索引篇:
1.说说对数据库中索引的理解
数据库中,索引类似于书本的目录,是一种加快查询速度的数据结构,可以显著减少数据查找的扫描量,从而提升SELECT、UPDATE、DELETE等操作的效率。
按「数据结构」分类:B+tree索引、Hash索引、Full-text索引。
B+Tree是多路搜索树,所有的值存储在叶子结点,内部结点只做导航。范围查询效率很高,支持排序、范围、前缀匹配等
Hash索引是适用哈希函数对简直对进行映射,精确匹配很快,但是不支持范围查询。
按「物理存储」分类:聚簇索引(主键索引)、二级索引(辅助索引)。
聚簇索引是索引结构与数据行一起存储,数据的物理储存位置由主键顺序决定。
二级索引是索引结构中不含数据,只存储主键值,查询数据时需要回表通过主键找到整行数据
按「字段特性」分类:主键索引、唯一索引、普通索引、前缀索引。
主键索引:唯一+非空+自动聚簇索引,是表的唯一标识,必须存在
唯一索引:必须唯一,但是可空,比如邮箱、手机号
普通索引:可不唯一、可空
前缀索引:仅索引字符串前缀部分
按「字段个数」分类:单列索引、联合索引。
单列索引是仅索引一个字段,create INDEX idx_name ON user(name);
联合索引是多个字段组合索引,遵守最左前缀原则 create INDEX idx_multi ON user(name,age);
2. 讲一下MySQL的索引优化策略,讲一下索引覆盖
索引优化策略的核心就是利用已有的索引来避免全表扫描、减少回表操作、提升查询效率。常用的策略有:
前缀索引优化:使用某个字段中字符串的前几个字符建立索引,可以减小索引字段的大小,有效提高索引的查询速度。
覆盖索引优化:查询所需的所有字段都能在索引中找到,不需要“回表”查询主键上的完整行
主键索引最好是自增的:这样的话每次插入的新数据会按顺序添加到当前索引节点的位置,不需要移动已有的数据,当页面写满,会自动开辟一个新页面,否则每次插入数据都要移动其他数据,影响查询效率。
防止索引失效:使用左或者左右模糊匹配,like %xx 或者 %xx% 两种方式都会造成索引失效;查询条件中对索引列做计算、函数、类型转换等,会造成索引失效(字符串会转int比较);联合索引要遵循最左匹配原则,否则会失效;where子句中,如果or前的列是索引列,or后的不是,索引会失效
SELECT * FROM user WHERE a > 1 AND b = 2;

3. 不使用索引怎么优化sql
1.限制返回数据量,使用LIMIT、分页等,只取必要字段
2.减少返回不必要的列
3.减少子嵌套查询,使用JOIN优化
4.避免where中对字段做函数运算
5.拆分大表
6.使用缓存
4. 回表查询
在使用**二级索引(辅助索引)**查到了对应的主键值后,MySQL 还需要回到主键(聚簇)索引中再次查找整行数据的过程,使用覆盖索引或者主键查询可以避免这个问题
5. 有了解过索引下推吗?
在使用联合索引的情况下,MySQL 允许在索引遍历的过程中,对联合索引中包含的字段先做判断,直接过滤掉不满足条件的记录,从而减少不必要的回表操作,提升查询效率。它适用于 InnoDB 引擎,且条件字段需要包含在联合索引中。是否使用索引下推可以通过 EXPLAIN 查看 Extra 字段是否显示 Using index condition。
6. 索引的优缺点
索引的优点在于显著提升查询性能,尤其是针对大量数据的快速定位、排序、分组、JOIN 等操作。它还支持覆盖索引和索引下推等高级优化。但索引也不是越多越好。它们会占用空间,在写操作时带来额外的维护成本,同时在使用不当时会失效或误导优化器。因此,在实际工作中,我们会通过分析查询频率、字段选择性和执行计划(EXPLAIN)来平衡索引的使用,避免盲目索引而拖慢性能。
