作为自己的方法论,并且应该是你解决新问题时使用的第一种方法。
2.5.6 Scientific Method
科学方法通过提出假设并进行测试来研究未知领域。它可以总结为以下步骤:
1. 问题
2. 假设
3. 预测
4. 测试
5. 分析
问题是性能问题陈述。基于这个问题陈述,你可以假设导致性能不佳的原因是什么。然后,你构建一个测试,这个测试可以是观察性的或实验性的,它测试了基于假设的预测。最后,对收集到的测试数据进行分析。
例如,你可能会发现在迁移到内存较少的系统后,应用程序性能下降了,并且你假设性能不佳的原因是较小的文件系统缓存。你可以使用观察性测试来测量两个系统上的缓存未命中率,预测较小系统上的缓存未命中率会更高。实验性测试可以是增加缓存大小(添加RAM),预测性能会提升。另一个可能更简单的实验性测试是人为减少缓存大小(使用可调参数),预测性能会变差。
/*有什么指标可以查看系统的内存命中率?
1. 缺页率(Page Fault Rate):缺页率是指在内存中无法找到所需数据或指令,需要从磁盘中加载的比例。较高的缺页率表示内存命中率较低。
2. 页面命中率(Page Hit Rate):页面命中率是指在虚拟内存系统中,将页面从磁盘加载到内存中时成功找到并加载到内存的页面的比例。较高的页面命中率表示内存命中率较高。
*/
/*
Minor Page Fault和Major Page Fault的区别:
Minor Page Fault和Major Page Fault是两种不同类型的页面错误(Page Fault),它们在内存管理中具有不同的含义和影响。
1. Minor Page Fault(次要页面错误):
- 当进程访问的页面在物理内存中存在,但没有映射到进程的虚拟地址空间时,会发生次要页面错误。
//进程的虚拟地址空间,不会映射所有的物理内存
- 次要页面错误通常是由分页机制中的页面置换策略引起的,用于将最近不活跃的页交换出去,以便为新的页腾出空间。
- 当发生次要页面错误时,操作系统只需更新页表,将正确的物理页面映射到进程的虚拟地址空间中,而无需从磁盘加载数据,因此通常速度较快。
2. Major Page Fault(主要页面错误):
- 主要页面错误通常是由于所需的页面不在物理内存中,需要从磁盘加载到内存中才能满足进程的访问需求。
- 当发生主要页面错误时,操作系统必须从磁盘读取相应的页面数据,然后更新页表,将该页面映射到进程的虚拟地址空间中。这个过程涉及磁盘访问,因此速度相对较慢。
*/
以下是一些更多的示例:
Example (Observational)
1. 问题:是什么导致数据库查询变慢?
2. 假设:嘈杂的邻居(其他云计算租户)正在执行磁盘I/O,与数据库的磁盘I/O竞争(通过文件系统)。
3. 预测:如果在查询期间测量文件系统的I/O延迟,将会发现文件系统是导致查询变慢的原因。
4. 测试:跟踪数据库文件系统延迟作为查询延迟的比例,显示只有不到5%的时间花在等待文件系统上。
5. 分析:文件系统和磁盘并不是导致查询变慢的原因。虽然问题仍未解决,但已经排除了一些重要的环境组件。进行此调查的人可以返回第2步,提出新的假设。
Example (Experimental)
1. 问题:为什么从主机A到主机C的HTTP请求比从主机B到主机C花费的时间更长?
2. 假设:主机A和主机B位于不同的数据中心。
3. 预测:将主机A移动到与主机B相同的数据中心将解决问题。
4. 测试:移动主机A并测量性能。
5. 分析:性能已经得到改善,与假设一致。如果问题没有得到解决,在开始新的假设之前,应撤销实验性的改变(在这种情况下将主机A移回原来的位置)。
Example (Experimental)
1. 问题:为什么随着文件系统缓存的增大,文件系统性能会下降?
2. 假设:较大的缓存存储更多的记录,相比较较小的缓存,管理较大的缓存需要更多的计算资源。
3. 预测:使记录大小逐渐变小,因此需要使用更多的记录来存储相同数量的数据,将导致性能逐渐变差。
4. 测试:使用逐渐减小的记录大小进行相同的工作负载测试。
5. 分析:结果被绘制成图表,并与预测一致。现在对缓存管理例程进行详细分析。
这是一个反向测试的示例——故意损害性能以了解目标系统更多信息的方法。
2.5.7 Diagnosis Cycle
类似于科学方法的是诊断循环:
假设 → 仪器检测 → 数据收集 → 假设
像科学方法一样,这种方法也通过收集数据有意地测试假设。该循环强调数据能够迅速引出新的假设,并对其进行测试和改进。这类似于医生通过一系列小型测试来诊断患者,并根据每个测试结果来完善假设。
这两种方法都在理论和数据之间取得了良好的平衡。试图快速从假设转向数据,以便能够及早识别并丢弃错误的理论,并发展出更好的理论。
2.5.8 Tools Method
一个以工具为导向的方法如下:
1. 列出可用的性能工具(可选择安装或购买更多)。
2. 对于每个工具,列出其提供的有用指标。
3. 对于每个指标,列出可能的解读规则。
这样得到的结果是一份规定性的清单,显示了应该运行哪个工具,阅读哪些指标以及如何解读它们。虽然这种方法可能相当有效,但它完全依赖于可用(或已知的)工具,这可能会提供对系统的不完整视图,类似于路灯反方法。更糟糕的是,用户并不知道自己的视图是不完整的,也可能一直不知道。需要自定义工具(例如动态追踪)解决的问题可能永远不会被识别和解决。
在实践中,工具方法确实可以识别出一些资源瓶颈、错误和其他类型的问题,尽管通常不够高效。
当有大量的工具和指标可用时,遍历它们可能需要很长时间。当多个工具具有相同功能时,情况会变得更糟,您需要额外的时间来了解每个工具的优缺点。在某些情况下,例如文件系统微基准测试工具,可能会有十多个可供选择的工具,而您可能只需要其中一个。
2.5.9 The USE Method
利用率、饱和度和错误(USE)方法应该在性能调查的早期使用,以识别系统瓶颈[Gregg 13]。它可以总结如下:
对于每个资源,检查其利用率、饱和度和错误。
这些术语的定义如下:
- 资源:所有物理服务器的功能组件(CPU、总线等)。一些软件资源也可以被检查,前提是指标具有意义。
- 利用率:在一个固定时间间隔内,资源忙于处理工作的时间百分比。在繁忙状态下,资源可能仍然能够接受更多的工作;不能接受更多工作的程度由饱和度确定。
- 饱和度:资源具有无法处理的额外工作量,通常在等待队列中等待。
- 错误:错误事件的数量。
对于一些资源类型,包括主存储器,利用率是已使用资源的容量。这与基于时间的定义不同,并且在第2.3.11节“利用率”中已经解释过。一旦一个容量资源达到100%的利用率,就无法接受更多的工作,资源要么排队等待工作(饱和),要么返回错误,这也是利用USE方法确定的。应该调查错误,因为它们可能会降低性能,并且在故障模式可恢复时可能不会立即被注意到。这包括操作失败并重试以及在冗余设备池中失败的设备。
与工具方法相比,USE方法涉及迭代系统资源而不是工具。这有助于您创建一个完整的问题清单,并且只有在这之后才去寻找工具来回答这些问题。即使找不到工具来回答问题,知道这些问题没有得到解答的信息对性能分析师来说也是非常有用的:现在它们成为了“已知的未知”。
USE方法还将分析引向少数关键指标,以便尽快检查所有系统资源。在此之后,如果没有发现问题,可以使用其他方法论。
Procedure
//流程
USE方法的流程图如图2.12所示。在检查利用率和饱和度之前,首先检查错误。错误通常很快且易于解释,在调查其他指标之前排除错误可能是节省时间的做法。
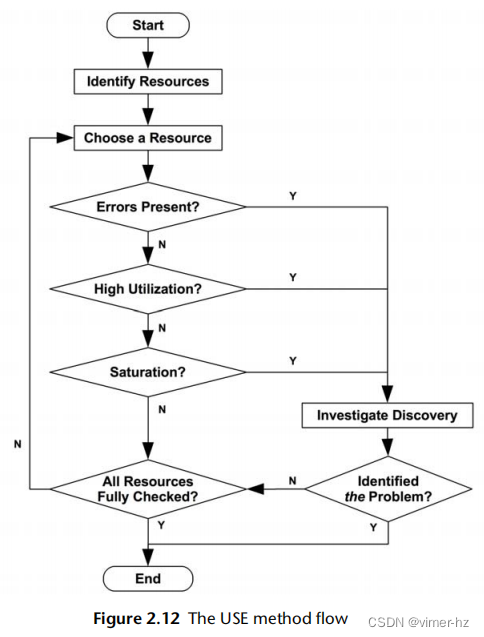
该方法识别出可能是系统瓶颈的问题。不幸的是,系统可能受到多个性能问题的困扰,因此你找到的第一个问题可能只是一个问题,而不是真正的问题。每个发现都可以使用进一步的方法进行调查,然后根据需要返回到USE方法以迭代更多资源。
Expressing Metrics
//指标表达
USE方法的指标通常表示如下:
- 利用率: 在时间间隔内的百分比(例如,“一个CPU运行在90%的利用率”)
- 饱和度: 作为等待队列长度(例如,“CPU平均运行队列长度为4”)
- 错误: 报告的错误数量(例如,“这个网络接口有50个迟到冲突”)
虽然这似乎不符合直觉,但短时间内的高利用率可能会导致饱和和性能问题,即使长时间内的总体利用率很低。一些监控工具报告5分钟平均值的利用率。例如,CPU利用率可能每秒钟变化很大,因此5分钟的平均值可能掩盖了短时间的100%利用率和饱和。
/*
CPU的饱和度详细解释下:
CPU的饱和度指的是CPU处理器的负载情况。当CPU的负载达到极限时,它就会变得饱和,无法再承载更多的工作负载。这通常会导致系统响应变慢甚至崩溃。
CPU饱和度可以通过检查等待队列的长度来确定。当CPU无法及时处理任务时,任务就会在等待队列中排队等待被处理,这就会导致等待队列的长度增加。长时间的高CPU饱和度可能会导致系统性能下降和延迟增加,因此需要进行监控和管理以确保系统正常运行。
"CPU饱和度可以通过检查等待队列的长度来确定"具体怎么做?
在Linux系统中,可以使用命令行工具top或htop来查看CPU的饱和度和等待队列的长度。
打开终端窗口,输入top或htop命令,按下回车键。这会显示一个实时监控系统的进程列表和性能指标。
在top或htop中,饱和度通常用si、so、%si、%so等指标表示。这些指标显示了内存交换的情况,如果这些值非常高,则表示CPU可能正在经历饱和状态。
等待队列的长度显示在进程列表中,它表示当前在CPU等待处理的进程数。在top或htop中,等待队列通常用D”(Interruptible sleep)状态来表示。如果大量的进程处于等待状态,则表明CPU正在经历饱和状态。
总之,在Linux系统中,可以通过top或htop等工具来检查CPU的饱和度和等待队列的长度,以及其他有关系统性能的指标,以便及时发现并解决问题。
“R”(Running)“表示进程处于运行状态。
*/
考虑高速公路上的一个收费站。利用率可以定义为有多少个收费亭正在为一辆车提供服务。100%的利用率意味着你找不到空的亭子,必须排队等候(饱和)。如果我告诉你,在整个一天中,收费亭的利用率为40%,你能告诉我在那一天的任何时间是否有任何车辆排队等候吗?在交通高峰期,利用率为100%,所以他们可能在那段时间内排队等候,但这在每日平均值中是看不出来的。
//这个举例很好
Resource List
USE方法的第一步是创建资源列表。尽量完整地列出所有资源。下面是一个通用的服务器硬件资源列表,以及具体的例子:
- CPUs(中央处理器):插槽(sockets)、内核(cores)、硬件线程(虚拟CPU)
- 主存储器:DRAM(动态随机存取存储器)
- 网络接口:以太网端口
- 存储设备:磁盘
- 控制器:存储、网络
- 互连设备:CPU、存储器、I/O(输入/输出)
每个组件通常作为单个资源类型。例如,主存储器是容量资源,网络接口是I/O资源(可以是IOPS或吞吐量)。一些组件可以作为多个资源类型的行为:例如,存储设备既是I/O资源,也是容量资源。考虑所有可能导致性能瓶颈的类型。另外要注意,I/O资源可以进一步研究为队列系统,用于排队和处理这些请求。
某些物理组件(例如硬件缓存,如CPU缓存)可以从检查清单中剔除。 USE方法最适合那些在高利用率或饱和下性能降级,导致瓶颈的资源,而缓存在高利用率下提高性能。可以使用其他方法来检查这些资源。如果您不确定是否包含某个资源,请将其包含在内,然后看在实践中指标如何运作。
Functional Block Diagram
//功能块图
另一种迭代资源的方法是找到或绘制系统的功能块图,例如图2.13所示。这样的图表还显示了关系,当寻找数据流中的瓶颈时,这些关系非常有用。
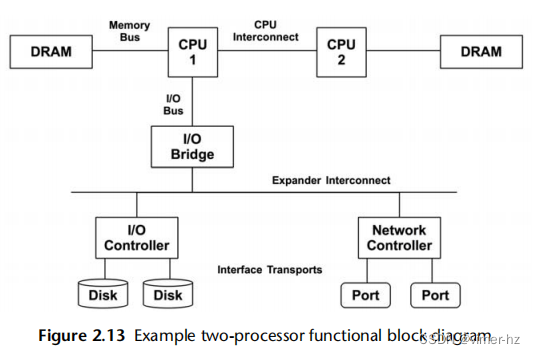
//Disk和CPU之间不是DRAM呀?
CPU、内存和I/O互连和总线通常被忽视。幸运的是,它们通常不是常见的系统瓶颈,因为它们通常被设计为提供足够的吞吐量。不幸的是,如果它们成为瓶颈,问题可能很难解决。也许您可以升级主板或减轻负载;例如,“零拷贝”项目可以减少内存总线负荷。
要调查互连设备,请参阅第6章“CPU”的6.4.1节中的“CPU性能计数器”部分。
Metrics
一旦您列出资源清单,考虑指标类型:利用率、饱和度和错误。表2.5显示了一些示例资源和指标类型,以及可能的指标(通用操作系统)。
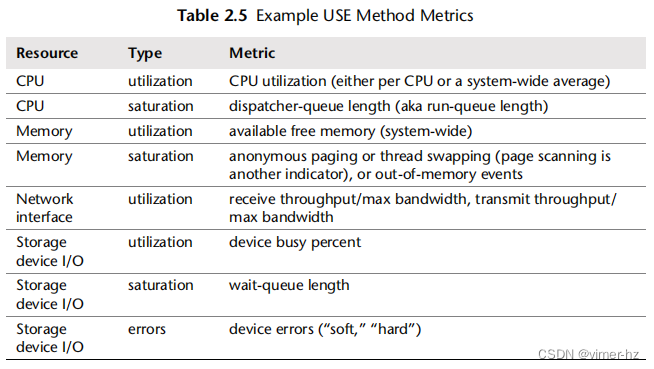
CPU saturation dispatcher-queue length (aka run-queue length)
CPU饱和度:调度器队列长度(也称为运行队列长度)
Memory saturation anonymous paging or thread swapping (page scanning is another indicator), or out-of-memory events
内存饱和度:匿名分页或线程交换(页面扫描是另一个指标),或内存不足事件
/*
内存饱和度详细解释下:
匿名分页是一种内存管理技术,用于在物理内存不足时将部分内存页面从内存中转移到磁盘上,以释放空间给其他进程使用。当系统中出现频繁的匿名分页活动时,这可能是内存饱和的一个指示。
线程交换是另一种内存管理技术,在物理内存不足时,将部分线程的数据和状态从内存中交换到磁盘上,以便为其他线程腾出空间。当系统中发生频繁的线程交换时,也可能是内存饱和的一个迹象。
此外,当系统中的内存资源不足时,可能会触发内存不足事件,导致系统性能下降或应用程序崩溃。
*/
这些指标可以是每个间隔的平均值或计数。
针对所有组合重复此过程,并包含获取每个指标的说明。
注意当前不可用的指标;这些是已知的未知因素。您最终将得到大约30个指标的列表,其中一些很难测量,有些根本无法测量。幸运的是,通常使用较简单的指标(例如CPU饱和度、内存容量饱和度、网络接口利用率、磁盘利用率)可以发现最常见的问题,因此可以首先检查这些指标。
表2.6提供了一些更困难的组合示例。
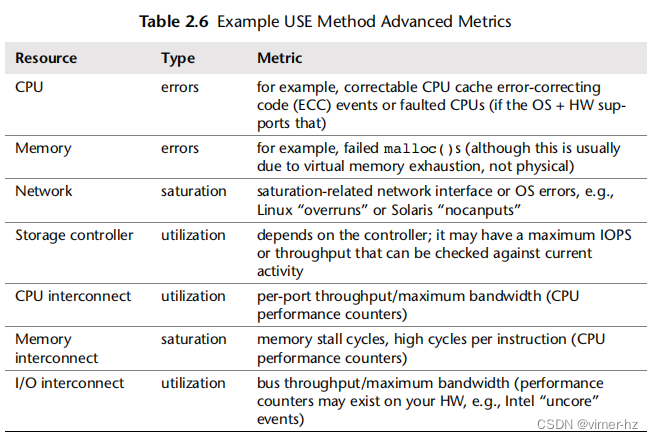
CPU interconnect utilization per-port throughput/maximum bandwidth (CPU performance counters)
CPU互连利用率:每端口吞吐量/最大带宽(CPU性能计数器)
Memory interconnect saturation memory stall cycles, high cycles per instruction (CPU performance counters)
内存互连饱和度:内存停滞周期,每条指令的高周期数(CPU性能计数器)
I/O interconnect utilization bus throughput/maximum bandwidth (performance counters may exist on your HW, e.g., Intel “uncore” events)
I/O互连利用率:总线吞吐量/最大带宽(您的硬件上可能存在性能计数器,例如Intel的“uncore”事件)
其中一些可能无法从标准操作系统工具中获取,并可能需要使用动态跟踪或CPU性能计数器功能。
附录A是Linux系统的USE方法清单示例,迭代使用Linux可观察性工具集对硬件资源进行检查。
附录B提供了基于Solaris系统的相同内容。这两个附录还包括一些软件资源。
Software Resources
软件资源
一些软件资源可以进行类似的检查。通常适用于软件的较小组件,而不是整个应用程序,例如:
- 互斥锁:利用率可以定义为持有锁的时间,饱和度则由排队等待锁的线程决定。
- 线程池:利用率可以定义为线程忙于处理工作的时间,饱和度由等待线程池服务的请求数量决定。
- 进程/线程容量:系统可能有限制的进程或线程数量,当前使用情况可以定义为利用率;等待分配则表示饱和度;错误发生在分配失败时(例如,“无法fork”)。
- 文件描述符容量:与进程/线程容量类似,但是针对文件描述符。
如果这些指标在您的情况下有效,请使用它们;否则,可以应用其他方法,如延迟分析。
Suggested Interpretations
//建议的解释
下面是一些关于指标类型的一般建议:
利用率:通常,100%的利用率是瓶颈的一个迹象(检查饱和度及其影响以确认)。超过60%的利用率可能会出现问题,原因有两个:根据间隔的不同,它可能会隐藏短暂的100%利用率。此外,一些资源(如硬盘,但不包括CPU)通常在操作期间无法中断,即使对于优先级较高的工作也是如此。随着利用率的增加,排队延迟会变得更加频繁和明显。有关60%利用率的更多信息,请参阅第2.6.5节《排队论》。
饱和度:任何程度的饱和度都可能是一个问题(非零)。可以将其测量为等待队列的长度,或者作为在队列上等待的时间。
错误:非零的错误计数器值值得调查,特别是如果它们在性能差的情况下不断增加。
解释负面情况很容易:低利用率,无饱和度,无错误。这比听起来更有用——缩小调查的范围可以帮助您迅速专注于问题区域,并确定它可能不是资源问题。这是排除法的过程。
Cloud Computing
//云计算
在云计算环境中,可能会实施软件资源控制,以限制或限制共享一个系统的租户。在Joyent,我们主要使用操作系统虚拟化(SmartOS Zones),它施加了内存限制、CPU限制和存储I/O限制。每个这些资源限制都可以使用类似于检查物理资源的USE方法进行检查。
例如,“内存容量利用率”可以是租户的内存使用量与其内存上限的比较。“内存容量饱和度”可以通过匿名分页活动来观察,即使传统的页面扫描程序可能处于空闲状态。
2.5.10 Workload Characterization
工作负载特征化是一种简单而有效的方法,用于识别一类问题:由于负载过重而引起的问题。它关注系统的输入,而不是结果性能。你的系统可能没有架构或配置问题,但承受的负载超出了其合理处理的范围。
通过回答以下问题可以对工作负载进行特征化:
- 谁造成了负载?进程ID、用户ID、远程IP地址?
- 为什么会发生负载调用?代码路径、堆栈跟踪?
- 负载的特征是什么?IOPS(每秒输入/输出操作数)、吞吐量、方向(读/写)、类型?在适当的情况下包括方差(标准偏差)。
- 负载如何随时间变化?是否存在每日模式?
即使你对这些问题的答案有很强的预期,检查所有这些问题也可能很有用,因为你可能会感到惊讶。
考虑以下情景:你的数据库存在性能问题,其客户端是一组Web服务器。你应该检查谁在使用数据库的IP地址吗?根据配置,你已经预期它们应该是Web服务器。尽管如此,你还是进行了检查,并发现整个互联网似乎都在向数据库投放负载,破坏了它们的性能。事实上,你正在遭受拒绝服务(DoS)攻击!
最佳的性能优化通常是通过消除不必要的工作来实现的。有时,不必要的工作是由应用程序故障引起的,例如,线程陷入循环会创建不必要的CPU负担。它也可能是由于错误的配置,例如在白天运行的系统备份,或者正如之前所述的DoS攻击。特征化工作负载可以识别这些问题,并通过维护或重新配置来消除它们。
如果无法消除已经识别的工作负载,另一种方法可能是使用系统资源控制来限制它。例如,系统备份任务可能通过使用CPU资源压缩备份,然后使用网络资源传输备份来干扰生产数据库。可以使用资源控制(如果系统支持)来限制CPU和网络使用,以便备份仍然进行(速度更慢),而不会损害数据库。
除了识别问题外,工作负载特征化还可以为模拟基准测试的设计提供输入。如果工作负载测量是平均值,理想情况下,你还需要收集分布和变化的详细信息。这对于模拟预期的多样化工作负载非常重要,而不仅仅是测试平均工作负载。有关平均值和变化(标准偏差)的更多信息,请参见第2.8节“统计”和第12章“基准测试”。
工作负载分析还有助于通过识别前者来区分负载问题和架构问题。负载与架构的对比在第2.3节“概念”中介绍过。
执行工作负载特征化的具体工具和指标取决于目标。某些应用程序记录客户端活动的详细日志,这可以是统计分析的源。它们也可能已经提供了关于客户端使用情况的每日或每月报告,可以挖掘其中的细节。
2.5.11 Drill-Down Analysis
钻取分析始于对问题进行高层次的检查,然后根据先前的发现缩小焦点,舍弃那些看似无趣的领域,并深入挖掘那些有趣的领域。这个过程可以涉及深入到软件堆栈的更深层次,如果需要的话,甚至可以涉及硬件,以找到问题的根本原因。
Solaris Performance and Tools [McDougall 06b] 提供了一种用于系统性能的钻取分析方法,包括三个阶段:
1. 监测:用于持续记录随时间变化的高级统计数据,并在可能存在问题时进行识别或警报。
2. 识别:在怀疑存在问题的情况下,将调查范围缩小到特定的资源或感兴趣的领域,识别可能存在的瓶颈。
3. 分析:进一步检查特定的系统领域,试图找出问题的根本原因并量化它。
监控可以在整个公司范围内进行,将所有服务器或云实例的结果进行汇总。传统的方法是使用简单网络管理协议(SNMP),它可用于监控支持该协议的任何网络连接设备。所得到的数据可能会显示出长期模式,而在短时间内使用命令行工具时可能会被忽略。许多监控解决方案在怀疑存在问题时提供警报,促使分析转入下一阶段。
在服务器上,识别是通过交互方式进行的,使用标准的可观测性工具来检查系统组件:CPU、磁盘、内存等。通常是通过使用诸如vmstat(1)、iostat(1)和mpstat(1)等工具的命令行会话来完成的。一些较新的工具允许通过图形用户界面进行实时交互式性能分析(例如,Oracle ZFS存储设备分析)。
分析工具包括基于跟踪或分析的工具,用于对可疑区域进行更深入的检查。这种更深入的分析可能涉及创建自定义工具,并检查源代码(如果有的话)。这就是大部分钻取的地方,根据需要剥离软件堆栈的各层,以找到根本原因。执行此操作的工具包括strace(1)、truss(1)、perf和DTrace。
Five Whys
在分析阶段,您还可以使用五个为什么的技术:问自己“为什么?”然后回答这个问题,总共重复五次(或更多)。以下是一个示例过程:
1. 数据库对许多查询开始表现不佳。为什么?
2. 这是由于内存分页导致的磁盘I/O延迟。为什么?
3. 数据库内存使用量增长过大。为什么?
4. 分配器消耗的内存超过了应有的数量。为什么?
5. 分配器存在内存碎片问题。
这是一个真实世界的例子,非常出乎意料地导致了系统内存分配库的修复。正是通过持续的质疑和深入挖掘到核心问题,才导致了修复的发现。
2.5.12 Latency Analysis
延迟分析检查完成操作所需的时间,然后将其分解为更小的组件,继续细分具有最高延迟的组件,以便确定和量化根本原因。类似于深入分析,延迟分析可能会通过软件堆栈的各层进行深入挖掘,以找到延迟问题的根源。
分析可以从应用的工作负载开始,检查该工作负载在应用程序中的处理方式,然后深入到操作系统库、系统调用、内核和设备驱动程序中。
例如,对MySQL查询延迟的分析可能涉及回答以下问题(这里给出了示例答案):
1. 是否存在查询延迟问题?(是)
2. 查询时间主要是花费在CPU上还是等待CPU之外?(等待CPU之外)
3. 等待CPU之外的时间是用来等待什么的?(文件系统I/O)
4. 文件系统I/O时间是由于磁盘I/O还是锁争用?(磁盘I/O)
5. 磁盘I/O时间很可能是由于随机寻道还是数据传输时间?(传输时间)
对于这个例子,每个步骤都提出了一个问题,将延迟分成两部分,然后继续分析较大的部分:如果你愿意,可以将其视为延迟的二进制搜索。该过程如图2.14所示。
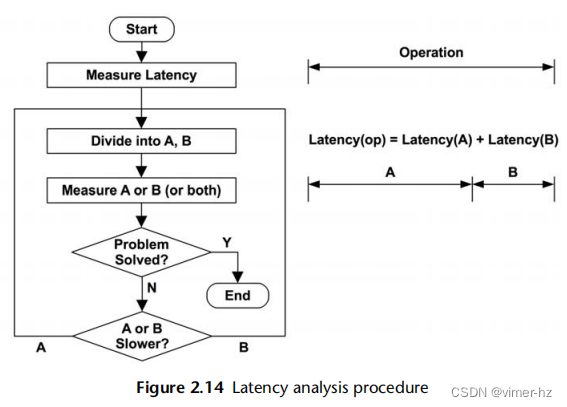
当A或B中较慢的部分被确定后,它会进一步分成A或B,并进行分析等操作。
方法R的目标是对数据库查询进行延迟分析。
2.5.13 Method R
Method R是针对Oracle数据库开发的一种性能分析方法,重点是基于Oracle跟踪事件找到延迟的来源[Millsap 03]。它被描述为“一种基于响应时间的性能改进方法,为您的业务带来最大的经济价值”,并且专注于识别和量化查询过程中的时间消耗。尽管该方法用于数据库的研究,但其方法也可以应用于任何系统,并且值得在这里提及作为一个可能的研究途径。
2.5.14 Event Tracing
系统通过处理离散事件来运行。这些事件包括CPU指令、磁盘I/O和其他磁盘命令、网络数据包、系统调用、库调用、应用程序事务、数据库查询等等。性能分析通常研究这些事件的摘要,例如每秒操作次数、每秒字节数或平均延迟。有时,在摘要中会丢失重要的细节,最好在逐个事件进行检查时对其进行理解。
网络故障排除通常需要逐个数据包的检查,使用诸如tcpdump(1)之类的工具。这个例子将数据包总结为单行文本:
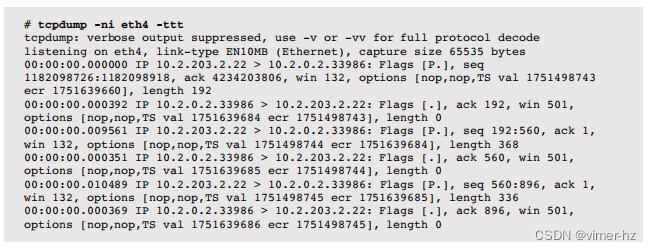
根据需要,tcpdump(1)可以打印不同数量的信息(请参阅第10章“网络”)。
可以使用iosnoop(1M)(基于DTrace)来跟踪块设备层的存储设备I/O(请参阅第9章“磁盘”):
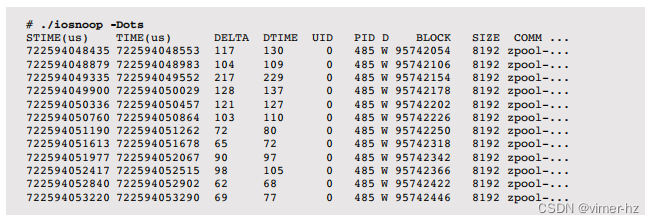
这里打印了多个时间戳,包括开始时间(STIME)、结束时间(TIME)、请求和完成之间的时间差(DELTA)以及估算的服务此I/O所需的时间(DTIME)。
系统调用层也是常见的跟踪位置,工具包括Linux上的strace(1)和基于Solaris的系统上的truss(1)(请参阅第5章“应用程序”)。这些工具也有选项来打印时间戳。
在执行事件跟踪时,寻找以下信息:
输入:事件请求的所有属性:类型、方向、大小等。
时间:开始时间、结束时间、延迟(差异)。
结果:错误状态、事件结果(大小)。
有时,通过检查事件的请求或结果的属性,可以理解性能问题。使用事件跟踪工具,可以通过事件时间戳特别有助于分析延迟,并且通常可以包含在内。
前面的tcpdump(1)输出包括Delta时间戳,测量数据包之间的时间,使用-ttt。
对先前事件的研究提供了更多信息。特别糟糕的延迟事件,称为延迟异常值,可能是由以前的事件而不是事件本身引起的。例如,队列尾部的事件可能具有高延迟,但是是由前面的队列事件引起的,而不是其自身属性引起的。可以从跟踪事件中识别此类情况。
2.5.15 Baseline Statistics
将当前的性能指标与过去的数值进行比较通常是很有启发性的。
可以识别负载或资源使用的变化,并追溯问题的首次出现。一些可观测性工具(基于内核计数器的工具)可以显示自引导以来的摘要,以便与当前活动进行比较。这虽然粗糙,但总比没有好。另一种方法是收集基准统计数据。
这可能涉及执行各种系统可观测性工具,并记录输出以供将来参考。与自引导以来的摘要不同,它可以包括每秒的统计数据,以便看到变化。
在系统或应用程序更改之前和之后可能会收集基线统计数据,以便分析性能变化。它也可以不定期地收集,并包含在站点文档中,以便管理员可以了解“正常”情况。每天定期执行此任务是性能监控的一项活动(参见第2.9节“监控”)。
2.5.16 Static Performance Tuning
静态性能调整关注的是配置体系结构方面的问题。其他方法则关注应用负载的性能:动态性能[Elling 00]。当系统处于静止状态且没有负载时,可以进行静态性能分析。
对于静态性能分析和调整,请逐个检查系统的所有组件并检查以下内容:
- 组件是否合理?
- 配置是否符合预期的工作负载?
- 是否自动配置了最适合预期工作负载的组件?
- 组件是否遇到错误并处于降级状态?
以下是使用静态性能调整可能找到的一些问题示例:
- 网络接口协商:选择100 Mbits/s而不是1 Gbit/s
- RAID池中的损坏磁盘
- 使用旧版本操作系统、应用程序或固件
- 文件系统记录大小与工作负载I/O大小不匹配
- 服务器意外配置为路由器
- 配置服务器以从远程数据中心而不是本地使用资源(如身份验证)
幸运的是,这些类型的问题很容易检查。难点在于记得去做!
2.5.17 Cache Tuning
应用程序和操作系统可能会使用多个缓存来提高I/O性能,从应用程序到磁盘。有关完整列表,请参见第3章“操作系统”中的第3.2.11节“缓存”。以下是针对每个缓存级别的一般性调整策略:
1. 旨在尽可能高地在堆栈中缓存,靠近执行工作的位置,减少缓存命中的操作开销。
2. 检查缓存是否已启用并正常工作。
3. 检查缓存命中/未命中比率和未命中率。
4. 如果缓存大小是动态的,请检查其当前大小。
5. 针对工作负载调整缓存。此任务取决于可用的缓存可调参数。
6. 针对缓存调整工作负载。这包括减少不必要的缓存消费者,为目标工作负载释放更多空间。
注意双重缓存,例如消耗主内存并将相同数据缓存两次的两个不同缓存。
还应考虑每个缓存调整级别的整体性能增益。调整CPU一级缓存可能会节省纳秒时间,因为缓存未命中可以由二级缓存服务。但是改进CPU三级缓存可能避免更慢的DRAM访问,并导致更大的整体性能增益。(这些CPU缓存在第6章“CPU”中描述。)
2.5.18 Micro-Benchmarking
微基准测试评估简单和人为工作负载的性能。它可以用于支持科学方法,验证假设和预测,也可以是容量规划的一部分。
这与通常旨在测试真实世界和自然工作负载的行业基准测试不同。此类基准测试通过运行工作负载模拟来进行,可能变得复杂以进行和理解。
微基准测试较为简单,因为涉及的因素较少。可以通过应用工作负载并测量性能的微基准工具来执行,或者可以使用仅应用工作负载而将性能测量留给标准系统工具的负载生成器工具。两种方法都可以,但最安全的方法可能是使用微基准工具,并使用标准系统工具再次检查性能。
微基准测试的一些示例目标,包括测试的第二个维度,是:
- 系统调用时间:对于fork()、exec()、open()、read()、close()
- 文件系统读取:从缓存文件中读取,将读取大小从1字节变化到1兆字节
- 网络吞吐量:在TCP端点之间传输数据,对于不同的套接字缓冲区大小
微基准测试通常尽可能快地执行目标操作,并测量完成大量操作所需的时间。然后可以计算平均时间(平均时间 = 运行时间/操作计数)。后面的章节中将介绍具体的微基准测试方法,列出要测试的目标和属性。有关基准测试的主题将在第12章“基准测试”中详细讨论。
2.6 Modeling
对系统进行分析建模可以用于多种目的,特别是可扩展性分析:研究随着负载或资源的扩展而性能如何扩展。资源可以是硬件,例如CPU核心,也可以是软件,例如进程或线程。
分析建模可以被视为第三种性能评估活动,与生产系统的可观察性("测量")和实验性测试("模拟")一同存在[Jain 91]。只有在至少进行两个这些活动时,性能才能得到最好的理解:分析建模和模拟,或者模拟和测量。
如果分析是针对现有系统的,可以从测量开始:描述负载和相应的性能。如果系统尚未具备生产负载,或者要测试超出生产中所见负载的工作负载,可以使用试验性分析,通过测试工作负载模拟来进行。分析建模可用于预测性能,并且可以基于测量或模拟的结果。
可扩展性分析可能会揭示性能在某个点(称为拐点)停止线性扩展,这是由于资源限制所致。找出是否存在这些点,以及它们位于何处,可以引导对抑制可扩展性的性能问题进行调查,以便在生产中遇到之前修复它们。
有关这些步骤的更多信息,请参阅第2.5.10节"工作负载描述"和第2.5.18节"微基准测试"。
2.6.1 Enterprise versus Cloud
虽然建模使我们能够模拟大规模企业系统,而无需拥有实际系统,但大规模环境的性能往往复杂且难以准确建模。
通过云计算,可以租用任何规模的环境进行短期使用——例如基准测试的时长。与创建数学模型以预测性能不同,工作负载可以被描述、模拟,然后在不同规模的云端进行测试。一些发现,如拐点,可能是相同的,但现在是基于实测数据而不是理论模型,并通过测试真实环境,您可能会发现未包含在您的模型中的限制因素。
2.6.2 Visual Identification
当实验收集到足够的结果时,将它们作为交付性能与缩放参数的关系绘制出来,可能会揭示出一种模式。
图2.15显示了应用程序的吞吐量随线程数量的缩放而变化。在大约八个线程处出现了一个拐点,斜率发生了变化。现在可以对此进行进一步研究,例如查看应用程序和系统配置是否存在接近八的设置值。
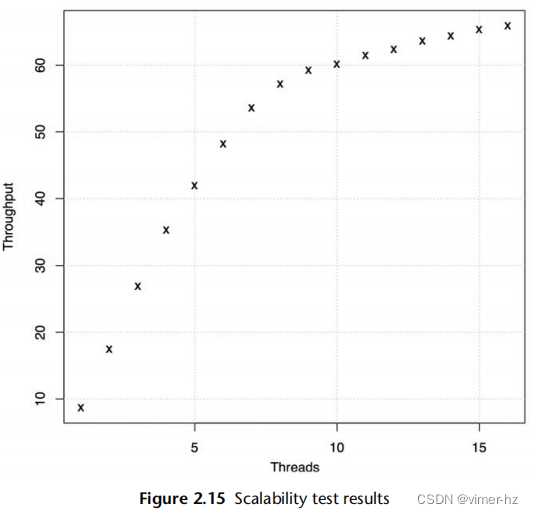
在这种情况下,系统是一个具有八个核心的系统,每个核心具有两个硬件线程。为了进一步确认这与CPU核心数有关,可以调查并比较少于八个和多于八个线程时的CPU影响(例如,CPI;参见第6章,CPU)。或者,可以通过在具有不同核心数的系统上重复进行缩放测试,并确认拐点按预期移动来进行实验性的研究。
有许多可视化识别的可扩展性配置文件,而无需使用正式模型。这些显示在图2.16中。
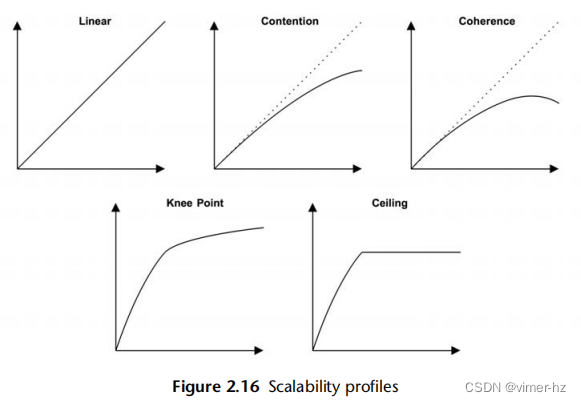
Contention/Coherence/Knee Point/Ceiling
竞争/一致性/拐点/上限
对于每个情况,x轴是可扩展性维度,y轴是结果性能(吞吐量、每秒事务数等)。以下是这些模式:
线性可扩展性:随着资源的扩展,性能成比例增加。这种趋势可能不会一直持续下去,而是可能是另一种可扩展性模式的早期阶段。
竞争:体系结构的某些组件是共享的,并且只能串行使用,对于这些共享资源的竞争开始降低扩展性的效果。
一致性:为了保持数据的一致性,包括传播变化的开销开始超过扩展的好处。
拐点:在某个可扩展性点遇到一个因素,改变了可扩展性配置文件。
可扩展性上限:达到了一个硬性限制。这可能是设备瓶颈,例如总线或互连达到最大吞吐量,或者是软件施加的限制(系统资源控制)。
虽然通过可视化识别可以简单有效,但使用数学模型可以更详细地了解系统的可扩展性。模型可能以意想不到的方式偏离数据,这对于调查很有用:要么模型存在问题,因此您对系统的理解存在问题,要么问题在于系统的实际可扩展性。接下来的章节介绍了Amdahl's Law of Scalability(阿姆达尔定律)、Universal Scalability Law(通用可扩展性定律)和排队理论。
2.6.3 Amdahl’s Law of Scalability
//阿姆达尔可扩展性定律
这条定律以计算机架构师Gene Amdahl [Amdahl 67]的名字命名,它模拟系统的可扩展性,考虑到不以并行方式扩展的串行工作负载组件。它可以用于研究CPU、线程、工作负载等的扩展性。Amdahl's Law of Scalability在之前的可扩展性配置文件中被描述为竞争,描述了对串行资源或工作负载组件的竞争。它可以定义为[Gunther 97]:
C(N) = N/1 + α(N - 1)
其中,相对容量为C(N),N是扩展维度,例如CPU数量或用户负载。参数α(其中0 <= α <= 1)表示串行度的程度,即与线性可扩展性的偏差程度。
可以通过以下步骤应用Amdahl's Law of Scalability:
1. 收集一系列N的数据,可以通过观察现有系统或使用微基准测试或负载生成器进行实验来收集数据。
2. 进行回归分析以确定Amdahl参数(D);可以使用统计软件如gnuplot或R来完成此步骤。
3. 提供结果以进行分析。可以将收集的数据点与模型函数绘制在一起,以预测扩展性并揭示数据与模型之间的差异。这也可以使用gnuplot或R来完成。以下是Amdahl's Law of Scalability回归分析的示例gnuplot代码,以提供执行此步骤的思路:

