
作者: Sebastian Barbas Laina, Simon Boche, Sotiris Papatheodorou, Simon Schaefer, Jaehyung Jung, Stefan Leutenegger
单位:慕尼黑工业大学计算、信息与技术学院智能机器人实验室,帝国理工学院计算机系智能机器人实验室,慕尼黑机器人与机器智能研究所,慕尼黑机器学习中心
论文标题:FindAnything: Open-Vocabulary and Object-Centric Mapping for Robot Exploration in Any Environment
论文链接:https://arxiv.org/pdf/2504.08603
主要贡献
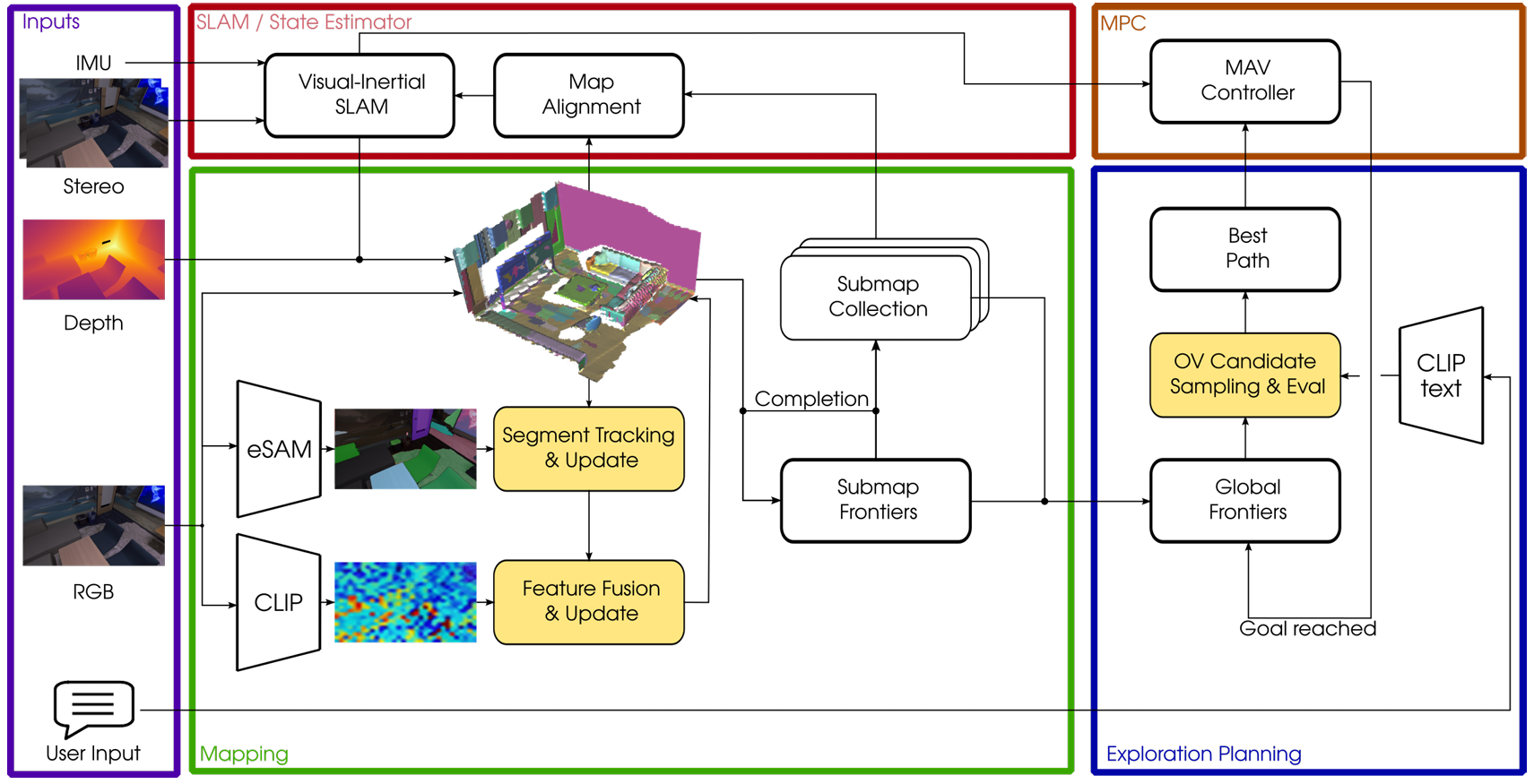
提出了一种能够在实时在线大规模 SLAM 过程中,将语言特征嵌入到体素占据子图中的完整系统,实现了状态最先进的语义一致性。
首次提出了一种能够实时支持部署时和即时自然语言文本查询的 3D 探索系统,这些查询可以调节探索启发式算法。
通过在资源受限的 MAV 上仅依赖于机载计算进行真实世界实验,证明了系统的鲁棒性和计算效率。
研究背景
