上篇文章分享了如何使用两种TTS(文本转语音)模型:F5-TTS和GPT-SoVITS在实际使用中的表现对比。总体来说,两者各有优劣,兄弟们可以根据实际需求选择合适的模型。今天就来讲讲怎么部署其中之一的TTS模型部署,GPT-SoVITS部署。
1 环境配置
这里就不赘述咋下载这个项目了,如果有不知道的兄弟可以看我上一篇文章:
TTS语音合成|盘点两款主流TTS模型,F5-TTS和GPT-SoVITS
我写这篇文章的时候已经出v4版本了,呢就以v4版本为例,目录结构大概是这样的:
GPT-SoVITS-v4-20250422fix
...
GPT_SoVITS/configs
...
runtime
api.py
api_V2.py
go-webui.bat
1.1 API推理配置文件
这里GPT_SoVITS/configs文件夹是部署api接口配置文件,如下图所示:
这里我们要用的是tts_infer.yaml.
配置文件如下:
custom:
bert_base_path: GPT_SoVITS/pretrained_models/chinese-roberta-wwm-ext-large
cnhuhbert_base_path: GPT_SoVITS/pretrained_models/chinese-hubert-base
device: cuda
is_half: true
t2s_weights_path: GPT_SoVITS/pretrained_models/s1v3.ckpt
version: v4
vits_weights_path: GPT_SoVITS/pretrained_models/gsv-v4-pretrained/s2Gv4.pth
v1:
bert_base_path: GPT_SoVITS/pretrained_models/chinese-roberta-wwm-ext-large
cnhuhbert_base_path: GPT_SoVITS/pretrained_models/chinese-hubert-base
device: cpu
is_half: false
t2s_weights_path: GPT_SoVITS/pretrained_models/s1bert25hz-2kh-longer-epoch=68e-step=50232.ckpt
version: v1
vits_weights_path: GPT_SoVITS/pretrained_models/s2G488k.pth
v2:
bert_base_path: GPT_SoVITS/pretrained_models/chinese-roberta-wwm-ext-large
cnhuhbert_base_path: GPT_SoVITS/pretrained_models/chinese-hubert-base
device: cpu
is_half: false
t2s_weights_path: GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s1bert25hz-5kh-longer-epoch=12-step=369668.ckpt
version: v2
vits_weights_path: GPT_SoVITS/pretrained_models/gsv-v2final-pretrained/s2G2333k.pth
v3:
bert_base_path: GPT_SoVITS/pretrained_models/chinese-roberta-wwm-ext-large
cnhuhbert_base_path: GPT_SoVITS/pretrained_models/chinese-hubert-base
device: cpu
is_half: false
t2s_weights_path: GPT_SoVITS/pretrained_models/s1v3.ckpt
version: v3
vits_weights_path: GPT_SoVITS/pretrained_models/s2Gv3.pth
v4:
bert_base_path: GPT_SoVITS/pretrained_models/chinese-roberta-wwm-ext-large
cnhuhbert_base_path: GPT_SoVITS/pretrained_models/chinese-hubert-base
device: cpu
is_half: false
t2s_weights_path: GPT_SoVITS/pretrained_models/s1v3.ckpt
version: v4
vits_weights_path: GPT_SoVITS/pretrained_models/gsv-v4-pretrained/s2Gv4.pth
custom中的version表示是你要用的版本,bert_base_path和cnhuhbert_base_path都是默认的路径不用管,如果你想要部署你训练后的模型,只需要将t2s_weights_path和vits_weights_path这两个路径改成你训练好的模路径即可。
1.2 API文件
这里有两个部署文件,一个是api.py,另一个是api_V2.py,这里我们重点介绍api_V2.py,打开文件可以看到可传参数:
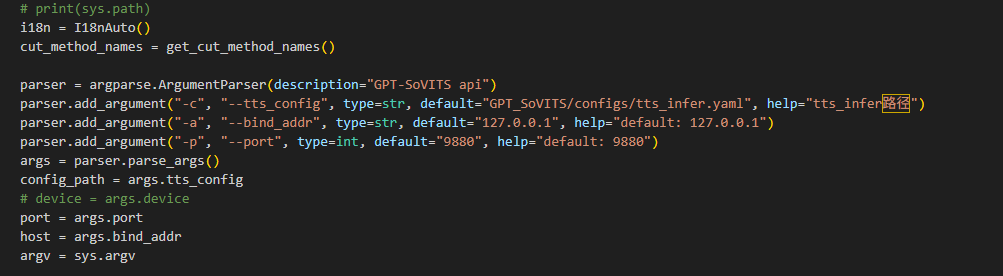
-c:参数表示你http服务器推理使用的模型位置,详情可以看tts_infer.yaml
-a:表示你的监听端口,如果你只允许本地访问,直接不用填。
如果你想局域网内可访问,或者想要映射到公网上,可以使用 -a 0.0.0.0
-p:表示你要使用的本地端口,默认9880
