1. 引言:为什么需要MOE?
本章将简要介绍传统稠密模型在扩展时遇到的瓶颈,并引出混合专家模型(MOE)作为一种高效、可扩展的稀疏化解决方案的核心思想与价值。
2. 从稠密到稀疏:DenseMoE与 SparseMOE 的核心区别
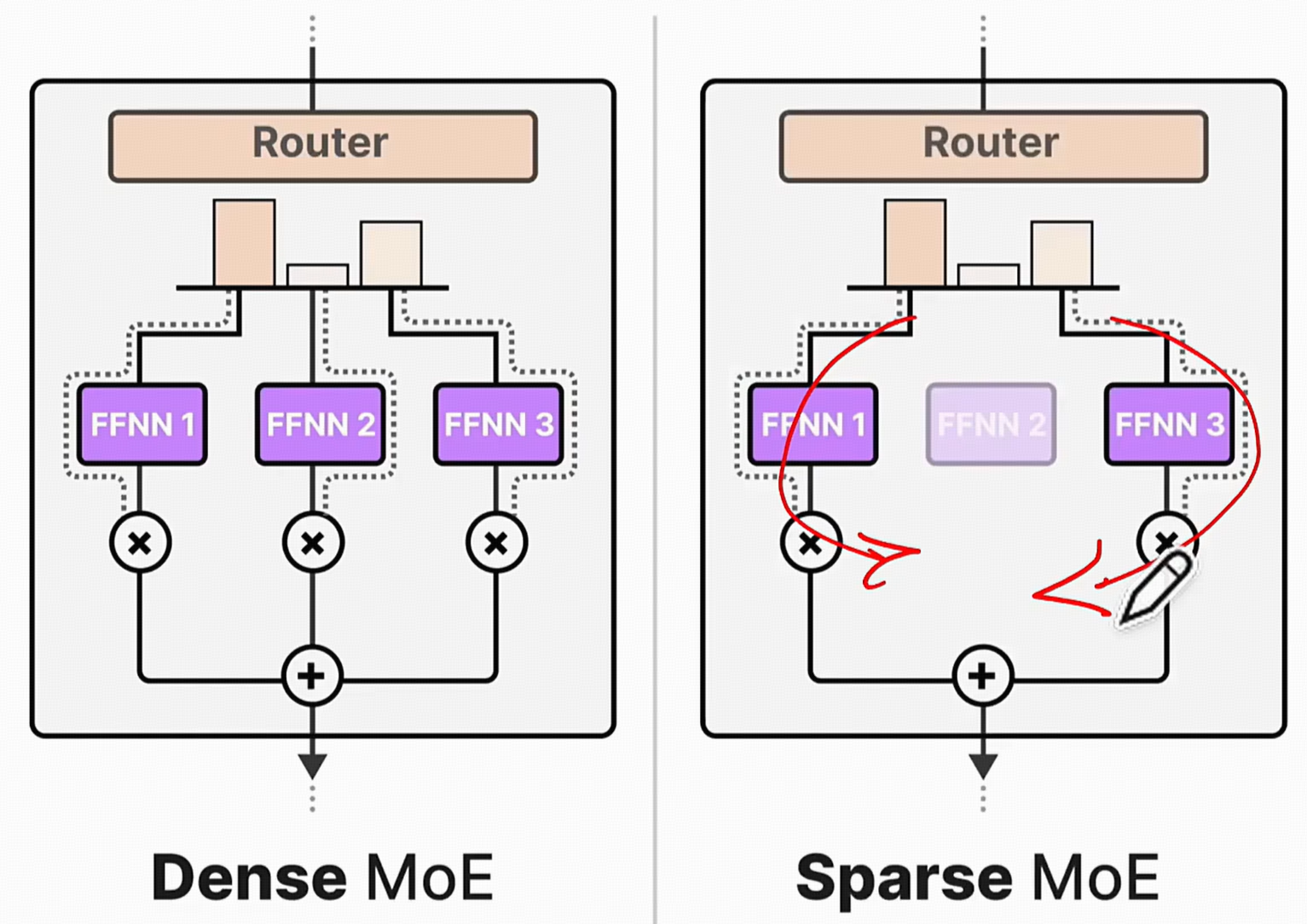
2.1 稠密模型(Dense Model):全员参与
在Transformer等现代神经网络架构中,前馈神经网络(Feed-Forward Network, FNN)层是核心的计算单元之一。我们通常所说的稠密模型(Dense Model),其关键特征在于,每当一个数据(如一个token)流经FNN层时,该层所有的参数都会被激活并参与计算。
这就像一个“全员大会”,无论议题是什么,公司里的每一位员工(参数)都必须参加并发言,贡献自己的计算力。
- 工作方式:输入向量经过第一个线性变换,通过一个非线性激活函数(如ReLU或GeLU),再经过第二个线性变换输出。
- 计算成本:计算量与模型的参数总量成正比。模型越大,参数越多,计算就越昂贵,对硬件的压力也越大。
- 扩展瓶颈:这种“全员参与”的模式使得模型在扩展到千亿甚至万亿参数时,训练和推理成本会变得极其高昂,构成了性能提升的“天花板”。
2.2 稀疏MOE模型(Sparse MOE):专家会诊
为了打破稠密模型的扩展瓶颈,**稀疏混合专家模型(Sparse Mixture-of-Experts, MOE)**应运而生。它引入了“分而治之”和“术业有专攻”的思想。
MOE层将一个庞大的FNN层替换为两个核心组件:
- 多个“专家”网络(Experts):每个专家本身是一个小型的FNN。
- 一个“门控”网络(Gating Network):一个轻量级的路由系统。
其工作模式更像一个“专家会诊”系统:当一个任务(数据token)进来时,一位“总调度师”(门控网络)会迅速判断这个任务的性质,然后只把它分配给最相关的一两个“专家”(Experts)去处理,其他专家则继续“休息”。
- 工作方式:对于每个输入token,门控网络会为其计算一个路由权重,然后根据权重选择得分最高(Top-K)的少数几个专家。输入token只被发送给这些被选中的专家进行计算,最终结果是这些专家输出的加权和。
- 计算成本:虽然MOE模型的总参数量可以非常巨大(所有专家参数之和),但单次前向传播的计算量只与被激活的少数几个专家相关。这实现了模型总容量与计算成本的解耦。
- 高效扩展:这种稀疏激活机制使得模型可以在参数量上扩展到万亿级别,而计算成本(FLOPs)仅与一个规模小得多的稠密模型相当。
2.3 核心差异对比表
为了更清晰地展示三者之间的关系,我们可以通过下图和表格进行对比。通用稀疏模型(如通过剪枝得到的模型)与MOE模型都属于稀疏模型的范畴,但它们实现稀疏的方式有所不同。MOE是一种结构化稀疏(Structured Sparsity),它移除了整个神经元或模块;而通用稀疏通常指非结构化稀疏(Unstructured Sparsity),例如移除独立的权重连接,这在现代硬件上往往难以实现高效加速。
