
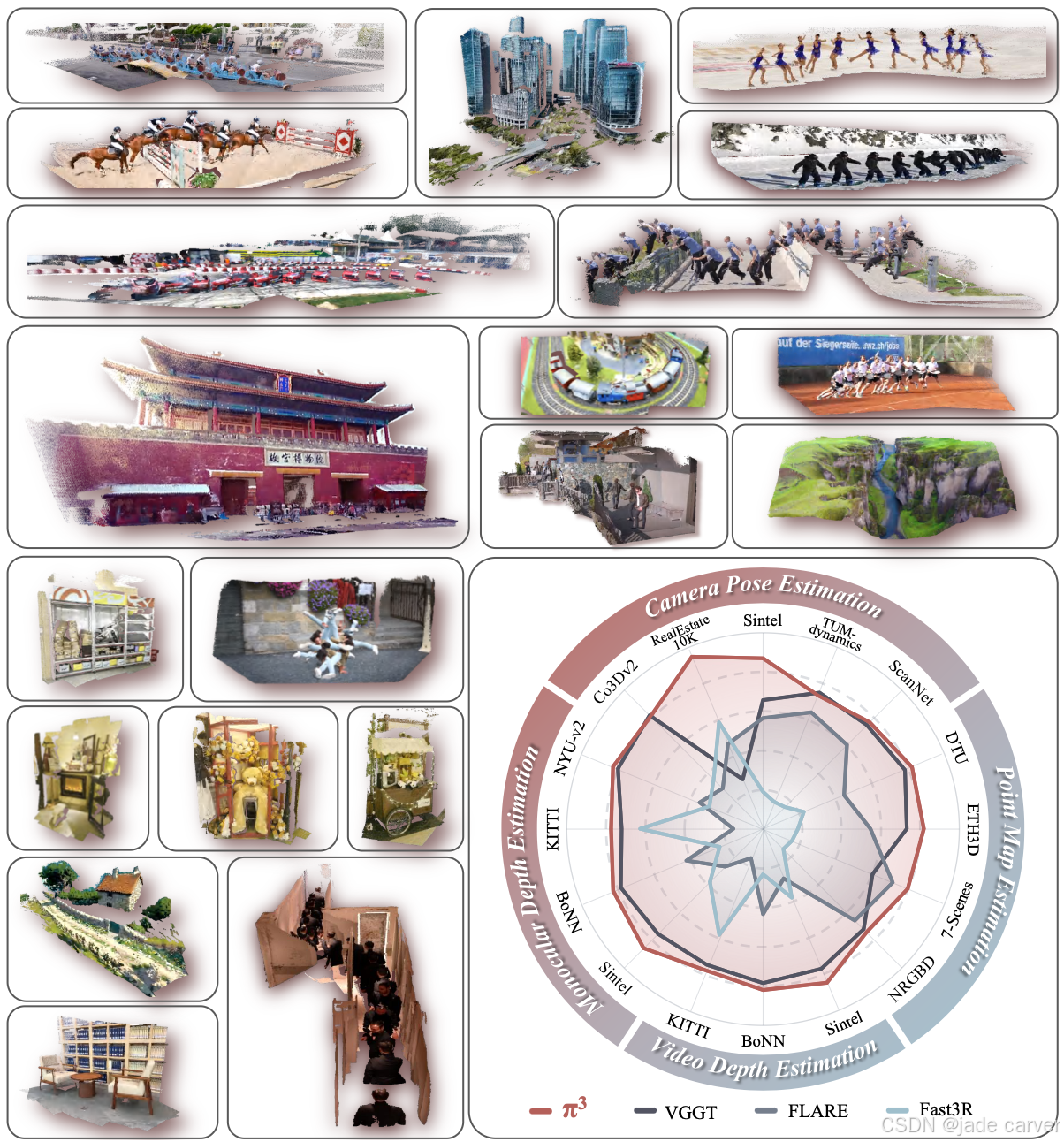
膜拜来自上海AI lab和浙大的大佬们!在VGGT获得CVPR 2025 BEST PAPER以后,提出了置换等变的3r系列feed- forward重建方法,并且首次向我们揭示了传统方法以及当前feed- forward方法存在的归纳偏置导致模型对于视图的强依赖,π3在具有高扩展性的同时在多种下游任务中达到了SOTA或者接近的效果,包括pose估计、稠密重建、视频深度估计、单目深度估计。同时π³证明了无参考系统不仅可行,更能催生更稳定、更通用的三维视觉模型。
abstract
我们推出π3——一种前馈神经网络,其通过创新性的视觉几何重建方法,突破了传统固定参考视图的局限。现有方法通常将重建结果锚定在指定视角,这种归纳偏置容易因参考视图不佳而导致重建不稳定甚至失败。相比之下,π3采用完全置换等变的网络架构,无需任何参考帧即可预测仿射不变的相机位姿与尺度不变的局部点云图。该设计使模型天然具备输入顺序鲁棒性和高度可扩展性。这些优势让我们以简单无偏置的方法,在相机位姿估计、单目/视频深度估计以及稠密点云图重建等多项任务中实现了最先进的性能表现。
1. Introduction
视觉几何重建作为计算机视觉领域长期存在的基础性问题,在增强现实[7]、机器人[50]和自主导航[17]等领域具有重要应用价值。尽管传统方法通过束调整(BA)[11]等迭代优化技术应对这一挑战,但前馈神经网络的最新进展为这一领域带来了革命性突破。DUST3R[39]及其后续模型等端到端系统已证明深度学习在图像对[13,46]、视频或多视角集合[34,42,47]几何重建中的强大能力。
然而,无论是传统方法还是现代方法,都存在一个关键局限:对固定参考视图的依赖。这种将选定视图的相机坐标系作为全局参考框架的做法,源自传统的运动恢复结构(SfM)[4,11,20,24]和多视角立体视觉(MVS)[9,25]技术。我们认为这种设计引入了不必要的归纳偏置,从根本上限制了前馈神经网络的性能和鲁棒性。实证研究表明,包括最先进的VGGT[34]在内的现有方法对初始视图选择极为敏感——不当的参考视图会导致重建质量急剧下降(图3),阻碍构建鲁棒可扩展的系统。
