在 PyTorch 中,DataLoader是torch.utils.data模块中的一个重要类,用于将数据集包装成可迭代对象,在训练和测试模型时提供了高效、便捷的数据加载和批处理功能。
主要作用:批量处理数据:将数据集中的样本整理成一个个批次(batch),方便模型进行一次处理多个样本,加速训练过程。例如,设置batch_size=32,就会每次从数据集中取出 32 个样本组成一个批次。
- 数据打乱:在训练过程中,为了让模型更好地学习数据特征,避免过拟合,可以通过设置
shuffle=True,在每个 epoch 开始时打乱数据顺序。 - 多线程加载:利用多个线程并行加载数据,提高数据加载效率,尤其在处理大型数据集时效果显著。通过
num_workers参数指定加载数据的线程数。 - 自定义数据处理:支持对数据进行自定义的预处理和增强操作,结合
Dataset类的transform和target_transform参数,可对输入数据和标签进行灵活处理。
关键参数:
dataset:必填参数,指定要加载的数据集,是继承自torch.utils.data.Dataset的类的实例,如torchvision.datasets.CIFAR10。batch_size:每个批次包含的样本数量,默认值为 1。例如,设置batch_size=64,意味着每个批次有 64 个样本。shuffle:是否在每个 epoch 开始时打乱数据顺序,是一个布尔值,默认值为False。在训练时,通常设为True。num_workers:加载数据时使用的子进程数,默认值为 0(意味着在主进程中加载数据)。在处理大型数据集或复杂数据预处理时,适当增加该值可以加快数据加载速度。但设置过高可能会占用过多系统资源,甚至导致性能下降。collate_fn:用于将一个批次中的样本整理成合适格式的函数,默认的整理方式适用于大多数情况。但在处理一些特殊数据结构(如变长序列)时,需要自定义该函数。drop_last:是否丢弃最后一个不完整的批次,是一个布尔值,默认值为False。如果设为True,当数据集样本数量不能被batch_size整除时,最后一个不完整的批次将被丢弃。
使用示例
以加载 CIFAR10 数据集为例:
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载训练集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
# 创建训练集DataLoader
train_loader = DataLoader(
dataset=train_dataset,
batch_size=32,
shuffle=True,
num_workers=2,
drop_last=True
)
# 遍历DataLoader
for epoch in range(2): # 训练2个epoch
for images, labels in enumerate(train_loader):
# 这里进行模型训练相关操作,如前向传播、计算损失、反向传播等
代码练习:
import torchvision
from torch.utils.data import DataLoader
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriter
dataset_transform = transforms.Compose([
transforms.ToTensor()
])
transforms = transforms.Compose([
transforms.ToTensor()
])
test_data = torchvision.datasets.CIFAR10("./torchvision_dataset", train=False, transform=transforms, download=True)
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
# 测试数据集中第一张图片集及target
img, target = test_data[0]
print(img.shape)
print(target)
step = 0
writer = SummaryWriter("dataloader")
print(test_loader)
for epoch in range(2):
for data in test_loader:
imgs, targets = data
print(imgs.shape)
writer.add_images("test_data_drop_last{}".format(epoch), imgs, step)
step += 1
writer.close()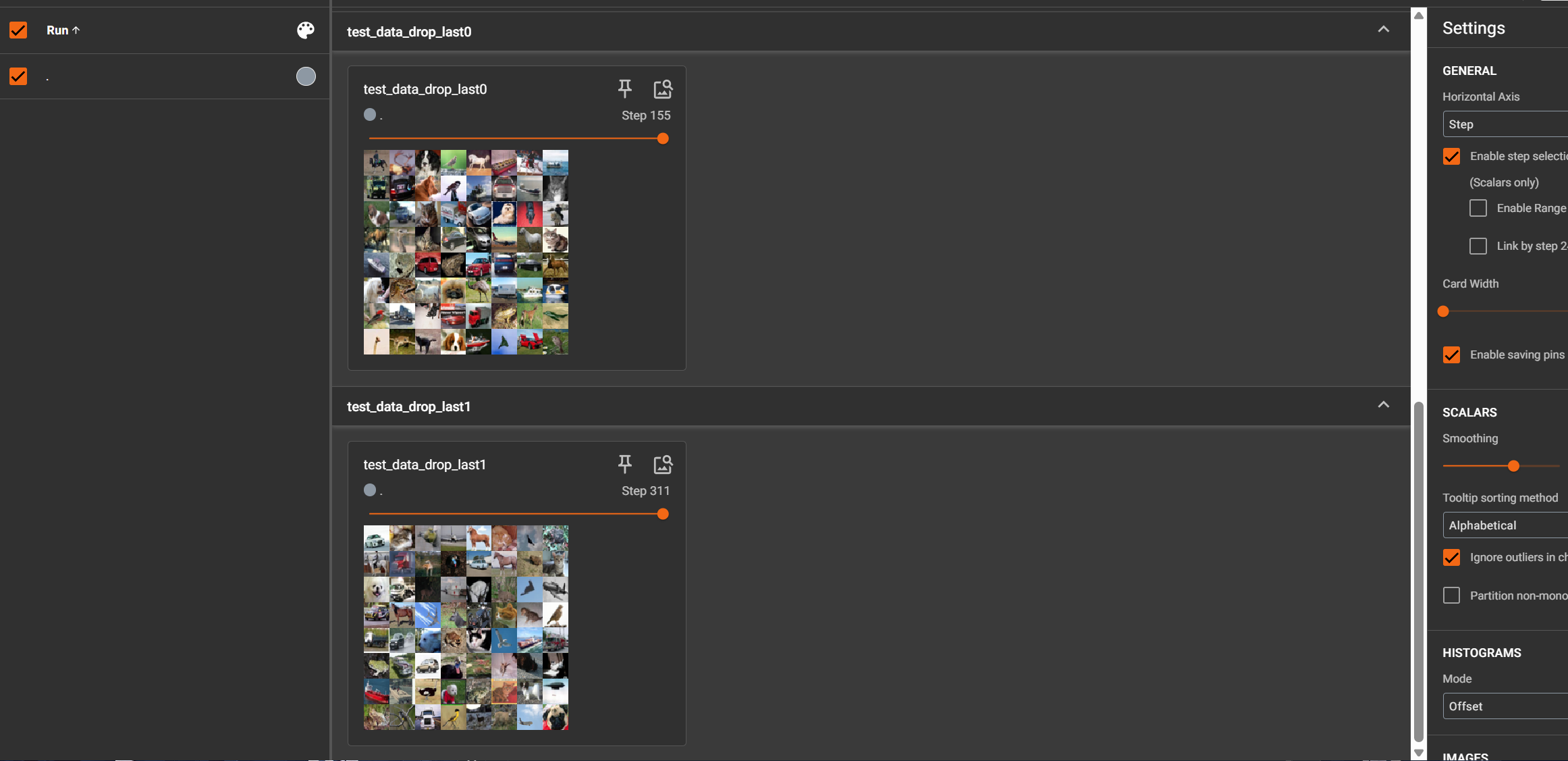
- 首先加载了 CIFAR10 训练集,并定义了数据预处理操作。
- 然后通过
DataLoader将训练集包装成可迭代对象,设置了每个批次包含 64 个样本,每个 epoch 开始时打乱数据,使用 2 个子进程加载数据,丢弃最后一个不完整的批次。 - 最后通过两层循环,外层循环控制 epoch,内层循环遍历每个 epoch 中的批次数据,可在循环内进行模型训练相关的操作。