7. 拷打 mysql 索引结构,聊到 b+树、哈希索引、b 树
mysql索引的底层结构有三种,B树、B+树以及哈希索引。B+树是多路平衡查找树,所有数据存在于叶子结点,内部结点只做导航,支持范围、前缀、排序查询。B树是B+树的前身,类似于B+树,但是数据可以存在于内部结点,查询效率不稳定。哈希索引基于哈希表结构(key->value),只支持等值查询,不支持范围查询和排序。
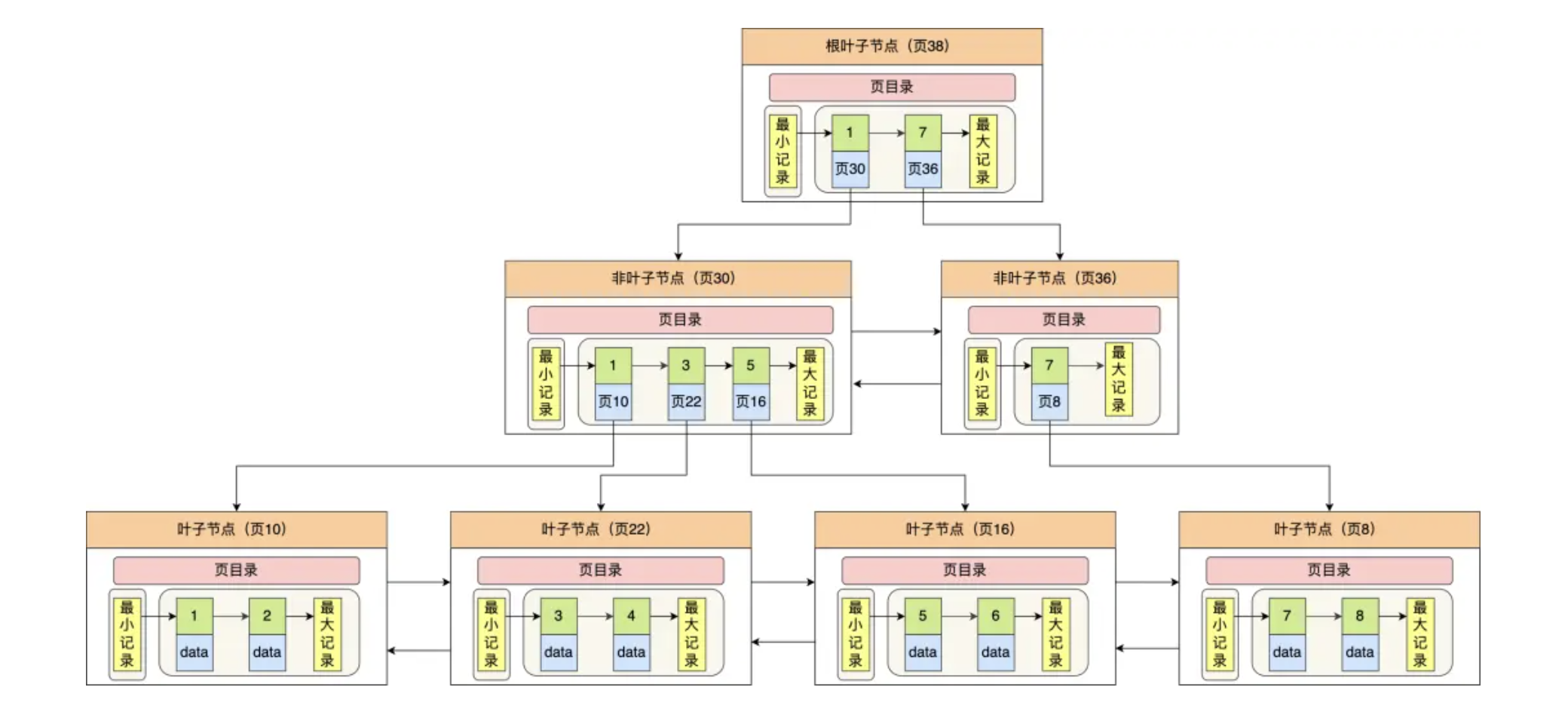
B+索引树结构如图所示:
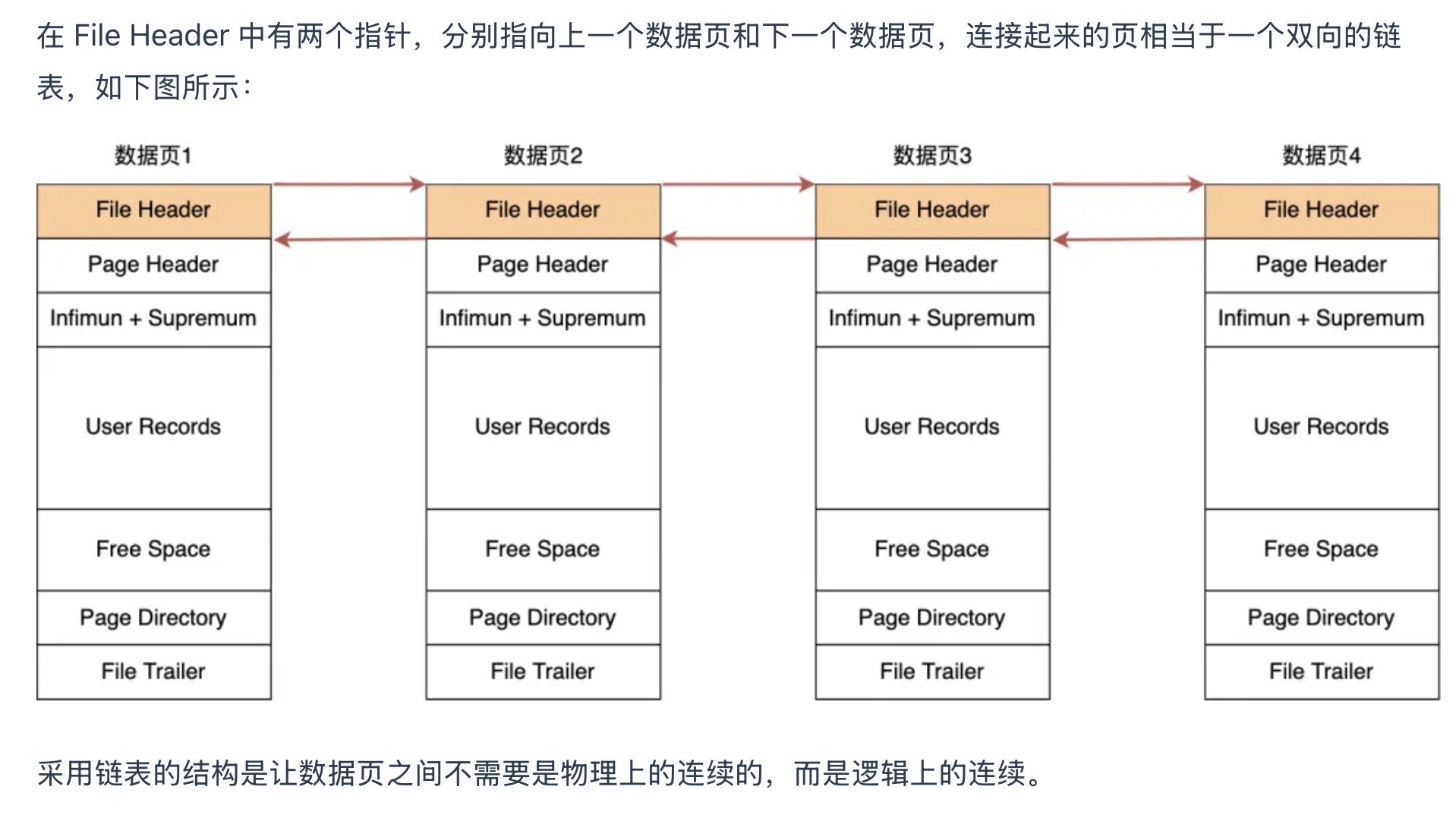
数据页面之间为双向链表:
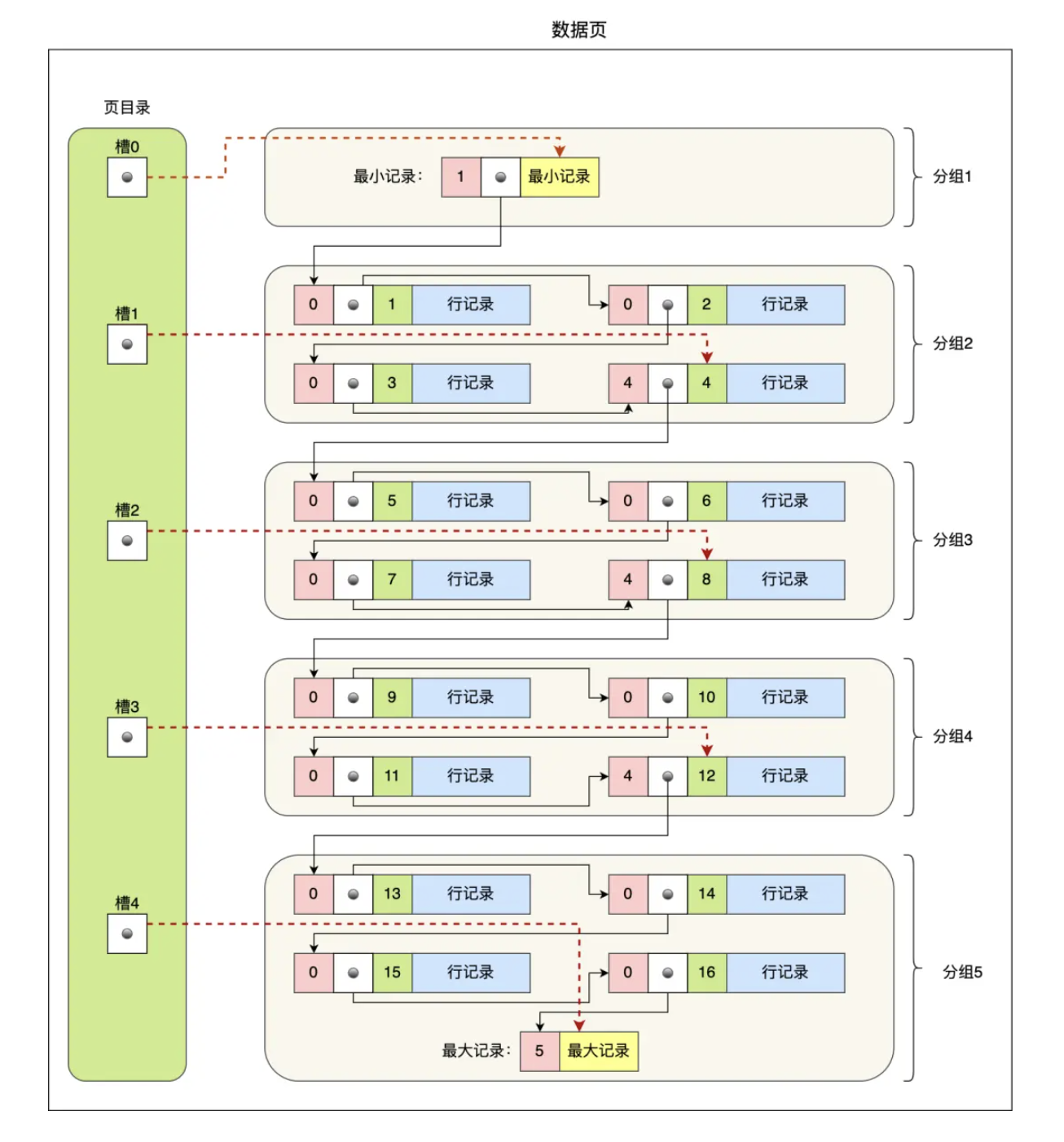
数据页中的记录是按照主键顺序组成的单向链表,特点就是插入、删除非常方便,但是检索效率不高
User Records中行记录的存储如图所示:
8. 为什么用b+树,b+树和b树的区别
B+树与B树差异的点,主要有以下几点:叶子节点才会存放实际数据,非叶子结点只会存放索引;所有索引都会在叶子结点出现,叶子结点之间构成一个有序链表;非叶子节点的索引也会同时存在子节点当中;非叶子结点有多少个子节点,就有多少个索引。
性能差别:
1.单点查询:B树在进行单个索引查询时,最快可以在O(1)时间内查到,而平均时间代价来看,B+树稍快。B树查询时间不稳定,有时在非叶子结点,有时在叶子结点。B+树的非叶子结点只有索引没有数据,因此数据量相同情况下,每层能存储的索引更多,B+树因此更加矮胖,查询底层结点磁盘IO次数更少
2.插入和删除效率:B+树有大量的冗余结点,每次删除一个结点的时候可以从叶子结点直接删除,甚至不动非叶子结点,树的结构不会发生太大变形,因此删除效率很高。而B树的删除结点有时非常复杂,比如删除根结点数据,可能设计复杂的树的变化。插入也比较类似,B+树有冗余结点,插入可能存在结点分裂,但是最多只涉及树的一条路径。
3.范围查询:
B树和B+树的等值查询基本原理都是从根结点查找,然后对比目标数据范围,最后递归进入子节点查询。
B+树所有的叶子结点之间还有一个链表进行连接,对范围查找很有帮助,比如想查询12月1日到12月12日之间的订单,可以先查询12月1日所在的叶子结点,然后利用链表向右遍历,直到找到12月12日的结点,这样不用每次从根结点查询,进一步节约查询时间。
9. 三层 b+树的数据量,两千万,怎么计算的
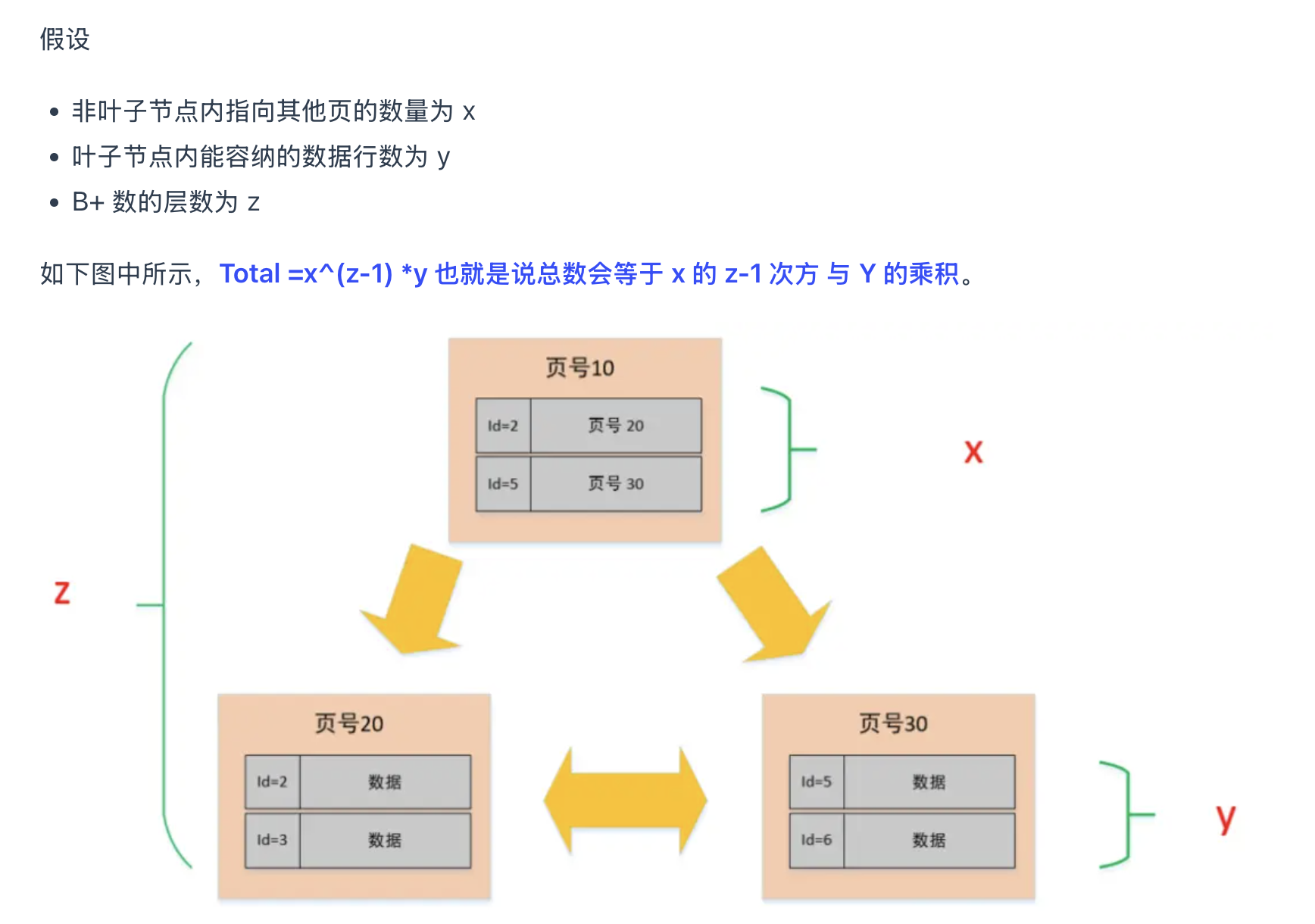
整页的大小是16K,页的结构中除了User Records之外的部分大约是1k左右,剩下15k用于存储数据,索引页的一条数据大约是12byte
所以x=15*1024/12=1280行
y中存储的是真正的数据,暂按每行数据1000byte来算的话
y= 15*1024/1000=15
假如是两层,z=2,total =(1280^1)*15 = 19200
假如是三层,z=3,total = (1280^2)* 15 = 2.45kw
一般B+的层级就是三层,因此大约就是2000万
10. 为什么数据库建索引会快,那索引越多越好吗
