【2025版】9、第三节 卷积神经网络CNN_哔哩哔哩_bilibili
李宏毅机器学习-RNN网络(中英文)_哔哩哔哩_bilibili
目录
2. 池化pooling 步幅stride 填充padding
分类问题:将分类结果表示为独热向量y 向量长度即识别物体种类数 用softmax 交叉熵描述损失
图像可描述为三维的像素张量 宽 高 通道
通道指同一样东西同一个/位置的多个维度/模式 如色彩RGB 三个颜色通道
卷积神经网络(Convolutional Neural Network, CNN)是一种专门用于处理网格结构数据(如图像、视频、语音)的深度学习模型,其核心是通过卷积层(Convolution Layer)和池化层(Pooling Layer)的堆叠来自动提取多层次特征。
1. 卷积
观察1. 我们要识别一个图片是否为小鸟 可以不一定需要看他的整个图像
可以分别观察每个小块 有没有鸟嘴 翅膀
观察2.翅膀可以出现在整张图的各个部分 所以对图像的不同位置可以共享参数 用同样的识别模型
所以我们可以运用 h*k的卷积核 把整个矩阵对应位置元素相乘再相加
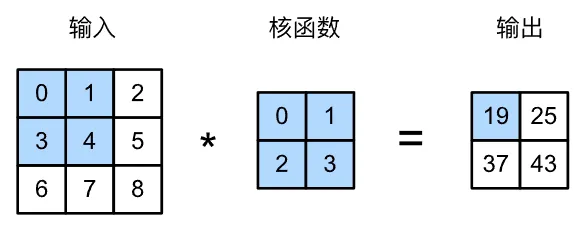
根据这个原理 可以手写一个corr2d的卷积函数。每个位置的Y 由h*w的X中的小矩阵 乘以核k得到
import torch
from torch import nn
def corr2d(X, K):
h, w = K.shape
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1)) #输出的长宽
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