特性 |
✅ 稠密模型 (Dense Model) |
🟡 通用稀疏模型 (General Sparse) |
🚀 稀疏MOE模型 (Sparse MoE) |
🏗️ 结构特点 |
所有神经元全连接,结构固定。 |
连接被静态移除(如权重剪枝),拓扑不规则。 |
结构化稀疏,由完整的、可替换的专家模块构成。 |
🧠 参数激活 |
全部参数被激活。 |
静态稀疏,激活的参数路径固定。 |
动态稀疏,由门控网络根据输入动态选择激活的专家。 |
💻 计算负载 |
与总参数量成正比,计算密集。 |
理论上计算量下降,但因非结构化,在GPU上难以获得实际加速。 |
计算量仅与少数被激活的专家相关,总参数多但计算成本可控。 |
📈 扩展性 |
受限于计算资源,扩展成本高。 |
扩展性较差,剪枝比例受限。 |
极佳,易于通过增加专家数量扩展至万亿级参数。 |
⚙️ 实现与优化 |
简单,易于训练和部署。 |
实现复杂,需要专门的稀疏计算库和硬件支持才能获得收益。 |
实现相对复杂,需处理路由、负载均衡等,但对现代硬件友好。 |
3. MOE 核心机制深度剖析
本章将深入拆解MOE模型的内部工作机制,详细介绍其模型结构、路由原理、负载均衡策略、专家容量设定及辅助损失函数等关键技术点。
3.1 模型结构:专家与门控
一个标准的MOE层由两大核心组件构成:一组“专家网络”和一个“门控网络”。它们协同工作,实现了计算的稀疏化。
3.1.1 专家网络 (Experts)
🎯 定义:每个专家(Expert)都是一个独立的神经网络模块。在基于Transformer的MOE模型中,每个专家通常就是一个标准的前馈神经网络(FFN)。一个MOE层中可以包含数十、数百甚至数千个这样的专家。
- 功能:各司其职的“专才”。在训练过程中,不同的专家会逐渐学习并擅长处理不同类型的数据、特征或模式。例如,在语言模型中,一个专家可能专精于语法分析,另一个则可能擅长识别命名实体。
- 并行性:由于所有专家在结构上相互独立,它们可以被高效地部署在不同的计算核心(如GPU/TPU)上,进行并行计算,这是MOE架构能够高效扩展的关键。
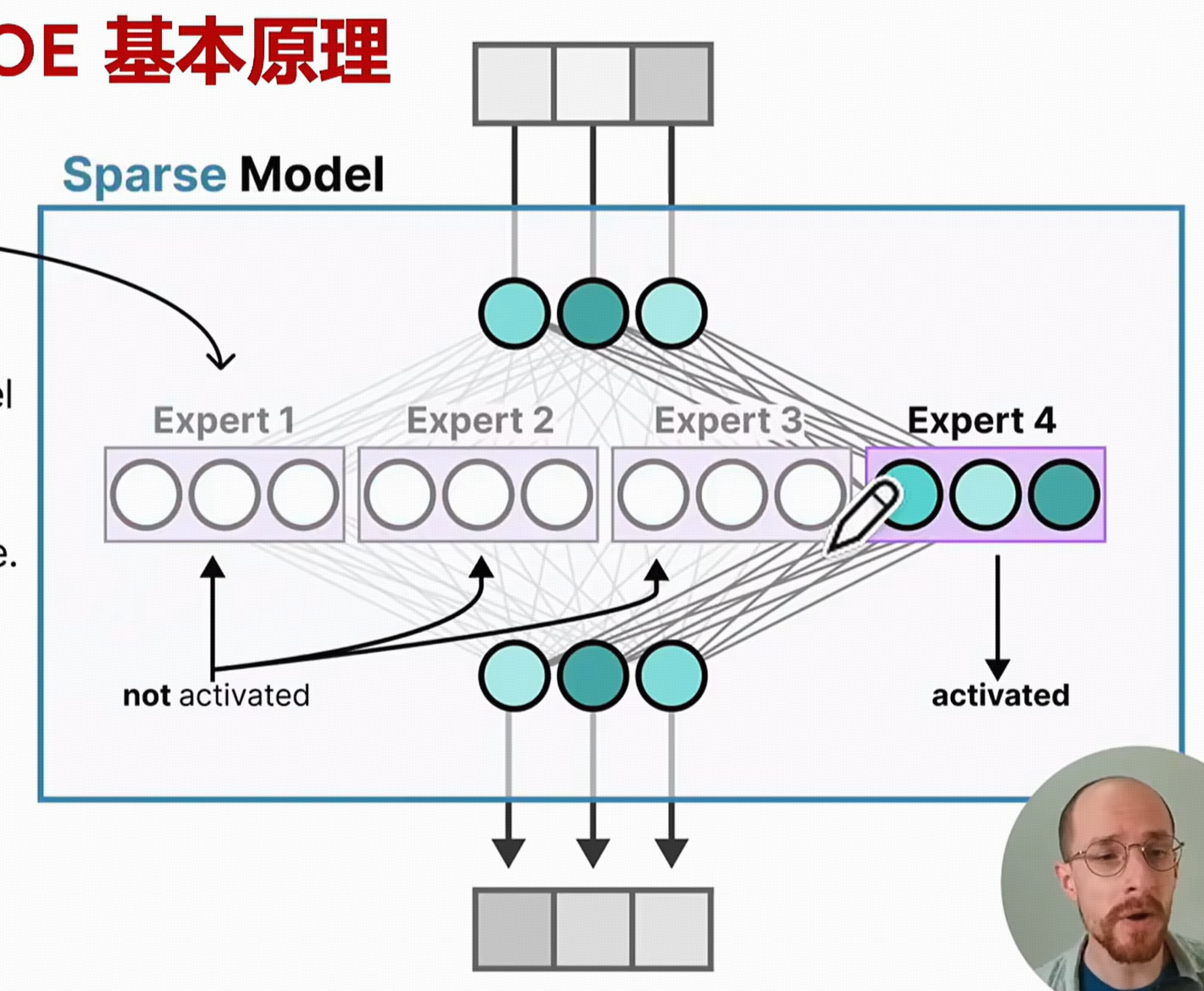
3.1.2 门控网络 (Gating Network)
🎯 定义:门控网络(Gating Network)通常是一个非常轻量级的神经网络,比如一个简单的线性层,其后跟一个Softmax函数。
- 功能:智慧的“调度中心”或“路由器”。它的唯一职责是根据当前的输入数据(Token),为每一个专家计算一个“匹配分数”或“权重”,然后依据这些分数来决定应该将该Token发送给哪些专家处理。
- 动态性:门控网络的路由决策是高度动态的,即对不同的输入Token,它会给出不同的路由方案,从而实现计算资源的灵活按需分配。

3.2 路由原理:如何选择合适的专家?
