
🙋♀️ 个人主页:颜颜yan_
⭐ 本期精彩:Python函数式编程之美:深入理解生成器与高阶函数
🏆 热门专栏:零基础玩转Python爬虫:手把手教你成为数据猎人
🚀 专栏亮点:零基础友好 | 实战案例丰富 | 循序渐进教学 | 代码详细注释
💡 学习收获:掌握爬虫核心技术,成为数据采集高手,开启你的数据科学之旅!🔥 如果觉得文章有帮助,别忘了点赞👍 收藏⭐ 关注🚀,你的支持是我创作的最大动力!
文章目录
前言
在Python的世界里,函数式编程思想为我们提供了一种优雅而高效的编程方式。今天我们将深入探讨两个重要概念:生成器(Generator)和高阶函数(Higher-Order Functions)。这些特性能显著提升程序的性能和内存使用效率。
生成器:惰性计算的艺术
什么是生成器?
生成器是Python中的一种特殊函数,它可以用来创建迭代器。与普通函数最大的不同在于,生成器包含yield关键字,而不是return。当你调用生成器函数时,它不会立即执行,而是返回一个生成器对象。
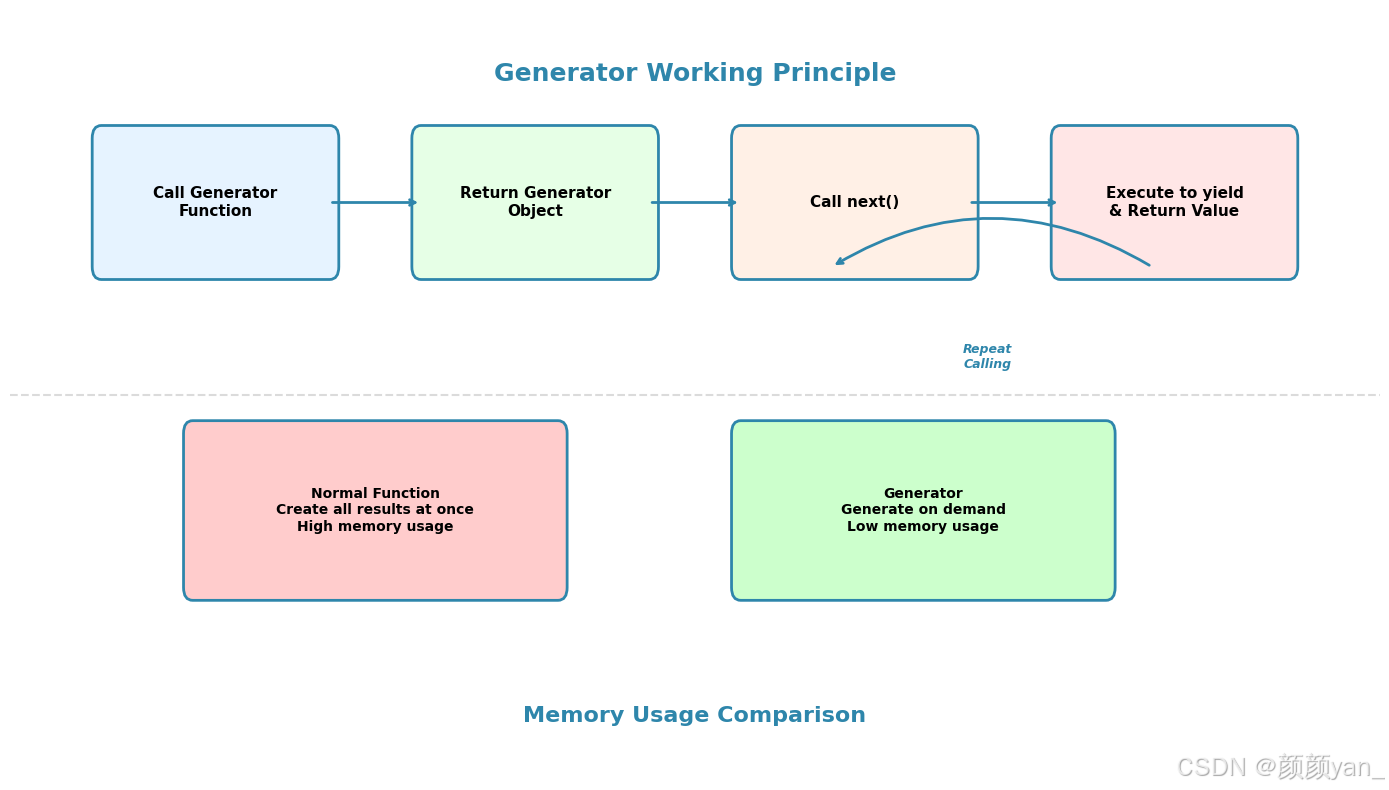
生成器的工作机制
生成器采用的是惰性计算(Lazy Evaluation)方式。这意味着函数不会一次性计算所有结果,只有在需要时才会计算下一个值。不仅极大地节省了内存空间,还特别适合处理大数据集。
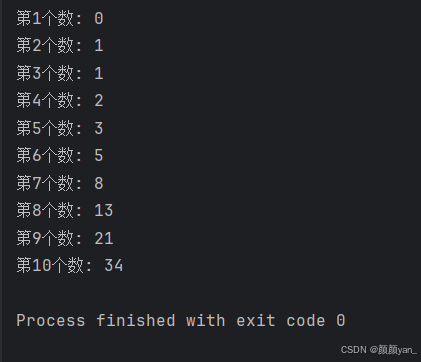
让我们通过一个经典的斐波那契数列例子来理解生成器:
def fibonacci_generator(num):
"""生成斐波那契数列的生成器函数"""
a, b = 0, 1
for _ in range(num):
yield a # 使用yield而不是return
a, b = b, a + b
# 使用生成器
fibonacci = fibonacci_generator(10)
for i, num in enumerate(fibonacci, 1):
print(f"第{i}个数: {num}")
运行结果:
生成器的优势
- 内存效率:即使生成1000个斐波那契数,也只占用很少的内存