X = torch.ones((6, 8))
X[:, 2:6] = 0
K = torch.tensor([[1.0, -1.0]]) # 初始卷积核
Y = corr2d(X, K)# 二维卷积层使用四维输入和输出格式(批量大小、通道、高度、宽度),
# 我们这个例子中批量大小和通道数都为1
如果用 nn.conv2d 可以一行把卷积写成
Y = nn.functional.conv2d(X, K.reshape((1, 1, 1, 2)), padding=0)多输入输出通道 不同模式下,矩阵变量的维度分别是这样的
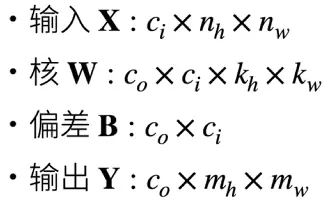
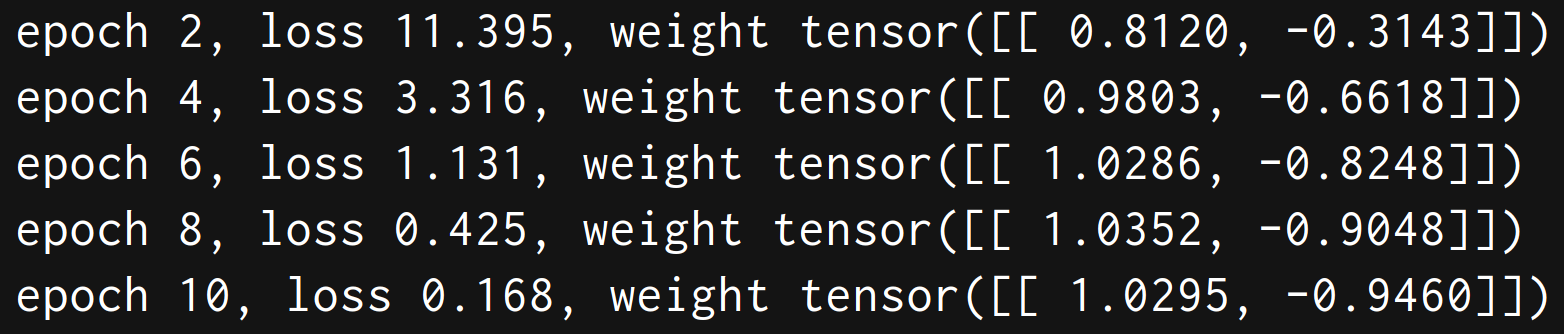
然后我们试一下训练求卷积核K:之前是由X和K得到Y K设置为(1,-1); 现在我们用X和Y 推K
X = X.reshape((1, 1, 6, 8))
Y = Y.reshape((1, 1, 6, 7))
conv2d = nn.Conv2d(1,1, kernel_size=(1, 2), bias=False)
lr = 3e-2 # 学习率
for i in range(10):
Y_hat = conv2d(X)
l = (Y_hat - Y) ** 2
conv2d.zero_grad()
l.sum().backward()
# 迭代卷积核
conv2d.weight.data[:] -= lr * conv2d.weight.grad
if (i + 1) % 2 == 0:
print(f'epoch {i+1}, loss {l.sum():.3f}, weight {conv2d.weight.data.reshape((1, 2))}')训练结果可以看出 随着loss下降 w越来越接近(1,-1)
