背景
大语言模型(LLMs)的迅速发展,让很多复杂的编程任务都可以通过自然语言实现,其编程能力对于制作大部分的心理学范式是绰绰有余的。但是目前LLMs在心理学范式生成方面的应用还有局限;比如你和LLMs说帮我使用PsychoPy写一个GO/No-GO范式,大概率会得到一堆无法运行的代码,甚至参杂着pygame的机制。任务范式的组织方式缺少统一的规则是主要的原因之一。此外,对于使用网络资源训练的LLMs来说,网上开源的心理学范式来源于不同的实验室,同样缺少统一的规范和标准。另一方面,心理学任务的标准和规范,对于任务范式的分享、重复使用、甚至心理学、认知心理学研究的可重复性也至关重要。
TAPS

因此,我提出了TAPS的任务结构,可以把它理解为是TASK-BIDS结构。但是考虑到BIDS实际上大脑成像数据结构,除了磁共振数据还拓展到了EEG-BIDS,fNRI-BIDS,iEEG-BIDS等方面,而这里重点是任务范式的结构,不一定涉及影像数据,因此单独命名。
TAPS 的设计充分考虑了心理学任务的核心要素,包括:实验逻辑、刺激材料、配置文件、文档说明以及输出数据。
实验逻辑由三个核心 Python 脚本构成:
main.py控制整体任务结构与流程;run_trial.py定义试次级别的逻辑,如刺激呈现和反应采集;utils.py提供复杂任务中所需的辅助函数。
刺激材料(如图片、音频、视频)被单独存放在 assets/ 文件夹中。实验参数(如条件设置、试次数量、时序参数、显示属性、刺激特征、按键响应规则、被试信息等)由 YAML 格式的配置文件统一定义。文档说明保存在结构化的 README.md 文件中,内容包括任务名称、版本、链接、开发者等元数据,任务概述、区块与试次逻辑、配置细节、示例说明以及参考文献。
被试完成任务后的输出数据存储在 data/ 文件夹中,包括:
自定义的试次级行为数据(CSV 文件),
自动生成的运行日志(log 文件),
记录实验配置与被试信息的元数据(JSON 文件)。
src和assets设置是在学习Unity时受到的启发,刚开始的版本还有一个meta.json文件受到BIDS的启发但是后续这一部分信息调整到了REAME.md中。
psyflow

TAPS任务结构的核心是任务参数和任务逻辑的分离,相比于把任务参数硬编码到任务逻辑中的方式,使用单独的yaml文件储存任务参数,可以提高任务修改的灵活性,更重要的是为任务的本土化(localization)提供便利。为了支持TAPS这一核心设置,我进一步开发了psyflow工具包,该包是对psychopy已有工具的整合与二次开发,方便用户更快地建立任务范式。
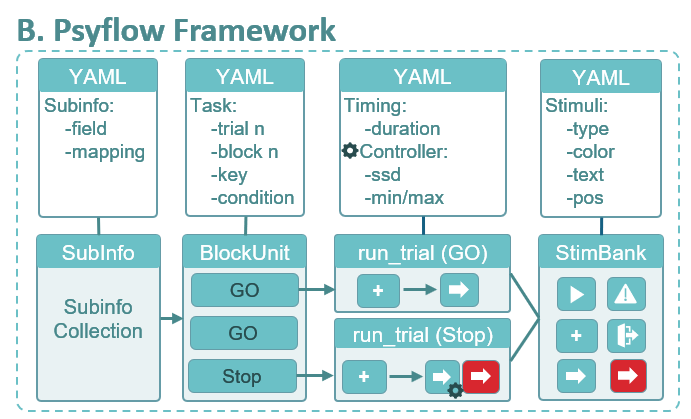
Psyflow创建的心理学范式,使用 YAML 文件定义被试信息、任务结构、时序参数和刺激属性。配置文件由 psyflow 中相应的类加载:SubInfo 负责收集被试元数据,BlockUnit 管理区块级的任务逻辑,StimBank 注册并管理所有刺激材料。试次级的逻辑在 run_trial.py 中定义,可根据条件(例如 Go vs. Stop)进行变化。每个试次通常由多个 StimUnit 组成,例如注视点、Go 刺激、Stop 刺激等,每个 StimUnit 控制试次中某一阶段的刺激呈现、反应采集和数据记录。
TaskBeacon

