MySQL 的三大范式(1NF、2NF、3NF)是关系型数据库设计的核心原则,用于减少数据冗余、消除插入/删除/更新异常,确保数据一致性。以下是简明解释:
一、第一范式(原子性)
要求:每列的值必须是不可再分的原子值。
例如:出生日期这一列存了某年某月某日,但是把出生日期这列可以拆分为年,月,日,三列,这样的列就不具有原子性。
二、第二范式(消除部分依赖)
要求:在满足第一范式的基础上,非主键列必须完全依赖整个主键(不能仅依赖主键的一部分)。
正例:
学生表:
学号,年龄,姓名。
学生选修成绩表:
学号,课程编号,成绩。
在学生表中,学号作为主键,通过学号,可以知道年龄,通过学号也可以知道姓名。这就是完全依赖。
在学生选修成绩表中,学号和课程编号作为复合主键,通过这个复合主键可以唯一确定学生的成绩。
反例:
学生选修课成绩表:
学号,姓名,年龄,课程名,学分,成绩。
这个表中学号作为主键,只有姓名和年龄完全依赖于学号主键,学分这个字段依赖于课程名,成绩字段依赖于课程名和学号这样的复合主键,所以这个表只能满足部分依赖。
三、第三范式(消除传递依赖)
要求:在满足第二范式的基础上,非主键列必须直接依赖主键,不能通过其他非主键列间接依赖(消除传递依赖)。
反例:
学生表:学号,姓名,年龄,所在院校,学院电话,学院地址。
这个表中学号作为主键,只有姓名和年龄和学号是强相关的。
院校电话和院校地址是和所在院校强相关的。
存在的传递关系:
学号->所在院校->学院电话->院校地址。
解决办法就是将学生表一分为二。
学生表:
学号,年龄,姓名,学院编号
学院表:
学院编号,学员名,学院电话,学院地址
用学院编号作为外键将两张表联系起来。
总结:
| 范式 | 核心目标 | 常见问题示例 | 解决方案 |
|---|---|---|---|
| 1NF | 列原子性 | 地址字段存复合信息 | 拆分列 |
| 2NF | 消除部分主键依赖 | 表的主键是组合键,非主键列依赖部分主键 | 拆分表 |
| 3NF | 消除非主键间的传递依赖 | 非主键列依赖其他非主键列 | 拆分表,建立外键关联 |
四、表设计
一对一模型:

或者:

一对多:

在n端加入另一张表的主键。
多对多:

例如学生运动会的模型如下:
(1)有若干个班级,每个班级包括班级号、班级名、专业、人数。
(2)每个班级有若干个运动员,运动员只能属于一个班,包括运动员号、姓名、性别、年龄。
(3)有若干个比赛项目,包括项目号、名称、比赛地点。
(4)每个运动员可参加多个比赛项目,且每个项目可有多人参加。
(5)要求能够公布每个比赛项目的运动员名次与成绩。
(6)要求能够公布各个班级团体总分的名次和成绩。
E-R图:
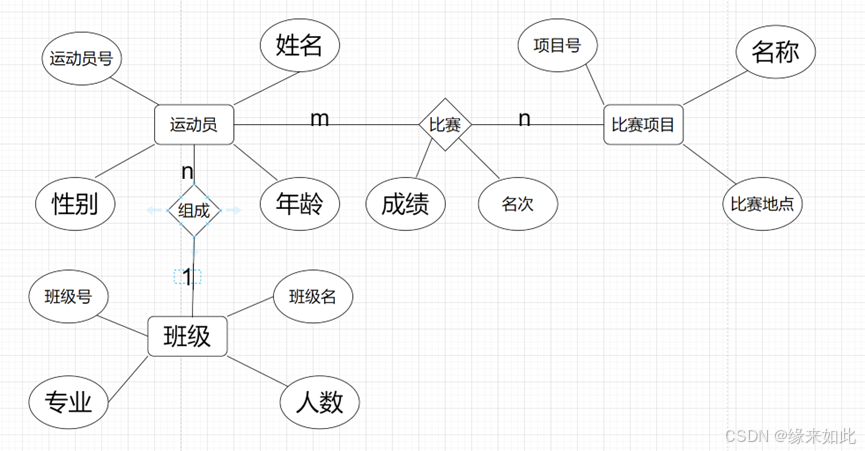
关系模型:
运动员(运动员号,班级号,姓名,性别,年龄)
班级(班级号,班级名,专业,人数)
比赛项目(项目号,比赛地点,名称)
比赛(项目号,运动员号,成绩,名次)
五、聚合函数
| 函数名 | 作用描述 | 是否忽略 NULL | 示例代码(含 GROUP BY) |
|---|---|---|---|
| COUNT() | 统计行数或列值个数 | 是(COUNT(*)除外) | SELECT city, COUNT(*) FROM users GROUP BY city; |
| SUM() | 求数值列总和 | 是 | SELECT user_id, SUM(amount) FROM orders GROUP BY user_id; |
| AVG() | 求数值列平均值 | 是 | SELECT category, AVG(price) FROM products GROUP BY category; |
| MAX() | 返回列最大值 | 是 | SELECT user_id, MAX(order_date) FROM orders GROUP BY user_id; |
| MIN() | 返回列最小值 | 是 | `SELECT user_id, MIN(order_date) FROM |
| COUNT(DISTINCT) | 统计去重后的行数 | 是 | SELECT COUNT(DISTINCT city) FROM users; |
| HAVING | 对聚合结果二次过滤 | — | SELECT user_id, SUM(amount) AS total FROM orders GROUP BY user_id HAVING total>1000; |
六、正则表达式
| 维度 | 符号/语法 | 作用说明(一句话) | 示例片段 |
|---|---|---|---|
| 字符集 | [a-z] |
任意单个小写字母 | [a-z] |
[A-Z0-9] |
任意大写字母或数字 | [A-Z0-9] |
|
[^abc] |
除 a、b、c 外的任意单个字符 | [^abc] |
|
[[:alnum:]] |
任意字母或数字(POSIX 类) | [[:alnum:]] |
|
| 元字符 | . |
匹配除换行外的任意单个字符 | a.c → abc, a3c |
^ |
匹配字符串开头 | ^abc |
|
$ |
匹配字符串结尾 | xyz$ |
|
\ |
转义保留字符,使其按字面匹配 | \. 匹配真实点 |
|
| |
逻辑“或” | cat|dog |
|
| 量词 | * |
前一项 0 次或多次 | ab*c → ac, abc |
+ |
前一项 1 次或多次 | ab+c → abc, abbc |
|
? |
前一项 0 次或 1 次 | ab?c → ac, abc |
|
{n} |
前一项恰好 n 次 | a{3} → aaa |
|
{n,m} |
前一项 n 到 m 次 | a{2,4} → aa, aaa |
|
{n,} |
前一项至少 n 次 | a{2,} → aa, aaaa |
示例1:查找 11 位手机号
SELECT * FROM users
WHERE phone REGEXP ‘^1[3-9][0-9]{9}$’;
示例二: 查找邮箱格式
SELECT * FROM users
WHERE email REGEXP '^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\\.[A-Za-z]{2,}$';
示例三:查找 18 位身份证号
SELECT * FROM users
WHERE id_card REGEXP '^[0-9]{17}[0-9Xx]$';
示例四:查找包含至少 1 个大写字母的密码字段
SELECT * FROM users
WHERE password REGEXP '[A-Z]';
完结。