第八章:字幕服务
欢迎来到第八章!
在上一章中,我们将LLM生成的脚本转换为语音音频,并获取了每个单词发音时间的关键时序信息。
现在我们已经拥有旁白音频及其时间信息,下一步关键步骤是创建与音频匹配的屏幕显示文字——即字幕。
什么是字幕服务?
想象观看视频时,文字内容与人物说话完全同步显示在屏幕上,这正是字幕的功能。MoneyPrinterTurbo中的字幕服务专门用于创建广泛使用的.srt格式字幕文件,该文件告知视频播放器每行文字应该出现和消失的精确时间。
其主要目标包括:
- 生成
.srt文件:创建具有正确结构和时间信息的纯文本文件 - 匹配音频时序:确保字幕文件中的文本行与音频中的发音完全对齐
- 提供文本内容:使用原始视频脚本或音频转录文本作为字幕来源
- 处理不准确性:当自动转录不够精确时,通过将字幕与原始脚本对齐来处理时间和文本误差
我们可以将其视为一个仔细聆听生成音频,并附带时间戳键入文本的服务,从而使视频播放器知晓每行文字的显示时机。
为何需要独立字幕服务?
尽管第七章的语音合成服务能提供单词级时间信息,但创建包含正确分组行(如完整句子或短语)的最终.srt文件,以及处理潜在错误都需要特定逻辑。
当需要通过语音转录(例如使用Whisper技术)重新生成字幕时,该服务能提供更精确的时序数据(尤其在原始TTS时序不够理想时)。字幕服务封装了这些逻辑,为后续视频生成服务提供可靠的.srt文件生成方式。
字幕创建方法
MoneyPrinterTurbo支持多种字幕生成方式:
- 使用TTS时序(来自voice.py):直接利用语音合成过程中获取的精确单词时序(SubMaker对象)创建.srt文件
- 使用音频转录(来自subtitle.py):通过
Whisper等转录模型处理音频文件,同时生成文本和时序信息 - 校正转录文本:当使用转录方式时,通过比较转录字幕与原始脚本,基于脚本修正文本内容
以下重点解析subtitle.py文件实现的转录和校正功能。
Whisper前文传送:[Meetily后端框架] Whisper转录服务器 | 后端服务管理脚本
服务使用流程(编排器视角)
任务编排器根据配置决定使用哪种方法。
当采用subtitle.py管理的转录方法时,将调用create函数,若启用字幕校正则继续调用correct函数:
# 来自app/services/task.py的简化片段
def start(task_id, params: VideoParams, stop_at: str = "video"):
# ...生成音频文件后...
# 步骤4:生成字幕
logger.info("## 步骤4:生成字幕...")
subtitle_output_path = utils.storage_file(task_id, "subtitle.srt")
# 调用字幕服务创建函数
subtitle.create(
audio_file=audio_file,
subtitle_file=subtitle_output_path
)
# 可选:校正字幕
if params.subtitle_correction_enabled:
logger.info("## 步骤4.1:校正字幕...")
subtitle.correct(
subtitle_file=subtitle_output_path,
video_script=video_script
)
此流程确保首先生成基础字幕文件,随后根据配置决定是否进行文本校正。
字幕服务核心实现(app/services/subtitle.py)
通过转录创建字幕(create函数)
# subtitle.py的简化实现
def create(audio_file, subtitle_file: str = ""):
global model
# 加载Whisper模型
model = WhisperModel(
model_size_or_path=config.whisper["model_size"],
device=config.whisper["device"],