TaskBeacon 是一个基于 GitHub 的社区协作平台,专为管理符合 TAPS 和 psyflow 标准的心理学任务而设计。平台支持三类任务的贡献:标准任务、任务变体和新任务提案。用户可通过 GitHub 的常规流程(fork、修改、提交 PR)参与标准任务的改进,管理员审核通过后合并至主分支。任务变体统一管理在 variant/* 分支,支持在原有任务基础上提出改进或创建新版本。对于全新的任务,用户需基于 TAPS 和 psyflow 开发原型,并在 taskbeacon/task-registry 提交包含任务描述和元数据的 issue 进行注册,由管理员审核决定是否纳入平台管理。
目前TaskBeacon上面共享了一些简单的任务

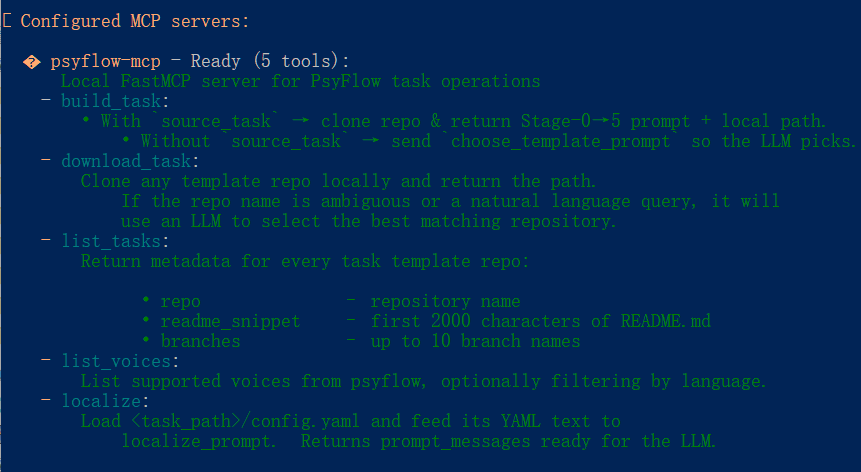
taskbeacon-mcp

在完成以上工作后,回到最有意思的问题,如何使用大语言模型创建心理学范式?
实际上在开发psyflow就已经实现了调用LLMs接口实现任务到文档的转化和任务配置文件的翻译,调用LLMs涉及格式的问题,不同模型的SDK不同等问题,而且文档到任务生成效果不佳,最后发现MCP才是答案。
对于心理学范式这样的编程任务,可能不需要做fine-tuning,做一些few-shot learning,或者提供psyflow文档应该够用,事实上我发现这样的效果很差。目前找到比较好的方式是可以让LLMs从已有的范式中选择一个和目标范式最相近的作为模板,然后根据目标任务的具体要求进行修改和更新。这里具体的任务受到task-master项目的启发,做了任务细分。
目前已经将这个工具整理为taskbeacon-mcp并发布。使用该mcp工具已经快速创建了诸如ANT,Simon, Flanker,GO/No-GO等简单的任务范式,大部分任务都或多或少存在一些小bug,需要人工调试,有的时候不需要人工调整能够一次点亮。开发主要是通过gemini-cli调用gemini-2.5-pro完成,期间由于达到限额,转到gemini-2.5-flash发现效果也还不错。其他工具比如cursor、trae(主要基于Claude模型)以及qwen-code,claude-code的表现和费用未知。受到task-master项目启发,如果可以在planning阶段调用低级的模型比如2.5-flash,在coding部分调用高级模型比如2.5-pro应该会达到比较好的降本增效目标。
目前该MCP提供的工具主要是下载、创建任务和本土化。对于其他类型或者复杂的任务范式,其有效性还有待验证,但我相信随着taskbeacon中的任务越来越多,可用的模板也会随之丰富,能覆盖的新范式范围能随之增加。实际上,在制作过程中,我发现很多时候刺激的呈现(编程部分)并不是我们需要投入更多时间,而实验的设计,比如延迟折扣任务中的奖赏金额、折扣率等具体细节的部分才是需要花时间的地方。此处提供的 build_task 主要用于辅助快速原型设计(prototyping),以便加速任务开发流程。