2. 池化pooling 步幅stride 填充padding
做下采样(downsampling)把图像偶数列、奇数行都拿掉
虽然图像变为原来的 1/4 信息变少了 但仍然能看出来图片是什么

所以我们在处理大量的数据时 可以进行池化(pooling)的操作 保持特征减少数据量
池化层 可以用最大元素/平均值 分别为下面的两种
pool2d = nn.MaxPool2d(3, padding=1, stride=2) #最大 周围一圈补0
avgpool = nn.AvgPool2d(kernel_size=3, padding=1, stride=2, count_include_pad=False)# 平均 最后一个参数 补的0是否参与计算stride步幅 核矩阵一个一个移动 子矩阵还是太大 可以通过扩大步幅移动比较多
padding填充 每次移动stride 结果行列数不能整除,就在原始矩阵最外面加上几层不影响结果的值
输入行数与输出行数有这样的数值关系,两边各填充P个后,移动S次长度为K的核
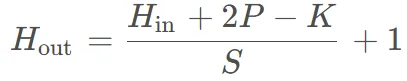
3. CNN其他应用
语音识别 文字处理等 但要根据问题本身的情境和建模原理 选择如何搭建全连接层
下围棋应用:19*19的矩阵每个元素 黑棋、白棋、没下 三种状态值
通道:专家挑选出48个重要状态(比如吃子 旁边不同颜色的棋子数之类 从不同角度描述这个位置的状态)
为什么围棋适用CNN:1.也是网格式的
2.也可以关注小局部(比如这一块黑白的死活只用看一个局部)
3.但是池化缩小尺度 就对围棋没帮助 所以CNN用什么层 需要具体问题具体分析
4. RNN 循环神经网络
