目 录
一、实验目的
1. 掌握使用 Spark 访问本地文件和 HDFS 文件的方法。
2. 掌握 Spark 应用程序的编写、编译和运行方法。
二、实验环境
1. 硬件要求:笔记本电脑一台
2. 软件要求:VMWare虚拟机、Ubuntu 18.04 64、JDK1.8、Hadoop-3.1.3、Hive-3.1.2、Windows11操作系统、Eclipse、Flink-1.9.1、IntelliJ IDEA、Spark-2.4.0
三、实验内容与完成情况
3.1 Spark读取文件系统的数据。
在 Linux 系统中安装 IntelliJ IDEA,然后使用 IntelliJ IDEA 工具开发 WordCount 程序,并打 包成JAR 文件,提交到 Flink 中运行。
(1)在 spark-shell 中读取 Linux 系统本地文件“/home/hadoop/test.txt”,然后统计出文件的行数。
①下载spark压缩包并使用如下语句将对应的压缩包解压到/usr/local的文件目录下:
sudo tar -zxf ./spark-2.4.0-bin-without-hadoop.tgz -C /usr/local
②使用如下语句将解压后的文件夹“spark-2.4.0-bin-without-hadoop”重命名为“spark”:
sudo mv ./spark-2.4.0-bin-without-hadoop/ ./spark

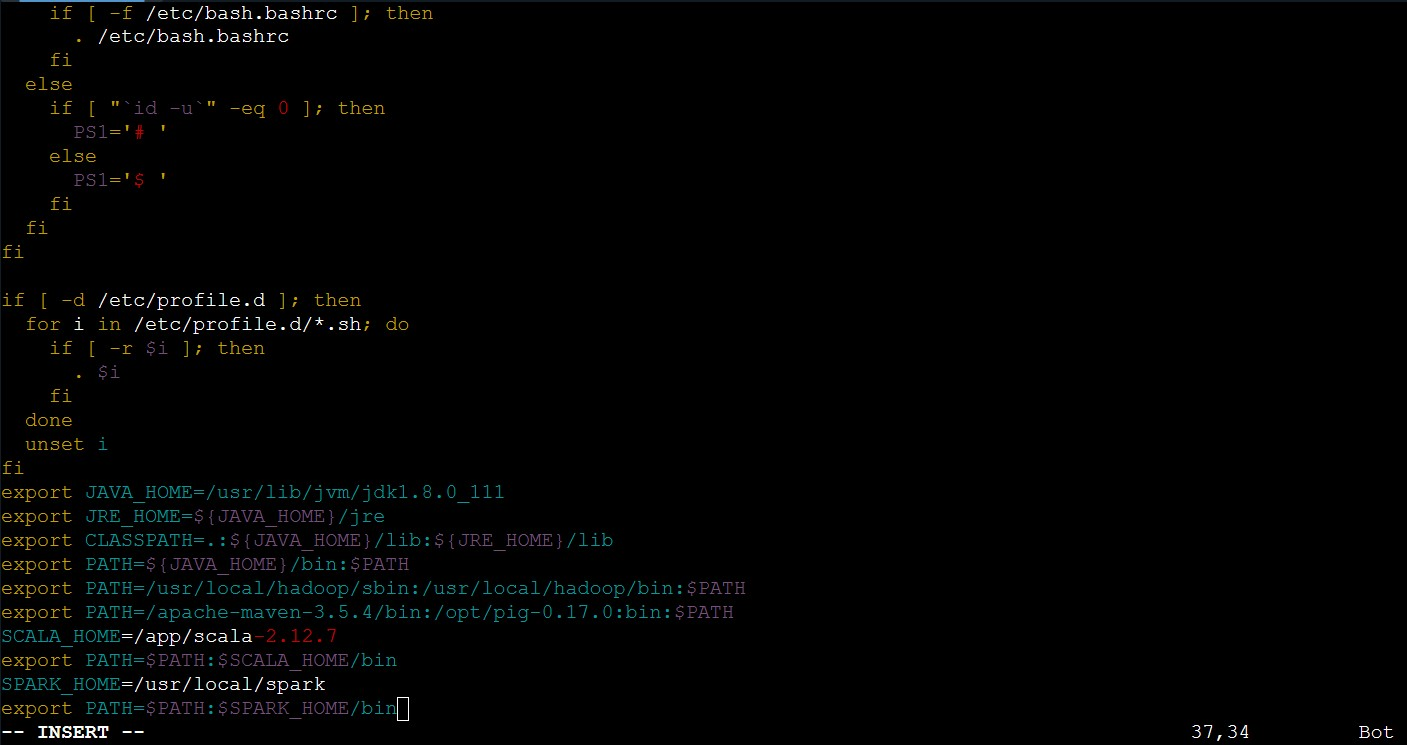
③使用如下语句修改spark的配置文件信息:
vim /etc/profile
④使用如下语句让刚修改完的配置信息立即生效:
source /etc/profile

⑤使用如下语句复制"spark-env.sh.template"文件的内容并将其存入到"spark-env.sh"文件中:
cp spark-env.sh.template spark-env.sh

