系列目录
《Web安全之深度学习实战》笔记:第一章 深度学习工具(Keras与Tensorflow图像分类 2个案例)
《Web安全之深度学习实战》笔记:第二章 卷积神经网络进行图像分类(3个案例)
《Web安全之深度学习实战》笔记:第三章 RNN实现影评分类+莎士比亚风格写作(3个案例)
《Web安全之深度学习实战》笔记:第八章 骚扰短信识别(1)
《Web安全之深度学习实战》笔记:第八章 骚扰短信识别(2)
《Web安全之深度学习实战》笔记:第八章 骚扰短信识别(3)
《Web安全之深度学习实战》笔记:第八章 骚扰短信识别(4)
《Web安全之深度学习实战》笔记:第八章 骚扰短信识别(5)
《Web安全之深度学习实战》笔记:第九章 Linux后门检测
《Web安全之深度学习实战》笔记:第十章 用户行为分析与恶意异常行为检测
《Web安全之深度学习实战》笔记:第十一章 Webshell检测
《Web安全之深度学习实战》笔记:第十二章 智能扫描器(1) XSS攻击载荷
《Web安全之深度学习实战》笔记:第十二章 智能扫描器(2) 自动登录
《Web安全之深度学习实战》笔记:第十四章 恶意程序分类识别
目录
本文是《Web安全与深度学习实战》的读书笔记总结,这本书涵盖垃圾邮件/垃圾短信、恶意流量检测、XSS检测、DGA域名、恶意软件分析等场景,结合实战案例讲解如何用机器学习和深度学习模型(CNN、RNN等)解决传统安全难题。

这个笔记总结写在我第三次读这本书,大概与上次读这本书隔了3年左右。
第一次读这本书时大概是2021年,当时初次接触深度学习、对自然语言处理也是才接触没多久,大部分精力都用在调试代码,几乎全部都是自学,要学习并理解每个算法的原理,特征构造方法。由于这个代码最初给的是python2,而且代码使用的库文件有的很旧也导致报错,修改代码就花了很多时间。好在经过了《Web安全之机器学习入门》这本书的学习后,这本书理解起来容易很多,当时读完这本书后只是大概理解了如何将机器学习、深度学习应用到网络安全领域。
第二次读这本书是在大概2022年,这次写了《Web安全与深度学习实战》系列读书笔记博客,将修改好的python3能跑通的程序写到博客中,结合书本分析代码并加入自己的理解,写博客的过程也让自己结合案例思考每种方法的优势和劣势,相对于第一次算是做了个总结。