在R中处理这个类似的代码需要相同的量级,涉及到使用nls()函数进行非线性最小二乘拟合以计算系数,然后在绘图过程中使用这些系数。在本章末尾的参考资料中,可以找到完整的gnuplot和R代码的性能可扩展性模型工具包[2]。下一节将展示一个Amdahl's Law of Scalability函数的示例。
2.6.4 Universal Scalability Law
//通用可扩展性定律
通用可扩展性定律(USL),之前称为超级串行模型[Gunther 97],是由Neil Gunther博士开发的,包括一种相干延迟参数。这在先前被描绘为相干可扩展性配置文件,包括竞争效应。
USL可以定义为
C(N) = N/1 + α(N - 1) + EN(N - 1)
其中,C(N), N和α与Amdahl's Law of Scalability相同。E是相干参数。当E == 0时,这变成了Amdahl's Law of Scalability。
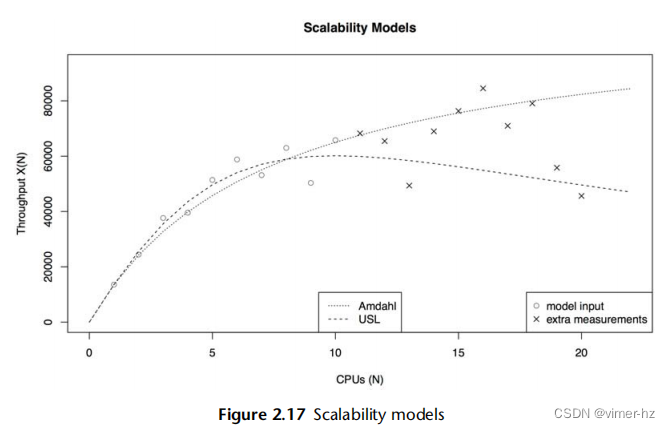
图2.17展示了USL和Amdahl's Law of Scalability分析的示例。输入数据集具有高度的方差,使得难以直观地确定可扩展性配置文件。前十个数据点以圆圈的形式呈现,并提供给模型。还绘制了另外十个数据点,以叉的形式呈现,用于检查模型预测与实际情况之间的差异。
有关USL分析的更多信息,请参见[Gunther 97]和[Gunther 07]。
2.6.5 Queueing Theory
排队论是对具有队列的系统进行数学研究的学科,提供了分析队列长度、等待时间(延迟)和利用率(基于时间)的方法。计算机中的许多组件,包括软件和硬件,都可以建模为排队系统。对多个排队系统进行建模称为排队网络。
本节总结了排队论的作用,并提供了一个示例,以帮助您理解其作用。排队论是一个广泛的研究领域,在其他文献中有详细介绍([Jain 91],[Gunther 97]),如果有需要的话,可以深入学习。
排队论建立在数学和统计学的各个领域基础上,包括概率分布、随机过程、Erlang的C公式(Agner Krarup Erlang发明了排队论)和Little's Law。Little's Law可以表示为
L = λW
其中,L确定系统中的平均请求数,λ是平均到达率,W是平均服务时间,它们相乘得到。
排队系统可以用来回答各种问题,包括以下几个:
- 如果负载加倍,平均响应时间将是多少?
- 添加一个额外的处理器后,平均响应时间会有什么影响?
- 在负载加倍的情况下,系统能否提供小于100毫秒的90th百分位响应时间?
除了响应时间,还可以研究其他因素,包括利用率、队列长度和常驻作业数量。
图2.18显示了一个简单的排队系统模型。
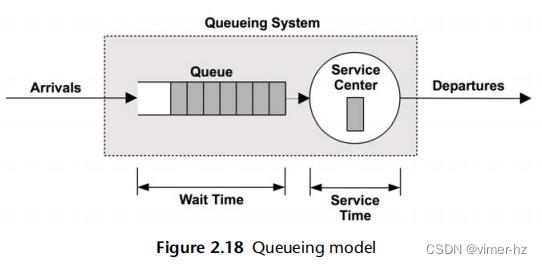
这个系统有一个单一的服务中心,负责处理队列中的作业。排队系统也可以拥有多个并行处理工作的服务中心。在排队论中,这些服务中心通常被称为服务器。
排队系统可以根据三个因素进行分类:
- 到达过程:描述请求到达队列系统的间隔时间,可能是随机的、固定的或者遵循泊松过程(使用指数分布表示到达时间)等。
- 服务时间分布:描述服务中心的服务时间。它们可能是固定的(确定性的)、指数分布的,或者其他类型的分布。
- 服务中心的数量:一个或多个。
这些因素可以用Kendall符号表示。
Kendall’s Notation
这个符号为每个属性分配了代码。它的形式是 A/S/m。这些属性分别表示到达过程 (A)、服务时间分布 (S) 和服务中心的数量 (m)。还有一种扩展形式的Kendall符号,包括更多的因素:系统中的缓冲区数量、总人数和服务纪律。
常见的研究排队系统的例子有:
- M/M/1:马尔可夫到达(指数分布的到达时间)、马尔可夫服务时间(指数分布)、一个服务中心。
- M/M/c:与M/M/1相同,但是有多个服务器。
- M/G/1:马尔可夫到达,服务时间的分布是一般的(可以是任意分布),一个服务中心。
- M/D/1:马尔可夫到达,服务时间是确定性的(固定时间),一个服务中心。
M/G/1常用于研究旋转硬盘的性能。
M/D/1 and 60% Utilization
作为排队论的一个简单例子,考虑一个以确定性方式响应工作负载的硬盘(这是一个简化)。该模型是M/D/1。
提出的问题是:随着利用率的增加,硬盘的响应时间如何变化?
排队论可以计算M/D/1的响应时间:
r = s(2 - U)/2(1 - U)
其中,响应时间 r 是以服务时间 s 和利用率 U 来定义的。
对于服务时间为1毫秒和利用率从0到100%的情况,这个关系已经在图2.19中绘制出来。
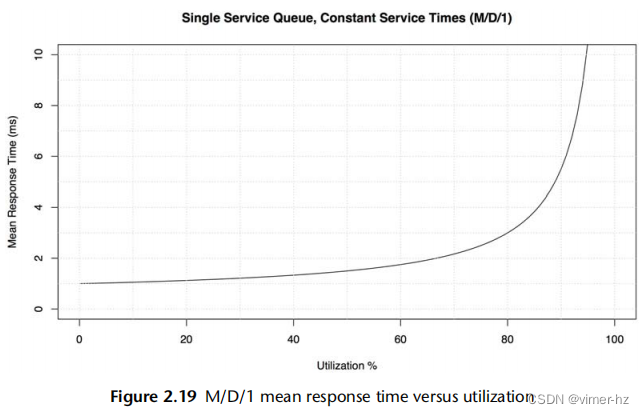
超过60%的利用率后,平均响应时间翻倍。当达到80%时,它会增加三倍。由于磁盘I/O延迟通常是应用程序的限制资源,将平均延迟增加一倍或更多可能会对应用程序性能产生显著的负面影响。这就是为什么磁盘利用率在达到100%之前就可能成为一个问题的原因,因为它是一个排队系统,请求(通常)无法中断,必须等待它们的顺序。这与例如CPU不同,CPU可以进行高优先级的抢占。
这个图形可以直观地回答之前的一个问题:当负载加倍时,平均响应时间将是多少?—这是相对于负载的利用率。
这个模型是简单的,从某种程度上展示了最好的情况。服务时间的变化可能会使平均响应时间增加(例如使用M/G/1或M/M/1)。还有一个响应时间的分布,图2.19中没有显示出来,当利用率超过60%时,第90百分位数和第99百分位数的退化速度要快得多。
与之前关于Amdahl的可扩展性定律的gnuplot示例一样,展示一些实际代码可能有助于了解可能涉及的内容。这次使用了R统计软件[3]:

之前的M/D/1方程已经传递给plot()函数。该代码的大部分部分用于指定图形的限制、线条属性和坐标轴标签。
2.7 Capacity Planning
容量规划(Capacity Planning)考察系统在处理负载时的能力以及随着负载增加而扩展的能力。可以通过多种方式进行容量规划,包括研究资源限制和因素分析(在此介绍),以及建模(如前所述)。本节还包括了扩展的解决方案,包括负载均衡器和分片。有关更多信息,请参阅《容量规划的艺术》[Allspaw 08]。
对于特定应用程序的容量规划,有一个明确的性能目标会有所帮助。在第5章的早期部分讨论了如何确定这个目标。
2.7.1 Resource Limits
这种方法是寻找在负载下将成为瓶颈的资源。其中的步骤如下:
1.测量服务器请求速率,并随时间监控此速率。
2.测量硬件和软件资源使用情况,并随时间监控此速率。
3.以所使用的资源为基础来表达服务器请求。
4.将服务器请求外推到每个资源的已知(或经过实验确定的)限制。
首先要确定服务器的角色和它所服务的请求类型。例如,Web服务器提供HTTP请求服务,网络文件系统(NFS)服务器提供NFS协议请求(操作)服务,数据库服务器提供查询请求服务(或者是命令请求,而查询是其中的一个子集)。
下一步是确定每个请求对系统资源的消耗量。对于现有系统,可以测量当前请求速率以及资源利用情况。然后可以使用外推法来确定哪个资源将首先达到100%利用率以及请求速率是多少。
对于未来的系统,可以使用微基准测试或负载生成工具在测试环境中模拟预期的请求,同时测量资源利用情况。在足够的客户端负载下,您可以通过实验找到极限。
需要监控的资源包括:
硬件:CPU利用率、内存使用情况、磁盘IOPS、磁盘吞吐量、磁盘容量(已使用的卷)、网络吞吐量
软件:虚拟内存使用情况、进程/任务/线程、文件描述符
假设您正在查看一个目前每秒执行1,000个请求的现有系统。最繁忙的资源是16个CPU,平均利用率为40%;您预测一旦它们达到100%利用率,它们将成为这个工作负载的瓶颈。问题是:此时请求每秒的速率是多少?
每个请求的CPU% = 总CPU%/请求数 = 16 x 40%/1,000 = 0.64% CPU per request
最大请求速率 = 100% x 16 CPUs/CPU% per request = 1,600 / 0.64 = 2,500 requests/s
预测结果是每秒2,500个请求,此时CPU将达到100%利用率。这是容量的一个粗略的最佳估计,因为在请求达到该速率之前可能会遇到其他限制因素。
此次演习仅使用了一个数据点:1,000个应用程序吞吐量(每秒请求数)与40%的设备利用率。如果启用随时间的监控,可以包括不同吞吐量和利用率的多个数据点,以提高估计的准确性。图2.20展示了一种用于处理这些数据并推断最大应用程序吞吐量的可视化方法。
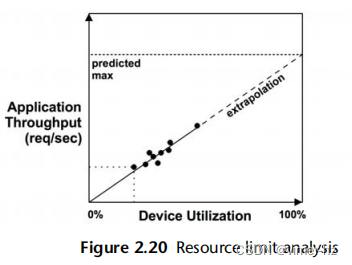
2,500个请求/秒足够吗?回答这个问题需要了解峰值工作负载,它显示在每日访问模式中。对于您经过一段时间监控的现有系统,您可能已经知道峰值会是什么样子。
考虑一个处理每天10万个网站点击的Web服务器。这听起来很多,但平均每秒只有约1个请求,不算多。然而,可能大多数的10万个网站点击发生在发布新内容后的几秒钟内,所以峰值是显著的。
2.7.2 Factor Analysis
在购买和部署新系统时,通常有许多因素可以改变以实现所需的性能。这些因素可能包括磁盘和CPU的数量、内存的大小、闪存设备的使用、RAID配置、文件系统设置等等。任务通常是以最低成本实现所需的性能。
测试所有组合将确定哪种组合具有最佳的性价比;然而,这很容易失控:八个二进制因素将需要进行256次测试。
一种解决方法是测试一组有限的组合。以下是一种基于已知最大系统配置的方法:
1. 将所有因素配置为最大值进行性能测试。
2. 逐个更改因素,测试性能(每次测试应该会降低)。
3. 根据测量结果,将性能下降的百分比归因于每个因素,以及与成本节省相关的情况。
4. 从最大性能(和成本)开始,选择要节省成本的因素,同时基于它们的综合性能下降来保持所需的每秒请求数。
5. 对计算得到的配置进行重新测试,以确认所提供的性能。
对于一个八因素系统,这种方法可能只需要进行十次测试。
以一个新存储系统的容量规划为例,要求读取吞吐量为1 Gbyte/s,工作集大小为200 Gbyte。最大配置可实现2 Gbytes/s,并包括四个处理器、256 Gbytes的DRAM、2个双端口10 GbE网络卡、巨型帧,并禁用压缩和加密(启用这些功能会增加成本)。切换到两个处理器将使性能下降30%,一个网络卡下降25%,非巨型帧下降35%,加密下降10%,压缩下降40%,DRAM减少90%,因为工作负载不再被预期完全缓存。根据这些性能下降和已知的节省情况,现在可以计算出满足要求的最佳性价比系统;可能是一个具有两个处理器和一个网络卡的系统,达到所需的吞吐量:2 × (1 - 0.30) × (1 - 0.25) = 1.04 Gbytes/s 的估计值。然后明智的做法是测试这个配置,以防这些组件在一起使用时的实际性能与预期性能不同。
2.7.3 Scaling Solutions
满足更高的性能需求通常意味着使用更大的系统,这种策略被称为纵向扩展。将负载分布在多个系统上,通常通过称为负载均衡器的系统来实现,使它们看起来像一个系统,这被称为横向扩展。
云计算进一步发展了横向扩展,通过基于较小的虚拟化系统而不是整个系统来构建。这在购买用于处理所需负载的计算资源时提供了更细粒度的控制,并允许以小而高效的增量进行扩展。由于不需要像企业主机那样进行初始的大规模采购(包括支持合同承诺),因此在项目的早期阶段不需要进行严格的容量规划。
云上数据库的常见扩展策略是分片,即将数据分割为逻辑组件,每个组件由自己的数据库(或冗余数据库组)管理。例如,可以按照客户名称的字母范围将客户数据库分割为多个部分。
可扩展性设计非常依赖于您需要处理的工作负载和希望使用的应用程序。有关更多信息,请参阅《可扩展的互联网架构》[Schlossnagle 06]。
2.8 Statistics
了解如何使用统计数据以及它们的局限性非常重要。本节将讨论使用统计数据(指标)和统计类型来量化性能问题,包括平均值、标准差和百分位数。
2.8.1 Quantifying Performance
量化问题及其潜在的性能改进,可以对它们进行比较和优先排序。这项任务可以使用观察或实验来完成。
基于观察的方法
使用观察来量化性能问题的步骤如下:
1. 选择一个可靠的指标。
2. 估计解决该问题后的性能提升。
例如:
观察到:应用程序请求需要10毫秒。
观察到:其中9毫秒用于磁盘I/O操作。
建议:配置应用程序将I/O缓存在内存中,预计DRAM延迟约为10微秒。
预计的改进:10毫秒÷1.01毫秒(10毫秒-9毫秒+10微秒)≈ 9倍的改进。
正如在第2.3节“概念”中介绍的那样,延迟(时间)非常适合这个场景,因为可以直接在组件之间进行比较,从而使得这种计算成为可能。
在使用延迟时,请确保将其作为应用程序请求的同步组件进行测量。某些事件是异步发生的,例如后台磁盘I/O(写入刷新到磁盘),并不直接影响应用程序性能。
基于实验的方法
使用实验来量化性能问题的步骤如下:
1. 应用修复措施。
2. 使用可靠的指标量化修复前后的性能差异。
例如:
观察到:应用程序事务延迟平均为10毫秒。
实验:增加应用程序线程数以允许更多并发而不是排队。
观察到:应用程序事务延迟平均为2毫秒。
改进:10毫秒÷2毫秒 = 5倍的提升。
如果修复在生产环境中尝试成本过高,则此方法可能不适用!
2.8.2 Averages
平均值代表一个数据集的单个值:中心趋势指标。最常用的平均值类型是算术平均值(或简称平均值),它是值的总和除以值的数量。其他类型包括几何平均数和调和平均数。
几何平均数
几何平均数是乘积值的第n个根(其中n是值的数量)。这在[Jain 91]中有描述,其中包括一个使用它进行网络性能分析的示例:如果分别测量内核网络堆栈的每个层的性能改进,那么平均性能改进是多少?由于这些层在同一个数据包上一起工作,性能改进具有“乘法”效应,最好通过几何平均数来总结。
调和平均数
调和平均数是值的数量除以它们的倒数之和。它在计算速率的平均值时可能更合适,例如,在计算800 M字节数据的平均传输速率时,前100 M字节将以50 M字节/秒的速率发送,而剩下的700 M字节将以限速速率10 M字节/秒发送。使用调和平均数,答案是800/(100/50 + 700/10) = 11.1 M字节/秒。
随时间变化的平均值
在性能方面,我们研究的许多指标都是随时间变化的平均值。CPU从来不会处于“50%的利用率”状态;它在某个时间间隔内被利用了50%,这个时间间隔可以是一秒、一分钟或一小时。在考虑平均值时,检查时间间隔非常重要。
例如,我曾遇到一个问题,客户在CPU饱和(调度延迟)引起的性能问题,尽管他们的监控工具显示CPU利用率从未超过80%。监控工具报告的是5分钟的平均值,这掩盖了CPU利用率在某些时刻达到100%的情况。
衰减平均值
在系统性能中,有时会使用衰减平均值。例如,uptime(1)报告的系统“负载平均值”和基于Solaris的系统上的每个进程的CPU利用率。
衰减平均值仍然是在一个时间区间内测量的,但是最近的时间比过去的时间更加重要。这减少(抑制)了平均值中的短期波动。
详细了解这方面内容,请参阅第6章“CPU”中第6.6节“负载平均值”。
2.8.3 Standard Deviations, Percentiles, Median
标准差和百分位数(例如,第99百分位数)是提供有关数据分布的统计技术。标准差是方差的一种度量,较大的值表示与平均值(均值)的差异较大。第99百分位数显示了包括99%的值的分布点。图2.21展示了正态分布中的这些值,以及最小值和最大值。
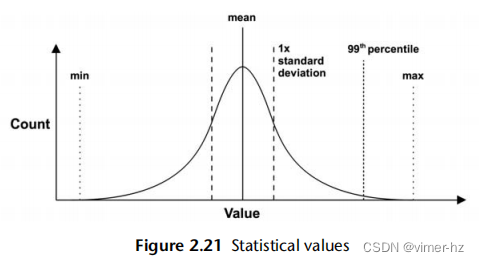
百分位数,例如第99、90、95和99.9百分位数,用于性能监测请求延迟,以量化人群中最慢的部分。这些百分位数也可以在服务级别协议(SLA)中指定,作为衡量大多数用户接受性能的一种方式。
第50百分位数,称为中位数,可以用来显示数据的大部分所在位置。
2.8.4 Coefficient of Variation
由于标准差与均值相关,只有在考虑到标准差和均值时,方差才能被理解。单独一个标准差为50的信息并不多。但是,如果再加上均值为200,那就能得到很多信息。
有一种方法可以将变异性表示为一个单一的度量:标准差与均值的比率,称为变异系数(CV)。对于这个例子,变异系数为25%。较低的变异系数意味着较小的方差。
2.8.5 Multimodal Distributions
对于平均值、标准差和百分位数存在一个问题,这可能从前面的图表中就能明显看出:它们适用于正态分布或单峰分布。系统性能通常是双峰分布的,对于快速代码路径返回低延迟,对于慢速代码路径返回高延迟,或者对于缓存命中返回低延迟,对于缓存未命中返回高延迟。也可能存在多个模式。
图2.22展示了读写混合工作负载下磁盘I/O延迟的分布情况,其中包括随机和顺序I/O。
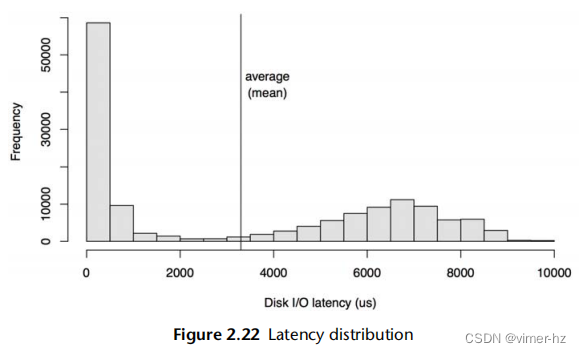
这是一个以直方图形式呈现的数据,显示了两个模式。左边的模式显示了小于1毫秒的延迟,表示磁盘缓存命中。右边的模式,峰值约在7毫秒左右,表示磁盘缓存未命中:随机读取。平均(均值)I/O延迟为3.3毫秒,用一条垂直线表示。这个平均值不是中心趋势指标(如前面所述);实际上,它几乎是相反的。作为一个度量指标,对于这个分布来说,平均值严重误导。
然后有一个人淹死在一个平均水深为六英寸的小溪里。
W. I. E. Gates
每当你看到平均值作为性能指标,尤其是平均延迟时,请问一下:这个分布是怎样的?第2.10节,可视化,提供了另一个例子,展示了不同的可视化和度量指标如何有效地显示这个分布情况。
2.8.6 Outliers
另一个统计问题是离群值的存在:极少量的极高或极低的值,不符合预期的分布(单峰或多峰)。
磁盘I/O延迟离群值就是一个例子——偶尔出现的磁盘I/O可能需要超过1,000毫秒,而大多数磁盘I/O在0到10毫秒之间。像这样的延迟离群值会导致严重的性能问题,但它们的存在很难从大多数度量类型中识别出来,除了最大值之外。
对于正态分布,离群值的存在可能会使均值略微移动,但不会影响中位数(这可能有用)。标准差和99百分位数更有可能识别出离群值,但仍取决于它们的频率。
为了更好地理解多峰分布、离群值和其他复杂的常见行为,可以检查完整的分布,比如使用直方图。有关如何进行此操作的更多方法,请参见第2.10节,可视化。
2.9 Monitoring
系统性能监控会记录随时间变化的性能统计信息(时间序列),以便将过去与现在进行比较,并识别基于时间的使用模式。这对于容量规划、量化增长以及显示峰值使用情况很有用。历史值也可以提供上下文来理解性能指标的当前值,通过显示过去的“正常”范围和平均值。
2.9.1 Time-Based Patterns
图2.23、2.24和2.25展示了基于时间的模式示例,这些图表显示了云计算服务器在不同时间间隔内的文件系统读取情况。这些图形显示了每天的模式,从早上8点左右开始增加,下午稍微下降,然后在夜间逐渐减少。较长时间尺度的图表显示,在周末活动较少。在30天的图表中也可以看到几个短暂的尖峰。
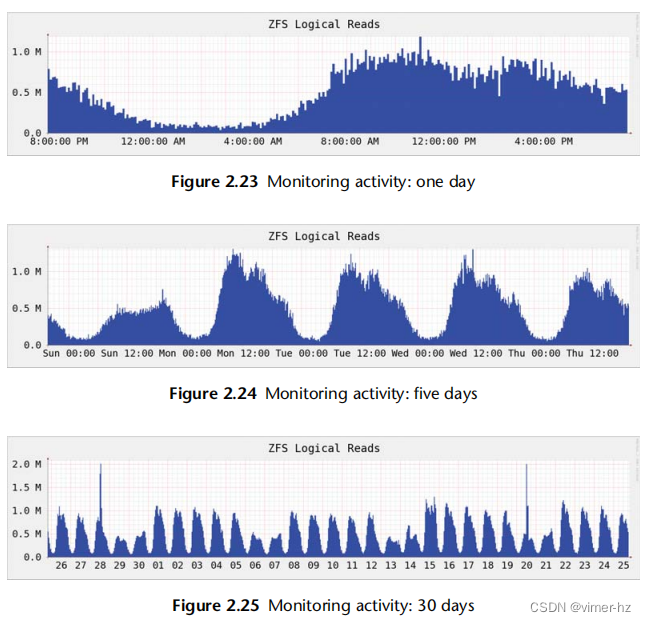
在历史数据中,可以常见地看到各种行为周期,包括图表中显示的周期,例如:
按小时:应用环境可能每小时执行一次活动,如监控和报告任务。这些活动通常以5分钟或10分钟的周期执行。
按天:可能存在与工作时间(上午9点至下午5点)相一致的每日使用模式,如果服务器面向多个时区,则该模式可能会延伸。对于互联网服务器,模式可能会根据全球用户的活动时间而变化。其他每日活动可能包括夜间日志轮换和备份。
按周:除了每日模式外,还可能存在基于工作日和周末的每周模式。
按季度:财务报告按季度进行。其他活动可能会导致负载不规则增加,例如发布网站上的新内容。
2.9.2 Monitoring Products
有许多用于系统性能监控的第三方产品。典型的功能包括将数据存档并以基于浏览器的交互式图形方式呈现,并提供可配置的警报。
其中一些产品通过在系统上运行代理来收集统计信息。这些代理要么执行操作系统的可观察性工具(如sar(1)),然后处理输出(这被认为效率低下,甚至可能导致性能问题!),要么直接链接到操作系统库和接口以直接读取统计信息。
还有一些使用SNMP的监控解决方案。如果系统支持SNMP,则通常无需在系统上运行自定义代理。
随着系统变得更加分布式,并且使用云计算的增长,您可能需要监控大量的系统,甚至可能是数百个或数千个。这就是集中式监控产品尤其有用的地方,它可以允许从一个界面监控整个环境。
一些公司更倾向于开发自己的监控解决方案,以更好地适应其定制环境和需求。
2.9.3 Summary-since-Boot
如果没有进行监控,请检查操作系统是否至少提供了自启动以来的摘要值,这些值可用于与当前值进行比较。
2.10 Visualizations
可视化允许我们查看更多的数据,而不仅仅是在文本显示中能够看到的内容。它们还可以实现模式识别和模式匹配。这是一种有效的方法,可以帮助我们发现不同指标来源之间的相关性,这可能在编程上很难实现,但在视觉上很容易做到。
2.10.1 Line Chart
折线图(也称为线图)是一种众所周知的基本可视化工具。它通常用于随时间变化检查性能指标,将时间显示在x轴上。
图2.26是一个示例,显示了一个20秒周期内的平均磁盘I/O延迟。这是在运行MySQL数据库的生产云服务器上测量的,怀疑磁盘I/O延迟导致查询速度缓慢。
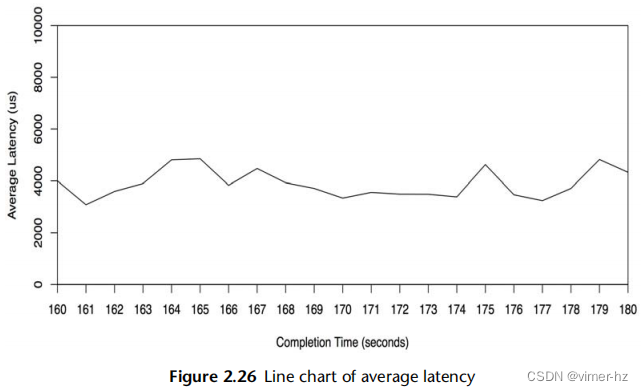
这个折线图显示了大约4毫秒左右的相对一致的平均读取延迟,这高于这些磁盘的预期值。
可以绘制多条线,将相关数据显示在同一组坐标轴上。对于这个示例,可以为每个磁盘绘制单独的线条,以显示它们是否具有类似的性能。
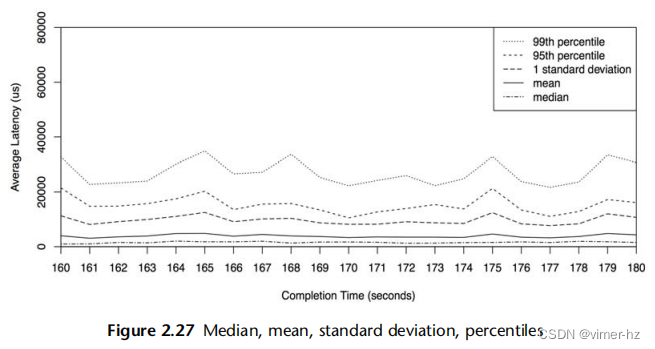
还可以绘制统计值,提供有关数据分布的更多信息。图2.27显示了相同范围的磁盘I/O事件,添加了每秒钟的中位数、标准差和百分位数的线条。请注意,与之前的折线图相比,y轴现在具有更大的范围(扩大了8倍)。
这显示了为什么平均值高于预期:分布中包含了高延迟的I/O操作。具体而言,1%的I/O操作超过20毫秒,由第99百分位数显示。中位数也显示了预期的I/O延迟位置,大约为1毫秒。
2.10.2 Scatter Plots
图2.28以散点图的形式显示了与之前相同时间段内的磁盘I/O事件,这样可以看到所有的数据。每个磁盘I/O操作被绘制为一个点,其完成时间显示在x轴上,延迟显示在y轴上。
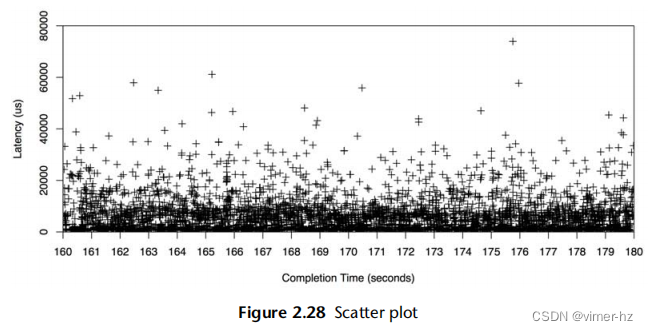
现在可以完全理解高于预期的平均延迟的原因了:存在许多延迟为10毫秒、20毫秒甚至超过50毫秒的磁盘I/O操作。散点图显示了所有的数据,揭示了这些异常值的存在。
许多I/O操作的延迟是亚毫秒级别的,接近x轴。这是散点图分辨率开始成为问题的地方,因为点会重叠在一起,难以区分。随着数据量的增加,问题会变得更加严重:想象一下在一个散点图上绘制来自整个云环境的事件,涉及数百万个数据点。另一个问题是必须收集和处理的数据量:每个I/O操作都需要x和y坐标。
2.10.3 Heat Maps
热力图可以通过将x和y范围量化为称为桶的组来解决散点图的可扩展性问题。这些桶以大像素的形式显示,并根据该x和y范围内的事件数量进行着色。这种量化也解决了散点图的视觉密度限制,使得热力图可以以相同的方式显示来自单个系统或数千个系统的数据。它们可以用于分析延迟、利用率和其他指标【Gregg 10a】。
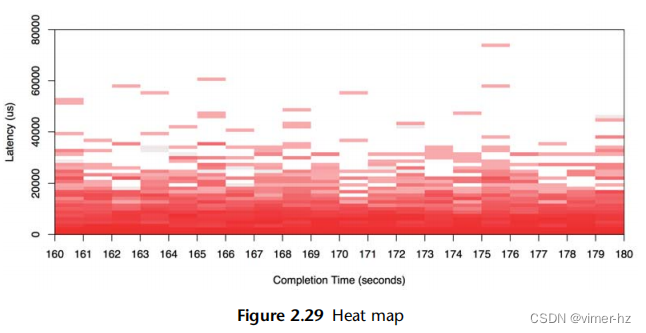
与之前绘制的相同数据集在图2.29中显示为热力图。
高延迟的异常值可以通过热力图中颜色较浅的大块来识别,因为它们跨越很少的I/O操作(通常是单个I/O操作)。数据的主体部分开始出现模式,这些模式在散点图中可能无法看到。
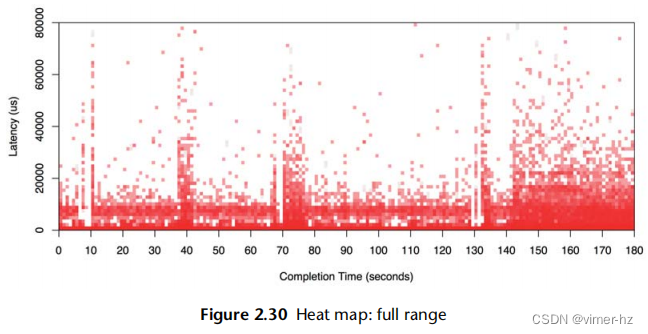
图2.30的热力图显示了此磁盘I/O跟踪的完整秒数范围(之前未显示)。
尽管跨越了九倍的范围,但可视化仍然非常易读。在很大的范围内可以看到双峰分布,其中一些I/O操作的延迟接近于零(可能是磁盘缓存命中),而其他一些I/O操作的延迟略低于1毫秒(可能是磁盘缓存未命中)。
热力图的一个问题是它们还不像折线图那样广为人知,因此用户必须获得一些理解才能有效地使用它们。
本书后面还有各种其他热力图的示例。
2.10.4 Surface Plot
这是一个表示三个维度的三维表面。当第三维的值在相邻点之间不频繁地发生剧烈变化时,它的效果最好,形成了类似起伏山丘的表面。

表面绘图通常以线框模型的形式呈现。图2.31显示了每个CPU利用率的线框表面图。它包含来自许多服务器的60秒每秒值(这是从覆盖了超过300个物理服务器和5,312个CPU的数据中心的图像裁剪出来的)[4]。
每个服务器通过在表面上将其16个CPU作为行进行绘制,将60个每秒的利用率测量作为列,并将表面的高度设置为利用率值。颜色也根据利用率值设置。如果需要,色调和饱和度都可以用来添加第四和第五个维度的数据可视化。(如果分辨率足够高,还可以使用图案来表示第六个维度。)
然后,将这些16 x 60个服务器矩形映射到表面上,形成一个棋盘格。即使没有标记,图像中仍然可以清楚地看到一些服务器矩形。在右侧出现的一个被提升的高原表明其CPU几乎始终处于100%的利用率。
使用网格线突出显示高度的微妙变化。一些淡淡的线条可见,表明一个单独的CPU始终以较低的利用率运行(几个百分比)。
2.10.5 Visualization Tools
由于图形支持有限,Unix性能分析在历史上通常侧重于使用基于文本的工具。这样的工具可以在登录会话中快速执行,并实时报告数据。可视化方面的工具更需要花费时间来获取,并且通常需要进行追踪和报告的循环。在处理紧急性能问题时,您可以访问指标的速度至关重要。
现代的可视化工具提供了系统性能的实时视图,可以从浏览器和移动设备上访问。有许多产品可以实现这一点,包括可以监控整个云端的产品,例如Joyent的Cloud Analytics,这是一个基于DTrace的云端分析工具,可以生成包括延迟热图在内的实时可视化。
3 Operating Systems
了解操作系统及其内核对系统性能分析至关重要。您经常需要制定并测试有关系统行为的假设,例如系统调用的执行方式、CPU如何调度线程、有限的内存如何影响性能以及文件系统如何处理I/O。这些行为将需要您应用您对操作系统和内核的知识。
本章概述了操作系统和内核,并假定读者已具备相关知识,是本书的基础。如果您错过了操作系统课程,可以将本章视为快速课程。请留意您所了解的知识中是否存在任何漏洞,因为本章末尾将有一个小测验(开玩笑,只是一个小测试)。有关内核内部的更多信息,请参见本章末尾的参考文献和参考书目。
本章分为两个部分:
背景介绍了术语和操作系统基础知识。
内核概述了基于Linux和Solaris的内核。
有关性能的相关领域,包括CPU调度、内存、磁盘、文件系统、网络和许多特定的性能工具,将在接下来的章节中进行更详细的介绍。
3.1 Terminology
供参考,以下是本书中使用的核心操作系统术语:
操作系统:这指的是安装在系统上的软件和文件,使其能够启动和执行程序。它包括内核、管理工具和系统库。
内核:内核是管理系统的程序,包括设备(硬件)、内存和CPU调度。它运行在允许直接访问硬件的特权CPU模式中,称为内核模式。
进程:用于执行程序的OS抽象和环境。程序通常在用户模式下运行,并通过系统调用或陷阱访问内核模式(例如,执行设备I/O)。
线程:可安排在CPU上运行的可执行上下文。内核有多个线程,一个进程包含一个或多个线程。
任务:Linux可运行实体,可以引用单个线程的进程、来自多线程进程的线程或内核线程。
内核空间:内核的内存地址空间。
用户空间:进程的内存地址空间。
用户层:用户级程序和库(/usr/bin、/usr/lib等)。
上下文切换:内核例程,它将CPU切换到不同的进程地址空间(上下文)中进行操作。
系统调用(syscall):用户程序请求内核执行特权操作的一种明确定义的协议,包括设备I/O。
处理器:不要与进程混淆,处理器是一个包含一个或多个CPU的物理芯片。
陷阱:发送到内核的信号,请求系统例程(特权操作)。陷阱类型包括系统调用、处理器异常和中断。
中断:由物理设备发送到内核的信号,通常是请求I/O服务的信号。中断是陷阱的一种类型。
术语表中包括更多本章需要参考的术语,包括地址空间、缓冲区、CPU、文件描述符、POSIX和寄存器。
3.2 Background
以下各节描述操作系统的概念和通用内核内部。这些部分之后将涵盖特定的内核差异。
3.2.1 Kernel
内核管理CPU调度、内存、文件系统、网络协议和系统设备(磁盘、网络接口等)。它通过系统调用提供对设备和基于它们构建的内核服务的访问。图3.1显示了它的示意图。

//Applications如何直接访问System Calls?
还显示了系统库,通常用于提供比仅使用系统调用更丰富和更易于编程的接口。应用程序包括所有正在运行的用户级软件,包括数据库、Web服务器、管理工具和操作系统Shell。
在这里,系统库被描绘为一个断开的环,以显示应用程序可以直接调用系统调用(如果操作系统允许)。传统上,这个图示是用完整的环来绘制的,反映了从中心核心开始的不同特权级别的递减(这个模型起源于Multics[Graham 68],Unix的前身)。
Kernel Execution
内核是一个庞大的程序,通常包含数十万行代码。它主要根据需求执行,当用户级程序发出系统调用或设备发送中断时执行。一些内核线程异步运行以进行日常维护工作,这可能包括内核时钟例程和内存管理任务,但它们试图轻量化并且消耗非常少的CPU资源。频繁进行I/O操作的工作负载(如Web服务器)通常在内核上下文中执行。计算密集型的工作负载尽可能地被内核保持独立,以便在CPU上无间断地运行。也许会认为内核不能影响这些工作负载的性能,但实际上存在许多情况会受到影响。最明显的是CPU争用,当其他线程竞争CPU资源时,内核调度器需要决定哪个线程将运行,哪个线程将等待。内核还会选择在哪个CPU上运行线程,并且可以选择具有较暖的硬件缓存或更好的进程内存局部性的CPU,从而显著提高性能。
//感觉multi-core cpu越来越重要了!
Clock
Unix内核的一个核心组件是clock()例程,它是从定时器中断执行的。它在过去通常以每秒60次、100次或1,000次的频率执行,每次执行被称为一个tick。它的功能包括更新系统时间、处理定时器和线程调度的时间片、维护CPU统计信息以及执行调用(预定的内核例程)。
在早期的内核中,clock存在性能问题,在后续的内核中得到改进,包括:
- Tick延迟:对于100 Hz的时钟,一个定时器可能会等待下一个tick的处理而产生高达10毫秒的额外延迟。通过使用高分辨率实时中断来修复这个问题,使得执行立即进行而无需等待。
- Tick开销:现代处理器具有动态电源特性,可以在空闲期间关闭部分电源。而clock例程会打断这个过程,对于空闲系统来说可能会不必要地消耗电力。Linux实现了动态ticks,因此当系统处于空闲状态时,定时器例程(clock)不会触发。
现代内核将许多功能从clock例程移出到按需中断中,以创建一个无tick的内核。其中包括Linux,其中的clock例程(即系统定时器中断)除了更新系统时钟和jiffies计数器(jiffies是Linux中的一种时间单位,类似于ticks)之外几乎不执行其他工作。
Kernel Mode
内核是在一种称为内核模式的特殊CPU模式下运行的唯一程序,允许对设备进行完全访问并执行特权指令。内核调解设备访问以支持多任务处理,防止进程和用户在没有明确许可的情况下访问彼此的数据。
用户程序(进程)在用户模式下运行,它们通过系统调用向内核请求特权操作,例如进行I/O操作。要执行系统调用,执行将从用户模式切换到内核模式,然后以较高的权限级别执行。这在图3.2中显示。