- 按需计算:只计算当前需要的值
- 支持无限序列:可以创建理论上无限长的序列
# 创建一个大的生成器,但不立即计算所有值
big_fibonacci = fibonacci_generator(1000)
print(f"创建了生成器对象: {big_fibonacci}")
# 只有调用时才会计算具体值
高阶函数:函数式编程的精髓
高阶函数是函数式编程的核心概念,指的是参数是函数或返回值是函数的函数。Python中最常用的高阶函数包括filter()、map()和reduce()等
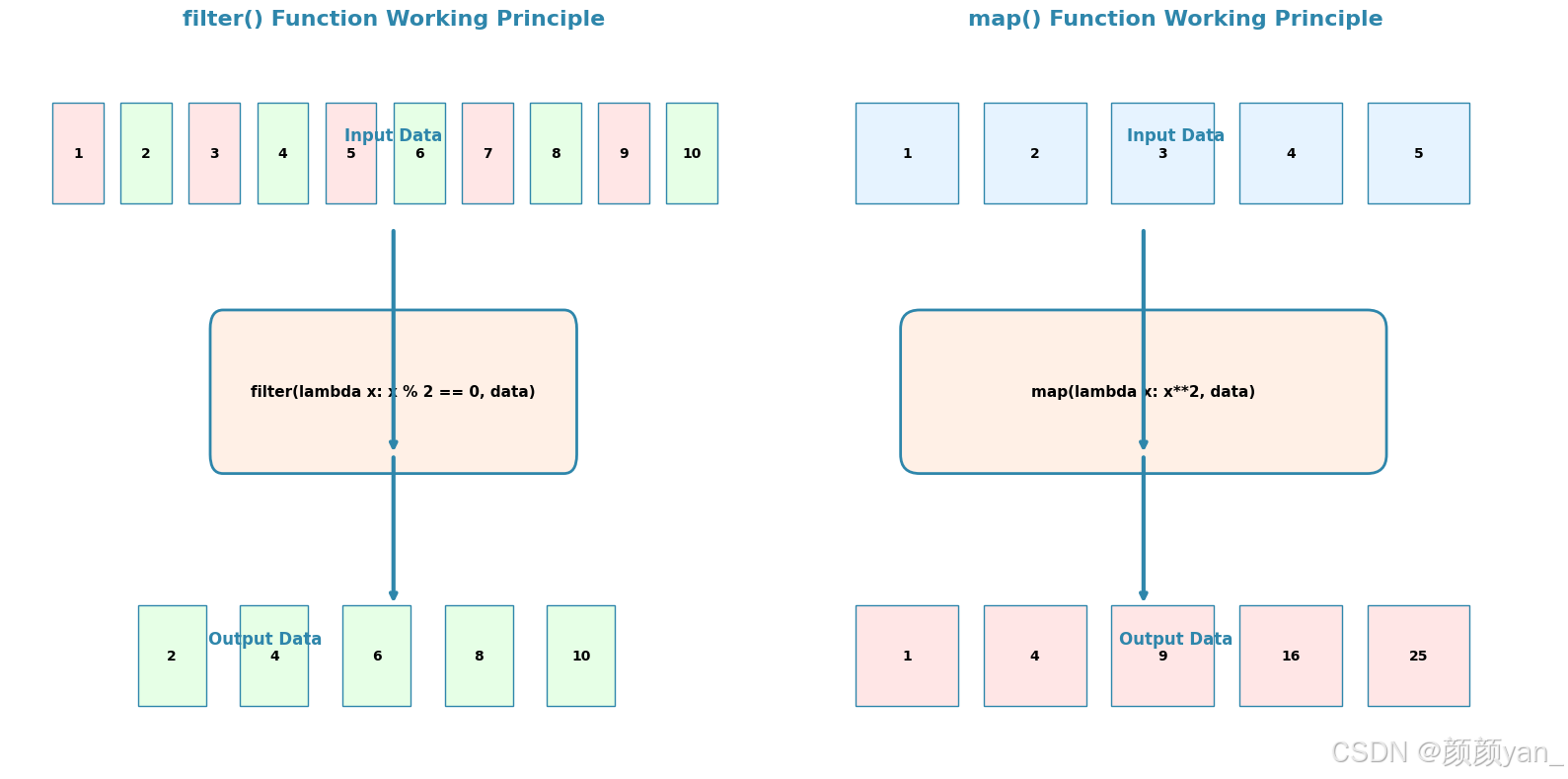
filter()函数
filter()函数用于过滤数据,它接受一个判断函数和一个可迭代对象,返回满足条件的元素。
语法格式:
filter(function, iterable)
工作原理:
- 遍历可迭代对象中的每个元素
- 将元素传入判断函数
- 保留返回
True的元素,过滤掉返回False的元素
示例:
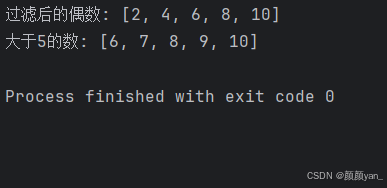
numbers = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 过滤偶数
even_numbers = list(filter(lambda x: x % 2 == 0, numbers))
print(f"过滤后的偶数: {even_numbers}")
# 输出: [2, 4, 6, 8, 10]
# 过滤大于5的数
greater_than_5 = list(filter(lambda x: x > 5, numbers))
print(f"大于5的数: {greater_than_5}")
# 输出: [6, 7, 8, 9, 10]
map()函数
map()函数用于对数据进行变换操作,它将函数应用到可迭代对象的每个元素上。
语法格式:
map(function, iterable)
工作原理:
- 遍历可迭代对象中的每个元素
- 将元素传入变换函数
- 收集变换后的结果
示例:
numbers = [1, 2, 3, 4, 5]