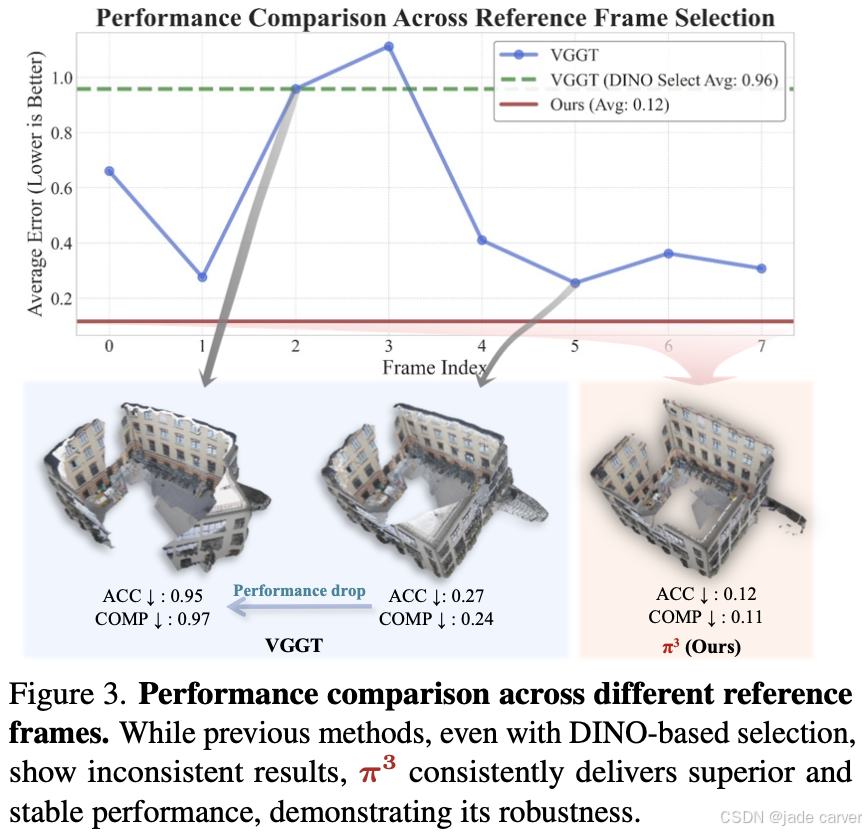
为突破这一局限,我们提出π³:一种鲁棒、可扩展且完全置换等变的新方法,彻底消除了视觉几何学习中的参考视图偏置。π³可接受单幅图像、视频序列或静态/动态场景的无序图像集合作为输入,无需指定参考视图。相反,我们的模型为每帧预测相对于自身相机坐标系的仿射不变相机位姿和尺度不变局部点云图。通过摒弃帧索引位置编码等顺序相关组件,并采用交替进行视图级与全局自注意力计算的Transformer架构(类似[34]),π³实现了真正的置换等变性。这确保了视觉输入与重建几何间稳定的一一映射关系,使模型天然具备输入顺序鲁棒性,彻底规避了参考视图选择问题。
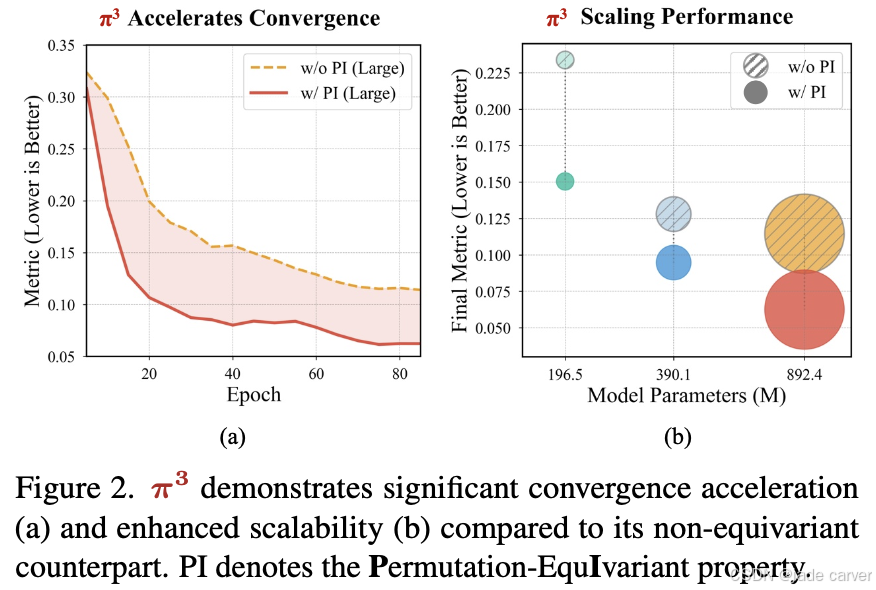
我们的设计具有显著优势:首先展现出卓越的可扩展性,模型性能随规模提升持续增强;其次实现更快的训练收敛速度;最重要的是具备更强的鲁棒性。
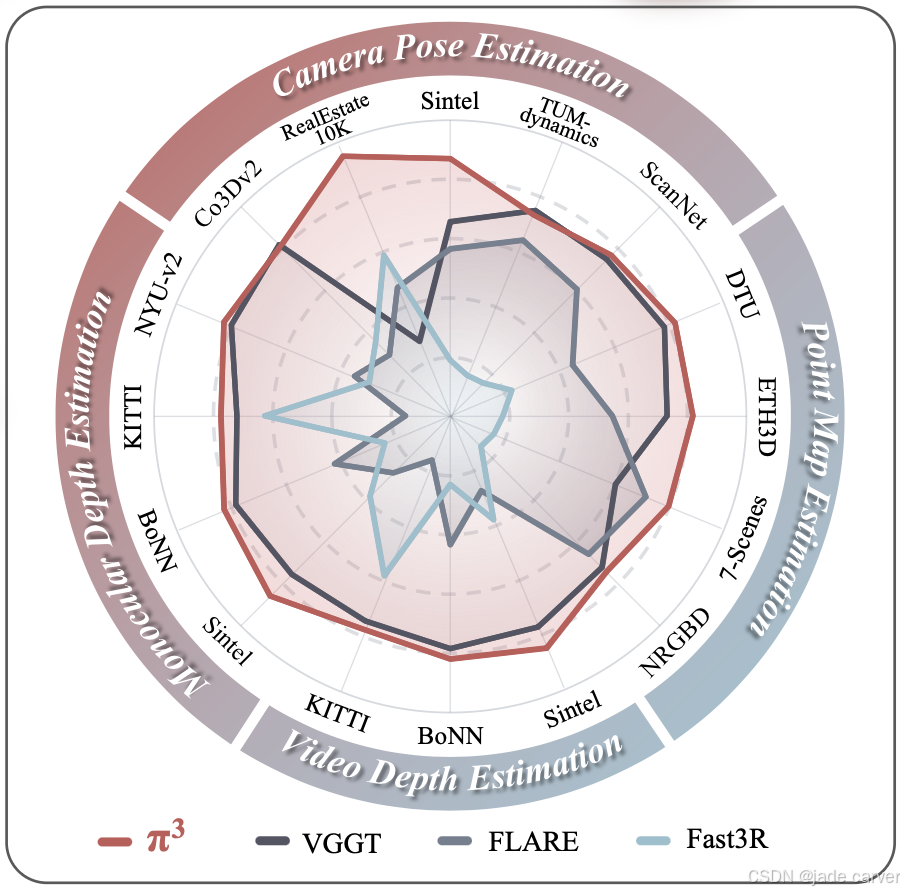
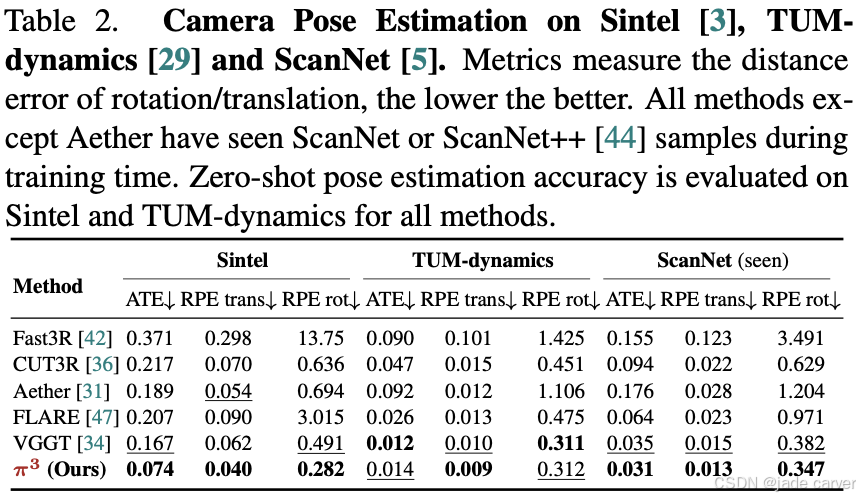
π³在多项基准测试中创下新纪录:在单目深度估计任务达到与MoGe[37]相当的精度,在视频深度估计和相机位姿估计任务超越VGGT[34]。在Sintel基准测试中,π³将相机位姿估计的绝对轨迹误差(ATE)从VGGT的0.167降至0.074,并将尺度对齐的视频深度相对误差从0.299优化至0.233。此外,π³兼具轻量与高效特性,57.4 FPS的推理速度显著优于DUST3R的1.25 FPS和VGGT的43.2 FPS。其静态/动态场景的通用重建能力,使之成为实际应用的理想解决方案。
本工作的核心贡献:
- 首次系统性地揭示并挑战视觉几何重建中对固定参考视图的依赖,论证这种常见设计如何引入损害模型鲁棒性与性能的归纳偏置
- 提出完全置换等变的π³架构,通过预测仿射不变相机位姿和尺度不变点云图的纯相对化方案,彻底消除对全局坐标系的需求
- 经大量实验验证,π³在相机位姿估计、单目/视频深度估计及点云图重建等任务中全面超越现有方法,确立新的性能标杆
- 证明该方法不仅对输入视图顺序更具鲁棒性、随模型规模扩展性更佳,且训练收敛速度显著提升
2.Method
本文方法介绍主要包含两部分,第一部分是置换等变定义介绍,以及设计的对应的神经网络架构,第二部分是神经网络使用的loss,包括两个模块,第一个是利用pointmap对模型的最优尺度估计,以及法线估计loss,以及置信度图(这里直接设置为二值函数)的loss,第二个是相机相对位姿估计。通过以上,本文做到了去除原先3r系列pipeline的归纳偏置,以及更高的数据实验精度。
2.1 置换等变架构(其实就是算子的交换性)
从dust3r到vggt的这些方法的共同特点是依赖指定参考帧作为预测三维结构的基准,我们则考虑一个更加一般且通用的范式:不依赖某一帧图像对应的3D空间来构建模型,这是我们去除以上归纳偏置的基本逻辑。


为实现这一等变性,我们的实现方案(如图4所示)省略了所有顺序相关的组件。具体而言,我们摒弃了诸如用于区分帧的序列位置编码、以及指定参考视图的可学习特殊标记(如VGGT[34]中的相机标记)等顺序依赖组件。我们的流程首先使用DINOv2[18]主干网络将每个视图嵌入为图像块标记序列,随后通过一系列交替的视图内自注意力和全局自注意力层(类似于[34])进行处理,最终由解码器生成输出。
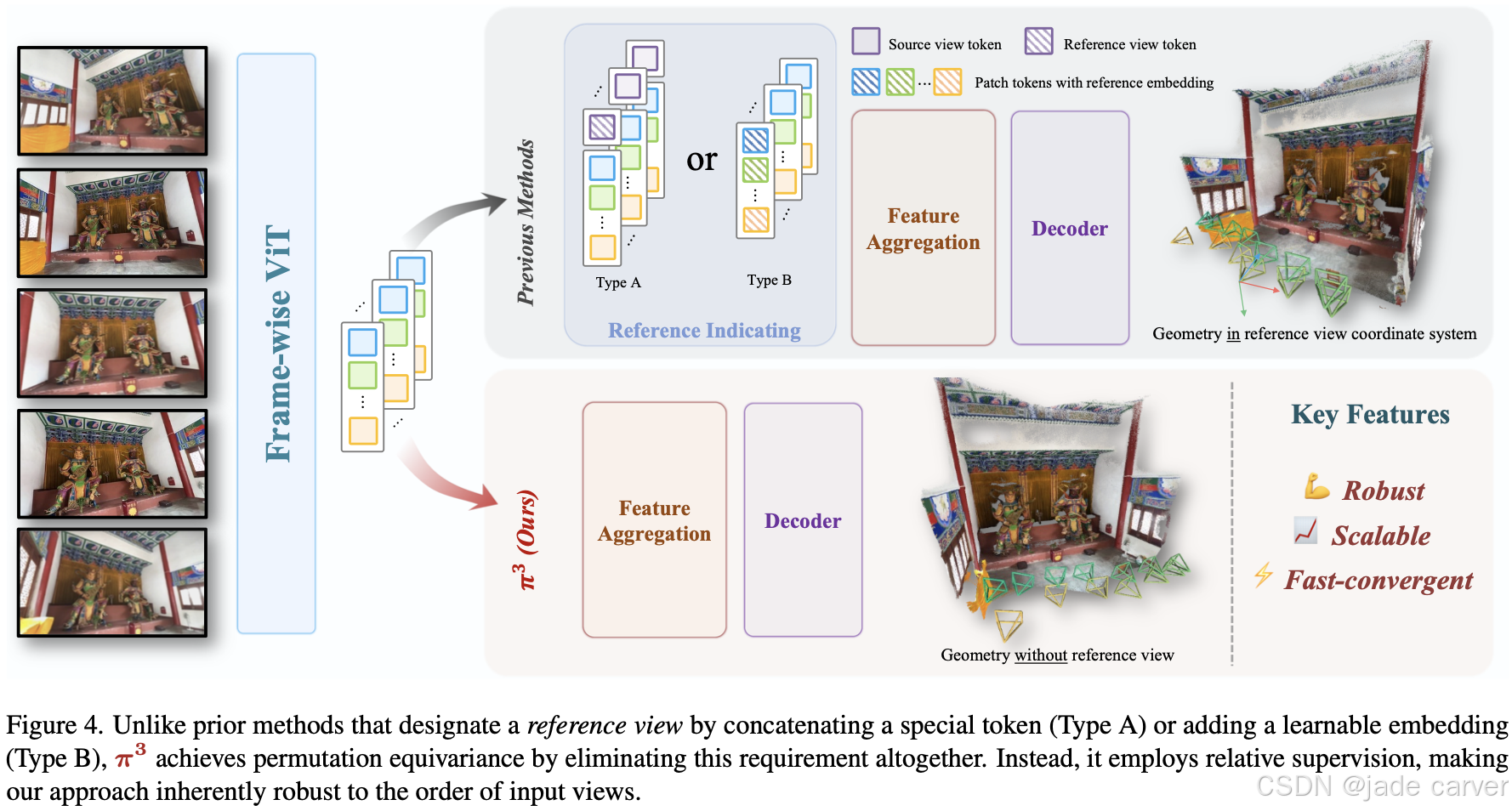
模型的详细架构
编码器和交替注意力模块与VGGT[34]中的相同,除了我们只使用36层进行交替注意力模块,而VGGT使用48层。相机pose、pointmap和置信度图的解码器共享相同的架构,但不共享权重。该架构是一个轻量级的5层transformer,专门针对每个图像的特征应用自注意力。