数据库建索引后之所以查询变快,是因为索引本质上是一个高效的有序数据结构(如 B+ 树)。它允许数据库通过树状路径快速定位目标数据,避免了全表扫描。同时,索引还支持范围查询、排序、联合索引、多字段过滤等优化方式。在实际应用中,查询通常只需读取几层索引节点(一般为 2~4 层),磁盘 I/O 极少,因此性能提升显著。这也是为什么索引是数据库性能优化的核心手段之一。
虽然索引可以加快查询速度,但乱建索引会带来一系列问题。首先,每个索引都是一个独立的 B+ 树结构,会增加磁盘空间占用。其次,在写操作时,所有相关索引都需要同步更新,导致写性能下降。另外,如果索引设计不合理,还可能导致 MySQL 优化器选择了非最优索引,从而使查询效率下降。维护过多冗余索引还会增加系统的管理成本。因此,索引需要根据查询场景、字段选择性、读写比例等进行有针对性的设计。
事务篇:
1.面试官:讲一下事务
事务的定义:
事务Transaction是一组操作的集合,这些操作要么全部执行成功,要么全部不执行,他们作为一个原子单位提交或者回滚,用来保证数据的完整性和一致性。
事务的四大特性ACID:
原子性Atomicity:事务中的所有操作要么全部执行,要么都不执行(undo log)
一致性Constitency: 执行前后,数据库保持一致性状态(延迟双删)
隔离性Isolation:多个事务之间互不干扰(事务隔离级别+MVCC+锁机制)
持久性Durability:提交后的操作永久保存(redo log)
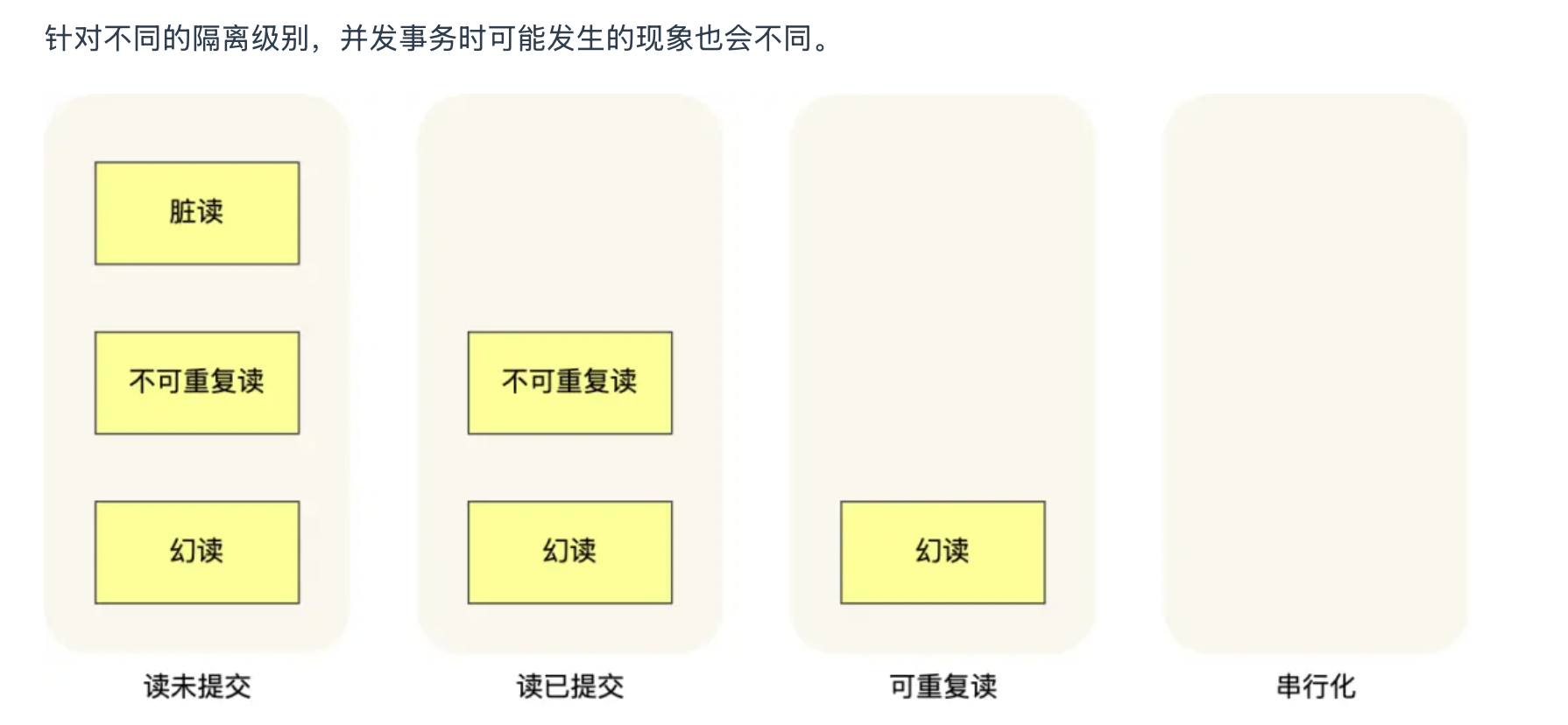
并发事务可能导致的问题:
脏读:一个事务读到了另一个未提交事务的数据
不可重复读:同一事务两次查询结果不同
幻读:同一事务两次查询出来的“记录数量”不同
事务隔离级别:
读未提交 read uncommited:指的是一个事务还未提交,它做的变更就能被其他事务看见
读提交read commited:指的是一个事务提交之后,它做的变更才能被其他事务看见
可重复读 repeatable read:指的是一个事务执行过程中看到的数据,一直跟这个事务启动时看到的数据是一致的,是MySQL InnoDB引擎的默认隔离级别
串行化 serializable:会对记录加上读写锁,多个事务对这条记录进行读写操作时,如果发生读写冲突,后一个必须等前一个事务执行完成才能继续执行。
在标准 SQL 中,Repeatable Read 并不能完全防止幻读,只能防止不可重复读。但在 MySQL 的 InnoDB 存储引擎中,通过 MVCC 和 Next-Key Lock(间隙锁)的组合实现,Repeatable Read 默认是可以防止幻读的。这种实现机制使得 MySQL 实际上在 Repeatable Read 下具备了接近 Serializable 的效果,但性能更优。
MySQL如何实现事务:
使用undoLog实现原子性(事务回滚)
使用redoLog实现持久性(崩溃恢复)
使用MVCC+锁实现隔离性
binlog配合redo log实现崩溃恢复与主从同步
2. mysql事务机制
MySQL 的事务机制是基于 InnoDB 存储引擎实现的,主要通过 Undo Log、Redo Log、Binlog 和 Buffer Pool 等组件协同工作来保障事务的 ACID 特性。原子性通过 Undo Log 实现回滚,一致性依赖事务的完整执行,持久性通过 Redo Log + WAL 实现崩溃恢复,而隔离性则通过 MVCC 和锁机制(如行锁、间隙锁)来实现。在高并发场景下,MySQL 默认使用 Repeatable Read 隔离级别,并结合 MVCC 技术,既保证了性能,又保证了事务的正确性。
3. 隔离级别,和默认隔离级别?