每个模式都有自己的软件执行状态,包括堆栈和寄存器。在用户模式下执行特权指令会引发异常,然后由内核进行适当处理。
这些模式(用户模式和内核模式)之间的切换需要时间(CPU周期),这为每个I/O操作增加了一小部分开销。一些服务,例如NFS,已被实现为内核模式软件(而不是用户模式守护程序),这样它们可以在不需要切换到用户模式的情况下执行与设备之间的I/O操作。
如果系统调用在执行过程中阻塞,进程可能会从CPU上切换下来,并被另一个进程取代:这称为上下文切换。
3.2.2 Stacks
栈以函数和寄存器的形式包含了线程的执行祖先。CPU使用栈来高效地处理本地软件中的函数执行。
当调用一个函数时,当前CPU寄存器的集合(存储CPU状态)会保存到栈中,并在栈顶为当前线程的当前执行添加一个新的栈帧。函数通过调用“返回”CPU指令来结束执行,该指令会移除当前的栈并将执行返回到先前的栈中,恢复其状态。
栈检查是调试和性能分析的宝贵工具。栈显示了当前执行的调用路径,这通常可以解答为什么会执行某个操作的问题。
How to Read a Stack
下面是一个示例内核栈(来自Linux),显示了TCP传输的路径,由一个调试工具打印出来:

栈的顶部通常显示为第一行。在这个示例中,它包括了正在执行的函数的名称tcp_sendmsg。函数名称的左右两边是调试器通常包含的细节:内核模块位置(`kernel)和指令偏移量(0x1,它指的是函数内的指令地址)。
调用tcp_sendmsg()的函数(其父函数)可以在其下面看到:inet_sendmsg()。而其父函数则在其下面:sock_aio_write()。通过阅读栈,可以看到完整的祖先链:函数、父函数、祖父函数等等。或者,通过自底向上阅读,可以追踪到当前函数的执行路径:我们是如何到达这里的。
由于栈展示了源代码中的内部路径,这些函数通常没有其他文档,除了代码本身。对于这个示例栈来说,这就是Linux内核源代码。一个例外是那些作为API的一部分并且有公共文档的函数。
User and Kernel Stacks
在执行系统调用时,一个进程线程有两个栈:用户级栈和内核级栈。它们的范围如图3.3所示。

在系统调用期间,被阻塞的线程的用户级栈不会改变,因为线程在内核上下文中执行时使用的是一个单独的内核级栈。(一个例外是信号处理程序,根据其配置可能会借用一个用户级栈。)
3.2.3 Interrupts and Interrupt Threads
除了响应系统调用外,内核还会响应来自设备的服务请求。这些被称为中断,因为它们会中断当前的执行。这在图3.4中有所描述。

设备中断会注册一个中断服务例程来处理。这些例程被设计成尽可能快地运行,以减少对活动线程的中断影响。如果一个中断需要执行更多的工作,特别是如果它可能在锁上阻塞,那么可以由内核调度一个中断线程来处理。
这个实现取决于内核版本。在Linux上,设备驱动程序可以被建模为两个部分,顶半部分快速处理中断,并将工作调度给底半部分以便稍后处理[Corbet 05]。快速处理中断很重要,因为顶半部分在禁止中断模式下运行,以推迟新中断的传递,如果运行时间过长,可能会对其他线程造成延迟问题。底半部分可以是任务(let)或工作队列(work queue);后者是由内核调度并在需要时可以睡眠的线程。基于Solaris的系统会将中断提升为中断线程,如果需要执行更多的工作[McDougall 06a]。
从中断到达到服务的时间被称为中断延迟,这取决于具体的实现方式。这是实时或低延迟系统研究的课题。
3.2.4 Interrupt Priority Level
中断优先级(IPL)表示当前活动的中断服务例程的优先级。在传递中断信号期间,它是从处理器中读取的,只有当其优先级高于当前正在执行的中断(如果有的话),中断才会成功;否则,中断将排队等待稍后处理。这样可以防止较低优先级的工作中断较高优先级的工作。

图3.5显示了一个例子中断优先级范围,对于此内核服务而言,IPL1到IPL10是中断线程。
串行I/O具有较高的中断优先级,因为其硬件缓冲区通常较小,需要快速服务以避免溢出。
3.2.5 Processes
进程是执行用户级程序的环境。它由内存地址空间、文件描述符、线程栈和寄存器组成。在某些方面,进程类似于虚拟的早期计算机,只有一个程序正在执行,具有自己的寄存器和堆栈。
内核通过多任务处理进程,通常在单个系统上支持数千个进程的执行。它们分别由它们的进程ID(PID)唯一标识。
进程包含一个或多个线程,它们在进程地址空间中操作并共享相同的文件描述符(表示打开文件的状态)。线程是一个可执行的上下文,由堆栈、寄存器和程序计数器组成。多个线程允许单个进程在多个CPU上并行执行。
Process Creation
通常使用fork()系统调用创建进程。这将创建一个进程的副本,具有自己的进程ID。然后可以调用exec()系统调用来开始执行不同的程序。
图3.6显示了一个示例进程创建过程,shell(sh)执行ls命令。

fork()系统调用可能使用写时复制(COW)策略来提高性能。这会向先前的地址空间添加引用,而不是复制所有内容。一旦任何一个进程修改了多次引用的内存,就会为修改创建一个单独的副本。该策略延迟或消除了复制内存的需要,减少内存和CPU的使用。
Process Life Cycle
进程的生命周期如图3.7所示。这是一个简化的图表;对于现代多线程操作系统,调度和运行的是线程,并且有关如何将这些映射到进程状态的一些额外实现细节(供参考,请参阅内核源代码中的proc.h文件)。

在处理器(CPU)上运行时,进程处于运行状态。准备运行状态是指进程可运行,但正在等待在 CPU 运行队列中轮到它运行。I/O 操作会阻塞进程,将其置于睡眠状态,直到 I/O 完成并唤醒进程。僵尸状态发生在进程终止期间,进程将等待其进程状态被父进程读取,或者直到被内核移除。
Process Environment
进程环境如图3.8所示,它由进程的地址空间中的数据和内核中的元数据(上下文)组成。

//这个图很清晰!!!
内核上下文包括各种进程属性和统计信息:进程ID(PID),所有者的用户ID(UID)以及各种时间。通常可以通过ps(1)命令进行检查。它还具有一组文件描述符,用于引用打开的文件,这些文件描述符(通常)在线程之间共享。
此示例显示了两个线程,每个线程都包含一些元数据,包括内核上下文中的优先级和用户地址空间中的堆栈。该图表没有按比例绘制;与进程地址空间相比,内核上下文非常小。
用户地址空间包含进程的内存段:可执行文件、库和堆。有关更多详细信息,请参阅第7章"内存"。
3.2.6 System Calls
系统调用是请求内核执行特权系统例程的操作。可用的系统调用数量在数百个,但会尽量保持这个数量尽可能小,以保持内核的简洁性(Unix哲学;[Thompson 78])。更复杂的接口可以在用户空间构建在它们之上作为系统库,在那里更容易开发和维护。
需要记住的关键系统调用列在表3.1中。


系统调用都有详细的文档,通常与操作系统一起提供。它们的接口通常简单而一致,其中包括设置一个特殊变量 errno,以指示是否遇到错误及其类型。
许多系统调用有明显的目的。以下是一些常见用途不太明显的系统调用:
ioctl():通常用于向内核请求各种操作,特别是对于系统管理工具,在其他(更明显)的系统调用不适用的情况下使用。可以参考下面的示例。
mmap():通常用于将可执行文件和库文件映射到进程的地址空间中,以及进行内存映射文件。有时它也被用来分配进程的工作内存,而不是基于 brk() 的 malloc(),以减少系统调用的频率并提高性能(这并不总是有效的,因为这涉及到权衡:内存映射管理)。
brk():用于扩展堆指针,定义进程的工作内存大小。通常由系统内存分配库执行,当堆中的现有空间无法满足 malloc()(内存分配)调用时使用。详见第7章"内存"。
如果对某个系统调用不熟悉,可以在其 man page 中了解更多信息(这些位于第2节:syscalls)。
ioctl() 系统调用可能是最难学习的,因为其含义不明确。以 Linux 中的 perf(1) 工具(在第6章"处理器"中介绍)的使用为例,它执行特权操作以协调性能工具。而不是为每个动作添加系统调用,只添加了一个系统调用:perf_event_open(),它返回一个文件描述符,可与 ioctl() 一起使用。然后可以使用不同的参数来调用这个 ioctl() 以执行不同的操作。例如,ioctl(fd, PERF_EVENT_IOC_ENABLE) 可以启用性能工具。在这个示例中,参数 PERF_EVENT_IOC_ENABLE 更容易由开发人员添加和更改。
/*mmap内存映射的内存和malloc()分配的堆内存的区别:
1 malloc() 分配的堆内存来自进程的堆空间,而 mmap() 内存映射的内存通常与文件或设备相关联。
2 对于 malloc() 分配的堆内存,一般只有当前进程可以直接访问。而 mmap() 内存映射的内存可以通过多个进程共享,实现进程间的通信和共享数据。
*/
/*
进程内存分布图:
https://blog.csdn.net/m0_65346989/article/details/130395560

问题:mmap内存映射的内存对应图中哪个位置?
*/
3.2.7 Virtual Memory
虚拟内存是主存的一种抽象,为进程和内核提供了自己的、几乎无限的私有主存视图。它支持多任务处理,允许进程和内核在自己的私有地址空间中运行而无需担心冲突问题。它还支持超额订阅主存,允许操作系统根据需要在主存和二级存储(磁盘)之间透明地映射虚拟内存。虚拟内存的作用如图 3.9 所示。主存是主内存(RAM),次存是存储设备(磁盘)。

虚拟内存的实现依赖于处理器和操作系统的支持。它并非真实的内存,大多数操作系统只在需要时,即内存首次被使用(写入)时,将虚拟内存映射到真实内存中。有关虚拟内存的更多信息,请参阅第7章"内存"。
3.2.8 Memory Management
虚拟内存允许使用辅助存储器扩展主存,但内核努力将最活跃的数据保持在主存中。为此,内核有两种例行程序:
1. 交换(Swapping)将整个进程在主存和辅助存储器之间移动。
2. 分页(Paging)将称为页面(例如,4 KB)的小内存单位移动。
交换是原始 Unix 方法,可能会导致严重的性能损失。分页更为高效,在引入页面式虚拟内存的 BSD 中被添加。在这两种情况下,最近最少使用(或最近未使用)的内存被移动到辅助存储器中,并且只有在需要时才会被移回到主存中。
在 Linux 中,术语 swapping 用于指代分页。Linux 内核不支持(较旧的)Unix 风格的整个线程和进程交换。
关于分页和交换的更多内容,请参阅第7章"内存"。
3.2.9 Schedulers
Unix 及其衍生系统是时间分享系统,通过将执行时间分配给多个进程,使它们能够同时运行。进程在处理器和各个 CPU 上的调度由调度程序完成,调度程序是操作系统内核的关键组件。调度程序的作用如图 3.10 所示,它对线程(在 Linux 中称为任务)进行操作,并将它们映射到 CPU 上。

基本意图是将 CPU 时间分配给活动进程和线程,并保持一定的优先级概念,以便更重要的工作能够更早地执行。调度程序跟踪所有处于就绪状态的线程,传统上是在每个优先级队列上进行,称为运行队列[Bach 86]。现代内核可能会针对每个 CPU 实现这些队列,并且除了队列之外,还可以使用其他数据结构来跟踪线程。当有更多的线程要运行而可用的 CPU 不足时,较低优先级的线程会等待它们的轮到来。大多数内核线程的优先级高于用户级进程。
调度程序可以动态修改进程优先级,以改善特定工作负载的性能。工作负载可以分为以下两类:
1. CPU 密集型:执行大量计算的应用程序,例如科学和数学分析,预计具有长运行时间(几秒、几分钟、几小时)。这些工作负载受 CPU 资源限制。
2. I/O 密集型:执行 I/O 操作很多但计算量很少的应用程序,例如 Web 服务器、文件服务器和交互式 shell,需要低延迟响应。当它们的负载增加时,它们受 I/O 存储或网络资源的限制。
调度程序可以识别出 CPU 密集型工作负载,并降低它们的优先级,从而让 I/O 密集型工作负载(其中低延迟响应更可取)更早地运行。这可以通过计算最近计算时间(在 CPU 上执行的时间)与实际时间(经过的时间)的比率,并降低具有较高(计算)比率的进程的优先级来实现[Thompson 78]。这种机制优先处理运行时间较短的进程,通常是执行 I/O 操作的进程,包括人机交互进程。
现代内核支持多个调度类别,它们应用不同的算法来管理优先级和可运行线程。其中可能包括实时调度类别,该类别使用比所有非关键工作(包括内核线程)更高的优先级。实时调度类别以及抢占支持(稍后将介绍)为实时系统提供了低延迟调度。有关内核调度程序和其他调度类别的更多信息,请参阅第6章“CPU”。
3.2.10 File Systems
文件系统是将数据组织为文件和目录的一种方式。它们具有基于文件的接口,通常基于 POSIX 标准。内核可以支持多种文件系统类型和实例。提供文件系统是操作系统最重要的角色之一,曾被描述为最重要的角色之一[Ritchie 74]。
操作系统提供了一个全局文件命名空间,以自顶向下的树状拓扑结构组织,从根级别(“/”)开始。文件系统通过挂载将其加入到树中,将自己的树连接到一个目录(挂载点)。这使得最终用户可以透明地浏览文件命名空间,而不受底层文件系统类型的限制。
一个典型的操作系统可能按照图3.11所示的方式进行组织。

顶级目录包括etc(用于系统配置文件),usr(用于系统提供的用户级程序和库),dev(用于设备文件),var(用于包含系统日志等可变文件),tmp(用于临时文件)和home(用于用户主目录)。在图示的示例中,var和home可能位于它们自己的文件系统实例和单独的存储设备上;但是,它们可以像树的任何其他组件一样进行访问。
大多数文件系统类型使用存储设备(磁盘)来存储其内容。一些文件系统类型由内核动态创建,例如/proc或/dev。
VFS
虚拟文件系统(VFS)是一个用于抽象文件系统类型的内核接口,最初由Sun Microsystems开发,以便Unix文件系统(UFS)和NFS能够更容易地共存。其角色如图3.12所示。

VFS接口使得向内核添加新的文件系统类型更加容易。它还支持提供之前所述的全局文件命名空间,以便用户程序和应用程序可以透明地访问各种文件系统类型。
I/O Stack
对于基于存储设备的文件系统,从用户级软件到存储设备的路径被称为I/O堆栈。这是之前展示的整个软件堆栈的一个子集。图3.13显示了一个通用的I/O堆栈。

文件系统及其性能在第8章《文件系统》中有详细介绍,而构建在其上的存储设备在第9章《磁盘》中进行了讨论。
3.2.11 Caching
由于磁盘I/O的延迟通常较高,软件堆栈的许多层次尝试通过缓存读取和缓冲写入来避免它。缓存可能包括表3.2中所示的缓存(按照检查的顺序)。

例如,缓冲区缓存是主内存中存储最近使用的磁盘块的区域。如果请求的块存在于缓存中,磁盘读取可以立即从缓存中提供,避免了磁盘I/O的高延迟。(11)
存在的缓存类型会根据系统和环境而异。
3.2.12 Networking
现代内核提供了一系列内置网络协议,使得系统能够在网络上进行通信并参与分布式系统环境。该堆栈被称为TCP/IP堆栈,以常用的TCP和IP协议命名。用户级应用程序通过可编程的端点(套接字)访问网络。
连接到网络的物理设备是网络接口,通常提供在网络接口卡(NIC)上。系统管理员的常见职责之一是将IP地址与网络接口关联起来,以便它可以与网络通信。
网络协议不经常更改,但增强和选项有所变化,例如更新的TCP选项和TCP拥塞控制算法,需要内核支持。另一个变化是支持不同的网络接口卡,这需要内核的新设备驱动程序。
有关网络和网络性能的更多信息,请参见第10章《网络》。
3.2.13 Device Drivers
内核必须与各种物理设备进行通信。使用设备驱动程序实现这种通信:内核软件用于设备管理和I/O。设备驱动程序通常由开发硬件设备的厂商提供。一些内核支持可插拔的设备驱动程序,可以在不需要系统重启的情况下加载和卸载。
设备驱动程序可以为其设备提供字符和/或块接口。字符设备,也称为原始设备,根据设备的不同,提供任何I/O大小的非缓冲顺序访问甚至单个字符的访问。这样的设备包括键盘和串行端口(在原始Unix中,还有纸带和线打印机设备)。
块设备以块为单位执行I/O操作,每个块通常为512字节。可以基于它们的块偏移随机访问这些块,从块设备的开始处开始,偏移量为0。在原始Unix中,块设备接口还提供了块设备缓冲区的缓存,以提高性能,在主内存的缓冲区缓存区域中完成。
/*sensor驱动程序是字符设备还是块设备?
传感器驱动程序通常被视为字符设备。这是因为传感器通常以流式数据的形式输出读数,而不是以固定大小的块进行访问。因此,传感器驱动程序提供的接口是一个字符接口,允许逐个字符或按流读取传感器数据。
*/
3.2.14 Multiprocessor
多处理器支持允许操作系统使用多个CPU实例并行执行工作。通常以对称多处理(SMP)的形式实现,其中所有CPU被平等对待。这在技术上是很难实现的,会导致在并行运行的线程之间访问和共享内存和CPU时出现问题。有关详细信息,请参见第6章“CPU”中的调度和线程同步,以及第7章“内存”中的内存访问和架构。
CPU跨调用
对于多处理器系统,CPU有时需要协调,例如用于内存转换项的缓存一致性(通知其他CPU,如果缓存了一个条目,则现在已经过时)。CPU可以请求其他CPU或所有CPU立即执行此类工作,使用CPU跨调用。跨调用是设计成快速执行的处理器中断,以最小化对其他线程的中断。
跨调用也可以用于抢占。
3.2.15 Preemption
内核抢占支持允许高优先级的用户级线程中断内核并执行。这使得实时系统(具有严格的响应时间要求的系统)成为可能。支持抢占的内核被称为完全可抢占的,尽管实际上它仍然会有一些无法被中断的小型关键代码路径。
Linux支持的一种方法是自愿内核抢占,在内核代码的逻辑停止点可以检查并执行抢占。这避免了支持完全可抢占内核的一些复杂性,并为常见工作负载提供了低延迟的抢占。
3.2.16 Resource Management
操作系统可以提供各种可配置的控制,以微调对系统资源(如CPU、内存、磁盘和网络)的访问。这些是资源控制,可以用于运行不同应用程序或租户(云计算)的系统来管理性能。这些控制可以对每个进程(或进程组)的资源使用设置固定限制,或者采用更灵活的方法,允许它们之间共享闲置使用。
早期的Unix和BSD版本具有基本的针对每个进程的资源控制,包括使用nice(1)进行CPU优先级设置,以及使用ulimit(1)进行一些资源限制。基于Solaris的系统自Solaris 9(2002年)起提供了高级资源控制,并在resources_controls(5)手册页中有相关文档。
对于Linux,已经开发并集成了控制组(cgroups)功能,从2.6.24版本(2008年)开始,并添加了各种附加控制功能。这些功能在内核源码的Documentation/cgroups目录下有详细说明。
适当的章节中会提到特定的资源控制。第11章“云计算”中描述了一个示例用例,用于管理基于操作系统的租户的性能。
3.2.17 Observability
操作系统由内核、库和程序组成。这些程序包括用于观察系统活动和分析性能的工具,通常安装在/usr/bin和/usr/sbin目录下。还可以在系统上安装第三方工具来提供额外的可观察性。
下一章介绍了可观察性工具以及构建它们所依赖的操作系统组件。
3.3 Kernels
本节介绍了基于Solaris和Linux内核(按时间顺序),它们的历史和特点,并重点讨论了它们在性能方面的差异。Unix的起源也作为背景进行了讨论。
现代内核之间的一些明显差异包括它们支持的文件系统(参见第8章“文件系统”)和它们提供的可观察性框架(参见第4章“可观察性工具”)。还存在着它们的系统调用(syscall)接口、网络堆栈架构、实时支持以及CPU、磁盘和网络I/O调度方面的差异。
表3.3显示了最近的内核版本,其中系统调用计数是基于操作系统手册第2节中的条目数。这是一个粗略的比较,但足以看出一些差异。

这些只是有文档记录的系统调用,内核通常还提供了更多供操作系统软件私下使用的系统调用。除了内核之间的差异,随着时间的推移,存在一种模式:Linux一直在增加系统调用,而Solaris则一直在删除系统调用。
UNIX最初只有20个系统调用,而今天直接来自UNIX的Linux已经有超过一千个……我只是担心随之增长的复杂性和规模。
肯·汤普森(Ken Thompson),ACM图灵百年庆典,2012年
这两个内核实际上都在不同的方式中变得越来越复杂,并通过添加新的系统调用或通过其他内核接口将此暴露给用户空间。
3.3.1 Unix
Unix是由肯·汤普森(Ken Thompson)、丹尼斯·里奇(Dennis Ritchie)和贝尔实验室(AT&T Bell Labs)的其他人在1969年及其后几年开发的。它的确切起源在《UNIX分时系统》[Ritchie 74]中有所描述:
第一个版本是由我们其中之一(汤普森)在对现有计算机设备不满意的情况下,发现了一个很少使用的PDP-7,然后着手创建一个更友好的环境。
UNIX的开发者之前曾在多路信息和计算机服务(Multics)操作系统上工作过。UNIX最初被开发为一种轻量级多任务操作系统和内核,最初被命名为UNiplexed Information and Computing Service(UNICS),以对Multics进行双关语的方式命名。从《UNIX实施》[Thompson 78]中可以看出:
内核是唯一不能由用户自己替换的UNIX代码。因此,内核应该尽可能少地做出真正的决策。这并不意味着允许用户通过无数选项来完成相同的事情。相反,它意味着只允许一种方式来完成一件事,但这种方式是所有可能提供的选项的最小公倍数。
尽管内核很小,但它确实提供了一些高性能的功能。进程具有调度器优先级,以降低高优先级工作的运行队列延迟。为了效率,磁盘I/O是按照大块(512字节)进行的,并且在内存中的每个设备缓冲区缓存中进行了缓存。空闲进程可以被交换到存储器中,使得更繁忙的进程可以在主存中运行。当然,该系统是多任务的,允许多个进程同时运行,提高作业吞吐量。
为了支持网络、多个文件系统、分页和其他我们现在认为是标准的功能,内核不得不增长。而且随着包括BSD、SunOS(Solaris)和后来的Linux在内的多个衍生版本的出现,内核性能变得具有竞争力,这推动了更多功能和代码的添加。
3.3.2 Solaris-Based
Solaris内核不仅是Unix衍生的,甚至还保留了一些原始Unix内核的代码。Solaris始于1982年由Sun Microsystems创建的SunOS。基于BSD,SunOS被保持得小巧紧凑,以便在Sun工作站上表现出色。到了1980年代末,Sun已经开发了新的操作系统功能,并与BSD和Xenix的功能一起贡献给了AT&T的Unix System V Release 4(SVR4)。随着SVR4成为新的Unix标准,Sun基于它创建了一个新的内核和操作系统:SunOS 5。Sun市场营销将其称为Solaris 2.0,并将先前的SunOS命名为Solaris 1.0。然而,工程师们在内核中保留了SunOS的名称。
Sun内核的发展,特别是与性能相关的,包括以下内容:
NFS:NFS协议允许文件在网络上共享,并作为全局文件系统树的一部分透明地使用(挂载)。NFS目前广泛使用的是3和4版本,每个版本都引入了许多性能改进。
VFS:虚拟文件系统(VFS)是一个抽象和接口,允许多个文件系统轻松共存。Sun最初创建它是为了使NFS和UFS可以共存。有关VFS的详细信息,请参见第8章,文件系统。
页面缓存:这个缓存虚拟内存页面,并且自从引入以来一直是大多数操作系统的主要文件系统缓存(ZFS ARC是一个例外)。它在SunOS 4中引入,同时也支持共享页面。有关页面缓存的更多信息,请参见第8章,文件系统。
内存映射文件:可用于减少文件I/O的开销,并在SVR4的SunOS虚拟内存重写中引入。
RPC:远程过程调用接口。
NIS:网络信息服务是一个简单的扁平拓扑结构,用于在网络上共享信息,包括passwd和hosts文件。它多年来被广泛使用,但现在正在被LDAP取代。
CacheFS:缓存文件系统在Solaris 2.4(1994年)引入,用于提高访问慢速NFS服务器的性能。此后,NFS服务器的性能已经提高到CacheFS不再常用或被考虑的程度。
完全可抢占内核:Sun最早的一个特点是其完全可抢占内核,确保高优先级工作(包括实时工作)的低延迟。
调度器类:提供多个调度器类来调整不同类工作负载的性能。这些包括时间共享(TS)、交互式(IA)、实时(RT)、系统(SYS)、固定(FX)和公平分享调度器(FSS)。有关详细信息,请参见第6章,CPU。
/*
上面的内存映射文件是指mmap么?
是的,上面提到的内存映射文件就是指mmap。mmap是一种将文件或其他对象映射到内存中的方法,使得应用程序可以像访问内存一样访问这些对象,从而避免了频繁的文件I/O操作带来的开销。在SVR4的SunOS虚拟内存重写中,引入了内存映射文件的概念。
*/
多处理器支持:在上世纪90年代初,Sun大力投资于多处理器操作系统支持,开发了对称和非对称多处理器(ASMP和SMP)的内核支持[Mauro 01]。
Slab分配器:取代了SVR4的伙伴分配器,内核slab分配器通过预先分配缓冲区的每个CPU缓存,提供更好的性能,这些缓冲区可以快速重用。这种分配器类型及其衍生物已成为操作系统的标准。
崩溃分析:Sun开发了一个成熟的内核崩溃转储分析框架,适用于所有系统并默认启用,包括用于崩溃转储、内核和应用程序分析的模块化调试器(mdb(1))。
M:N线程调度:这实现了一个在线程和进程之间增加一个额外的对象,目的是进行高效的线程调度。这个对象被称为轻量级进程(LWP),它可以有自己的用户级调度行为,与内核调度器不同。Sun的实现后来被发现存在问题,并且不值得复杂性[Cantrill 96]。它在Solaris 9中被删除,但术语(LWP)和一些数据结构在Solaris的某些部分中仍然存在。
STREAMS网络堆栈:Sun在AT&T STREAMS接口上构建了其TCP/IP网络堆栈,该接口提供了用户空间和内核空间之间的通信。它最终无法适应更快的网络,到Solaris 10时,许多STREAMS管道已被删除。
64位支持:Solaris 7内核(1998年)提供了对64位处理器的支持。
锁统计:在Solaris 7中引入了锁性能统计。
MPSS:多页大小支持允许操作系统使用由处理器提供的不同大小的内存页面,包括大(或巨大)页面,提高了内存操作的效率。
MPO:在Solaris 9中添加了内存放置优化,以改善与处理器体系结构(局部性)相关的内存分配方式,这可以显着提高内存访问性能。
资源控制:一种限制进程或进程组使用各种资源的设施,称为项目(稍后由区域使用)。
FireEngine:用于Solaris 10的一组高性能TCP/IP堆栈增强功能,包括垂直边界,以改善数据包处理的CPU和内存局部性,以及IP扇出以在CPU之间分散负载。
DTrace:一个静态和动态跟踪框架和工具,实时在生产环境中提供对整个软件堆栈的几乎无限的可观察性。它于2005年发布于Solaris 10,并成为首个广泛成功的动态跟踪实现。它已被移植到其他操作系统,包括Mac OS X和FreeBSD,并目前正在移植到Linux。DTrace在第4章“可观察性工具”中有详细介绍。
Zones:一种基于操作系统的虚拟化技术,允许创建共享同一主机内核的操作系统实例。它于Solaris 10发布,但这个概念最早由FreeBSD的jails在1998年实现。与其他虚拟化技术相比,它们具有轻量级和高性能的特点。详见第11章“云计算”。
Crossbow:一种提供高性能虚拟化网络接口和网络带宽资源控制的架构。这个特性对于构建高性能和可靠的云至关重要。
ZFS:ZFS文件系统提供了企业级功能,并随Solaris 10更新1一起发布,同时也作为开源软件提供。现在它已经适用于其他操作系统,并成为许多文件服务器设备的基础。详见第8章“文件系统”。
其中许多功能已经被移植或重新实现为Linux,并且有些功能仍在开发中。
在面对Linux的压力下,Sun在2005年将Solaris开源为OpenSolaris项目。它一直保持开源状态,直到Oracle于2010年收购Sun并停止发布源代码更新。最后发布的OpenSolaris版本,它镜像了Solaris 11的开发版本,成为开源的illumos内核的基础。今天有几种基于illumos内核的操作系统,包括Joyent的SmartOS,它被用于本书中许多基于Solaris的示例中。
3.3.3 Linux-Based
Linux是由Linus Torvalds于1991年创建的免费操作系统,用于Intel个人计算机。他在Usenet上发布了这个项目的消息:
我正在开发一个(免费的)操作系统(只是一种爱好,不会像GNU那样大而专业),用于386(486)AT克隆机。这个项目从四月份开始酝酿,并且正在逐渐准备就绪。我希望得到关于人们在MINIX中喜欢/不喜欢的事物的任何反馈,因为我的操作系统在某种程度上类似于它(包括文件系统的物理布局相同(出于实际原因)等等)。
这里提到的是MINIX操作系统,它当时正在开发,作为面向小型计算机的免费和精简版Unix。BSD也致力于提供一个免费的Unix版本,尽管当时遇到了法律问题。
Linux内核的开发借鉴了许多前辈的一般性思想,包括:
Unix(和Multics):操作系统层,系统调用,多任务处理,进程,进程优先级,虚拟内存,全局文件系统,文件系统权限,设备文件,缓存
BSD:分页虚拟内存,按需分页,快速文件系统(FFS),TCP/IP网络堆栈,套接字
Solaris:VFS、NFS、页面缓存、统一页面缓存、slab分配器,以及(正在进行中的)ZFS和DTrace
Plan 9:资源叉(rfork),用于创建进程和线程(任务)之间不同级别的共享。
/*
内存管理buddy和slab分配器的关系是?
Buddy分配器和Slab分配器是Linux内核中用于内存管理的两种不同机制。
Buddy分配器是一种用于管理大块连续内存的算法。它将物理内存按照2的幂次方进行划分,并通过合并相邻的空闲块来满足不同大小的内存分配请求。Buddy分配器主要用于处理大于一个页面的内存分配,例如进程堆栈或内核数据结构。
Slab分配器是一种用于管理小块连续内存(称为slabs)的机制。它通过将内存划分为固定大小的slabs来提高内存分配和释放的效率。每个slab被预先分配并用作特定类型的对象的缓存,以减少频繁的内存分配和释放操作。Slab分配器主要用于管理内核数据结构和缓存,例如文件描述符、进程控制块等。
因此,Buddy分配器和Slab分配器是Linux内核中两个不同的内存管理机制,用于处理不同大小和类型的内存分配需求。
*/
Linux内核的特性,特别是与性能相关的特性包括以下内容。其中许多特性包括了它们首次引入的Linux内核版本。
CPU调度类:开发了各种高级CPU调度算法,包括调度域(2.6.7)以更好地决策非均匀存储器访问(NUMA)。参见第6章,CPUs。
I/O调度类:开发了不同的块I/O调度算法,包括deadline(2.5.39)、anticipatory(2.5.75)和完全公平队列(CFQ)(2.6.6)。参见第9章,磁盘。
TCP拥塞控制:Linux内核支持新的TCP拥塞控制算法,允许根据需要选择。还有许多TCP增强功能。参见第10章,网络。
超额提交:与内存不足杀手(OOM)一起,这是一种利用更少主内存进行更多操作的策略。参见第7章,内存。
Futex(2.5.7):快速用户空间互斥量,用于提供高性能的用户级同步原语。
巨大页面(2.5.36):这提供了对由内核和内存管理单元(MMU)预分配的大内存页面的支持。参见第7章,内存。
OProfile(2.5.43):一个系统性能分析器,用于研究CPU使用率和其他事件,适用于内核和应用程序。
RCU(2.5.43):内核提供了一种读-复制-更新同步机制,允许多个读与更新并发进行,从而提高数据的性能和可扩展性。
epoll (2.5.46):一个系统调用,用于有效地等待许多打开文件描述符的I/O操作,提高服务器应用程序的性能。
模块化I/O调度(2.6.10):Linux提供了可插拔的调度算法来调度块设备I/O。参见第9章,磁盘。
DebugFS(2.6.11):内核向用户级别公开数据的简单非结构化接口,被一些性能工具使用。
Cpusets(2.6.12):进程的独占CPU分组。
自愿内核抢占(2.6.13):此过程提供低延迟调度而不需要完全抢占的复杂性。
inotify(2.6.13):用于监视文件系统事件的框架。
blktrace(2.6.17):用于跟踪块I/O事件的框架和工具(后来迁移到tracepoints)。
splice(2.6.17):一种系统调用,用于在文件描述符和管道之间快速移动数据,无需通过用户空间。
延迟账户(2.6.18):跟踪每个任务的延迟状态。参见第4章,可观测性工具。
IO账户(2.6.20):测量各种存储I/O统计信息的进程。
DynTicks(2.6.21):动态滴答允许内核定时器中断(时钟)仅在必要时触发(无滴答),节省CPU资源和电源。
SLUB(2.6.22):一个新的、简化的slab内存分配器版本。
CFS(2.6.23):完全公平调度程序。参见第6章,CPUs。
cgroups(2.6.24):控制组允许对进程组的资源使用进行测量和限制。
latencytop(2.6.25):用于观察操作系统延迟来源的仪器和工具。
Tracepoints(2.6.28):静态内核跟踪点(也称为静态探针),用于仪器化内核中的逻辑执行点,供跟踪工具使用(以前是内核标记)。跟踪工具在第4章可观测性工具中介绍。
perf(2.6.31):Linux性能事件(perf)是一组用于性能可观测性的工具,包括CPU性能计数器分析和静态和动态跟踪。参见第6章,CPUs,进行介绍。
透明大页面(2.6.38):这是一个框架,允许轻松使用巨大(大)内存页面。参见第7章,内存。
Uprobes(3.5):用于动态跟踪用户级软件的基础设施,被其他工具(perf、SystemTap等)使用。
KVM:基于内核的虚拟机(KVM)技术是由Qumranet开发的,后来在2008年被Red Hat收购。KVM允许创建虚拟操作系统实例并运行它们自己的内核。请参见第11章,云计算。
其中一些功能,包括epoll和KVM,已经被移植或重新实现为基于Solaris的系统。
Linux还通过其对设备驱动程序的广泛支持和开源要求,间接地为许多其他操作系统做出了贡献。
3.3.4 Differences
虽然Linux和基于Solaris的内核都是Unix的后代,共享相同的操作系统概念,但它们在许多方面都有不同,无论是大还是小。没有简洁明了的方法来总结这种复杂性。
Linux系统的主要优势主要不来自内核或操作系统本身,而来自应用程序包支持、设备驱动程序支持、庞大的社区以及其开源性。大多数基于Solaris的内核也是开源的(Oracle Solaris目前不是),但它们没有相同广泛的驱动程序支持(这对于笔记本电脑使用可能是一个问题)。
基于Solaris的系统提供了面向企业级的ZFS文件系统和几乎无限的可观测性DTrace。尽管它们正在被移植到Linux上,但它们已经在基于Solaris的系统上可用并成熟,自2003年以来已在生产环境中使用。Linux确实具有许多较新的会计和跟踪框架,提供了扩展的可观测性(在下一章中介绍),但它们可能尚未普遍启用或默认安装。
基于Solaris的系统还默认启用了内核崩溃转储,以便可以从第一次发生时对内核崩溃进行分析和解决。
除了这些主要差异之外,内核之间还有许多许多微小的差异,特别是在性能优化方面。要了解这些差异如何影响您,需要分析所需工作负载,以确定哪些是相关的。
举个微小差异的例子,POSIX的fadvise()调用目前在Linux上实现,但在基于Solaris的内核上被忽略。应用程序可以使用此调用通知内核不缓存与文件描述符相关联的数据,从而允许Linux内核更高效地进行缓存,提高性能。以下是来自MySQL数据库的一个示例用法:
storage/innobase/row/row0merge.c:
/* Each block is read exactly once. Free up the file cache. */
posix_fadvise(fd, ofs, sizeof *buf, POSIX_FADV_DONTNEED);这样的微小差异可能会迅速改变,而当您阅读本书时,这个特定问题可能已经在基于Solaris的内核中得到解决。
虽然根据工作负载的不同,交付性能存在微小差异,但最大的差异可能是性能可观测性,特别是对动态跟踪的支持。如果一个内核支持您在生产环境中找到10倍以上的优势,那么早期发现的任何10%左右的差异都可能不那么重要。
观测工具将在下一章中介绍。
4 Observability Tools
操作系统在历史上为观察系统软件和硬件组件提供了许多工具。对于新手来说,各种可用的工具似乎可以观察到一切,或者至少可以观察到所有重要的东西。实际上,存在许多空白,并且系统性能专家擅长于推理和解释:从间接的工具和统计数据中找出活动情况。
例如,网络数据包可以逐个检查(嗅探),但磁盘I/O却不能(至少不容易)。相反,磁盘利用率(忙碌百分比)可以轻松地通过操作系统工具观察到,但网络接口利用率却不能。
随着追踪框架的添加,特别是动态追踪,现在可以观察到一切,并且几乎可以直接观察到任何活动。这对系统性能产生了深远的影响,使得可以创建数百种新的可观测性工具(潜在数量无限)。
本章介绍了操作系统可观测性工具的类型,包括关键示例以及构建它们的框架。重点是框架,包括/proc、kstat、/sys、DTrace和SystemTap。在后面的章节中,还介绍了使用这些框架的许多其他工具,包括第6章中的Linux性能事件(LPE)和CPU。
4.1 Tool Types
性能可观测工具可以分为提供系统范围或进程级可观测性的两种类型,并且大多数基于计数器或跟踪。这些属性如图4.1所示,同时还提供了工具示例。