compute_type=config.whisper["compute_type"]
)
# 执行语音转录
segments, info = model.transcribe(
audio_file,
beam_size=5,
word_timestamps=True, # 获取单词级时间戳
vad_filter=True
)
# 处理转录结果
subtitles = []
for segment in segments:
# 组合单词形成字幕行
current_line_text = ""
current_line_start_time = -1.0
for word in segment.words:
# 组合单词并检测标点以分割字幕行
if utils.str_contains_punctuation(word.word):
subtitles.append({
"msg": current_line_text.strip(),
"start_time": current_line_start_time,
"end_time": word.end
})
current_line_text = ""
# 写入SRT文件
utils.text_to_srt(subtitle_item, subtitle_file)
该实现通过Whisper模型获取单词级时间戳,根据标点符号智能分割字幕行,最终生成符合规范的.srt文件。
字幕校正(correct函数)
def correct(subtitle_file, video_script):
# 读取字幕文件和原始脚本
subtitle_items = file_to_subtitles(subtitle_file)
script_lines = utils.split_string_by_punctuations(video_script)
# 对齐脚本与字幕条目
new_subtitle_items = []
while script_index < len(script_lines):
# 使用编辑距离算法进行相似度匹配
similarity_score = similarity(script_line, combined_subtitle_text)
if similarity_score > 0.8:
# 保留原始脚本文本,使用字幕时间戳
new_subtitle_items.append((
new_index,
combined_timing,
script_line
))
# 写入校正后的SRT文件
with open(subtitle_file, "w") as fd:
fd.write(f"{item[0]}\n{item[1]}\n{item[2]}\n\n")
校正流程通过Levenshtein距离算法匹配原始脚本与生成字幕,在保持时间戳的前提下替换为准确文本,有效解决语音识别误差问题。
服务配置参数
| 配置项 | 说明 |
|---|---|
model_size |
Whisper模型规格(如large-v3),模型越大精度越高但资源消耗越大 |
device |
运算设备(cpu/cuda),GPU加速可大幅提升转录速度 |
compute_type |
计算类型(int8/float16),影响内存占用和计算精度 |
服务交互流程
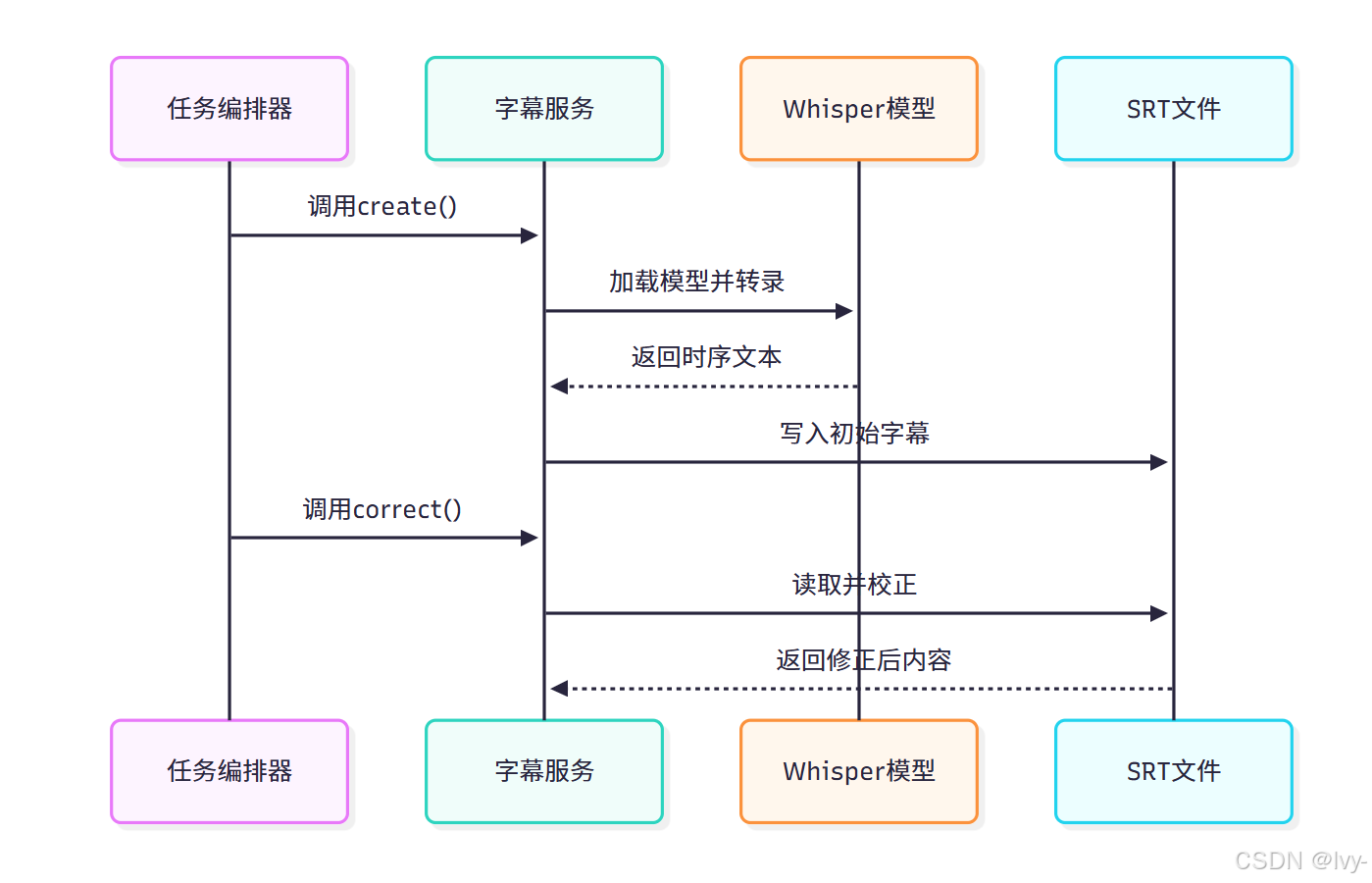
该序列图展示了字幕生成与校正的完整工作流程。
总结
字幕服务通过智能语音转录和文本校正双机制,确保视频字幕在时间精度和文本准确性方面达到最佳效果。下一章我们将进入《视频素材服务》,探讨如何为旁白匹配视觉元素。
第九章:视频素材服务
在前几章中,我们已经完成了脚本生成(LLM服务)、语音合成(语音合成服务)和字幕时间轴处理(字幕服务)。
现在,我们拥有故事脚本和语音内容,但视觉素材呢?视频需要动态画面来增强吸引力!而寻找合适的视觉素材往往耗时费力。
这正是视频素材服务的核心价值所在。
什么是视频素材服务?