在解码器之后,输出头因任务而异。pointmap和置信度图的head是一个简单的MLP,然后是像素洗牌操作。对于相机pose估计,head改编自Reloc3r [6],并使用MLP、平均pooling和另一个MLP。旋转最初在9D表示中预测[14],然后通过SVD正交化转换为3×3旋转矩阵。
2.2尺度不变的局部几何(基于局部pointmap的全局点云尺度估计)
对于每张输入图像 ![]() ,我们的网络预测一个像素对齐的3D点图
,我们的网络预测一个像素对齐的3D点图![]() 。每个点云最初是在其自身的局部相机坐标系中定义的。单目重建中一个众所周知的挑战是固有的尺度模糊性。为解决这一问题,我们的网络预测的点云在所有N 张图像中具有一个未知但一致的尺度因子。
。每个点云最初是在其自身的局部相机坐标系中定义的。单目重建中一个众所周知的挑战是固有的尺度模糊性。为解决这一问题,我们的网络预测的点云在所有N 张图像中具有一个未知但一致的尺度因子。
因此,训练过程需要将预测的点图 ![]() 与对应的真实值
与对应的真实值 ![]() 对齐。通过求解一个最优尺度因子
对齐。通过求解一个最优尺度因子 ![]() 来实现,该因子最小化整个图像序列的深度加权L1距离。故优化问题为:
来实现,该因子最小化整个图像序列的深度加权L1距离。故优化问题为:
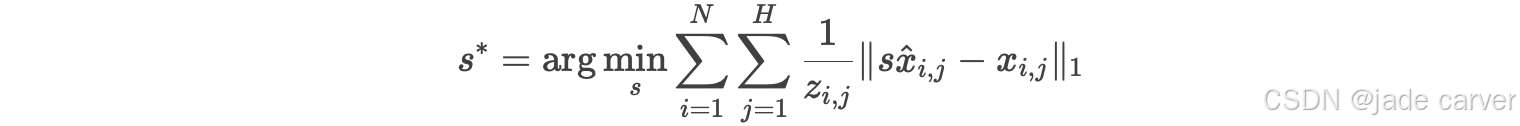

最终,点云重建损失 ![]() 使用最优尺度因子
使用最优尺度因子![]() 定义:
定义:
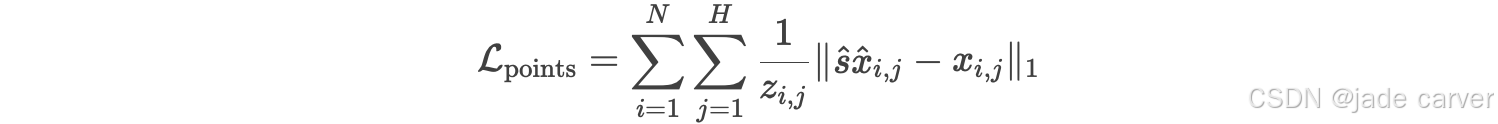
为鼓励重建局部平滑的表面,我们还引入了法向损失 ![]() 。对于预测点图
。对于预测点图 ![]() 中的每个点,其法向量
中的每个点,其法向量 ![]() 通过图像网格中相邻点的向量叉积计算得到。我们通过最小化其与真实法向量