1.3 环境及运行命令
这里GPT-SoVITS的部署环境已经给我们配置好了,环境目录就在runtime下面,直接拿来用即可。
使用方法1.2已经给了,这里我们将目录切换到GPT-SoVITS-v4目录下使用命令启动api项目:
.\runtime\python api_v2.py -a 0.0.0.0 -p 46154 -c GPT_SoVITS/configs/tts_infer.yaml
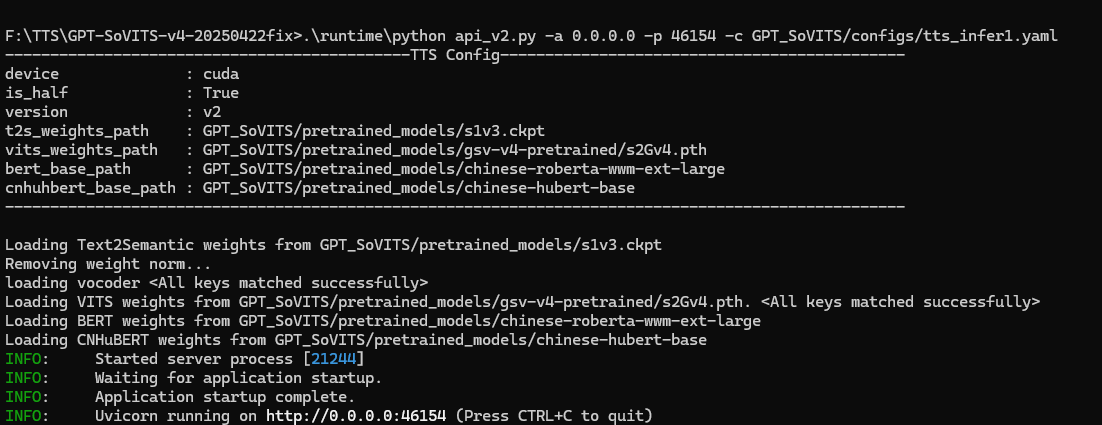
2 调用http服务,合成语音
2.1 服务端代码分析
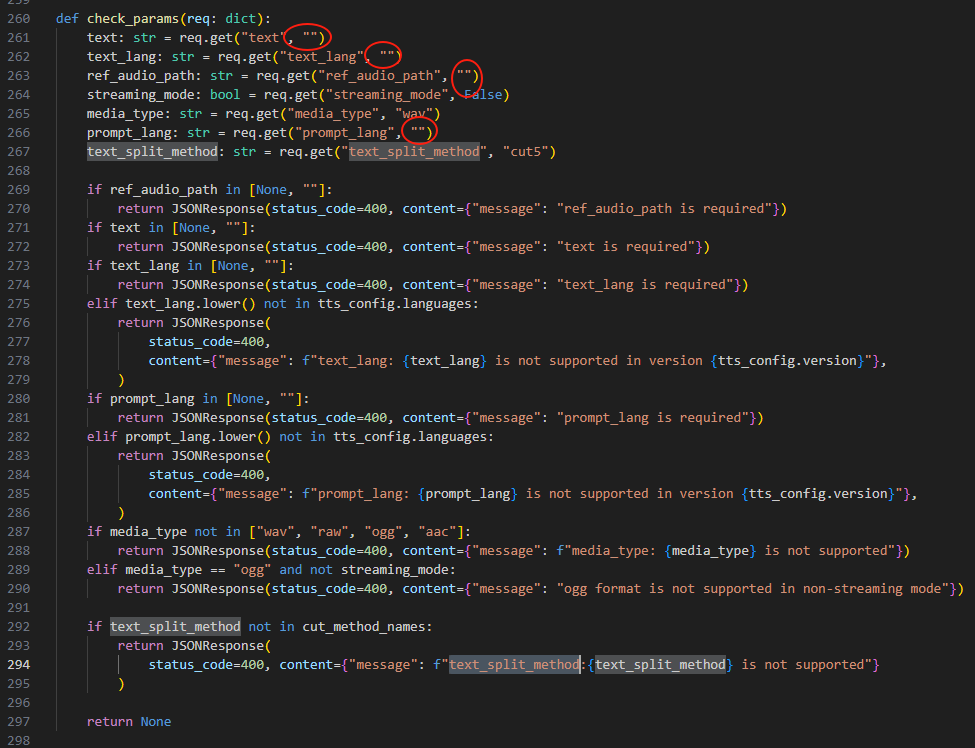
在api_v2.py可以定位到,有个check_params函数:
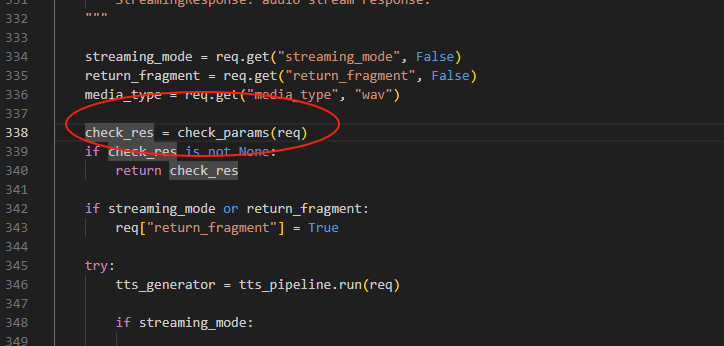
进去之后发现定义,只需要传5个参数即可调用api。
2.2 客户端代码
所以我让gpt给我写了一段调用服务器的代码:
# gpt_gen_voice.py
import requests
# TTS 服务器地址
local_url = "http://127.0.0.1:46154/tts"
data = {
"text": "先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。",
"text_lang": "zh",
"ref_audio_path": "E:/Desktop/TTS/anchor1.wav",
"prompt_text": "对不对?红彤彤的,多喜庆呀!往茶几上一摆,节日氛围满满的。吃到嘴巴里面,又是酸甜可口,酥酥脆脆的口感。",
"prompt_lang": "zh",
}
headers = {"Content-Type": "application/json"}
# 发送 POST 请求
response = requests.post(
local_url,
json=data, # 使用 `json=` 自动转换为 JSON 格式
headers=headers
)
# 检查响应
if response.status_code == 200:
# 保存 WAV 文件
with open("output.wav", "wb") as f:
f.write(response.content)
print("✅ TTS 合成成功,音频已保存为 output.wav")
else:
error_msg = response.json()
print(f"❌ TTS 合成失败: {error_msg}")
注:这里的text为你要合成语音的文字,text_lang为你你要合成语音的文字的语言,ref_audio_path为你本地的参考音频路径,prompt_text为你本地的参考音频的文字,prompt_lang为你本地的参考音频的语言。
调用之后,服务端显示:
合成完毕的音频会自动保存在你的客户端代码(gpt_gen_voice.py)同级目录下。
3 代码调整
我感觉GPT-SoVITS官网给的代码自由度很高,但效率不一定是最高的,我们可以根据自己的需求去调整代码,比如说将音色文件放在服务端,减少网络开销,默认指定参数,减少客户端传参,调整推理架构,加快推理速度,下面是我修改后的代码,仅供参考:
import os
import sys
import traceback
from typing import Generator
now_dir = os.getcwd()
sys.path.append(now_dir)
sys.path.append("%s/GPT_SoVITS" % (now_dir))
import argparse
import subprocess
import wave
import signal
import numpy as np
import soundfile as sf
import httpx
from fastapi import FastAPI, Request, HTTPException, Response
from fastapi.responses import StreamingResponse, JSONResponse
from fastapi import FastAPI, UploadFile, File
import uvicorn
from io import BytesIO
from tools.i18n.i18n import I18nAuto
from GPT_SoVITS.TTS_infer_pack.TTS import TTS, TTS_Config
from GPT_SoVITS.TTS_infer_pack.text_segmentation_method import get_method_names as get_cut_method_names
from fastapi.responses import StreamingResponse
from pydantic import BaseModel
from oss_uploader import upload_to_oss
model_dict = {
"anchor1.wav": "111",
"anchor2.wav": "222",
"anchor3.wav": "333",
}
import time
import random
def generate_unique_id():
# 获取当前时间戳(毫秒)
timestamp_ms = int(time.time() * 1000)
# 生成一个随机数
random_number = random.randint(1000, 9999) # 可以根据需求调整随机数的范围
