
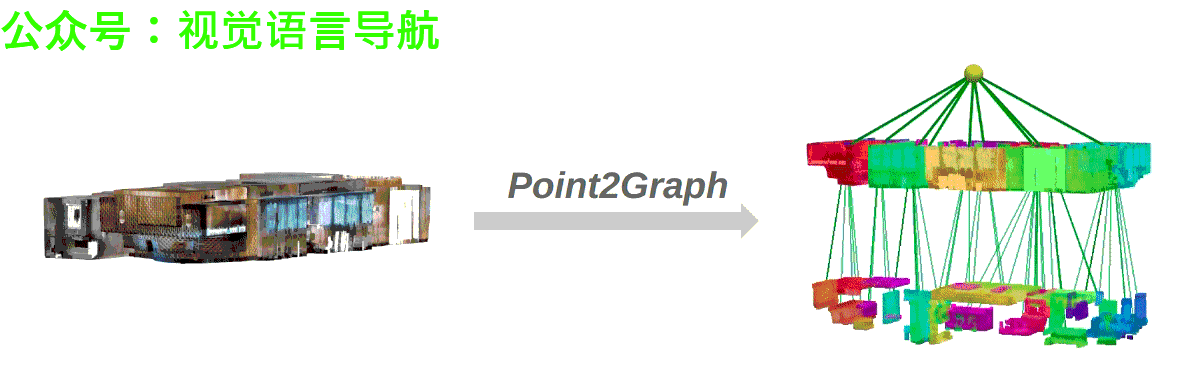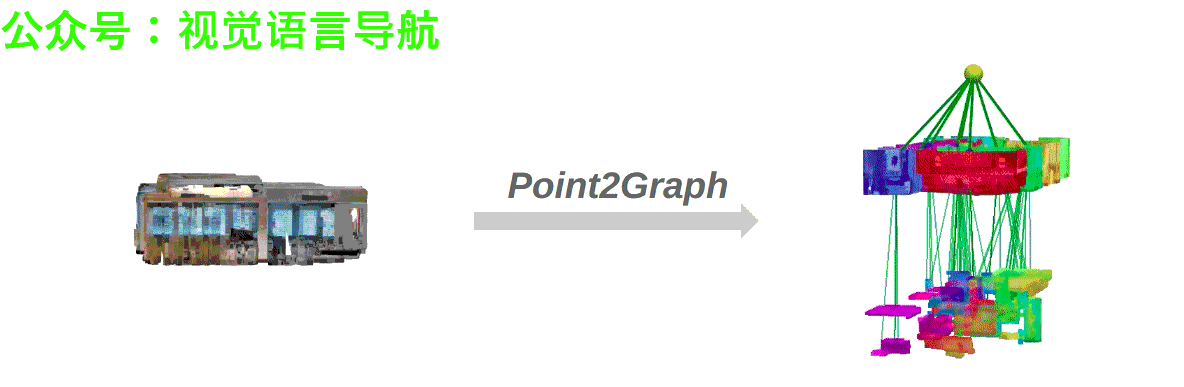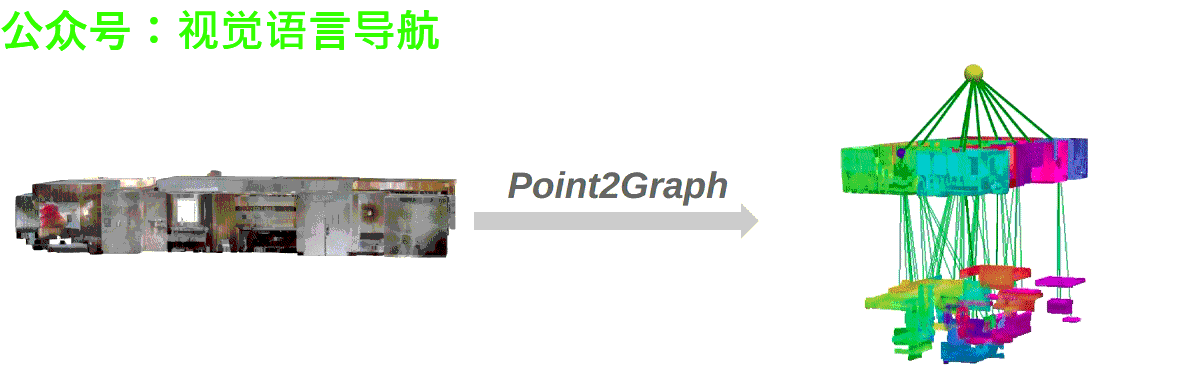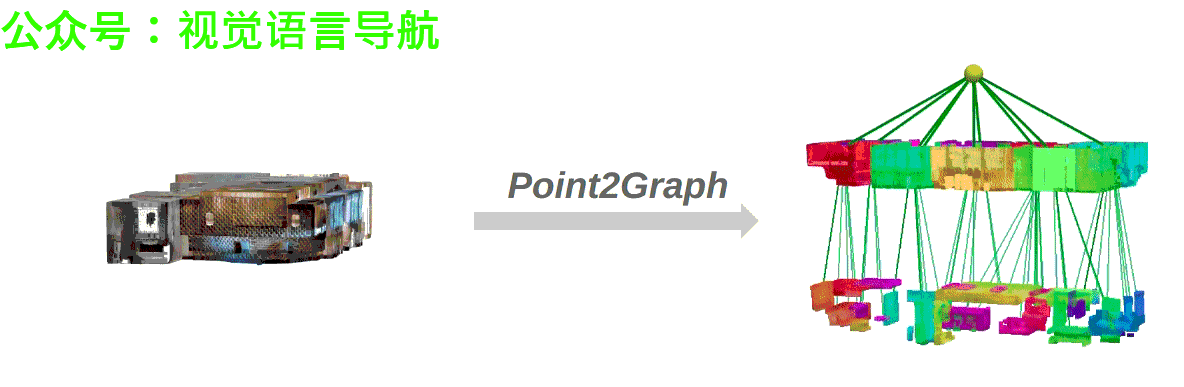
- 作者:Yifan Xu, Ziming Luo, Qianwei Wang, Vineet Kamat, and Carol Menassa
- 单位:密歇根大学
- 论文标题:Point2Graph: An End-to-end Point Cloud-based 3D Open-Vocabulary Scene Graph for Robot Navigation
- 论文链接:https://www.arxiv.org/pdf/2409.10350
- 项目主页:https://point2graph.github.io/
- 代码链接:https://github.com/zimingluo/Point2Graph
主要贡献
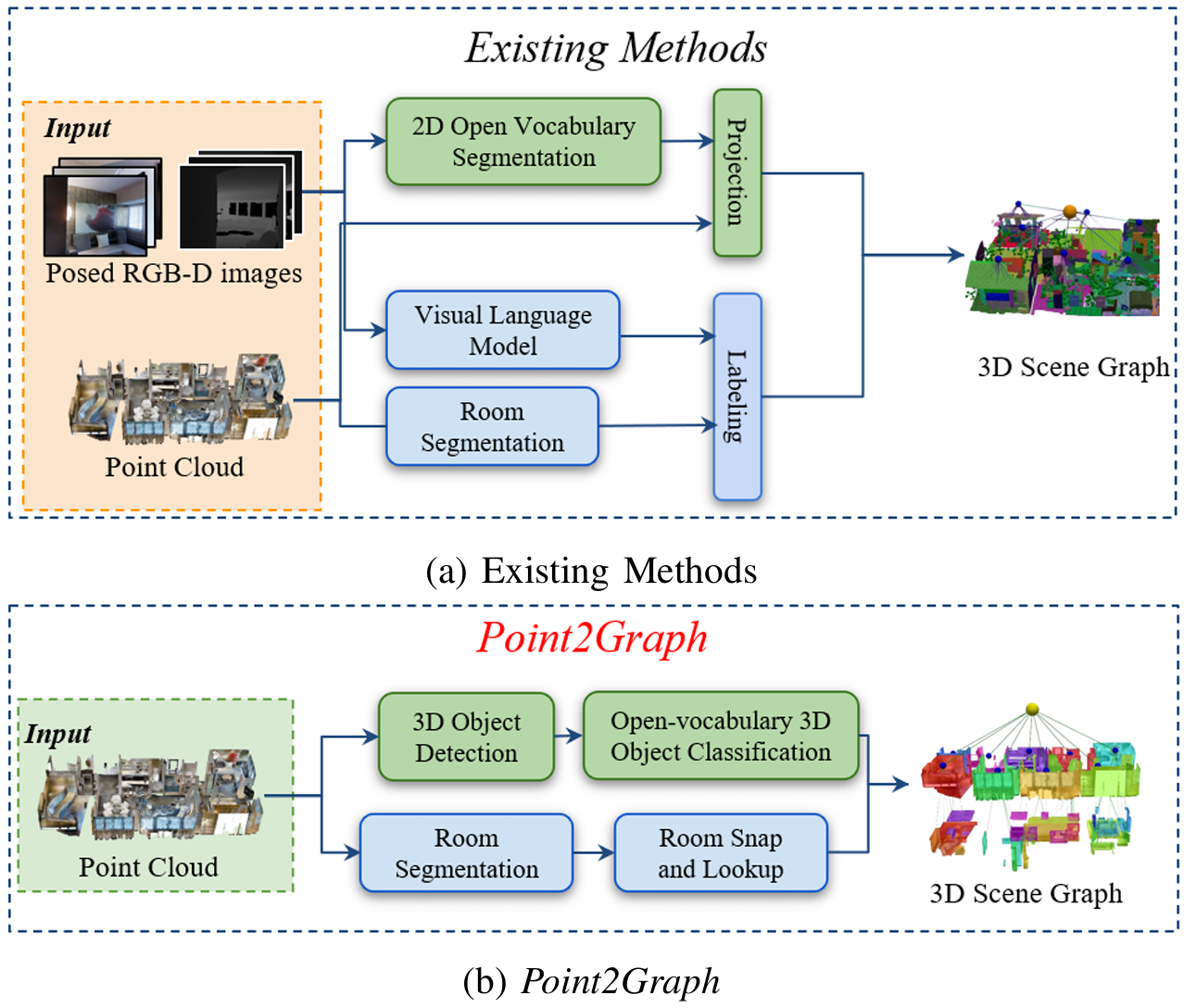
- 提出了基于点云的端到端三维开放词汇场景图生成框架Point2Graph,无需依赖于对齐的RGB-D图像序列,解决了现有开放词汇场景图生成算法在RGB-D图像或相机姿态信息不可用场景下应用受限的问题。
- 提出了基于点云的三维目标检测与分类流程,能够理解高度复杂且真实世界的场景,相比以往的最佳算法能够获得更好的性能。
- 在多个广泛使用的场景基准数据集上进行了性能评估,并在真实世界环境中对辅助移动机器人的导航性能进行了测试。