通过图像网格中相邻点的向量叉积计算得到。我们通过最小化其与真实法向量 ![]() 之间的角度来监督这些法向量:
之间的角度来监督这些法向量:
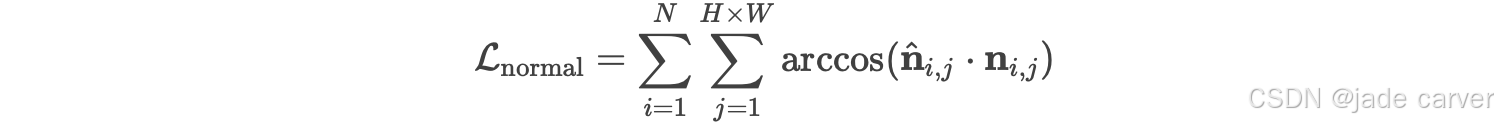

总结

2.3 仿射不变的相机位姿(相对位姿)
模型的置换等变性与多视图重建固有的尺度模糊性共同表明,输出的相机位姿 ![]() 仅能定义到任意相似变换的程度。这类特定的仿射变换由一个刚体变换和一个未知的全局尺度因子组成。
仅能定义到任意相似变换的程度。这类特定的仿射变换由一个刚体变换和一个未知的全局尺度因子组成。
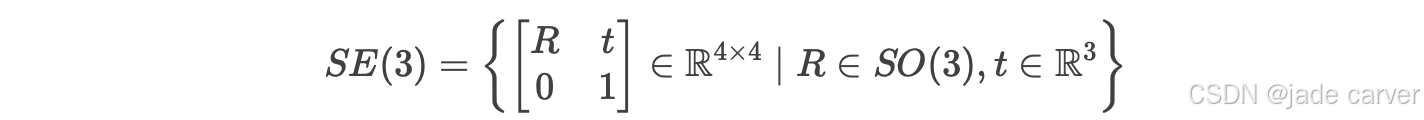
为消除全局参考系的不确定性,我们通过对视图间相对位姿的监督来训练网络。从视图 j 到视图 i 的预测相对位姿![]() 计算如下:
计算如下:
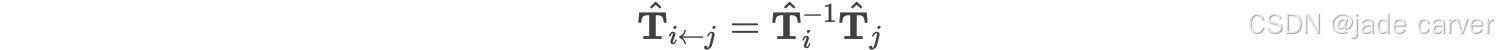
每个预测的相对位姿 ![]() 由一个旋转
由一个旋转 ![]() 和一个平移
和一个平移 ![]() 组成。虽然相对旋转对这种全局变换具有不变性,但相对平移的幅度仍然模糊。
组成。虽然相对旋转对这种全局变换具有不变性,但相对平移的幅度仍然模糊。
我们通过利用最优尺度因子 ![]() 来解决这一问题,这一全局一致的尺度因子用于校正所有预测的相机平移,从而可以直接监督旋转和经过正确缩放的平移分量。
来解决这一问题,这一全局一致的尺度因子用于校正所有预测的相机平移,从而可以直接监督旋转和经过正确缩放的平移分量。
相机损失 ![]() 是旋转损失项和平移损失项的加权和:
是旋转损失项和平移损失项的加权和:
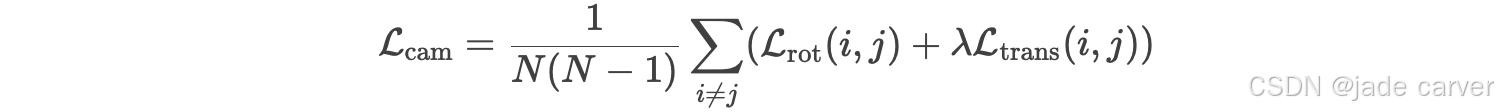
其中 λ 是平衡两项的超参数。旋转损失最小化预测的相对旋转 ![]() 与其真实目标
与其真实目标 ![]() 之间的测地距离(角度):
之间的测地距离(角度):
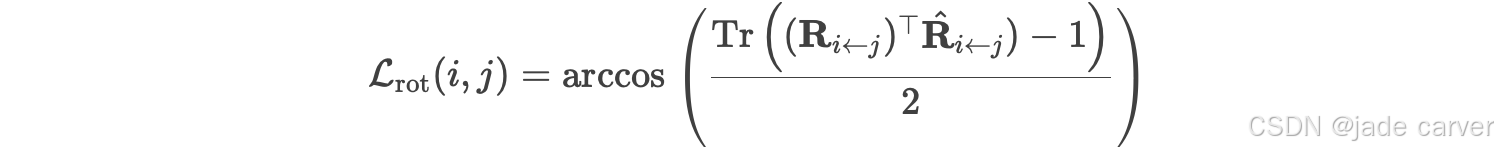