# 返回时间戳和随机数组合的字符串,确保唯一性
unique_id = f"{timestamp_ms}{random_number}"
return unique_id
# print(sys.path)
i18n = I18nAuto()
cut_method_names = get_cut_method_names()
parser = argparse.ArgumentParser(description="GPT-SoVITS api")
parser.add_argument("-c", "--tts_config", type=str, default="GPT_SoVITS/configs/tts_infer.yaml", help="tts_infer路径")
parser.add_argument("-a", "--bind_addr", type=str, default="127.0.0.1", help="default: 127.0.0.1")
parser.add_argument("-p", "--port", type=int, default="9880", help="default: 9880")
args = parser.parse_args()
config_path = args.tts_config
# device = args.device
port = args.port
host = args.bind_addr
argv = sys.argv
if config_path in [None, ""]:
config_path = "GPT-SoVITS/configs/tts_infer.yaml"
tts_config = TTS_Config(config_path)
#print(tts_config)
tts_pipeline = TTS(tts_config)
APP = FastAPI()
class TTS_Request(BaseModel):
text: str = None
voice_type:int = 0
anchor_id:int = None
#text_lang: str = None
text_lang: str = "zh"
ref_audio_path: str = None
aux_ref_audio_paths: list = None
#prompt_lang: str = None
prompt_lang: str = "zh"
prompt_text: str = ""
top_k:int = 5
top_p:float = 1
temperature:float = 1
#text_split_method:str = "cut5"
text_split_method:str = "cut2"
batch_size:int = 1
batch_threshold:float = 0.75
split_bucket:bool = True
speed_factor:float = 1.0
fragment_interval:float = 0.3
seed:int = -1
media_type:str = "wav"
streaming_mode:bool = False
parallel_infer:bool = True
repetition_penalty:float = 1.35
### modify from https://github.com/RVC-Boss/GPT-SoVITS/pull/894/files
def pack_ogg(io_buffer:BytesIO, data:np.ndarray, rate:int):
with sf.SoundFile(io_buffer, mode='w', samplerate=rate, channels=1, format='ogg') as audio_file:
audio_file.write(data)
return io_buffer
def pack_raw(io_buffer:BytesIO, data:np.ndarray, rate:int):
io_buffer.write(data.tobytes())
return io_buffer
def pack_wav(io_buffer:BytesIO, data:np.ndarray, rate:int):
io_buffer = BytesIO()
sf.write(io_buffer, data, rate, format='wav')
return io_buffer
def pack_aac(io_buffer:BytesIO, data:np.ndarray, rate:int):
process = subprocess.Popen([
'ffmpeg',
'-f', 's16le', # 输入16位有符号小端整数PCM
'-ar', str(rate), # 设置采样率
'-ac', '1', # 单声道
'-i', 'pipe:0', # 从管道读取输入
'-c:a', 'aac', # 音频编码器为AAC
'-b:a', '192k', # 比特率
'-vn', # 不包含视频
'-f', 'adts', # 输出AAC数据流格式
'pipe:1' # 将输出写入管道
], stdin=subprocess.PIPE, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
out, _ = process.communicate(input=data.tobytes())
io_buffer.write(out)
return io_buffer