⑥使用如下语句启动spark进行实验操作:
./sbin/start-all.sh

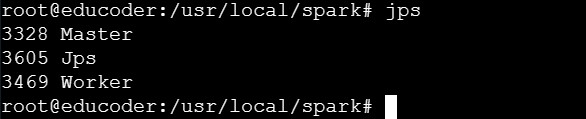
⑦使用如下语句进行进程信息查看:
jps
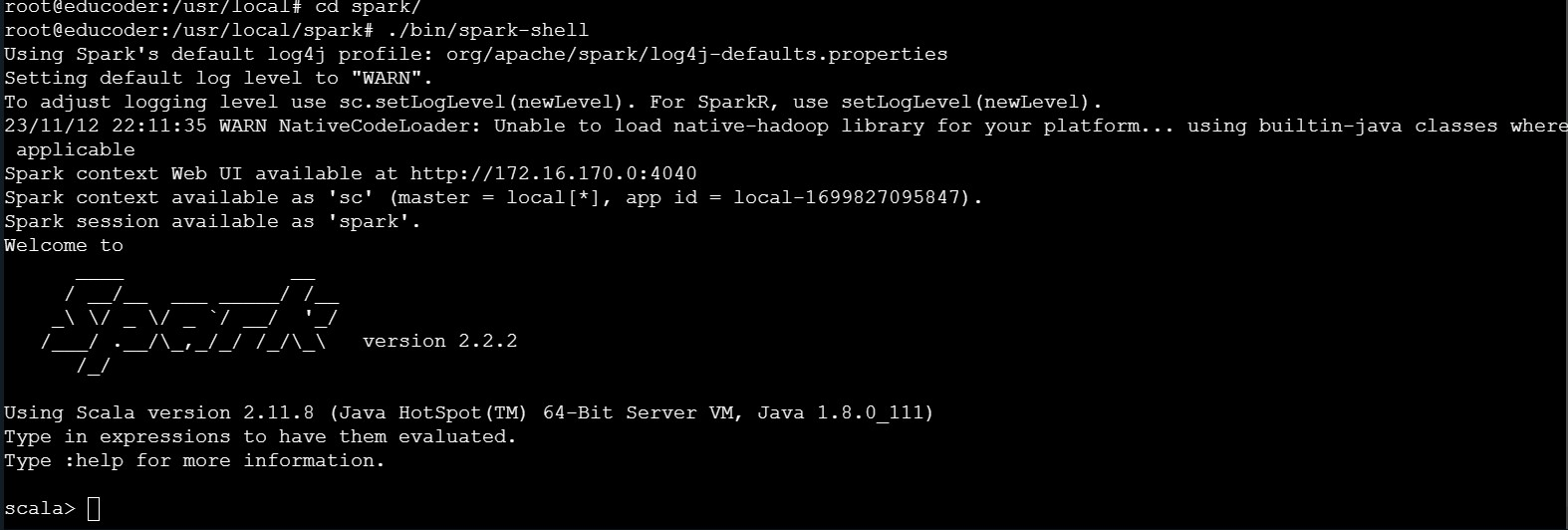
⑧使用如下语句完成spark-shell的启动工作:
./bin/spark-shell
⑨使用如下语句读取 Linux 系统本地文件“/home/hadoop/test.txt”:
cd /home/hadoop/test.txtval textFile=sc.textFile("file:///home/hadoop/test.txt")

⑩使用如下语句统计文件“/home/hadoop/test.txt”的行数:
textFile.count()

(2)在 spark-shell 中读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在, 请先创建),然后统计出文件的行数。
①使用如下语句在HDFS上传文件"1.txt",上传完成后并进行查看是否成功完成上传:
cd /usr/local/hadoophadoop fs -lshadoop fs -put 1.txthadoop fs -ls
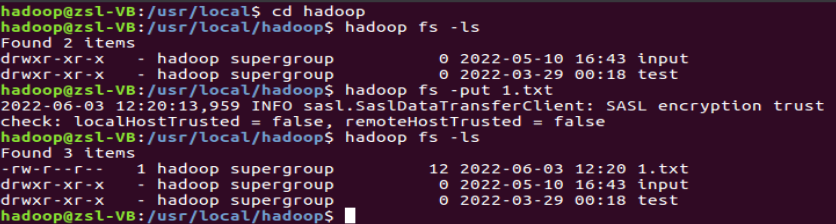
②使用如下语句读取 Linux 系统HDFS系统文件“/user/hadoop/test.txt”:
val textFile=sc.textFile("hdfs://localhost:9000/user/hadoop/test.txt")