第三次读这本书是在2025年,打算整理下工智能安全的应用案例,再次阅读整本书把代码再次调试,哈哈,随着库文件的迭代更新,我发现2022年调试好的程序很多又跑不通了,需要重写搭建环境修改代码。相对于前几年,在扎实掌握机器学习和深度学习核心原理的基础上,现在研读相关技术资料和代码实现变得非常高效。在当前人工智能技术快速迭代的背景下,大模型技术(如GPT-4、Codex等)正以惊人的速度发展演进。这些具备强大自然语言理解和代码生成能力的AI系统,正在深刻改变软件开发的工作方式,大大提升了读代码的效率。
一、案例总结
1、第1章 打造深度学习工具箱
《Web安全之深度学习实战》笔记:第一章 深度学习工具(Keras与Tensorflow图像分类 2个案例)
本章节以 Keras 和 TensorFlow 两大框架识别 MNIST 数据集为例,从数据加载、预处理,到模型构建、训练与评估,展示两大框架在深度学习任务中的基本操作步骤。
- 案例1:Keras实现MNIST分类
- 案例2:TensorFlow实现MNIST分类
2、第2章 卷积神经网络(CNN)
《Web安全之深度学习实战》笔记:第二章 卷积神经网络进行图像分类(3个案例)
本章通过CNN、AlexNet、VGG算法来识别图片分类,展示神经网络在图像领域的应用。
- 案例1:使用TFLearn构建卷积神经网络(CNN)用于MNIST手写数字识别。
- 案例2:使用经典的AlexNet模型基于Flower17数据集进行花卉图片分类。
- 案例3:使用经典的VGG模型基于Flower17数据集进行花卉图片分类。
3、第3章 循环神经网络(RNN)
《Web安全之深度学习实战》笔记:第三章 RNN实现影评分类+莎士比亚风格写作(3个案例)
本章讲解RNN的基本概念和应用场景,包括序列分类、序列生成以及序列翻译。
- 案例1:基于LSTM对影评(imdb数据集)进行文本分类。
- 案例2:基于BI-LSTM对影评(imdb数据集)进行文本分类。
- 案例3:基于Char-RNN的莎士比亚风格文本生成模型。
4、第4章 基于OpenSOC的机器学习框架
这一章节讲解OpenSOC机器学习开源框架,没有对应的源码,了解即可。
5、第5章 验证码识别
在 Web 安全领域,验证码识别是保障系统安全的关键防线,本小节实际上就是用KNN、SVM、MLP、CNN识进行图像分类,实际上这些在《Web安全之机器学习入门》中都有讲过,而这些也是非常基础的应用。