4.1 任务引入-需要“记忆”的任务
一句话中每个词属于哪个槽slot
比如说 我从南京出发 我从南京离开 这两句话的南京 是目的地还是出发地?
光看“南京”这个词无法完全判断 需要由上下文推导
4.2 两种编码方式
独热编码:n维向量 对应n个种类 每个种类只有对应的一个位置为1 其余位置为0
如果出现单词表里没有的 放在Other里
还可以用 词哈希来表示单词 连续三个字母 26*26*26种
比如apple就是 app ppl ple这三个位置为1 其余位置为0
4.3 隐状态
每一次隐藏层神经元产生输出后会被存到记忆元 记忆元的值叫隐状态
循环计算隐状态的神经网络被称为循环神经网络(同一个网络在不同时间点多次调用)
像“南京”会因为上一个隐状态不同 导致输出不同
之前神经网络:仅凭南京这一个词进行输出 用x算出中间层w w再往后算出y
但Elman网络 通过x计算w 然后结合前一个w 来算y 就用了之前的记忆(计算w受上一个w的影响)
Jordan网络 将上一个输出y' 作为隐状态
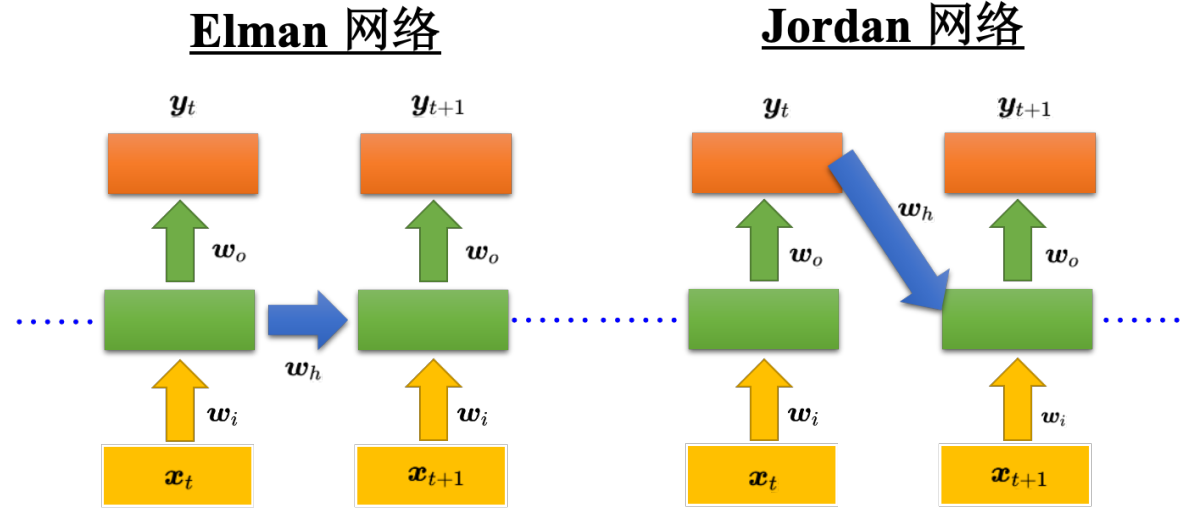
这种递推相当于 我现在的w受到之前所有w的影响; 但还可以优化成 双向的
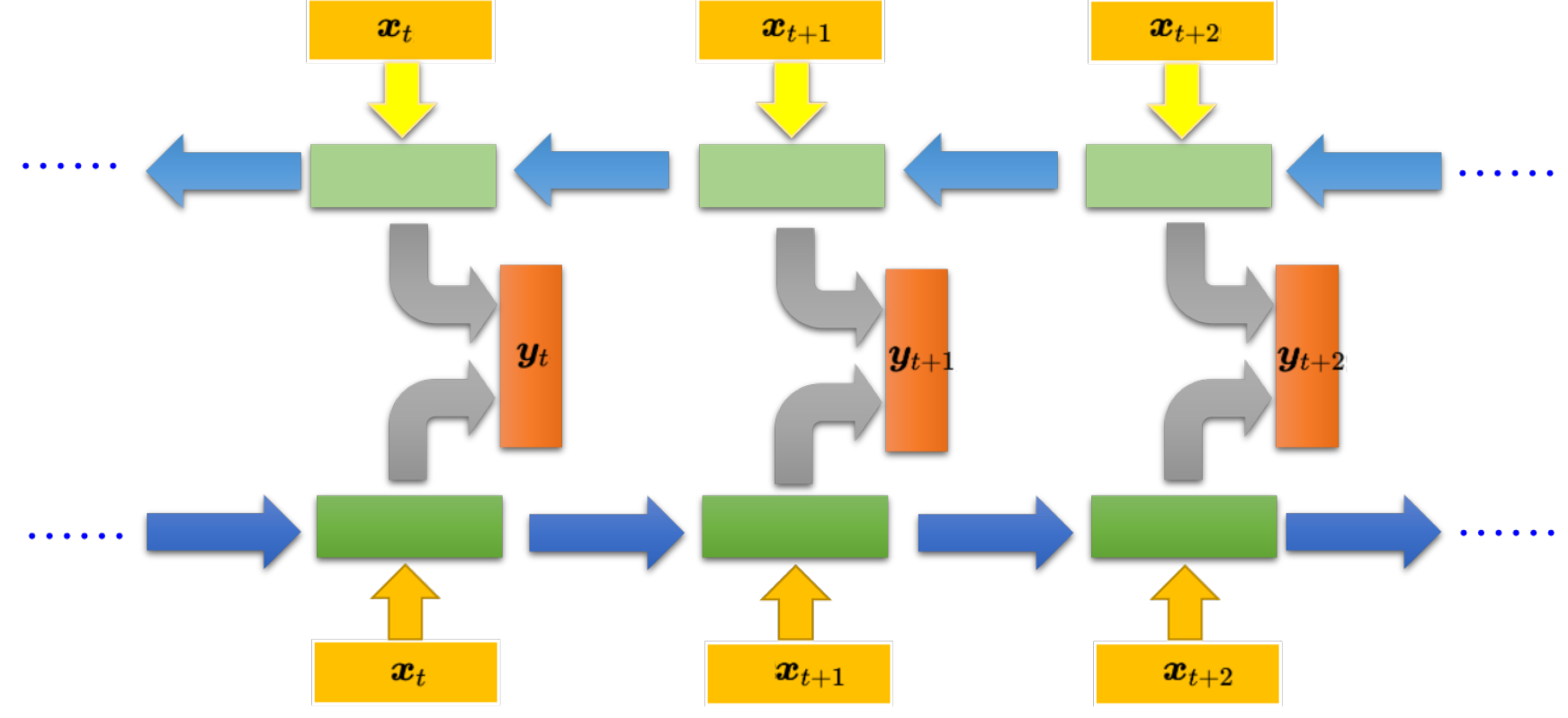
双向循环Bi-RNN 可以不止看到之前的 还可以看到后面的 相当于看了一个完整的句子效果更好
5. LSTM 长短期记忆网络
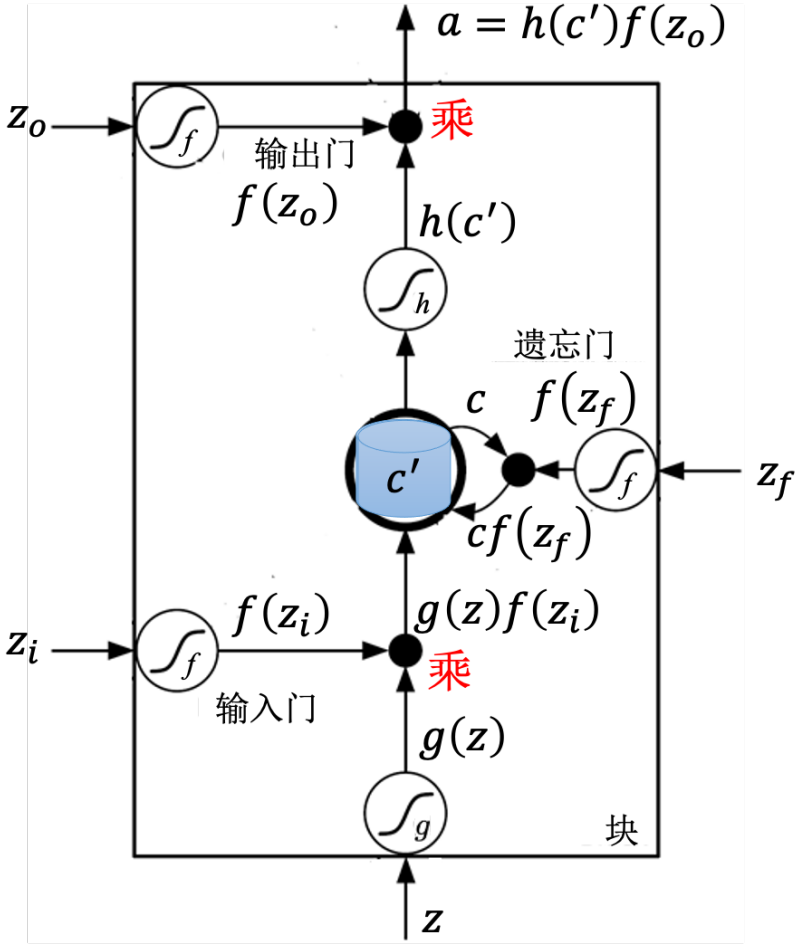
X输入 H隐状态 C细胞状态
三大门:输入门I 遗忘门F 输出门O
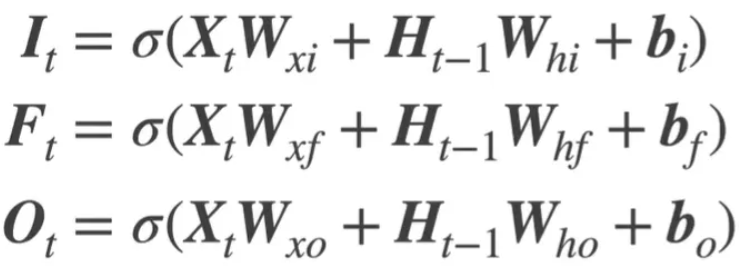
C更新 = 前一个*遗忘门 + 候选状态*输入门 H更新 = C*输出门