# 计算平方
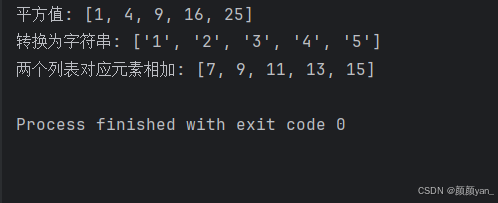
squares = list(map(lambda x: x**2, numbers))
print(f"平方值: {squares}")
# 输出: [1, 4, 9, 16, 25]
# 类型转换
strings = list(map(str, numbers))
print(f"转换为字符串: {strings}")
# 输出: ['1', '2', '3', '4', '5']
# 多个可迭代对象的映射
numbers2 = [6, 7, 8, 9, 10]
sums = list(map(lambda x, y: x + y, numbers, numbers2))
print(f"两个列表对应元素相加: {sums}")
# 输出: [7, 9, 11, 13, 15]
实际应用场景
数据清洗
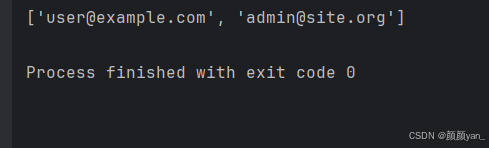
# 从用户输入中过滤有效的邮箱地址
emails = ['user@example.com', 'invalid-email', 'admin@site.org', '']
valid_emails = list(filter(lambda x: '@' in x and '.' in x, emails))
数据预处理
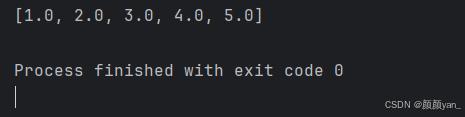
# 将字符串列表转换为浮点数,并计算平方根
import math
str_numbers = ['1', '4', '9', '16', '25']
sqrt_values = list(map(lambda x: math.sqrt(float(x)), str_numbers))
生成器与高阶函数的完美结合
当生成器遇上高阶函数,就能创造出既优雅又高效的代码:
def number_generator(start, end):
"""生成指定范围的数字"""
for i in range(start, end + 1):
yield i