视频素材服务如同视频创作的智能采购专员,其核心职责包括:
- 智能搜索:基于脚本关键词匹配视觉素材
- 多源获取:接入Pexels/Pixabay等免费素材平台
- 精准过滤:按宽高比、最低时长等参数筛选
- 批量下载:自动化下载合规素材至本地
- 本地处理:支持用户预存素材的直接调用
- 素材预备:为后续视频编辑环节准备标准化素材
简言之,该服务负责收集视频旁白播放期间需要呈现的所有动态/静态视觉内容。
视觉素材的重要性
视觉元素是维持观众注意力的关键!它们通过以下方式提升视频质量:
- 具象化语音内容
- 增加制作专业度
- 增强内容动态表现
视频素材服务自动化完成素材收集,确保视频编辑环节拥有充足素材。
任务编排器调用流程
任务编排器在获取脚本、关键词和音频时长后调用素材服务,主要调用接口为download_videos:
# app/services/task.py的简化调用逻辑
def start(task_id, params: VideoParams):
# 获取关键词和音频时长后...
# 步骤5:获取视频素材
if params.video_source == "local":
# 调用本地素材处理
downloaded_videos = material.process_local_materials(task_id, params)
else:
# 在线素材下载
downloaded_videos = material.download_videos(
task_id=task_id,
search_terms=video_terms, # LLM生成的关键词
source=params.video_source, # 素材源选择
video_aspect=params.video_aspect, # 宽高比
audio_duration=audio_duration, # 音频总时长
max_clip_duration=params.video_clip_duration # 单片段最大时长
)
该流程体现任务编排器通过参数控制素材获取方式,确保获得足够时长的合规素材。
服务核心实现(app/services/material.py)
主流程函数(download_videos)
def download_videos(task_id, search_terms, source, video_aspect, audio_duration, max_clip_duration):
valid_video_items = [] # 有效素材对象池
# 根据来源选择搜索接口
search_func = search_videos_pexels if source == "pexels" else search_videos_pixabay
# 关键词轮询搜索
for term in search_terms:
items = search_func(term, max_clip_duration, video_aspect)
valid_video_items.extend([item for item in items if item.url not in seen_urls])
# 确定存储路径
save_dir = config.get("material_directory") or utils.task_dir(task_id)
# 下载与时长控制
downloaded_paths = []
total_duration = 0.0
for item in valid_video_items:
path = save_video(item.url, save_dir)
if path:
downloaded_paths.append(path)
total_duration += min(item.duration, max_clip_duration)
if total_duration >= audio_duration:
break # 达到时长要求即终止
return downloaded_paths
该函数实现多关键词搜索、素材去重、路径管理和智能下载终止等核心逻辑。
素材搜索接口
Pexels搜索实现
def search_videos_pexels(term, min_duration, aspect):
api_key = config.get("pexels_api_keys")
headers = {"Authorization": api_key}
params = {