路由(Routing)是MOE的核心机制,它决定了数据在MOE层中的流向。现代MOE的基石是由Shazeer等人在其开创性论文《Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer》中提出的**稀疏门控(Sparsely-Gated)**机制。
在一个标准的Transformer解码器(Decoder)模块中,MOE层通常用于替换原有的前馈网络(FFN)层。
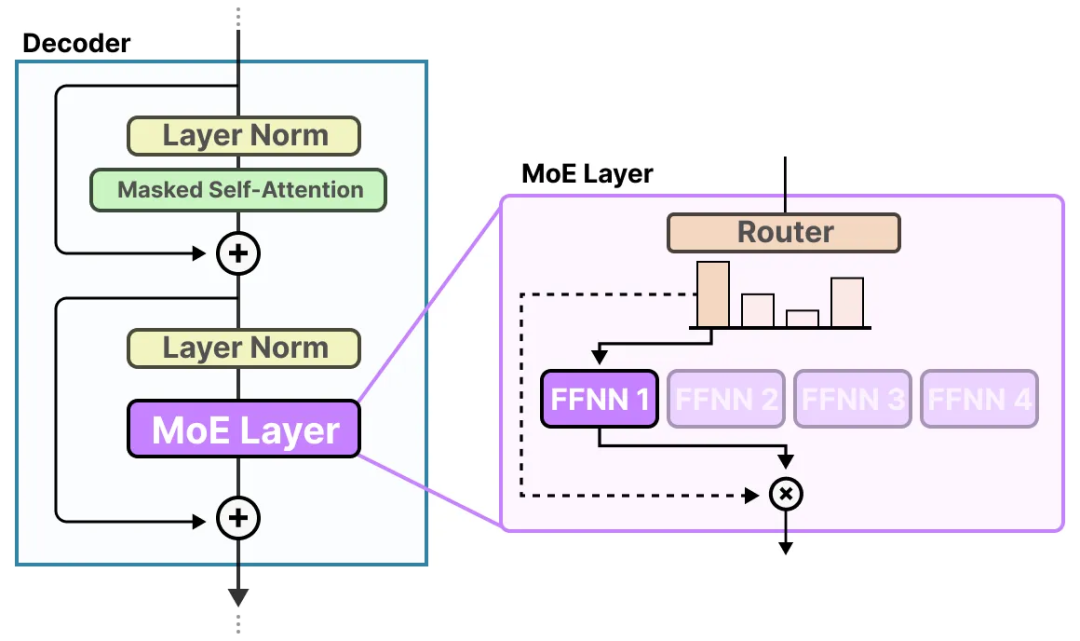
图:左侧为标准Transformer解码器块,右侧展示了如何用一个MOE层替换FFN层。MOE层内部包含一个路由器(Router)和多个专家(Experts)。 (来源: Jay Alammar)
整个过程可以概括为“决策-分发-计算-整合”四个步骤,其核心就是Top-K Gating。
📝 Top-K Gating 工作流程
- 计算路由分数:输入Token
x的向量表示被送入门控网络G(通常是一个简单的线性层W_g)。门控网络为所有n个专家输出一个分数(logits)向量h(x) = x · W_g。 - 保留Top-K分数:系统会选择分数向量
h(x)中最高的K个值,并将其余值设为-∞。K是一个小的超参数(例如1或2),这步是实现稀疏性的关键。 - 计算专家权重:将经过处理的分数向量通过
Softmax函数进行归一化,生成最终的路由权重G(x)。由于上一步的操作,只有Top-K个专家会获得非零权重。G(x) = Softmax(Top_K(h(x)))。 - 加权整合输出:将输入
x分发给所有专家E_i进行计算,然后将它们的输出E_i(x)与门控网络计算出的权重G(x)_i相乘并求和,得到MOE层的最终输出Y。
Y = Σ (G(x)_i * E_i(x))
由于只有K个权重非零,所以实际上只有K个专家参与了计算。
通过这个精巧的路由机制,MOE模型成功地在每次前向传播中只使用了一小部分参数,从而在拥有巨大模型容量的同时,保持了极高的计算效率。
3.3 负载均衡:防止专家“过劳”或“摸鱼”
当训练过程中,模型可能会去选择一些计算比较快的网络,无论是什么输入,模型都会去选择一些小网络计算快。为了放在小网络学到太多,但是大网络学的太少。
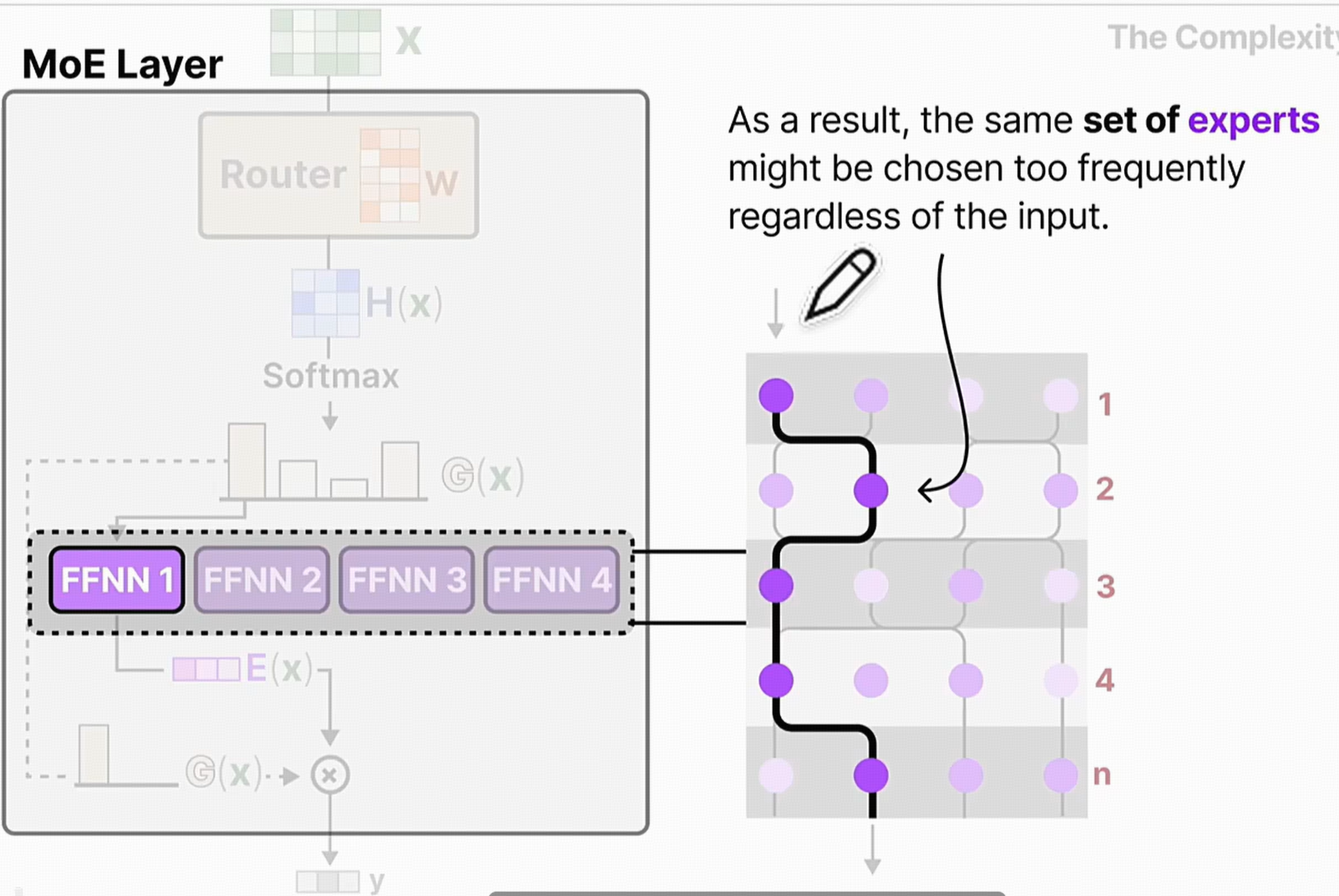
Sparsely-Gated MoE 论文的另一大核心贡献是识别并解决了**负载不均衡(Load Imbalance)**问题。