研究背景
- 三维场景图通过组织房间、目标及其空间层次中的关系来提供结构化的场景表示,有助于理解房间和目标的存在、位置、方向、大小以及它们之间的相对关系,对于机器人地图构建、导航和路径规划等领域至关重要。
- 随着大型语言模型(LLM)和视觉语言模型(VLM)的成功,开放词汇能力对于三维场景图的重要性日益凸显,它能够有效连接机器人与人类,促进机器人在复杂室内环境中的自主性。
- 然而,三维场景图生成面临的一个主要挑战是大规模三维文本数据集的稀缺性,与丰富的互联网规模二维文本数据集相比,三维文本数据对的缺乏导致三维目标和房间分割与分类性能不佳。
- 现有的开放词汇三维场景图生成方法大多依赖于对齐的RGB-D图像和三维点云来创建三维文本对,但这些算法要求能够获取到对齐的RGB-D图像,而在现实场景中,RGB-D图像可能缺失,或者相机姿态信息不可用,这限制了这些算法的应用范围。
方法
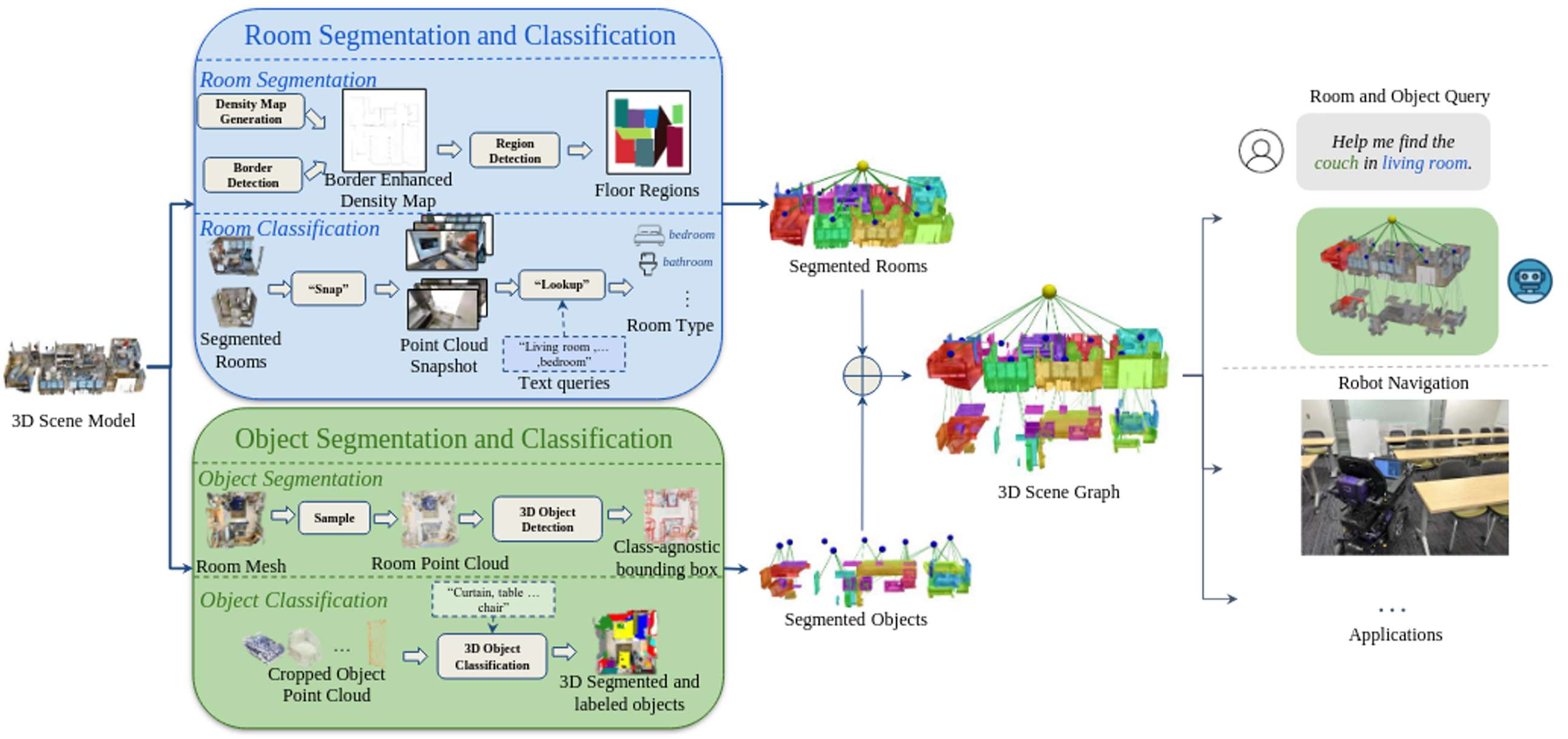
Point2Graph框架分为房间层级和目标层级。在房间层级,通过结合基于几何的边界检测算法与基于学习的区域检测来分割房间,并构建“Snap-Lookup”框架用于开放词汇房间分类;在目标层级,开发了一种端到端的三维目标检测与分类流程,仅依赖于三维点云数据来准确检测和分类三维目标。
房间层级分割与分类
Point2Graph框架在房间层级的任务是通过分割和分类来获取场景中的房间信息。这一部分分为两个子任务:房间分割和房间分类。
房间分割
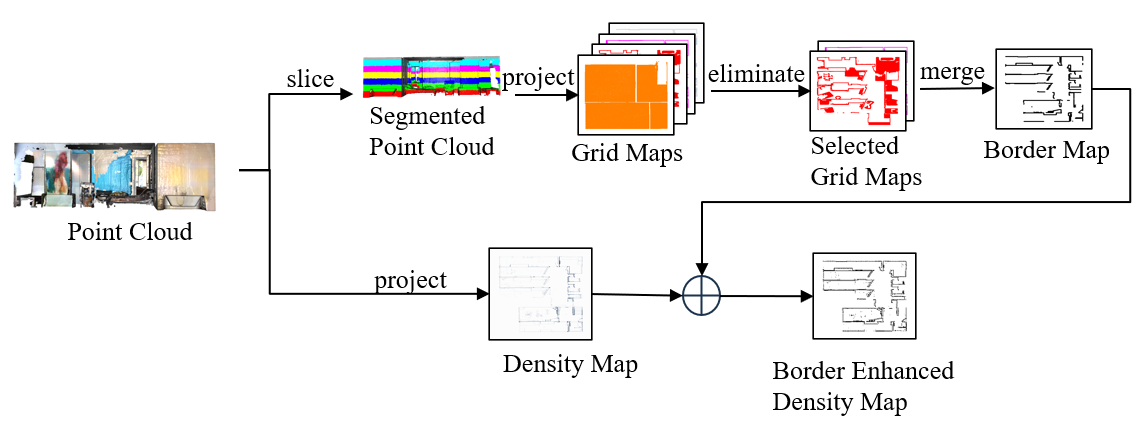
为了准确分割出每个房间,作者采用了基于几何的方法生成边界增强密度图。具体步骤如下:
- 点云切片与投影:将输入点云沿z轴分割成N片,每片投影到一个占用网格图 GkG_kGk 上。
- 自由空间面积计算:计算每个网格图的自由空间面积 SkS_kSk。
- 网格图筛选:通过特定的覆盖标准筛选出有效的网格图层,公式为:
Gselect={Gk∣δbS<Sk<δtS,k=1,…,N} G_{\text{select}} = \{G_k \mid \delta_b S < S_k < \delta_t S, k = 1, \dots, N\} Gselect={Gk∣δbS<Sk<δtS,k=1,…,N}
其中,参数 δb\delta_bδb 和 δt\delta_tδt 分别设为 115\frac{1}{15}151 和 15\frac{1}{5}51。 - 边界图生成:将筛选后的有效网格图层合并,构建边界图 GborderG_{\text{border}}Gborder,公式为:
Gborder(i,j)={1,if ∑k=1MGk(i,j)≥34M0,otherwise G_{\text{border}}(i, j) = \begin{cases} 1, & \text{if } \sum_{k=1}^{M} G_k(i, j) \geq \frac{3}{4}M \\ 0, & \text{otherwise} \end{cases} Gborder(i,j)={1,0,if ∑k=1MGk(i,j)≥43Motherwise
其中,MMM 表示筛选后有效网格图的数量。 - 边界增强密度图生成:将边界图与从原始点云直接投影得到的密度图 GdenG_{\text{den}}Gden 结合,生成边界增强密度图 GcombineG_{\text{combine}}Gcombine,公式为:
Gcombine=γGden+(1−γ)Gborder G_{\text{combine}} = \gamma G_{\text{den}} + (1 - \gamma) G_{\text{border}} Gcombine=γGden+(1−γ)Gborder
权重参数 γ\gammaγ 设为0.9。 - 区域检测:使用RoomFormer模型作为区域检测器,该模型在Structure3D数据集上预训练,并在Matterport3D数据集上进行了微调。
房间分类
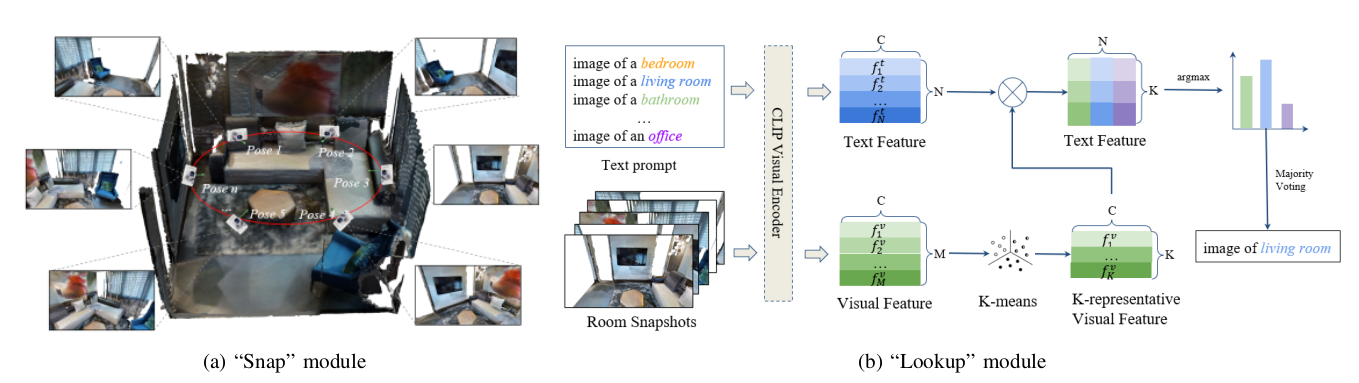
房间分类部分采用“Snap-Lookup”流程,具体步骤如下:
- “Snap”模块:设计了一种椭圆形轨迹的相机姿态,使相机均匀分布在房间周围并面向房间中心,从不同位置对房间进行拍照,获取房间的二维图像。相机姿态公式为:
4(x−xc)2L2+4(y−yc)2W2=1,z=zc \frac{4(x - x_c)^2}{L^2} + \frac{4(y - y_c)^2}{W^2} = 1, \quad z = z_c L24(x−xc)2+W24(y−yc)2=1,z=zc
其中,房间的长度和宽度分别为 LLL 和 WWW,房间中心为 (xc,yc)(x_c, y_c)(xc,yc)。 - 特征提取与分类:使用CLIP视觉编码器从图像中提取嵌入特征,通过K均值算法提取K个代表性视图嵌入,构建这些代表性特征与CLIP文本特征之间的余弦相似度矩阵,沿类别轴取argmax得到K个房间类型预测,最后通过多数投票确定房间类型。
目标层级检测与分类