- 案例1:使用KNN识别MNIST数据集
- 案例2:使用SVM识别MNIST数据集
- 案例3:使用MLP识别MNIST数据集
- 案例4:使用CNN识别MNIST数据集
6、第6章 垃圾邮件识别
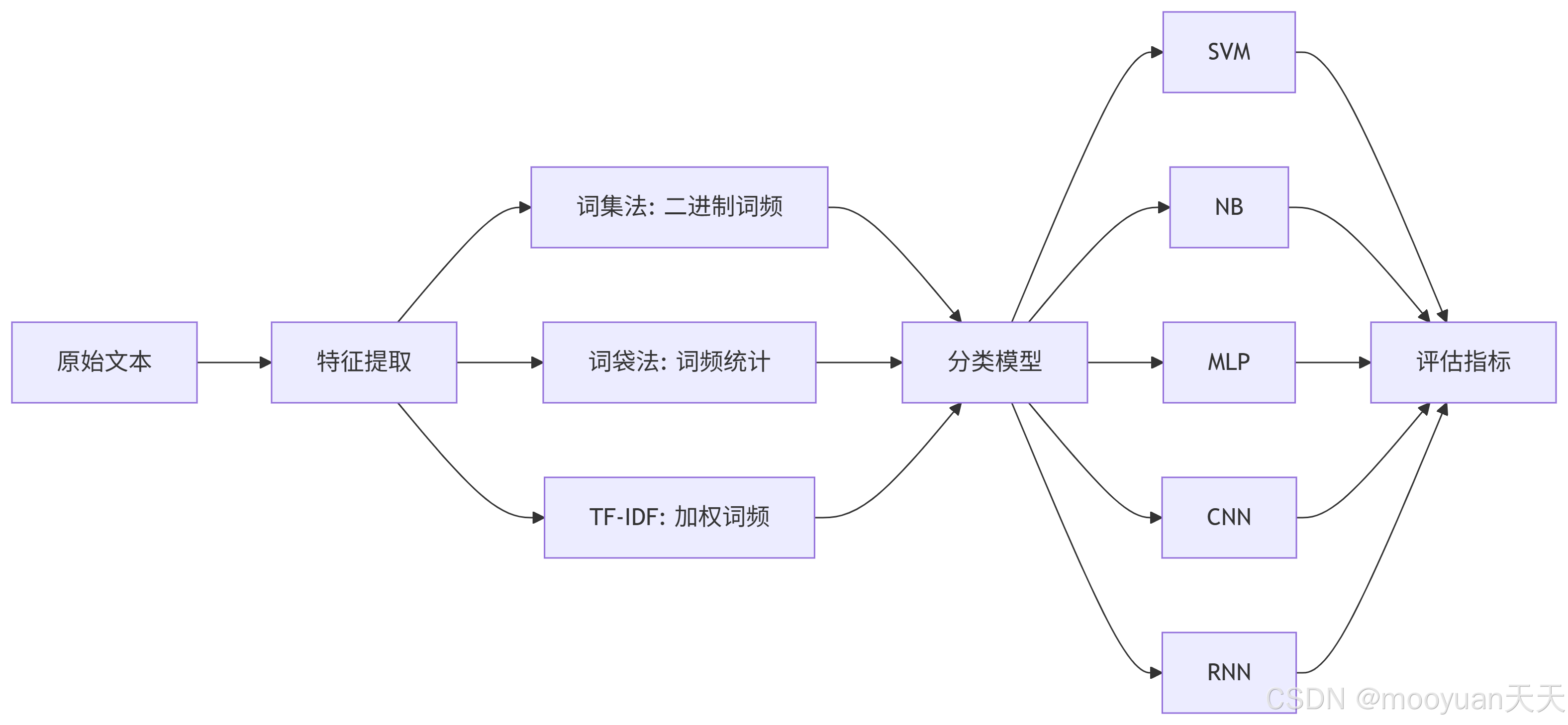
本小节使用Enron-Spam数据集来识别垃圾邮件,使用词集法、词袋法、TFIDF等方法提取数据特征,同时SVM、NB、MLP、CNN和RNN等机器学习的方法来识别垃圾邮件。
7、第7章 负面评论识别
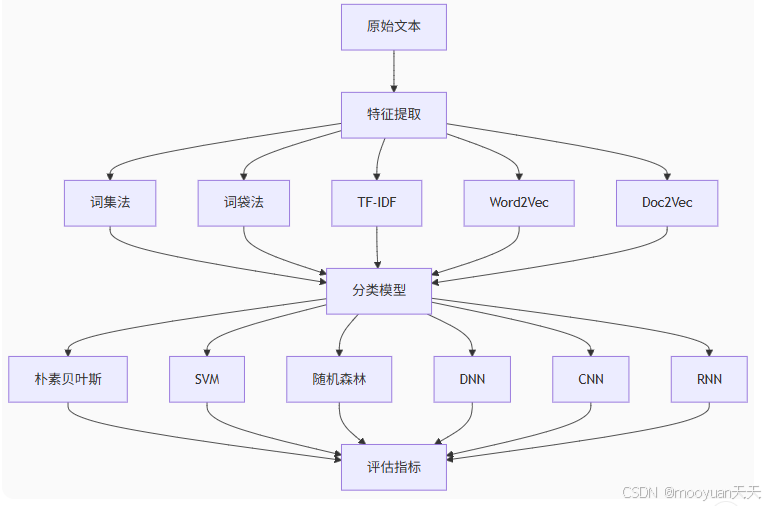
本小节讲述通过imdb数据集,使用词集法、词袋法和TF-IDF法,以及新的Word2Vec和DocVec法进行特征提取,分别构建朴素贝叶斯(NB)、支持向量机(SVM)、随机森林(RF)、深度学习算法(DNN,CNN,RNN)模型来识别负面评论。
8、第8章 骚扰短信识别
《Web安全之深度学习实战》笔记:第八章 骚扰短信识别(1)
《Web安全之深度学习实战》笔记:第八章 骚扰短信识别(2)
《Web安全之深度学习实战》笔记:第八章 骚扰短信识别(3)
《Web安全之深度学习实战》笔记:第八章 骚扰短信识别(4)
《Web安全之深度学习实战》笔记:第八章 骚扰短信识别(5)
本章主要以SMS Spam Collection数据集 为例介绍骚扰短信的识别技术。介绍识别骚扰短信使用的征提取方法,包括词袋和TF-IDF模型、词汇表模型以及Word2Vec和Doc2Ve等c模型,使用的机器学习算法则是包括朴素贝叶斯、支持向量机、XGBoost、MLP、CNN和RNN等算法。
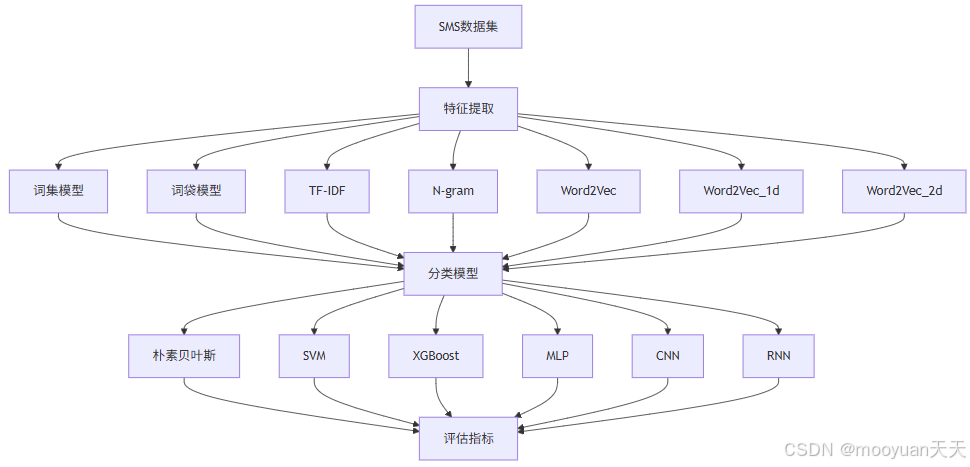
graph TD
A[SMS数据集] --> B[特征提取]
%% 特征提取模块
B --> B1[词集模型]
B --> B2[词袋模型]
B --> B3[TF-IDF]
B --> B4[N-gram]
B --> B5[Word2Vec]
B --> B6[Word2Vec_1d]
B --> B7[Word2Vec_2d]
%% 分类模型模块
B1 --> D[分类模型]
B2 --> D
B3 --> D
B4 --> D
B5 --> D
B6 --> D
B7 --> D
D --> D1[朴素贝叶斯]
D --> D2[SVM]