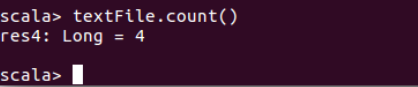
③使用如下语句统计HDFS系统文件“/user/hadoop/test.txt”的行数:
textFile.count()
(3)编写独立应用程序(推荐使用 Scala 语言),读取 HDFS 系统文件“/user/hadoop/test.txt”(如果该文件不存在,请先创建),然后统计出文件的行数;通过 sbt 工具将整个应用程 序编译打包成 JAR 包,并将生成的 JAR 包通过 spark-submit 提交到 Spark 中运行命令。
①使用hadoop用户名登录Linux系统,打开一个终端在Linux终端中执行如下命令创建一个文件夹sparkapp作为应用程序根目录:
cd ~mkdir ./sparkappmkdir -p ./sparkapp/src/main/scala

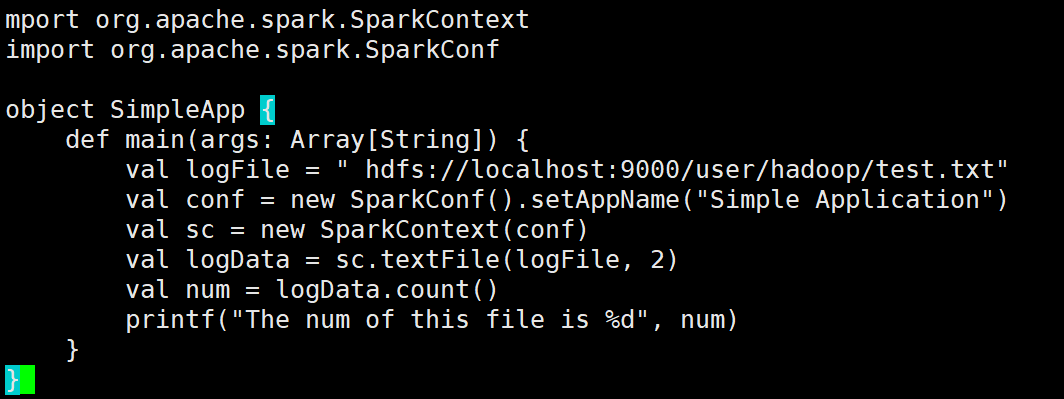
②将对应的应用程序代码存放在应用程序根目录下的“src/main/scala”目录下,使用vim编辑器在“~/sparkapp/src/main/scala”下建立一个名为 SimpleApp.scala的Scala代码文件:
import org.apache.spark.{SparkConf, SparkContext}
object SimpleApp {