读未提交,读提交,可重复读,串行化,默认的方式为可重复读,可重复是Mysql默认的隔离级别。
4.MySQL事务隔离等级,怎么实现的
对于读未提交隔离级别:因为可以直接读到未提交的数据,所以直接读取最新的数据即可
对于读提交和可重复读中的快照读(普通select语句):通过read Veiw来实现的,区别在于创建read view的时机不同,可理解为数据快照。读提交隔离级别是在每个语句执行前都重新生成一个read view,而可重复读隔离级别是启动事务时生成一个read view,然后整个事务期间都使用这个read view
针对可重复读中的当前读(select...for update),通过next-key lock(记录锁+间隙锁)的方式解决幻读,在执行语句时加锁,如果其他事务在next-key lock锁的范围插入了一条记录,那么这个插入语句就会被阻塞,无法成功插入。
但是可重复读不是完全解决幻读,比如事务A更新了一条事务B插入的记录,事务A前后两次查询的记录条目就不一致了,发生幻读。
对于可串行化,是通过加读写锁的方式来避免并行访问。
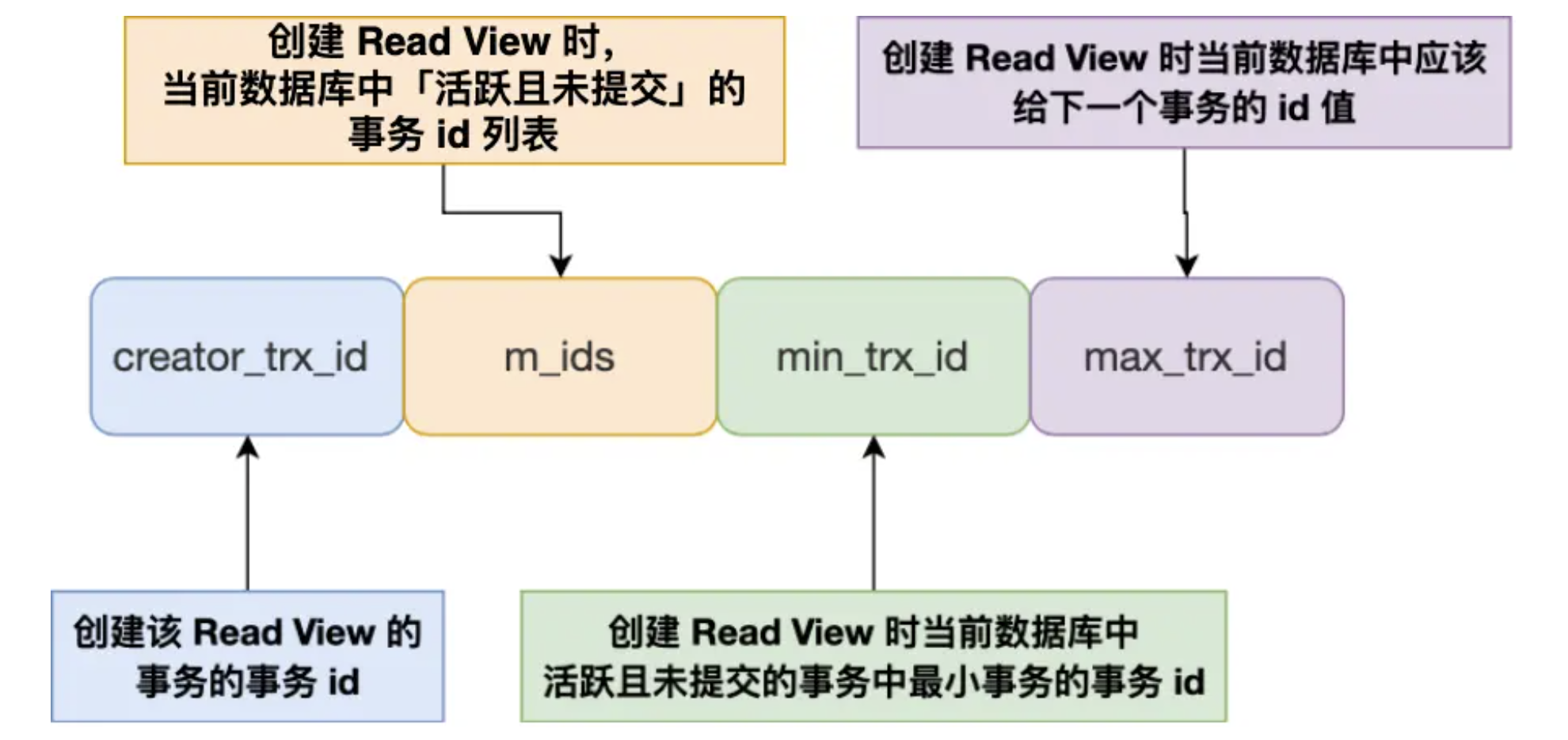
5. read view在MVCC里是如何工作的
MVCC的全称是多版本并发控制,read view主要由四个字段构成:
聚簇索引记录中有两个隐藏列:
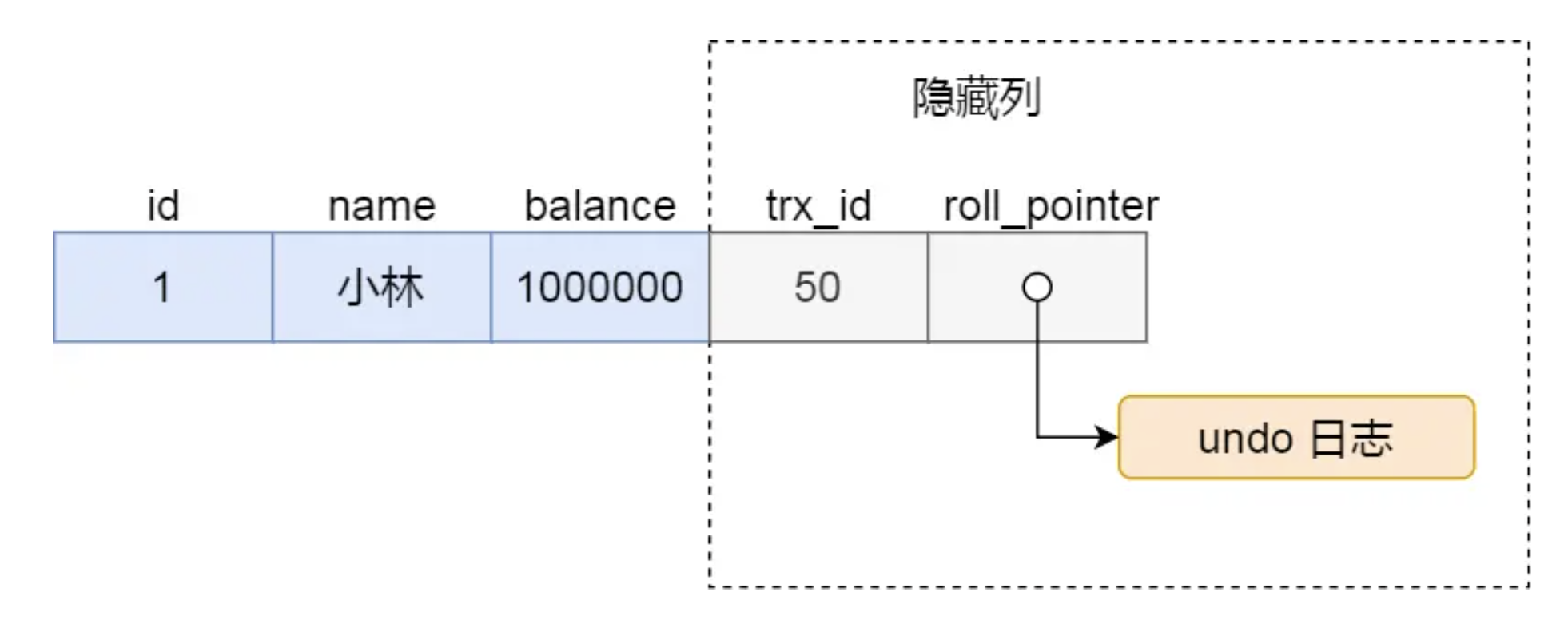
其中,当一个事务对某条聚簇索引记录改动时,就会把该事务的事务id记录在trx_id的隐藏列中,每次对聚簇索引记录的改动,都会把旧版本记录写入undo日志,然后这个隐藏列是个指针,指向一个旧版本记录,于是就可以通过它找到修改前的记录。
在创建read view后,可以把记录中的trx_id分为3种情况:
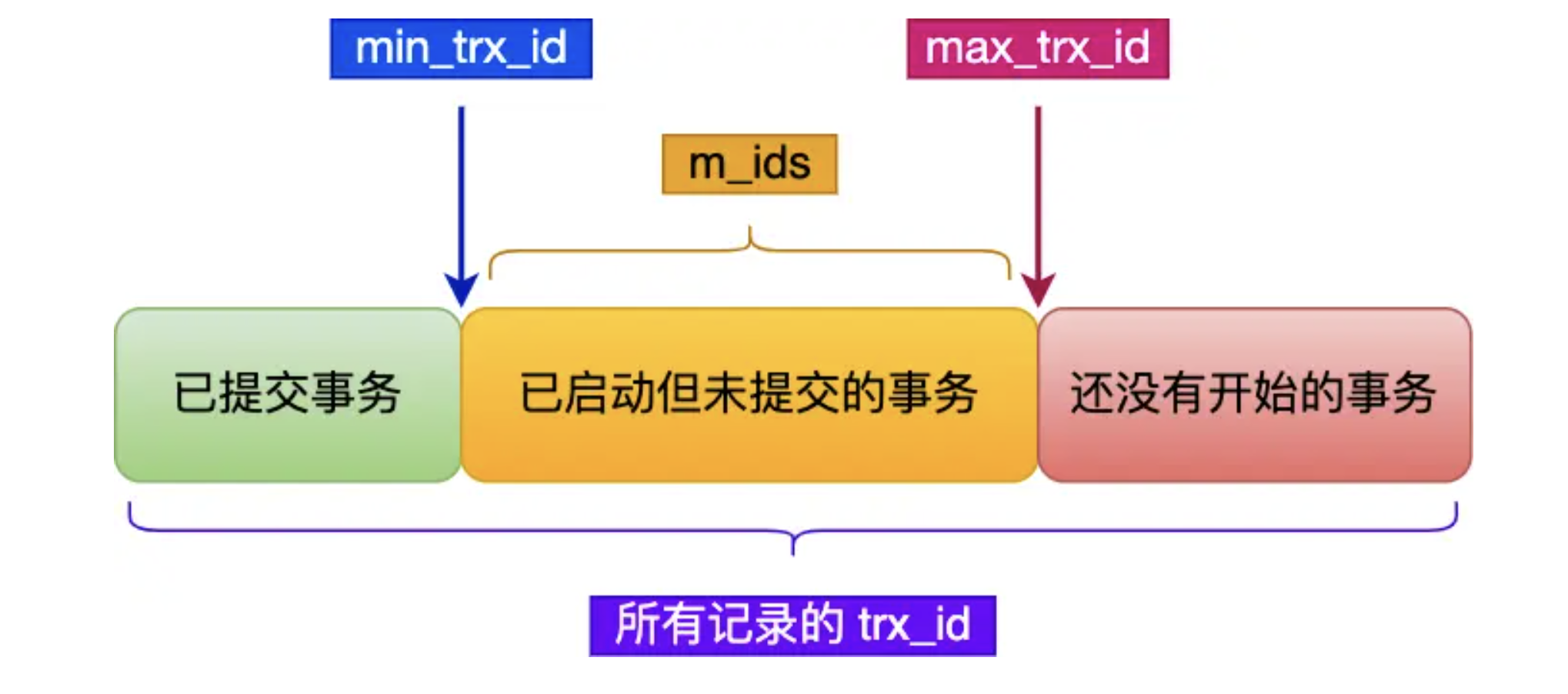
除去自己更新的记录总是可见外,还有如下几种情况:
trx_id小于min_trx_id,说明这个事务是创建该read view时已经提交的,可见
trx_id大于max_trx_id,说明这个事务是创建该read view后才开始的,不可见
如果事务的trx_id在read view的min_trx_id和max_trx_id之间,需要判断是否在m_ids列表中,如果在,说明该事务还在活跃未提交,所以不可见。如果不在,说明该事务已经被提交,可见。
可重复读是具体如何实现的呢:可重复读诗启动事务时生成一个read view,然后整个事务期间都使用这个read view。就是利用上述read view的机制实现的。如果事务B在事务A之后启动,事务A修改了某一条记录,事务B会发现该记录的trx_id在min_trx_id和max_trx_id之间,且在m_id中,说明该记录被未提交的事务修改了,会顺着undo log链条往下找旧版本的记录,直到找到trx_id小于事务B的read view中min_trx_id的记录,完成读取。即使事务A提交,trx_id离开m_ids也不会被读取最新值,因为事务B的read view还是创建时的那一个。
读提交是如何实现的:读提交是每次读取数据时,都会生成一个read view。与可重复读的区别在于,如果事务A提交了,事务B再读取,会读到事务A修改的最新值,因为此时事务B的read view中显示行数据记录中idx_id(事务A),小于min_trx_id,属于已提交事务,所以可见。
锁篇:
1. 列举MySQL锁及使用场景
锁可以分为全局锁、表级锁以及行级锁:
全局锁:执行后,整个数据库都处于只读状态了,这时其他线程的增删改查操作都会被阻塞,全局锁主要用于全库逻辑备份。加上全局锁意味着整个数据库都是处于只读状态。
表级锁:表锁、元数据锁、意向锁等
表锁:
lock tables t_student read 表级别的共享锁,允许当前会话读取被锁定的表,但阻止其他会话对这些表进行写操作
lock tables t_students write 表级别的独占锁,允许当前会话对表进行读写操作,但阻止其他会话对这些表进行任何操作(读或者写)
就是对一张表加锁,除了限制别的线程的读写外,也会限制本线程接下来的读写操作,例如线程A lock table t1 read, t2 write。其他线程不能写t1,不能读写t2. 同时,线程A在执行unlock tables 之前,只能读t1、读写t2,写t1不允许,也不能访问其他表。
元数据锁:
不需要显示使用,对一张表进行CRUD的时候,加的是MDL读锁。对一张表做结构变更操作的时候,加的是MDL写锁。MDL是防止用户对表执行crud的时候,其他线程对表的结构做出变更。在事务执行期间,MDL一直持有,直到事务提交后才会被释放。
意向锁:
在使用InnoDB引擎的表里,对某些记录加上共享锁之前,需要先在表级别加上一个意向共享锁
