我们看到贝叶斯是不是能想到这种方式是通过算概率的方式对样本进行分类的,算概率的方式也是能对样本进行分类的,朴素贝叶斯算那种标参形数据要比连续性数据要准确的多。
1.贝叶斯分类理论
认识朴素贝叶斯前我们先学习贝叶斯理论。
假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示:
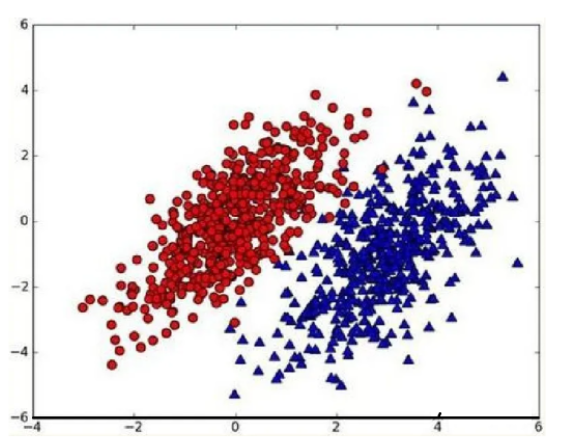
我们现在用p1(x,y)表示类别1(图中红色圆点)的概率,用p2(x,y)类别2(图中蓝色三角)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
如果p1(x,y)>p2(x,y),那么类别为1
如果p1(x,y)<p2(x,y),那么类别为2
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
那么概率怎么算的,我这里就不给大家推理了,直接上公式。
2.贝叶斯公式
B的条件下发生A的概率。
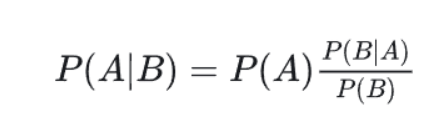
我们把P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成下面的式子:
后验概率 = 先验概率x调整因子
这就是贝叶斯推断的含义。我们先预估一个"先验概率",然后加入实验结果,看这个实验到底是增强还是削弱了"先验概率",由此得到更接近事实的"后验概率"。
3. 朴素贝叶斯
贝叶斯和朴素贝叶斯的概念是不同的,区别就在于“朴素”二字,朴素贝叶斯对条件概率分布做了条件独立性的假设。
贝叶斯公式为:
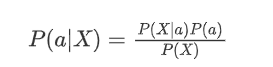
假设是特征之间的条件独立性,即给定类别 a ,特征 x_i 和 x_j (其中 i \neq j 相互独立。)
因此,我们可以将联合概率 P(X|a) 分解为各个特征的概率乘积:

3.1 为什么可以用朴素贝叶斯来分类
首先我们的数据集特征是每一条数据都有一个目标值的,我们训练模型的时候通过找到每一个类别对应的特征规律,当我们测试的时候我们就通过规律去给样本分类,如果用概率的方式是不是在某某特征的条件下为什么类别的概率。
看个例子。
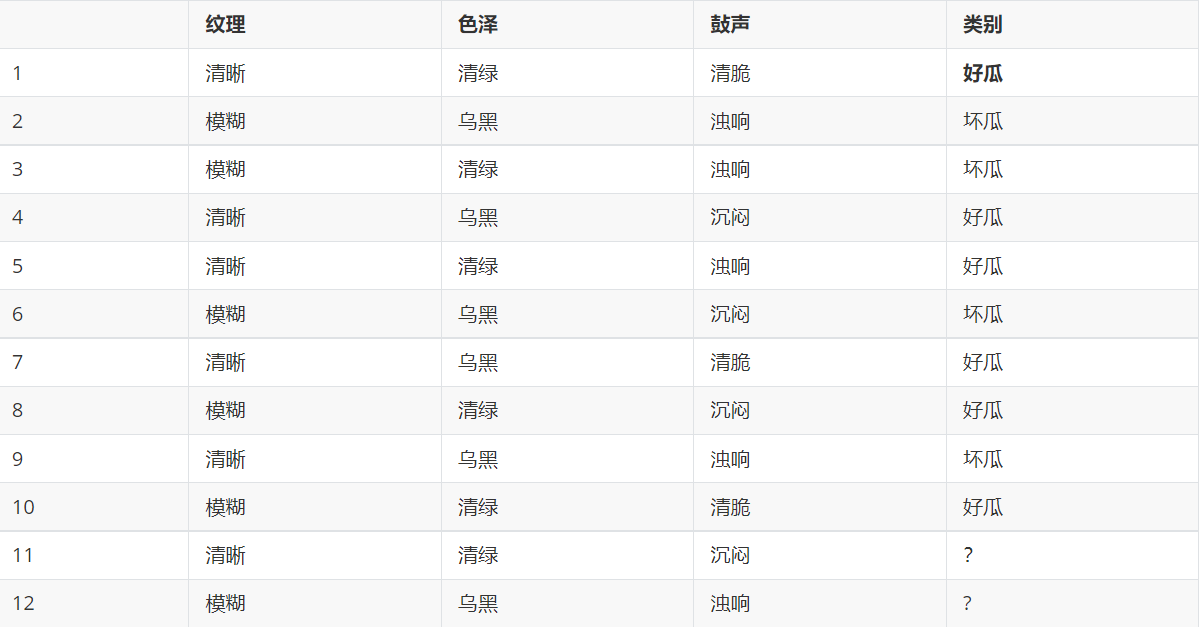
这里的数据特征是纹理,色泽,鼓声,然后我们要在这三个条件下判断是不是好瓜,
我们直接看11,我们要以在纹理是清晰,色泽是青绿,鼓声是沉闷的条件下,是好瓜和坏瓜的概率,我们直接转换为公式。

然后根据表格我们一计算,然后我们再比较两个的概率谁更大是不是就能推断出是好瓜还是坏瓜了。
4. 拉普拉斯平滑系数
某些事件或特征可能从未出现过,这会导致它们的概率被估计为零。然而,在实际应用中,即使某个事件或特征没有出现在训练集中,也不能完全排除它在未来样本中出现的可能性。拉普拉斯平滑技术可以避免这种“零概率陷阱”
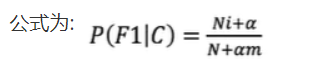
一般α取值1,m的值为总特征数量
通过这种方法,即使某个特征在训练集中从未出现过,它的概率也不会被估计为零,而是会被赋予一个很小但非零的值,从而避免了模型在面对新数据时可能出现的过拟合或预测错误
5 .api
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
# 1)获取数据
news =load_iris()
# 2)划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
# 3)特征工程:不用做标准化
# 4)朴素贝叶斯算法预估器流程
estimator = MultinomialNB()
estimator.fit(x_train, y_train)
# 5)模型评估
score = estimator.score(x_test, y_test)
print("准确率为:\n", score)
# 6)预测
index=estimator.predict([[2,2,3,1]])
print("预测:\n",index,news.target_names,news.target_names[index])