def main(args: Array[String]) {
// 正确的路径:去掉路径字符串中的多余空格
val logFile = "hdfs://localhost:9000/user/hadoop/test.txt"
// 设置SparkConf
val conf = new SparkConf().setAppName("Simple Application")
// 初始化SparkContext
val sc = new SparkContext(conf)
// 读取文件并进行计算
val logData = sc.textFile(logFile, 2)
// 计算并输出文件的行数
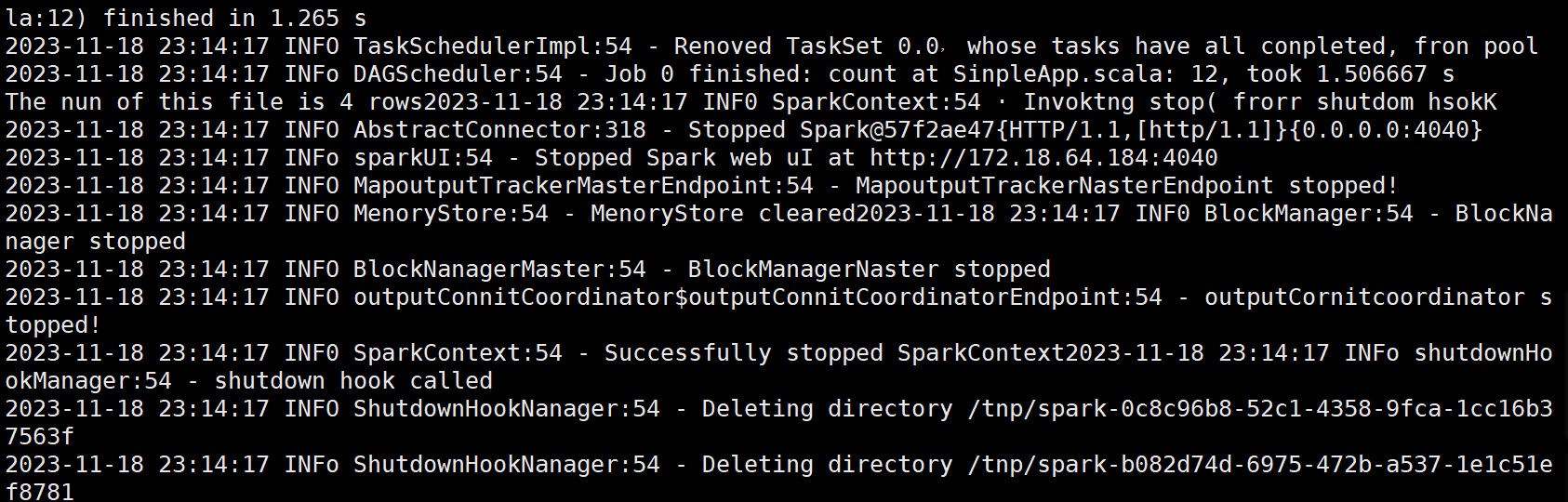
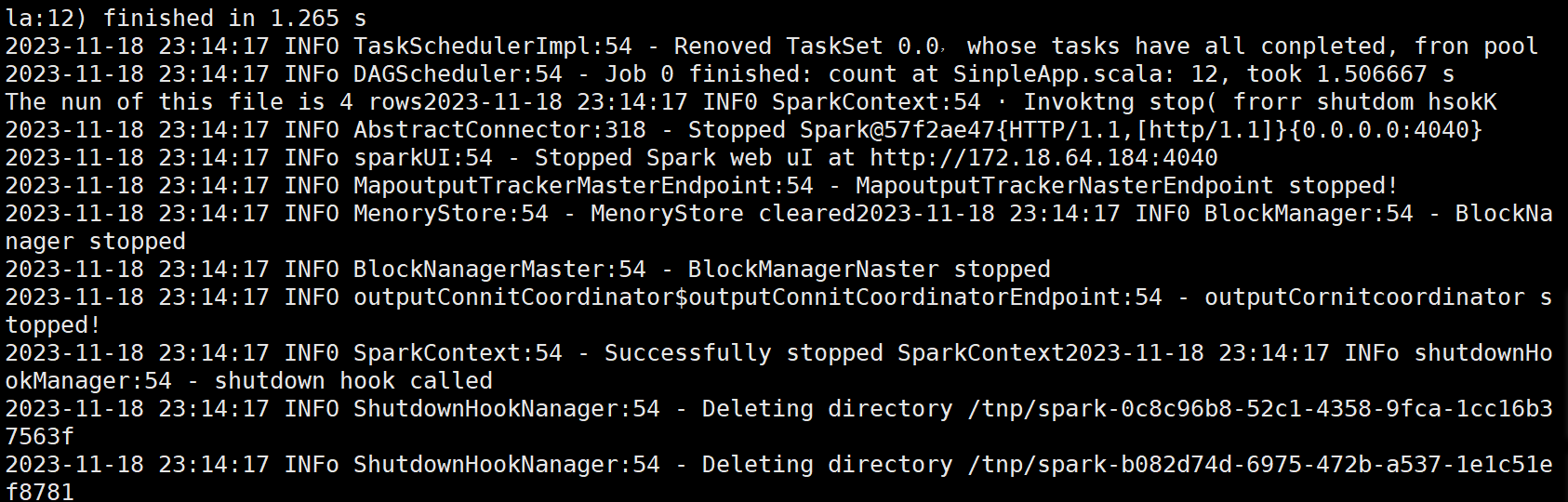
val num = logData.count()
printf("The num of this file is %d\n", num)
// 关闭SparkContext
sc.stop()
}
}
③SimpleApp.scala程序依赖于Spark API,因此需要通过sbt进行编译打包以后才能运行。 首先需要使用vim编辑器在“~/sparkapp”目录下新建文件simple.sbt:
cd ~vim ./sparkapp/simple.sbt