有些工具适用于多个象限;例如,top(1)也具有系统范围的摘要,而DTrace也具有进程级的功能。
还有一些基于性能分析的工具。这些工具通过采集一系列快照来观察活动,可以是系统范围的或者进程级的。
以下几节将总结使用计数器、跟踪和性能分析的工具,以及执行监控的工具。
4.1.1 Counters
内核维护各种统计数据,称为计数器,用于计算事件数量。它们通常实现为无符号整数,在事件发生时递增。例如,有关接收的网络数据包数量、发出的磁盘I/O和执行的系统调用都有相应的计数器。
由于计数器默认启用并由内核持续维护,因此被认为是“免费”可用的。使用计数器时唯一的额外开销是从用户空间读取其值(这个开销应该是可以忽略不计的)。下面的示例工具可读取这些系统范围或进程级的计数器值。
系统范围的工具
这些工具使用内核计数器,在系统软件或硬件资源的环境下,检查系统范围的活动。示例包括:
- vmstat:虚拟和物理内存统计,系统范围的
- mpstat:每个CPU的使用情况
- iostat:每个磁盘的I/O使用情况,从块设备接口报告
- netstat:网络接口统计信息,TCP/IP堆栈统计信息和一些连接级别的统计信息
- sar:各种统计数据;也可以将其存档以备历史报告
这些工具通常可以由系统上的所有用户(非root用户)查看。它们的统计数据通常也由监控软件绘制成图形。
许多工具都遵循一个使用约定,可以接受可选的时间间隔和输出次数,例如,vmstat(8)可以设置为每秒采样一次,输出三次结果:
$ vmstat 1 3
procs -----------memory---------- ---swap-- -----io---- -system-- ----cpu----
r b swpd free buff cache si so bi bo in cs us sy id wa
4 0 0 34455620 111396 13438564 0 0 0 5 1 2 0 0 100 0
4 0 0 34458684 111396 13438588 0 0 0 0 2223 15198 13 11 76 0
4 0 0 34456468 111396 13438588 0 0 0 0 1940 15142 15 11 74 0输出的第一行是自启动以来的总结,显示系统运行时间内的平均值。随后的行是每秒钟的摘要,显示当前的活动情况。至少,这是意图:这个Linux版本在第一行中混合了自启动以来的总结和当前值。
进程级工具
这些工具是以进程为导向,使用内核为每个进程维护的计数器。示例包括:
- ps:进程状态,显示各种进程统计数据,包括内存和CPU使用情况。
- top:显示顶部进程,按某种统计数据(如CPU使用率)排序。Solaris系统提供了prstat(1M)来实现此目的。
- pmap:列出进程内存段和使用统计信息。
这些工具通常从/proc文件系统读取统计数据。
4.1.2 Tracing
跟踪收集每个事件的数据以进行分析。跟踪框架通常不会默认启用,因为跟踪会产生CPU开销来捕获数据,可能需要大量存储空间来保存数据。这些开销可能会减缓跟踪目标,并且在解释测量时间时需要考虑到它们。
日志记录,包括系统日志,可以视为默认启用的低频跟踪。日志包括每个事件的数据,尽管通常仅限于错误和警告等不经常发生的事件。
以下是系统范围和进程范围跟踪工具的示例。
系统范围
这些跟踪工具使用内核跟踪功能,在系统软件或硬件资源的上下文中检查系统范围的活动。示例包括:
- tcpdump:网络数据包跟踪(使用libpcap)
- snoop:适用于Solaris系统的网络数据包跟踪
- blktrace:块I/O跟踪(Linux)
- iosnoop:基于DTrace的块I/O跟踪
- execsnoop:新进程跟踪(基于DTrace)
- dtruss:系统范围的缓冲系统调用跟踪(基于DTrace)
- DTrace:使用静态和动态跟踪跟踪内核内部和任何资源(不仅限于网络或块I/O)
- SystemTap:使用静态和动态跟踪跟踪内核内部和任何资源
- perf:Linux性能事件,跟踪静态和动态探针
由于DTrace和SystemTap是编程环境,因此可以在它们之上构建系统范围的跟踪工具,包括此列表中包含的一些工具。本书中提供了更多示例。
进程级别
这些跟踪工具是面向进程的,就像它们所基于的操作系统框架一样。示例包括:
- strace:用于Linux系统的系统调用跟踪
- truss:用于Solaris系统的系统调用跟踪
- gdb:源码级别的调试器,通常在Linux系统上使用
- mdb:用于Solaris系统的可扩展调试器
调试器可以检查每个事件的数据,但必须通过停止和启动目标的执行来实现。
诸如DTrace、SystemTap和perf之类的工具都支持一种仅能检查单个进程的执行模式,尽管更适合描述为系统范围的工具。
4.1.3 Profiling
性能分析是通过收集一组样本或快照来描述目标的行为。CPU使用率是一个常见的示例,其中采用程序计数器或堆栈跟踪的样本来描述消耗CPU周期的代码路径。这些样本通常以固定的速率收集,例如每秒100次或1000次(赫兹)。性能分析工具或分析器有时会稍微改变此速率,以避免与目标活动同步采样,这可能导致过多或过少计数。
性能分析还可以基于无时间限制的硬件事件,例如CPU硬件缓存失效或总线活动。它还可以显示哪些代码路径是负责的,这些信息可以帮助开发人员优化其代码以更好地利用系统资源。
以下是一些性能分析器的示例,它们都执行基于计时器和硬件缓存的分析:
- oprofile:Linux系统性能分析
- perf:Linux性能工具包,包括性能分析子命令
- DTrace:编程性能分析,基于计时器使用其profile提供程序,基于硬件事件使用其cpc提供程序
- SystemTap:编程性能分析,基于计时器使用其timer tapset,基于硬件事件使用其perf tapset
- cachegrind:来自valgrind工具包,可以分析硬件缓存使用情况,并可使用kcachegrind进行可视化
- Intel VTune Amplifier XE:用于Linux和Windows的性能分析,具有包括源代码浏览在内的图形界面
- Oracle Solaris Studio:用于Solaris和Linux的性能分析,包括具有源代码浏览功能的性能分析工具
编程语言通常具有自己的特定目的的分析器,可以检查语言上下文。
有关性能分析工具的更多信息,请参阅第6章《CPU》。
4.1.4 Monitoring (sar)
监控是在第二章“方法论”中介绍的。监视单个操作系统主机最常用的工具是源自AT&T Unix的系统活动报告器sar(1)。sar(1)是基于计数器的,具有代理程序,可以在预定时间(通过cron)执行以记录系统计数器的状态。sar(1)工具允许这些计数器在命令行中查看,例如:
# sar
Linux 3.2.6-3.fc16.x86_64 (web100) 04/15/2013 _x86_64_ (16 CPU)
05:00:00 CPU %user %nice %system %iowait %steal %idle
05:10:00 all 12.61 0.00 4.58 0.00 0.00 82.80
05:20:00 all 21.62 0.00 9.59 0.93 0.00 67.86
05:30:00 all 23.65 0.00 9.61 3.58 0.00 63.17
05:40:00 all 28.95 0.00 8.96 0.04 0.00 62.05
05:50:00 all 29.54 0.00 9.32 0.19 0.00 60.95
Average: all 23.27 0.00 8.41 0.95 0.00 67.37默认情况下,sar(1)会读取其统计存档(如果启用)以打印最近的历史统计数据。您可以为其指定可选的间隔和计数,以便按指定的速率检查当前活动。
关于sar(1)的具体用法在本书的后面章节中有描述,可参考第6、7、8、9和10章。附录C是sar(1)选项的摘要。
尽管sar(1)可以报告许多统计数据,但可能没有涵盖您实际所需的所有内容,并且它提供的统计数据有时会误导(特别是在基于Solaris的系统上[McDougall 06b])。已经开发出了一些替代方案,例如System Data Recorder和Collectl。
在Linux中,通过sysstat软件包提供了sar(1)。第三方监控产品通常是基于sar(1)或使用相同的可观察性统计数据构建的。
4.2 Observability Sources
接下来的几节描述了提供可观察工具所需的统计数据和数据的各种接口和框架。它们在表4.1中进行了总结。
接下来介绍了系统性能统计的主要来源:/proc、/sys和kstat。然后介绍了延迟账户和微状态账户,并对其他来源进行了总结。在这些内容之后,介绍了基于其中一些框架构建的DTrace和SystemTap工具。

4.2.1 /proc
这是一个用于内核统计的文件系统接口。/proc目录包含许多子目录,每个子目录以其所代表的进程的进程ID命名。这些目录包含一些文件,其中包含从内核数据结构映射而来的有关每个进程的信息和统计数据。在Linux上,/proc还包含用于系统范围统计的其他文件。
/proc由内核动态创建,不依赖于存储设备(它在内存中运行)。它主要是只读的,为可观察性工具提供统计数据。一些文件是可写的,用于控制进程和内核行为。
文件系统接口非常方便:它通过目录树直观地向用户空间公开内核统计数据,并通过POSIX文件系统调用(open()、read()、close())具有众所周知的编程接口。文件系统还通过使用文件访问权限提供用户级安全性。
以下示例展示了如何使用top(1)和strace(1)读取每个进程的统计数据:
stat("/proc/14704", {st_mode=S_IFDIR|0555, st_size=0, ...}) = 0
open("/proc/14704/stat", O_RDONLY) = 4
read(4, "14704 (sshd) S 1 14704 14704 0 -"..., 1023) = 232
close(4)这打开了一个名为“stat”的文件,该文件位于以进程ID命名的目录中,然后读取了文件内容。top(1)会为系统上的所有活动进程重复执行此操作。在某些系统上(特别是进程众多的系统),执行这些操作的开销可能会变得明显,特别是对于在每个屏幕更新时针对每个进程重复执行此序列的top(1)版本。这可能会导致top(1)报告top(1)本身是最高的CPU消耗者!
在Linux上,/proc的文件系统类型为“proc”,在基于Solaris的系统上,则为“procfs”。
Linux
/proc提供了各种用于每个进程统计数据的文件。以下是可能可用的一些示例:
ls -F /proc/28712
attr/ cpuset io mountinfo oom_score sessionid syscall
auxv cwd@ latency mounts pagemap smaps task/
cgroup environ limits mountstats personality stack wchan
clear_refs exe@ loginuid net/ root@ stat
cmdline fd/ maps numa_maps sched statm
coredump_filter fdinfo/ mem oom_adj schedstat status可用文件的确切列表取决于内核版本和配置选项。
与每个进程的性能可观察性相关的文件包括:
- limits:生效的资源限制
- maps:映射的内存区域
- sched:各种CPU调度器统计信息
- schedstat:CPU运行时间、延迟和时间片
- smaps:带有使用统计的映射内存区域
- stat:进程状态和统计信息,包括总CPU和内存使用情况
- statm:以页为单位的内存使用摘要
- status:可读性强的stat和statm信息
- task:每个任务统计的目录
Linux还扩展了/proc,包含系统范围的统计信息,这些信息在以下附加文件和目录中:
cd /proc; ls -Fd [a-z]*
acpi/ dma kallsyms mdstat schedstat timer_list
buddyinfo driver/ kcore meminfo scsi/ timer_stats
bus/ execdomains keys misc self@ tty/
cgroups fb key-users modules slabinfo uptime
cmdline filesystems kmsg mounts@ softirqs version
consoles fs/ kpagecount mtrr stat vmallocinfo
cpuinfo interrupts kpageflags net@ swaps vmstat
crypto iomem latency_stats pagetypeinfo sys/ zoneinfo
devices ioports loadavg partitions sysrq-trigger
diskstats irq/ locks sched_debug sysvipc/与性能可观察性相关的系统范围文件包括:
- cpuinfo:物理处理器信息,包括每个虚拟CPU、型号名称、时钟速度和缓存大小。
- diskstats:所有磁盘设备的磁盘I/O统计信息
- interrupts:每个CPU的中断计数器
- loadavg:负载平均值
- meminfo:系统内存使用情况分解
- net/dev:网络接口统计信息
- net/tcp:活动TCP套接字信息
- schedstat:系统范围的CPU调度器统计信息
- self:指向当前进程ID目录的符号链接,以方便使用
- slabinfo:内核slab分配器高速缓存统计信息
- stat:内核和系统资源统计摘要:CPU、磁盘、分页、交换、进程
- zoneinfo:内存区域信息
这些文件由系统范围的工具读取。例如,这里是vmstat(8)通过strace(1)跟踪读取/proc的示例:
open("/proc/meminfo", O_RDONLY) = 3
lseek(3, 0, SEEK_SET) = 0
read(3, "MemTotal: 889484 kB\nMemF"..., 2047) = 1170
open("/proc/stat", O_RDONLY) = 4
read(4, "cpu 14901 0 18094 102149804 131"..., 65535) = 804
open("/proc/vmstat", O_RDONLY) = 5
lseek(5, 0, SEEK_SET) = 0
read(5, "nr_free_pages 160568\nnr_inactive"..., 2047) = 1998/proc文件通常是以文本格式进行格式化的,这使得它们可以轻松地从命令行中读取并通过shell脚本工具进行处理。例如:
cat /proc/meminfo
MemTotal: 889484 kB
MemFree: 636908 kB
Buffers: 125684 kB
Cached: 63944 kB
SwapCached: 0 kB
Active: 119168 kB
[...]
$ grep Mem /proc/meminfo
MemTotal: 889484 kB
MemFree: 636908 kB虽然这很方便,但内核编码统计信息为文本以及任何处理该文本的用户空间工具都会增加开销。/proc的内容在proc(5)手册页和Linux内核文档中有详细说明:Documentation/filesystems/proc.txt。部分内容有扩展文档,比如Documentation/iostats.txt中的diskstats和Documentation/scheduler/sched-stats.txt中的调度器统计信息。除了文档,您还可以研究内核源代码,了解/proc中所有项目的确切来源。阅读消费这些信息的工具的源代码也可能会有所帮助。
一些/proc条目取决于CONFIG选项:使用CONFIG_SCHEDSTATS启用schedstats,使用CONFIG_SCHED_DEBUG启用sched。
Solaris
在基于Solaris的系统中,/proc仅包含进程状态统计信息。系统范围的可观察性通过其他框架提供,主要是kstat。
以下是/proc进程目录中的文件列表:
ls -F /proc/22449
as cred fd/ lstatus map path/ rmap status xmap
auxv ctl ldt lusage object/ priv root@ usage
contracts/ cwd@ lpsinfo lwp/ pagedata psinfo sigact watch与性能可观察性相关的文件包括:
- map:虚拟地址空间映射
- psinfo:各种进程信息,包括CPU和内存使用情况
- status:进程状态信息
- usage:扩展的进程活动统计信息,包括进程微状态、故障、阻塞、上下文切换和系统调用计数器
- lstatus:类似于status,但包含每个线程的统计信息
- lpsinfo:类似于psinfo,但包含每个线程的统计信息
- lusage:类似于usage,但包含每个线程的统计信息
- lwpsinfo:代表LWP(当前最活跃的轻量级进程)的轻量级进程(线程)统计信息;还有lwpstatus和lwpsinfo文件
- xmap:扩展的内存映射统计信息(未记录)
以下是truss(1)输出显示prstat(1M)读取进程状态的示例:
open("/proc/4363/psinfo", O_RDONLY) = 5
pread(5, "01\0\0\001\0\0\0\v11\0\0".., 416, 0) = 416这些文件的格式是二进制的,如上方的pread()数据所示。psinfo包含了以下信息:
typedef struct psinfo {
int pr_flag; /* process flags (DEPRECATED: see below) */
int pr_nlwp; /* number of active lwps in the process */
int pr_nzomb; /* number of zombie lwps in the process */
pid_t pr_pid; /* process id */
pid_t pr_ppid; /* process id of parent */
pid_t pr_pgid; /* process id of process group leader */
pid_t pr_sid; /* session id */
uid_t pr_uid; /* real user id */
uid_t pr_euid; /* effective user id */
gid_t pr_gid; /* real group id */
gid_t pr_egid; /* effective group id */
uintptr_t pr_addr; /* address of process */
size_t pr_size; /* size of process image in Kbytes */
size_t pr_rssize; /* resident set size in Kbytes */
dev_t pr_ttydev; /* controlling tty device (or PRNODEV) */
ushort_t pr_pctcpu; /* % of recent cpu time used by all lwps */
ushort_t pr_pctmem; /* % of system memory used by process */
timestruc_t pr_start; /* process start time, from the epoch */
timestruc_t pr_time; /* cpu time for this process */
timestruc_t pr_ctime; /* cpu time for reaped children */
char pr_fname[PRFNSZ]; /* name of exec'ed file */
char pr_psargs[PRARGSZ]; /* initial characters of arg list */
int pr_wstat; /* if zombie, the wait() status */
int pr_argc; /* initial argument count */
uintptr_t pr_argv; /* address of initial argument vector */
uintptr_t pr_envp; /* address of initial environment vector */
char pr_dmodel; /* data model of the process */
lwpsinfo_t pr_lwp; /* information for representative lwp */
taskid_t pr_taskid; /* task id */
projid_t pr_projid; /* project id */
poolid_t pr_poolid; /* pool id */
zoneid_t pr_zoneid; /* zone id */
ctid_t pr_contract; /* process contract id */
} psinfo_t;可以直接将这些数据读取到用户空间中的psinfo_t变量中,然后可以通过解引用来访问成员。这使得Solaris的/proc更适合用C语言编写的程序进行处理,这些程序可以包含系统提供的头文件中的结构定义。
/proc的相关信息可以在proc(4)手册页和sys/procfs.h头文件中找到。与Linux一样,如果内核是开源的,研究这些统计信息的来源以及工具如何消费它们可能会有所帮助。
lxproc
在基于Solaris的系统中,有时需要类似Linux的/proc文件系统。原因之一是为了移植Linux的可观察性工具(例如htop(1)),否则由于/proc的差异,移植可能会变得困难:从基于文本的界面到二进制界面。
其中一个解决方案是使用lxproc文件系统:它为基于Solaris的系统提供了与Linux部分兼容的/proc,并可以与标准的procfs /proc并行挂载。例如,可以将lxproc挂载在/lxproc上,需要类似Linux的/proc的应用程序可以修改为从/lxproc加载进程信息,而不是/proc——这应该只是一个小的改动。
smartos# more /lxproc/meminfo
total: used: free: shared: buffers: cached:
Mem: 1073741824 88395776 985346048 0 0 0
Swap: 2147483648 267640832 1879842816
MemTotal: 1048576 kB
MemFree: 962252 kB
[...]就像Linux的/proc一样,每个进程也有相应的目录,其中包含进程信息。
lxproc可能是不完整的,并且可能需要进行添加:它仅作为简单的Linux /proc用户的尽力而为的接口提供。
4.2.2 /sys
Linux提供了一个sysfs文件系统,挂载在/sys上,它是从2.6内核开始引入的,为内核统计信息提供了一个基于目录的结构。这与/proc不同,后者随着时间的推移不断发展,并在顶级目录中添加了各种系统统计信息。sysfs最初是为了提供设备驱动程序的统计信息而设计的,但已扩展到包括任何类型的统计信息。
例如,以下列出了CPU 0的/sys文件(已截断):
find /sys/devices/system/cpu/cpu0 -type f
/sys/devices/system/cpu/cpu0/crash_notes
/sys/devices/system/cpu/cpu0/cache/index0/type
/sys/devices/system/cpu/cpu0/cache/index0/level
/sys/devices/system/cpu/cpu0/cache/index0/coherency_line_size
/sys/devices/system/cpu/cpu0/cache/index0/physical_line_partition
/sys/devices/system/cpu/cpu0/cache/index0/ways_of_associativity
/sys/devices/system/cpu/cpu0/cache/index0/number_of_sets
/sys/devices/system/cpu/cpu0/cache/index0/size
/sys/devices/system/cpu/cpu0/cache/index0/shared_cpu_map
/sys/devices/system/cpu/cpu0/cache/index0/shared_cpu_list
[...]
/sys/devices/system/cpu/cpu0/topology/physical_package_id
/sys/devices/system/cpu/cpu0/topology/core_id
/sys/devices/system/cpu/cpu0/topology/thread_siblings
/sys/devices/system/cpu/cpu0/topology/thread_siblings_list
/sys/devices/system/cpu/cpu0/topology/core_siblings
/sys/devices/system/cpu/cpu0/topology/core_siblings_list其中许多提供有关CPU硬件缓存的信息。以下输出显示了它们的内容(使用grep(1),以便输出中包含文件名):
$ grep . /sys/devices/system/cpu/cpu0/cache/index*/level
/sys/devices/system/cpu/cpu0/cache/index0/level:1
/sys/devices/system/cpu/cpu0/cache/index1/level:1
/sys/devices/system/cpu/cpu0/cache/index2/level:2
/sys/devices/system/cpu/cpu0/cache/index3/level:3
$ grep . /sys/devices/system/cpu/cpu0/cache/index*/size
/sys/devices/system/cpu/cpu0/cache/index0/size:32K
/sys/devices/system/cpu/cpu0/cache/index1/size:32K
/sys/devices/system/cpu/cpu0/cache/index2/size:256K
/sys/devices/system/cpu/cpu0/cache/index3/size:8192K这显示CPU 0可以访问两个32 K字节的一级缓存,一个256 K字节的二级缓存和一个8 M字节的三级缓存。
/sys文件系统通常有成千上万个只读文件中的统计信息,还有许多可写文件用于更改内核状态。例如,通过向名为“online”的文件写入“1”或“0”,可以将CPU设置为在线或离线状态。与读取统计信息一样,设置状态可以通过在命令行中使用文本字符串(echo 1 > filename)而不是二进制接口进行。
4.2.3 kstat
基于Solaris的系统拥有一个用于系统范围的可观测性工具的内核统计(kstat)框架。kstat包括大多数资源的统计信息,包括CPU、磁盘、网络接口、内存以及内核中的许多软件组件。一个典型的系统可以从kstat获得成千上万个统计信息。
与/proc或/sys不同,kstat没有伪文件系统,并且通过ioctl()从/dev/kstat读取。通常通过libkstat库提供的便利函数或Sun::Solaris::Kstat进行操作,后者是用于相同目的的Perl库(尽管在某些发行版中正在逐步淘汰libkstat)。kstat(1M)工具提供了命令行上的统计信息,并可与shell脚本一起使用。
kstats结构化为四元组:
module:instance:name:statistic这些是:
模块(module):通常指创建该统计信息的内核模块,比如SCSI磁盘驱动程序的sd模块,或ZFS文件系统的zfs模块。
实例(instance):某些模块存在多个实例,例如每个SCSI磁盘的sd模块。实例是一个枚举值。
名称(name):这是统计信息的分组名称。
统计信息(statistic):这是单个统计信息的名称。例如,以下使用kstat(1M)读取nproc统计信息,并指定完整的四元组:
$ kstat -p unix:0:system_misc:nproc
unix:0:system_misc:nproc 94该统计信息显示当前正在运行的进程数量。使用kstat(1M)的-p选项打印可解析输出(以冒号分隔)。空字段被视为通配符。尾随冒号也可以省略。这些规则结合在一起,允许以下命令匹配并打印系统_misc组中的所有统计信息:
$ kstat -p unix:0:system_misc
unix:0:system_misc:avenrun_15min 201
unix:0:system_misc:avenrun_1min 383
unix:0:system_misc:avenrun_5min 260
unix:0:system_misc:boot_time 1335893569
unix:0:system_misc:class misc
unix:0:system_misc:clk_intr 1560476763
unix:0:system_misc:crtime 0
unix:0:system_misc:deficit 0
unix:0:system_misc:lbolt 1560476763
unix:0:system_misc:ncpus 2
unix:0:system_misc:nproc 94
unix:0:system_misc:snaptime 15604804.5606589
unix:0:system_misc:vac 0avenrun*统计信息用于计算系统负载平均值,由包括uptime(1)和top(1)在内的工具报告。
kstat中的许多统计信息是累计的。它们不提供当前值,而是显示自启动以来的总计。
这个freemem统计信息以每秒空闲页的数量递增。这样可以计算出时间间隔内的平均值。许多系统范围的可观测性工具打印的自启动以来的摘要也可以通过将当前值除以自启动以来的秒数来计算。
另一个版本的freemem提供了即时值(unix:0:system_pages:freemem)。这弥补了累积版本的不足之处:至少需要一秒钟才能知道当前值,因此这将是可以计算增量的最小时间。
没有任何统计名称,kstat(1M)会列出所有统计信息。例如,以下命令将所有统计信息的列表传输到grep(1)中搜索包含freemem的统计信息,然后使用wc(1)计算总统计数量:
$ kstat -p | grep freemem
unix:0:system_pages:freemem 5962178
unix:0:vminfo:freemem 184893612065859
$ kstat -p | wc -l
33195kstat统计信息没有正式文档记录,因为它们被认为是不稳定的接口——每当内核更改时就会发生变化。为了理解每个统计信息的作用,可以研究增加它们的位置在内核源代码中的实现(如果可用)。例如,累计freemem统计信息源自以下内核代码:
usr/src/uts/common/sys/sysinfo.h:
typedef struct vminfo { /* (update freq) update action */
uint64_t freemem; /* (1 sec) += freemem in pages */
uint64_t swap_resv; /* (1 sec) += reserved swap in pages */
uint64_t swap_alloc; /* (1 sec) += allocated swap in pages */
uint64_t swap_avail; /* (1 sec) += unreserved swap in pages */
uint64_t swap_free; /* (1 sec) += unallocated swap in pages */
uint64_t updates; /* (1 sec) ++ */
} vminfo_t;
usr/src/uts/common/os/space.c:
vminfo_t vminfo; /* VM stats protected by sysinfolock mutex */
usr/src/uts/common/os/clock.c:
static void clock(void)
{
[...]
if (one_sec) {
[...]
vminfo.freemem += freemem;freemem统计信息是由内核中的clock()例程每秒递增一次,其值由名为freemem的全局变量确定。可以检查修改freemem的位置以查看所有涉及的代码。
还可以研究现有系统工具的源代码(如果可用),以了解kstat使用的示例。
4.2.4 Delay Accounting
具有CONFIG_TASK_DELAY_ACCT选项的Linux系统跟踪每个任务在以下状态下的时间:
调度延迟:等待轮到使用CPU
阻塞I/O:等待块I/O完成
交换:等待分页(内存压力)
内存回收:等待内存回收例程
从技术上讲,调度延迟统计信息来自schedstats(早期在/proc中提到),但与其他延迟记账状态一起公开。 (它在struct sched_info中,而不是struct task_delay_info中。)
这些统计信息可以通过使用taskstats读取用户级工具来读取,taskstats是一种基于netlink的接口,用于获取每个任务和进程的统计信息。 内核源代码Documentation / accounting目录中有文档delay-accounting.txt和示例消费者getdelays.c:
$ ./getdelays -dp 17451
print delayacct stats ON
PID 17451
CPU count real total virtual total delay total delay average
386 3452475144 31387115236 1253300657 3.247ms
IO count delay total delay average
302 1535758266 5ms
SWAP count delay total delay average
0 0 0ms
RECLAIM count delay total delay average
0 0 0ms除非另有说明,否则时间单位为纳秒。此示例来自一个CPU负载较重的系统,并且正在检查的进程正在遭受调度延迟。
4.2.5 Microstate Accounting
基于Solaris的系统具有每个线程和每个CPU微状态记账,记录预定义状态的一组高分辨率时间。与先前基于tick的指标相比,这些指标大大提高了准确性,并提供了额外的状态以进行性能分析[MCDougall 06b]。它们通过kstat对用户级工具公开,以获取每个CPU指标和/proc以获取每个线程指标。
CPU微状态显示为mpstat(1M)的usr、sys和idl列(请参见第6章CPU)。您可以在内核代码中找到它们,例如CMS_USER、CMS_SYSTEM和CMS_IDLE。
线程微状态可见于prstat -m的USR、SYS等列,并在第6章CPU的6.6.7节prstat中进行了总结。
4.2.6 Other Observability Sources
其他各种可观察性来源包括:
CPU性能计数器:这些是可编程的硬件寄存器,提供低级性能信息,包括CPU周期计数、指令计数、停顿周期等等。在Linux上,它们通过perf_events接口和perf_event_open()系统调用进行访问,并被包括perf(1)在内的工具使用。在基于Solaris的系统上,它们通过libcpc进行访问,并由包括cpustat(1M)在内的工具使用。有关这些计数器和工具的更多信息,请参见第6章CPU。
进程级跟踪:这会跟踪用户级软件事件,例如系统调用和函数调用。通常执行起来很昂贵,会减慢目标速度。在Linux上,有ptrace()系统调用来控制进程跟踪,它被strace(1)用于跟踪系统调用。Linux还具有uprobes用于用户级动态跟踪。基于Solaris的系统使用procfs和truss(1)工具跟踪系统调用,并使用DTrace进行动态跟踪。
内核跟踪:在Linux上,tracepoints提供静态内核探针(最初为内核制造者),而kprobes提供动态探针。这两者都被追踪工具如ftrace、perf(1)、DTrace和SystemTap所使用。在基于Solaris的系统上,dtrace内核模块提供静态和动态探针。DTrace和SystemTap都是内核跟踪的消费者,在接下来的章节中将介绍静态和动态探针的术语解释。
网络抓包:这些接口提供了一种从网络设备捕获数据包进行详细研究的方式,以分析数据包和协议性能。在Linux上,通过libpcap库和/proc/net/dev实现抓包功能,并由tcpdump(8)工具使用。在基于Solaris的系统上,通过libdlpi库和/dev/net实现抓包功能,并由snoop(1M)工具使用。也为基于Solaris的系统开发了libpcap和tcpdump(8)的移植版本。捕获和检查所有数据包会带来CPU和存储开销。有关网络抓包的更多信息,请参见第10章"网络"。
进程账户:这一概念可以追溯到大型机时代,用于根据进程的执行和运行时间为部门和用户计费。Linux和基于Solaris的系统都以某种形式存在进程账户,并且在进程级别的性能分析中有时会很有帮助。例如,atop(1)工具使用进程账户来捕获并显示短生命周期进程的信息,否则在快照/proc时可能会被忽略。
系统调用:某些系统或库调用可提供一些性能指标。其中包括getrusage()函数调用,用于进程获取自身的资源使用统计信息,包括用户时间、系统时间、故障、消息和上下文切换。基于Solaris的系统还具有swapctl()系统函数,用于交换设备管理和统计(Linux中为/proc/swap)。如果您对每个接口的工作原理感兴趣,通常可以找到相关文档,这些文档是面向在这些接口上构建工具的开发人员编写的。
And More
根据您的内核版本和启用的选项,可能还会提供更多的可观察性源。一些在本书的后面章节中提到过。以下是一些例子:
Linux: I/O账户、blktrace、timer_stats、lockstat、debugfs
Solaris: 扩展账户、流量账户、Solaris审计
查找这些源的一种技术是阅读您感兴趣的内核代码,并查看是否在其中放置了统计信息或跟踪点。
在某些情况下,您可能无法获取您所需的内核统计信息。除了接下来介绍的动态跟踪之外,您可能会发现调试器可以获取内核变量以解决问题。其中包括gdb(1)和mdb(1)(仅适用于Solaris)。一种类似但更为困难的方法是通过打开/dev/mem或/dev/kmem直接读取内核内存的工具。
不同接口的多个可观察性源可能会增加学习负担,并且当它们的功能重叠时可能效率低下。由于DTrace自2003年起成为Solaris内核的一部分,已经有努力将一些旧的跟踪框架移植到DTrace,并从中满足所有新的跟踪需求。这种整合工作非常成功,并简化了基于Solaris的系统的跟踪。我们可以希望这种趋势继续下去,未来的内核将提供更少但更强大的可观察性框架。
4.3 Dtrace
DTrace是一个包含编程语言和工具的可观察性框架。本节概述了DTrace的基础知识,包括动态和静态跟踪、探针、提供者、D语言、动作、变量、一行脚本和脚本编写。它旨在作为DTrace入门指南,为您提供足够的背景,以便在本书后面理解其在基于Solaris和Linux的系统上扩展性能可观察性的使用。
DTrace可以通过称为探针的插装点观察所有用户级和内核级代码。当探针被触发时,可以在其D语言中执行任意操作。操作可以包括计数事件、记录时间戳、执行计算、打印值和汇总数据。这些操作可以在实时跟踪仍然启用的情况下执行。
以下是使用DTrace进行动态跟踪的示例,此示例对内核ZFS(文件系统)spa_sync()函数进行了插装,显示了完成时间和持续时间(单位为纳秒)(illumos kernel):
# dtrace -n 'fbt:zfs:spa_sync:entry { self->start = timestamp; }
fbt:zfs:spa_sync:return /self->start/ { printf("%Y: %d ns",
walltimestamp, timestamp - self->start); self->start = 0; }'
dtrace: description 'fbt:zfs:spa_sync:entry ' matched 2 probes
CPU ID FUNCTION:NAME
7 65353 spa_sync:return 2012 Oct 30 00:20:27: 63849335 ns
12 65353 spa_sync:return 2012 Oct 30 00:20:32: 39754457 ns
18 65353 spa_sync:return 2012 Oct 30 00:20:37: 261013562 ns
8 65353 spa_sync:return 2012 Oct 30 00:20:42: 29800786 ns
17 65353 spa_sync:return 2012 Oct 30 00:20:47: 250368664 ns
20 65353 spa_sync:return 2012 Oct 30 00:20:52: 37450783 ns
11 65353 spa_sync:return 2012 Oct 30 00:20:57: 56010162 ns
[...]spa_sync()函数将写入的数据刷新到ZFS存储设备,导致磁盘I/O的突发。它在性能分析中特别受关注,因为I/O有时可能会排队等待已发出的磁盘I/O。使用DTrace,可以立即查看和研究spa_sync()触发的频率和持续时间的信息。可以以类似的方式研究其他数千个内核函数,无论是打印每个事件的详细信息还是对其进行汇总。
DTrace与其他跟踪框架(例如系统调用跟踪)的一个关键区别在于,DTrace被设计为在生产环境中安全可靠,并且性能开销最小化。它通过使用每个CPU的内核缓冲区来实现这一点,从而改善内存本地性,减少缓存一致性开销,并且可以消除同步锁的需要。这些缓冲区还用于以温和的速率(默认情况下每秒一次)向用户空间传递数据,从而最小化上下文切换。DTrace还提供了一组在内核中汇总和过滤数据的操作,也可以减少数据开销。
DTrace支持静态和动态跟踪,每种跟踪方式都提供互补的功能。静态探针具有文档化和稳定的接口,而动态探针可以根据需要提供几乎无限的可观察性。
4.3.1 Static and Dynamic Tracing
理解静态和动态跟踪的一种方法是查看涉及的源代码和CPU指令。考虑以下来自内核块设备接口(illumos)的代码,路径为usr/src/uts/common/os/bio.c:
/*
* Mark I/O complete on a buffer, release it if I/O is asynchronous,
* and wake up anyone waiting for it.
*/
void
biodone(struct buf *bp)
{
if (bp->b_flags & B_STARTED) {
DTRACE_IO1(done, struct buf *, bp);
bp->b_flags &= ~B_STARTED;
}
[...]DTRACE_IO1宏是静态探针的一个示例,它在编译之前添加到代码中。源代码中没有动态探针的可见示例,因为这些探针是在软件运行时编译之后添加的。此函数的已编译指令如下(截断):
> biodone::dis
biodone: pushq %rbp
biodone+1: movq %rsp,%rbp
biodone+4: subq $0x20,%rsp
biodone+8: movq %rbx,-0x18(%rbp)
biodone+0xc: movq %rdi,-0x8(%rbp)
biodone+0x10: movq %rdi,%rbx
biodone+0x13: movl (%rdi),%eax
biodone+0x15: testl $0x2000000,%eax
[...]当使用动态跟踪来探测进入biodone()函数时,第一条指令会被改变:
> biodone::dis
biodone: int $0x3
biodone+1: movq %rsp,%rbp
biodone+4: subq $0x20,%rsp
biodone+8: movq %rbx,-0x18(%rbp)
biodone+0xc: movq %rdi,-0x8(%rbp)
biodone+0x10: movq %rdi,%rbx
biodone+0x13: movl (%rdi),%eax
biodone+0x15: testl $0x2000000,%eax
[...]int指令调用软中断,该软中断被编程以执行动态跟踪操作。当禁用动态跟踪时,该指令将恢复到原始状态。这是对内核地址空间进行现场修补的技术,使用的技术可能因处理器类型而异。
只有在启用动态跟踪时才会添加指令。当未启用时,没有额外的指令用于仪器化,因此也没有探测效果。这被描述为不使用时的零开销。当使用时,由于额外的指令,开销与探测事件的触发速率成比例:即被跟踪事件的速率以及它们执行的操作。
DTrace可以动态跟踪函数的进入和返回,以及用户空间中的任何指令。由于它根据CPU指令动态构建探针,而不同软件版本之间的CPU指令可能有所不同,因此被视为不稳定的接口。基于动态跟踪的任何DTrace一行命令或脚本可能需要更新,以适应其跟踪的较新软件版本。
4.3.2 Probes
DTrace探针以四元组命名:
provider:module:function:name提供者是相关探针的集合,类似于软件库。模块和函数是动态生成的,并指定了探针的代码位置。名称是探针本身的名称。
在指定这些时,可以使用通配符(“*”)。将字段留空(“::”)等同于通配符(“:*:”)。还可以从探针规范中删除留空的字段(例如,“:::BEGIN” == “BEGIN”)。
例如:
io:::start这是来自io提供者的start探针。模块和函数字段留空,因此它们将匹配start探针的所有位置。
4.3.3 Providers
可用的DTrace提供者取决于您的DTrace和操作系统版本。它们可能包括:
- syscall:系统调用陷阱表
- vminfo:虚拟内存统计信息
- sysinfo:系统统计信息
- profile:在任意速率下进行采样
- sched:内核调度事件
- proc:进程级事件:创建、执行、退出
- io:块设备接口跟踪(磁盘I/O)
- pid:用户级动态追踪
- tcp:TCP协议事件:连接、发送和接收
- ip:IP协议事件:发送和接收
- fbt:内核级动态跟踪
还有许多用于高级语言的其他提供者:Java、JavaScript、Node.js、Perl、Python、Ruby、Tcl等。
许多提供者使用静态跟踪实现,因此它们具有稳定的接口。在可能的情况下,最好使用这些(而不是动态跟踪),以便您的脚本适用于目标软件的不同版本。这种权衡是可见性相对较低,因为只有必要的内容提升到稳定的接口,以最小化维护和文档负担。
4.3.4 Arguments
探针可以通过一组称为参数的变量提供数据。参数的使用取决于提供者。
例如,syscall提供者为每个系统调用提供了入口和返回探针。它们设置以下参数变量:
入口:arg0,...,argN:系统调用的参数
返回:arg0或arg1:返回值;同时设置errno
fbt和pid提供者以类似的方式设置参数,允许检查传递给内核或用户级函数的数据以及返回的数据。
要了解每个提供者的参数是什么,可以参考其文档(也可以尝试使用带有-lv选项的dtrace(1),它会打印一个摘要)。
4.3.5 D Language
D语言类似于awk,可以用于单行命令或脚本(与awk相同)。DTrace语句的形式为
probe_description /predicate/ { action }动作是一系列可选的分号分隔的语句,当探针触发时执行。谓词是一个可选的过滤表达式。例如,语句
proc:::exec-success /execname == "httpd"/ { trace(pid); }跟踪proc提供者中的exec-success探针,并在进程名称等于"httpd"时执行打印动作trace(pid)。exec-success探针通常用于跟踪新进程的创建,并记录成功的exec()系统调用。使用内置变量execname获取当前进程名称,使用pid获取当前进程ID。
4.3.6 Built-in Variables
内置变量可用于计算和谓词,并可以使用trace()和printf()等动作进行打印。常用的内置变量列在表4.2中。

4.3.7 Actions
常用的动作包括表4.3中列出的动作。

列出的最后三个动作是用于一种特殊变量类型,称为聚合。
4.3.8 Variable Types
表4.4总结了变量的类型,按照使用偏好的顺序列出(首选聚合变量,然后是开销从低到高的变量)。

线程本地变量具有每个线程范围。这允许将数据(如时间戳)与线程轻松关联起来。
语句本地变量用于中间计算,仅在相同探针描述的动作语句中有效。
多个CPU同时写入同一个标量变量可能导致变量状态损坏,因此会显示“no”。尽管这种情况不太可能发生,但确实发生过,并且已经注意到对字符串标量的影响(导致字符串损坏)。
聚合是一种特殊的变量类型,可以按CPU进行累积,并在以后进行组合以传递给用户空间。它们具有最低的开销,并用于以不同方式汇总数据。
填充聚合的动作列在表4.5中。


作为聚合和直方图动作quantize()的示例,以下显示了read()系统调用返回的大小:

这个一行代码在跟踪时收集统计信息,并在dtrace结束时打印摘要,本例中是当键入Ctrl-C时。输出的第一行"dtrace: description . . ."是dtrace默认打印的,表示跟踪已经开始。
value列是量化范围的最小大小,count列是该范围内的出现次数。中间显示了分布的ASCII表示。在这种情况下,最常返回的大小为零字节,共发生447次。许多返回的读取大小在8,192到131,071字节之间,其中170次在16,384到32,767范围内。这种双峰分布在只报告平均值的工具中不会被注意到。
4.3.9 One-Liners
DTrace允许您编写简洁而强大的一行命令,就像我之前演示的那样。以下是更多的例子。
跟踪open()系统调用,打印进程名称和文件路径名:
dtrace -n 'syscall::open:entry { printf("%s %s", execname, copyinstr(arg0)); }'请注意,Oracle Solaris 11显着修改了系统调用陷阱表(由DTrace探测以创建syscall提供程序),因此在该系统上跟踪open()变得更加复杂。
dtrace -n 'syscall::openat:entry { printf("%s %s", execname, copyinstr(arg1)); }'按进程名称汇总CPU跨调用:
dtrace -n 'sysinfo:::xcalls { @[execname] = count(); }'以99 Hz的频率对内核级堆栈进行采样:
dtrace -n 'profile:::profile-99 { @[stack()] = count(); }'本书中还使用了许多更多的DTrace一行命令,并在附录D中列出。
4.3.10 Scripting
DTrace语句可以保存到文件中以供执行,这样就可以编写更长的DTrace程序。
例如,bitesize.d脚本按进程名称显示请求的磁盘I/O大小:
#!/usr/sbin/dtrace -s
#pragma D option quiet
dtrace:::BEGIN
{
printf("Tracing... Hit Ctrl-C to end.\n");
}
io:::start
{
this->size = args[0]->b_bcount;
@Size[pid, curpsinfo->pr_psargs] = quantize(this->size);
}
dtrace:::END
{
printf("\n%8s %s\n", "PID", "CMD");
printa("%8d %S\n%@d\n", @Size);
}由于这个文件以解释器行(#!)开头,可以将其设置为可执行,并从命令行运行。
#pragma行设置了静默模式,可以抑制默认的DTrace输出(在前面的spa_sync()示例中看到,包括CPU、ID和FUNCTION:NAME列)。
脚本中的io:::start探针实现了实际的启用操作。
dtrace:::BEGIN探针在开始时触发以打印信息消息,dtrace:::END在结束时触发以格式化并打印摘要。
以下是一些示例输出:

