一文掌握YOLOv13最新特性
1、引言
小屌丝:雨哥,你看这是啥
小鱼:没时间啊, 我再看别的呢
小屌丝:看一下,就看一眼
小鱼:不看不看,没得时间
小屌丝:确定,如果不看的话,那我可找小云看了哦
小鱼:… 那我看一下
小屌丝:好嘞,你看

小鱼:… 这个我看过啊
小屌丝:你既然看过了, 那就给我讲一讲呗
小鱼:哪有时间啊哥哥
小屌丝:挤一挤,就有了
小鱼:…什么挤一挤就有了
小屌丝:… 你说嘞?
小鱼:讲! ! !
2、Yolov13详细讲解
2.1 发布时间与背景
YOLOv13由清华大学联合太原理工大学、北京理工大学等高校团队于2025年6月26日正式发布。作为YOLO系列的最新成员,其核心目标是解决复杂场景下目标检测的鲁棒性问题。
传统YOLO模型受限于局部信息聚合和成对相关性建模,难以捕捉多目标间的高阶语义关联(如遮挡、密集目标等场景)。
YOLOv13通过引入超图理论和轻量化设计,在MS COCO数据集上以6.4G FLOPs的Nano版本实现41.6% mAP,较YOLOv12-Nano提升1.5%精度,同时参数量减少0.1M
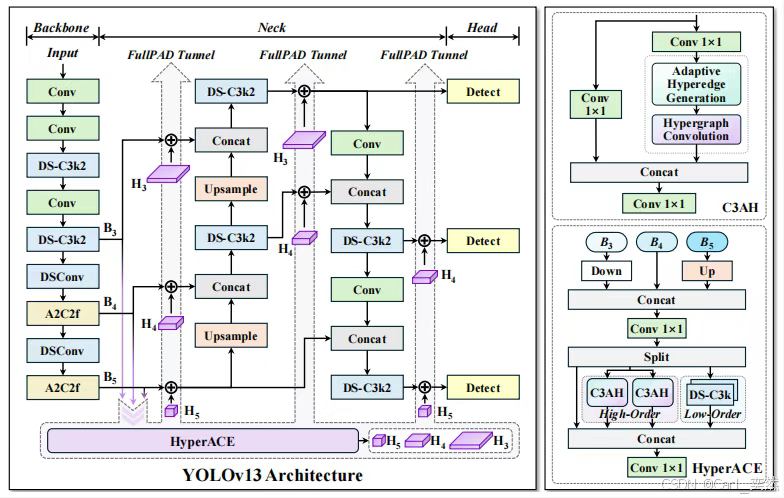
2.2 相对于YOLOv12的核心提升
2.2.1 精度显著提升
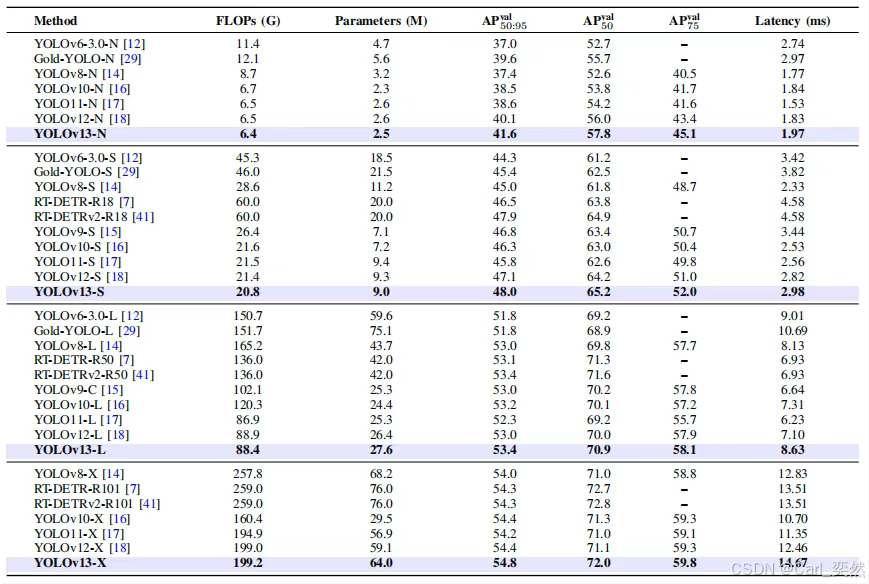
Nano模型(YOLOv13-N)mAP达41.6%,较v12-N提升1.5%;Small模型(v13-S)mAP达48.0%,较v12-S提升0.9%。
小目标检测AP提升2.2%,遮挡场景鲁棒性增强。
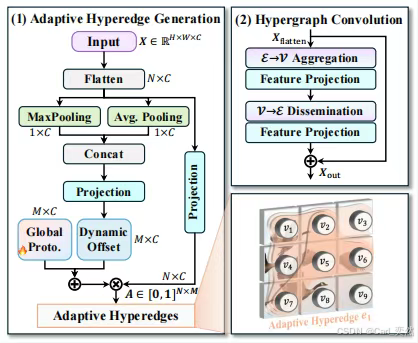
2.2.2 轻量化与效率优化
采用深度可分离卷积(DSConv)替代传统大核卷积,计算量降低20%。
Nano模型参数量仅2.5M,在Intel Xeon CPU上推理速度达25 FPS。
2.2.3 高阶语义建模能力
突破传统注意力机制的二元关联限制,首次实现多对多目标关系建模(如“滑雪者+雪橇+雪杖”的组合场景)
2.3 架构设计与核心创新
2.3.1 超图自适应关联增强(HyperACE)
超图结构构建:将特征图像素视为超图顶点,通过可学习超边动态连接多个顶点(如同时关联“餐桌上的盘子、刀叉、水杯”),建模高阶语义关系。
双分支协同:
高阶全局分支:基于C3AH模块实现跨空间位置的高阶语义聚合(线性复杂度消息传递)。
低阶局部分支:DS-C3k模块提取细粒度纹理特征
# HyperACE模块伪代码
class HyperACE(nn.Module):
def __init__(self):
self.global_branch = C3AH() # 超图全局建模
self.local_branch = DS_C3k() # 局部分支
self.shortcut = nn.Identity()
def forward(self, x):
return self.global_branch(x) + self.local_branch(x) + self.shortcut(x)
2.3.2 全流程聚合-分发(FullPAD)
三隧道特征分发:通过三条独立路径将HyperACE增强特征定向传递至:
- 骨干网与颈部连接处
- 颈部网络内部
- 颈部与检测头连接处