使用方法:
最简单的方式就是使用uvx调用
首先电脑使用pip安装uvx(或者找到uv官网安装uv也行),然后在通过以下方式设置mcp服务
{ "name": "taskbeacon-mcp", "type": "stdio", "description": "Local FastMCP server for taskbeacon task operations. Uses uvx for automatic setup.", "isActive": true, "command": "uvx", "args": [ "taskbeacon-mcp" ]}当看到这些工具出现说明设置成功,
你就可以说,
“请使用build_task工具,以SST任务为模板创建一个Simon任务” (如果不提供模板,它会根据目标任务的需求寻找一个最匹配的模板进行修改)
几分钟后Simon任务就创建好,可以手动调试了。
在写本文的时候又尝试了一次,生成的任务,存在的一些小的bug:
1. 代码中换行符\缺失
2. 受到SST任务影响,它定义了条件生成函数(并且还是有问题的),实际上psyflow有自带的条件生成函数
可以手动修改,也可以与gemini-cli对话让它帮你改。
修改后就能顺利运行。
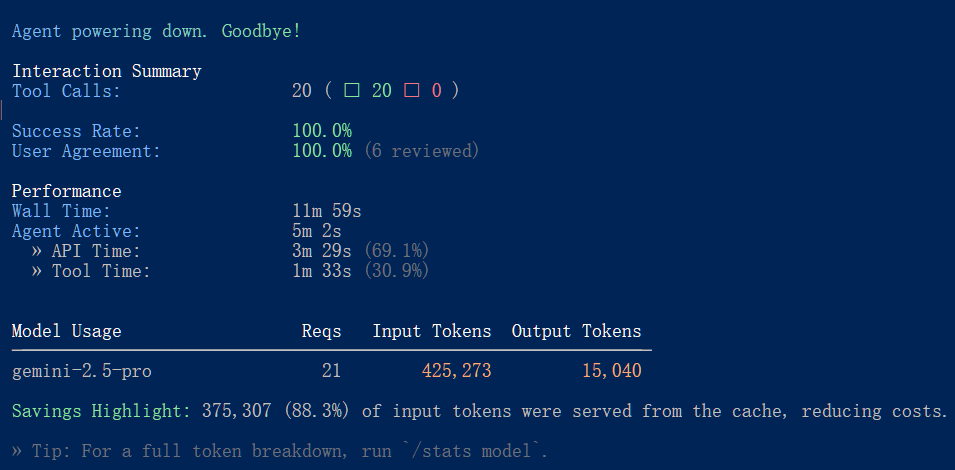
结束后可以看到一个任务大概需要40多万的token,虽然有一些cache hit,不过换作其他模型收费情况如何未知,感谢谷歌提供的白嫖额度让这部分内容得以开展。
你也可用说
“请使用download_task工具下载MID任务,然后使用localize工具将它改为韩语版的” 此时它会下载MID任务,并将文本内容转化为韩语,并选择相应字体和语音(读指导语)。
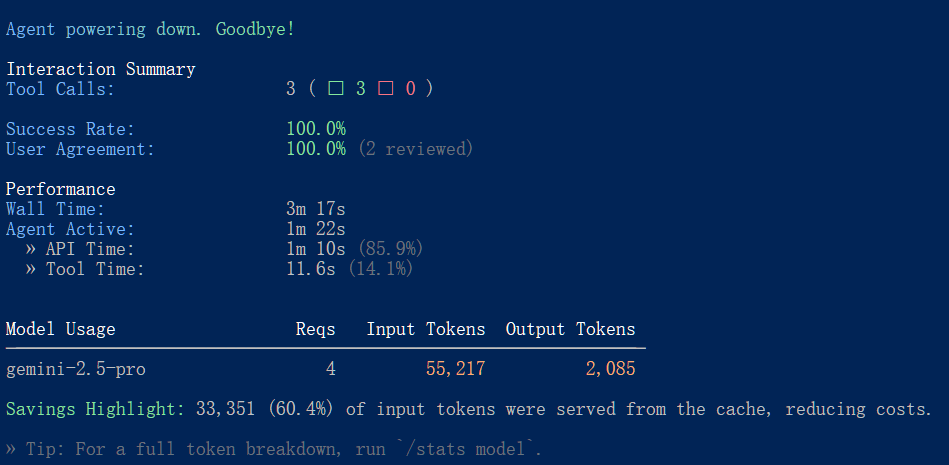
大语言模型难免会有纰漏,特别是翻译内容需要母语者进行校对。本文读者应该不需要这个功能,因为在taskbeacon上的任务目前都是中文。
本项目最后一块拼图——MCP 工具的已基本完成,后续考虑加入:根据文章描述制作任务;将非psyflow任务转为psyflow+taps的任务。
小结
整个项目在实验任务结构、开发框架、任务集构建及大语言模型的融合方面已初步成形。希望这一生态系统能够得以维系和发展,更多研究者带来帮助。同时也需指出,Psyflow 框架及其支持的任务仍处于持续迭代阶段,其可行性与准确性尚需在更多实际应用中进行验证和系统性评估。
📍 项目主页:https://taskbeacon.github.io/
🙌 欢迎前往相关repo提交任务范式或贡献PR