D --> D3[XGBoost]
D --> D4[MLP]
D --> D5[CNN]
D --> D6[RNN]
%% 评估模块
D1 --> E[评估指标]
D2 --> E
D3 --> E
D4 --> E
D5 --> E
D6 --> E9、第9章 Linux后门检测
《Web安全之深度学习实战》笔记:第九章 Linux后门检测
本章主要以ADFA-LD数据集为例检测Linux系统后门,使用特征提取方法为2-Gram和TF-IDF,构建的机器学习模型包括朴素贝叶斯NB、XGBoost和深度学习之多层感知机MLP。
- 案例1:基于3-Gram和TF-IDF提取特征并构建NB分类模型检测Linux后门
- 案例2:基于3-Gram和TF-IDF提取特征并构建XGBoost分类模型检测Linux后门
- 案例3:基于3-Gram和TF-IDF提取特征并构建MLP分类模型检测Linux后门
10、第10章 用户行为分析与恶意行为检测
《Web安全之深度学习实战》笔记:第十章 用户行为分析与恶意异常行为检测
本章主要以SEA数据集检测用户的恶意行为,使用Wordbag、n-gram、Word2Vec、词集法等方法提取特征,使用NB、XGB-BOOST、MLP、CNN、RNN、Bi-RNN等机器学习方法构建分类模型。
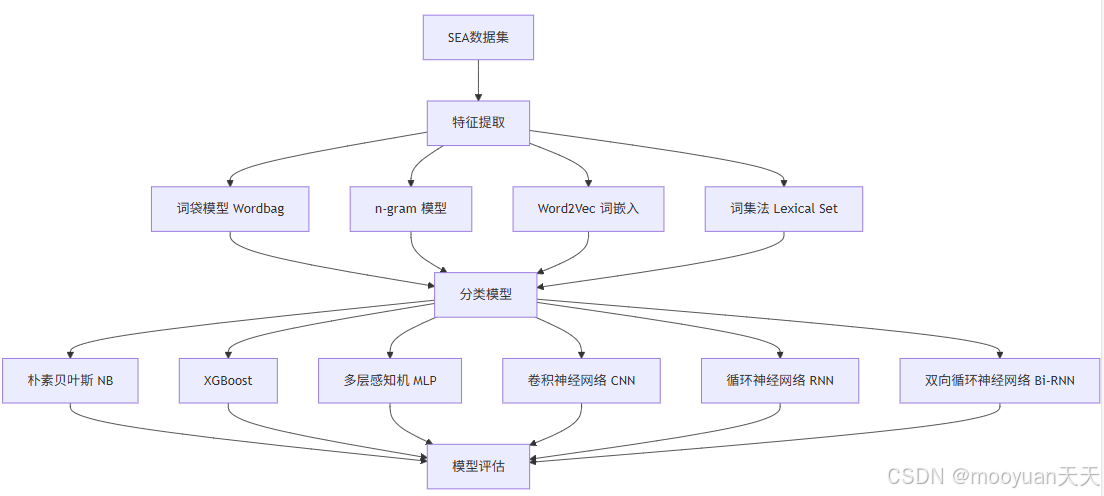
graph TD
A[SEA数据集] --> B[特征提取]
%% 特征提取模块
B --> B1[词袋模型 Wordbag]
B --> B2[n-gram 模型]
B --> B3[Word2Vec 词嵌入]
B --> B4[词集法 Lexical Set]
%% 分类模型模块
B1 --> C[分类模型]
B2 --> C
B3 --> C
B4 --> C
C --> C1[朴素贝叶斯 NB]
C --> C2[XGBoost]
C --> C3[多层感知机 MLP]
C --> C4[卷积神经网络 CNN]
C --> C5[循环神经网络 RNN]
C --> C6[双向循环神经网络 Bi-RNN]
C1--> D[模型评估]
C2--> D
C3--> D
C4--> D
C5--> D
C6--> D11、第11章 WebShell检测
《Web安全之深度学习实战》笔记:第十一章 Webshell检测