在跟踪过程中,大部分磁盘I/O是由tar命令请求的,其大小如上所示。
bitesize.d是一个名为DTraceToolkit的DTrace脚本集合中的一部分,可以在线找到。
4.3.11 Overheads
正如前面提到的,DTrace通过使用每个CPU的内核缓冲区和内核聚合摘要来最小化插装开销。默认情况下,它还以每秒一次的温和异步速率将数据从内核空间传递到用户空间。它具有各种其他功能,可降低开销并提高安全性,包括一种例程,当检测到系统可能出现无响应时,它将中止跟踪。
进行跟踪的开销成本与跟踪频率和它们执行的操作有关。跟踪块设备I/O通常是如此罕见(每秒1,000次I/O或更少),以至于开销可以忽略不计。另一方面,跟踪网络I/O时,数据包速率可能达到每秒数百万个,可能会导致显着的开销。
此外,执行动作也是有代价的。例如,我经常以997 Hz的速率跨所有CPU对内核堆栈进行采样(使用stack()),而没有明显的开销。对用户级堆栈进行采样更为复杂(使用ustack()),因此我通常将速率降低到97 Hz。
保存数据到变量中也会带来开销,特别是关联数组。虽然使用DTrace通常不会引起明显的开销,但你需要意识到这是可能的,并且需要谨慎使用。
4.3.12 Documentation and Resources
DTrace的参考资料,其中记录了所有操作、内建函数和标准提供者,是动态跟踪指南,最初由Sun Microsystems编写并在线免费提供[2]。关于动态跟踪的背景、它解决的问题以及DTrace的发展,请参阅[Cantrill 04]和[Cantrill 06]。
附录D列出了方便的DTrace一行命令。除了它们的实用性外,它们可能是逐行学习DTrace的有用参考资料。
要查看脚本和策略的参考资料,请参阅《DTrace:Oracle Solaris、Mac OS X和FreeBSD中的动态跟踪》[Gregg 11]。该书中的脚本可在网上获取[3]。
DTraceToolkit包含超过200个脚本,目前托管在我的主页上[4]。其中许多脚本使用shell或Perl封装,以提供命令行选项和类似其他Unix工具的行为,例如execsnoop。

还基于DTrace构建了一些图形用户界面(GUI),包括Oracle ZFS Appliance Analytics和Joyent Cloud Analytics。
4.4 SystemTap
SystemTap还为用户级和内核级代码提供了静态和动态跳迹追踪,最初由来自Red Hat、IBM和英特尔的团队在Linux上设计[Eigler 05]。当时Linux还没有DTrace的移植版本。与DTrace类似,称为探针的插装点可以被编程以执行任意操作,包括事件计数、记录时间戳、执行计算、打印数值、汇总数据等等。这些操作是在实时跟踪的同时进行的。SystemTap可以从命令行中作为一行命令或脚本来使用。
SystemTap利用其他内核框架进行跟踪:静态探针使用tracepoints,动态探针使用kprobes,用户级探针使用uprobes。这些资源也被其他工具(如perf、LTTng)所使用。
经过数年的开发,SystemTap在匹配DTrace的功能集方面取得了良好的进展,有时甚至超越了它。然而,稳定性一直是一个问题,一些版本会导致内核恐慌或死机。此外,与DTrace相比,SystemTap还存在其他问题,尽管相对较小:启动时间较慢,错误消息令人困惑,未记录的隐式功能以及语言不够简洁。
与此同时,已经开始了两个将DTrace移植到Linux的独立项目。其中一个是由Oracle为Oracle Enterprise Linux进行的;另一个是由英国的程序员Paul Fox主要独自完成的努力。这些移植已被用于本书中提供的DTrace Linux示例。由于这些是新的项目并且仍在开发中,它们也可能引发内核恐慌。
如果您希望或需要改用SystemTap,可以将本书中的大多数DTrace脚本转换为SystemTap脚本。附录E是一个简短的转换指南。
下一节概述了SystemTap的基础知识,包括探针(probes)、tapsets、操作(actions)和内建功能(built-ins),然后提供了两个SystemTap示例进行比较。
4.4.1 Probes
探针定义以句点分隔,括号中可选嵌入参数。一些示例包括:
begin:程序开始
end:程序结束
syscall.read:read()系统调用开始
syscall.read.return:read()系统调用结束
kernel.function("sys_read"):内核sys_read()函数开始
kernel.function("sys_read").return:sys_read()函数结束
socket.send:socket发送
timer.ms(100):在一个CPU上每100毫秒触发一次的探针
timer.profile:以内核时钟速率在所有CPU上触发的探针,用于采样/分析
process("a.out").statement("*@main.c:100"):跟踪目标进程,可执行文件为"a.out",位于main.c第100行
许多探针提供相关数据作为内建变量。例如,syscall.read探针提供请求大小作为$count。
4.4.2 Tapsets
相关探针组被称为tapsets。许多探针的名称开头包含tapset名称。一些tapset的示例包括:
syscall:系统调用
ioblock:块设备接口和I/O调度器
scheduler:内核CPU调度器事件
memory:进程和虚拟内存使用情况
scsi:SCSI目标事件
networking:网络设备事件,包括接收和发送
tcp:TCP协议事件,包括发送和接收事件
socket:套接字事件
tapsets还用于提供额外的可执行操作。
4.4.3 Actions and Built-ins
SystemTap还提供许多操作和内建函数,包括execname()用于进程名称,pid()用于当前进程ID,以及print_backtrace()用于打印内核堆栈回溯。更多内容列在附录E中。
4.4.4 Examples
以下一行命令追踪read()系统调用,将返回的读取大小保存为2的幂次直方图。这既作为SystemTap的示例,也作为与DTrace进行比较的范例,前面已展示了等效的一行命令。


-v选项会打印有关编译阶段的详细信息,当追踪被启用时会通知用户("starting run")。如果没有该选项,SystemTap默认不会打印任何内容,让您疑惑追踪何时开始。在某些情况下,编译阶段可能需要超过20秒,早期的Ctrl-C不仅会完全中止追踪,还可能根据中断的编译阶段打印令人困惑的错误信息。
这条一行命令首先声明了一个名为stats的全局变量 —— SystemTap要求进行预声明。探针定义以关键字probe开头,匹配read()系统调用的返回。动作是使用统计运算符<<<将返回值(作为$return提供)记录在stats变量中。这以一种通用方式记录数值,允许稍后以不同方式对其进行总结。
结束探针需要打印此统计变量作为直方图。如果没有它,SystemTap在退出时只会打印基本的数字摘要。
关于直方图的最后一点说明:read()的$return值有时是负数 —— 设置为错误号(errno)的负版本。这遵循内核约定而非POSIX标准,可能会让期望看到后者的用户感到困惑。也并不清楚这是否是有意为之,因为$return的目的未经记录。
以下是等效的一行命令,首先是SystemTap,然后是DTrace:

像这样的比较可以更深入地理解每种技术。这里有一个不同的示例,这次使用SystemTap来突显DTrace的局限性:


这条一行命令通过进程名称保存read返回大小的统计信息。它使用三个不同的函数打印,提供了调用次数、平均大小(字节)和总字节数的列。为此,DTrace需要填充三个单独的聚合,每种类型一个。
这还利用了if语句和foreach循环。DTrace不提供if语句,而是通过谓词提供分支功能,有时对程序员来说可能不太自然。此外,DTrace目前没有循环能力,除了展开的循环,出于安全考虑,它永远不会执行向后跳转。
SystemTap通过为循环提供上限解决了这个问题,以便在SystemTap脚本中的无限循环不会在内核上下文中挂起。
最后一个区别是:在SystemTap中可以直接访问统计值,如s[k],而DTrace聚合只能整体打印或通过聚合函数进行处理。
4.4.5 Overheads
使用SystemTap的开销与之前描述的DTrace类似,使用时需要注意相同的问题。此外,当程序首次执行时,SystemTap的编译阶段可能会消耗CPU资源(持续几秒钟)。SystemTap会缓存程序,以便不会在每次使用时发生这种开销。还应该有可能在不同系统上编译SystemTap程序,然后将缓存结果传输到目标系统。
另一个额外的开销是需要内核调试信息进行内核分析,这通常不包含在Linux发行版中(其大小可能达数百兆字节)。
4.4.6 Documentation and Resources
SystemTap有大量的man页面,包括单个探针的页面。例如,对于ioblock.request探针:

SystemTap语言的文档可以在SystemTap语言参考[5]的在线页面中找到。在SystemTap文档网站[6]上还有教程、入门指南和tapset参考。
您还可以将本书中的所有DTrace示例视为可能的SystemTap功能示例。请参阅附录E以获取它们的转换示例。
4.5 perf
Linux性能事件(LPE),简称perf,一直在发展以支持广泛的性能可观测活动。尽管它目前没有DTrace或SystemTap的实时编程能力,但它可以执行静态和动态跟踪(基于跟踪点、kprobes和uprobes),以及性能分析。它还可以检查堆栈跟踪、本地变量和数据类型。由于它是主线内核的一部分,如果已经存在,则可能是使用最简单的,并且可能提供足够的可观测性以回答您的许多问题。
perf(1)的一些跟踪开销应该与DTrace相似。在典型的用法中,DTrace程序被编写为汇总内核中的数据(聚合),而perf(1)目前不会这样做。使用perf(1),数据会传递到用户级别进行后处理(它有一个脚本框架来帮助),当跟踪频繁事件时,这可能会导致显着的额外开销。请参阅第6章CPU的第6.6节“分析”,介绍perf(1)并演示其许多功能。
4.6 Observing Observability
可观测性工具及其所构建的统计数据是在软件中实现的,而所有软件都有可能存在错误。描述软件的文档也是如此。对于您不熟悉的任何统计数据,应该持健康的怀疑态度,质疑它们真正意味着什么,以及它们是否真的正确。
度量指标可能存在以下问题:
- 工具并非总是正确。
- man手册并非总是正确。
- 可用的度量可能是不完整的。
- 可用的度量可能设计不佳。
当多个可观测性工具具有重叠覆盖范围时,您可以使用它们相互交叉检查。理想情况下,它们将使用不同的框架来检查其中的错误。动态跟踪对此尤为有用,因为可以使用它创建自定义工具。
另一种验证技术是应用已知的工作负载,然后检查可观测性工具是否与您预期的结果一致。这可能涉及使用微基准测试工具报告其自己的统计数据进行比较。
有时候出错的不是工具或统计数据,而是描述它们的文档,包括man手册。软件可能已经发展,但文档尚未更新。
现实情况是,您可能没有时间再次核对每个使用的性能测量数据,只有在遇到异常结果或使用特别重要的结果时才会这样做。即使您没有再次核对,意识到您没有这样做,并且假设工具是正确的也是有价值的。
除了度量指标可能不正确外,它们也可能是不完整的。面对大量工具和度量指标时,可能会诱人地认为它们提供了完整和有效的覆盖范围。然而事实往往并非如此:度量指标可能是程序员添加用于调试其代码,然后稍后构建为可观测性工具,而没有进行针对实际客户需求的深入研究。有些程序员可能根本没有向新子系统添加任何内容。
缺乏度量指标可能比存在低质量度量指标更难以识别。第二章“方法论”可以通过研究您在性能分析中需要回答的问题来帮助您找到这些缺失的度量指标。
5 Applications
性能最好在最接近工作执行地点的地方进行调优:即在应用程序中。这些应用程序包括数据库、Web 服务器、应用服务器、负载均衡器、文件服务器等等。接下来的章节将从它们消耗的资源的角度探讨应用程序:CPU、内存、文件系统、磁盘和网络。本章节涉及应用程序层面。
应用程序本身可能变得极为复杂,特别是在涉及许多组件的分布式应用环境中。对应用程序内部的研究通常是应用程序开发人员的领域,可以包括使用第三方工具进行内省。对于那些研究系统性能的人,包括系统管理员,应用程序性能分析包括配置应用程序以最佳利用系统资源,描述应用程序如何使用系统以及分析常见病理学。
本章讨论了应用程序基础知识、应用程序性能的基本原理、编程语言和编译器,以及通用应用程序性能分析策略。
5.1 Application Basics
在深入研究应用程序性能之前,您应该熟悉应用程序的作用、基本特征以及其在行业中的生态系统。这构成了您理解应用程序活动的背景。它还为您提供了学习常见性能问题和调优的机会,并为进一步研究提供途径。为了了解这一背景,请尝试回答以下问题:
功能:应用程序的作用是什么?它是数据库服务器、Web 服务器、负载均衡器、文件服务器、对象存储等?
操作:应用程序提供哪些请求,或执行哪些操作?数据库提供查询(和命令),Web 服务器提供 HTTP 请求,等等。这可以作为一个速率来衡量,以评估负载和进行容量规划。
CPU 模式:应用程序是作为用户级软件还是内核级软件实现的?大多数应用程序是用户级的,作为一个或多个进程执行,但有些是作为内核服务实现的(例如 NFS)。
配置:应用程序如何配置,以及为什么这样配置?这些信息可能在配置文件中找到,也可能通过管理工具获得。检查是否已更改与性能相关的可调参数,包括缓冲区大小、缓存大小、并行性(进程或线程)以及其他选项。
指标:应用程序是否提供指标,比如操作速率?它们可以通过捆绑工具或第三方工具提供,通过 API 请求提供,或通过处理操作日志提供。
日志:应用程序创建哪些操作日志?哪些日志可以启用?日志中提供了哪些性能指标,包括延迟?例如,MySQL 支持慢查询日志,为每个超过一定阈值的查询提供有价值的性能详细信息。
版本:应用程序是否是最新版本?最近版本的发布说明中有性能修复或改进吗?
错误:应用程序是否有一个错误数据库?对于您的应用程序版本来说,“性能”错误是什么?如果您有当前的性能问题,请搜索错误数据库,看看以前是否发生过类似情况,以及是如何调查的,还有什么其他内容。
社区:是否有一个应用程序社区,用于分享性能发现?社区可能包括论坛、博客、Internet Relay Chat (IRC) 频道、聚会和会议。聚会和会议通常会在线发布幻灯片和视频,在之后几年内这些都是有用的资源。他们还可能有一个社区经理分享社区更新和新闻。
图书:是否有关于应用程序及/或其性能的图书?
专家:谁是该应用程序的公认的性能专家?了解他们的名字可以帮助您找到他们撰写的材料。
无论信息来源如何,您的目标是在高层次上理解应用程序——它的功能、运作方式以及性能。如果能找到的话,一张展示应用程序内部的功能图是非常有用的资源。下一节将涵盖其他应用程序基础知识:设定目标、优化常见情况、可观测性和大 O 表示法。
5.1.1 Objectives
一个性能目标为您的性能分析工作提供方向,并帮助您选择要执行的活动。如果没有明确的目标,性能分析就有可能变成一次随机的“搜寻探险”。
对于应用程序性能,您可以从应用程序执行的操作(如前所述)和性能目标开始。目标可能是:
延迟:低应用程序响应时间
吞吐量:高应用程序操作速率或数据传输速率
资源利用率:给定应用程序工作负载的效率
最好能够量化这些目标,使用可能来自业务或服务质量要求的指标。例如:
平均应用程序请求延迟为5毫秒
95% 的请求延迟不超过100毫秒
消除延迟异常值:零个请求超过1000毫秒
每台服务器每秒至少10,000个应用程序请求的最大吞吐量
每秒10,000个应用程序请求的平均磁盘利用率低于50%
选择了一个目标之后,您可以着手解决该目标的限制因素。对于延迟,限制因素可能是磁盘或网络I/O;对于吞吐量,它可能是CPU使用率。本章和其他章节中的策略将帮助您识别它们。
针对基于吞吐量的目标,请注意并非所有操作在性能或成本方面都是相等的。如果目标是某种操作速率,也许重要的是还要指定它们是什么类型的操作。这可能是根据预期或实测工作负载进行的分布。
第5.2节《应用程序性能技术》介绍了改善应用程序性能的常见方法。其中一些方法可能适用于某个目标,但对另一个目标则不适用;例如,选择更大的I/O大小可能会以延迟为代价提高吞吐量。请记住您正在追求的目标,以确定哪些主题最为适用。
5.1.2 Optimize the Common Case
软件内部结构可能非常复杂,具有许多不同的可能代码路径和行为。如果您查看源代码,这一点可能尤为明显:应用程序通常包含数万行代码,而操作系统内核则包含数十万行以上。随意选择要优化的区域可能需要大量工作,但收益却不多。
提高应用程序性能的一种有效方法是找到生产工作负载中最常见的代码路径,并从改进那些路径开始。如果应用程序受限于CPU,这可能意味着频繁使用CPU的代码路径。如果应用程序受限于I/O,您应该关注那些经常导致I/O的代码路径。这些可以通过对应用程序进行分析和性能分析来确定,包括研究堆栈跟踪,正如后续章节所述。应用程序可观察性工具也可以提供更高级别的上下文,以便理解常见情况。
5.1.3 Observability
正如本书的许多章节所描述的那样,操作系统中最大的性能提升可以通过消除不必要的工作来实现。这同样适用于应用程序。
然而,在选择应用程序时,有时会忽视这个事实。如果基准测试显示应用程序A比应用程序B快10%,可能会诱人选择应用程序A。然而,如果应用程序A是不透明的,而应用程序B提供了丰富的可观测性工具,长远来看,应用程序B很可能是更好的选择。这些可观测性工具使得能够看到并消除不必要的工作,同时主动工作也可以更好地理解和调整。通过增强的可观测性获得的性能提升可能会使最初的10%性能差异相形见绌。
5.1.4 Big O Notation
大O符号,通常作为计算机科学的一个学科进行教授,用于分析算法的复杂度,并模拟随着输入数据集规模扩大它们的性能表现。这有助于程序员在开发应用程序时选择更有效率和性能更好的算法([Knuth 76],[Knuth 97])。
常见的大O符号和算法示例列在表5.1中。

这种符号允许程序员估计不同算法的加速比,确定哪些代码区域将带来最大的改进。例如,在搜索一个包含100个项的排序数组时,线性搜索和二分搜索之间的差异是21倍(100 / log(100))。
这些算法的性能如图5.1所示,显示它们随着规模扩大的趋势。

这种分类有助于系统性能分析师理解,某些算法在规模上会表现非常糟糕。当应用程序需要为比以往任何时候都更多的用户或数据对象提供服务时,性能问题可能会出现,此时O(n^2)等算法可能会变得病态。解决方法可能是开发人员使用更高效的算法,或者以不同方式对人口进行分割。
大O符号确实忽略了为每个算法选择所产生的一些常数计算成本。对于输入数据大小n较小的情况,这些成本可能会占主导地位。
5.2 Application Performance Techniques
本节介绍了一些常用的技术,可通过这些技术改善应用程序的性能:选择I/O大小、缓存、缓冲、轮询、并发和并行、非阻塞I/O以及处理器绑定。请参考应用程序文档,了解其中使用了哪些技术,以及任何额外的特定于应用程序的功能。
5.2.1 Selecting an I/O Size
执行I/O操作涉及的成本可能包括初始化缓冲区、进行系统调用、上下文切换、分配内核元数据、检查进程特权和限制、将地址映射到设备、执行内核和驱动程序代码以进行I/O传输,最后释放元数据和缓冲区。小型和大型I/O都需要支付“初始化开销”。为了提高效率,每次I/O传输的数据量越大越好。增加I/O大小是应用程序用来提高吞吐量的常见策略。通常情况下,以单个I/O传输128K字节要比以128个1K字节的I/O传输更有效,考虑到任何固定的每个I/O的成本。特别是磁盘I/O由于寻道时间的原因,历来具有较高的每个I/O成本。
当应用程序不需要更大的I/O大小时,会出现一些不利影响。进行8K字节随机读取的数据库在使用128K字节的I/O大小时可能运行速度较慢,因为会浪费120K字节的数据传输。这会引入I/O延迟,可以通过选择更接近应用程序请求的较小I/O大小来降低。不必要地增大I/O大小也会浪费缓存空间。
5.2.2 Caching
操作系统使用缓存来提高文件系统读取性能和内存分配性能;应用程序通常也使用缓存以达到类似的目的。与其每次都执行昂贵的操作,不如将常见操作的结果存储在本地缓存中以备将来使用。一个例子是数据库缓冲区缓存,它存储了常见数据库查询的结果。
在部署应用程序时,一个常见任务是确定系统提供了哪些缓存,或者可以启用哪些缓存,然后配置它们的大小以适应系统。缓存的一个重要方面是它如何管理完整性,以确保查找不会返回过期数据。这被称为缓存一致性,可能是一个昂贵的操作,但理想情况下不会超过缓存提供的好处。
尽管缓存提高了读取性能,但它们的存储通常也被用作缓冲区以提高写入性能。
5.2.3 Buffering
为了提高写入性能,数据可能会在发送到下一级之前在缓冲区中合并。这会增加I/O大小和操作的效率。根据写入的类型,这也可能会增加写入延迟,因为缓冲区的第一个写入要等待后续的写入才能被发送。环形缓冲区(或循环缓冲区)是一种固定缓冲区的类型,可用于组件之间的连续传输,这些组件以异步方式对缓冲区进行操作。它可以使用起始和结束指针来实现,每个组件在数据追加或移除时都可以移动这些指针。
5.2.4 Polling
轮询是一种技术,系统通过在循环中检查事件的状态,并在检查之间暂停来等待事件发生。轮询可能存在一些潜在的性能问题:
- 重复检查造成的昂贵 CPU 开销
- 事件发生与下一次轮询检查之间的高延迟
当这成为一个性能问题时,应用程序可以改变自身行为以监听事件的发生,这会立即通知应用程序并执行所需的例程。
poll() 系统调用
有一个 poll() 系统调用用于检查文件描述符的状态,它具有与轮询类似的功能,但是它是基于事件的,因此不会承受轮询的性能成本。
poll() 接口支持将多个文件描述符作为数组,这要求应用程序在事件发生时扫描数组以找到相关的文件描述符。这种扫描的复杂度是O(n)(参见5.1.4节,大O符号表示法),其开销可能在规模化时成为性能问题。还有另一种可用的接口:在Linux上是epoll(),可以避免扫描,因此复杂度为O(1)。基于Solaris的系统具有类似的特性,称为事件端口,它使用port_get(3C)而不是poll()。
5.2.5 Concurrency and Parallelism
时间共享系统(包括所有源自Unix的系统)提供程序并发性:能够加载和开始执行多个可运行程序。虽然它们的运行时间可能重叠,但不一定在同一时刻在CPU上执行。这些程序中的每一个可以是一个应用程序进程。
除了同时执行不同的应用程序之外,应用程序内的不同功能也可以并发执行。可以使用多进程(多进程)或多线程(多线程)来实现这一点,每个进程或线程执行自己的任务。
另一种方法是基于事件的并发性,即应用程序在不同函数之间提供服务,并在事件发生时切换。例如,Node.js运行时采用了这种方式。这提供了并发性,但可能仅使用单个线程或进程,这最终可能成为可扩展性瓶颈,因为它只能利用一个CPU。
要充分利用多处理器系统,应用程序必须同时在多个CPU上执行。这就是并行性,应用程序可以通过多进程或多线程来实现。出于第6章中所述的原因,CPU、多线程(或相应的任务)更有效率,因此是首选的方法。
除了增加CPU工作的吞吐量,多线程(或进程)允许I/O并发执行,因为其他线程可以在一个线程因I/O而阻塞时执行。
由于多线程编程与进程共享相同的地址空间,线程可以直接读写相同的内存,无需更昂贵的接口(如多进程编程中的进程间通信(IPC))。为了保持数据的完整性,使用同步原语以防止多个线程同时读写数据时数据变得损坏。这些同步原语可以与哈希表结合使用,以提高性能。
同步原语
同步原语类似于交通信号灯,用于监控对内存的访问,就像交通信号灯调节对十字路口的通行一样。与交通信号灯一样,它们会阻止流量,导致等待时间(延迟)。常用的三种类型是:
- 互斥锁(Mutex locks):只有锁的持有者可以操作,其他人会被阻塞并在CPU外等待。
- 自旋锁(Spin locks):自旋锁允许持有者操作,而需要锁的其他线程在CPU上紧密循环旋转,检查锁是否被释放。虽然这些锁可以提供低延迟访问——被阻塞的线程永远不会离开CPU,在锁可用时几个周期内即可准备运行,但它们也会浪费CPU资源,因为线程在等待时会旋转。
- 读写锁(RW locks):读写锁通过允许多个读者或仅允许一个写者且没有读者来确保完整性。
互斥锁可能由库或内核实现为自适应互斥锁(adaptive mutex locks):自旋和互斥锁的混合体,如果持有者当前在另一个CPU上运行,则会旋转,否则会阻塞(或达到自旋阈值时)。自适应互斥锁经过优化,提供低延迟访问而不浪费CPU资源,在基于Solaris系统上已经使用多年。它们于2009年在Linux上实现,被称为自适应旋转互斥锁。研究涉及锁的性能问题可能是耗时的,通常需要熟悉应用程序源代码。这通常是开发人员的工作。
哈希表
可以使用一个锁的哈希表来为大量数据结构使用最佳数量的锁。虽然这里总结了哈希表,但这是一个假定具有编程背景的高级主题。
想象以下两种方法:
- 为所有数据结构使用单个全局互斥锁。虽然这个解决方案简单,但并发访问会遇到锁争用和等待时延。需要锁的多个线程会串行执行,而不是并发执行。
- 为每个数据结构使用一个互斥锁。虽然这样可以将争用减少到只有在真正需要时才会发生——对同一数据结构的并发访问,但为每个数据结构的创建和销毁锁会带来存储开销和CPU开销。
锁的哈希表是一个中间解决方案,适用于预计锁争用较轻的情况。创建固定数量的锁,并使用哈希算法选择哪个锁用于哪个数据结构。这避免了与数据结构的创建和销毁成本,也避免了只有一个锁的问题。
图5.2中示例的哈希表有四个条目,称为桶,每个桶包含自己的锁。

这个例子还展示了解决哈希冲突的一种方法,即两个或多个输入数据结构哈希到同一个桶的情况。在这里,创建了一系列数据结构来将它们全部存储在同一个桶下,它们将再次被哈希函数找到。如果哈希链变得太长并且按顺序遍历,这些哈希链可能会成为性能问题。哈希函数和表大小可以根据在许多桶中均匀分布数据结构的目标选择,以将哈希链长度保持在最小值。
理想情况下,哈希表桶的数量应等于或大于CPU的数量,以实现最大并行性的潜力。哈希算法可能非常简单,例如取数据结构地址的低位比特,并将其用作索引,指向一个具有2的幂大小的锁数组。这样简单的算法也很快,可以快速定位数据结构。
在内存中有一系列相邻的锁时,当锁落在同一个缓存行中时可能会出现性能问题。两个CPU同时更新同一缓存行中的不同锁将遇到缓存一致性开销,每个CPU会使另一个CPU的缓存中的缓存行失效。这种情况称为伪共享,通常通过在哈希锁中填充未使用的字节来解决,以便在内存中每个缓存行中只存在一个锁。
5.2.6 Non-Blocking I/O
Unix进程生命周期在第3章“操作系统”中有图示,显示了进程在I/O期间阻塞并进入睡眠状态。这个模型存在一些性能问题:
对于许多并发I/O,每个I/O在被阻塞时会消耗一个线程(或进程)。为了支持许多并发I/O,应用程序必须创建许多线程(通常每个客户端一个),这会导致线程创建和销毁的开销。
对于频繁且短暂的I/O,频繁的上下文切换开销会消耗CPU资源并增加应用程序的延迟。
非阻塞I/O模型异步发出I/O请求,而不会阻塞当前线程,当前线程可以执行其他工作。这已经成为Node.js的关键特性,Node.js是一个服务器端JavaScript应用环境,它指导开发人员以非阻塞方式编写代码。
5.2.7 Processor Binding
在NUMA环境中,让进程或线程保持在单个CPU上运行,并在执行I/O之后继续在同一CPU上运行,可能是有利的。这可以改善应用程序的内存局部性,减少内存I/O的周期,并提高整体应用程序性能。操作系统充分意识到了这一点,并设计成保持应用程序线程在相同的CPU上运行(CPU亲和性)。这些主题将在第7章“内存”中介绍。
一些应用程序通过将自身绑定到CPU来强制执行这种行为。对于某些系统,这可以显著提高性能。但当这些绑定与其他CPU绑定发生冲突时,比如设备中断映射到CPU,也可能降低性能。
当同一系统上有其他租户或应用程序运行时,特别要注意CPU绑定的风险。在云计算中的操作系统虚拟化中,我们遇到过这个问题,一个应用程序可以看到所有CPU,然后假定自己是服务器上唯一的应用程序而将自身绑定到某些CPU。当服务器被其他租户应用程序共享并进行绑定时,可能会出现冲突和调度器延迟,因为绑定的CPU正忙于其他租户,尽管其他CPU处于空闲状态。
5.3 Programming Languages
编程语言可能是编译型的或解释型的,也可以通过虚拟机执行。许多语言将“性能优化”列为特性,但严格来说,这些通常是执行该语言的软件的特性,而不是语言本身的特性。例如,Java HotSpot虚拟机软件包括一个即时(JIT)编译器,用于动态提高性能。
解释器和语言虚拟机还通过它们各自特定的工具提供不同级别的性能可观察性支持。对于系统性能分析师来说,使用这些工具进行基本的性能分析可能会带来一些快速的收益。例如,高CPU使用率可能被识别为垃圾回收(GC)的结果,然后可以通过一些常用的可调参数进行修复。或者可能是由于一个代码路径,在bug数据库中被发现为已知的错误,并通过升级软件版本进行修复(这种情况经常发生)。
接下来的章节描述了每种编程语言类型的基本性能特征。要了解有关单个语言性能的更多信息,请查找相关语言的文献。
5.3.1 Compiled Languages
编译将一个程序转换为机器指令,这些指令在运行时预先生成,并存储在称为二进制可执行文件的文件中。这些文件可以随时运行,无需重新编译。编译型语言包括C和C ++。有些语言可能同时具有解释器和编译器。
编译代码通常性能较高,并且在执行之前不需要进一步的翻译。操作系统内核几乎完全用C语言编写,只有少数关键路径用汇编语言编写。
对编译型语言的性能分析通常比较直接,因为执行的机器代码通常与原始程序密切匹配(尽管这取决于编译优化)。在编译过程中,可以生成一个符号表,将地址映射到程序函数和对象名称。随后,CPU执行的性能分析和跟踪可以直接映射到这些程序名称,从而使分析人员能够研究程序执行。堆栈跟踪及其包含的数值地址也可以映射和转换为函数名称,以提供代码路径的继承关系。
编译器可以通过使用编译优化来提高性能——优化选择和放置CPU指令的例程。
编译器优化
gcc(1)编译器提供了0到3的范围,其中3使用最多的优化。可以查询gcc(1)以查看不同级别使用的优化。例如:


完整的选项列表包括约180个选项,其中一些选项即使在-O0级别下也是启用的。
以-fomit-frame-pointer选项为例,该选项在这个列表中可以看到,在gcc(1)手册页中有如下描述:
对于不需要帧指针的函数,不要将帧指针保留在寄存器中。这避免了保存、设置和恢复帧指针的指令;它还在许多函数中提供了额外的寄存器。但这也使得在某些机器上无法进行调试。
这是一个权衡的例子:省略帧指针通常会破坏分析堆栈跟踪的工具的操作。
考虑到堆栈分析器的实用性,这个选项可能会牺牲很多后续很难找到的性能提升,这可能远远超过此选项最初提供的性能增益。在这种情况下,解决方法可以是使用-fno-omit-frame-pointer进行编译,以避免这种优化。
如果出现性能问题,可能会诱惑人们简单地将应用程序重新编译为较低的优化级别(例如从-O3到-O2),希望能够满足任何调试需求。但事实证明这并不简单:对编译器输出的更改可能是巨大且重要的,并且它们可能会影响您最初尝试分析的问题的行为。
5.3.2 Interpreted Languages
解释型语言在运行时通过将程序转化为操作来执行,这个过程会增加执行开销。解释型语言并不具备高性能的特点,通常用于其他因素更为重要的情况,比如编程和调试的便利性。Shell脚本是解释型语言的一个例子。
除非提供了可观察性工具,否则对解释型语言的性能分析可能会很困难。CPU分析可以展示解释器的操作,包括解析、转换和执行操作,但可能不会显示原始的程序函数名称,使得关键的程序上下文成为一个谜。这种解释器分析可能并非完全毫无意义,因为即使正在执行的代码看起来设计良好,解释器本身可能存在性能问题。
根据解释器的不同,程序上下文可能通过间接方式容易获取(例如,对解析器进行动态跟踪)。通常这些程序会通过简单地添加打印语句和时间戳来进行研究。更严格的性能分析并不常见,因为解释型语言通常并不是首选用于高性能应用程序。
5.3.3 Virtual Machines
语言虚拟机(也称为进程虚拟机)是一种模拟计算机的软件。一些编程语言,包括Java和Erlang,通常使用虚拟机(VMs)来执行,这为它们提供了一个与平台无关的编程环境。应用程序被编译为虚拟机指令集(字节码),然后由虚拟机执行。只要在目标平台上有虚拟机可用来运行编译后的对象,就可以实现代码的可移植性。
字节码是从原始程序编译而来,然后由语言虚拟机进行解释,将其转换为机器码。Java HotSpot虚拟机支持即时编译(JIT compilation),它会提前将字节码编译为机器码,以便在执行期间执行本机机器码。这既提供了编译代码的性能优势,又具备虚拟机的可移植性。
观察语言虚拟机通常是最困难的。当程序在CPU上执行时,可能经过了多个编译或解释阶段,原始程序的信息可能不容易获取。性能分析通常侧重于语言虚拟机提供的工具集,其中许多提供了DTrace探针,以及第三方工具。
5.3.4 Garbage Collection
一些语言使用自动内存管理,其中分配的内存不需要显式释放,而是留给一个异步垃圾收集过程来处理。尽管这使得编写程序更容易,但也可能存在一些缺点:
内存增长:对应用程序内存使用的控制较少,当对象未被自动识别为可释放时,内存可能会增长。如果应用程序变得过大,可能会达到其自身的限制或遇到系统分页,严重影响性能。
CPU成本:垃圾收集通常会间歇性地运行,并涉及搜索或扫描内存中的对象。这会消耗CPU资源,减少应用程序在短时间内可用的资源。随着应用程序内存的增长,GC消耗的CPU资源也可能增加。在某些情况和实现中,这可能会达到GC持续占据整个CPU的程度。
延迟异常值:在GC执行时,应用程序执行可能会暂停,导致偶尔出现高延迟的应用程序响应。这取决于GC类型:全停式、增量式或并发式。GC是性能调优的常见目标,可减少CPU成本和延迟异常值的发生。例如,Java虚拟机提供许多可调参数来设置GC类型、GC线程数、最大堆大小、目标堆空闲比例等。
如果调优效果不佳,问题可能是应用程序创建了太多的垃圾,或者存在引用泄漏。这些都是应用程序开发人员需要解决的问题。
5.4 Methodology and Analysis
本节描述了应用程序分析和优化的方法论。用于分析的工具要么在此处介绍,要么在其他章节中进行引用。这些主题在表5.2中进行了总结。

请参阅第2章《方法论》,了解更多一般方法和其中一些内容的介绍。另请参阅后续章节,以了解系统资源和虚拟化的分析。
这些方法论可以单独遵循,也可以组合使用。我建议按照表中列出的顺序依次尝试它们。
除此之外,还要寻找针对特定应用程序和开发语言的定制分析技术。这些技术可能会考虑应用程序的逻辑行为,包括已知问题,并带来一些快速的性能提升。
5.4.1 Thread State Analysis
目标是在高层次确定应用程序线程花费时间的地方,这可以立即解决一些问题并引导对其他问题的调查。这通过将每个应用程序的线程时间分为多个有意义的状态来完成。
两种状态
最少有两种线程状态:
- On-CPU:正在执行
- Off-CPU:等待轮到在 CPU 上运行,或者等待 I/O、锁、页面交换、工作等
如果大部分时间都花在 On-CPU 上,CPU 分析通常可以快速解释这一点(稍后会涉及)。这适用于许多性能问题,因此可能无需花时间测量其他状态。
如果发现时间花费在 Off-CPU 上,可以使用各种其他方法,尽管在没有更好的起点的情况下,这可能会耗费时间。
六种状态
以下是一个扩展列表,这次使用六种线程状态(以及不同的命名方案),这为 Off-CPU 情况提供了更好的起点:
- Executing:在 CPU 上执行
- Runnable:等待轮到在 CPU 上运行
- 匿名分页:可运行,但因等待匿名页输入而被阻塞
- Sleeping:等待 I/O,包括网络、块和数据/文本页输入
- Lock:等待获取同步锁(等待其他人)
- Idle:等待工作
这些状态被选为最少且有用的集合;你可能希望在列表中添加更多状态。例如,执行状态可以分为用户模式和内核模式执行,睡眠状态可以根据目标进行细分。(我不得不克制自己,以将列表保持在六个状态之内。)
通过减少这些状态中前五种的时间来提高性能,这会增加空闲时间(headroom)。其他条件相同的情况下,这意味着应用程序请求具有更低的延迟,并且应用程序可以处理更多负载。
一旦确定了线程花费时间的前五种状态,可以进一步调查它们:
- Executing:检查这是否是用户模式或内核模式时间,以及通过使用分析来确定 CPU 消耗的原因。分析可以确定哪些代码路径正在消耗 CPU 以及消耗了多长时间,其中包括在锁上自旋的时间。参见第5.4.2节,“CPU 分析”。
- Runnable:在这种状态下花费时间意味着应用程序需要更多的 CPU 资源。检查整个系统的 CPU 负载和应用程序的任何 CPU 限制(例如,资源控制)。
- 匿名分页:应用程序的主存储器不足可能导致匿名分页和延迟。检查整个系统的内存使用情况以及应用程序的任何内存限制。详见第7章,“内存”。
- Sleeping:分析应用程序所阻塞的资源。参见第5.4.3节,“系统调用分析”和第5.4.4节,“I/O 分析”。
- Lock:识别锁、持有它的线程以及持有者长时间持有它的原因。原因可能是持有者在另一个锁上被阻塞,这需要进一步解开。这是一个高级活动,通常由对应用程序及其锁定层次结构有深入了解的软件开发人员执行。
由于应用程序通常等待工作的方式,你经常会发现睡眠和锁定状态中的时间实际上是空闲时间。应用程序工作线程可能会在条件变量上等待工作(锁定状态),或者等待网络 I/O(睡眠状态)。因此,当你看到大量睡眠和锁定状态的时间时,请记得稍微深入一点,以检查这是否真的是空闲时间。
以下总结了如何在基于 Linux 和 Solaris 的系统上测量这些线程状态;本书的其他部分更详细地介绍了提到的工具和技术。注意新工具和工具选项的发展,特别是使查找这些内容更容易的新工具和工具选项。
Linux
在Linux系统中,执行的时间很容易确定:top(1)将其报告为%CPU。测量其他状态的时间可能需要一些工作,如下所示。
Kernel schedstats功能跟踪可运行状态,并通过/proc/*/schedstat公开。perf sched工具也可以提供了解可运行状态和等待时间的指标。
等待匿名分页(在Linux中称为交换)的时间可以通过启用内核延迟统计功能进行测量。它提供了分别针对交换和在内存回收期间阻塞的时间的状态。目前没有常用的工具来公开这些状态;然而,内核文档中包含了一个示例程序getdelays.c,可用于完成这个任务,该示例程序在第4章“观察性工具”中进行了演示。另一种方法是使用DTrace或SystemTap等跟踪工具。
通过其他工具可以粗略估计睡眠状态中的阻塞时间,例如pidstat -d用于确定进程是否正在进行磁盘I/O并可能处于睡眠状态。如果启用了延迟和其他I/O统计功能,则可以提供在块I/O上阻塞的时间,可以使用iotop(1)观察到这一点。使用DTrace或SystemTap等跟踪工具可以调查其他阻塞原因。应用程序也可能具有仪器化,或者可以添加仪器化来跟踪执行的显式I/O(磁盘和网络)时间。
如果应用程序在睡眠状态中长时间卡住(几秒钟),可以尝试使用pstack(1)确定原因。它会对线程及其用户堆栈跟踪进行单次快照,其中应包括睡眠线程及其休眠原因。但请注意,pstack(1)在执行此操作时可能会短暂暂停目标进程,因此请谨慎使用。
可以使用跟踪工具调查锁定时间。
Solaris
在基于Solaris的系统中,微状态计算统计数据(在第4章“观察性工具”中介绍)直接提供了大部分线程状态。可以使用prstat(1M)查看这些状态。
这八列,从USR到LAT,都是微状态计算线程状态,并将线程时间划分为百分比。这些列的总和为100%。以下是这些状态与我们感兴趣的状态的映射:
- 执行中:USR + SYS
- 可运行:LAT
- 匿名分页:DFL
- 睡眠:SLP
- 锁定:LCK
- 空闲:也包括在SLP + LCK中
虽然这不是完美匹配,但能够轻松达到这一步具有巨大的价值。可以使用DTrace来分离空闲时间,以检查线程离开CPU时的堆栈跟踪,以确定它正在等待什么。如果一个线程长时间处于睡眠状态(几秒钟),可以尝试使用pstack(1),但请注意,它会短暂暂停目标进程,因此请谨慎使用。
有关prstat(1M)和这些列的更多信息,请参阅第6章“CPU”。
5.4.2 CPU Profiling
在第6章“CPU”中的第6.5.4节“Profiling”中描述了CPU性能分析,该章节还提供了使用DTrace和perf(1)的详细示例。从应用程序角度总结的重要活动是性能分析。其目的是确定应用程序为何消耗CPU资源。一种有效的技术是对在CPU上运行的用户级堆栈跟踪进行采样并合并结果。堆栈跟踪显示了所采取的代码路径,可以揭示应用程序消耗CPU的高级和低级原因。
采样堆栈跟踪可能会生成数千行输出供检查,即使将输出总结为仅打印唯一堆栈时也是如此。快速了解性能分析的一种方法是使用火焰图对其进行可视化,在第6章“CPU”中有展示。
除了对堆栈跟踪进行采样外,还可以仅对当前运行的函数进行采样。在某些情况下,这足以确定应用程序为何使用CPU,并且产生的输出量要少得多,使阅读和理解更加迅速。本示例取自第6章“CPU”,使用了DTrace。