几何精确且语义丰富的地图表示对于移动机器人的稳健和安全导航以及任务规划至关重要。然而,实时、开放词汇的语义理解在大规模未知环境中仍然是一个未解决的问题。
以往的几何和语义注释地图虽然被广泛使用,但定义一个能够实现复杂任务的地图表示仍然是一个挑战。SLAM 算法通过闭环等漂移校正机制来估计机器人在野外的位姿,但不同的机器人、传感器和环境特性以及应用和任务需求导致没有一种通用的地图表示。
以往的语义信息集成方法受限于语义分割网络的封闭集能力,而新兴的视觉语言模型虽然具有开放词汇的泛化能力,但需要更高的计算能力且输出的高维特征嵌入在 3D 地图聚合时面临内存使用挑战。
研究方法
符号与定义
- 符号定义:
视觉惯性 SLAM(VI-SLAM)系统跟踪带有 IMU 和多个摄像头的移动物体相对于静态世界坐标系 的位置。
IMU 坐标系表示为 ,摄像头坐标系表示为 (使用立体相机,)。
左侧索引表示坐标系,齐次位置向量用斜体表示,可以通过变换矩阵 进行坐标转换。
图像以矩阵形式表示为 ,可以通过像素坐标 获取图像值。
视觉惯性 SLAM
- 系统基础:
基于扩展的 OKVIS2 系统,融合 IMU 测量和立体图像进行状态估计。
系统通过 IMU 因子和视觉关键点提取进行状态估计,同时利用深度信息提高估计精度。