对于平移损失,我们将缩放后的预测与真实相对平移 ![]() 进行比较,并使用Huber损失
进行比较,并使用Huber损失 ![]() 以提高对异常值的鲁棒性:
以提高对异常值的鲁棒性:
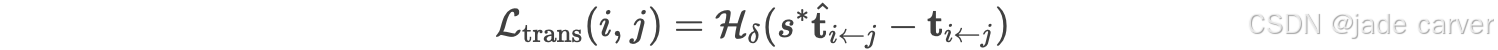
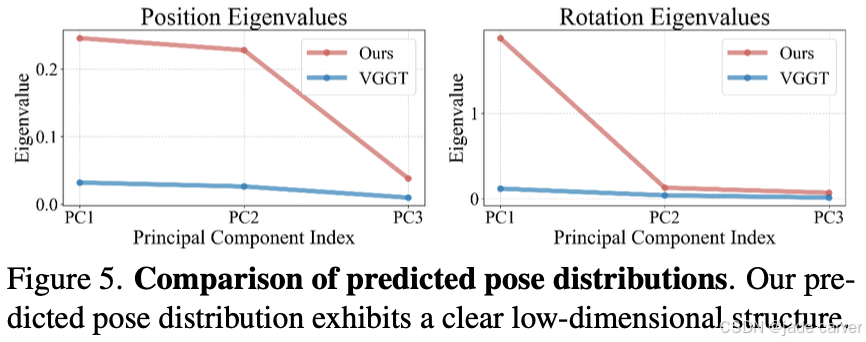
仿射不变相机模型基于一个关键发现:真实世界的相机运动路径具有高度结构性,而非随机分布。例如,环绕物体拍摄的相机沿球面运动,而车载相机的轨迹则遵循曲线。这是一个很重要且基本的先验信息。
在图5中,我们对预测位姿分布的结构进行了定量分析。特征值分析证实,与VGGT相比,我们的预测位姿方差集中在更少的主成分上,验证了输出的低维结构特性。

2.4 整体loss
我们通过最小化复合损失函数LL对模型进行端到端训练,该损失函数是点云重建损失、置信度损失和相机位姿损失的加权和:
![]()
为确保模型的鲁棒性和广泛适用性,我们在15个多样化数据集的大规模聚合上进行训练。这个组合数据集全面覆盖室内外环境,包含从合成渲染到真实场景捕捉的多种场景类型:
- GTA-SfM [35]
- CO3D [21]
- WildRGB-D [41]
- Habitat [23]
- ARKitScenes [2]
- TartanAir [40]
- ScanNet [5]
- ScanNet++ [44]
- BlendedMVG [43]
- MatrixCity [15]
- MegaDepth [16]
- Hypersim [22]
- Taskonomy [45]
- Mid-Air [8]
- 内部动态场景数据集
三、实验
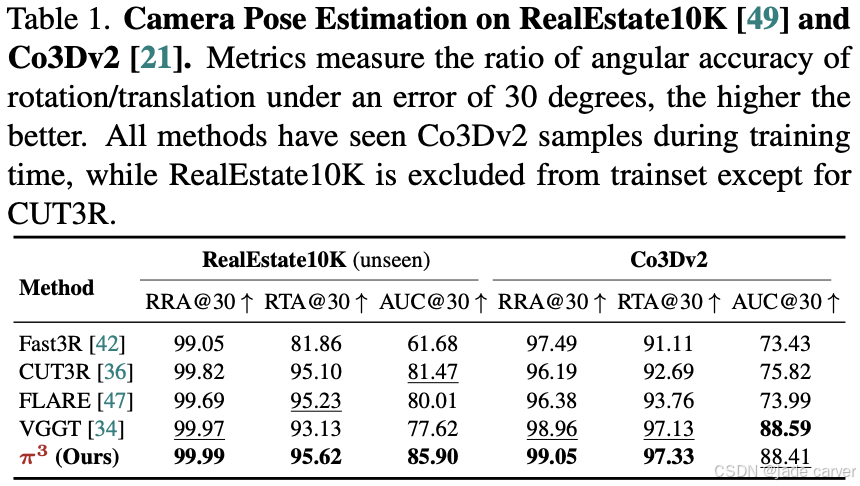
3.1位姿估计
使用的metric为:
1.角度精度指标(Angular Accuracy)
评估数据集:RealEstate10K(场景级)、Co3Dv2(物体中心)