在使用InnoDB引擎的表里,对某些记录加上独占锁之前,需要先在表级别加上一个意向独占锁
也就是,当执行插入、更新、删除操作,需要先对表加上意向独占锁,然后再加独占锁
行级锁: record lock、gap lock、 Next-Key lock 、插入意向锁
record lock:
称为记录锁,锁住的是一条记录,有S锁和X锁之分。
当一个事务对一条记录加了S型记录锁后,其他事务也可以对该记录加S锁,但不可以加X锁。(S与X不兼容)
当一个事务对一条记录加了X记录锁之后,其他事务既不可以加S锁也不可以加X锁
gap lock:
称为间隙锁,只存在于可重复隔离级别,目的是解决可重复读隔离级别下的幻读,例如id(3,5)之间的间隙锁,id=4的就无法插入了。间隙锁之间是可兼容的,不存在互斥。
Next-Key Lock:
record lock + gap lock,既锁定一个范围,也锁定记录本身,例如(3,5】,不同事务的相同范围的X锁是相互阻塞的,虽然gap lock兼容,但是record lock不相互兼容
插入意向锁:
一个事务在插入一条记录的时候,需要判断插入位置是否被其他事务加了间隙锁。有的话,插入操作就会发生阻塞,直到拥有间隙锁的那个事务提交,再次期间就会生成一个插入意向锁,表明有事务想在某期间插入新纪录,但是现在处于等待状态。
2. 如何理解锁是加在索引上的
在 InnoDB 中,无论是行锁、间隙锁还是 Next-Key Lock,本质上都是基于索引结构加的锁,而不是直接加在记录行本身上。因为 InnoDB 是索引组织表,所有行必须通过索引定位,因此锁加在索引记录上是最合理和高效的方式。如果没有合适的索引,InnoDB 会进行全表扫描,然后通过主键索引记录加锁,这样的性能差、冲突多,是需要避免的。因此我们在实际开发中非常重视 SQL 的索引设计,以确保锁控制粒度合理、效率高
日志篇:
1.如何查看日志最新的200条
查看通用日志,比如tail -n 200 + 日志的路径
查看binlog,二进制log文件,不能用tail,需要用mysqlbinlog工具配合tail查看
2.根据关键字查找大日志文件你会怎么做
如果日志文件非常大,我会优先使用 grep 直接在文件中查找包含关键字的行,例如 grep 'error' mysql-error.log。
grep "error" /var/log/mysql/mysql-error.log
如果需要上下文或人工分析,我会用 less 加 /error 来交互式搜索。
less /path/to/logfile.log
然后按/输入关键字查找
/error
可以按n滚动查看,上下文分析好用
3. 为什么需要undo log
undo log 回滚日志,用于保证事务ACID中的Atomicity原子性,是一种用于撤销回退的日志,在事务没提交之前,MySQL会记录更新前的数据到undo log日志文件,当事务回滚时,利用undo log 回滚。
undo log有两大作用:
1. 实现事务回滚,保障事务原子性:如果事务处理过程中,出现了错误或者用户执行了rollback语句,MySQL可以利用undo log中的历史数据将数据恢复到事务开始之前的状态。
2.实现MVCC多版本并发控制:MVCC是通过read view + undo log实现的。Mysql在执行快照读(普通select语句)时,会根据read view里的信息,顺着undo log的版本链找到满足其可见性的记录
4.为什么需要buffer pool
缓冲池Buffer pool 的作用是提高数据库的读写性能。读取数据时,如果数据在buffer pool就直接读取buffer pool中的数据,否则再去磁盘中读取。当修改数据时,如果数据存在于Buffer pool,那么直接修改buffer pool中数据所在的页,然后将该页设置为脏页,为了减少磁盘IO,不会讲脏页立即写入磁盘,后序由后台线程找一个合适的时间将脏页写入磁盘
buffer除了数据页、索引页等,还有undo页。每次查询一条记录,不是值缓存一条记录,而是把整页数据加载到buffer pool中,再通过页里的页目录取定位某条具体的记录。开启事务后,innoDB更新记录前,首先要记录undo log,比如更新操作前把被更新列的旧值记下来,也就是生成一条undo log,写入buffer pool 的undo页面。
5.为什么需要redo log
buffer pool 是基于内存的,内存总是不可靠的,因此为了防止数据丢失,当一条数据需要更新时,innoDB会先更新内存,标记为脏页,然后将本次对页的修改以redo log的形式记录下来,这时就算更新完成了。后续InnoDB在适当的时候,后台线程会将缓存在Buffer Pool的脏页刷新到磁盘里,这就是WAL(Write-Ahead Logging)技术。