def pack_audio(io_buffer:BytesIO, data:np.ndarray, rate:int, media_type:str):
if media_type == "ogg":
io_buffer = pack_ogg(io_buffer, data, rate)
elif media_type == "aac":
io_buffer = pack_aac(io_buffer, data, rate)
elif media_type == "wav":
io_buffer = pack_wav(io_buffer, data, rate)
else:
io_buffer = pack_raw(io_buffer, data, rate)
io_buffer.seek(0)
return io_buffer
# from https://huggingface.co/spaces/coqui/voice-chat-with-mistral/blob/main/app.py
def wave_header_chunk(frame_input=b"", channels=1, sample_width=2, sample_rate=32000):
# This will create a wave header then append the frame input
# It should be first on a streaming wav file
# Other frames better should not have it (else you will hear some artifacts each chunk start)
wav_buf = BytesIO()
with wave.open(wav_buf, "wb") as vfout:
vfout.setnchannels(channels)
vfout.setsampwidth(sample_width)
vfout.setframerate(sample_rate)
vfout.writeframes(frame_input)
wav_buf.seek(0)
return wav_buf.read()
def handle_control(command:str):
if command == "restart":
os.execl(sys.executable, sys.executable, *argv)
elif command == "exit":
os.kill(os.getpid(), signal.SIGTERM)
exit(0)
def check_params(req:dict):
text:str = req.get("text", "")
text_lang:str = req.get("text_lang", "")
ref_audio_path:str = req.get("ref_audio_path", "")
streaming_mode:bool = req.get("streaming_mode", False)
media_type:str = req.get("media_type", "wav")
prompt_lang:str = req.get("prompt_lang", "")
text_split_method:str = req.get("text_split_method", "cut5")
if ref_audio_path in [None, ""]:
return JSONResponse(status_code=400, content={"message": "ref_audio_path is required"})
if text in [None, ""]:
return JSONResponse(status_code=400, content={"message": "text is required"})
if (text_lang in [None, ""]) :
return JSONResponse(status_code=400, content={"message": "text_lang is required"})
elif text_lang.lower() not in tts_config.languages:
return JSONResponse(status_code=400, content={"message": "text_lang is not supported"})
if (prompt_lang in [None, ""]) :
return JSONResponse(status_code=400, content={"message": "prompt_lang is required"})
elif prompt_lang.lower() not in tts_config.languages:
return JSONResponse(status_code=400, content={"message": "prompt_lang is not supported"})
if media_type not in ["wav", "raw", "ogg", "aac"]:
return JSONResponse(status_code=400, content={"message": "media_type is not supported"})
elif media_type == "ogg" and not streaming_mode:
return JSONResponse(status_code=400, content={"message": "ogg format is not supported in non-streaming mode"})