3.3.1 负载不均的风险
在训练过程中,门控网络可能会出现“马太效应”:它倾向于将大部分输入Token路由给少数几个“受欢迎”的专家,因为这些专家可能在训练初期表现稍好。
- 恶性循环:受欢迎的专家得到更多训练,能力变得更强,从而吸引更多Token,形成正反馈循环。
- 专家“死亡”:不受欢迎的专家很少被激活,得不到充分训练,其参数基本不变,最终成为无效的模型容量。
- 后果:整个MOE系统会退化成一个规模小得多的模型,浪费了大量的参数和计算潜力,并可能导致训练不稳定。
3.3.2 负载均衡损失(Load Balancing Loss)
为了解决这个问题,论文引入了一项巧妙的辅助损失函数(Auxiliary Loss),即负载均衡损失。它被加入到模型的总损失中,以激励门控网络将Token更均匀地分配给所有专家。
💡 核心思想
负载均衡损失通过惩罚那些“分配不均”的路由决策来起作用。它会计算在一个训练批次(batch)中,分配给每个专家的Token比例,如果这个比例分布不均(某些专家过多,某些过少),损失值就会变大。
该损失旨在最小化专家负载的变异系数。一个简化的概念是,如果一个批次中的T个Token被分配给了n个专家,那么理想情况下每个专家应该处理T/n个Token。负载均衡损失会惩罚偏离这个理想状态的分配方案。
模型的最终损失函数变为:Total Loss = Main Loss (e.g., Cross-Entropy) + α * Load Balancing Loss,其中 α 是一个用于平衡主任务和负载均衡任务的超参数。通过这种方式,模型在学习主任务的同时,也被引导去更有效地利用所有专家,从而最大化整体性能和训练稳定性。
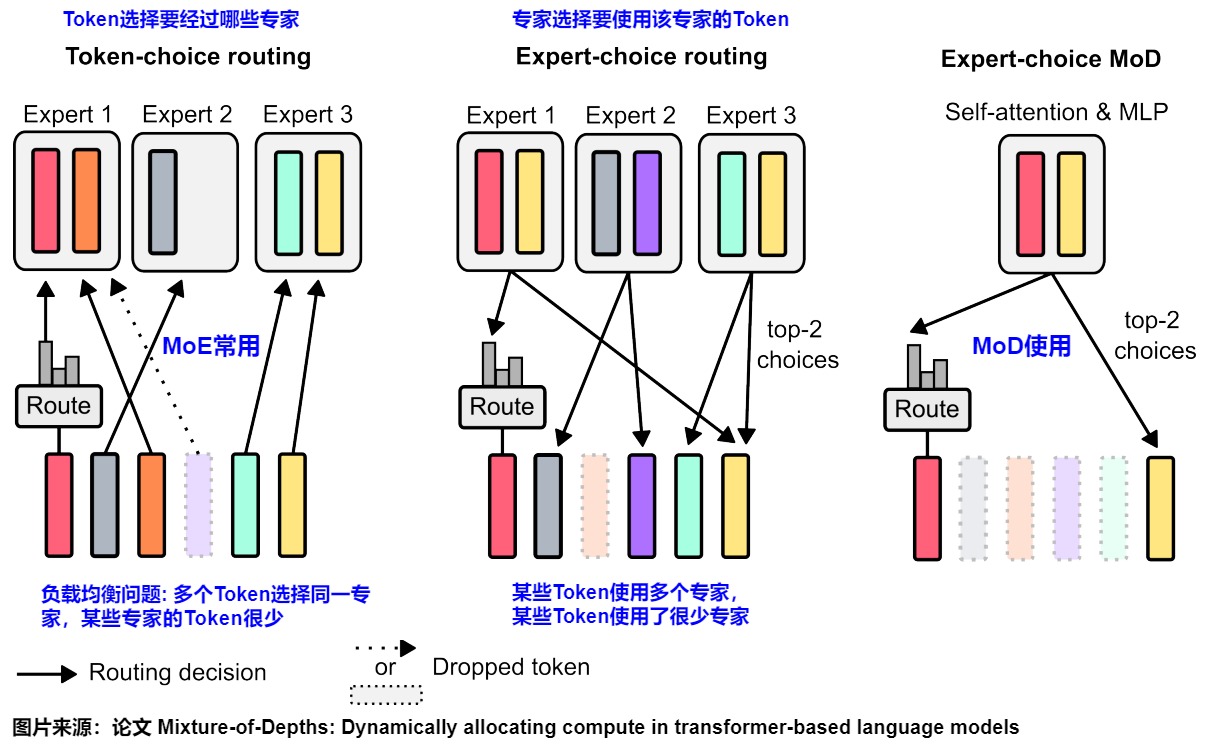
图:不同的路由策略示意图。Token-choice(左)是让Token选择专家,容易导致负载不均。而Expert-choice(中、右)则是让专家反过来选择Token,这是一种更主动的负载均衡方式。 (来源: Google Research)
3.4 专家选择
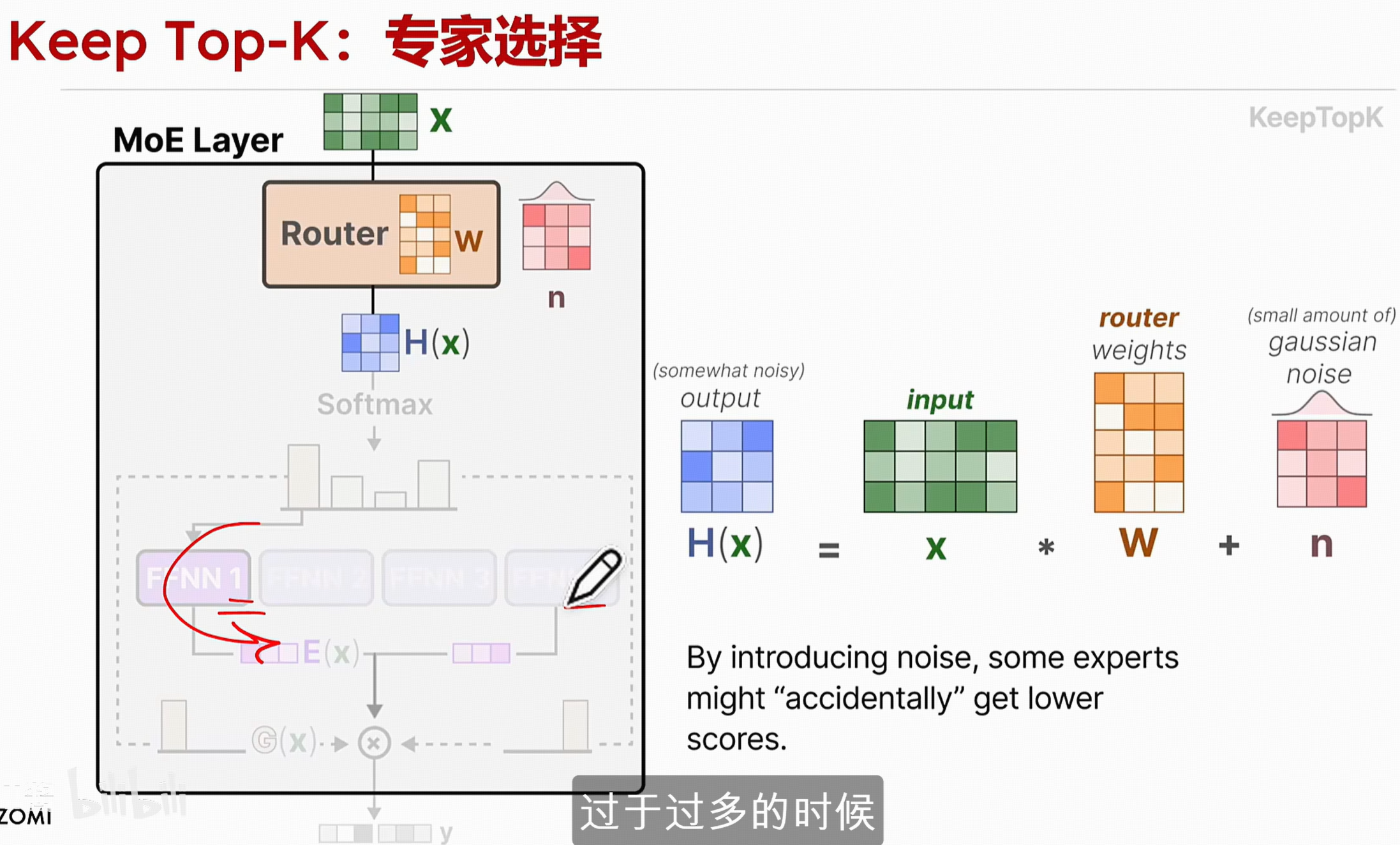
当某些专家被选择的过于频繁,就会引入一个高斯噪声n去抑制,这个高斯噪声不是随机的矩阵,而是当某些专家被过于平凡的选择的时候去降低他在路由选择中的一个得分。
3.4 专家容量:每个专家能接待多少“访客”?