④simple.sbt文件用于声明该独立应用程序的信息以及与 Spark的依赖关系,需要在simple.sbt文件中输入以下内容:
name := "Simple Project"version := "1.0"scalaVersion := "2.11.12"libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"

⑤为了保证sbt能够正常运行,先执行如下命令检查整个应用程序的文件结构:
cd sparkapp/find .
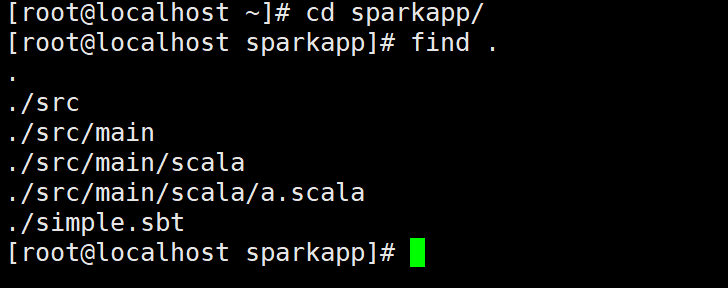
⑥通过如下代码将整个应用程序打包成 JAR:
/usr/local/sbt/sbt package
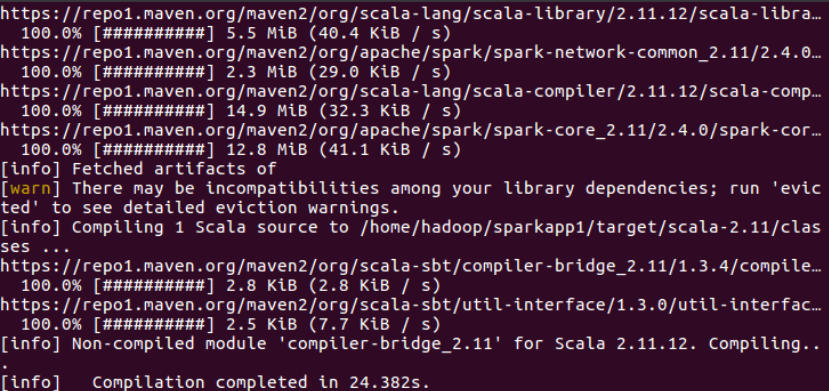
⑦生成的JAR包的位置为“~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar”,使用sbt打包得到的应用程序JAR包可以通过 spark-submit 提交到 Spark 中运行:
/usr/local/spark/bin/spark-submit --class "SimpleApp"~/sparkapp/target/scala-2.11/simple-project_2.11-1.0.jar
3.2 编写独立应用程序实现数据去重。
对于两个输入文件 A 和 B,编写 Spark 独立应用程序(推荐使用 Scala 语言),对两个 文件进行合并,并剔除其中重复的内容,得到一个新文件 C。下面是输入文件和输出文件的 一个样例供参考。
输入文件 A 的样例如下:
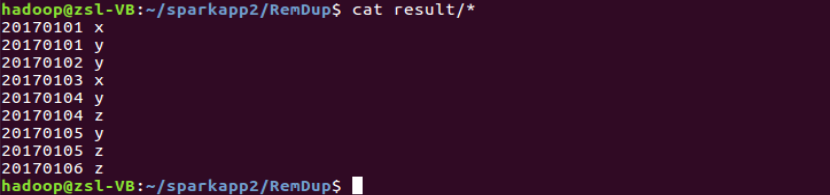
20170101 x20170102 y20170103 x20170104 y20170105 z20170106 z
输入文件 B 的样例如下:
20170101 y20170102 y20170103 x20170104 z20170105 y
根据输入的文件 A 和 B 合并得到的输出文件 C 的样例如下:
20170101 x20170101 y20170102 y20170103 x20170104 y20170104 z20170105 y20170105 z20170106 z
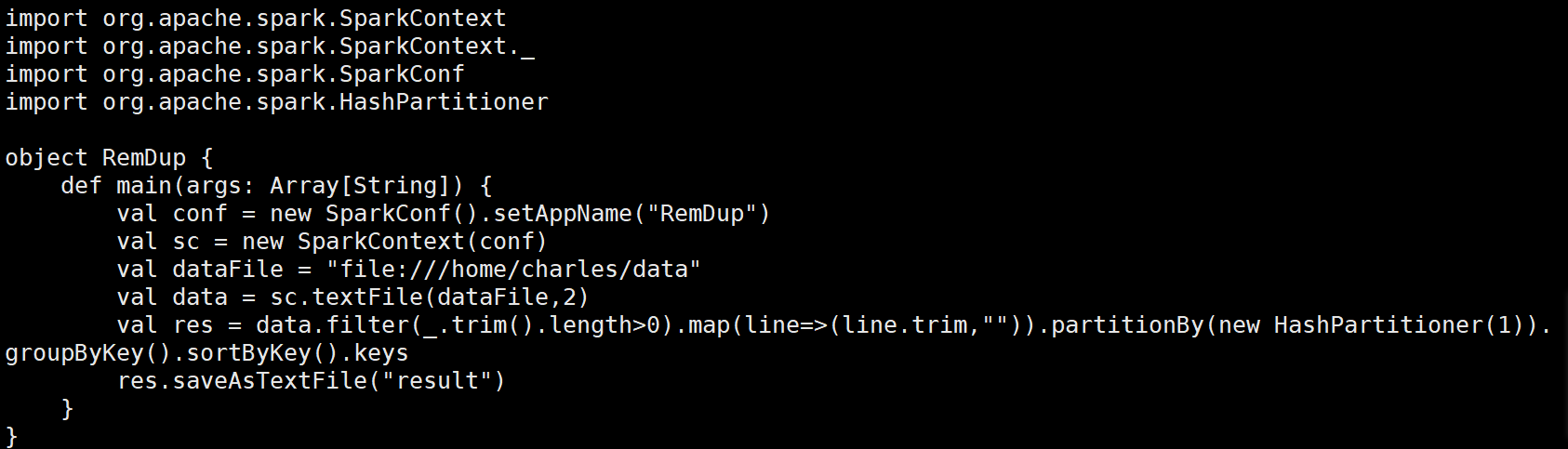
(1)在目录/usr/local/spark/mycode/remdup/src/main/scala下新建一个remdup.scala,然后输入如下代码:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.HashPartitioner
object RemDup {
def main(args: Array[String]) {
// 初始化SparkConf和SparkContext
val conf = new SparkConf().setAppName("RemDup")
val sc = new SparkContext(conf)
// 输入文件路径
val dataFile = "file:///home/charles/data"
// 读取文件并创建RDD,设置为2个分区
val data = sc.textFile(dataFile, 2)
// 处理数据:过滤空行,去除多余空格并进行分区和排序
val res = data
.filter(_.trim.length > 0) // 过滤空行
.map(line => (line.trim, "")) // 每行生成键值对(键为去除空格的行内容,值为空字符串)
.partitionBy(new HashPartitioner(1)) // 使用HashPartitioner进行分区
.groupByKey() // 根据键进行分组
.sortByKey() // 按照键进行排序
.keys // 只保留键(去除重复行)
// 将结果保存到文件
res.saveAsTextFile("result")
// 停止SparkContext
sc.stop()
}
}
(2)在目录/usr/local/spark/mycode/remdup目录下新建simple.sbt,然后输入如下代码:
name := "Simple Project"version := "1.0"scalaVersion := "2.11.12"libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"