"query": term,
"orientation": aspect.name,
"per_page": 20
}
response = requests.get("https://api.pexels.com/videos/search", params=params, headers=headers)
return [
MaterialInfo(
provider="pexels",
url=video_file["link"],
duration=video["duration"]
) for video in response.json()["videos"]
if video["duration"] >= min_duration
]
Pixabay搜索实现
def search_videos_pixabay(term, min_duration, aspect):
api_key = config.get("pixabay_api_keys")
params = {
"q": term,
"video_type": "all",
"per_page": 50
}
response = requests.get("https://pixabay.com/api/videos/", params=params)
return [
MaterialInfo(
provider="pixabay",
url=video["url"],
duration=video["duration"]
) for video in response.json()["hits"]
if video["duration"] >= min_duration
]
两个搜索函数均实现API调用、时长过滤和标准素材对象构造。
素材下载验证
def save_video(url, save_dir):
# 生成唯一缓存文件名
file_hash = utils.md5(url.split("?")[0])
save_path = f"{save_dir}/vid-{file_hash}.mp4"
# 本地缓存检查
if os.path.exists(save_path):
return save_path
# 下载与校验
try:
with requests.get(url, stream=True) as r:
with open(save_path, "wb") as f:
for chunk in r.iter_content(1024*1024):
f.write(chunk)
# 视频文件验证
with VideoFileClip(save_path) as clip:
if clip.duration > 0 and clip.fps > 0:
return save_path
else:
os.remove(save_path)
return ""
except Exception as e:
logging.error(f"下载失败: {str(e)}")
return ""
该函数实现MD5缓存命名、流式下载、视频文件完整性校验三重保障机制。
配置参数说明
| 配置项 | 作用说明 |
|---|---|
pexels_api_keys |
Pexels平台API访问密钥 |
pixabay_api_keys |
Pixabay平台API访问密钥 |
material_directory |
素材存储路径(task表示任务目录) |
proxy |
网络代理配置 |
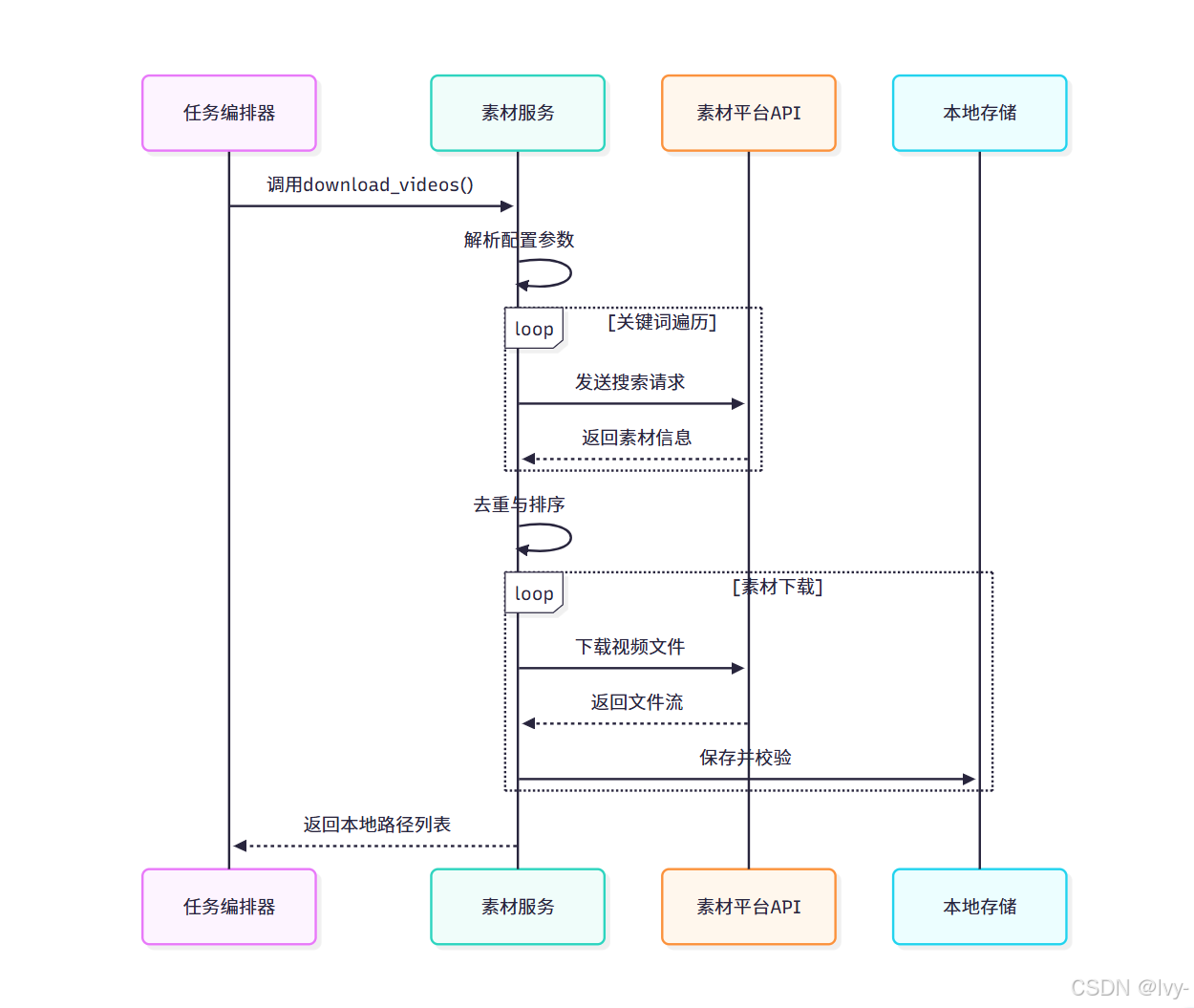
服务交互流程图
结语
视频素材服务通过智能搜索与自动化下载机制,有效解决视频制作中的素材获取难题。
下一章我们将深入《视频生成服务》,解析如何将语音、字幕与素材合成为最终视频。
第十章:视频生成服务
欢迎来到MoneyPrinterTurbo教程的最后一个功能章节!在前几章中,我们已经收集了视频制作所需的所有素材:脚本(LLM服务)、配音音频及其时间轴(语音合成服务)、字幕文本及其时间轴(字幕服务),以及背景视频片段或图片(视频素材服务)。
现在,我们拥有所有组件。如何将它们组合成最终可观看和分享的视频文件?
这就是视频生成服务的职责。
视频生成服务是什么?
可以将视频生成服务视为项目中的专业视频编辑器。它接收所有独立组件——视频片段、配音音频、背景音乐(如果选择添加)和字幕文件——并将它们精心组合成完整的高质量视频文件。
其主要职责包括:
- 视觉素材整合:将视频片段集合拼接成连续背景视频,匹配音频时长
- 画面适配:调整每个视频片段尺寸,裁剪或添加遮幅以符合目标宽高比(如9:16竖版或16:9横版),避免画面变形
- 转场特效:在视频片段间应用平滑过渡效果(如淡入淡出或滑动切换)
- 音频混合:合并配音和背景音乐,根据需要调整音量平衡
- 字幕叠加:根据
.srt字幕文件的时间信息,使用指定字体、字号、颜色和位置将字幕"烧录"到视频帧 - 最终输出:将完整视频(画面、音频和字幕)保存为MP4格式文件
本质上,该服务通过最终组装和渲染生成成品视频。MoneyPrinterTurbo使用强大的Python库moviepy来处理大部分视频编辑任务。
https://github.com/Zulko/moviepy
任务协调器如何调用该服务
任务协调器如同指挥家,在其它组件(脚本、音频、字幕、素材)准备就绪并保存为文件后,通知视频生成服务开始组装视频。
协调器通常调用视频服务(app/services/video.py)中的两个核心函数:
combine_videos:将下载的视频片段拼接成连续背景视频generate_video:将整合后的背景视频、音频文件、字幕文件及样式设置合并为最终视频
以下是协调器(task.py)的调用示例:
# 来自app/services/task.py的简化代码片段
from app.services import video # 导入视频服务模块
# ... 其它导入 ...
def start(task_id, params: VideoParams, stop_at: str = "video"):
# ... 获取downloaded_videos和audio_file, subtitle_path后 ...
# --- 步骤6: 生成最终视频 ---
logger.info("## 步骤6: 生成最终视频...")
# 确定中间文件和最终输出路径
combined_video_path = utils.storage_file(task_id, "combined_clips.mp4") # 合并片段临时文件
final_video_path = utils.storage_file(task_id, "final.mp4") # 最终输出文件
# 第一步:合并下载的视频片段
combined_video_path = video.combine_videos(
combined_video_path=combined_video_path,
video_paths=downloaded_videos, # 来自素材服务的路径列表
audio_file=audio_file, # 用于确定目标时长
video_aspect=params.video_aspect, # 宽高比设置
video_concat_mode=params.video_concat_mode, # 片段排序方式
video_transition_mode=params.video_transition_mode, # 转场样式
max_clip_duration=params.video_clip_duration, # 单片段最大时长
threads=params.n_threads, # 处理线程数
)
if not combined_video_path:
logger.error(f"任务{task_id}视频片段合并失败")
sm.state.update_task(task_id, state=const.TASK_STATE_FAILED)
return
# 第二步:添加音频和字幕生成最终视频
video.generate_video(
video_path=combined_video_path, # 合并后的背景视频
audio_path=audio_file, # 配音音频
subtitle_path=subtitle_path, # 字幕文件路径
output_file=final_video_path, # 最终输出路径
params=params, # 传递字幕/BGM参数
)
if not os.path.exists(final_video_path):
logger.error(f"任务{task_id}最终视频生成失败")
sm.state.update_task(task_id, state=const.TASK_STATE_FAILED)
return
logger.success(f"任务{task_id}成功完成!")