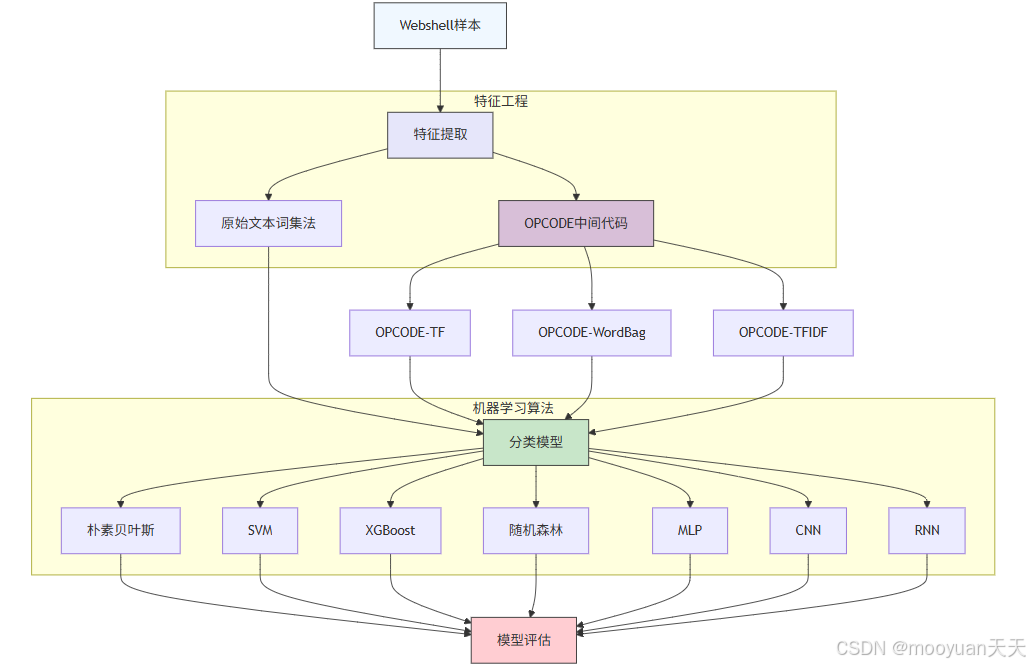
本章通过多种机器学习和深度学习算法来识别webshell ,较新的知识点是opcode的特征处理。其中特征提取的方法共4种,包括原始文本使用词集法提取特征、通过提取OPCODE中间代码,再使用TF法、WordBag法、TF-IDF法提取特征(即OPCODE-TF法、OPCODE-WordBag法、OPCODE-TFIDF法共3种中间代码特征提取法),然后使用NB、SVM、XGBoost、随机森林、MLP、CNN、RNN算法构建模型并评估模型。
graph TD
A[Webshell样本] --> B[特征提取]
%% 特征提取模块
subgraph 特征工程
B --> B1[原始文本词集法]
B --> B2[OPCODE中间代码]
end
%% OPCODE特征子分支
B2 --> C1[OPCODE-TF]
B2 --> C2[OPCODE-WordBag]
B2 --> C3[OPCODE-TFIDF]
%% 模型训练
B1 --> D[分类模型]
C1 --> D
C2 --> D
C3 --> D
subgraph 机器学习算法
D --> D1[朴素贝叶斯]
D --> D2[SVM]
D --> D3[XGBoost]
D --> D4[随机森林]
D --> D5[MLP]
D --> D6[CNN]
D --> D7[RNN]
end
%% 模型评估
D1 --> E[模型评估]
D2 --> E
D3 --> E
D4 --> E
D5 --> E
D6 --> E
D7 --> E
E --> F[精确率]
E --> G[召回率]
E --> H[F1-Score]
E --> I[ROC曲线]
style A fill:#F0F8FF,stroke:#333
style B fill:#E6E6FA,stroke:#333
style B2 fill:#D8BFD8,stroke:#333
style D fill:#C8E6C9,stroke:#333
style E fill:#FFCDD2,stroke:#33312、第12章 智能扫描器
《Web安全之深度学习实战》笔记:第十二章 智能扫描器(1) XSS攻击载荷
《Web安全之深度学习实战》笔记:第十二章 智能扫描器(2) 自动登录
本章节标题为“智能扫描器”,通过两个案例讲解人工智能在网络安全领域的应用。