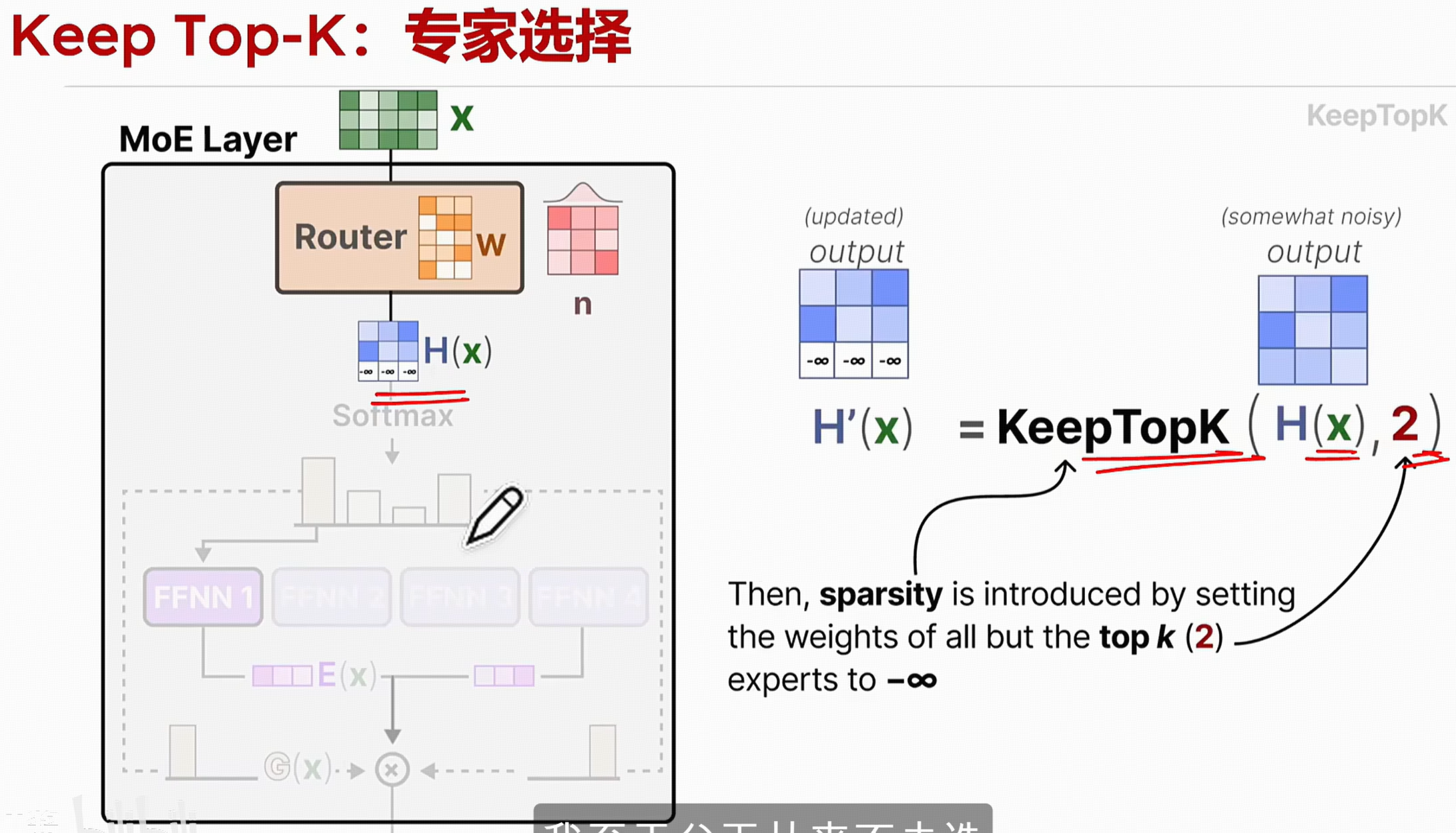
引入一个keepTopK来只获取得分最高的矩阵参数,将其他的置为负无穷。这样当softmax之后就变0。
只会去选择得分最高的专家。

3.5 辅助损失(load balancing loss):其实也是为了提升均衡负载


4. 主流大模型中的MOE架构
本章将分析当前业界顶尖的大语言模型(如GPT系列、Qwen、DeepSeek等)是如何应用MOE架构的,并对比它们在实现方案、创新点及优缺点上的异同。
4.1 GPT 系列的MOE探索
尽管OpenAI从未官方公布GPT-4的详细架构,但根据业界广泛的分析和爆料,它极有可能是一个大型的MOE模型。这种架构是其实现卓越性能和庞大知识容量的关键。
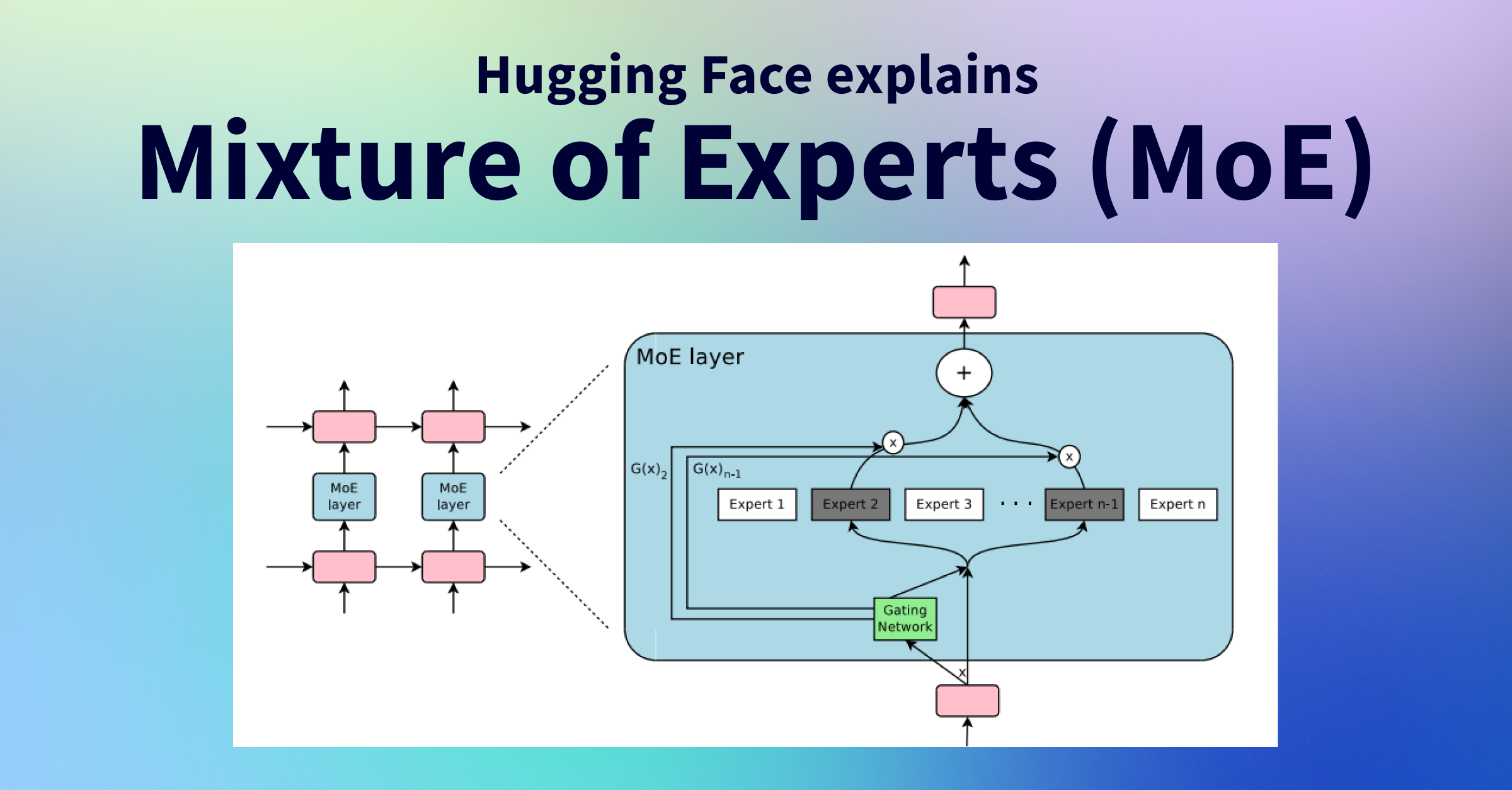
图:据传GPT-4采用了类似的MOE架构,通过组合多个专家子网络来提升模型总容量。
- 推测结构:据传GPT-4可能由8个甚至16个专家模型组成,每个专家的参数量约为2200亿,总参数量高达1.8万亿。
- 路由机制:它很可能采用了标准的Top-K门控机制(K可能为2),即对每个Token,路由到最相关的两个专家进行处理。
- 优缺点:
-
- 优势:通过MOE架构,GPT-4在保持相对可控的单次计算成本下,实现了巨大的模型容量,这是其强大通用能力的基础。
- 劣势:巨大的总参数量带来了极高的训练和推理硬件成本,部署和维护复杂度极高,且模型本身不开源,限制了社区的研究和应用。
4.2 Qwen (通义千问) 的MOE实践
阿里巴巴通义千问团队则采取了更为灵活和开放的策略,在其Qwen系列模型中同时布局了稠密模型和MOE模型,为不同需求的用户提供了多样化的选择。
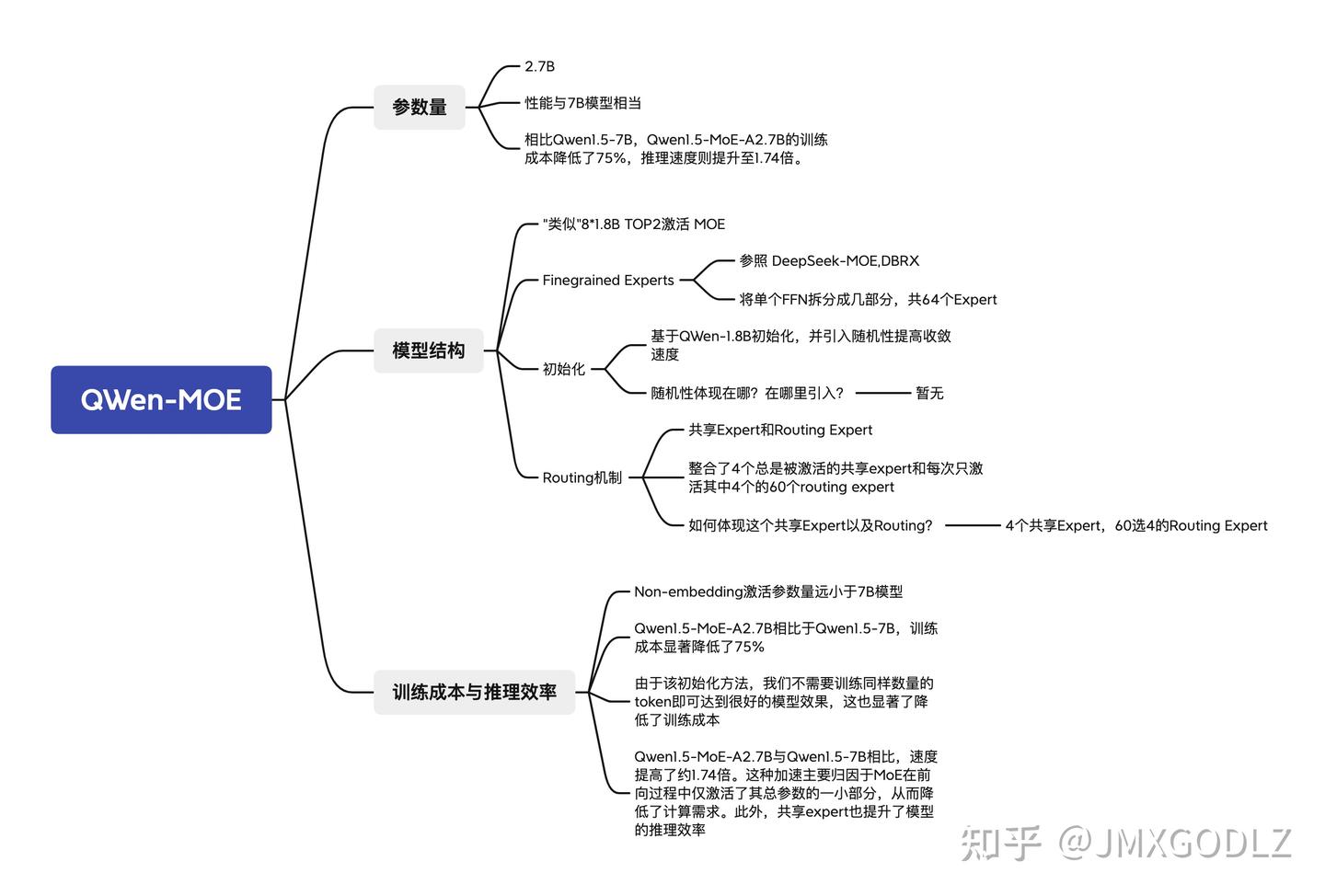
图:Qwen-MOE的技术特点,涵盖了模型结构、路由机制和训练效率等方面的优化。 (来源: 知乎 @JMXGODLZ)
- 结构特点:Qwen的MOE模型(如Qwen1.5-MoE-A2.7B, Qwen2-57B-A14B)明确地将MOE层集成到其Transformer架构中,并向社区开源。如上图所示,其设计参考了DeepSeek和DBRX等模型的Top-2激活机制,并对专家进行了细粒度划分。
- 核心创新:
-
- 全局负载均衡损失:Qwen团队在实践中发现,传统的负载均衡损失可能无法很好地保证专家特异性。他们提出了一种全局批次负载均衡损失(Global Batch Load Balancing Loss),在更大范围内(全局批次而非本地批次)促进负载均衡,有助于训练出分工更明确、能力更专业的专家。
- 优缺点:
-
- 优势:开源策略极大地推动了MOE技术的普及。其灵活的模型矩阵(同时提供Dense和MoE版本)满足了从端侧到云端的不同部署需求。在负载均衡等关键技术上有深入的探索和创新。
- 劣势:与GPT或DeepSeek等在特定路线上极致优化的模型相比,其通用性策略可能需要在特定任务的峰值性能上做出一些权衡。
4.3 DeepSeek 的MOE架构
DeepSeek是MOE架构坚定的实践者和创新者,其开源的DeepSeek系列模型(如DeepSeek-V2)以极高的性价比(优异性能和低廉的推理成本)而闻名。
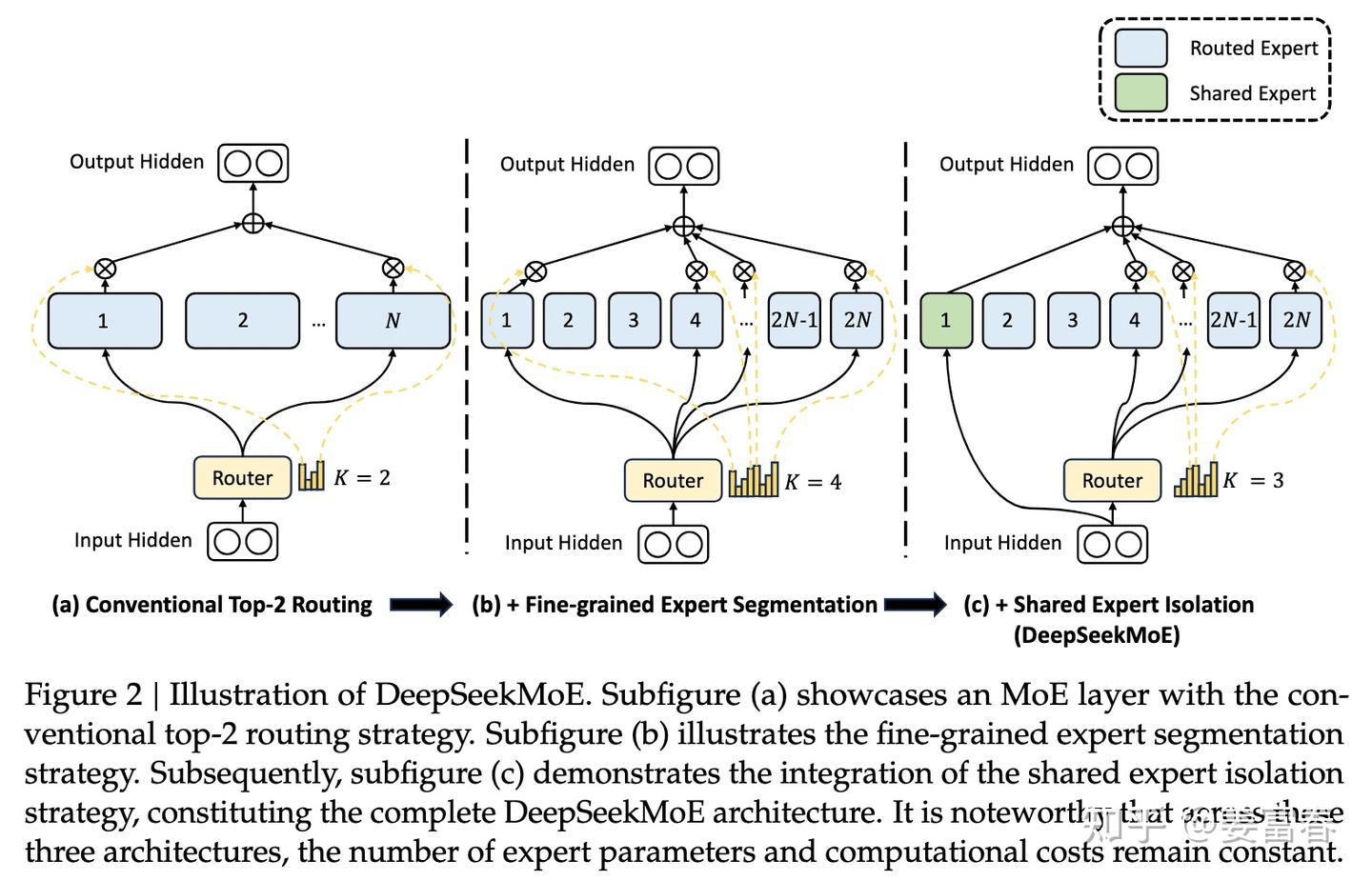
图:DeepSeekMoE架构的演进示意图。从传统的Top-2路由(左),到细粒度的专家切分(中),再到引入隔离的共享专家(右),体现了其在结构上的持续创新。 (来源: DeepSeek AI)
- 结构特点:DeepSeek的MOE架构在设计上追求极致的效率。
- 核心创新:
-