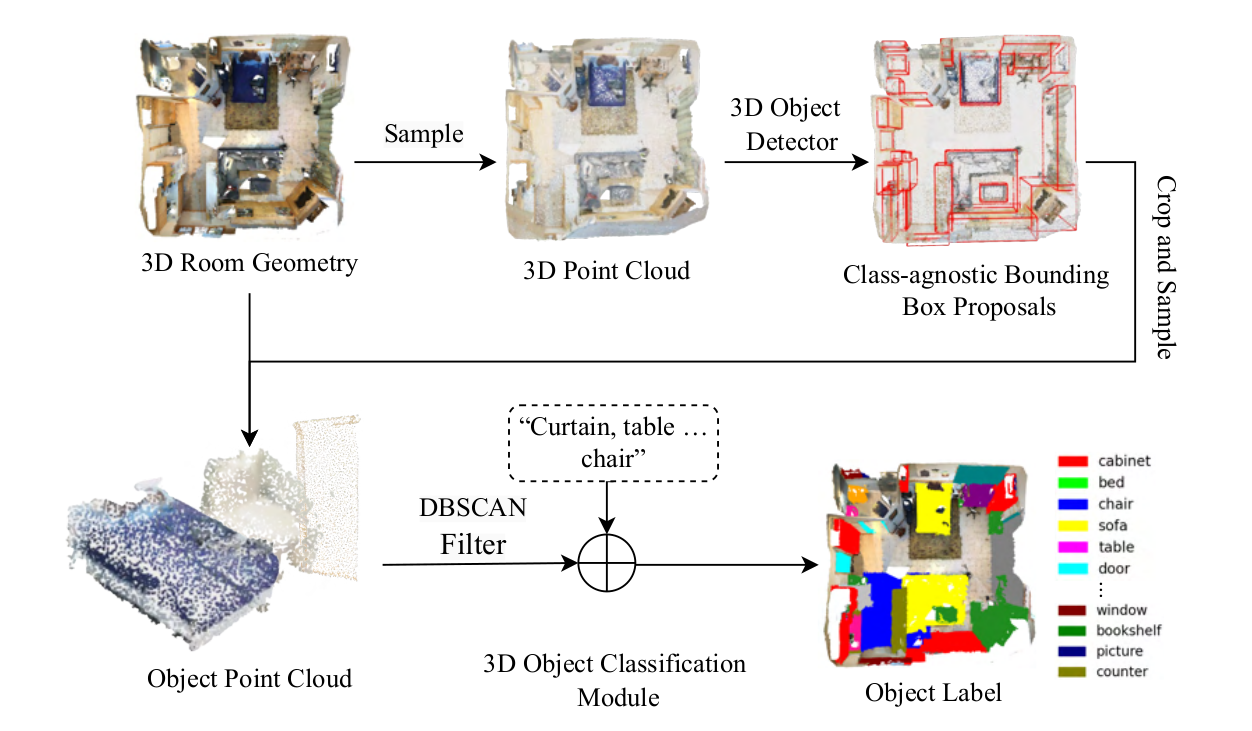
在目标层级的任务是通过检测和分类来获取每个房间中的目标信息。这一部分也分为两个子任务:目标检测和目标分类。
目标检测
目标检测部分的流程如下:
- 点云采样与边界框生成:从分割后的房间级几何信息中对房间点云数据进行采样,利用基于变换器的模块(来自预训练的三维目标检测模型V-DETR)生成每个目标候选的N个边界框。
- 点云裁剪与过滤:对于每个提出的三维边界框,从原始房间点云中提取并裁剪出对应的目标点云 PkbP_k^bPkb,然后使用DBSCAN算法对裁剪后的点云进行过滤,排除噪声点或背景区域,公式为:
Pkobj=DBSCAN(Pkb,n),k=1,…,N P_k^{\text{obj}} = \text{DBSCAN}(P_k^b, n), \quad k = 1, \dots, N Pkobj=DBSCAN(Pkb,n),k=1,…,N
其中,nnn 表示目标检测模块所需的点数,PkobjP_k^{\text{obj}}Pkobj 表示过滤后的目标点云。 - 点云中心化与归一化:将过滤后的点云进行中心化和归一化处理,以便为后续分类阶段准备数据。
目标分类
- 跨模态检索:利用一种最先进的语言对齐的大规模三维基础模型Uni3D进行开放词汇三维目标分类。该模型将过滤后的三维点云和文本描述作为输入,通过识别点云的视觉特征与文本特征之间的对齐关系来检索适当的目标标签。这种方法无需注释训练数据和RGB-D对齐,能够有效地泛化到各种目标和环境中。
Voronoi导航图
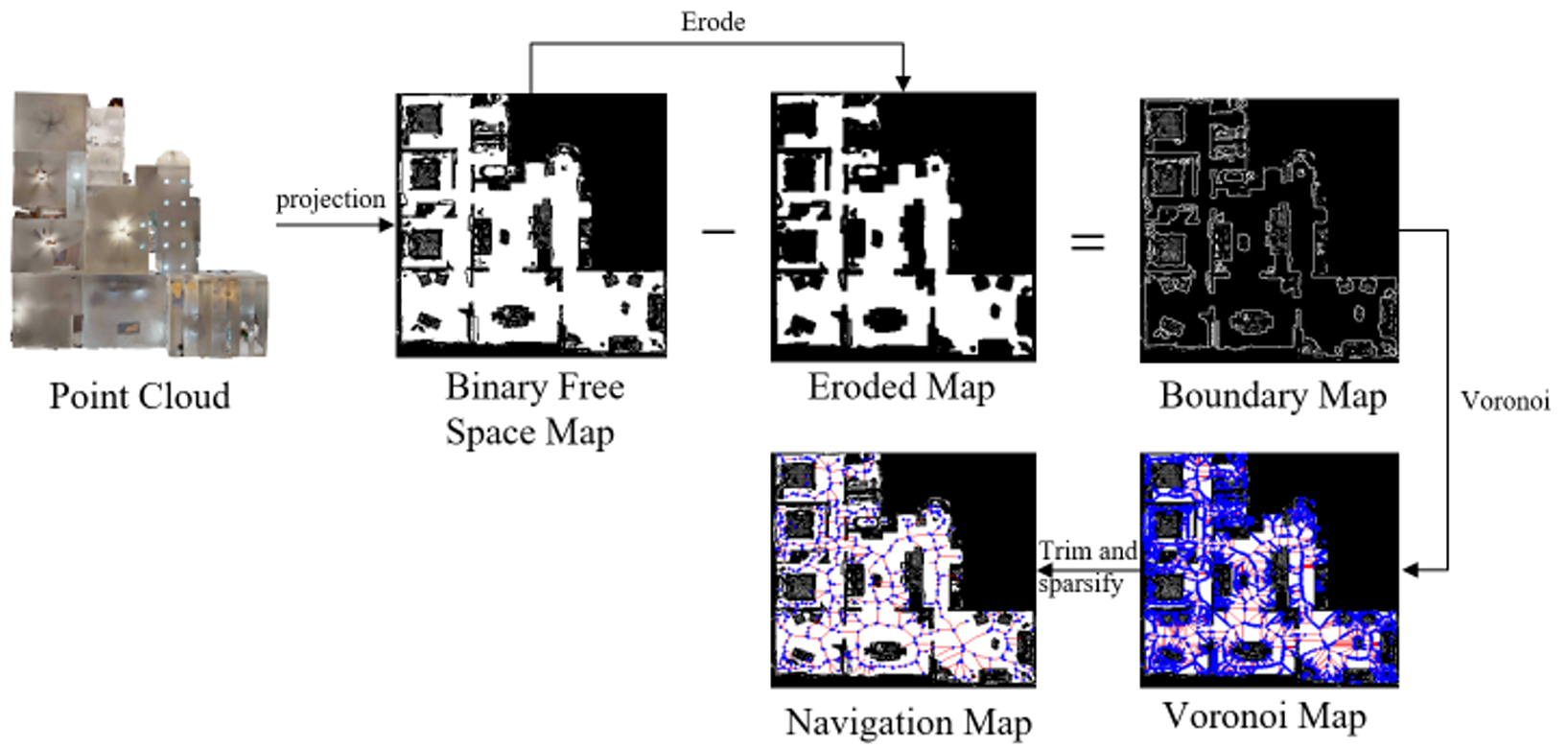
为了使机器人能够在构建场景图的区域内进行导航,作者提出了一种基于Voronoi图的导航图。具体步骤如下:
- 自由空间图生成:将点云投影到xy平面内机器人高度范围内的区域,得到二值自由空间图。
- 边界提取:通过从原始二值自由空间图中减去侵蚀后的自由空间图,得到整个楼层的边界。
- Voronoi图生成与稀疏化:利用Voronoi规划器生成Voronoi导航图,并对其进行稀疏化和修剪,得到最终的导航图。
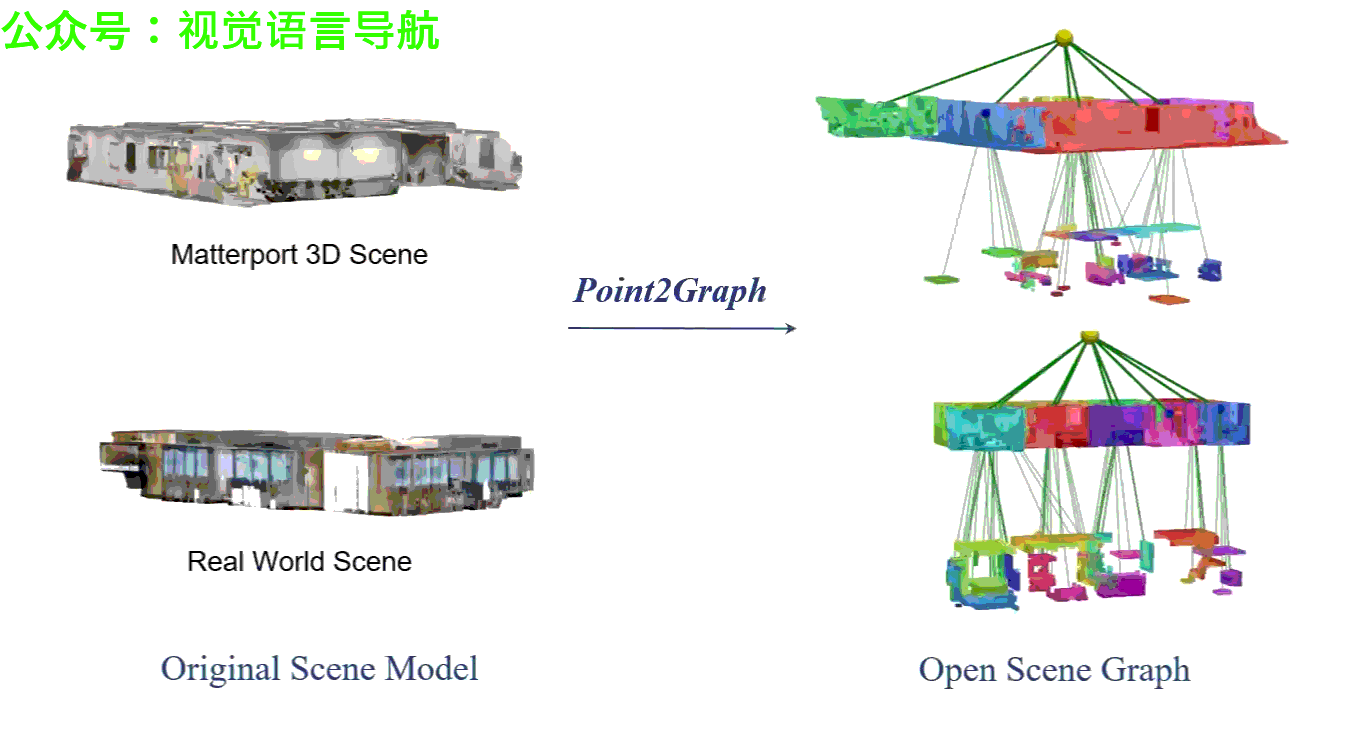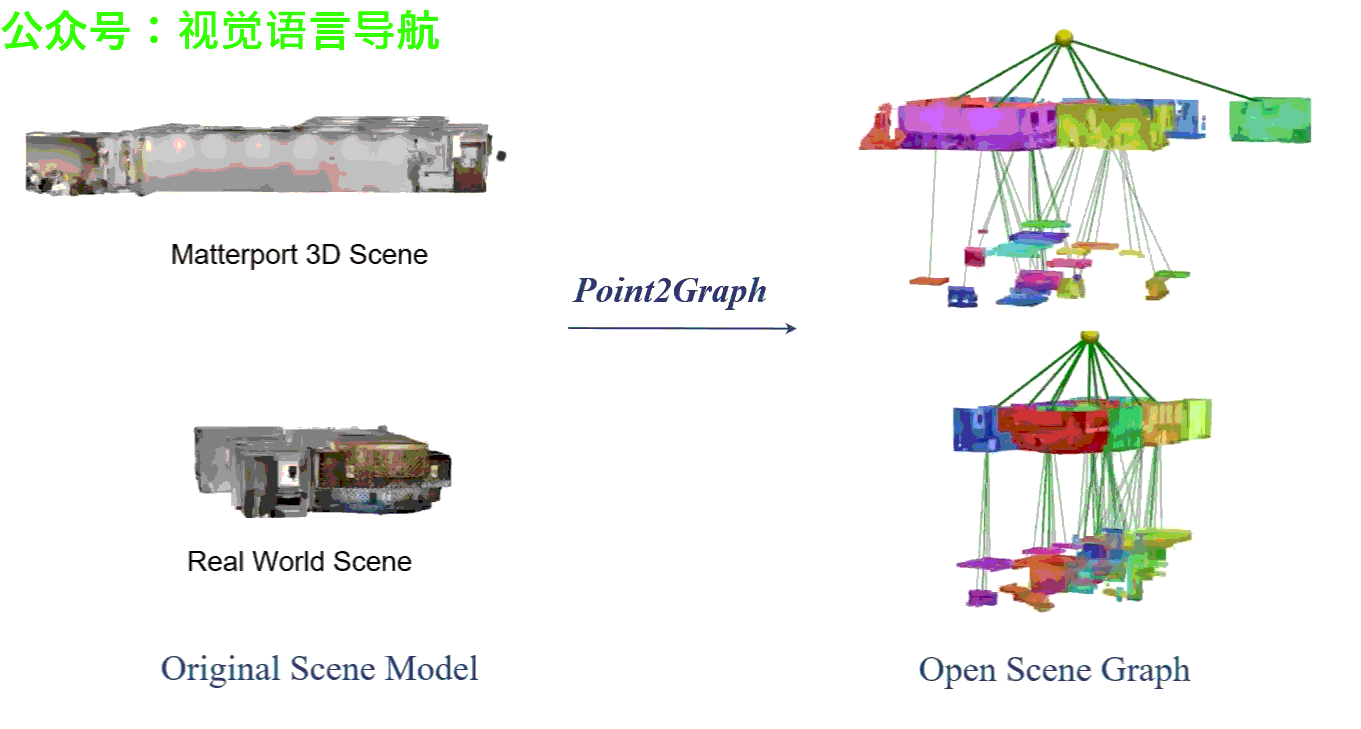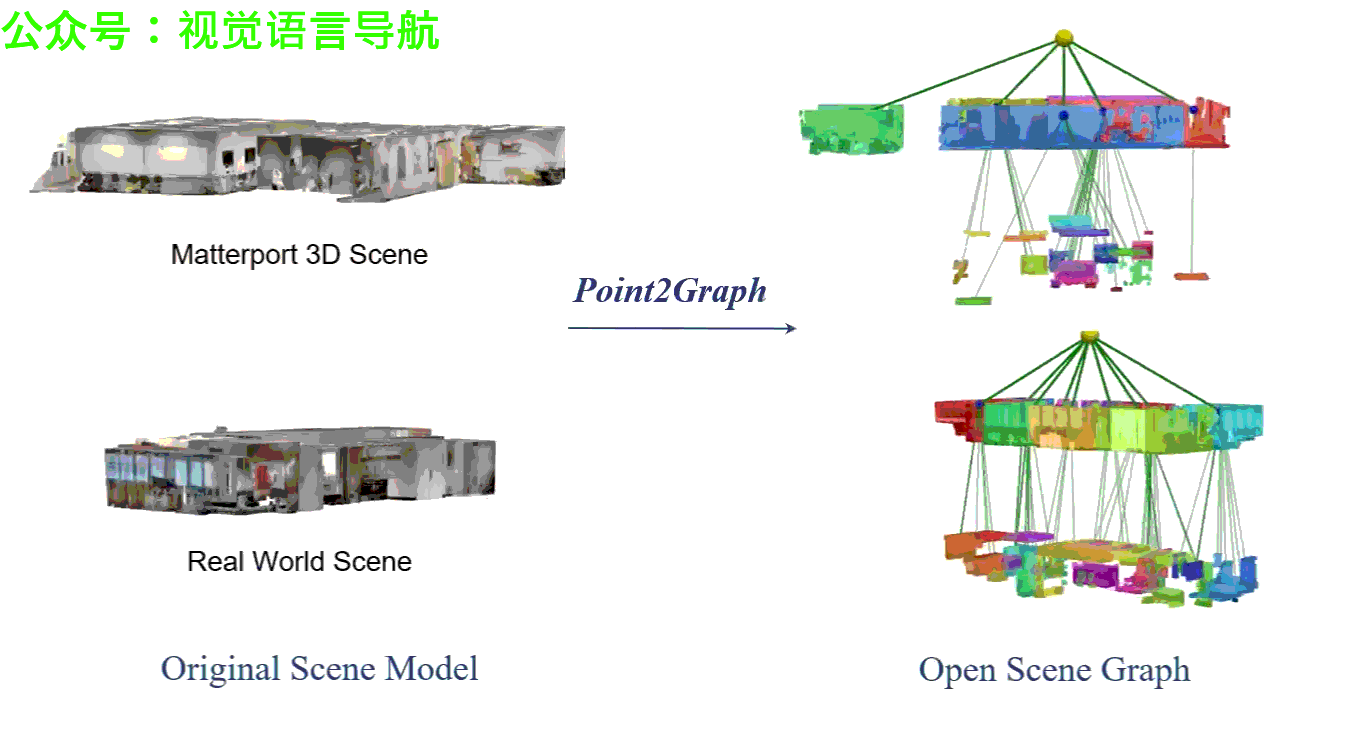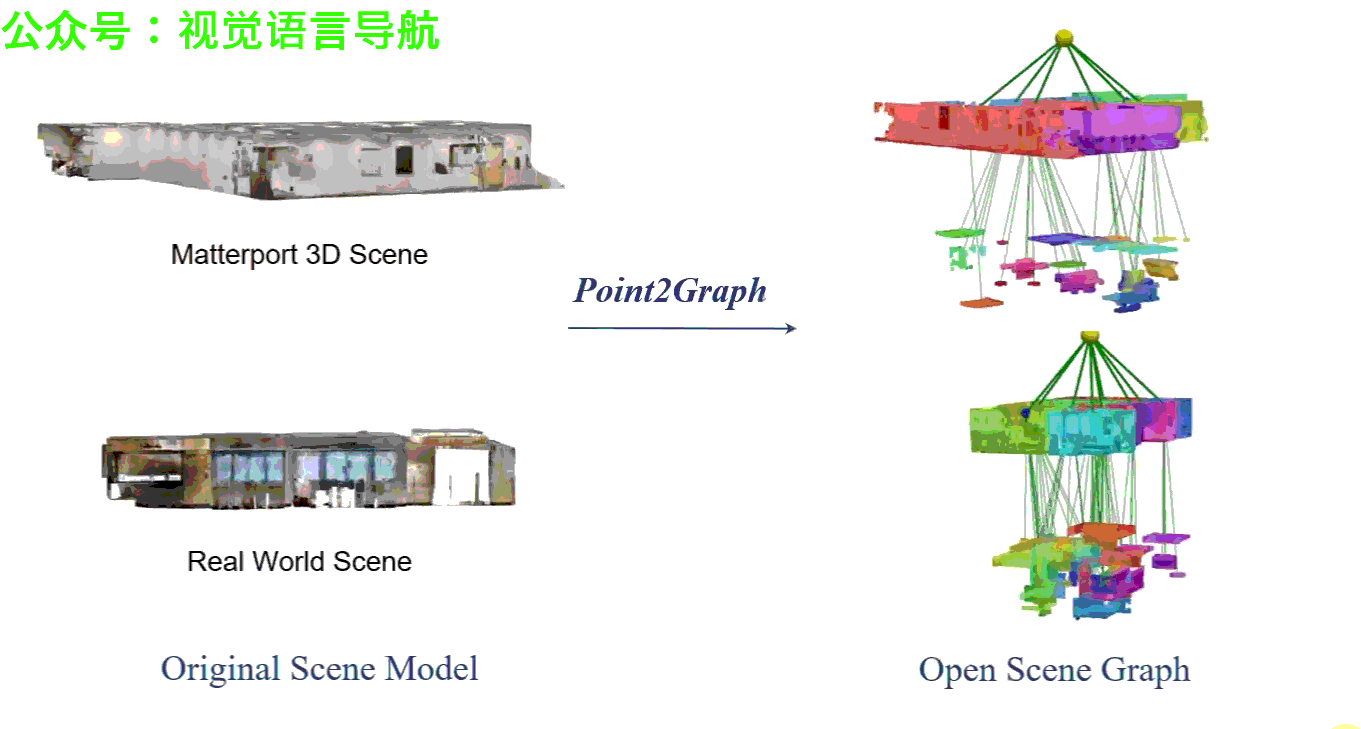
实验
房间分割与分类实验
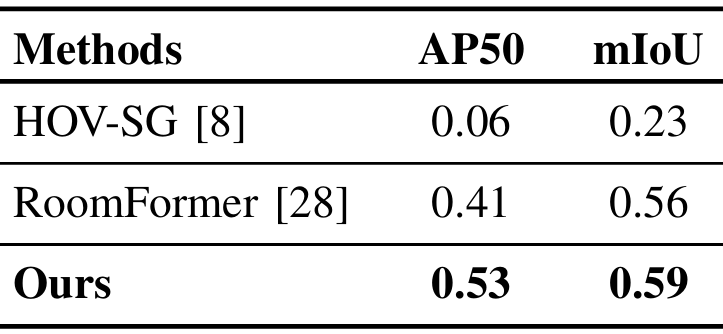
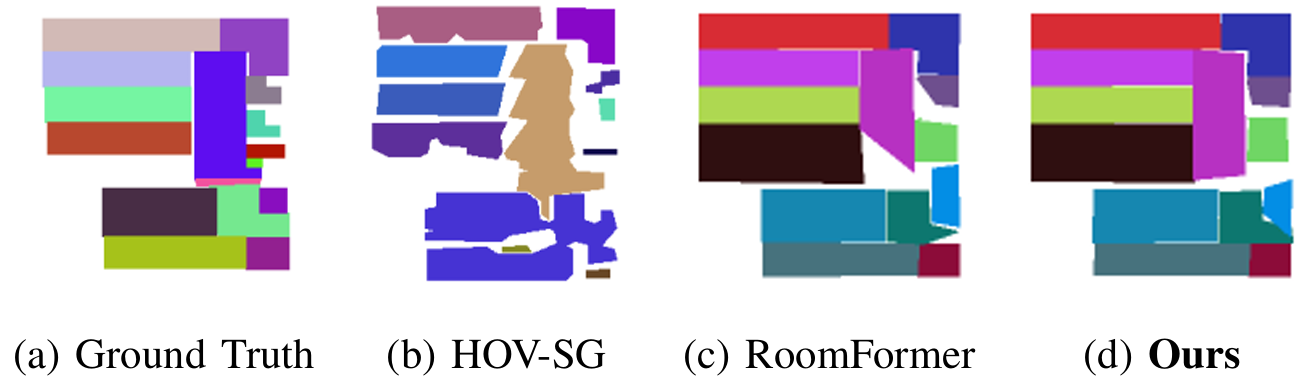
- 房间分割评估:
- 在Matterport3D数据集上进行实验,将所有多楼层场景分割成单楼层场景,共得到189个场景,选取43个场景作为房间分割的测试集。
- 与RoomFormer、HOV-SG等方法进行比较,采用平均精度(AP50)和平均交并比(mIoU)作为评估指标。
- 结果表明,通过生成边界增强密度图后输入到RoomFormer,该方法在AP50上提高了12%,在mIoU上提高了3%,证明了该方法作为房间分割预处理模块的有效性。
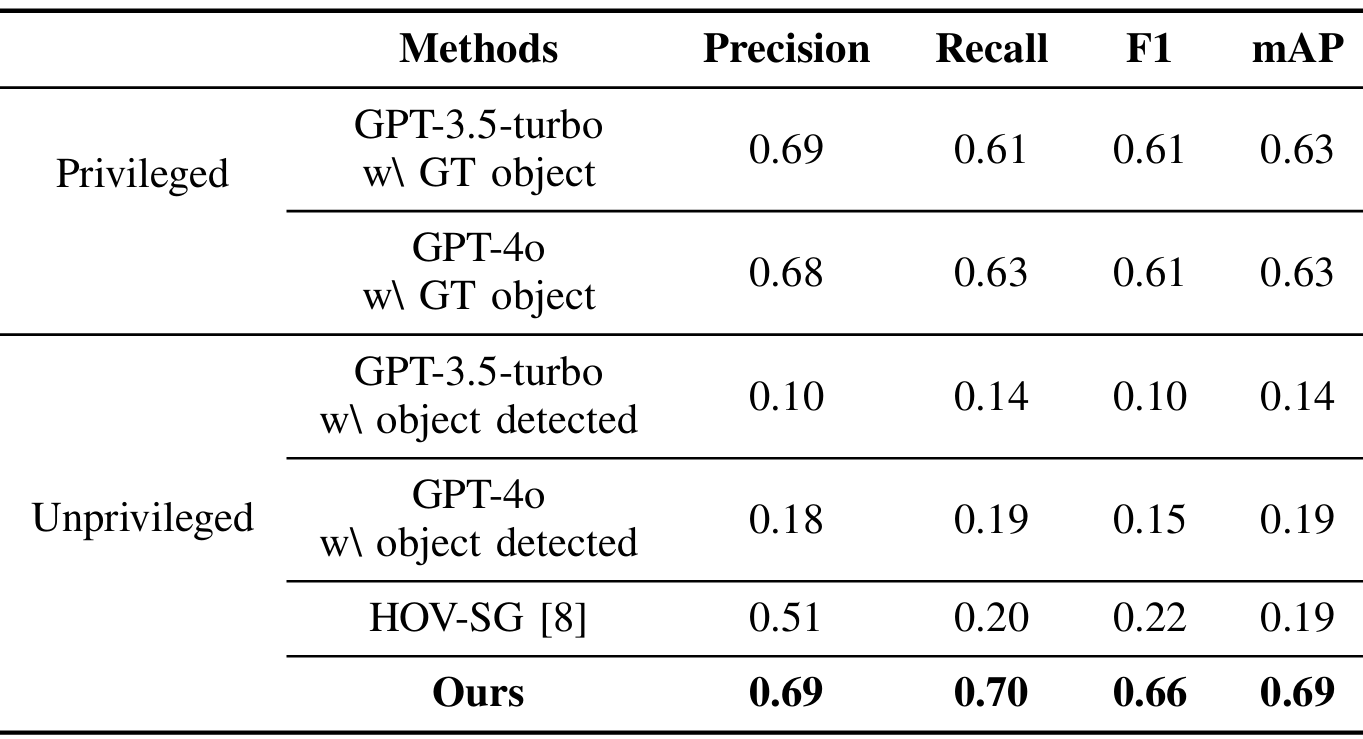
- 房间分类评估:
- 在Matterport3D数据集的100个分割后的房间场景上对“Snap-Lookup”流程进行评估,使用这些场景的全部房间类别进行分类。