案例1:通过学习攻击样本,使用RNN的LSMT算法自动生成XSS攻击载荷
案例2:自动识别登录界面,通过Word2Vec分析相似度并生成相似度高的关键词
13、第13章 DGA域名识别
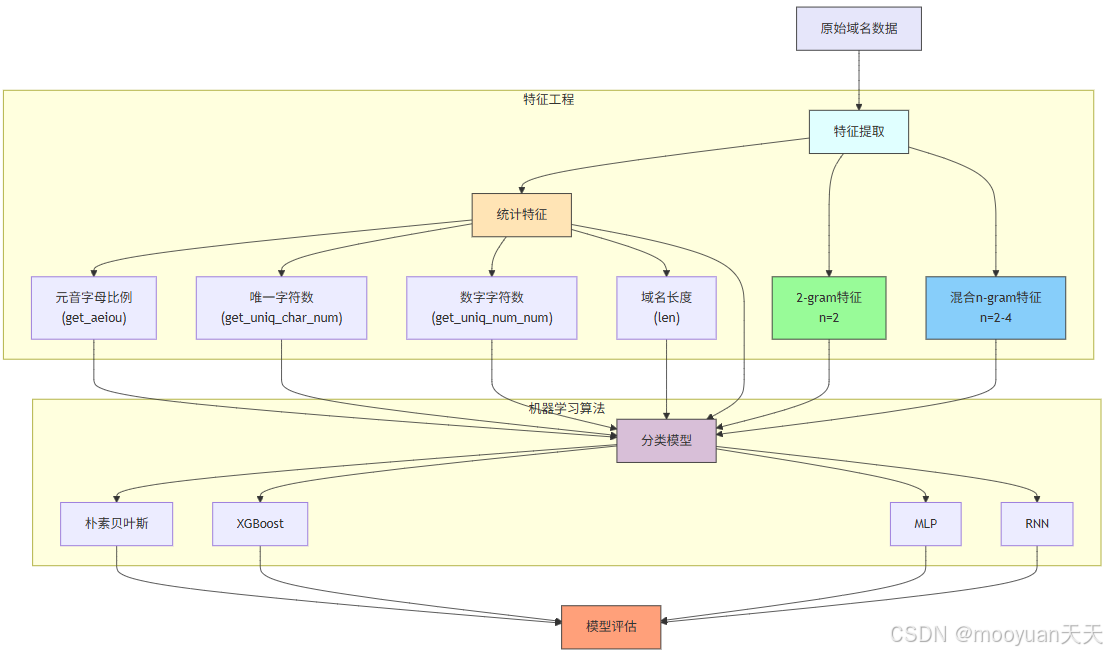
本章聚焦于 DGA 域名检测,采用三种特征提取方法:一是对每个域名计算元音字母比例、唯一字符数量、数字字符数量及域名长度这 4 个特征;二是基于 2-gram 特征(ngram_range=(2, 2))进行提取;三是结合 2-4gram 组合特征(ngram_range=(2, 4))开展提取。在此基础上,运用 NB、XGBoost、MLP 及 RNN 四种机器学习算法进行分类,并对各模型的检测性能展开全面评估,旨在通过多维度特征与多算法的对比分析,探究 DGA 域名检测的有效方案。
graph LR
A[原始域名数据] --> B[特征提取]
%% 特征提取模块
subgraph 特征工程
B --> B1[统计特征]
B1 --> B11["元音字母比例<br>(get_aeiou)"]
B1 --> B12["唯一字符数<br>(get_uniq_char_num)"]
B1 --> B13["数字字符数<br>(get_uniq_num_num)"]
B1 --> B14["域名长度<br>(len)"]
B --> B2["2-gram特征<br>n=2"]
B --> B3["混合n-gram特征<br>n=2-4"]
end
%% 模型训练
B1 --> C[分类模型]
B2 --> C
B3 --> C
subgraph 机器学习算法
C --> C1[朴素贝叶斯]
C --> C2[XGBoost]
C --> C3[MLP]
C --> C4[RNN]
end
%% 模型评估
C1 --> D[模型评估]
C2 --> D
C3 --> D
C4 --> D
B11 --> C
B12 --> C
B13 --> C
B14 --> C
style A fill:#E6E6FA,stroke:#333
style B fill:#E0FFFF,stroke:#333
style B1 fill:#FFE4B5,stroke:#333
style B2 fill:#98FB98,stroke:#333