- 共享专家与路由专家:如上图右侧所示,DeepSeek创新地为每个MOE层引入了“共享专家”(Shared Expert)。所有Token都会经过这个共享专家,它负责学习通用知识;同时,Token还会被路由到几个“路由专家”(Routed Experts)之一,这些专家则学习更专业的知识。这种设计兼顾了知识的广度与深度。
- MLA低秩压缩注意力:为了解决大模型推理中KV缓存占用显存过多的问题,DeepSeek设计了多头低秩注意力(Multi-head Latency-aware Attention, MLA),显著压缩了KV缓存大小,进一步降低了部署成本。
- 优缺点:
-
- 优势:推理效率极高,成本低廉,使其在开源社区和商业应用中极具竞争力。在MOE架构上有独特的创新(如共享专家),性能表现优异。
- 劣势:作为一个相对较新的模型系列,其在各种复杂场景下的鲁棒性和生态系统的成熟度仍在持续发展和验证中。
4.4 各模型MOE方案对比
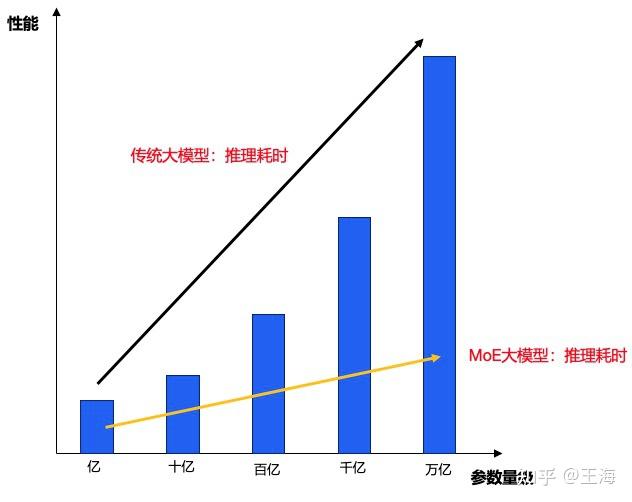
图:MOE模型与传统稠密模型在不同参数规模下的能力对比示意图。可以看出,MOE架构(蓝线)能以相对更平缓的成本增长,实现与更大规模传统模型(红线)相媲美的性能。
特性 |
🤖 GPT-4 (业界推测) |
阿里 Qwen (通义千问) |
🚀 DeepSeek |
架构特点 |
纯MOE架构,专家数量多,总参数规模巨大。 |
Dense和MoE双轨并行,提供多种尺寸选择。 |
效率优先的MOE架构,创新性引入“共享专家”。 |
参数规模 |
总参数量约1.8万亿,激活参数量未知。 |
提供多种规模,如Qwen2-57B-A14B(激活14B)。 |
DeepSeek-V2总参数236B,激活21B。 |
路由机制 |
标准的Top-K Gating。 |
标准的Top-K Gating。 |
路由到“路由专家”,同时所有数据经过“共享专家”。 |
核心创新 |
将MOE架构成功应用于超大规模模型,并取得SOTA性能。 |
提出全局批次负载均衡损失,优化专家训练。 |
共享专家机制、MLA低秩压缩注意力机制。 |
优势 |
性能强大,通用能力极强。 |
开源开放,选择灵活,在负载均衡上有深入研究。 |
推理成本极低,性价比高,架构创新性强。 |
劣势 |
成本高昂,不开源,技术细节是黑盒。 |
性能与极致优化模型相比可能有权衡。 |
生态和全场景鲁棒性有待进一步成熟。 |
开源情况 |
❌ 不开源 |
✅ 开源(部分模型) |
✅ 开源 |
6. 核心代码实现:稠密 vs. 稀疏
本章将提供基于PyTorch的稠密FFN层和稀疏MOE层的核心代码实现,通过带注释的代码对比,帮助您从实践层面理解二者在编程实现上的差异。
6.1 稠密前馈网络(FFN)代码示例
稠密FFN层的实现非常直接。它通常由两个线性层和一个非线性激活函数组成。所有输入数据都会无差别地流经整个网络。

图:稠密FFN层的数据流。输入会经过网络中的每一个连接和计算单元。
代码实现 (PyTorch)
import torch
import torch.nn as nn
import torch.nn.functional as F
class Linear(nn.Module):
def __init__(self, in_feature,out_feature):
super(Linear,self).__init__()
self.fc = nn.Linear(in_feature,out_feature)
def forward(self,x):
return self.fc(x)
class DenseMoELayer(nn.Module):
def __init__(self,num_experts,in_feature,out_feature):
super(MoELayer,self).__init__()
self.num_experts=num_experts