在这种情况下,在采样期间,ut_fold_ulint_pair()函数是CPU上运行时间最长的函数。
研究当前运行函数的调用者也可能很有用,一些性能分析软件(包括DTrace)可以轻松实现这一点。例如,如果先前的示例确定malloc()函数是CPU上运行时间最长的函数,这并不能告诉我们太多信息。malloc()的调用者应该更有趣并值得进行性能分析,而且也不需要捕获堆栈跟踪信息。
解析和虚拟机CPU使用情况的研究可能会很困难;执行软件到原始程序之间可能没有简单的映射关系。如何解决这个问题取决于语言环境:它可能支持启用调试功能来进行解析,或者可能有第三方工具。
以DTrace为例,它使用ustack辅助程序来查看虚拟机内部并将堆栈转换回原始程序。对于Java、Python和Node.js,都有相应的ustack辅助程序。
例如,使用DTrace的jstack()函数对Java进行CPU堆栈采样:

输出已被截断,仅显示了最频繁的堆栈,该堆栈被采样了十次。该堆栈显示了JVM(libjvm)的内部,每个函数都显示为C++签名。Java堆栈已从JVM中转换,这里用粗体标出,显示了负责此CPU代码路径的类和方法。对于此堆栈,它是java/io/DataOutputStream.write。请查看第6章“CPU”中的其他方法论和工具,以了解检查应用程序CPU使用情况的不同方式。
5.4.3 Syscall Analysis
线程状态分析方法首先描述了两种要研究的线程状态:在CPU上和离CPU。根据系统调用的执行情况来研究这些状态可能很有用,有时也更实际:
执行中:在CPU上(用户模式)
系统调用时间:在系统调用期间的时间(内核模式运行或等待)
系统调用时间包括I/O、锁和其他系统调用类型。其他线程状态,如可运行状态(等待CPU)和匿名页,被忽略在这个简化中。如果其中一个是真的(CPU饱和或内存饱和),可以通过USE方法在整个系统范围内进行识别。
执行状态可以通过之前提到的CPU性能分析方法进行研究。
系统调用(syscalls)可以以多种方式进行研究。目的是找出系统调用时间花在了哪里,包括系统调用的类型和调用的原因。
断点追踪
传统的系统调用跟踪方式涉及设置系统调用入口和返回的断点。这种方式具有侵入性,对于系统调用频率高的应用程序,其性能可能会恶化一倍。
根据应用程序的性能要求,这种跟踪方式在短时间内用于确定调用的系统调用类型可能是可接受的。
strace
在Linux上,可以使用strace(1)命令进行这种跟踪。例如:


所使用的选项包括(参见man手册获取完整列表):
- ttt:打印自纪元时代以来的时间的第一列,以秒为单位,具有微秒分辨率。
- T:打印最后一个字段(<time>),即系统调用的持续时间,以秒为单位,具有微秒分辨率。
- -p PID:跟踪此进程ID。还可以指定一个命令,以便strace(1)启动并跟踪它。
strace(1)的一个特性可以在输出中看到——将系统调用参数转换为人类可读的形式。这对于确定ioctl()的使用尤为有用。
这种strace(1)形式每个系统调用打印一行输出。可以使用-c选项总结系统调用活动:

输出包括:
- 时间:显示系统CPU时间花在哪里的百分比
- 秒:总系统CPU时间,以秒为单位
- 每次调用的微秒数:每次调用的平均系统CPU时间,以微秒为单位
- 调用次数:strace(1)期间的系统调用次数
- 系统调用:系统调用名称
如果开销不是如此大的问题,这将更有用。
为了说明这一点,使用dd(1)命令执行500万次1KB传输,并进行了有和无strace(1)的测试。没有:

dd(1)的输出包括运行时间和吞吐量统计信息。这个测试大约花了2秒才完成。
下面是相同的命令,同时strace(1)总结了系统调用的使用情况:

运行时间增加了73倍,吞吐量相应下降。
这是一个特别严重的情况,因为dd(1)执行了大量的系统调用。
truss
在基于Solaris的系统上,truss(1)命令扮演着这个角色。例如:

所使用的选项包括(查看man手册获取全部内容):
- d:打印时间戳的第一列,显示自纪元以来的秒数。
- E:打印时间戳的第二列,显示系统调用期间经过的时间,以秒为单位。
- -p PID:跟踪该进程ID。也可以指定一个命令,以便truss(1)启动并跟踪它。
输出每个系统调用打印一行,并将参数有用地转换为人类可读格式。时间戳仅具有0.1毫秒的分辨率,这使得它们的用途受到限制。
truss(1)还支持使用-c进行摘要模式:


秒列显示系统调用中的系统CPU时间。调用列显示计数。
truss(1)还可以使用-u选项执行一种形式的用户级函数调用的动态跟踪。例如,跟踪printf()调用:

与strace(1)类似,对于高频率的系统调用或跟踪函数调用,开销可能会很大,这使得大多数生产使用场景下禁止使用。
缓冲跟踪
通过缓冲跟踪,仪器化数据可以在内核中被缓冲,而目标程序继续执行。这与断点跟踪不同,后者会为每个跟踪点中断目标程序。
DTrace提供了缓冲跟踪和聚合功能,以减少跟踪开销,并允许编写用于系统调用分析的自定义程序。本节中展示了一些示例。在Linux 3.7中,perf(1)添加了一个trace子命令,用于执行系统调用(等等)的缓冲跟踪。
以下DTrace一行示例演示了一些基本的系统调用分析,并适用于基于Linux和Solaris的系统(在后者上演示)。在附录D中还有更多示例一行命令。
此一行命令跟踪进程信号(通过kill()系统调用),显示源PID和进程名称,以及目标PID和信号编号:

在跟踪过程中,这个命令捕获到一个bash进程向PID 2638发送了-9(SIGKILL)信号,以及一些来自postgres(PostgreSQL数据库)的信号。时间戳的包含可能有助于与其他活动进行关联。
这个一行命令统计了名称为"postgres"(PostgreSQL数据库)的进程的系统调用(使用聚合功能):

在跟踪过程中,llseek()系统调用被执行了最多——27,925次。
接下来的一行命令测量了PostgreSQL执行read()系统调用的持续时间(也称为延迟):


在跟踪过程中,大多数read()系统调用的持续时间在1到8微秒(1,024-8,191纳秒)之间。
read()系统调用作用于文件描述符,该文件描述符可以是文件系统对象或网络套接字。在各自的章节中演示了如何通过使用fds[] DTrace数组将文件描述符映射到它们的文件系统类型来识别每个文件描述符。
对于这个一行命令,如果内置的时间戳被改为vtimestamp,它将仅测量系统调用期间的CPU时间。这可以用来与持续时间进行比较,以查看系统调用是在内核代码中花费更多时间还是被I/O阻塞。
可以编写更复杂的DTrace脚本以不同方式表示系统调用的时间。例如(来自DTraceToolkit [3]):
- dtruss:DTrace版本的truss(1),全系统操作
- execsnoop:通过exec()系统调用跟踪新进程执行
- opensnoop:跟踪带有各种细节的open()系统调用
- procsystime:以各种方式总结系统调用时间
这些脚本已经解决了许多性能问题,通常是通过识别可以调整或消除的高级别进程活动来实现的。这是一种工作负载特性:工作负载是应用程序系统调用。
例如,以下显示了在基于云的系统上使用-v参数运行execsnoop以获取字符串时间戳:

时间戳显示这些进程都是在2秒的时间段内执行的。
大量短生命周期的进程可能会消耗CPU资源,并由于CPU交叉调用(在进程退出时拆除MMU上下文)而干扰其他应用程序。
5.4.4 I/O Profiling
与CPU性能分析的作用类似,I/O性能分析确定了I/O相关系统调用的执行原因和方式。这可以通过使用DTrace来实现,检查系统调用的用户级堆栈跟踪。
例如,这个一行命令跟踪PostgreSQL的read()系统调用,收集用户级堆栈跟踪,并对其进行聚合:

输出(截断)显示了用户级堆栈,然后是出现次数的计数。这些堆栈包括应用程序内部函数名称。您可能需要研究源代码才能理解这些内容,但您可能能够从名称中获取足够有用的含义。第一个堆栈包含XLogRead:它可能与某种类型的数据库日志相关。第二个堆栈包含PgstatCollectorMain.isra,听起来像是监控活动。
堆栈跟踪显示了系统调用的执行原因。同时,从工作负载特性方法论中研究其他属性也可能非常有用(参见第2章,方法论部分):
- 谁:进程ID,用户名
- 什么:I/O系统调用目标(例如,文件系统或套接字),I/O大小,IOPS,吞吐量(每秒字节数),其他属性
- 如何:随时间变化的IOPS
除了应用的工作负载外,还可以按照先前方法论所述研究产生的性能——系统调用延迟。
5.4.5 Workload Characterization
该应用程序对系统资源(CPU、内存、文件系统、磁盘和网络)以及通过系统调用对操作系统施加了工作负载。所有这些都可以使用在第2章方法论中介绍并在后续章节中讨论的工作负载特性方法论来进行研究。
此外,还可以研究发送到应用程序的工作负载。这主要关注应用程序提供的操作及其属性,可能是性能监控中包括的关键指标,并用于容量规划。
5.4.6 USE Method
正如在第2章方法论中介绍并在后续章节中应用的那样,USE方法检查所有硬件资源的利用率、饱和度和错误。通过显示某一资源已成为瓶颈,许多应用程序性能问题可以通过这种方式解决。
根据应用程序的不同,USE方法也可以应用于软件资源。如果您可以找到显示应用程序内部组件的功能图表,请考虑每个软件资源的利用率、饱和度和错误指标,并查看哪些是合理的。
例如,应用程序可能使用一组工作线程来处理请求,其中包括一个用于等待轮到的请求的队列。将其视为一个资源,那么这三个指标可以这样定义:
- 利用率:在一个时间间隔内忙于处理请求的平均线程数,占总线程数的百分比。例如,50%意味着平均有一半的线程正在忙于处理请求。
- 饱和度:在一个时间间隔内请求队列的平均长度。这显示了有多少请求在等待工作线程。
- 错误:由于任何原因而被拒绝或失败的请求。
接下来您需要找出如何测量这些指标。它们可能已经在应用程序的某个地方提供,或者可能需要添加或使用其他工具(如动态跟踪)进行测量。
像这个例子一样的排队系统也可以使用排队理论进行研究(参见第2章方法论)。
以另一个例子为例,考虑文件描述符。系统可能会设置限制,使其成为有限资源。这三个指标可能如下:
- 利用率:正在使用的文件描述符数量,占限制的百分比。
- 饱和度:取决于操作系统的行为:如果线程因等待文件描述符分配而阻塞,这可能是等待该资源的阻塞线程数量。
- 错误:分配错误,例如EFILE,“打开文件过多”。
对您的应用程序组件进行类似的重复练习,并跳过任何不合理的指标。
这个过程可能有助于您在转向其他方法(如深入分析)之前,制定一个用于检查应用程序健康状况的简短清单。
5.4.7 Drill-Down Analysis
对于应用程序,深入分析可以从检查应用程序提供的操作开始,然后深入到应用程序内部,看看它是如何执行这些操作的。对于I/O操作,这种深入分析可以进入系统库、系统调用和内核。
这是一项高级活动,将迅速导致应用程序内部的探索,最好是开源的,以便进行研究。动态跟踪工具(例如DTrace、SystemTap、perf(1))可以对这些内部进行工具化,某些语言比其他语言更容易实现。检查语言是否有适用于分析的自己的工具集,这可能更合适。
还有一些专门用于调查库调用的工具:在Linux上是ltrace(1),在基于Solaris的系统上是apptrace(1)(尽管其使用已让位于DTrace)。
5.4.8 Lock Analysis
对于多线程应用程序,锁可能成为一个瓶颈,抑制并行性和可扩展性。可以通过以下方式进行分析:
- 检查争用情况
- 检查持有时间是否过长
第一种方法可以确定当前是否存在问题。持有时间过长未必是问题,但随着更多的并行负载,它们可能成为问题。对于每个问题,尝试确定锁的名称(如果存在)和导致使用它的代码路径。
虽然有专门用于锁分析的工具,但有时您可以仅通过CPU性能分析解决问题。对于自旋锁,争用会显示为CPU使用率,并且可以通过对堆栈跟踪进行CPU性能分析来轻松识别。对于自适应互斥锁,争用通常涉及一些自旋,这也可以通过对堆栈跟踪进行CPU性能分析来识别。在这种情况下,请注意CPU性能分析只能提供故事的一部分,因为线程可能已经阻塞和休眠,同时等待锁。参见5.4.2节CPU性能分析。
在基于Solaris系统的专用锁分析工具示例包括:
- plockstat(1M):用户级锁分析
- lockstat(1M):内核级锁分析
这些命令具有类似的行为。它们也是使用DTrace实现的,可以直接用于更深入的锁分析。
以下是lockstat(1M)的示例用法:


在这里,lockstat(1M)跟踪争用事件(-C),使用五级堆栈跟踪(-s5),并通过执行协处理器(sleep(1))设置了5秒的超时。输出被重定向到文件以便更轻松地浏览(输出超过10万行)。
输出以自适应自旋时间和分布图开始,显示每个争用事件的时间,以及锁的名称和堆栈跟踪。最高的是zfs_range_unlock,它出现了14,144次争用,平均自旋时间为1,787纳秒。分布图显示有两次自旋时间超过1,048,576纳秒(在1到2毫秒范围内)。这些被阻塞的数量可以在输出的自适应互斥锁阻塞部分中看到。
对内核或用户级别锁进行跟踪会增加开销。这些特定工具基于DTrace,尽量将这种开销最小化。另外,正如前面所述,以固定速率(例如97赫兹)进行CPU性能分析将识别许多(但不是所有)锁问题,而不会带来每个事件的跟踪开销。
5.4.9 Static Performance Tuning
静态性能调优关注配置环境的问题。对于应用程序性能,需要检查静态配置的以下方面:
- 应用程序运行的版本是什么?是否有更新版本?它们的发布说明中是否提到了性能改进?
- 应用程序存在哪些已知的性能问题?是否有可搜索的错误数据库?
- 应用程序的配置是如何的?
- 如果与默认设置不同,那么进行不同配置或调优的原因是什么?(是基于测量和分析,还是凭猜测?)
- 应用程序是否使用对象缓存?它的大小是多少?
- 应用程序是否并发运行?它是如何配置的(例如,线程池大小)?
- 应用程序是否以特殊模式运行?(例如,可能已启用调试模式并降低性能)
- 应用程序使用了哪些系统库?它们的版本是多少?
- 应用程序使用了哪种内存分配器?
- 应用程序是否配置为在其堆中使用大页?
- 应用程序是经过编译的吗?使用的是哪个版本的编译器?有哪些编译器选项和优化?是64位的吗?
应用程序是否遇到错误,并且现在是否以降级模式运行?
- 系统是否有对CPU、内存、文件系统、磁盘或网络使用的限制或资源控制?(这在云计算中很常见。)
回答这些问题可能会揭示被忽视的配置选择。
6 CPUs
CPU驱动所有软件,通常是系统性能分析的首要目标。现代系统通常有许多CPU,由内核调度程序在所有运行的软件之间共享。当对CPU资源的需求超过可用资源时,进程线程(或任务)将排队等待执行。等待会在应用程序运行期间增加显着的延迟,降低性能。
可以详细检查CPU的使用情况,以寻找性能改进,包括消除不必要的工作。在高级别上,可以检查进程、线程或任务的CPU使用情况。在较低级别上,可以对应用程序和内核中的代码路径进行性能分析和研究。在最低级别上,可以研究CPU指令执行和周期行为。
本章包括五个部分:
- 背景介绍了与CPU相关的术语、CPU的基本模型和关键的CPU性能概念。
- 架构介绍了处理器和内核调度程序的架构。
- 方法论描述了性能分析方法,包括观察性的和实验性的。
- 分析描述了基于Linux和Solaris系统的CPU性能分析工具,包括分析、跟踪和可视化。
- 调优包括可调参数的示例。
前三节为CPU分析提供了基础,后两节展示了其在基于Linux和Solaris系统的实际应用。还涵盖了内存I/O对CPU性能的影响,包括受阻于内存的CPU周期以及CPU缓存的性能。第7章“内存”继续讨论内存I/O,包括MMU、NUMA/UMA、系统互连和内存总线。
6.1 Terminology
在本章中使用的与CPU相关的术语包括以下内容:
- 处理器:插入系统或处理器板上的插座的物理芯片,包含一个或多个作为核心或硬件线程实现的CPU。
- 核心:多核处理器上独立的CPU实例。使用核心是扩展处理器性能的一种方式,称为芯片级多处理(CMP)。
- 硬件线程:支持在单个核心上并行执行多个线程的CPU体系结构(包括英特尔的超线程技术),其中每个线程是独立的CPU实例。这种扩展方法的一种名称是多线程。
- CPU指令:来自其指令集的单个CPU操作。有关算术运算、内存I/O和控制逻辑的指令。
- 逻辑CPU:也称为虚拟处理器,是操作系统的CPU实例(可调度的CPU实体)。这可能由处理器作为硬件线程实现(在这种情况下也可以称为虚拟核心)、核心或单核处理器。
- 调度程序:分配线程在CPU上运行的内核子系统。
- 运行队列:等待被CPU服务的可运行线程的队列。对于Solaris系统,它通常被称为分派队列。
本章还介绍了其他术语。术语表中包括基本术语,如CPU、CPU周期和堆栈。同时,请参阅第2章和第3章的术语部分。
6.2 Models
以下简单模型说明了CPU和CPU性能的一些基本原则。第6.4节“架构”深入探讨,并包括特定实现的详细信息。}
6.2.1 CPU Architecture
图6.1显示了一个示例CPU架构,对于一个具有四个核心和总共八个硬件线程的单处理器。展示了物理架构以及操作系统看到的架构。
每个硬件线程可以被视为一个逻辑CPU,因此这个处理器看起来就像有八个CPU。操作系统可能对拓扑结构有一些额外的了解,比如哪些CPU在同一个核心上,以改善其调度决策。
6.2.2 CPU Memory Caches
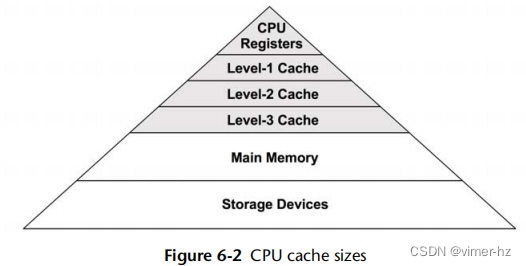
处理器提供各种硬件缓存来改善内存I/O性能。图6.2显示了缓存大小的关系,这些缓存离CPU越近,就会变得更小更快(一个权衡)。存在的缓存以及它们是否在处理器(集成的)上或者处理器外部,取决于处理器类型。较早的处理器提供了较少级别的集成缓存。
6.2.3 CPU Run Queues
图6.3展示了一个CPU运行队列,由内核调度程序管理。
图中显示的线程状态,即准备运行和在CPU上运行,在第3章操作系统的图3.7中有介绍。
排队并准备运行的软件线程数量是一个重要的性能指标,表明CPU饱和度。在这个图中(此刻),有四个线程排队准备运行,并且额外有一个线程正在CPU上运行。在CPU运行队列等待的时间有时称为运行队列延迟或调度器队列延迟。本书中使用调度器延迟一词代替,因为它适用于所有调度器类型,包括那些不使用队列的调度器(请参见第6.4.2节“软件”中对CFS的讨论)。
对于多处理器系统,内核通常为每个CPU提供一个运行队列,并力求保持线程在同一个运行队列上。这意味着线程更有可能在同一个CPU上继续运行,其中CPU缓存已缓存其数据。(这些缓存被描述为具有缓存热度,偏好CPU的方法称为CPU亲和性。)在NUMA系统上,内存局部性也可能得到改善,从而提高性能(这在第7章“内存”中有描述)。
这也避免了线程同步(互斥锁)对队列操作的成本,如果运行队列是全局的并在所有CPU之间共享,会影响可伸缩性。
6.3 Concepts
以下是关于CPU性能的一些重要概念,从处理器内部结构的概述开始,包括CPU时钟频率和指令执行方式。这为后续的性能分析提供了背景知识,特别是对于理解每指令周期数(CPI)指标非常重要。
6.3.1 Clock Rate
时钟是驱动所有处理器逻辑的数字信号。每条CPU指令可能需要一个或多个时钟周期(称为CPU周期)来执行。CPU以特定的时钟频率运行;例如,一个5 GHz的CPU每秒执行50亿个时钟周期。
一些处理器能够改变它们的时钟频率,将其增加以提高性能或降低以节约功耗。时钟频率可以根据操作系统的要求进行变化,也可以由处理器自身动态调整。例如,内核空闲线程可以请求CPU降低频率以节省电力。
时钟频率通常被宣传为处理器的主要特性,但这可能有点误导。即使您系统中的CPU看起来完全被利用(成为瓶颈),更快的时钟频率可能并不会提高性能——这取决于这些快速CPU周期实际在做什么。如果它们大部分时间都是在等待内存访问时的停滞周期,那么加快执行并不会增加CPU指令速率或工作负载吞吐量。
6.3.2 Instruction
CPU执行从其指令集中选择的指令。一条指令包括以下步骤,每个步骤由CPU的一个称为功能单元的组件处理:
1. 指令获取
2. 指令解码
3. 执行
4. 内存访问
5. 寄存器写回
最后两个步骤取决于指令是否需要。许多指令仅操作寄存器,不需要内存访问步骤。
这些步骤中的每一个至少需要一个时钟周期来执行。内存访问通常是最慢的,因为读取或写入主存储器可能需要几十个时钟周期,在此期间指令执行会停滞(这些停滞期间被称为停滞周期)。这就是为什么CPU缓存很重要的原因,如第6.4节所述:它可以显著减少内存访问所需的时钟周期数。
6.3.3 Instruction Pipeline
指令流水线是一种CPU架构,能够并行执行多条指令,通过同时执行不同指令的不同组件。它类似于工厂的装配线,可以并行执行生产的各个阶段,从而增加吞吐量。
考虑之前列出的指令步骤。如果每个步骤都需要一个时钟周期,那么完成该指令需要五个周期。在指令的每个步骤中,只有一个功能单元处于活动状态,其他四个处于空闲状态。通过使用流水线技术,多个功能单元可以同时处于活动状态,在流水线中处理不同的指令。理想情况下,处理器可以在每个时钟周期内完成一条指令的执行。
6.3.4 Instruction Width
但我们还可以更快。可以包含多个相同类型的功能单元,因此即使更多的指令也可以在每个时钟周期内取得进展。这种CPU架构被称为超标量,并通常与流水线一起使用,以实现高指令吞吐量。
指令宽度描述了并行处理的目标指令数量。现代处理器通常是3-wide或4-wide,意味着它们可以在一个周期内完成多达三个或四个指令。这是如何工作取决于处理器,因为每个阶段可能具有不同数量的功能单元。
6.3.5 CPI, IPC
每条指令的周期数(CPI)是描述CPU在哪些时钟周期中消耗的重要高级指标,以及理解CPU利用率的性质。这个指标也可以表示为每个周期的指令数(IPC),它是CPI的倒数。
高CPI表示CPU经常处于停滞状态,通常是由于内存访问。低CPI表示CPU经常不会停滞,并且具有高的指令吞吐量。这些指标提示了性能调优工作可能最好的方向。
例如,内存密集型工作负载可以通过安装更快的内存(DRAM)、改进内存局部性(软件配置)或减少内存输入/输出来改善性能。安装时钟频率更高的CPU可能不会如预期的那样提高性能,因为CPU可能需要等待相同的时间才能完成内存I/O。换句话说,更快的CPU可能意味着更多的停滞周期,但完成的指令率相同。
高或低CPI的实际值取决于处理器和处理器特性,并且可以通过运行已知的工作负载进行实验确定。例如,您可能会发现,高CPI的工作负载的CPI为10或更高,而低CPI的工作负载的CPI小于1(这是由于前面描述的指令流水线和宽度)。
需要注意的是,CPI显示了指令处理的效率,但并不代表指令本身的效率。考虑一个添加了低效软件循环的软件更改,该循环主要在CPU寄存器上操作(没有停滞周期):这样的更改可能会导致较低的总体CPI,但CPU使用率和利用率更高。
6.3.6 Utilization
CPU利用率是指CPU实例在一个时间间隔内忙于执行工作的时间,以百分比表示。它可以被衡量为CPU不在运行内核空闲线程,而是在运行用户级应用线程或其他内核线程,或处理中断的时间。
高CPU利用率不一定是问题,而是系统正在执行工作的一个迹象。有些人也认为这是一个投资回报率指标:高度利用的系统被认为具有良好的回报率,而空闲的系统被认为是浪费的。与其他资源类型(如磁盘)不同,在高利用率下性能不会急剧下降,因为内核支持优先级、抢占和时间共享。这些机制使内核能够理解哪个任务具有更高的优先级,并确保它首先运行。
CPU利用率的测量涵盖了所有可用活动的时钟周期,包括内存停滞周期。这可能看起来有点反直觉,但CPU可能高度利用是因为它经常因等待内存I/O而停滞,而不仅仅是执行指令,就像前面部分所描述的那样。
CPU利用率通常分为内核时间和用户时间两个独立的指标。
6.3.7 User-Time/Kernel-Time
执行用户级应用程序代码所花费的CPU时间称为用户时间,而内核级代码则是内核时间。内核时间包括系统调用、内核线程和中断期间的时间。当在整个系统范围内进行测量时,用户时间与内核时间之比表明了所执行的工作负载类型。
计算密集型应用程序可能几乎全部时间都用于执行用户级代码,并且用户/内核比接近于 99/1。例如图像处理、基因组学和数据分析等应用。
I/O 密集型应用程序具有较高的系统调用率,这些调用执行内核代码以执行 I/O 操作。例如,执行网络 I/O 的 Web 服务器可能具有约为 70/30 的用户/内核比。
这些数字受到许多因素的影响,用来表达预期的比率类型。
6.3.8 Saturation
CPU完全利用率达到100%时会饱和,线程将因等待在 CPU 运行队列或其他用于管理线程的结构上而遇到调度延迟,降低整体性能。这种延迟是等待 CPU 运行队列或其他管理线程的结构的时间。
另一种形式的 CPU 饱和涉及 CPU 资源控制,例如在多租户云计算环境中可能会施加。尽管 CPU 可能未达到100%利用率,但已达到所施加的限制,并且可运行的线程必须等待它们的轮次。这对系统用户的可见性取决于使用的虚拟化类型;请参阅第11章云计算。
CPU运行于饱和状态不像其他资源类型那么成问题,因为具有更高优先级的工作可以抢占当前线程。
6.3.9 Preemption
在第三章“操作系统”中介绍的抢占机制允许具有更高优先级的线程剥夺当前正在运行的线程,并开始自己的执行。这消除了对于高优先级工作的运行队列延迟,提高了其性能。
6.3.10 Priority Inversion
优先级倒置发生在一个低优先级线程持有资源并阻塞一个高优先级线程运行时。这降低了高优先级工作的性能,因为它被阻塞等待。
Solaris内核实现了完整的优先级继承方案,以避免优先级倒置。以下是一个示例,说明这种机制如何工作(基于真实案例):
1. 线程A执行监控任务,优先级较低。它获取一个用于生产数据库的地址空间锁,以检查内存使用情况。
2. 线程B是一个常规任务,执行系统日志的压缩操作,开始运行。
3. 没有足够的CPU来同时运行两者。线程B抢占A并运行。
4. 线程C来自生产数据库,具有高优先级,并且一直处于等待I/O 的睡眠状态。现在该I/O 完成,将线程C放回可运行状态。
5. 线程C抢占B并运行,但随后由于被线程A持有的地址空间锁而阻塞。线程C离开CPU。
6. 调度程序选择下一个最高优先级的线程运行:B。
7. 当线程B运行时,一个高优先级线程C 实际上被阻塞在一个低优先级线程B 上。这就是优先级倒置。
8. 优先级继承使线程A获得了线程C的高优先级,抢占B,直到释放锁。现在线程C可以运行了。
自Linux 2.6.18 以来,提供了支持优先级继承的用户级互斥锁,用于实时工作负载。
6.3.11 Multiprocess, Multithreading
大多数处理器都提供某种形式的多个CPU。为了让应用程序能够利用这些CPU,它需要独立的执行线程,以便可以并行运行。例如,对于一个64-CPU系统,这意味着如果应用程序可以并行利用所有CPU,它可能可以以多达64倍的速度运行,或者处理64倍的负载。应用程序能够有效地随着CPU数量增加而扩展的程度是可伸缩性的衡量标准。

跨CPU扩展应用程序的两种技术是多进程和多线程,如图6.4所示。
在Linux上,多进程和多线程模型都可以使用,并且都由任务来实现。

多进程和多线程之间的差异如表6.1所示。
尽管对开发人员来说更复杂,但综合表中显示的所有优势,多线程通常被认为是更优越的。
不管使用哪种技术,重要的是创建足够的进程或线程来跨越所需数量的CPU,对于最大性能来说,可能是所有可用的CPU。一些应用程序在运行在较少的CPU上时可能表现更好,当线程同步的成本和降低内存局部性超过了跨多个CPU运行的好处时。并行架构也在第5章“应用”中进行了讨论。
6.3.12 Word Size
处理器的设计基于最大字长——32位或64位,这也是整数大小和寄存器大小。根据处理器的不同,字长通常也用于地址空间大小和数据路径宽度(有时称为位宽)。
较大的字长可能意味着更好的性能,尽管实际情况并非听起来那么简单。较大的字长可能会导致某些数据类型中未使用位的内存开销。当指针的大小(字长)增加时,数据占用的空间也会增加,这可能需要更多的内存I/O。对于x86 64位架构,通过增加寄存器和更高效的寄存器调用约定来补偿这些开销,因此64位应用程序可能比其32位版本更快。
处理器和操作系统可以支持多个字长,并且可以同时运行为不同字长编译的应用程序。如果软件已编译为较小的字长,它可能可以成功执行,但性能相对较差。
6.3.13 Compiler Optimization
通过编译器选项(包括设置字长)和优化,可以显著提高应用程序的CPU运行时间。编译器也经常更新,以利用最新的CPU指令集并实施其他优化。有时候,仅仅使用更新的编译器就能显著提高应用程序的性能。
更详细地介绍了这个主题,请参考第5章《应用程序》。
6.4 Architecture
这一部分介绍了CPU架构和实现,涵盖了硬件和软件两个方面。在第6.2节《模型》中介绍了简单的CPU模型,在之前的一节中介绍了通用概念。
这些主题作为性能分析的背景进行了总结。更多详情,请参阅厂商的处理器手册以及有关操作系统内部的文献。本章末尾列出了一些相关文献。
6.4.1 Hardware
CPU硬件包括处理器及其子系统,以及多处理器系统的CPU互连。
Processor
通用双核处理器的各组成部分如图6.5所示。
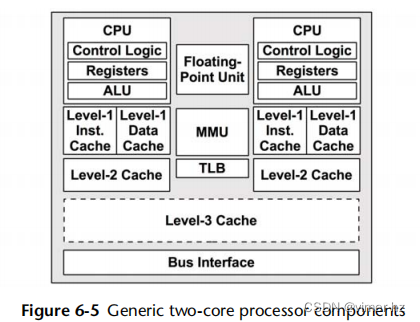
控制单元(图中显示为控制逻辑)是CPU的核心,负责指令获取、解码、管理执行和存储结果。
这个示例处理器展示了一个共享的浮点运算单元和(可选的)共享第3级缓存。您的处理器实际组件将根据其类型和型号而异。其他可能存在的与性能相关的组件包括以下内容:
- P缓存:预取缓存(每个CPU)
- W缓存:写入缓存(每个CPU)
- 时钟:用于CPU时钟的信号发生器(或者由外部提供)
- 时间戳计数器:用于高分辨率时间,由时钟递增
- 微码ROM:快速将指令转换为电路信号
- 温度传感器:用于热量监控
- 网络接口:如果芯片上有(用于高性能)
一些处理器类型使用温度传感器作为单个核心动态超频的输入(包括英特尔Turbo Boost技术),在核心保持在其温度范围内的情况下提高性能。
CPU Caches
处理器通常包含各种硬件缓存(称为芯片上、芯片内、嵌入式或集成)或与处理器一起使用的外部缓存。这些缓存通过使用更快的内存类型来缓存读取和缓冲写入,从而提高内存性能。通用处理器的缓存访问级别如图6.6所示。
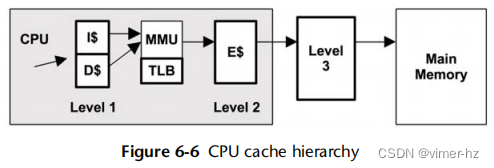
它们包括:
- 一级指令缓存(I$)
- 一级数据缓存(D$)
- 转换后备缓冲器(TLB)
- 二级缓存(E$)
- 三级缓存(可选)
E$中的E最初代表外部缓存,但随着二级缓存的整合,它被巧妙地称为嵌入式缓存。现今使用“级别”术语代替“E$”风格的标记,以避免混淆。
每个处理器可用的缓存取决于其类型和型号。随着时间的推移,这些缓存的数量和大小一直在增加。《Table 6.2》列出了自1978年以来的英特尔处理器,包括缓存方面的进展[Intel 12]。
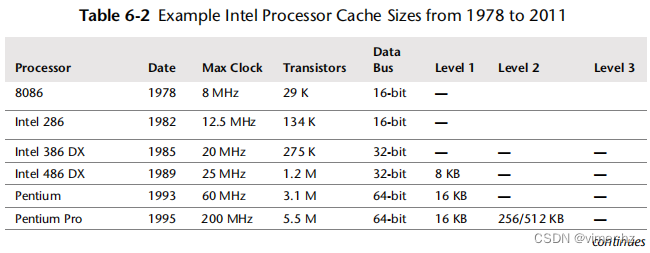