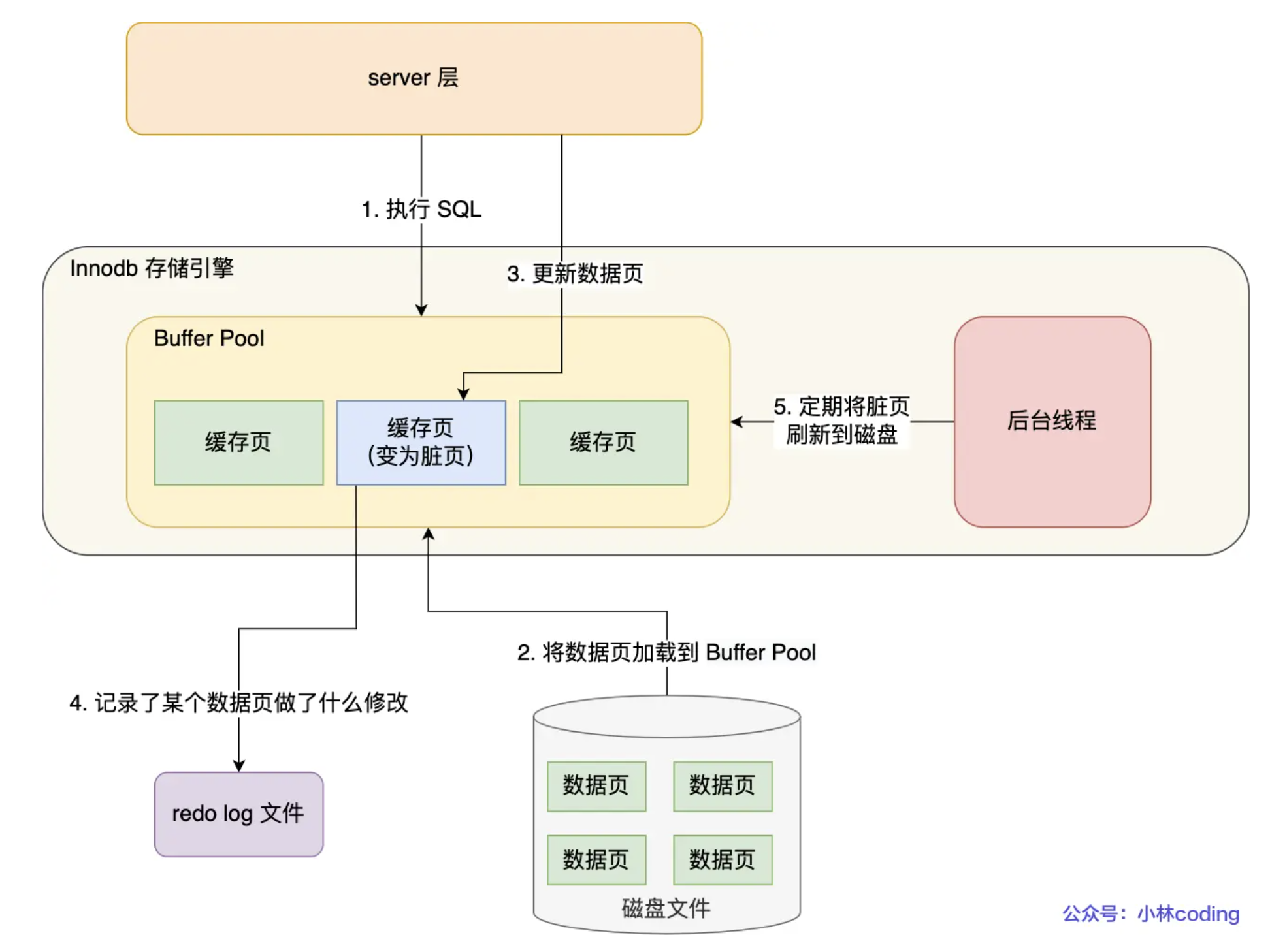
其中,redo log是物理日志,记录了某个数据页做了什么修改,每执行一个日志就会产生这样的一条或者多条物理日志,在事务提交时,只需要先将redo log持久化到磁盘即可,不需要等到缓存将Buffer pool里的脏页数据持久化到磁盘。如果此时系统崩溃,在MYSQL重启后,可以根据redo log恢复数据。
redo log的优势在于是追加操作,在磁盘中时顺序写,而写入数据是先需要找到数据,然后写入磁盘,是随机写,顺序写比随机写高效的多,因此开销更小
redo log的作用有两个:
1.实现事务的持久性,通过redo log + WAL 让mysql有了crash-safe的能力
2.将写操作从随机写变为了顺序写,提高了写入磁盘的性能
6. 为什么要bin log:
Mysql在完成一条更新操作后,server层还会生成一条binlog,等之后事务提交后,会将该事务的执行过程中产生的所有binlog统一写入binlog文件。
binlog文件记录了所有数据库表结构变更和表数据修改的日志,不会记录查询类的操作,比如SELECT。
binlog和redo log区别如下:
1. 适用对象不同:bin log 是MySQL的Server层实现的日志,所有的存储引擎都可以使用。redo log是Innodb存储引擎实现的日志
2. 文件格式不同:binlog有三种格式类型:statement (默认格式,每一条修改数据的SQL都会被记录到binlog中)、row(记录行数据最终被修改成什么样,会使得binlog文件过大)、mixed(会根据不同情况自动使用上面两种)
redo log是物理日志,记录的是某个数据页做了什么修改,比如对xxx表空间中的yy数据页zzz偏移量做了aaa更新
3.写入方式不同: binlog时追加写,不覆盖;redolog是循环写,日志大小固定,写满就保存未被刷入磁盘的脏页日志,然后从头开始写
4.用途不同:binlog用于备份恢复、主从复制,redo log用于掉电等故障恢复
7. Mysql当中主从复制是怎么实现的
MYSQL的主从复制依赖于binlog,也就是记录mysql上所有变化并且以二进制的形式保存在磁盘上。复制的过程就是将binlog中的数据从主库传输到从库上,这个过程一般是异步的,也就是说主库上执行事务操作的线程不会等待复制binlog的线程同步完成。、
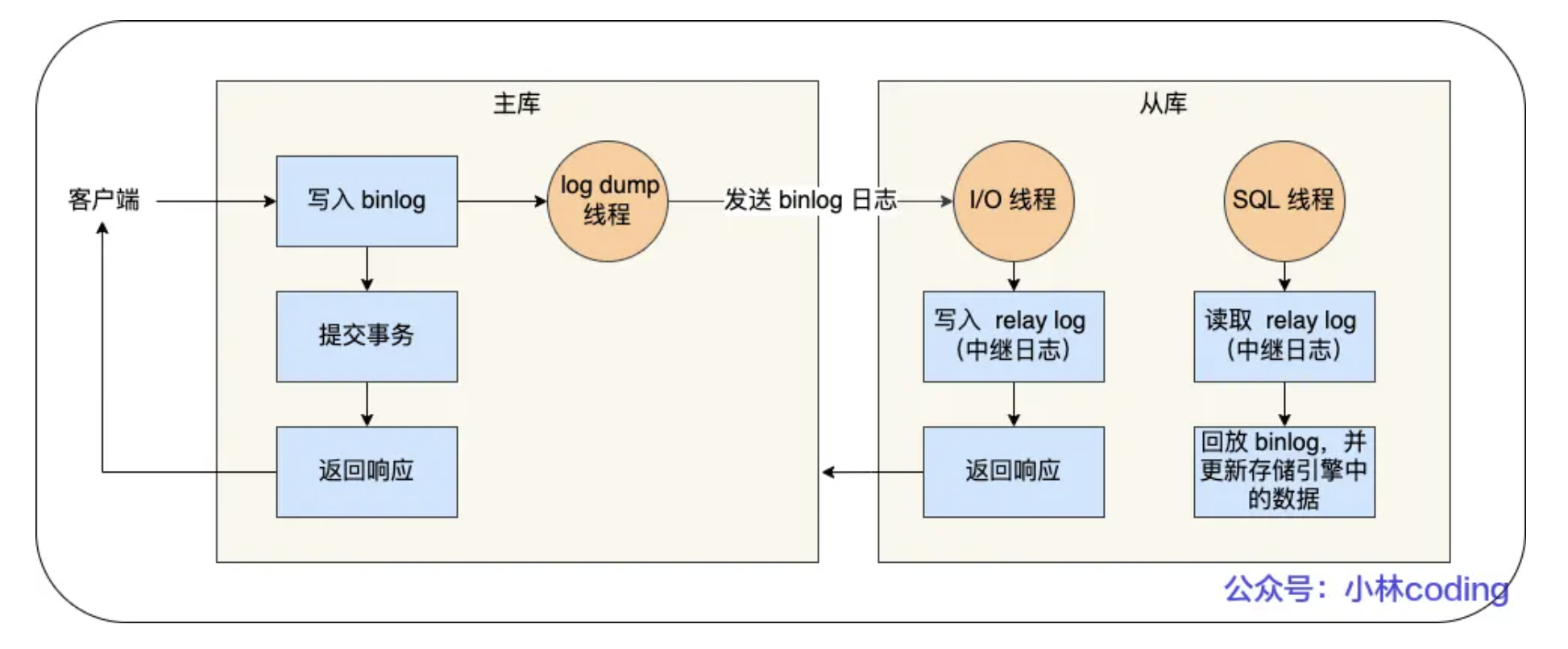
MYSQL集群的主从复制过程分为三步:
1.写入binlog:主库写binlog日志,提交事务,并且更新主库本地存储数据
2.同步binlog:把binlog复制到所有从库,每个从库把binlog写到暂存日志中
3.回放binlog:回放binlog,并更新从库储存引擎中的数据
具体过程为:
1.MYSQL主库在收到客户端提交事务的请求之后,会先写入binlog,再提交事务,更新存储引擎中的数据,事务提交完毕后,返回客户端“操作成功”响应。
2.从库会创建一个专门的io线程,连接主库的log dump线程,接收binlog日志,再把binlog信息写入relay log中继日志里,再返回给主库复制成功响应。
3.从库会创建一个用于回放binlog的线程,去读relay log中继日志,然后回放binlog更新存储引擎中的数据,最终实现主从数据一致性。
在完成主从复制之后,就可以在写数据时只写主库,读数据时只读从库,这样即使写请求锁表,也不会影响读请求的执行
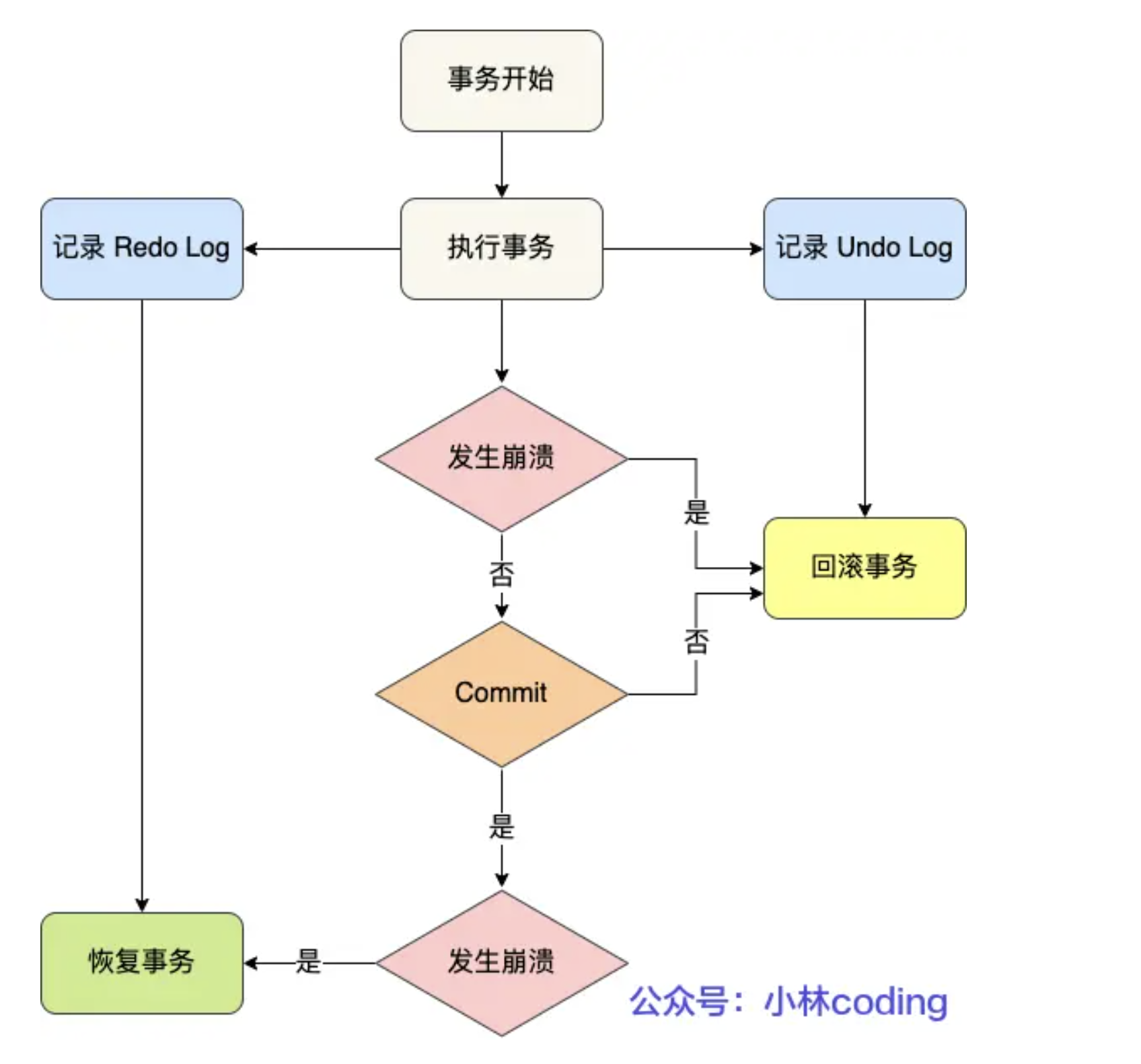
8.事务的执行流程

9. 两段提交过程
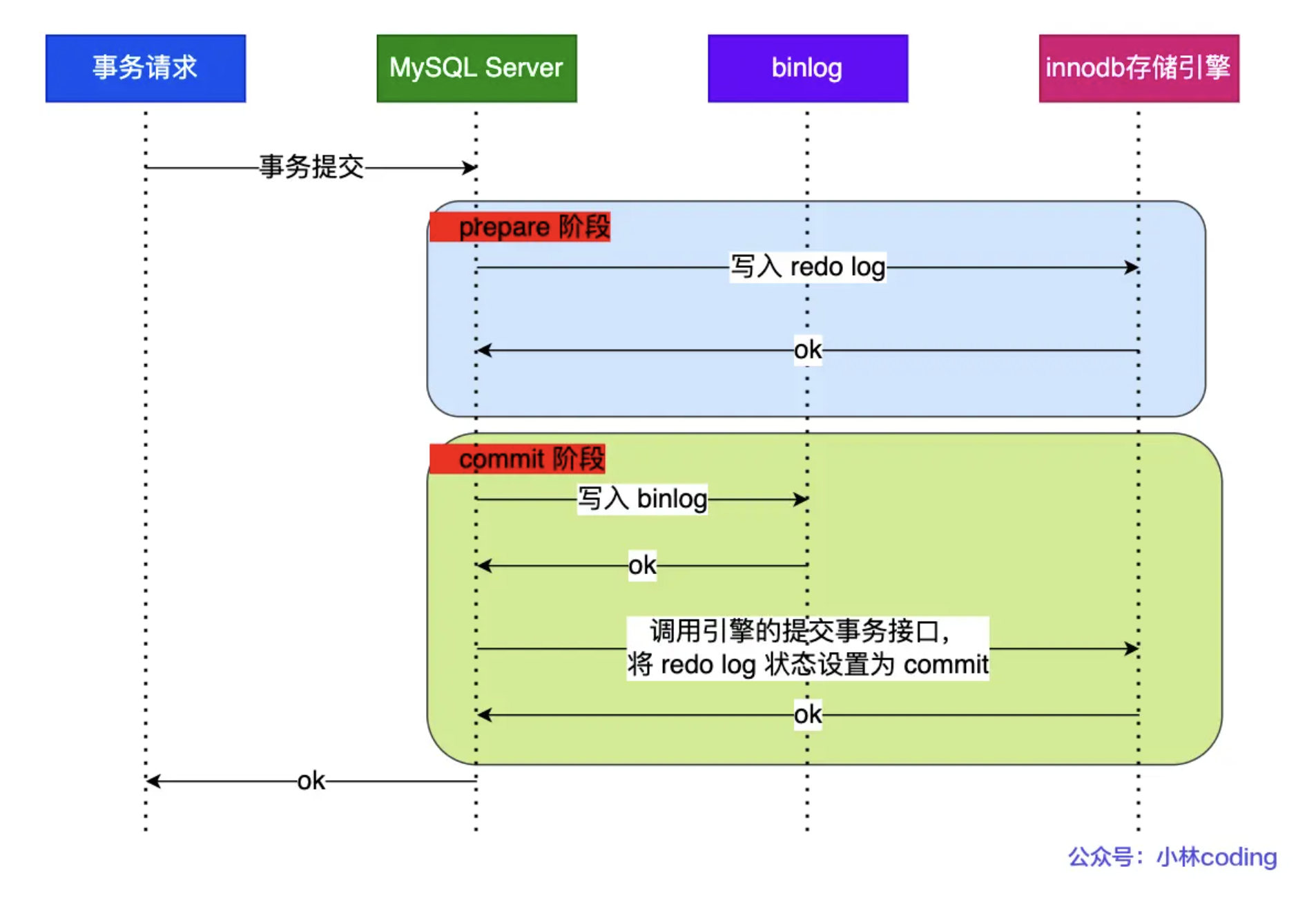
为了保证redo log和bin log这两个独立的逻辑都持久化到磁盘,保持逻辑一致,使用两段提交。MYSQL内部开启一个XA事务,分两阶段完成XA事务的提交。
prepare阶段将XID写入到redolog,同时将redo log对应的事务设置为prepare,然后redo持久化到磁盘。
commit阶段把XID写入binlog,将binlog持久化到磁盘,然后将redo log状态设置为commit,返回成功即可
如果发生崩溃,先检查redo log是否处于prepare状态,然后拿着redo log中的XID去binLog中查看是否存在。如果不存在说明redo完成刷盘但是binlog没有,回滚事务。如果存在说明都完成了刷盘,则提交事务
其他:
1. MySQL 行转列?
一般是使用case when + 聚合函数来实现
SELECT
name,
MAX(CASE WHEN subject = '数学' THEN score END) AS 数学,
MAX(CASE WHEN subject = '英语' THEN score END) AS 英语