(3)在目录/usr/local/spark/mycode/remdup下执行如下命令打包程序:
sudo /usr/local/sbt/sbt package

(4)最后在目录/usr/local/spark/mycode/remdup下执行如下命令提交程序,在目录/usr/local/spark/mycode/remdup/result下即可得到结果文件:
/usr/local/spark/bin/spark-submit --class "RemDup"/usr/local/spark/mycode/remdup/target/scala-2.11/simple-project_2.11-1.0.jar
3.3 编写独立应用程序实现求平局值问题。
每个输入文件表示班级学生某个学科的成绩,每行内容由两个字段组成,第一个是学生 名字,第二个是学生的成绩;编写 Spark 独立应用程序求出所有学生的平均成绩,并输出到 一个新文件中。下面是输入文件和输出文件的一个样例供参考。
Algorithm 成绩:
小明 92小红 87小新 82小丽 90
Database 成绩:
小明 95小红 81小新 89小丽 85
Python 成绩:
小明 82小红 83小新 94小丽 91
平均成绩如下:
( 小红 ,83.67)( 小新 ,88.33)( 小明 ,89.67)( 小丽 ,88.67)
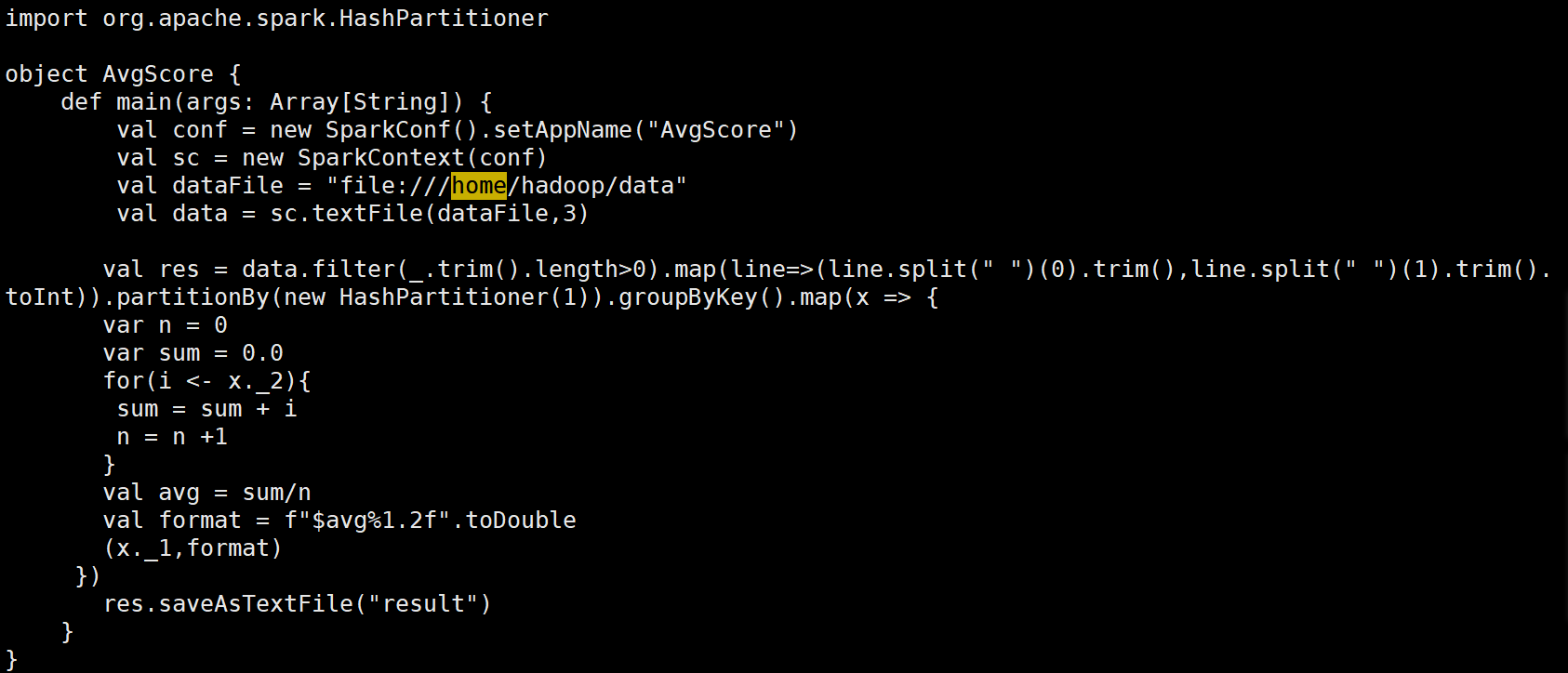
(1)在目录/usr/local/spark/mycode/avgscore/src/main/scala下新建一个avgscore.scala,然后输入如下代码:
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.HashPartitioner
object AvgScore {
def main(args: Array[String]) {
// 初始化SparkConf和SparkContext
val conf = new SparkConf().setAppName("AvgScore")
val sc = new SparkContext(conf)
// 输入文件路径
val dataFile = "file:///home/hadoop/data"
// 读取文件并创建RDD,设置为3个分区
val data = sc.textFile(dataFile, 3)
// 处理数据:过滤空行,拆分数据并转为键值对
val res = data
.filter(_.trim.length > 0) // 过滤空行
.map(line => {
val parts = line.split(" ")
(parts(0).trim, parts(1).trim.toInt) // 键为学生名字,值为成绩
})
.partitionBy(new HashPartitioner(1)) // 使用HashPartitioner进行分区
.groupByKey() // 根据键(学生名字)进行分组
.map(x => {
var n = 0
var sum = 0.0
// 计算每个学生的总成绩和数量
for (i <- x._2) {
sum += i
n += 1
}
// 计算平均成绩
val avg = sum / n
// 格式化平均成绩到两位小数
val format = f"$avg%1.2f"
(x._1, format) // 返回学生名字和格式化后的平均成绩
})
// 将结果保存到文件
res.saveAsTextFile("result")
// 停止SparkContext
sc.stop()
}
}
(2)在目录/usr/local/spark/mycode/avgscore目录下新建simple.sbt,然后输入如下代码:
name := "Simple Project"version := "1.0"scalaVersion := "2.11.12"libraryDependencies += "org.apache.spark" %% "spark-core" % "2.4.0"