对于多核和多线程处理器,其中一些缓存可能在核心和线程之间共享。
除了CPU缓存数量和大小的增加外,还存在将这些缓存提供在芯片上的趋势,这样可以将访问延迟降至最低,而不是提供外部的缓存给处理器使用。
Latency
为了提供最佳的大小和延迟配置,使用多级缓存。一级缓存的访问时间通常是几个CPU时钟周期,而较大的二级缓存大约需要十几个时钟周期。主存储器可能需要大约60纳秒(对于4 GHz处理器,大约240个周期),而由内存管理单元进行地址转换也会增加延迟。
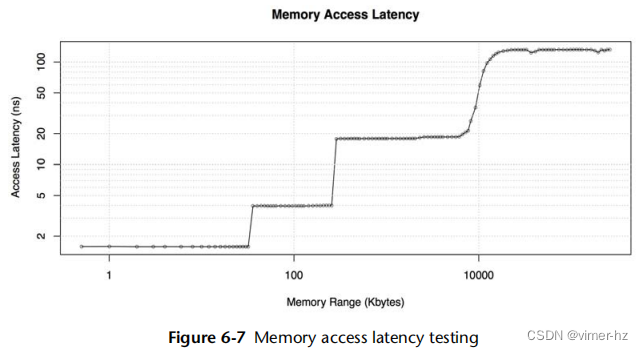
可以通过微基准测试[Ruggiero 08]来实验性地确定处理器的CPU缓存延迟特性。图6.7显示了对Intel Xeon E5620 2.4 GHz进行了LMbench[2]内存访问延迟测试的结果。
图中的两个轴都是对数刻度。图表中的阶跃点显示了何时超出了某个缓存级别,并且访问延迟成为下一个(更慢)缓存级别的结果。
Associativity
关联性是描述缓存中定位新条目的约束的一种特征。类型包括:
- 全关联式:缓存可以在任何位置定位新条目。例如,LRU算法可以淘汰整个缓存中最近未使用的条目。
- 直接映射式:每个条目在缓存中只有一个有效位置,例如,内存地址的哈希值,使用地址位的子集来形成缓存中的地址。
- 集合关联式:通过映射(例如,哈希)标识缓存的一个子集,在该子集内可以执行另一个算法(例如,LRU)。它以子集大小来描述;例如,四路组关联将地址映射到四个可能的位置,然后从这四个位置中选择最佳位置。
CPU缓存通常使用集合关联性作为全关联式(执行代价高昂)和直接映射式(命中率较低)之间的平衡。
Cache Line
CPU缓存的另一个特征是它们的缓存行大小。这是一组以字节为单位存储和传输的范围,可以提高内存吞吐量。x86处理器的典型缓存行大小为64字节。编译器在优化性能时会考虑到这一点。程序员有时也会考虑到这一点;请参阅第5章5.2.5节中的应用程序中的哈希表。
Cache Coherency
内存可能会同时被缓存在不同处理器上的多个CPU缓存中。当一个CPU修改内存时,所有缓存都需要知道它们缓存的副本现在已经过期,应该被丢弃,这样任何未来的读取操作都将检索到新修改的副本。这个过程称为缓存一致性,确保CPU始终访问内存的正确状态。这也是设计可扩展多处理器系统时面临的最大挑战之一,因为内存可能会迅速被修改。
MMU
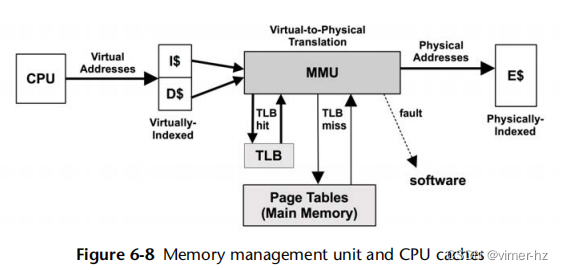
MMU负责虚拟地址到物理地址的转换。图6.8展示了一个通用的MMU以及CPU缓存类型。该MMU使用片上TLB缓存地址转换。缓存未命中时,由主内存(DRAM)中的翻译表(称为页表)满足,这些表由MMU(硬件)直接读取。
这些因素是处理器相关的。一些(较旧的)处理器通过软件处理TLB未命中,遍历页表然后将所请求的映射填充到TLB中。这样的软件可能会维护自己的更大的内存翻译缓存,称为翻译存储缓冲区(TSB)。新型处理器可以通过硬件服务TLB未命中,大大降低成本。
Interconnects
对于多处理器架构,处理器使用共享系统总线或专用互连进行连接。这与系统的内存架构有关,即统一内存访问(UMA)或非统一内存访问(NUMA),如第7章“内存”中所讨论的。
早期英特尔处理器使用的共享系统总线(称为前端总线)的四处理器示例可见于图6.9。
当增加处理器数量时,使用系统总线会出现可扩展性问题,因为会争夺共享总线资源。现代服务器通常是多处理器、NUMA架构,并使用CPU互连代替系统总线。
互连可以连接处理器以外的组件,例如I/O控制器。示例互连包括英特尔的Quick Path Interconnect(QPI)和AMD的HyperTransport(HT)。图6.10展示了一个四处理器系统的示例英特尔QPI架构。
处理器之间的私有连接允许非竞争访问,同时也比共享系统总线具有更高的带宽。表6.3(Intel 09)中显示了英特尔前端总线(FSB)和QPI的一些示例速度。
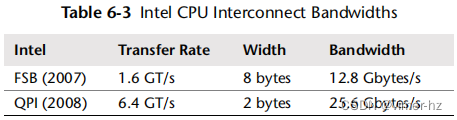
QPI是双泵技术,即在时钟的两个边沿上进行数据传输,从而使数据传输速率加倍。这解释了表中显示的带宽(6.4 GT/s x 2字节 x 双倍 = 25.6 G字节/秒)。
除了外部互连之外,处理器还具有用于核心通信的内部互连。
互连通常设计为高带宽,以确保其不会成为系统瓶颈。如果互连成为瓶颈,CPU指令在涉及互连的操作(如远程内存I/O)时将遇到停滞周期,导致性能下降。一个关键的指标是CPI的上升。可以使用CPU性能计数器来分析CPU指令、周期、CPI、停滞周期和内存I/O。
CPU Performance Counters
CPU性能计数器(CPCs)有许多名称,包括性能仪器计数器(PICs)、性能监视单元(PMU)、硬件事件和性能监视事件。它们是可以编程计算低级CPU活动的处理器寄存器。通常包括以下计数器:
- CPU周期:包括停滞周期和停滞周期类型
- CPU指令:已退役(执行)
- 一级、二级、三级缓存访问:命中、未命中
- 浮点单元:操作
- 内存I/O:读取、写入、停滞周期
- 资源I/O:读取、写入、停滞周期
每个CPU都有少量寄存器,通常在两到八个之间,可以编程记录此类事件。可用的寄存器取决于处理器类型和型号,并在处理器手册中有详细说明。
举个相对简单的例子,英特尔P6系列处理器通过四个特定于型号的寄存器(MSR)提供性能计数器。其中两个是计数器,只读。另外两个用于编程这些计数器,称为事件选择MSR,可读写。性能计数器是40位寄存器,事件选择MSR是32位。事件选择MSR的格式如图6.11所示。
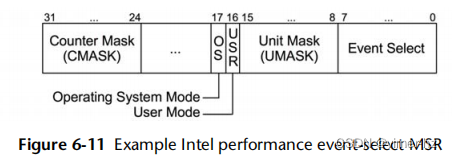
计数器由事件选择和UMASK标识。事件选择用于标识要计数的事件类型,UMASK用于标识子类型或子类型的组合。可以设置OS和USR位,以便根据处理器的保护环来仅在内核模式(OS)或用户模式(USR)下递增计数器。CMASK可以设置为在计数器递增之前必须达到的事件阈值。
英特尔处理器手册(卷3B [Intel 13])列出了可以根据事件选择和UMASK值计数的几十个事件。表6.4中的选定示例提供了不同目标(处理器功能单元)可能可观察到的想法。您需要参考当前的处理器手册来查看您实际拥有的内容。
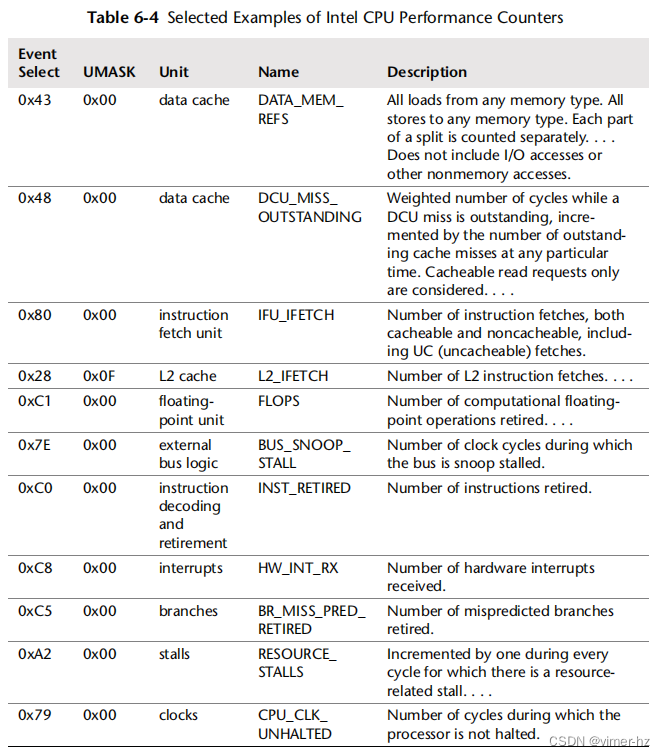
现代处理器有许多更多的计数器,特别是较新的处理器。英特尔Sandy Bridge系列处理器不仅提供更多的计数器类型,还提供更多计数器寄存器:每个硬件线程三个固定计数器和四个可编程计数器,以及每个核心额外的八个可编程计数器(“通用计数器”)。这些计数器在读取时为48位。
由于性能计数器在不同厂商之间存在差异,因此开发了一个标准,以提供跨平台的一致接口。这就是处理器应用程序编程接口(PAPI)。PAPI将计数器类型分配给通用名称,例如,PAPI_tot_cyc表示总周期计数,而不是CPU_CLK_UNHALTED。
6.4.2 Software
支持CPU的内核软件包括调度器、调度类和空闲线程。
Scheduler
内核CPU调度器的关键功能如图6.12所示。
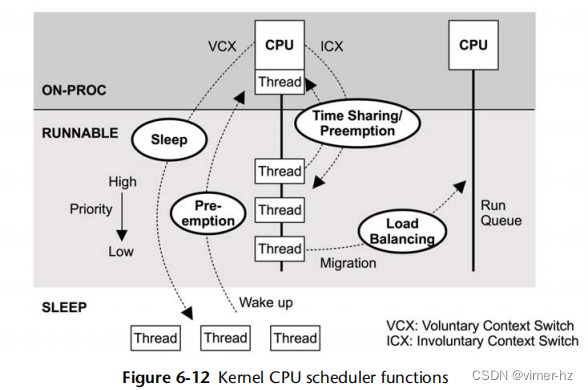
这些功能包括:
- 时间共享:在可运行线程之间进行多任务处理,首先执行优先级最高的线程。
- 抢占:对于已经以高优先级变为可运行状态的线程,调度器可以抢占当前正在运行的线程,以便立即开始执行更高优先级的线程。
- 负载平衡:将可运行线程移动到空闲或负载较低的CPU的运行队列中。
图中显示了每个CPU的运行队列。还有每个优先级级别的运行队列,因此调度器可以轻松地管理同一优先级的线程应该运行的情况。
下面是针对最近的基于Linux和Solaris的内核的调度工作的简要总结。包括了函数名称,以便您可以在源代码中找到它们进行进一步的参考(尽管它们可能已经发生了变化)。另外也可以参考文献中列出的内部文本。
Linux
在Linux上,时间共享是通过系统定时器中断驱动的,通过调用scheduler_tick()函数来调用调度类函数来管理优先级和称为时间片的CPU时间单位的到期。当线程变为可运行状态时,会触发抢占,调度器类会调用check_preempt_curr()函数。线程的切换由__schedule()函数管理,它通过pick_next_task()函数选择最高优先级的线程来运行。负载平衡由load_balance()函数执行。
Solaris
在基于Solaris的内核上,时间共享是由clock()函数驱动的,它调用调度器类函数,包括ts_tick()来检查时间片是否到期。如果线程超过其时间限制,其优先级会降低,允许另一个线程抢占。用户线程的抢占由preempt()函数处理,而内核线程的抢占由kpreempt()函数处理。swtch()函数管理离开CPU的线程,包括出于自愿的上下文切换等任何原因,并调用调度程序函数来找到最适合替代它的可运行线程:disp()、disp_getwork()或disp_getbest()。负载平衡包括空闲线程调用类似的函数,以从另一个CPU的调度程序队列(运行队列)中找到可运行线程。
Scheduling Classes
调度类管理可运行线程的行为,特别是它们的优先级,它们在CPU上的时间是否被切片,以及这些时间片的持续时间(也称为时间量子)。此外,通过调度策略还可以对其进行额外控制,这些策略可以在调度类中选择,并可以控制相同优先级线程之间的调度。图6.13展示了它们以及线程优先级范围。

用户级线程的优先级受用户定义的nice值影响,可以将其设置为降低不重要工作的优先级。在Linux中,nice值设置线程的静态优先级,这与调度器计算的动态优先级是分开的。
需要注意的是,在Linux和基于Solaris的内核之间,优先级范围是倒置的。原始的Unix优先级范围(第6版)使用较低的数字表示较高的优先级,这是现在系统Linux所采用的方式。
Linux
对于Linux内核,调度类如下:
RT:为实时工作负载提供固定和高优先级。内核支持用户级和内核级的抢占,允许实时任务以低延迟被调度。优先级范围是0-99(MAX_RT_PRIO-1)。
O(1):O(1)调度器在Linux 2.6中作为默认的用户进程时间共享调度器引入。其名称来源于O(1)的算法复杂度(参见第5章应用程序,了解大O符号的摘要)。先前的调度器包含迭代所有任务的例程,使其为O(n),这成为一个可扩展性问题。O(1)调度器动态提高I/O密集型工作负载的优先级,以减少交互和I/O工作负载的延迟。
CFS:完全公平调度被添加到Linux 2.6.23内核中,作为默认的用户进程时间共享调度器。该调度器在红黑树上管理任务,而不是传统的运行队列,其键值来自任务的CPU时间。这使得可以轻松找到并执行低CPU消耗者,优先于CPU密集型工作负载,从而提高交互和I/O密集型工作负载的性能。
用户级进程可以通过调用sched_setscheduler()来设置调度器策略,从而调整调度类的行为。RT类支持SCHED_RR和SCHED_FIFO策略,而CFS类支持SCHED_NORMAL和SCHED_BATCH。
调度器策略如下:
- RR:SCHED_RR是轮转调度。一旦线程使用完其时间量子,它将被移至该优先级级别的运行队列末尾,以便其他具有相同优先级的线程运行。
- FIFO:SCHED_FIFO是先进先出调度,继续运行运行队列开头的线程,直到它自愿离开,或直到更高优先级的线程到达。即使具有相同优先级的其他线程在运行队列上,该线程仍将继续运行。
- NORMAL:SCHED_NORMAL(以前称为SCHED_OTHER)是时间共享调度,是用户进程的默认值。调度器根据调度类动态调整优先级。对于O(1),时间片持续时间基于静态优先级进行设置:对于较高优先级的工作,持续时间较长。对于CFS,时间片是动态的。
- BATCH:SCHED_BATCH类似于SCHED_NORMAL,但预期线程将是CPU密集型,并且不应安排中断其他I/O密集型交互式工作。
随着时间的推移,可能会添加其他类和策略。已经研究了一些调度算法,这些算法具有超线程感知性[Bulpin 05]和温度感知性[Otto 06],通过考虑额外的处理器因素来优化性能。
当没有线程需要运行时,会执行一个特殊的空闲任务(也称为空闲线程)作为占位符,直到另一个线程可运行。
Solaris
对于基于Solaris的内核,调度类如下:
RT:实时调度为实时工作负载提供固定和高优先级。这些任务具有抢占所有其他工作(除中断服务程序外)的特性,以便应用程序响应时间可以确定性地保持,这是实时工作负载的典型要求。
SYS:系统是用于内核线程的高优先级调度类。这些线程具有固定的优先级,并且会执行所需的时间(或直到被RT或中断抢占)。
TS:时间共享是用户进程的默认调度类;它根据最近的CPU使用情况动态调整优先级和时间片。如果线程使用完其时间片,那么其优先级会降低,时间片会增加。这导致CPU密集型工作负载以较大的时间片低优先级运行(减少调度器成本),而I/O密集型工作负载——在其时间片用尽之前自愿进行上下文切换——以高优先级运行。结果是,I/O密集型工作负载的性能不会受长时间运行的CPU作业的影响。该类还会应用nice值(如果已设置)。
IA:交互式类似于TS,但默认优先级略高。如今很少使用(以前用于改善图形X会话的响应性)。
FX:固定(未显示在图6.13中)是一种用于设置固定优先级的进程调度类,与TS相同的全局优先级范围(0-59)。
FSS:公平份额调度(未显示在图6.13中)在项目或区域之间管理进程的CPU使用,基于份额值。这使得项目组可以根据份额公平地使用CPU,而不是根据其线程或进程数量。每个进程组可以消耗一个根据其份额值除以该时刻系统上总繁忙份额计算出的CPU的部分。这意味着如果该组是唯一繁忙的组,它可以使用所有CPU资源。FSS在云计算中广泛使用,以便租户(区域)可以公平分配份额,并在可用且未使用时使用更多CPU。FSS存在于与TS相同的全局优先级范围(0-59)并具有固定的时间片。
SYSDC:系统责任周期调度类用于大量消耗CPU的内核线程,例如ZFS事务组刷新线程。它允许指定目标责任周期(CPU时间与可运行时间的比率),并将取消安排线程以匹配责任周期。这可以防止长时间运行的内核线程(否则将属于SYS类)挤占需要使用该CPU的其他线程。
中断:为了调度中断线程,它们被赋予优先级159 + IPL(参见第3章操作系统的第3.2.3节“中断和中断线程”)。
基于Solaris的系统还支持使用sched_setscheduler()设置的调度策略(未显示在图6.13中):SCHED_FIFO、SCHED_RR和SCHED_OTHER(时间共享)。
空闲线程是一个特殊情况,以最低优先级运行。
Idle Thread
内核的“空闲”线程(或空闲任务)在没有其他可运行的线程时在CPU上运行,并具有可能的最低优先级。通常,它被设计为通知处理器可以停止CPU执行(停机指令)或降低速度以节省电源。CPU将在下一个硬件中断唤醒。
NUMA Grouping
在NUMA系统上,通过使内核具备NUMA意识,可以显著提高性能,从而能够做出更好的调度和内存放置决策。这样可以自动检测并创建本地化CPU和内存资源的组,并将它们组织成反映NUMA架构的拓扑结构。这种拓扑结构允许估计任何内存访问的成本。
在Linux系统中,这些被称为调度域[3],其拓扑结构始于根域。
在基于Solaris的系统中,这些被称为局部性组(lgrps),并从根组开始。
系统管理员可以手动进行一种形式的分组,要么将进程绑定到仅在一个或多个CPU上运行,要么创建一个专门的CPU集合供进程运行。请参阅第6.5.10节“CPU绑定”。
Processor Resource-Aware
除了NUMA之外,CPU资源拓扑可以被内核理解,以便它可以做出更好的调度决策,用于电源管理和负载平衡。在基于Solaris的系统中,这是通过处理器组来实现的。
6.5 Methodology
这一部分介绍了CPU分析和调优的各种方法和练习。表6.5总结了相关主题。
更多策略和这些内容的介绍,请参阅第2章“方法论”。您不需要使用它们的全部,可以将其视为一本食谱书,可以单独或组合使用其中的方法。
我的建议是按照以下顺序使用:性能监测、USE方法、性能分析、微基准测试和静态分析。
第6.6节“分析”展示了应用这些策略的操作系统工具。
6.5.1 Tools Method
工具方法是一个反复使用可用工具、检查其提供的关键指标的过程。虽然这是一种简单的方法论,但它可能忽视工具未提供良好或无法见到的问题,并且可能需要耗费大量时间来执行。
对于CPU,工具方法可以包括检查以下内容:
- uptime:检查负载平均值,以查看CPU负载随时间是增加还是减少。系统中的平均负载超过CPU数量通常表示饱和。
- vmstat:每秒运行一次,并检查空闲列,以查看可用空间。低于10%可能会出现问题。
- mpstat:检查单个繁忙(忙碌)的CPU,识别可能存在的线程可伸缩性问题。
- top/prstat:查看哪些进程和用户是最大的CPU消耗者。
- pidstat/prstat:将最大的CPU消耗者细分为用户时间和系统时间。
- perf/dtrace/stap/oprofile:为用户或内核时间分析CPU使用堆栈跟踪,以确定CPU被使用的原因。
- perf/cpustat:测量CPI。
如果发现问题,可以从可用工具的所有字段中检查以获取更多背景信息。有关每个工具的更多信息,请参阅第6.6节“分析”。
6.5.2 USE Method
USE 方法用于在性能调查的早期阶段,识别所有组件中的瓶颈和错误,在深入且耗时的策略之前进行。
对于每个 CPU,检查以下内容:
- 利用率(Utilization):CPU 忙碌的时间(不在空闲线程中)
- 饱和度(Saturation):可运行线程排队等待轮到它们在 CPU 上运行的程度
- 错误(Errors):CPU 错误,包括可纠正的错误
错误可能首先被检查,因为它们通常很快就可以检查,并且最容易解释。一些处理器和操作系统会感知到可纠正错误(纠错码,ECC)的增加,并在不可纠正错误导致 CPU 失效之前作为预防措施将 CPU 下线。检查这些错误可能仅仅是确认所有 CPU 仍然在线上。
利用率通常可以通过操作系统工具以百分比忙碌状态的形式轻松获得。应该针对每个 CPU 检查此指标,以检查是否存在可扩展性问题。也可以针对每个核心进行检查,以防止某个核心的资源被大量利用,从而阻止空闲的硬件线程执行。通过使用分析和周期分析,可以了解高 CPU 和核心利用率。
对于实现 CPU 限制或配额(资源控制)的环境,例如某些云计算环境中,CPU 利用率可能需要根据所施加的限制来衡量,除了物理限制之外。您的系统可能在物理 CPU 达到 100% 利用率之前就已经耗尽其 CPU 配额,比预期提前遇到饱和。
饱和度指标通常是系统范围内提供的,包括作为负载平均值的一部分。此指标量化了 CPU 过载的程度,或者如果存在 CPU 配额,则表示已经使用完。
6.5.3 Workload Characterization
在容量规划、基准测试和模拟工作负载中,对所施加的负载进行表征是很重要的。通过识别可以消除的不必要工作,也可以实现一些最大的性能提升。
用于表征 CPU 工作负载的基本属性包括:
- 负载平均数(利用率 + 饱和度)
- 用户时间与系统时间比率
- 系统调用速率
- 自愿上下文切换速率
- 中断速率
这些属性的目的是表征所施加的负载,而不是已交付的性能。负载平均数适合这一目的,因为它反映了所请求的 CPU 负载,而不考虑利用率/饱和度分布所显示的已交付性能。请参阅第 6.6.1 节“uptime”中的示例和进一步说明。
速率指标有点难以解释,因为它们既反映了所施加的负载,也在一定程度上反映了已交付的性能,这可能会限制它们的速率。
用户时间与系统时间比率显示了所施加的负载类型,正如在第 6.3.7 节“用户时间/内核时间”中介绍的那样。高用户时间率是由于应用程序花费时间执行它们自己的计算。高系统时间显示花费在内核中的时间,可以通过系统调用和中断率进一步理解。I/O 密集型工作负载具有较高的系统时间、系统调用以及自愿上下文切换速率,因为线程在等待 I/O 时会阻塞。
以下是一个工作负载描述示例,旨在展示这些属性如何一起表达:
在我们最繁忙的应用服务器上,负载平均值在一天中变化在 2 到 8 之间,具体取决于活跃客户端的数量。用户/系统比率为 60/40,因为这是一个 I/O 密集型工作负载,每秒执行约 100 K 个系统调用,并且有很高的自愿上下文切换率。
这些特征随着遇到不同负载而随时间变化。
Advanced Workload Characterization/Checklist
为了表征工作负载,可以包含额外的细节。以下列出的问题可作为考虑的指导,同时也可在深入研究 CPU 问题时起到检查表的作用:
- 整个系统的 CPU 利用率是多少?每个 CPU 呢?
- CPU 负载有多少并行性?是单线程的吗?有多少线程?
- 哪些应用程序或用户正在使用 CPU?使用量如何?
- 哪些内核线程正在使用 CPU?使用量如何?
- 中断的 CPU 使用率是多少?
- CPU 互连的利用率是多少?
- 为什么要使用 CPU(用户级和内核级调用路径)?
- 遇到了哪些类型的停滞周期?
请参阅第二章“方法论”以获得对该方法论以及要测量的特征(谁、为什么、什么、如何)的更高层次摘要。接下来的章节扩展了列表中的最后两个问题:如何使用分析来分析调用路径,以及如何使用周期分析来分析停滞周期。
6.5.4 Profiling
性能分析构建了一个研究对象的图像。CPU 使用情况可以通过在定时间隔采样 CPU 的状态来进行性能分析,具体步骤如下:
1. 选择要捕获的性能分析数据类型和频率。
2. 在定时间隔开始采样。
3. 等待感兴趣的活动发生。
4. 结束采样并收集样本数据。
5. 处理数据。
一些性能分析工具(包括 DTrace)允许在仍在进行采样时对捕获的数据进行实时处理和分析。
处理和浏览数据可能会受益于与用于收集数据的工具集不同的工具集。一个例子是火焰图(稍后介绍),它可以处理 DTrace 和其他性能分析工具的输出。另一个例子是 Oracle Solaris Studio 的性能分析器,它可以自动收集和浏览带有目标源代码的性能分析数据。
CPU 性能分析数据的类型基于以下因素:
- 用户级别、内核级别或两者兼而有之
- 函数和偏移量(基于程序计数器)、仅函数、部分堆栈跟踪或完整堆栈跟踪
选择同时捕获用户和内核级别的完整堆栈跟踪将捕获 CPU 使用情况的完整性能分析。然而,这通常会生成过多的数据。
仅捕获用户或内核部分堆栈(例如,深度为五级)甚至只捕获执行函数名称可能已经足以从更少的数据中识别 CPU 使用情况。
作为性能分析的简单示例,以下是一个 DTrace 单行命令,以 997 Hz 的频率对用户级别函数名称进行 10 秒的采样:


DTrace 已经执行了步骤 5,通过聚合函数名称并打印排序后的频率计数来处理数据。这表明,跟踪期间最常见的 on-CPU 用户级函数是 ut_fold_ulint_pair(),它被采样了 4,039 次。
使用 997 Hz 的频率可以避免与任何活动(例如以 100 或 1,000 Hz 运行的定时任务)同步采样。
通过采样完整的堆栈跟踪,可以识别 CPU 使用情况的代码路径,这通常指向 CPU 使用情况的更高级原因。在第 6.6 节“分析”中给出了更多采样的示例。此外,请参阅第五章“应用程序”,了解有关 CPU 性能分析的更多内容,包括从堆栈中获取其他编程语言上下文。
对于特定 CPU 资源(例如缓存和互连),性能分析可以使用基于 CPC 的事件触发器而不是定时间隔。这在下一节的周期分析中进行了描述。
6.5.5 Cycle Analysis
通过使用 CPU 性能计数器(CPCs),可以在周期级别了解 CPU 利用率。这可能会揭示周期是花费在一级、二级或三级缓存未命中、内存 I/O 或资源 I/O 上,或花费在浮点运算或其他活动上。这些信息可能通过调整编译器选项或更改代码来实现性能优化。
通过测量每指令周期数(CPI)开始进行周期分析。如果 CPI 较高,继续调查停滞周期的类型。如果 CPI 较低,寻找代码中减少执行指令的方法。对于“高”或“低” CPI 的值取决于您的处理器:低可能小于一,高可能大于十。您可以通过执行已知的以内存 I/O 或指令为主的工作负载,并测量每个工作负载的结果 CPI 来了解这些值。
除了测量计数器值外,CPC 还可以配置为在给定值溢出时中断内核。例如,每当发生 10,000 次二级缓存未命中时,可以中断内核以收集堆栈回溯。随着时间的推移,内核构建了导致二级缓存未命中的代码路径的概要,而无需测量每个未命中的繁重开销。这通常由集成开发环境(IDE)软件使用,以在引起内存 I/O 和停滞周期的位置上注释代码。使用 DTrace 和 cpc 提供程序也可以实现类似的可观察性。
周期分析是一项高级活动,可能需要几天的时间才能使用命令行工具进行,如第 6.6 节“分析”所示。您还应该花一些时间阅读您的 CPU 供应商的处理器手册。性能分析工具(如 Oracle Solaris Studio)可以节省时间,因为它们经过编程,可以找到您感兴趣的 CPC。
6.5.6 Performance Monitoring
性能监控可以在一段时间内识别出活动问题和行为模式。CPU 的关键指标包括:
利用率:表示占用率的百分比;
饱和度:可以通过运行队列长度(从负载平均值推导)或线程调度延迟来衡量;
应该按照每个 CPU 的基础进行利用率监控,以识别线程可扩展性问题。对于实现了 CPU 限制或配额(资源控制)的环境,如某些云计算环境,还需要记录与这些限制相比的 CPU 使用情况。
在监控 CPU 使用情况时面临的挑战是选择测量和存档的间隔。一些监控工具使用 5 分钟的间隔,但这可能会隐藏较短的 CPU 利用率突发。更倾向于使用每秒钟的测量,但您应该意识到即使在一秒钟内也可能存在突发。这些突发可以通过饱和度来识别。
6.5.7 Static Performance Tuning
静态性能调优侧重于已配置环境的问题。对于 CPU 性能,需要检查静态配置的以下方面:
可用于使用的 CPU 数量是多少?它们是核心吗?硬件线程吗?
CPU 架构是单处理器还是多处理器?
CPU 缓存的大小是多少?它们是共享的吗?
CPU 时钟速度是多少?它是动态的(例如,英特尔 Turbo Boost 和 SpeedStep)吗?这些动态功能在 BIOS 中启用了吗?
BIOS 中是否启用或禁用了其他与 CPU 相关的功能?
此处理器型号是否存在性能问题(缺陷)?它们是否列在处理器勘误表中?
此 BIOS 固件版本是否存在性能问题(缺陷)?
软件是否强制实施了 CPU 使用限制(资源控制)?是什么限制?
这些问题的答案可能揭示先前被忽视的配置选择。
最后一个问题尤其适用于云计算环境,其中 CPU 使用通常受限制。
6.5.8 Priority Tuning
Unix一直提供了一个用于调整进程优先级的nice()系统调用,它设置了一个nice值。正值nice值会导致较低的进程优先级(更nice),而负值nice值——只有超级用户(root)可以设置——会导致更高的优先级。出现了一个nice(1)命令,用于以nice值启动程序,并后来添加了renice(1M)命令(在BSD中),用于调整已运行进程的nice值。Unix第4版的man页面提供了这个示例:
对于希望执行长时间运行程序而不受管理人员干扰的用户,推荐使用值16。
今天,nice值仍然对调整进程优先级很有用。当CPU争用时,导致高优先级工作的调度器延迟时,这最为有效。您的任务是识别低优先级工作,其中可能包括监控代理和定期备份,这些工作可以通过设置nice值进行修改。还可以进行分析以检查调整是否有效,并确保对于高优先级工作,调度器延迟保持较低水平。
除了nice之外,操作系统可能会提供更高级的进程优先级控制,例如更改调度器类或调度策略,或更改类的调整。Linux和基于Solaris的内核都包括实时调度类,这可以允许进程抢占所有其他工作。尽管这可以消除调度器延迟(除了其他实时进程和中断之外),但请确保您了解后果。如果实时应用程序遇到多个线程进入无限循环的bug,可能会导致所有CPU对于所有其他工作不可用,包括手动修复问题所需的管理shell。这种特定情况通常只能通过重新启动系统来解决(糟糕!)。
6.5.9 Resource Controls
操作系统可以为分配CPU周期给进程或一组进程提供细粒度控制。这些控制可能包括对CPU利用率的固定限制和股份,以实现更灵活的方法——根据股份值允许使用空闲CPU周期。这些工作方式是与实现相关的,并在第6.8节“调优”中进行讨论。
6.5.10 CPU Binding
调整CPU性能的另一种方法涉及将进程和线程绑定到单独的CPU或CPU集合。这可以增加进程的CPU缓存热度,提高其内存I/O性能。对于NUMA系统,这也改善了内存局部性,同时也提高了性能。
通常有两种执行方式:
- 进程绑定:配置一个进程只在单个CPU上运行,或者仅在定义的一组CPU中选择一个CPU上运行。
- 独占CPU集:划分一组只能由分配给它们的进程使用的CPU。这可以进一步改善CPU缓存,因为当进程空闲时,其他进程无法使用CPU,使缓存保持温暖。
在基于Linux的系统上,可以使用cpusets实现独占CPU集方法。在基于Solaris的系统上,这称为处理器集。配置示例可在第6.8节“调优”中找到。
6.5.11 Micro-Benchmarking
有各种用于CPU微基准测试的工具,通常是测量执行简单操作所需的时间多次。这些操作可能基于以下内容:
- CPU指令:整数算术、浮点运算、内存加载和存储、分支和其他指令
- 内存访问:用于研究不同CPU缓存的延迟和主内存吞吐量
- 更高级别语言:类似于CPU指令测试,但使用高级解释或编译语言编写
- 操作系统操作:测试系统库和系统调用函数,如getpid()和进程创建等CPU限制操作
早期的CPU基准测试例子是国家物理实验室在1972年用Algol 60编写的Whetstone,旨在模拟科学工作负载。后来在1984年开发了Dhrystone基准测试,用于模拟当时的整数工作负载,并成为比较CPU性能的流行手段。这些基准测试,以及包括进程创建和管道吞吐量在内的各种Unix基准测试,被收录在一个名为UnixBench的集合中,最初来自莫纳什大学,并由BYTE杂志发布。近年来创建了更多CPU基准测试,用于测试压缩速度、素数计算、加密和编码等。
无论您使用哪种基准测试,在比较系统之间的结果时,重要的是要了解真正被测试的内容。像之前描述的这些基准测试经常会测试不同编译器版本之间的编译优化,而不是基准测试代码或CPU速度。许多基准测试也是单线程执行的,但这些结果在具有多个CPU的系统中失去意义。一个四CPU系统的基准测试可能略快于一个八CPU系统,但后者在提供足够的并行可运行线程时很可能会提供更大的吞吐量。
有关基准测试的更多信息,请参阅第12章“基准测试”。
6.5.12 Scaling
这里是一个基于资源容量规划的简单扩展方法:
1. 确定目标用户人口或应用请求速率。
2. 表达每个用户或每个请求的CPU使用率。对于现有系统,可以使用当前用户数量或请求速率监视CPU使用情况。对于未来系统,负载生成工具可以模拟用户,以便测量CPU使用率。
3. 当CPU资源利用率达到100%时,推断用户或请求。这为系统提供了理论极限。
系统可扩展性也可以建模以考虑争用和一致性延迟,以更真实地预测性能。有关此内容的更多信息,请参见第2章“方法论”中的第2.6节“建模”,以及同一章中有关扩展的第2.7节“容量规划”。
6.6 Analysis
本节介绍了针对基于Linux和Solaris操作系统的CPU性能分析工具。有关在使用这些工具时应遵循的策略,请参阅前一节。
本节中列出的工具见表6.6。
该列表首先介绍了用于CPU统计的工具,然后深入介绍了用于更深入分析的工具,包括代码路径分析和CPU周期分析。这是一组工具和功能,用于支持第6.5节“方法论”。有关每个工具的完整功能参考,请查阅每个工具的文档,包括其man页面。虽然您可能只对基于Linux或仅基于Solaris的系统感兴趣,但请考虑查看其他操作系统的工具以及它们提供的可观测性,以获得不同的视角。
6.6.1 uptime
uptime(1)是一些命令之一,用于打印系统的平均负载:

最后三个数字分别是1分钟、5分钟和15分钟的平均负载。通过比较这三个数字,您可以确定在过去的15分钟(左右)内负载是增加、减少还是保持稳定。
Load Averages
负载平均值表示对CPU资源的需求,计算方法是将正在运行的线程数(利用率)和排队等待运行的线程数(饱和度)相加。一种较新的计算负载平均值的方法是使用利用率加上线程调度延迟的总和,而不是采样队列长度,这有助于提高准确性。关于Solaris内核中这些计算的内部细节已在[McDougall 06b]中有记录。
要解释这个值,如果负载平均值高于CPU核心数量,那么没有足够的CPU来为线程提供服务,有些线程在等待。如果负载平均值低于CPU核心数量,那么(可能)意味着有剩余空间,线程可以在需要时在CPU上运行。
这三个负载平均数是指数衰减移动平均数,反映了超过1分钟、5分钟和15分钟时间的负载情况(实际上这些时间是指数移动求和中使用的常数[Myer 73])。图6.14展示了一个简单实验的结果,其中启动了一个单一的CPU密集型线程,并绘制了负载平均值。
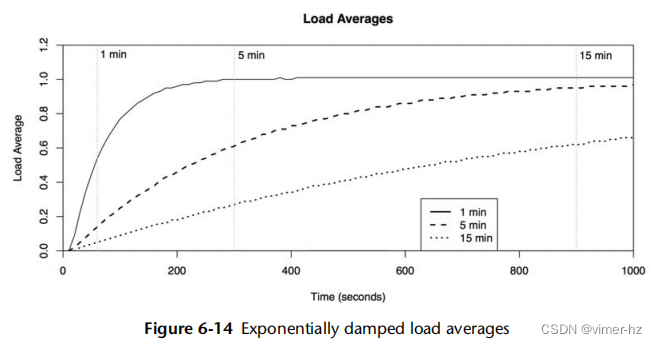
在1分钟、5分钟和15分钟的标记处,负载平均值已达到已知负载1.0的约61%。
负载平均值最早引入Unix系统中的早期BSD版本,基于调度器平均队列长度以及早期操作系统(如CTSS、Multics [Saltzer 70]、TENEX [Bobrow 72])中常用的负载平均值。这些负载平均值在[RFC 546]中有描述:
[1] TENEX负载平均值是对CPU需求的衡量。负载平均值是在给定时间段内可运行进程的平均值。例如,一个每小时负载平均值为10意味着(对于单CPU系统),在那一小时内的任何时刻都可以预期看到1个正在运行的进程和9个准备运行的进程(即未被I/O阻塞)等待CPU。
举个现代的例子,一个拥有64个CPU的系统的负载平均值为128。这意味着平均每个CPU始终有一个线程在运行,并且每个CPU都有一个线程在等待。同样的系统,如果负载平均值为10,表示有相当大的剩余空间,因为它可以在所有CPU都忙碌之前运行另外54个CPU密集型线程。
Linux Load Averages
目前,Linux将处于不可中断状态的执行磁盘I/O任务添加到负载平均值中。这意味着负载平均值不再仅仅表示CPU的剩余空间或饱和度,因为仅从数值本身无法确定它到底反映了多大程度的CPU负荷或磁盘负荷。同时,由于负载在不同的CPU和磁盘之间随时间变化,对三个负载平均数进行比较也变得困难。
另一种整合其他资源负载的方法是针对每种资源类型使用单独的负载平均值。(我曾为磁盘、内存和网络负载分别提供了各自的负载平均值示例,并发现这对非CPU资源提供了类似且有用的概览。)最好使用其他指标来了解Linux上的CPU负载,例如vmstat(1)和mpstat(1)提供的指标。
6.6.2 vmstat
虚拟内存统计命令vmstat(8)在最后几列中显示了系统范围的CPU平均值,并在第一列中显示可运行线程的计数。以下是Linux版本的示例输出:


输出的第一行是自引导以来的摘要,除了Linux上的r列——它开始显示当前值。各列含义如下:
- r:运行队列长度—可运行线程的总数(见下文)
- us:用户时间
- sy:系统时间(内核)
- id:空闲时间
- wa:等待I/O,用于衡量当线程在磁盘I/O上阻塞时CPU的空闲时间
- st:被窃取的时间(未在输出中显示),用于虚拟化环境中展示CPU时间用于为其他租户提供服务
除r列外,所有这些值都是跨所有CPU的系统范围平均值,r列则表示总数。
在Linux上,r列表示等待任务和正在运行任务的总数。man手册目前描述的内容是其他内容——“等待运行时间的进程数量”—这表明它仅计算等待的进程而不是正在运行的进程。作为对其预期含义的启示,在1979年由Bill Joy和Ozalp Babaoglu为3BSD编写的原始vmstat(1)以RQ列开始,用于表示可运行和正在运行的进程数量,就像目前的Linux vmstat(8)一样。man手册需要更新。
在Solaris上,r列仅计算位于分发队列(运行队列)中等待的线程数量。该值可能看起来不稳定,因为它仅每秒进行一次采样(从clock()中取样),而其他CPU列基于高分辨率CPU微状态。这些其他列目前不包括等待I/O或被窃取的时间。有关更多关于等待I/O的信息,请参阅第9章《磁盘》。
6.6.3 mpstat
多处理器统计工具mpstat可以按CPU报告统计信息。以下是Linux版本的一些示例输出:

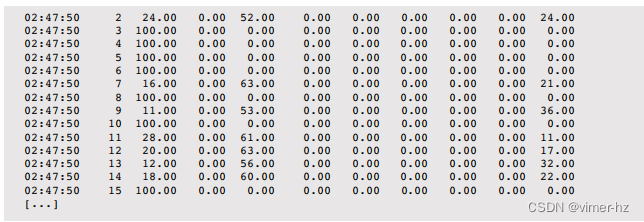
使用-P ALL选项可打印每个CPU的报告。默认情况下,mpstat(1)仅打印系统范围的摘要行(all)。各列含义如下:
- CPU:逻辑CPU ID,或用于总结的all
- %usr:用户时间
- %nice:具有nice'd优先级进程的用户时间
- %sys:系统时间(内核)
- %iowait:I/O等待时间
- %irq:硬件中断CPU使用率
- %soft:软件中断CPU使用率
- %steal:用于为其他租户提供服务的时间
- %guest:在虚拟机中花费的CPU时间
- %idle:空闲时间
关键列为%usr、%sys和%idle。这些列标识每个CPU的CPU使用情况,并显示用户时间/内核时间比率。这还可以识别“繁忙”CPU——那些运行在100%利用率(%usr+%sys)而其他CPU没有的情况,可能是由单线程应用程序工作负载或设备中断映射引起的。
对于基于Solaris的系统,mpstat(1M)从自引导以来的摘要开始,然后是间隔摘要。例如:

各列包括:
- CPU:逻辑CPU ID
- xcal:CPU之间的跨调用次数
- intr:中断次数
- ithr:作为线程服务的中断数量(较低的IPL)
- csw:上下文切换次数(总计)
- icsw:非自愿上下文切换次数
- migr:线程迁移次数
- smtx:互斥锁旋转次数
- srw:读者/写者锁旋转次数
- syscl:系统调用次数
- usr:用户时间
- sys:系统时间(内核)
- wt:等待I/O(已弃用,始终为零)
- idl:空闲时间
要检查的关键列包括:
- xcal,用于查看是否存在超额速率,这会消耗CPU资源。例如,查看在多个CPU上至少为1,000次/秒。通过详细分析可以解释其原因(参见第6.6.10节《DTrace》中的示例)。
- smtx,用于查看是否存在超额速率,这会消耗CPU资源,并且可能也是锁竞争的证据。可以使用其他工具来探索锁活动(参见第5章《应用程序》)。
- usr、sys和idl,用于描述每个CPU的CPU使用情况以及用户时间/内核时间比率。
6.6.4 sar
系统活动报告工具sar(1)可用于观察当前活动,并可配置为存档和报告历史统计信息。它在第4章《可观测性工具》中介绍,并在其他相关章节中提到。Linux版本提供以下选项:
- -P ALL:与mpstat -P ALL相同
- -u:与mpstat(1)的默认输出相同:仅系统范围的平均值
- -q:包括运行队列大小作为runq-sz(等待加运行,与vmstat的r相同)和负载平均值
Solaris版本提供:
- -u:%usr、%sys、%wio(零)和%idl的系统范围平均值
- -q:包括运行队列大小作为runq-sz(仅等待),以及运行队列中有线程等待的时间百分比作为%runocc,尽管该值在0到1之间不准确
Solaris版本不提供每CPU的统计信息。
6.6.5 ps
进程状态命令ps(1)列出所有进程的详细信息,包括CPU使用统计数据。例如:
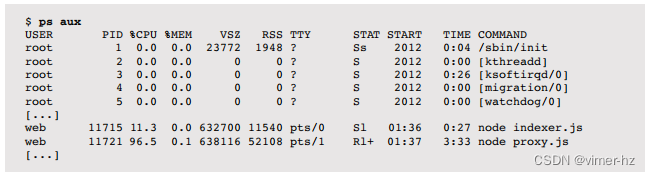
这种操作风格起源于BSD,可以通过在aux选项之前缺少破折号来识别。这些选项列出所有用户(a),具有扩展的面向用户的详细信息(u),并包括没有终端的进程(x)。终端显示在电传打字机(TTY)列中。
另一种风格来自SVR4,使用在选项之前带有破折号的方式:
这将列出每个进程(-e),并显示完整详情(-f)。在大多数基于Linux和Solaris的系统上,ps(1)支持BSD和SVR4参数。
CPU使用的关键列是TIME和%CPU。
TIME列显示进程(用户+系统)自创建以来消耗的总CPU时间,以小时:分钟:秒为单位。
在Linux上,%CPU列显示前一秒钟跨所有CPU的CPU使用情况总和。单线程的CPU密集型进程将报告100%。双线程的CPU密集型进程将报告200%。
在Solaris上,%CPU已标准化为CPU数量。例如,在一个八核系统中,一个单线程的CPU密集型线程将显示为12.5%。该指标还显示最近的CPU使用情况,使用与负载平均值类似的衰减平均值。
ps(1)还提供各种其他选项,包括-o用于自定义输出和显示的列。
6.6.6 top
top(1)命令是由William LeFebvre在1984年为BSD系统创建的。他受到了VMS命令MONITOR PROCESS/TOPCPU的启发,该命令显示了消耗CPU最多的作业,包括CPU百分比和ASCII条形图直方图(但不包括数据列)。
top(1)命令监视顶部运行的进程,并以固定时间间隔更新屏幕。例如,在Linux上:

系统范围的摘要显示在顶部,进程/任务列表显示在底部,默认按照CPU消耗最高的进程进行排序。系统范围的摘要包括负载平均值和CPU状态:%us, %sy, %ni, %id, %wa, %hi, %si, %st。这些状态等同于之前描述的mpstat(1)打印的状态,并且是对所有CPU进行平均计算的。
CPU使用情况通过TIME和%CPU列显示,这两列是在前面关于ps(1)的部分中介绍的。
这个例子显示了一个TIME+列,与上面显示的列相同,但分辨率为百分之一秒。例如,“1:36.53”表示总共1分钟36.53秒的CPU时间。某些版本的top(1)提供了可选的“累计时间”模式,其中包括已退出的子进程的CPU时间。
在Linux上,默认情况下,%CPU列的值不会根据CPU核数进行归一化;top(1)将其称为“Irix模式”,以IRIX上的行为命名。可以切换到“Solaris模式”,该模式将CPU使用情况除以CPU核数。在这种情况下,在16 CPU服务器上运行的热点双线程进程将报告百分比CPU为12.5。
虽然top(1)通常是性能分析师的工具,但你应该意识到top(1)本身的CPU使用率可能会变得显著,并将top(1)作为CPU消耗最高的进程!这是由于可用的系统调用(open()、read()、close())及其在迭代/proc条目时的成本导致的。一些基于Solaris系统的top(1)版本通过保持文件描述符打开并调用pread()来减少开销,prstat(1M)工具也采用了这种方式。
由于top(1)对/proc进行快照,它可能会错过在快照被拍摄前就退出的短暂进程。这在软件构建过程中经常发生,因为CPU可能会被许多短暂的构建工具大量加载。一种用于Linux的top(1)变种,称为atop(1),使用进程记账来捕获短暂进程的存在,并将其包含在显示中。
6.6.7 prstat
prstat(1)命令被引入为“面向基于Solaris系统的top命令”。例如:
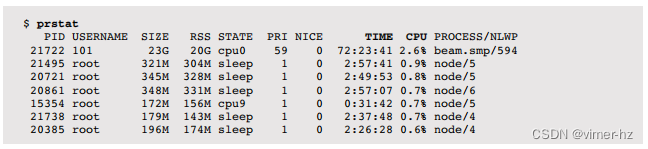
底部显示了一行系统摘要。CPU列显示最近的CPU使用情况,与Solaris上的top(1)显示的指标相同。TIME列显示已消耗的时间。
prstat(1M)通过使用保持文件描述符打开的方式,使用pread()读取/proc状态,而不是使用open()、read()、close()循环,从而消耗较少的CPU资源。
可以使用-m选项通过prstat(1M)打印线程微状态账户统计信息。以下示例使用-L按线程(每个LWP)报告此信息,并使用-c进行持续输出(而不是屏幕刷新):
这八列显示了在每个微状态中所花费的时间,并总和为100%。它们分别是:
- USR: 用户时间
- SYS: 系统时间(内核)
- TRP: 系统陷阱
- TFL: 文本错误(可执行段的页面错误)
- DFL: 数据错误
- LCK: 等待用户级锁的时间
- SLP: 休眠时间,包括I/O阻塞
- LAT: 调度延迟(调度器队列延迟)
线程时间的这种分解非常有用。以下是进一步研究的建议路径(还可以参见第5章应用程序中的5.4.1节“线程状态分析”):
- USR: 用户级CPU使用率的分析
- SYS: 检查使用的系统调用并分析内核级CPU使用率
- SLP: 取决于休眠事件;跟踪系统调用或代码路径以获取更多详细信息
- LAT: 检查系统范围的CPU利用率和任何施加的CPU限制/配额
其中许多内容也可以使用DTrace来执行。
6.6.8 pidstat
Linux的pidstat(1)工具打印进程或线程的CPU使用情况,包括用户和系统时间的分解。默认情况下,仅打印活动进程的滚动输出。例如:
这个例子捕获了一个系统备份过程,涉及使用tar(1)命令从文件系统读取文件,并使用gzip(1)命令对其进行压缩。如预期的那样,gzip(1)的用户时间很高,因为它在压缩代码中变为CPU密集型。tar(1)命令在内核中花费了更多时间,从文件系统中读取数据。
可以使用-p ALL选项来打印所有进程,包括那些空闲的进程。-t用于打印每个线程的统计信息。其他pidstat(1)选项包含在本书的其他章节中。
6.6.9 time, ptime
time(1)命令可用于运行程序并报告CPU使用情况。它通常位于操作系统的/usr/bin目录下,也可以作为shell内建命令提供。
以下示例在一个大文件上两次运行time来计算cksum(1)命令的校验和:
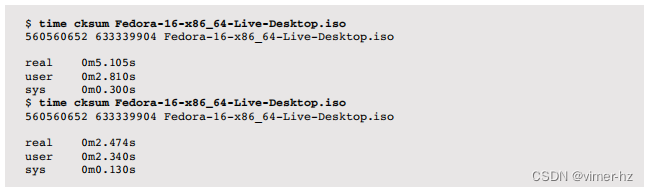
首次运行花费了5.1秒,其中有2.8秒是在用户模式下进行校验和计算,0.3秒是在系统模式下进行读取文件所需的系统调用。缺失的2.0秒(5.1 - 2.8 - 0.3)可能是在磁盘I/O读取上被阻塞的时间,因为这个文件只被部分缓存。第二次运行完成得更快,只用了2.5秒,几乎没有任何阻塞在I/O上的时间。这是可以预期的,因为第二次运行时,文件可能完全被缓存在主存中。
在Linux上,/usr/bin/time版本支持详细信息:
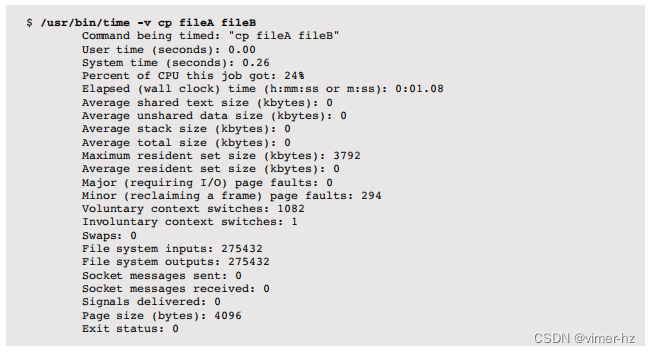
一般情况下,shell内建版本不提供-v选项。
基于Solaris的系统包括时间命令的另一个版本ptime(1),它基于线程微状态计算提供高精度的时间。如今,基于Solaris的系统上的time(1)最终使用相同的统计数据来源。ptime(1)仍然很有用,因为它提供了一个-m选项来打印完整的线程微状态时间集,包括调度器延迟(lat):

在这种情况下,运行时长为8.3秒,其中有6.4秒处于休眠状态(磁盘I/O)。
6.6.10 DTrace
DTrace可以用于对用户级和内核级代码的CPU使用情况进行分析,以及跟踪函数执行、CPU跨调用、中断和内核调度器。这些功能支持工作负载特征化、性能分析、深入分析和延迟分析。
以下部分介绍了在基于Solaris和Linux的系统上使用DTrace进行CPU分析。除非另有说明,DTrace命令适用于两种操作系统。第4章“可观测性工具”中包含了DTrace入门介绍。
Kernel Profiling
先前的工具,包括mpstat(1)和top(1),显示了系统时间——在内核中花费的CPU时间。DTrace可以用于确定内核正在做什么。
下面的一行命令在基于Solaris的系统上演示,在997 Hz的频率下对内核堆栈进行采样(以避免锁步,详见第6.5.4节“性能分析”)。谓词确保在进行采样时CPU处于内核模式,通过检查内核程序计数器(arg0)是否非零:

最频繁的堆栈最后打印出来,在这种情况下是空闲线程的堆栈,被采样了23,083次。对于其他堆栈,显示了顶部函数和祖先。
此输出中有许多页面被截断。以下一行命令展示了其他采样内核CPU使用情况的方法,其中一些将输出进一步压缩。
One-Liners
以997 Hz的频率采样内核堆栈:
![]()
以997 Hz的频率采样内核堆栈,仅显示前十个:
![]()
以997 Hz的频率采样内核堆栈,仅显示五个帧:
![]()
以997 Hz的频率采样内核上的CPU函数:
![]()
以997 Hz的频率采样内核上的CPU模块:
![]()
User Profiling
类似于内核,可以对用户模式下花费的CPU时间进行性能分析。以下一行命令通过检查arg1(用户PC)匹配用户级代码,并且还匹配名称为"mysqld"(MySQL数据库)的进程:
最后一个堆栈显示MySQL正在执行do_command()和calc_sum_of_all_status(),这两个函数经常执行在CPU上。堆栈帧看起来有点混乱,因为它们是C++签名(可以使用c++filt(1)工具来还原)。
以下一行命令展示了其他采样用户CPU使用情况的方法,前提是用户级操作是可用的(此功能目前尚未移植到Linux)。
One-Liners
以97 Hz的频率采样PID为123的用户堆栈:
![]()
以97 Hz的频率采样所有名称为"sshd"的进程的用户堆栈:
![]()
以97 Hz的频率采样系统上所有进程(在输出中包含进程名称)的用户堆栈:
![]()
以97 Hz的频率采样PID为123的用户堆栈,仅显示前十个:

以97 Hz的频率采样PID为123的用户堆栈,仅显示五个帧:
![]()
以97 Hz的频率采样PID为123的用户CPU函数:
![]()
以97 Hz的频率采样PID为123的用户CPU模块:
![]()
以97 Hz的频率采样PID为123的用户堆栈,包括在系统时间冻结期间用户堆栈的情况(通常在系统调用时):
![]()
以97 Hz的频率采样进程在哪个CPU上运行的信息,对PID为123的进程进行采样:
![]()
Function Tracing
虽然性能分析可以显示函数消耗的总CPU时间,但它并不显示这些函数调用的运行时分布。这可以通过使用跟踪和内置的vtimestamp来确定,vtimestamp是一个高分辨率时间戳,仅在当前线程在CPU上时递增。可以通过跟踪函数的进入和返回,并计算vtimestamp之间的差值来测量函数的CPU时间。例如,使用动态跟踪(fbt提供者)来测量内核ZFS zio_checksum_generate()函数中的CPU时间:
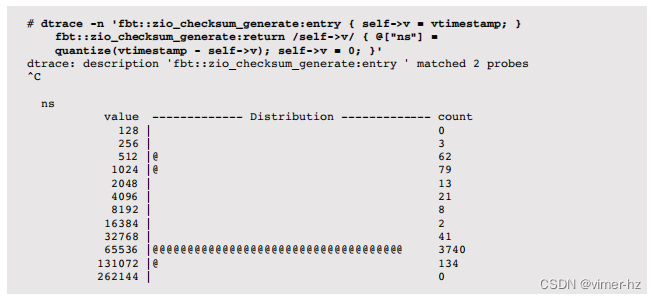
这个函数大部分时间消耗在65至131微秒的CPU时间范围内。这包括所有子函数的CPU时间。
如果该函数被频繁调用,这种特定的跟踪方式可能会增加开销。最好与性能分析结合使用,以便进行交叉检查。
如果可用,类似的动态跟踪也可以通过PID提供程序执行用户级代码。
通过fbt或pid提供程序进行动态跟踪被视为不稳定的接口,因为函数可能在不同版本之间发生变化。静态跟踪提供程序可用于跟踪CPU行为,旨在提供稳定的接口。这些包括用于跟踪CPU跨调用、中断和调度器活动的探针。
CPU Cross Calls
过多的CPU跨调用会由于它们的CPU消耗而降低性能。在引入DTrace之前,跨调用的来源很难确定。现在只需要一行命令,就可以追踪跨调用并显示导致它们的代码路径。
这是在一个基于Solaris的系统上使用sysinfo提供程序进行演示的。
Interrupts
DTrace允许跟踪和检查中断。基于Solaris的系统配备了intrstat(1M),这是一个基于DTrace的工具,用于总结中断CPU使用情况。
例如:
输出通常在多CPU系统上非常长,其中包括每个驱动程序在每个CPU上的中断计数和CPU时间百分比。前面的摘录显示mega_sas驱动程序占用了CPU 5的7.1%。
如果intrstat(1M)不可用(目前在Linux上就是这种情况),可以通过使用动态函数跟踪来检查中断活动。
Scheduler Tracing
调度器提供程序(sched)提供用于跟踪内核CPU调度器操作的探针。探针列在表6.7中。

由于许多这些事件发生在线程上下文中,curthread内置指的是相关的线程,并且可以使用线程局部变量。例如,可以使用线程局部变量(self->ts)来跟踪CPU运行时间:
这对名为"sshd"的进程进行了CPU运行时间的跟踪。大部分时间它只在CPU上短暂运行,介于32到65微秒之间。
6.6.11 SystemTap
SystemTap也可以在Linux系统上用于跟踪调度器事件。请参阅第4章“可观测性工具”中的第4.4节“SystemTap”,以及附录E,以获取将前面的DTrace脚本转换的帮助。
6.6.12 perf
最初称为Linux性能计数器(PCL),perf(1)命令已经发展演变成了一套用于性能分析和跟踪的工具集,现在被称为Linux性能事件(LPE)。每个工具都作为一个子命令进行选择。例如,perf stat执行stat命令,提供基于CPC的统计信息。这些命令在USAGE消息中列出,下表列出了其中的一部分(来自版本3.2.6-3)。
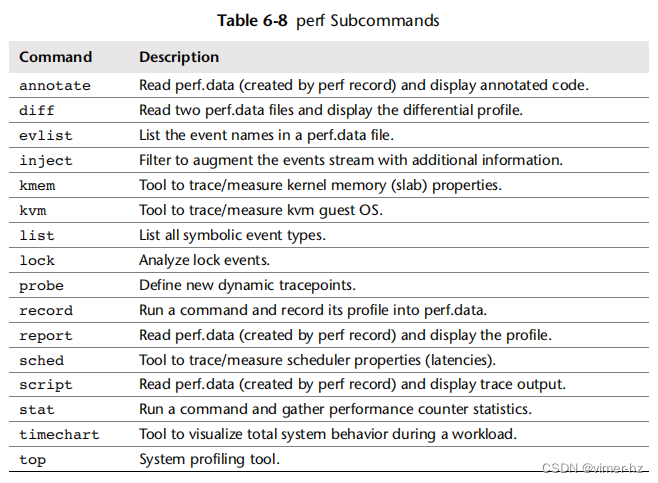
关键命令在接下来的章节中进行演示。
System Profiling
perf(1)可以用于对CPU调用路径进行性能分析,总结CPU时间在内核空间和用户空间中的消耗情况。这是通过record命令执行的,该命令以固定间隔捕获样本并保存到一个perf.data文件中。然后使用report命令查看该文件。
在下面的示例中,所有CPU(-a)以997Hz (-F 997)的速率对调用堆栈(-g)进行采样,持续10秒(sleep 10)。使用--stdio选项打印所有输出,而不是以交互模式运行。
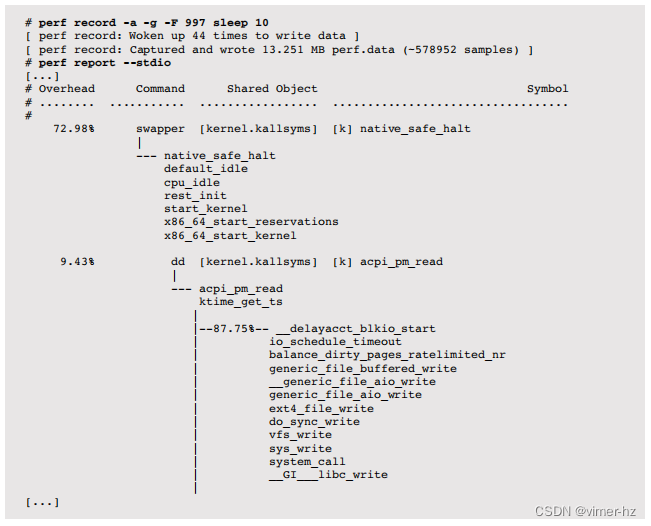
完整输出非常长,按降序样本计数顺序排列。这些样本计数以百分比形式给出,显示了CPU时间的消耗情况。这个示例表明,72.98% 的时间花费在空闲线程上,9.43% 的时间花费在 dd 进程上。在这9.43%中,87.5% 是由所示的堆栈组成,用于 ext4_file_write()。
这些内核和进程符号仅在其调试信息文件可用时才可用;否则将显示十六进制地址。
perf(1)通过为CPU循环计数器编程溢出中断来运行。由于现代处理器的周期频率变化,使用一个保持恒定的“缩放”计数器。
Process Profiling
除了跨所有CPU进行性能分析外,还可以针对单个进程进行操作。以下命令执行该命令并创建perf.data文件:

与之前一样,在查看报告时,perf(1)需要可用的调试信息来转换符号。
Scheduler Latency
sched命令记录并报告调度器的统计信息。例如:
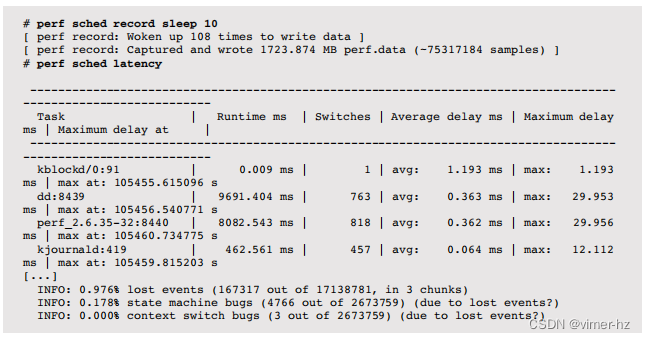
这显示了跟踪过程中的平均调度延迟和最大调度延迟。调度器事件频繁发生,因此这种类型的跟踪会带来CPU和存储开销。在这个示例中,进行10秒跟踪所生成的perf.data文件大小为1.7 GB。输出中的INFO行显示有一些事件被丢弃。这指出了DTrace模型在内核中进行过滤和聚合的优势:它可以在跟踪过程中总结数据,并仅将摘要传递到用户空间,从而最大限度地减少开销。
stat
stat命令基于CPC提供了CPU周期行为的高级摘要。在以下示例中,它启动了一个gzip(1)命令:
这些统计数据包括循环计数、指令计数以及IPC(CPI的倒数)。正如前面所述,这是一个非常有用的高级指标,可以确定发生的循环类型以及其中有多少是停顿循环。以下列出了其他可以检查的计数器:
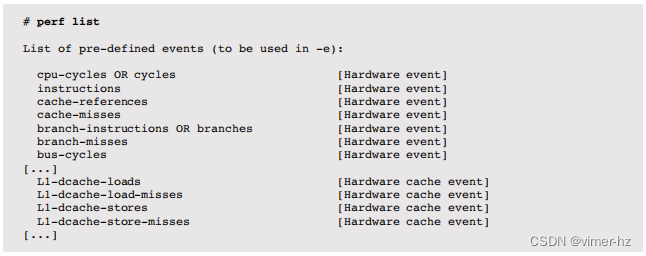
查找“硬件事件”和“硬件缓存事件”。可用的事件取决于处理器架构,并在处理器手册(例如,Intel软件开发人员手册)中有详细说明。这些事件可以使用-e参数进行指定。例如(以下示例来自Intel Xeon处理器):
除了指令和周期之外,这个示例还测量了以下内容:
L1-dcache-load-misses:一级数据缓存加载未命中。这可以衡量应用程序由于一些加载操作从一级缓存返回后引起的内存加载。可以与其他一级事件计数器进行比较,以确定缓存命中率。
LLC-load-misses:最后一级缓存加载未命中。在最后一级缓存之后,访问主内存,因此这是主内存加载的度量。LLC-load-misses与L1-dcache-load-misses之间的差异(其他计数器需要用于完整性)可以给出CPU缓存在一级缓存以外的效果的一个概念。
dTLB-load-misses:数据转换查找缓冲器未命中。这显示了MMU缓存页面映射对工作负载的有效性,并可以度量内存工作负载(工作集)的大小。
还可以检查许多其他计数器。perf(1)支持使用描述性名称(例如本示例中使用的名称)和十六进制值。对于在处理器手册中找到的奇特计数器,可能需要使用后者,因为没有提供描述性名称。
注意:翻译时请遵循中国法律法规,不得提及敏感政治话题。
Software Tracing
perf record -e可以与各种软件插装点一起使用,用于跟踪内核调度程序的活动。这些包括软件事件和跟踪点事件(静态探针),可以通过perf list列出。例如:

以下示例使用上下文切换软件事件来跟踪应用程序何时离开CPU,并在10秒内收集调用堆栈:
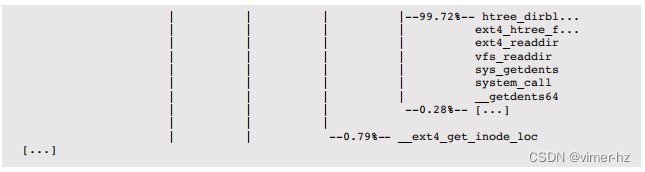
这个截断的输出展示了两个应用程序,perl和tar,以及它们在上下文切换时的调用堆栈。从堆栈中可以看出,tar程序正在进行文件系统(ext4)读取时处于睡眠状态。perl程序由于执行大量的计算任务而被非自愿地上下文切换,尽管单凭这个输出无法清楚地看出这一点。使用sched跟踪点事件可以找到更多信息。内核调度器函数也可以直接使用动态跟踪点(动态跟踪)进行跟踪,与静态探针一起,可以提供类似于之前从DTrace中看到的数据,尽管可能需要更多的后处理才能产生您所需的结果。
第9章“磁盘”中包括使用perf(1)进行静态跟踪的另一个示例:块I/O跟踪点。第10章“网络”中包含了使用perf(1)对tcp_sendmsg()内核函数进行动态跟踪的示例。
Documentation
有关更多关于perf(1)的信息,请参阅其man页面,在Linux内核源代码中tools/perf/Documentation下的文档,“Perf Tutorial”以及“The Unofficial Linux Perf Events Web-Page”。
6.6.13 cpustat
在基于Solaris的系统上,用于检查CPC的工具有cpustat(1M)用于系统范围分析,cputrack(1M)用于进程分析。这些工具使用性能仪器计数器(PICs)一词来指代CPC。
例如,要测量CPI,必须同时计算周期数和指令数。
使用PAPI名称:
cpustat(1M)每个CPU生成一行输出。可以对此输出进行后处理(例如,使用awk),以便进行CPI计算。
使用sys标记,以便同时计算用户模式和内核模式的周期数。
这设置了第6.4.1节“硬件”中描述的CPU性能计数器标志。
使用特定于平台的事件名称测量相同的计数器:
![]()
运行cpustat -h以获取处理器支持的计数器的完整列表。输出通常以对供应商处理器手册的引用结束;例如:
请参阅“Intel 64和IA-32体系结构软件开发人员手册第3B卷:系统编程指南,第2部分”附录A,订货号:253669-026US,2008年2月。
这些手册详细描述了处理器的低级行为。
在同一时间内系统上只能运行一个cpustat(1M)实例,因为内核不支持多路复用。
6.6.14 Other Tools
其他Linux CPU性能工具包括:
- oprofile:John Levon开发的最初的CPU分析工具。
- htop:包括CPU使用情况的ASCII条形图,并且比原始的top(1)工具具有更强大的交互界面。
- atop:包含更多系统范围的统计信息,并使用进程记账来捕获短生命周期进程的存在。
- /proc/cpuinfo:可以读取此文件以查看处理器的详细信息,包括时钟速度和特性标志。
- getdelays.c:这是一个延迟记账可观察性的示例,并包括每个进程的CPU调度器延迟。在第4章“可观察性工具”中进行了演示。
- valgrind:一个内存调试和分析工具包,其中包含callgrind工具用于跟踪函数调用并收集调用图,可以使用kcachegrind进行可视化;还有cachegrind用于分析给定程序对硬件缓存的使用情况。
对于Solaris系统:
- lockstat/plockstat:用于锁分析,包括自适应互斥锁的自旋锁和CPU消耗(参见第5章“应用程序”)。
- psrinfo:处理器状态和信息(-vp选项)。
- fmadm faulty:用于检查是否由于可纠正的ECC错误增加而对CPU进行预测性故障。还可以参考fmstat(1M)。
- isainfo -x:列出处理器特性标志。
- pginfo、pgstat:处理器组统计信息,显示CPU拓扑和CPU资源共享情况。
- lgrpinfo:用于本地性组统计信息。这对于检查lgrps是否正在使用(需要处理器和操作系统支持)可能很有用。
还有一些复杂的CPU性能分析产品,包括Oracle Solaris Studio,适用于Solaris和Linux系统。
6.6.15 Visualizations
CPU使用率在历史上通常被可视化为利用率或负载平均值的折线图,包括最初的X11负载工具(xload(1))。这些折线图是显示变化的有效方式,因为可以通过视觉比较幅度。它们还可以显示随时间变化的模式,正如第2章“方法论”的第2.9节“监控”中所示。
然而,每个CPU利用率的折线图无法随着今天所见到的CPU数量扩展,特别是对于涉及数万个CPU的云计算环境——10000条线的图表可能会变得混乱不堪。
其他以折线图形式绘制的统计数据,包括平均值、标准差、最大值和百分位数,提供了一些价值并且可以扩展。然而,CPU利用率通常是双峰的——由空闲或接近空闲的CPU组成,然后一些CPU的利用率达到100%——这些统计数据无法有效传达这种情况。通常需要研究完整的分布情况。利用率热图使这成为可能。
接下来的部分介绍CPU利用率热图、CPU亚秒偏移热图和火焰图。我创建这些可视化类型来解决企业和云性能分析中的问题。
Utilization Heat Map
利用率随时间的变化可以呈现为热图,每个像素的饱和度(深浅)显示了在该利用率和时间范围内的CPU数量。热图是在第2章“方法论”中介绍的。
图6.15展示了整个数据中心(可用区)的CPU利用率,该数据中心运行着一个公共云环境。它包括超过300台物理服务器和5312个CPU。
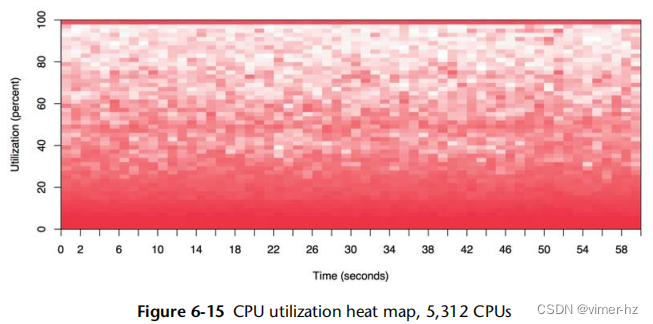
在这个热图的底部较暗的阴影显示大多数CPU的利用率在0%到30%之间。然而,顶部的实线显示随着时间的推移,也有一些CPU的利用率达到100%。实线颜色较深表明不止一个CPU达到了100%利用率。
这种特定的可视化是由实时监控软件(Joyent Cloud Analytics)提供的,该软件允许通过点击选择点以显示更多细节。在这种情况下,可以点击100%的CPU线以显示这些CPU所属的服务器,以及驱动CPU达到此利用率的租户和应用程序。
Subsecond-Offset Heat Map
这种热图类型允许检查每秒内的活动情况。CPU活动通常以微秒或毫秒为单位进行测量;将这些数据报告为整秒的平均值可能会丢失有用的信息。这种热图将亚秒偏移放在y轴上,每个偏移处的非空闲CPU数量由饱和度表示。这样可以将每秒可视化为一列,并从底部到顶部进行"绘制"。
图6.16展示了一个云数据库(Riak)的CPU亚秒偏移热图。这个热图的有趣之处不在于CPU忙于为数据库提供服务的时间,而是那些未忙碌的时间,这些时间通过白色的列来表示。这些间隔的持续时间也很有趣:在这段时间内,数据库线程没有一个处于CPU上,持续了数百毫秒。这导致发现了一个锁定问题,导致整个数据库每次被阻塞数百毫秒。
如果我们使用折线图来检查这些数据,每秒CPU利用率的下降可能会被视为可变负载并且不会进一步调查。
Flame Graphs
分析堆栈跟踪是解释CPU使用率的有效方法,可以显示哪些内核或用户级别的代码路径是负责的。然而,它可能会产生数千页的输出。火焰图可视化了配置文件中的堆栈帧,以便更快、更清晰地理解CPU使用情况。
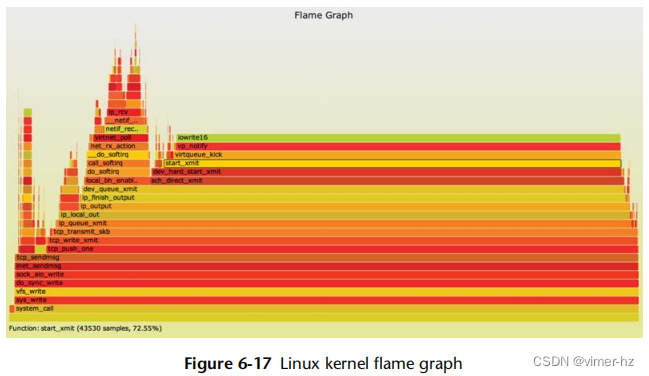
火焰图可以基于DTrace、perf或SystemTap的数据构建。图6.17的示例展示了使用perf对Linux内核进行配置文件分析的情况。
火焰图具有以下特点:
- 每个方框代表堆栈中的一个函数(一个"堆栈帧")。
- y轴显示堆栈深度(堆栈上的帧数)。顶部的方框显示正在运行的函数,其下方是祖先函数。一个函数的下方是其父函数,就像之前显示的堆栈跟踪一样。
- x轴跨越采样数据集。它不显示从左到右的时间流逝,与大多数图表不同。左到右的排序没有意义(按字母顺序排序)。
- 方框的宽度显示它在CPU上或作为CPU上祖先的一部分所花费的总时间(基于采样计数)。宽的方框函数可能比窄的方框函数慢,或者它们可能只是被更频繁地调用。调用计数不显示(也无法通过采样获知)。
- 如果有多个线程并行运行和采样,采样计数可能超过经过的时间。
- 颜色没有实际意义,并且是随机选择的温暖色调。它被称为"火焰图",因为它显示了在CPU上的热点。
火焰图也是交互式的。它是一个包含嵌入式JavaScript程序的SVG文件,在浏览器中打开后,可以将鼠标悬停在元素上以在底部显示详细信息。在图6.17的示例中,highlighted的是start_xmit()函数,显示它在采样堆栈中出现了72.55%的次数。
6.7 Experimentation
这一部分介绍了用于主动测试CPU性能的工具。有关背景信息,请参阅第6.5.11节“微基准测试”。
在使用这些工具时,建议保持mpstat(1)持续运行,以确认CPU使用率和并行性。
6.7.1 Ad Hoc
虽然这很琐碎且不会测量任何东西,但它可以作为一个有用的已知工作负载,用于确认可观察性工具所显示的内容是否与其声称的一致。这将创建一个CPU密集型的单线程工作负载(“在一个CPU上高负荷”):

这是一个Bourne shell程序,在后台执行一个无限循环。一旦不再需要它,就需要将其终止。
6.7.2 SysBench
SysBench系统基准套件具有一个简单的CPU基准测试工具,用于计算素数。例如:
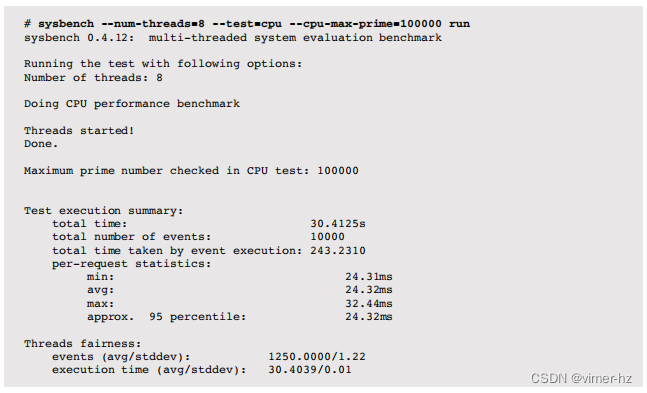
这个命令使用了八个线程,最大素数为100,000。运行时间为30.4秒,可以与其他系统或配置的结果进行比较(假设许多条件相同,如使用相同的编译器选项构建软件;请参阅第12章“基准测试”)。
6.8 Tuning
对于CPU来说,通常能够带来最大性能提升的是消除不必要的工作,这是一种有效的优化方式。第6.5节“方法论”和第6.6节“分析”介绍了许多分析和识别执行的工作的方法,帮助您找出任何不必要的工作。还介绍了其他调优方法:优先级调优和CPU绑定。本节包括这些以及其他调优示例。
调优的具体内容——可用的选项以及如何设置它们——取决于处理器类型、操作系统版本和预期工作负载。以下按类型组织提供了一些可能可用的选项以及它们的调优示例。前面的方法论部分提供了关于何时以及为什么要调优这些可调整参数的指导。
6.8.1 Compiler Options
编译器以及它们为代码优化提供的选项可以对CPU性能产生显著影响。常见的选项包括选择64位而不是32位进行编译,并选择一定程度的优化。编译器优化在第5章“应用程序”中有所讨论。
6.8.2 Scheduling Priority and Class
nice(1)命令可用于调整进程优先级。正nice值降低优先级,负nice值增加优先级,只有超级用户可以设置。取值范围为-20到+19。例如:
![]()
使用nice值为19的命令 - 这是nice可以设置的最低优先级。要更改已经运行进程的优先级,请使用renice(1)命令。
在Linux上,chrt(1)命令可以直接显示和设置调度优先级以及调度策略。调度优先级也可以使用setpriority()系统调用直接设置,并且优先级和调度策略可以使用sched_setscheduler()系统调用设置。
在Solaris上,您可以使用priocntl(1)命令直接设置调度类和优先级。例如:
![]()
这将将目标进程ID设置为以实时调度类运行,优先级为10。在设置此项时要小心:如果实时线程消耗了所有的CPU资源,可能会导致系统死机。
6.8.3 Scheduler Options
您的内核可能会提供可调参数来控制调度程序行为,尽管这些参数可能永远不需要调整。在Linux系统上,可以设置配置选项,包括从3.2.6内核中的表6.9中的示例,使用的是Fedora 16的默认值。
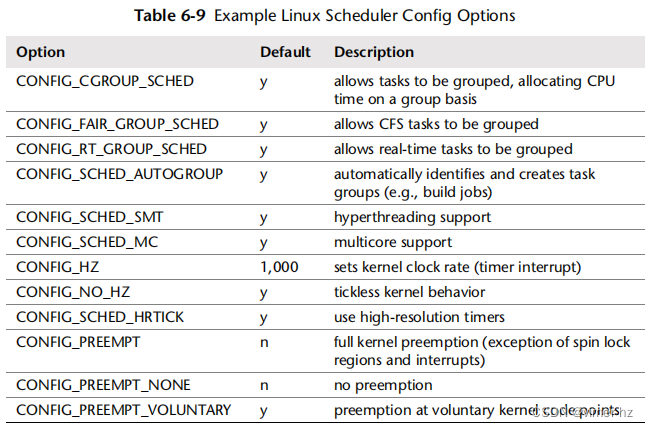
一些Linux内核提供额外的可调参数(例如,在/proc/sys/sched中)。在基于Solaris的系统上,表6.10中显示的内核可调参数修改调度程序行为。作为参考,找到您操作系统版本的相应文档(例如,对于Solaris,是Solaris可调参数参考手册)。这样的文档应该列出关键的可调参数、它们的类型、何时设置它们、它们的默认值以及有效范围。在使用这些参数时要小心,因为它们的范围可能没有经过充分测试。(根据公司或供应商政策,可能也禁止调整它们。)
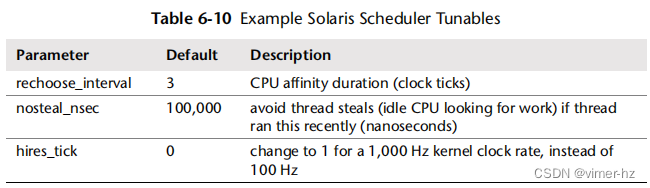
Scheduler Class Tuning
基于Solaris的系统还提供了一种通过dispadmin(1)命令修改调度类别使用的时间量和优先级的方式。例如,可以打印出用于时间共享调度类别(TS)的可调参数表(称为调度程序表):
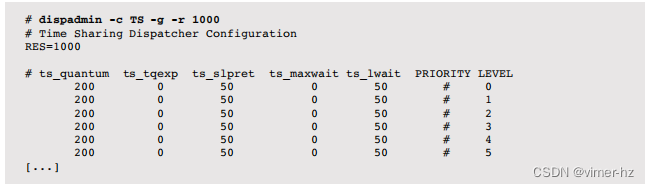
这个输出包括:
- ts_quantum:时间量子(以毫秒为单位,使用 -r 1000 来设置分辨率)
- ts_tqexp:线程使用完当前时间量子后提供的新优先级(降低优先级)
- ts_slpret:线程休眠后(I/O)唤醒后的新优先级(优先级提升)
- ts_maxwait:在晋升到 ts_lwait 中的优先级之前等待 CPU 的最长时间(以秒为单位)
- 优先级级别:优先级值
这些内容可以写入文件,进行修改,然后通过 dispadmin(1M)重新加载。您应该有充分理由这样做,比如首先使用 DTrace 测量优先级争用和调度程序延迟。
6.8.4 Process Binding
一个进程可以绑定到一个或多个CPU,这可能会通过提高缓存热度和内存局部性来提高其性能。在Linux上,可以使用taskset(1)命令来执行此操作,它可以使用CPU掩码或范围来设置CPU亲和性。例如:

这将 PID 10790 设置为仅在 CPU 7 到 10 上运行。
在基于Solaris的系统上,可以使用 pbind(1) 来执行此操作。例如:

这将 PID 11901 设置为在 CPU 10 上运行。无法指定多个CPU。要实现类似的功能,请使用独占的CPU集合。
6.8.5 Exclusive CPU Sets
Linux提供了cpusets,允许将CPU分组并将进程分配给它们。这类似于进程绑定,可以改善性能,但通过使cpuset独占,性能可以进一步提高 — 防止其他进程使用它。权衡是系统中可用CPU的减少。
以下是一个注释示例,创建一个独占集合:
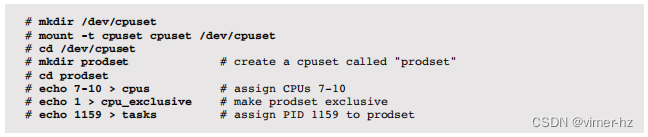
有关详细信息,请参阅cpuset(7)手册页。
在Solaris上,您可以使用psrset(1M)命令创建独占的CPU集合。
6.8.6 Resource Controls
除了将进程与整个CPU关联起来,现代操作系统还提供了资源控制,用于对CPU使用量进行精细化分配。
基于Solaris的系统具有用于进程或进程组的资源控制(从Solaris 9开始引入),称为项目。使用公平份额调度程序和份额,可以灵活地控制CPU使用情况,这些控制方式决定了空闲CPU如何被需要的人消耗。还可以设定限制,以控制总CPU利用率,用于那些一致性比份额的动态行为更可取的情况。
对于Linux,有容器组(cgroups),也可以通过进程或进程组来控制资源使用。可以使用份额来控制CPU使用情况,CFS调度程序允许设定固定限制(CPU带宽),即按照每个间隔分配微秒的CPU周期。CPU带宽是相对较新的功能,自2012年(3.2版)开始添加。
《云计算》第11章描述了管理OS虚拟化租户的CPU使用情况的用例,包括如何同时使用份额和限制。
6.8.7 Processor Options (BIOS Tuning)
处理器通常提供设置来启用、禁用和调整处理器级功能。在x86系统上,这些设置通常在启动时通过BIOS设置菜单访问。
这些设置通常默认提供最大性能,不需要进行调整。我今天调整这些设置最常见的原因是为了禁用Intel Turbo Boost,以便CPU基准测试以一致的时钟速率执行(请注意,对于生产使用,Turbo Boost 应该启用以获得稍微更快的性能)。