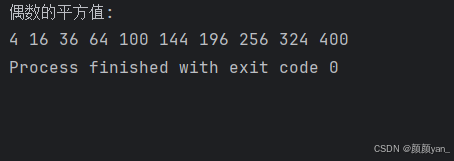
# 生成1-20的数字,过滤偶数,计算平方
numbers = number_generator(1, 20)
even_numbers = filter(lambda x: x % 2 == 0, numbers)
squares = map(lambda x: x**2, even_numbers)
print("偶数的平方值:")
for square in squares:
print(square, end=' ')
性能对比
内存使用对比
import sys
# 普通列表(一次性创建所有元素)
normal_list = [x**2 for x in range(1000000)]
print(f"列表内存占用: {sys.getsizeof(normal_list)} bytes")
# 生成器(按需生成)
generator = (x**2 for x in range(1000000))
print(f"生成器内存占用: {sys.getsizeof(generator)} bytes")
最佳实践建议
选择合适的工具:
- 小数据集:直接使用列表推导式
- 大数据集:优先考虑生成器
- 需要重复访问:使用列表
- 只遍历一次:使用生成器
性能优化:
- 避免不必要的
list()转换 - 合理使用
lambda表达式 - 考虑使用内置函数替代自定义函数
- 避免不必要的
🎯 与我一起学习成长
生成器和高阶函数是Python函数式编程的两大核心特性。生成器通过yield关键字实现惰性计算,能够显著节省内存,特别适合处理大数据集;而filter()和map()等高阶函数则提供了优雅的数据处理方式,让代码更加简洁和可读。掌握这两个概念,能让你写出更加高效、优雅的Python代码,在实际项目中发挥巨大作用。
我是颜颜yan_,一名专注于技术分享的博主。如果这篇文章对你有帮助,欢迎关注我的更多精彩内容!
📚 专栏推荐
💬 期待与你交流
- 有疑问?欢迎在评论区留言讨论
- 想深入学习?关注我获取更多优质教程
- 觉得有用?别忘了点赞👍 收藏⭐ 关注🚀