# 更新任务状态为完成(第四章内容)
sm.state.update_task(task_id, state=const.TASK_STATE_COMPLETE, progress=100, videos=[final_video_path])
return {"videos": [final_video_path]} # 返回最终视频路径
这段协调器代码展示了:
- 确定视频处理所需的临时文件和最终输出路径
- 调用
video.combine_videos,传递视频片段列表和视觉设置参数(来自第五章的params) - 检查合并是否成功
- 调用
video.generate_video,传入合并后的背景视频、音频路径、字幕路径及完整参数 - 验证最终文件是否存在
- 更新任务状态为完成或失败
协调器依赖视频服务处理视频编辑的复杂性。
视频生成服务内部实现(app/services/video.py)
通过app/services/video.py中的代码片段,了解combine_videos和generate_video如何利用moviepy工作。
合并视频片段(combine_videos)
此函数整合多个视频文件为连续长视频,处理尺寸调整、循环和转场:
# app/services/video.py的简化代码片段
from moviepy import VideoFileClip, CompositeVideoClip, concatenate_videoclips, ColorClip
import random # 随机排序
from app.models.schema import VideoAspect, VideoConcatMode, VideoTransitionMode
from app.services.utils import video_effects # 转场特效
from app.utils import utils # 路径处理
def combine_videos(
combined_video_path: str,
video_paths: List[str], # 下载/本地的视频片段路径
audio_file: str, # 用于确定时长
video_aspect: VideoAspect = VideoAspect.portrait, # 目标宽高比
video_concat_mode: VideoConcatMode = VideoConcatMode.random, # 排序方式
video_transition_mode: VideoTransitionMode = None, # 转场样式
max_clip_duration: int = 5, # 单片段最大时长
threads: int = 2, # 渲染线程
) -> str:
# 加载音频获取时长
audio_clip = AudioFileClip(audio_file)
audio_duration = audio_clip.duration
logger.info(f"音频时长: {audio_duration}秒")
audio_clip.close()
output_dir = os.path.dirname(combined_video_path)
aspect = VideoAspect(video_aspect)
video_width, video_height = aspect.to_resolution() # 获取目标分辨率
processed_clips_paths = [] # 处理后的片段路径
# 子片段处理逻辑(简化示例)
subclipped_items = [] # SubClippedVideoClip对象列表
for video_path in video_paths:
try:
clip = VideoFileClip(video_path)
start_time = 0
while start_time < clip.duration:
end_time = min(start_time + max_clip_duration, clip.duration)
if end_time - start_time > 0.5: # 最小时长检查
subclipped_items.append(SubClippedVideoClip(
file_path=video_path,
start_time=start_time,
end_time=end_time
))
start_time = end_time
clip.close()
except Exception as e:
logger.warning(f"处理片段{video_path}失败: {e}")
# 随机排序处理
if video_concat_mode.value == VideoConcatMode.random.value:
random.shuffle(subclipped_items)
# 渐进式合并处理(简化)
total_video_duration = 0.0
for i, subclipped_item in enumerate(itertools.cycle(subclipped_items)):
if total_video_duration >= audio_duration and i >= len(subclipped_items):
break # 满足时长且用完所有独特片段
# 尺寸适配处理
clip_w, clip_h = clip.size
clip_ratio = clip_w / clip_h
video_ratio = video_width / video_height
if clip_ratio != video_ratio:
# 添加黑边适配宽高比
background = ColorClip(size=(video_width, video_height), color=(0, 0, 0))
clip = CompositeVideoClip([background, clip_resized.with_position("center")])
# 应用转场特效
if video_transition_mode.value != VideoTransitionMode.none.value:
clip = video_effects.fadein_transition(clip, 1) # 示例淡入效果
# 写入临时文件
temp_clip_file = f"{output_dir}/temp-clip-{i}.mp4"
clip.write_videofile(temp_clip_file, logger=None, fps=30)
processed_clips_paths.append(temp_clip_file)
# 渐进式合并(防止内存溢出)
for i, next_clip_path in enumerate(processed_clips_paths[1:]):
base_clip = VideoFileClip(temp_merged_video)
next_clip = VideoFileClip(next_clip_path)
merged_clip = concatenate_videoclips([base_clip, next_clip])