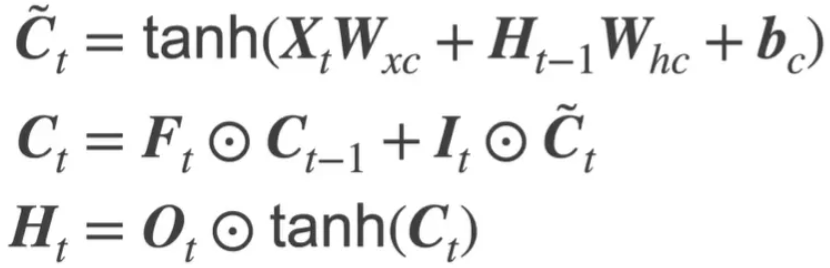
6. RNN的训练问题
训练时损失函数 输出与参考向量的交叉熵
由反向传播BP -> 时间序列的随时间反向传播BPTT(按照时间从后往前计算梯度)
梯度消失问题:梯度BPTT时指数级衰减,导致早期时间步的参数几乎无法更新
1)梯度需通过时间步连乘; 2)激活函数(如tanh/sigmoid)的导数在大部分区间远小于1
比如w的1000次方 在w=0 0.99 1 1.01 分别取值为0 0 1 20000
所以在(0,1) 梯度很小 在1附近梯度又很大; RNN就会在一些位置梯度消失 一些位置梯度爆炸
LSTM 通过门控单元激活函数调节 避免连乘 + 流量控制
GRU 旧的不去 新的不来;合并输入门和遗忘门为更新门 遗忘门打开才会打开输入门
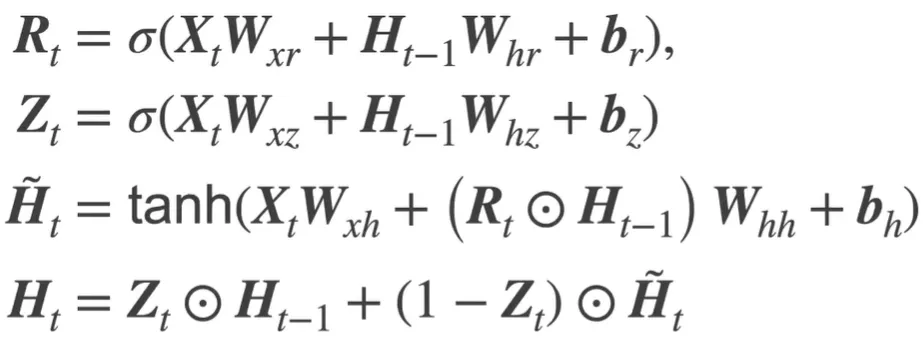
相比LSTM 参数更少,计算效率更高,缓解过拟合
7. RNN应用
1)多对一:一段文字情感分类正负、一篇文章关键词抽取。 看最后一个时间点的输出
2)多对多:如语音识别 输出长度会比输入短
如果以很短的间隔分割 会出现多个声音序列对应一个字 如“好好好棒棒棒棒棒棒”的情况
然后再把重复的字去掉 但这样无法区分输出 “好棒”和 叠词“好棒棒”
CTC训练 输出字符时可以输出null 比如输出 “好 null null 棒 null null” 再把null都去掉
3)序列到序列Seq2Seq:
如语言翻译 应该输出多少个字符事先是不知道的 也不知道输入长度与输出长度的大小关系。
进行 “理解一段序列,生成另一段任意长度的序列” 的过程。
RNN对给定序列 依次读入 进行编码和记忆,然后进行解码 输出下一个字/终止符。