style B3 fill:#87CEFA,stroke:#333
style C fill:#D8BFD8,stroke:#333
style D fill:#FFA07A,stroke:#33314、第14章 恶意程序分类识别
《Web安全之深度学习实战》笔记:第十四章 恶意程序分类识别
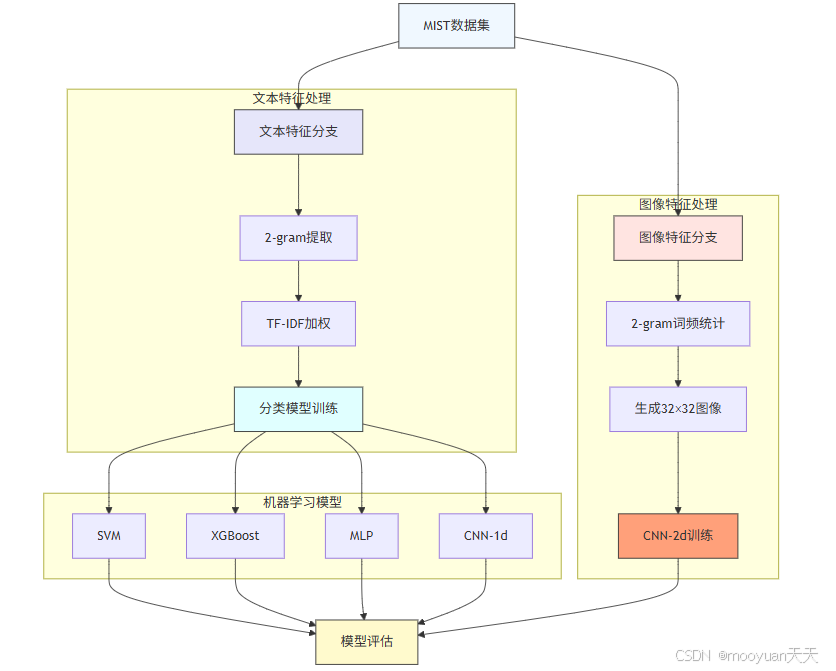
本章主要以MIST数据集(Malware Instruction Set for Behaviour Analysis),通过分析大量恶意程序,提取出静态文件特征以及动态程序行为特征)为例介绍恶意程序的分类识别技术,使用特征提取方法为2-Gram和TF-IDF模型,构建的分类模型包括支持向量机、XGBoost、多层感知机MLP和CNN-2d、CNN-1d算法。
案例1:基于2-gram和TF-IDF提取特征,使用SVM/XGBoost/MLP/CNN-1d算法训练分类模型
案例2:使用2-gram提取1024词频特征并转为32*32图像特征,使用CNN-2d算法训练分类模型
graph TD
A[MIST数据集] --> B[文本特征分支]
A --> C[图像特征分支]
%% 文本特征分支
subgraph 文本特征处理
B --> B1[2-gram提取]
B1 --> B2[TF-IDF加权]
B2 --> D[分类模型训练]
end
%% 图像特征分支
subgraph 图像特征处理
C --> C1[2-gram词频统计]
C1 --> C2[生成32×32图像]
C2 --> E[CNN-2d训练]
end
%% 模型训练
subgraph 机器学习模型
D --> D1[SVM]
D --> D2[XGBoost]
D --> D3[MLP]
D --> D4[CNN-1d]
end
%% 评估模块
D1 --> F[模型评估]
D2 --> F
D3 --> F
D4 --> F
E --> F
style A fill:#F0F8FF,stroke:#333
style B fill:#E6E6FA,stroke:#333
style C fill:#FFE4E1,stroke:#333
style D fill:#E0FFFF,stroke:#333
style E fill:#FFA07A,stroke:#333