# 写入中间合并文件...
# 清理临时文件
delete_files(processed_clips_paths)
return combined_video_path
# 辅助类定义
class SubClippedVideoClip:
def __init__(self, file_path, start_time=None, end_time=None):
self.file_path = file_path
self.start_time = start_time
self.end_time = end_time
self.duration = end_time - start_time if end_time else None
该函数主要流程:
- 计算需求时长:通过音频文件确定目标视频长度
- 预处理片段:将长视频切割为指定时长的子片段
- 随机排序:根据设置打乱片段顺序
- 循环填充:使用迭代循环确保视频总长度覆盖音频时长
- 尺寸适配:通过缩放和添加黑边保持宽高比一致
- 转场处理:应用淡入等过渡效果
- 渐进合并:分步合并防止内存溢出
- 清理资源:删除中间文件
生成最终视频(generate_video)
此函数整合背景视频、音频和字幕,生成最终输出:
# app/services/video.py的简化代码片段
from moviepy import (
AudioFileClip,
CompositeAudioClip,
CompositeVideoClip,
VideoFileClip,
afx, # 音频特效
)
from moviepy.video.tools.subtitles import SubtitlesClip
from PIL import ImageFont # 字体处理
def generate_video(
video_path: str, # 合并后的背景视频
audio_path: str, # 配音音频
subtitle_path: str, # 字幕文件
output_file: str, # 输出路径
params: VideoParams, # 配置参数
):
# 加载背景视频(忽略原声)
video_clip = VideoFileClip(video_path).without_audio()
# 加载配音并调整音量
audio_clip = AudioFileClip(audio_path).with_effects(
[afx.MultiplyVolume(params.voice_volume)]
)
# 字幕处理
if params.subtitle_enabled and subtitle_path:
def create_styled_text_clip(subtitle_item):
# 字体路径处理
font_path = os.path.join(utils.font_dir(), params.font_name or "STHeitiMedium.ttc")
# 文字换行处理
wrapped_text, _ = wrap_text(
text=phrase,
max_width=video_width * 0.9,
font=font_path,
fontsize=int(params.font_size)
)
# 创建字幕Clip
_clip = TextClip(
text=wrapped_text,
font=font_path,
fontsize=int(params.font_size),
color=params.text_fore_color,
bg_color=params.text_background_color,
stroke_color=params.stroke_color,