self.experts=nn.ModuleList(Linear(in_feature,out_feature) for _ in range(num_experts))
self.gate=nn.Linear(in_feature,num_experts)
def forward(self,x):
gate_score = F.softmax(self.gate(x),dim=-1)#[batch_size,num_experts]#(10,4)
expert_outputs=torch.stack([experts(x) for experts in self.experts],dim=1)#(10,4,3) #[batch_size,num_experts,out_feature]
output=torch.bmm(gate_score.unsqueeze(1),expert_outputs).squeeze(1)#[10,1,4]*[10,4,3]=[10,1,3]
return output#[10,3]
input_size=5
output_size=3
num_experts=4
model=DenseMoELayer(num_experts,input_size,output_size)
demo = torch.randn(10,input_size)
print(model(demo))实现要点
- 简单直接:结构清晰,代码易于理解。
- 全量计算:
forward函数中的每一步操作(self.fc1,self.activation,self.fc2)都会在每个输入Token上执行,所有参数都参与了计算。这是“稠密”的本质。
6.2 稀疏混合专家(MOE)代码示例
稀疏MOE层的实现则要复杂得多。它需要包含专家模块、门控网络以及处理稀疏路由的逻辑。核心在于forward传播过程中的条件计算。

图:稀疏MOE层的数据处理流程。输入通过门控被路由到被激活的少数专家,最后结果被加权汇总。
代码实现 (PyTorch)
import torch
import torch.nn as nn
import torch.nn.functional as F
class Expert(nn.Module):
"""
单个专家网络,其本身就是一个FFN。
"""
def __init__(self, model_dim, ffn_dim):
super().__init__()
self.net = nn.Sequential(
nn.Linear(model_dim, ffn_dim),
nn.ReLU(),
nn.Linear(ffn_dim, model_dim)
)
def forward(self, x):
return self.net(x)
class SparseMoE(nn.Module):
"""
一个简化的稀疏混合专家(MoE)层。
"""
def __init__(self, model_dim, ffn_dim, num_experts, top_k=2):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
# 创建专家列表
self.experts = nn.ModuleList([Expert(model_dim, ffn_dim) for _ in range(num_experts)])
# 创建门控网络
self.gate = nn.Linear(model_dim, num_experts)
def forward(self, x: torch.Tensor):
# 输入尺寸: [batch_size, seq_len, model_dim]
# 为了简化,我们先将 batch 和 seq_len 合并
original_shape = x.shape