- 状态表示:
状态向量 包括 IMU 帧在世界坐标系中的位置 、方向四元数 、速度 、陀螺仪偏置 和加速度计偏置 。
每次接收到一对立体图像时,系统会估计新的状态 ,并根据需要更新先前的状态 。
- 优化过程:
系统实时进行滑动窗口优化,覆盖最近 帧和 个关键帧。
优化过程包括 IMU 测量、重投影误差、姿态图误差和深度测量的地图对齐因子。
通过优化,系统能够实时校正位姿,提高地图的全局一致性。
体素占据映射
- 映射框架:
使用多分辨率体素占据映射框架 supereight2,通过占用概率的对数几率表示环境。
区分占用、观察到的自由空间和未观察到的空间,这对于安全路径规划和自主导航至关重要。
- 子图策略:
将感知信息整合到有限内存占用的小型子图中,允许快速更新。
子图的位姿可以随着任务的进行和漂移校正机制更新估计轨迹而刚性变换,实现更准确一致的全局地图重建。
- 地图变形:
每个子图与状态估计器的关键帧关联,随着关键帧的位姿更新,子图的位姿也会相应更新。
视觉语言特征融合
- 特征提取:
使用 CLIP 模型(ViT-L/14)作为视觉语言特征提取器,生成每个像素的 768 维特征嵌入。
- 对象中心方法:
使用 eSAM(高效 SAM)模型获得图像的二值分割掩码,将这些掩码与体素占据子图中的体素关联。
通过图像到地图的分割跟踪,将视觉语言信息从当前图像帧聚合到子图中。
- 特征更新:
对于每个分割 ID,计算其平均语言特征 和像素数量 。
通过加权平均更新每个分割的视觉语言特征,考虑历史观察到的像素,提高特征嵌入的一致性。
- 长期跟踪:
通过长期跟踪分割,系统能够在对象的部分视图中减少视觉语言嵌入的噪声,提高语义理解的准确性。
探索规划
- 基础方法:
扩展了基于子图的探索规划器,优先采样靠近边界(frontiers)的候选位置,因为这些区域可以扩展地图。
从当前 MAV 位置规划路径到每个候选位置,并计算其估计持续时间 。
通过 360° 地图熵射线投射计算每个候选位置的潜在增益 ,并选择效用最高的候选位置作为下一个目标。
- 自然语言引导:
用户输入的自然语言查询通过 CLIP 模型转换为语言嵌入 。
系统计算查询嵌入与已映射对象的视觉语言嵌入 的余弦相似度,选择相似度大于阈值 的对象。
优先采样与查询相关的对象或区域附近的候选位置,并调整候选位置的效用函数,以考虑与感兴趣对象的视觉语言嵌入的相似性。
- 灵活性:
系统可以在没有自然语言查询的情况下进行探索,表现出与传统方法相似的行为。
实验