FROM
scores
GROUP BY
name;
在行转列中使用 MAX(CASE WHEN ...) 是为了在 GROUP BY 后对每组生成一列值。MAX() 的本意并不是求最大,而是作为聚合函数让 SQL 语法通过,并提取唯一值。
2.MySQL 里如何判断if条件的?
1.三元表达式:IF(expr, true_val, false_val)(函数)
2.流程控制语句 if..then..else..end
3.case when,支持多个条件的判断
SELECT name,
CASE
WHEN score >= 90 THEN '优秀'
WHEN score >= 60 THEN '及格'
ELSE '不及格'
END AS result
FROM student;
3. 先更新数据库再更新缓存会发生情况
如果先更新数据库,再更新缓存,在高并发下可能会发生缓存脏读问题。原因是数据库更新后还没来得及更新缓存,就有另一个线程读到了旧的缓存数据,导致数据不一致。为避免这种问题,推荐使用延迟双删策略,确保缓存命中后读取的数据一定是新值。
延迟双删是一种解决数据库与缓存一致性问题的策略,核心流程是先删除缓存,再更新数据库,然后延迟一段时间再次删除缓存,以清除可能在这段时间被其他线程回填的旧数据。它简单有效,适用于大多数中等并发场景,是互联网系统中常用的缓存一致性保障方案之一
4. 怎么保证数据库缓存的一致性
因为更新操作有两个副本:数据库 + 缓存,如果并发写操作或网络延迟顺序错误,就可能导致缓存是旧值,数据库是新值,造成脏读。 所以上述的延迟双删是一个很不错的选择,还有分布式锁等
5. 慢sql排查思路
1.首先开启并查看慢查询日志,找到具体的慢sql问题
2.使用explain分析执行计划,重点关注key:使用了那个索引、rows扫描的行数、Extra是否使用了index
3.查看表结构和索引情况,看是否缺少合适的索引、是否使用了函数、模糊匹配、类型转换等导致索引失效
一般情况下问题在于:索引未命中、数据量大(无limit分页)、排序、Join不当
6. select、group by,order by,having,先后执行顺序
SQL 的实际执行顺序与书写顺序不同,通常按照:FROM → WHERE → GROUP BY → 聚合计算(如count) → HAVING → SELECT → ORDER BY → LIMIT 进行。WHERE 是对原始数据做行级过滤,而 HAVING 是对分组后的聚合结果做过滤,ORDER BY 和 LIMIT 是在所有过滤计算完成后执行的。
SELECT name, COUNT(*) as cnt
FROM students
WHERE age > 18
GROUP BY name
HAVING cnt > 2
ORDER BY cnt DESC
LIMIT 10;
7. 写SQL,学生表和成绩表,找出总成绩排名前三的学生班级,姓名和总成绩
-- 学生表 student
id | name | class
-----|--------|-------
1 | 张三 | 一班
2 | 李四 | 二班
3 | 王五 | 一班-- 成绩表 score
student_id | subject | score
-----------|---------|-------
1 | 语文 | 90
1 | 数学 | 95
2 | 语文 | 85
2 | 数学 | 88
3 | 数学 | 99
3 | 语文 | 98
SELECT s.class,s.naame,SUM(sc.score) AS total_score
FROM student s
JOIN score sc ON s.id = sc.student_id
GROUP BY s.id
ORDER BY total_score DESC
LIMIT 3; 8. 主键和唯一键的区别
主键和唯一键都能保证字段值的唯一性,但主键是表的唯一标识,不能有 NULL,一个表只能有一个主键,且默认使用聚簇索引。而唯一键可以有多个,字段允许为 NULL(且多个 NULL 不视为重复),默认使用二级索引。实际建模中,一般用主键作为实体标识,用唯一键约束邮箱、手机号等业务唯一字段
9. SQL语句优化思路
| 步骤 | 说明 |
|---|---|
| ① 明确业务目标 | 理解 SQL 的目的,确认是否可以改写 |
| ② 分析执行计划 | 用 EXPLAIN 或 EXPLAIN ANALYZE |
| ③ 检查索引使用情况 | 是否命中索引?索引是否合适? |
| ④ 避免低效操作 | 避免 SELECT *、OR、函数/类型转换 |
| ⑤ 控制数据量 | LIMIT、分页、分区、分表等策略 |
| ⑥ 数据库参数与结构优化 | 缓存设置、buffer pool、连接数、表结构调整等 |
10. 面试官:数据库了解多少?