if text_split_method not in cut_method_names:
return JSONResponse(status_code=400, content={"message": f"text_split_method:{text_split_method} is not supported"})
return None
async def tts_handle(req:dict):
streaming_mode = req.get("streaming_mode", False)
media_type = req.get("media_type", "wav")
check_res = check_params(req)
if check_res is not None:
return check_res
if streaming_mode:
req["return_fragment"] = True
try:
tts_generator=tts_pipeline.run(req)
if streaming_mode:
def streaming_generator_with_oss(tts_generator: Generator, media_type: str):
if media_type == "wav":
yield wave_header_chunk()
media_type = "raw"
oss_urls = [] # 用于存储每个片段的 OSS 地址
for sr, chunk in tts_generator:
# 将片段上传到 OSS
audio_data = pack_audio(BytesIO(), chunk, sr, media_type).getvalue()
oss_url = upload_to_oss(audio_data, media_type) # 调用上传函数
oss_urls.append(oss_url)
yield audio_data
print("Uploaded OSS URLs:", oss_urls)
return StreamingResponse(
streaming_generator_with_oss(tts_generator, media_type),
media_type=f"audio/{media_type}"
)
else:
sr, audio_data = next(tts_generator)
audio_data = pack_audio(BytesIO(), audio_data, sr, media_type).getvalue()
# 上传完整音频到 OSS
oss_url = upload_to_oss(audio_data, media_type) # 调用上传函数
return {"code": 200, "oss_url": oss_url}
except Exception as e:
#return JSONResponse(status_code=400, content={"message": f"tts failed", "Exception": str(e)})
return {"code": 400, "message": f"tts failed"}
@APP.get("/tts")
async def tts_get_endpoint(
text: str = None,
text_lang: str = None,
ref_audio_path: str = None,
aux_ref_audio_paths:list = None,
prompt_lang: str = None,
prompt_text: str = "",
top_k:int = 5,
top_p:float = 1,
temperature:float = 1,
text_split_method:str = "cut0",
batch_size:int = 1,
batch_threshold:float = 0.75,
split_bucket:bool = True,
speed_factor:float = 1.0,
fragment_interval:float = 0.3,
seed:int = -1,
media_type:str = "wav",
streaming_mode:bool = False,
parallel_infer:bool = True,
repetition_penalty:float = 1.35
):
req = {
"text": text,
"text_lang": text_lang.lower(),
"ref_audio_path": ref_audio_path,
"aux_ref_audio_paths": aux_ref_audio_paths,
"prompt_text": prompt_text,
"prompt_lang": prompt_lang.lower(),
"top_k": top_k,
"top_p": top_p,
"temperature": temperature,
"text_split_method": text_split_method,
"batch_size":int(batch_size),
"batch_threshold":float(batch_threshold),
"speed_factor":float(speed_factor),
"split_bucket":split_bucket,
"fragment_interval":fragment_interval,
"seed":seed,