stroke_width=int(params.stroke_width),
)
# 定位处理
if params.subtitle_position == "bottom":
_clip = _clip.with_position(("center", video_height * 0.95 - _clip.h))
return _clip
# 加载字幕文件
subtitles_clip = SubtitlesClip(subtitle_path, make_textclip=create_styled_text_clip)
video_clip = CompositeVideoClip([video_clip, subtitles_clip])
# 背景音乐处理
if bgm_file:
bgm_clip = AudioFileClip(bgm_file).with_effects([
afx.MultiplyVolume(params.bgm_volume),
afx.AudioFadeOut(3),
afx.AudioLoop(duration=video_clip.duration),
])
audio_clip = CompositeAudioClip([audio_clip, bgm_clip])
# 合成最终视频
video_clip = video_clip.with_audio(audio_clip)
video_clip.write_videofile(
output_file,
audio_codec="aac",
threads=params.n_threads,
fps=30,
)
video_clip.close()
核心处理流程:
- 加载素材:读取背景视频、音频和字幕文件
- 字幕渲染:根据样式设置生成带特效的文字层
- 音频混合:合并配音和背景音乐,应用淡出效果
- 最终合成:将画面、音频和字幕整合输出
- 资源释放:关闭视频对象释放内存
视频生成交互流程
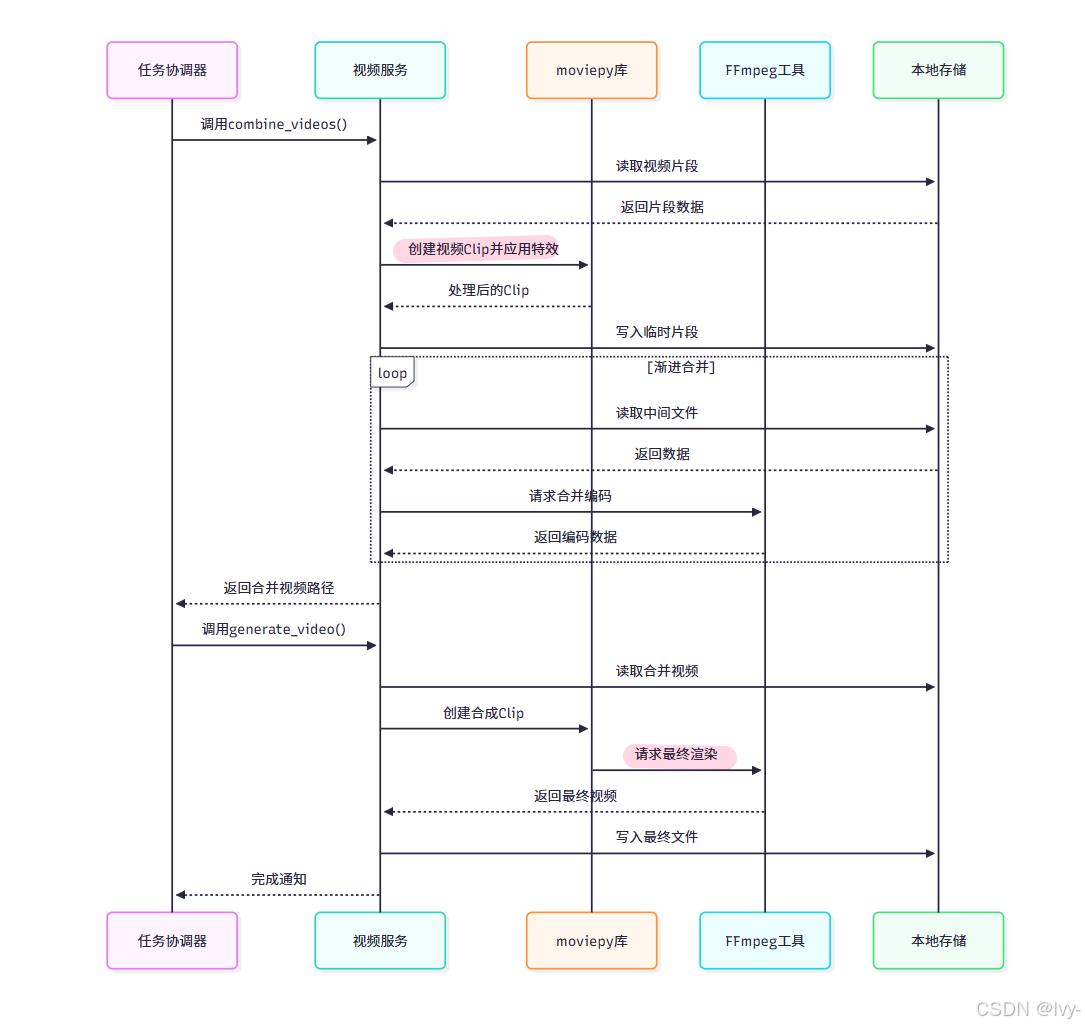
该流程图展示了视频服务 如何与底层工具(moviepy & ffmpeg)协作完成视频生成。
FFmpeg
FFmpeg 是一个开源的多媒体处理工具,能够录制、转换、流式传输音视频,支持几乎所有常见格式,功能强大且免费。
https://trac.ffmpeg.org/
配置参数说明
视频生成服务依赖以下配置参数:
| 参数 | 来源 | 作用说明 |
|---|---|---|
ffmpeg_path |
config.toml | FFmpeg可执行文件路径 |
n_threads |
VideoParams | 视频编码使用的CPU线程数 |
video_aspect |
VideoParams | 目标视频宽高比(竖版/横版) |
video_clip_duration |
VideoParams | 单视频片段最大时长 |
video_transition_mode |
VideoParams | 转场特效类型(无/淡入/滑动等) |
font_name |
VideoParams | 字幕字体文件名称 |
text_fore_color |
VideoParams | 字幕文字颜色 |
stroke_width |
VideoParams | 文字描边粗细 |
bgm_volume |
VideoParams | 背景音乐音量比例 |
结语
视频生成服务作为MoneyPrinterTurbo工作流的最终环节,通过整合各模块产出素材,运用moviepy和FFmpeg完成复杂的音视频处理,最终生成符合用户设定的高质量视频文件。
我们已经完整走过了从参数配置到素材准备,最终到视频合成的完整技术流程。
END ★,°:.☆( ̄▽ ̄).°★ 。