- 以基于零样本LLM的房间类型推理方法和HOV-SG的房间分类方法作为基线,基线分为两类:特权类(使用真实目标类型进行LLM推理)和非特权类(依赖于通过提出的对象检测算法检测到的对象类型)。
- 使用GPT-3.5-turbo和GPT-4作为LLM基线。评估指标包括精确度、召回率、加权F1分数和平均精度均值(mAP)。
- 结果表明,“Snap-Lookup”框架能够区分包含相同对象的各种类型的房间,而仅依赖文本的推理方法如GPT-3.5-turbo和GPT-4则无法实现。
- 此外,由于“Snap”模块能够捕获整个房间的快照,因此可以获得更高质量的图像,并且不受房间自由空间内特定位置和角度的限制,如HOV-SG那样。
目标检测与分类实验

- 在广泛使用的ScanNetv2室内点云数据集上进行实验,该数据集包含312个验证场景,每个场景都标注了18个目标类别的语义和实例分割掩码。在验证集上对开放词汇实例分割进行测试,并使用PLA的类别设置,排除ScanNetv2中的“其他家具”类别。
- 与PLA及其后续工作RegionPLC、Lowis3D进行比较,并在零样本推理设置中与OpenIns3D进行比较。报告不同交并比(IoU)阈值下的平均精度(AP),具体为AP25(0.25 IoU)和AP50(0.5 IoU)。
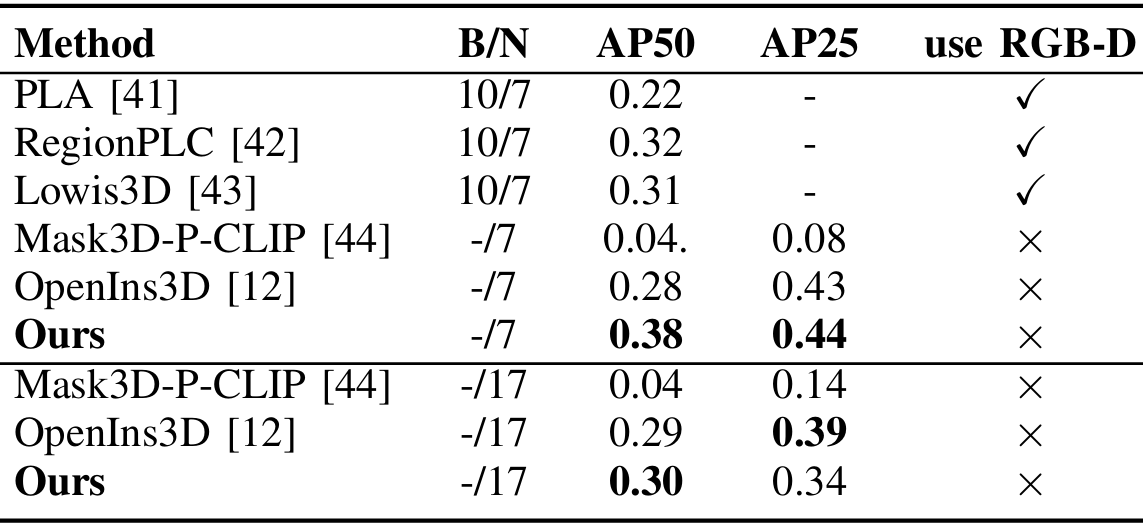
- 结果表明,该方法在七个新类别的AP50和AP25分数以及十七个新类别的最高AP50分数上均取得了最高值。该流程利用了预训练的三维目标检测模型的稳健性能以及对目标点云的精细处理。