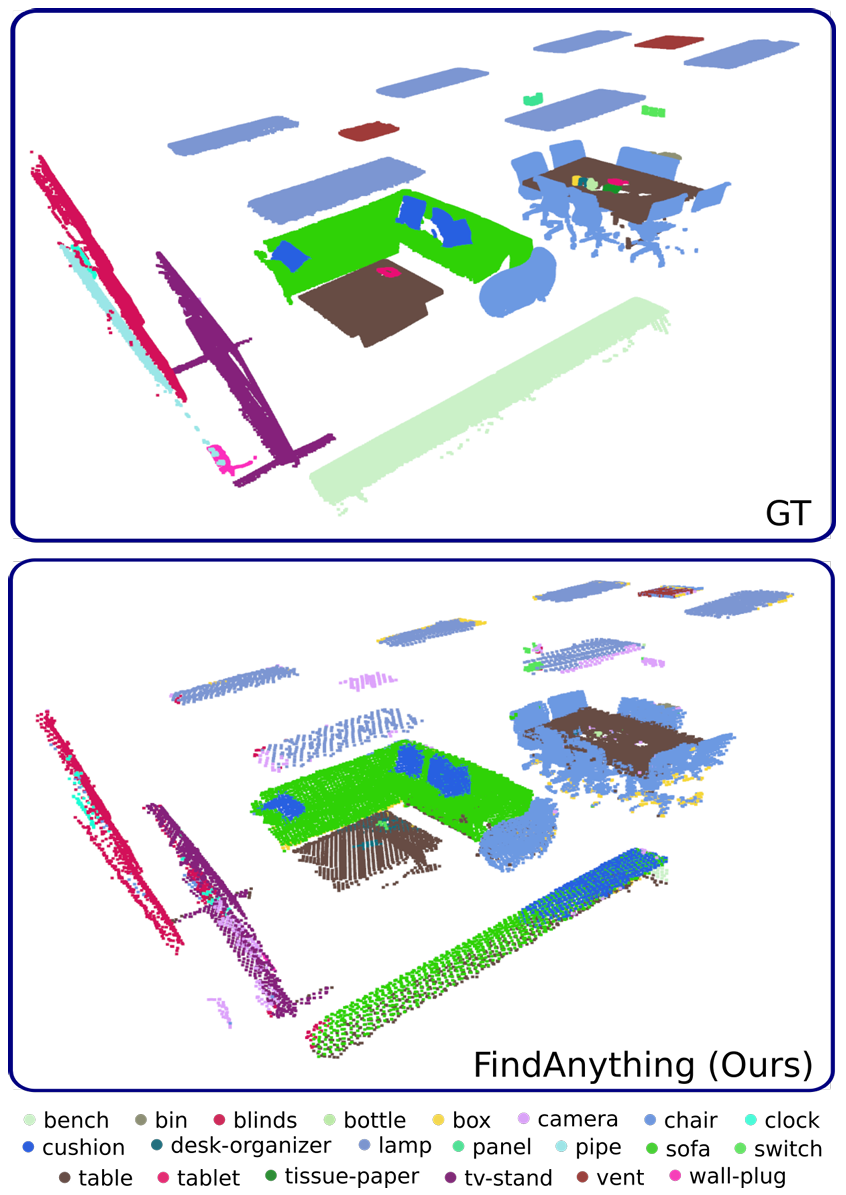
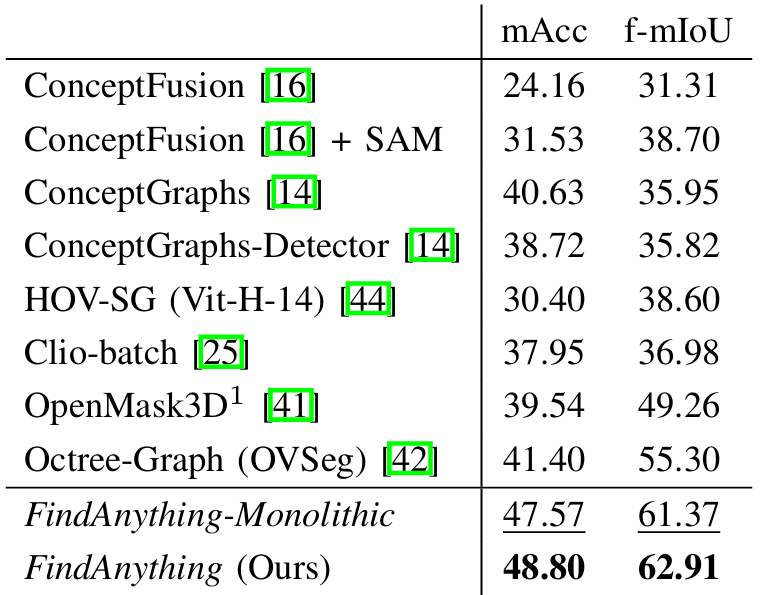
- 语义封闭集准确率:
在 Replica 数据集上评估聚合视觉语言特征的语义准确率,使用类均召回率(mAcc)和频率加权平均交并比(f-mIoU)作为指标。
结果表明,FindAnything 实现了状态最先进的语义准确率,这归功于系统对当前子图中所有可能分割的长期跟踪以及聚合方法,能够减少从对象的部分视图获得的视觉语言嵌入的噪声。
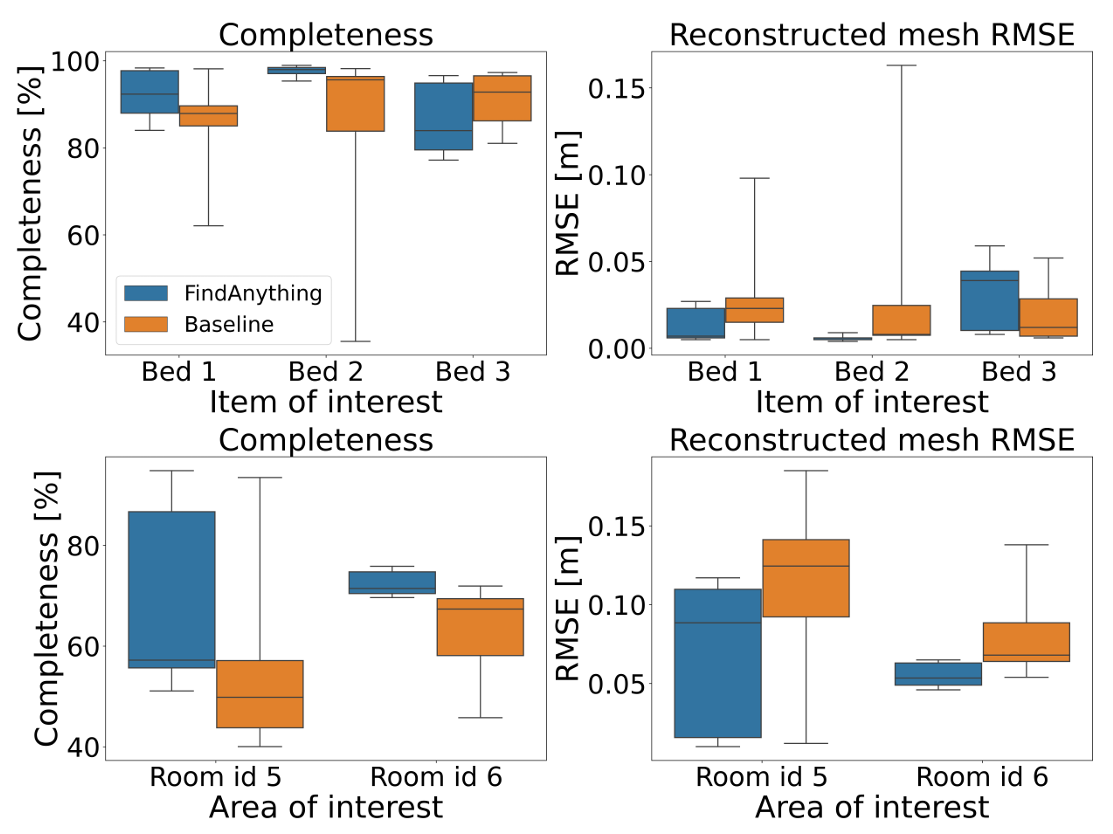
- 自主 MAV 探索:
在 Habitat-Matterport 3D 数据集的 00848-ziup5kvtCCR 场景中进行探索实验,使用自然语言查询“床”和“浴室”作为目标对象或区域。
与不包含语义信息的基线方法相比,FindAnything 在探索感兴趣对象或区域的重建准确性和完整性方面表现出更高的性能,尤其是在“浴室”区域的探索中,改进更为显著。
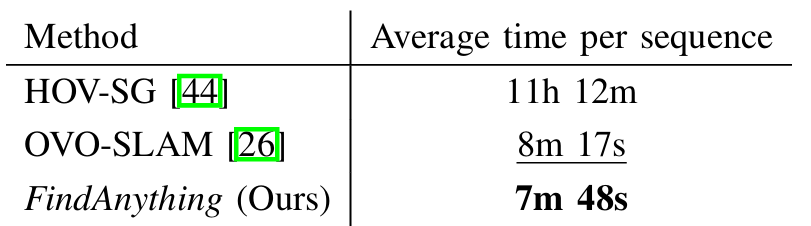
- 资源使用:
展示了处理 Replica 序列所需的平均时间,并提供了不同阶段的平均时间分布。