x = x.view(-1, original_shape[-1]) # -> [batch_size * seq_len, model_dim]
# 1. 通过门控网络计算路由分数 (logits)
gate_logits = self.gate(x) # -> [num_tokens, num_experts]
# 2. 找到 Top-K 的专家和对应的权重
# `topk`返回 (values, indices)
top_k_weights, top_k_indices = torch.topk(gate_logits, self.top_k, dim=-1)
# 3. 将权重通过 softmax 归一化
top_k_weights = F.softmax(top_k_weights, dim=-1)
# 4. 准备输出张量
final_output = torch.zeros_like(x)
# 5. 将token路由到对应的专家
# `flat_top_k_indices` 包含了每个token要去的专家的索引
flat_top_k_indices = top_k_indices.flatten()
# `token_indices` 用于追踪每个token的原始位置
token_indices = torch.arange(len(x)).repeat_interleave(self.top_k)
# 6. 稀疏计算:为每个专家分配其负责的tokens
for i in range(self.num_experts):
# 找到所有需要由专家 i 处理的token
expert_mask = (flat_top_k_indices == i)
if expert_mask.any():
# 获取这些token的原始索引
tokens_for_expert_i = token_indices[expert_mask]
# 从原始输入中选出这些token
input_for_expert_i = x[tokens_for_expert_i]
# 让专家 i 进行计算
output_from_expert_i = self.experts[i](input_for_expert_i)
# 获取这些token对应的路由权重
weights_for_expert_i = top_k_weights.flatten()[expert_mask]
# 将专家输出加权后,放回最终输出张量的对应位置
final_output.index_add_(0, tokens_for_expert_i, output_from_expert_i * weights_for_expert_i.unsqueeze(-1))
# 恢复原始形状
return final_output.view(original_shape)
# --- 使用示例 ---
num_experts = 8
top_k = 2
# 创建一个MoE实例
sparse_moe_layer = SparseMoE(model_dim, ffn_dim, num_experts, top_k)
# 使用与上面相同的模拟输入
output = sparse_moe_layer(input_tensor)
print(f"稀疏MoE输出尺寸: {output.shape}")实现要点
- 条件计算:最核心的区别在于
forward函数。它不是一个简单的线性流程,而是包含了路由逻辑。 - 门控决策:
self.gate网络先对每个Token进行评估,决定其与各个专家的相关性。 - Top-K路由:
torch.topk是实现稀疏性的关键,它确保了只有k个专家会被激活。 - 稀疏调度:代码中最复杂的部分(步骤5和6)是如何高效地将Token及其权重分发给被选中的专家,并把计算结果正确地组合回来。这与稠密模型中数据“一视同仁”地流过所有参数形成鲜明对比。