我对数据库整体有一定了解,主要使用的是 MySQL。在项目中我负责过表结构设计、SQL 编写与性能优化。我熟悉 MySQL 的事务机制、索引类型与优化策略,知道 InnoDB 存储引擎的实现,比如使用 B+ 树索引、MVCC 实现事务隔离。对 SQL 优化方面,我用过 EXPLAIN 分析执行计划,知道如何避免索引失效、如何用覆盖索引、控制分页性能等。
在事务方面,我了解四种隔离级别的区别,知道可重复读与幻读问题,以及如何通过间隙锁防止幻读。在锁方面,了解行锁、表锁、意向锁、间隙锁的使用场景和区别。
此外,我也了解一些数据库高可用相关的知识,比如 MySQL 的主从复制原理、binlog、延迟双删保证缓存一致性等。
11. 面试官:数据库怎么拼接字符串
在 MySQL 中拼接字符串通常使用 CONCAT() 或 CONCAT_WS() 函数。CONCAT() 是直接拼接多个字段或字符串,CONCAT_WS() 允许我们设置一个分隔符并自动忽略 NULL 值。在实际开发中我经常用这两个函数来格式化输出,比如拼接姓名、地址、日志描述等内容。
SELECT CONCAT(first_name, ' ', last_name) AS full_name
FROM users;
SELECT CONCAT_WS('-', province, city, district) AS location
FROM address;
截取字符串:
SELECT SUBSTRING('ShawnXiao', 1, 5); -- 输出:Shawn
| 参数 | 含义 |
|---|---|
str |
原始字符串 |
start |
开始位置(从 1 开始) |
length |
可选,截取多少个字符 |
12. 面试官:按月份统计具体出生人名(Java)
我:HashMap,Key 为月份,Value 出生人名(集合)
Map<Integer, List<String>> monthToNames = new HashMap<>();
// 假设persons是Person对象列表,含name和birthDate字段
for (Person person : persons) {
int month = person.getBirthDate().getMonthValue();
// LocalDate获取月份
monthToNames.computeIfAbsent(month, k -> new ArrayList<>()).add(person.getName());
}
// 输出结果
monthToNames.forEach((month, names) -> System.out.println(month + "月: " + String.join(", ", names)));
13. 一条sql语句从客户端发出,到返回结果到客户端中间经过了什么?
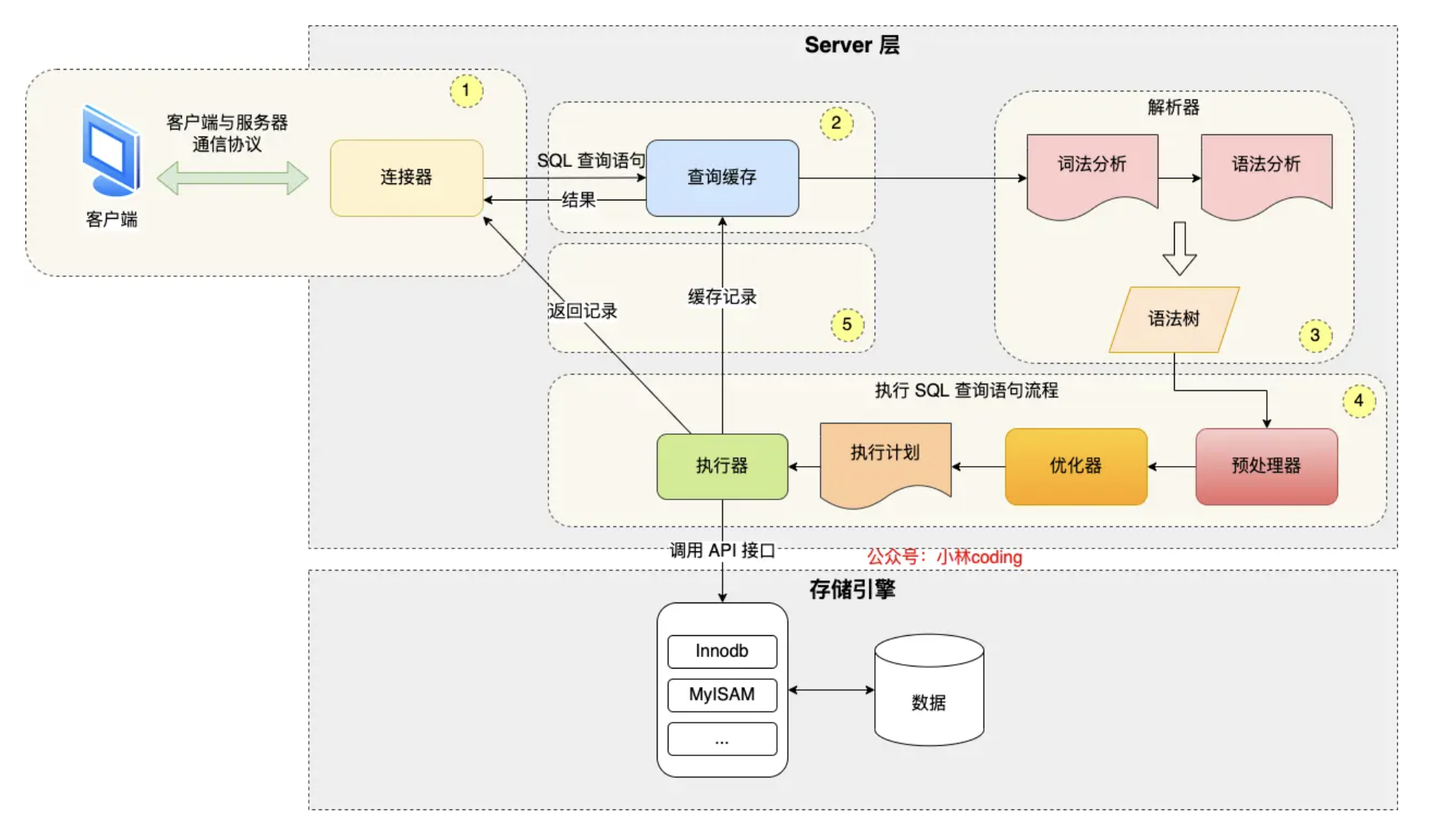
mysql 的架构一共分为两层,server层和存储引擎层。
server层负责建立连接、分析和执行sql,储存引擎层负责数据的存储和提取。
第一步是连接器,通过TCP协议,建立连接、管理连接、校验用户身份
第二步查询缓存,是Mysql先解析处sql语句的第一个字段,如果是select语句,mysql就会先去查询缓存里查找缓存数据,如果命中直接返回,未命中向下继续执行。mysql8.0已经删除这个模块
第三步是通过解析器解析sql,完成词法分析和语法分析,构建语法树,看sql语句是否正确,并方便模块后续读取表名、字段等。
第四步是执行sql,经过解析器解析后就进入执行阶段了,可分为三个阶段:预处理阶段、优化阶段、执行阶段。预处理阶段查询语句中的表或者字段是否存在,扩展*为所有列。优化器阶段就是为基于成本考虑,为sql语句制定一个最小的执行计划,比如选择索引。最后执行阶段根据执行计划执行sql语句,读取记录,再返回给客户端
14. 一个超级大表,有上亿条记录,进行select order by会触发什么,底层是怎么做的
如果在一个上亿记录的大表上执行 ORDER BY,如果排序字段能完全匹配有序的 B+ 树索引,且排序方向一致,就会使用“索引顺序扫描”,避免额外排序;否则MySQL 会先扫描全表,然后使用 filesort 机制对数据进行排序。如果数据超过内存 sort_buffer_size,就会触发外部排序,创建临时文件写磁盘,严重拖慢性能。
15. olap场景下大量聚集统计sql如何优化?
在 OLAP 场景下,我们经常面对超大表的多维度聚合查询。为了提升查询性能,我会从多个方面优化:
第一,在数据模型层,我会使用宽表设计、分区分桶表,预聚合表或物化视图减少实时计算;
第二,在存储引擎选择上,我会优先选用支持列式存储的系统如 ClickHouse、Doris,它们对聚合操作特别友好;
第三,在执行层,我会合理利用并发计算框架,比如 SparkSQL 或 Trino 来并行处理大规模数据。
此外,SQL 本身也要注意结构优化,比如避免 DISTINCT、合理使用 GROUP BY、限制返回数据量等