(3)在目录/usr/local/spark/mycode/avgscore下执行如下命令打包程序:
sudo /usr/local/sbt/sbt package

(4)最后在目录/usr/local/spark/mycode/avgscore下执行下面命令提交程序,在目录/usr/local/spark/mycode/avgscore/result下即可得到结果文件:
/usr/local/spark/bin/spark-submit --class "AvgScore"/usr/local/spark/mycode/avgscore/target/scala-2.11/simple-project_2.11-1.0.jar

四、问题和解决方法
1. 实验问题:Spark的配置可能变得很复杂,尤其是当涉及到不同的集群管理器、存储系统和应用需求时。
解决方法:仔细阅读Spark官方文档,并理解各种配置选项含义,根据应用需求和集群环境,选择正确配置选项并进行适当调整。
2. 实验问题:在Spark实验中,数据清洗、转换和聚合较为繁琐。
解决方法:使用Spark提供的丰富数据处理功能,例如DataFrame API和Transformations、Actions操作,通过使用这些功能,可以轻松地处理数据并对其进行各种操作。
3. 实验问题:用spark读取本地文件并统计文件内容行数时报出IllegalArgumentException(非法参数异常)。
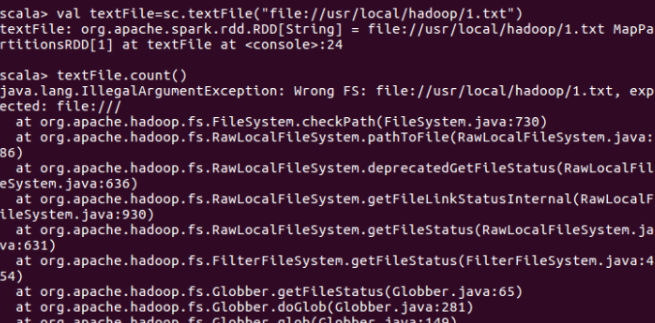
解决方法:由于file:///少打了一个/,spark读取本地文件的url路径有问题,正确的应该是valtextFile=sc.textFile("file:///usr/local/hadoop/1.txt")。
4. 实验问题:用spark读取hdfs文件系统中的文件并统计文件内容行数时报出InvalidInput Exception(无效输入异常),并提示输入路径不存在。
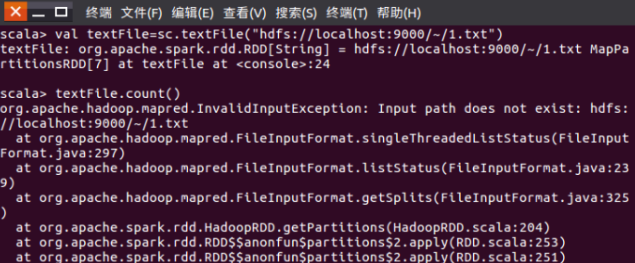
解决方法:读取hdfs文件的url路径有问题,hdfs文件系统的根目录不是~,而应该是/user/hadoop,其中hadoop是用户名。
5. 实验问题:编写spark独立应用程序并实现数据去重时,程序运行报出异常:java.net.URI SyntaxException: Illegal character in scheme name at index 0。
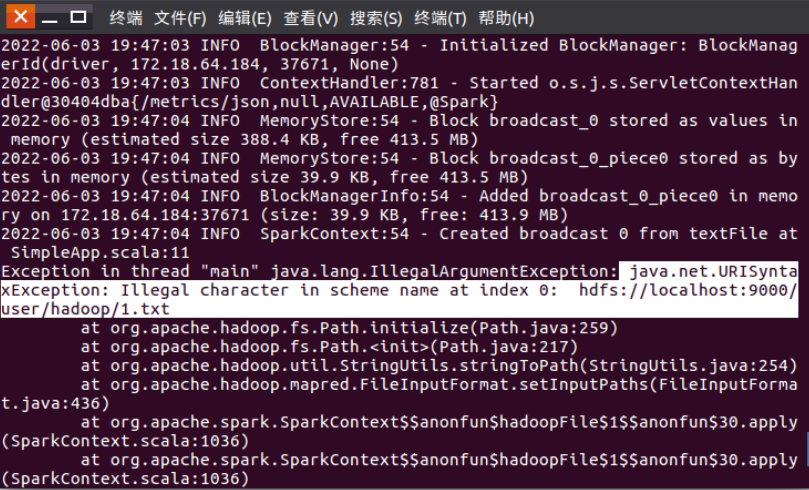
解决方法:代码中获取hdfs文件的地址URL前面有空格,就会报错java.net.URISyntaxException:Illegal character in scheme name at index 0,删掉空格就好了。
6. 实验问题:随着Spark版本更新,一些功能和API会发生变化,导致与旧版本不兼容。
解决方法:了解Spark版本之间差异并适应新API和功能通过仔细阅读官方文档并参考示例代码,可以更好地适应新版本Spark并利用其提供的新功能。