度量标准:相对旋转精度(RRA@θ),相对平移精度(RTA@θ),综合指标:min(RRA,RTA)曲线下面积(AUC)
2.距离误差指标(Distance Error)
评估数据集:Sintel(合成室外)、TUM-dynamics/ScanNet(真实室内)
度量标准:绝对轨迹误差(ATE)、相对位姿误差-平移(RPE trans)、相对位姿误差-旋转(RPE rot)
3.2点图估计
数据集配置:
场景级:7-Scenes(室内)、NRGBD(真实场景)、ETH3D(多场景)
物体级:DTU(可控光照物体)
视图采样:
数据集 稀疏视图步长 密集视图步长 7-Scenes 200帧 40帧 NRGBD 500帧 100帧 DTU/ETH3D 5帧间隔 -
对齐方法:
粗对齐:Umeyama算法(Sim3变换)
精修:ICP点云配准
核心指标
| 指标名称 | 计算原理 | 评估维度 |
|---|---|---|
| Accuracy (Acc.) | 预测点云到真实表面的平均距离 | 重建精度 |
| Completion (Comp.) | 真实表面到预测点云的平均距离 | 完整度 |
| Normal Consistency (N.C.) | 法向量夹角余弦值均值 | 表面平滑性 |
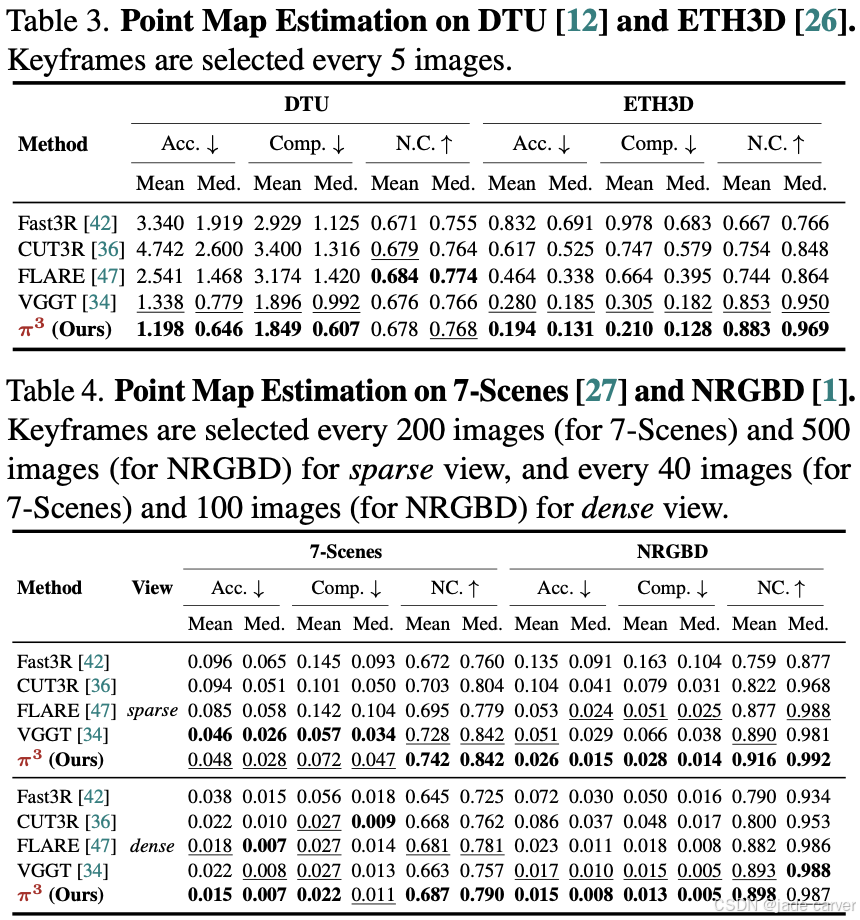
值得注意的是:在帧间隔200+的极端条件下仍保持稳定性能,证明模型有效利用空间先验知识。
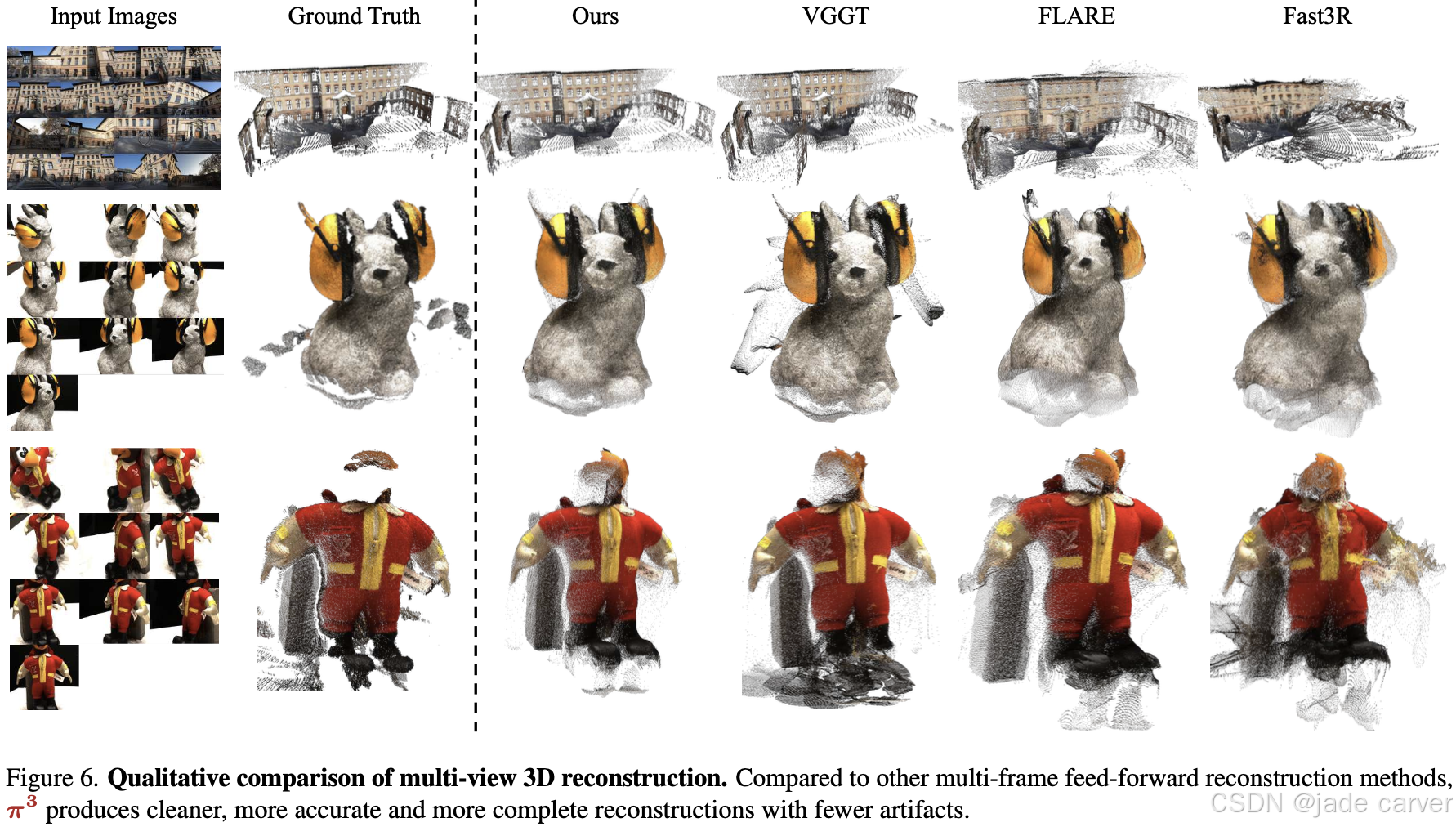

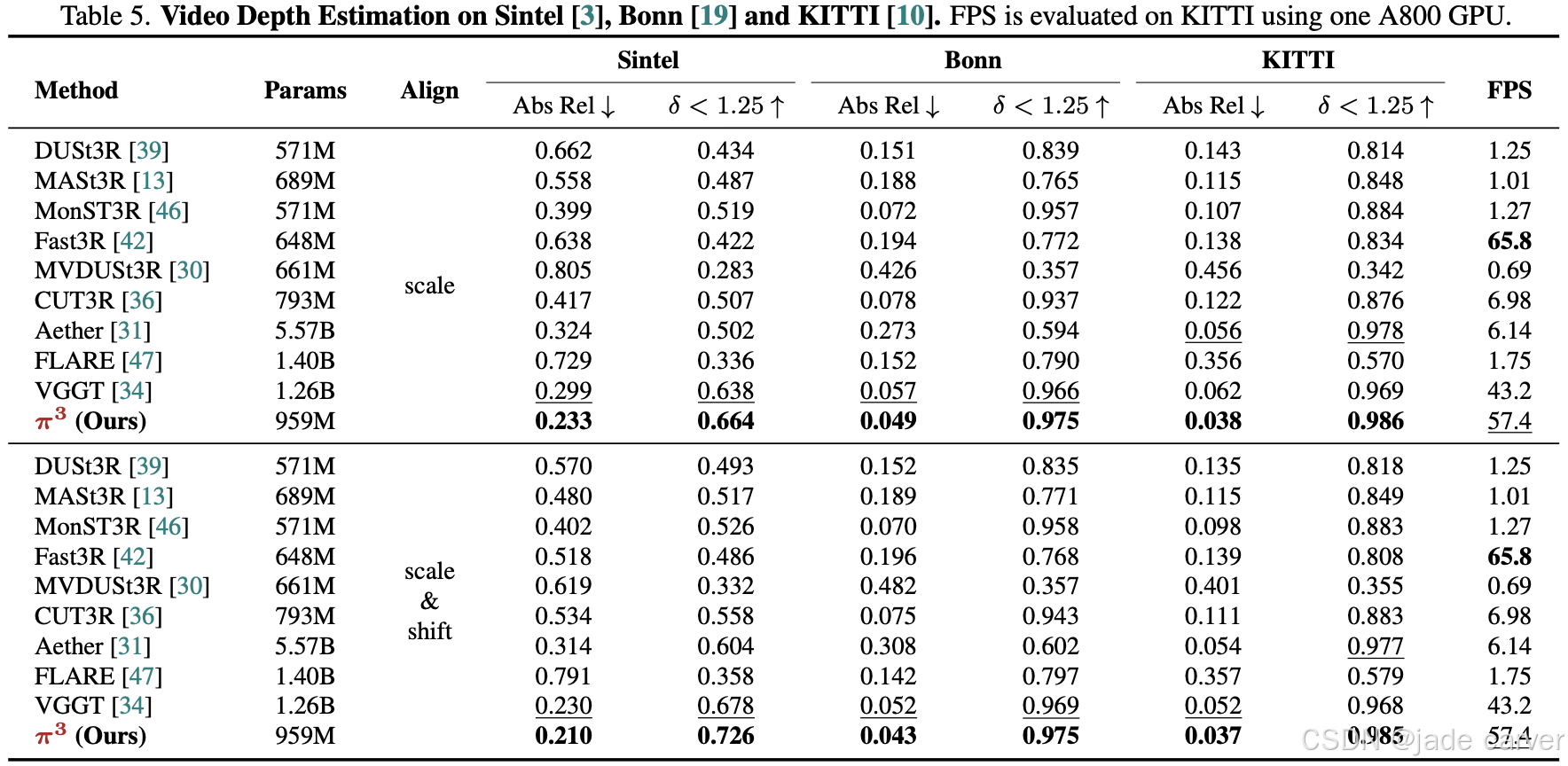
3.3视频深度估计
评估模式:
- 尺度对齐(Scale-only):仅优化全局尺度因子
- 全位姿对齐(Scale+3D Translation):联合优化尺度和三维平移
核心指标:
| 指标名称 | 计算公式 | 物理意义 |
|---|---|---|