协同效应:打破传统单向信息流,实现环形梯度传播,梯度传递效率提升40%,mAP最高提升3%。
2.3.3 轻量化模块设计
DS系列模块:使用DS-C3k2替换大核卷积,将标准卷积分解为深度卷积 + 逐点卷积,在保持感受野的同时减少计算量。
模型规模适配:支持Nano/Small/Large/Extra四种规格,满足边缘设备到服务器部署需求
2.4 性能对比
下表为MS COCO val2017数据集上的关键指标对比
| 模型 | FLOPs(G) | Params(M) | AP₅₀:₉₅ | 推理延迟(ms) |
|---|---|---|---|---|
| YOLOv12-Nano | 6.5 | 2.6 | 40.1 | 1.83 |
| YOLOv13-Nano | 6.4 | 2.5 | 41.6 | 1.97 |
| YOLOv12-Small | 21.4 | 9.3 | 47.1 | 2.82 |
| YOLOv13-Small | 20.8 | 9.0 | 48.0 | 2.98 |
2.4 代码示例
2.4.1 环境配置
conda create -n yolov13 python=3.11
conda activate yolov13
pip install torch==2.2.0 cu118 -f https://download.pytorch.org/whl/torch_stable.html
pip install ultralytics flash-attn
2.4.2 训练代码
from ultralytics import YOLO
# 加载预训练模型(支持n/s/l/x四种规模)
model = YOLO('yolov13s.pt')
# 训练配置
model.train(
data='coco.yaml',
epochs=600,
batch=256, # 根据GPU显存调整
imgsz=640,
scale=0.5, # L/X模型建议0.7/0.5
mixup=0.05, # 数据增强强度
hyperace_edges=32 # 超边数量(Nano模型建议16,Small建议32)
)
2.4.3 推理与部署
# 图像检测
results = model.predict(source='image.jpg', conf=0.5)
# 导出TensorRT引擎(需GPU支持)
model.export(format="engine", half=True, dynamic=True)
# CPU部署(OpenVINO)
model.export(format="openvino", imgsz=(640, 640))
3、总结
YOLOv13通过HyperACE机制实现了复杂场景的高阶语义建模,FullPAD范式重构了信息流路径提升梯度效率,深度可分离卷积则在精度与效率间取得平衡。
尽管存在超边数量需手动调参、训练轮数敏感等局限,其仍是实时目标检测领域的重要突破。未来可探索超边自适应生成、跨任务扩展(如实例分割)等方向。
我是小鱼:
- CSDN 博客专家;
- 阿里云 专家博主;
- 51CTO博客专家;
- 企业认证金牌面试官;
- 多个名企认证&特邀讲师等;
- 名企签约职场面试培训、职场规划师;
- 多个国内主流技术社区的认证专家博主;
- 多款主流产品(阿里云等)评测一等奖获得者;
关注小鱼,学习【机器视觉与目标检测】最新最全的领域知识。