"media_type":media_type,
"streaming_mode":streaming_mode,
"parallel_infer":parallel_infer,
"repetition_penalty":float(repetition_penalty)
}
return await tts_handle(req)
@APP.post("/tts")
async def tts_post_endpoint(request: TTS_Request):
req = request.dict()
# lmz add start
got_str = model_dict.get(req.get("ref_audio_path", ""),"")
print("===============get ref text: ", got_str)
if got_str != "":
req.update({
"prompt_text": got_str, # 固定值
})
# lmz add end
text = req.get("text", '')
voice_type = req.get("voice_type", '')
anchor_id = req.get("anchor_id", '')
# 调用接口查询是否存在记录
check_url = "xxxcheck"
async with httpx.AsyncClient() as client:
try:
response = await client.post(check_url, data={"voice_text": text, 'voice_type': generate_unique_id()})
if response.status_code == 200:
result = response.json()
if result.get("code") == 200 and result.get("data"):
# 如果接口返回 code 为 200 且 data 有值,表示有记录
return JSONResponse(status_code=200, content={"code": 200, "oss_url": result.get("data")})
except httpx.RequestError as e:
return JSONResponse(status_code=400, content={"code": 400, "message": "Request error", "Exception": str(e)})
# 如果接口没有记录,则调用 TTS 处理逻辑
try:
response = await tts_handle(req)
# 假设调用成功后返回的结果包含 oss_url
oss_url = response.get("oss_url")
# 将返回的 oss_url 插入数据库
insert_url = "xxxinsertVoice"
async with httpx.AsyncClient() as client:
insert_response = await client.post(insert_url, data={
"voice_text": text,
"voice_type": voice_type,
"oss_url": oss_url,
"anchor_id": anchor_id,
"type": 2
})
if insert_response.status_code == 200:
# 插入成功,返回生成的 oss_url
return JSONResponse(status_code=200, content={"code": 200, "oss_url": oss_url})
else:
# 如果插入失败,返回错误信息
return JSONResponse(status_code=400, content={"code": 400, "message": "Failed to insert oss_url into database"})
except Exception as e:
return JSONResponse(status_code=500, content={"code": 500, "message": "Error during TTS processing", "Exception": str(e)})
if __name__ == "__main__":
try:
uvicorn.run(app=APP, host=host, port=port, workers=1)
except Exception as e:
traceback.print_exc()
os.kill(os.getpid(), signal.SIGTERM)
exit(0)
这段代码实现了,服务端保存推理音色和参考音频,然后将音频上传到oss服务器上,做成网络音频数据,直接使用。
想要提高推理速度的可以参考项目:gpt_sovits_cpp

这个项目是使用libtorch C++推理框架实现的,推理速度加快了一点,个人感觉如果用TensorRT或者ONNXRuntime去做,效果应该会更好。
总结
这篇文章主要分享了GPT-SoVITS如何实现一个HTTP服务器,并通过该服务器提供文本到语音(TTS)的服务。通过搭建这个服务器,用户可以方便地通过API接口请求文本转语音功能,支持多种配置选项,如不同的音频格式、语言设置以及参考音频路径。该服务器不仅支持常规的语音合成任务,还能够进行模型切换、命令控制等操作,极大地提升了系统的灵活性和可扩展性。通过这种方式,GPT-SoVITS将强大的语音合成能力与现代Web应用相结合,为开发者提供了一个易于集成和使用的解决方案。