| 绝对相对误差 (Abs Rel) | 深度估计整体精度 | |
| 阈值精度 (δ<1.25δ<1.25) | 高置信度预测比例 |
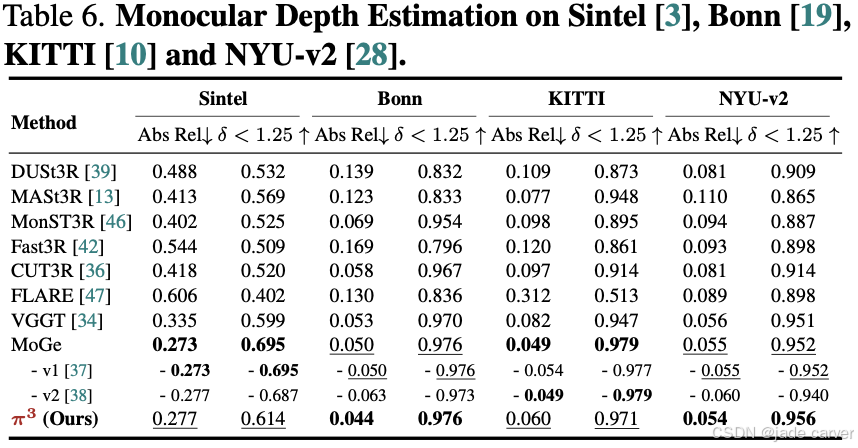
3.4单目深度估计
核心指标:
绝对相对误差 (Abs Rel):逐帧深度图与真值的尺度对齐误差
阈值精度 (δ<1.25):高置信深度预测占比
关键区别:
| 评估类型 | 对齐方式 | 优化目标 |
|---|---|---|
| 视频深度 | 序列全局统一尺度/平移对齐 | 跨帧一致性 |
| 单目深度 | 逐帧独立尺度对齐 | 单帧精度 |
在未专门优化单帧任务的情况下,Abs Rel误差达到多帧前馈重建方法的SOTA水平,与当前最优单目模型MoGe性能相当(差距<2%)
3.5鲁棒性评估
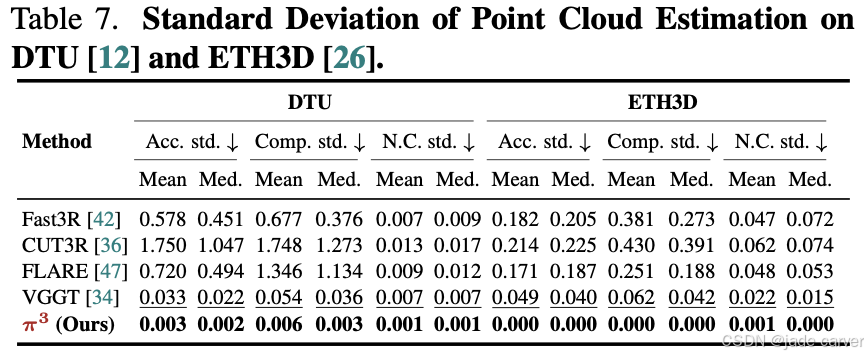
测试设计:在DTU(物体级)和ETH3D(场景级)数据集上,对长度为 NN 的输入序列进行 NN 次独立推理,每次替换序列的首帧为不同帧,模拟输入顺序扰动,计算重建指标(如精度、完整度)的标准差。
对比基线:传统方法(如VGGT):依赖固定参考帧,顺序变化导致显著性能波动,π³方法:置换等变设计,理论上应实现零方差。
四、结论
本文提出的π³网络通过摒弃固定参考视图的依赖,开创了视觉几何重建的新范式。这一前馈神经网络采用完全置换等变的架构设计,天然具备输入顺序鲁棒性与高度可扩展性。该设计消除了传统方法中存在的关键归纳偏置,使得我们的方案在相机位姿估计、深度估计与稠密重建等多项任务中均达到最先进性能。π³证明了无参考系统不仅可行,更能催生更稳定、更通用的三维视觉模型。
我们的模型虽展现出强劲性能,但仍存在局限:首先,由于未显式建模复杂的光线传输现象,无法有效处理透明物体;其次,与当前基于扩散的方法相比,重建几何体缺乏同等水平的细粒度细节;最后,点云生成依赖"MLP+像素重组"的简单上采样机制,该设计虽高效,但会在重建不确定性较高的区域产生明显的网格状伪影。