一、 Silu、Swish、GLU和SwiGLU的关系
首先说明下Silu、Swish、GLU和SwiGLU的关系。
Swish的公式如下:
其中 是sigmoid函数,
是可学习参数或固定为1,按照严格定义,当
= 1 的时候,Swish就等价于Silu。
GLU的公式如下:
SwiGLU的公式如下:
先说明下,GLU和SwiGLU并不是激活函数,而是一种门控网络,它将激活函数的输出作为门控信号。GLU使用的是sigmoid激活函数,而SwiGLU使用的是Swish激活函数。
在下图中,Swish激活函数是指“Act”部分,而SwiGLU包含上面的两个Linear、Act以及逐位乘操作。
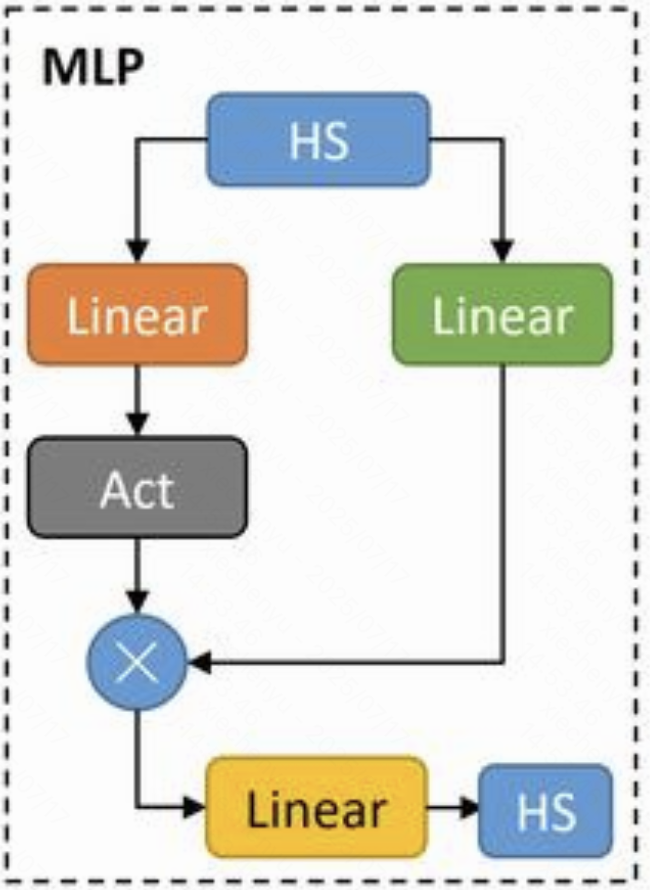
二、LLM部分使用SwiGLU
在Qwen2.5和Qwen3的MLP部分使用的激活函数是Silu,从源代码中可以看到,config.hidden_act==silu, 对应的激活函数就是nn.SiLU。在技术报告中之所以会说使用的技术是SwiGLU,是因为采用了门控机制。
class Qwen3MLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=False)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=False)
self.act_fn = ACT2FN[config.hidden_act] ## config.hidden_act==silu
def forward(self, x):
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_proj
ACT2CLS = {
"gelu": GELUActivation,
"gelu_10": (ClippedGELUActivation, {"min": -10, "max": 10}),
"gelu_fast": FastGELUActivation,
"gelu_new": NewGELUActivation,
"gelu_python": (GELUActivation, {"use_gelu_python": True}),
"gelu_pytorch_tanh": PytorchGELUTanh,
"gelu_accurate": AccurateGELUActivation,
"laplace": LaplaceActivation,
"leaky_relu": nn.LeakyReLU,
"linear": LinearActivation,
"mish": MishActivation,
"quick_gelu": QuickGELUActivation,
"relu": nn.ReLU,
"relu2": ReLUSquaredActivation,
"relu6": nn.ReLU6,
"sigmoid": nn.Sigmoid,
"silu": nn.SiLU,
"swish": nn.SiLU,
"tanh": nn.Tanh,
}三、ViT部分使用QuickGELU
Qwen2.5-VL的视觉编码器部分的VisionMLP部分使用的激活函数是QuickGELU。
torch.nn.functional.gelu中定义的GELU的公式如下:
对比之下,transformers库中定义的QuickGELU的公式如下:
乍一看,似乎QuickGELU就是Swish,只是 ,从形式上看确实如此,但实际上,这个1.702是一篇研究对GELU进行近似拟合得到的参数,本质上激活函数的曲线是与GELU基本一致,只是计算上采用了类似Swish的更简单的计算方法。
class GELUActivation(nn.Module):
"""
Original Implementation of the GELU activation function in Google BERT repo when initially created. For
information: OpenAI GPT's GELU is slightly different (and gives slightly different results): 0.5 * x * (1 +
torch.tanh(math.sqrt(2 / math.pi) * (x + 0.044715 * torch.pow(x, 3)))) This is now written in C in nn.functional
Also see the Gaussian Error Linear Units paper: https://arxiv.org/abs/1606.08415
"""
def __init__(self, use_gelu_python: bool = False):
super().__init__()
if use_gelu_python:
self.act = self._gelu_python
else:
self.act = nn.functional.gelu
def _gelu_python(self, input: Tensor) -> Tensor:
return input * 0.5 * (1.0 + torch.erf(input / math.sqrt(2.0)))
def forward(self, input: Tensor) -> Tensor:
return self.act(input)
class QuickGELUActivation(nn.Module):
"""
Applies GELU approximation that is fast but somewhat inaccurate. See: https://github.com/hendrycks/GELUs
"""
def forward(self, input: Tensor) -> Tensor:
return input * torch.sigmoid(1.702 * input)