style F fill:#FFFACD,stroke:#33315、第15章 反信用卡欺诈
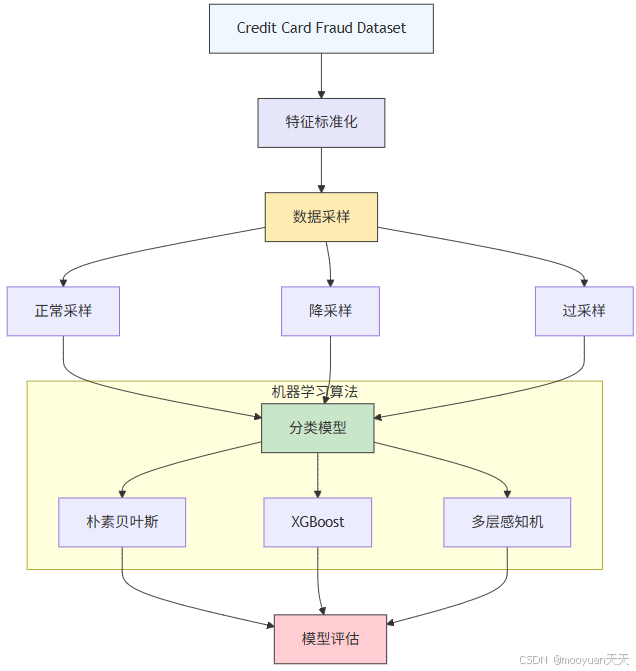
本章节Credit Card Fraud Detection数据集为例子介绍针对信用卡欺诈的检测技术,使用特征提取方法为标准化,然后采样的方法使用正常采样,降采样和过采样三种方法,分类算法包括朴素贝叶斯、XGBoost和多层感知机,然后进行模型评估。
graph TD
A[Credit Card Fraud Dataset] --> B[特征标准化]
%% 数据采样分支
B --> C[数据采样]
C --> C1[正常采样]
C --> C2[降采样]
C --> C3[过采样]
%% 模型训练
C1 --> D[分类模型]
C2 --> D
C3 --> D
subgraph 机器学习算法
D --> D1[朴素贝叶斯]
D --> D2[XGBoost]
D --> D3[多层感知机]
end
%% 模型评估
D1 --> E[模型评估]
D2 --> E
D3 --> E
style A fill:#F0F8FF,stroke:#333
style B fill:#E6E6FA,stroke:#333
style C fill:#FFECB3,stroke:#333
style D fill:#C8E6C9,stroke:#333
style E fill:#FFCDD2,stroke:#333二、源码部分
这本书的源码是本书原始代码基于Python 2.7环境开发,而当前主流技术栈已全面转向Python 3.x版本。这个代码基本上想调试成功每个章节的每个源码都需要修改(python2改为python3),要有这个心理准备,并不是代码一跑就直接通了,除了python2和python3的核心语法变化导致需要修改代码外;很多库文件由于基于老的版本,还会有依赖库兼容性问题,比如部分示例使用的第三方库已停止维护。整体来讲需要改很多代码,比较麻烦。
对于python2的code,由于当前主流技术栈已全面转向Python 3.x版本,想调试成功code要将《Web安全之机器学习入门》书中Python 2环境代码转换为Python 3代码,可以使用Python自带的2to3工具,具体方法如下所示。
(1)对于单个Python文件
2to3 -w 原文件.py(2)对于整个目录
2to3 -w 目录路径/