- 通过实验观察到,目标检测模块能够准确地定位目标,而点云分类精度则通过使用DBSCAN过滤掉噪声和背景点来提高。这种集成方法能够有效地捕获全局和局部上下文,从而在各种IoU阈值下提高精度和泛化能力。
真实世界实验
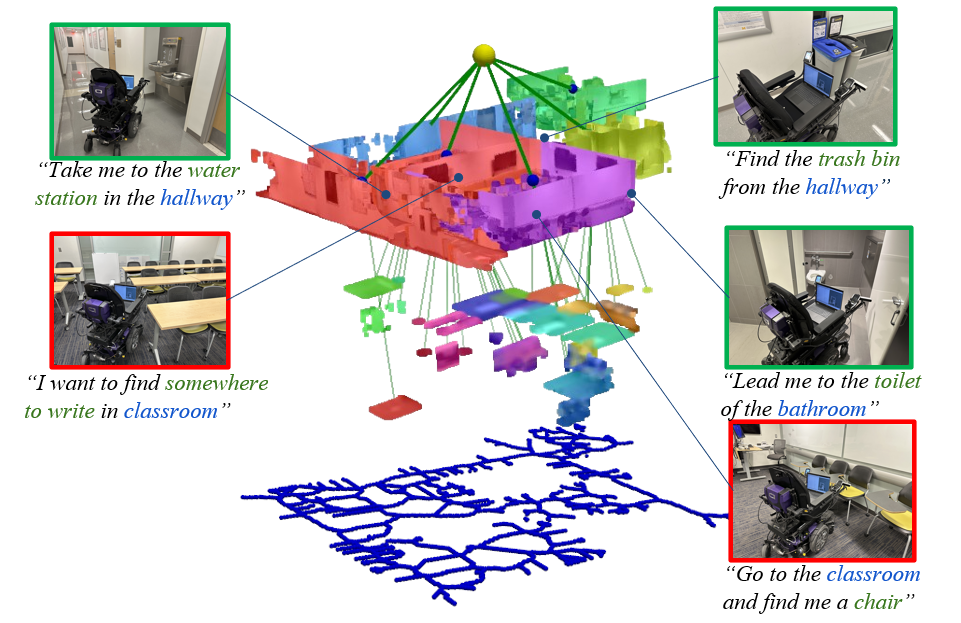
- 利用配备有校准的激光雷达和相机的智能轮椅移动平台,在GG Brown大楼的一楼进行实验。首先使用GPT-4对解释器进行提示工程,以提取房间和目标信息。
- 机器人需要解释人类的查询,并在预先构建的三维场景图中分层搜索房间和目标位置,然后导航到最相关的位置。例如,当用户输入提示“带我去大厅的饮水站”时,机器人需要在房间级别搜索大厅的位置,在目标级别搜索饮水站的位置。
- 实验进行了5个案例测试,其中3个成功,2个失败。失败的案例发生在查询教室和写字的地方时。由于环境中存在多个教室,而三维场景图没有考虑对同一类型房间的进一步识别,这会导致机器人产生混淆。
结论与未来工作
- 结论:
- Point2Graph框架通过消除对对齐的RGB-D图像的需求,解决了当前开放词汇三维场景图生成方法的局限性。
- 通过在广泛使用的场景基准数据集上的评估以及在真实世界中对辅助移动机器人的测试,证明了该框架在多样化和复杂环境中的稳健性能,为机器人在复杂室内环境中的自主导航和人机交互提供了有力支持。
- 未来工作:
- 尽管Point2Graph取得了显著的成果,但仍存在一些局限性。例如,在存在多个相同类型的房间或目标时,开放词汇查询可能会导致混淆。
- 未来的工作方向可能包括:整合深度学习算法进行房间编号检测,或者使用基于LLM的多轮共形预测来更清晰地理解人类的查询意图,从而进一步提高系统的准确性和鲁棒性。