7. 实验问题:在Spark应用程序运行过程中,对其进行监控和调试是一项重要任务会面临日志分析困难、任务跟踪和性能分析等。
解决方法:使用Spark提供的监控工具和API,例如Spark UI、Event Tracker和Profiler等,通过这些工具和API,可以实时监控Spark应用程序状态、跟踪任务执行过程并分析性能瓶颈等。
五、心得体会
1、在这次实验中我深刻体会到了数据去重的重要性,在处理和分析大规模数据时,数据去重能够避免重复数据的干扰,提高数据的质量和准确性。例如在分析用户行为或销售数据时,如果存在大量的重复数据,将会对结果产生误导。通过使用Spark的distinct()函数可以轻松地实现数据去重,并且在处理大规模数据时,去重操作能够显著提高计算效率和结果质量。此外数据去重还可以应用于数据清洗和预处理阶段,在数据预处理时需要删除无效、重复和不完整的数据,以便进行后续的数据分析和挖掘。通过使用Spark的distinct()函数可以快速地去除重复数据,并且对数据进行清洗和预处理,以便更好地探索和分析数据的规律和信息。
2、Spark是一个开源的大规模数据处理工具,具有高效、可扩展和易用的特点,通过使用Spark可以快速地读取和处理大量数据,并且使用丰富的转换和操作来分析和挖掘数据中的规律和信息。DataFrame提供了一种以表格形式组织数据的结构,可以方便地处理各种类型的数据。在处理和分析数据时,Spark提供了丰富的转换和操作,例如可以使用map()函数对数据进行转换,使用filter()函数对数据进行筛选,使用reduceByKey()函数对数据进行聚合操作。
3、使用Spark的read()函数来读取不同格式的数据,使用DataFrame API提供的各种函数对数据进行处理和分析,使用select()函数选择指定的列进行输出,使用where()函数对数据进行筛选,使用groupBy()函数对数据进行分组和聚合操作,还可以使用DataFrame API提供的统计函数来计算数据的统计信息,如平均值、标准差、计数等。
4、合理地设置Spark的配置参数,以提高计算效率和减少资源浪费,选择合适的转换和操作来处理和分析数据以确保结果的准确性和可靠性。在分布式计算中,某些键值对的出现频率可能远高于其他键值对,导致数据分布不均衡,这会引发集群中的负载倾斜问题,影响计算性能和结果质量。为了避免数据倾斜对计算性能的影响,可以对数据进行预处理或使用应对数据倾斜的算法来解决问题。
5、DataFrame API提供了丰富的统计和分析函数,可以方便地对数据进行分组、聚合、过滤和排序等操作,通过使用DataFrame API可以快速地获得数据的统计信息和分布情况,并且对数据进行更深入的挖掘和分析。可以使用groupBy()函数对数据进行分组操作,然后使用agg()函数对分组后的数据进行聚合操作。使用window()函数对数据进行窗口分析,以便更好地探索数据的趋势和规律,窗口函数可以用于计算滑动平均值、累计和等动态变化的数据指标。
6、使用Spark进行数据处理具有高效处理大规模数据、简单易用的API、灵活的数据处理方式、高效的资源利用率、稳定的计算性能等优点,这些优点使得Spark成为目前大规模数据处理领域中备受关注和常用的工具之一。