结果表明,FindAnything 的处理速度比一些现有方法更快,尽管在资源受限的设备上运行,仍能实现实时处理。
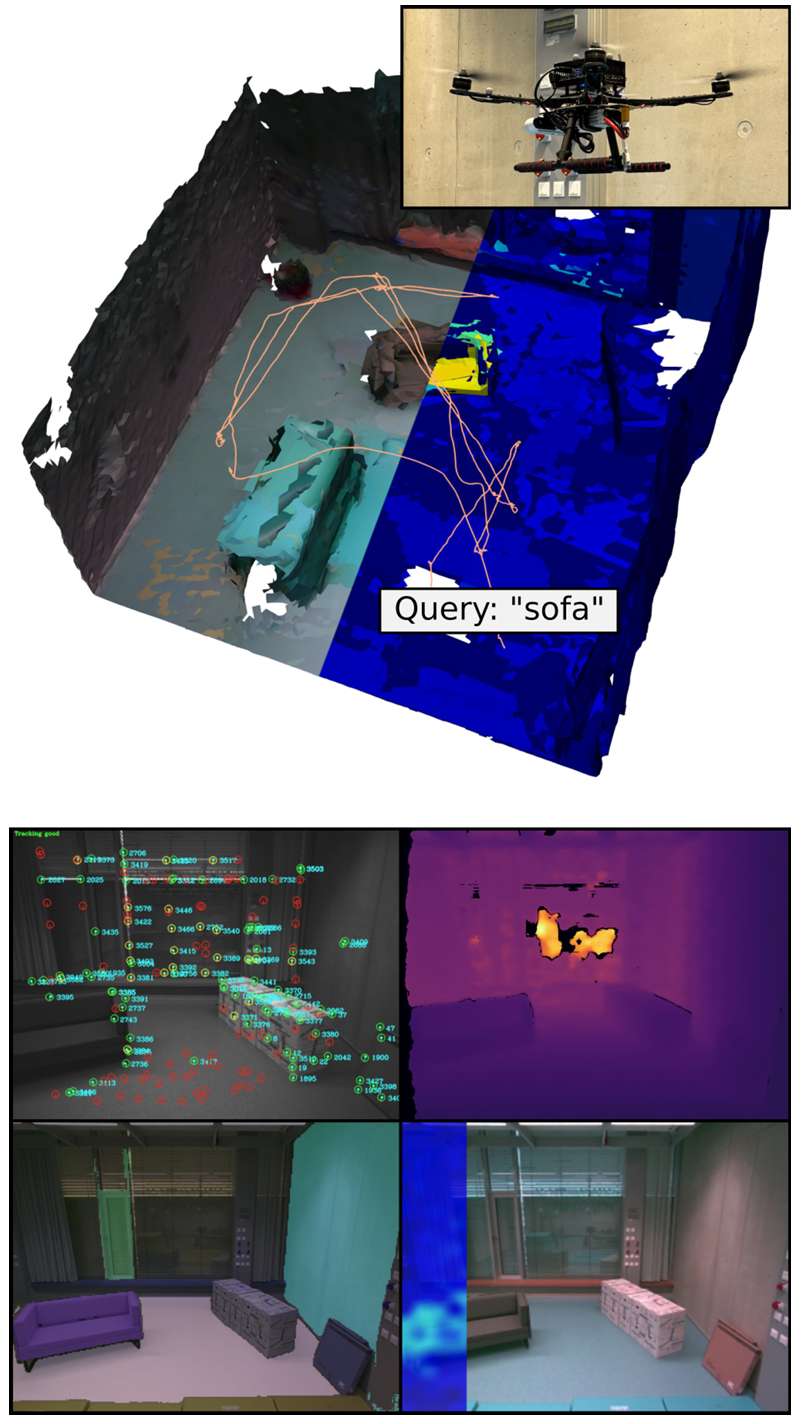
- 真实世界实验:
在真实世界的 MAV 上部署 FindAnything 系统,仅依赖于机载计算。实验目标是通过自然语言查询“沙发”来探索环境。
结果表明,系统能够在资源受限的设备上运行,并在探索过程中构建适合探索的体素占据表示,同时在对象中心的子图中聚合语言嵌入。
结论与未来工作
- 结论:
FindAnything 是一种实时开放词汇对象中心的映射和探索框架,能够利用基础模型实现开放词汇引导的探索。
系统通过跟踪对象并将其开放词汇特征聚合到体素占据子图中,展示了在模拟和真实世界中的映射准确性和语义一致性,并证明了自然语言用户输入可以引导探索以提高实际感兴趣区域的映射准确性和完整性。
作为同类中的首创,该框架已成功部署在资源受限的 MAV 上。
- 未来工作:
未来的工作将致力于通过引入语义先验或层次化地图表示来进一步推动机器人探索的边界,以便在当前场景中缺乏观察时实现有信息的探索。
此外,考虑动态对象和人员在场景中的交互仍然是需要解决的挑战。
