前言
由于我司「七月在线」自24年Q3以来,一直在针对各个工厂、公司、客户特定的业务场景,做解决方案或定制开发,所以针对每一个场景,我们都会反复考虑“用什么样的机器人、什么样的技术方案”做定制开发
于此,便不可避免的追踪国内外最前沿的机器人技术进展,本来准备在上一篇博客《VLM驱动机器狗——从UMI on Legs到Helpful DoggyBot:分别把机械臂装到机器狗背上、夹爪装到机器狗嘴里》之后,解读今天上午看到的字节刚发的机器人大模型GR2
当时,还发微博说,“头一次看paper不看正文,而是直奔其References:看有没有我预想中的文献,说明咱看paper的能力相比去年强很多了”
没想到
- 晚上,一在上海一机器人公司的朋友,又发我了一个链接:OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning,并说这个挺可以的
我回复他说,这个工作 之前看到过,和humanplus、television 挺像『OmniH2O论文(24年6.13)和humanplus(24年6.15)的发布时间差不多,但比television(24年7月初)发布的更早,但后来再一细究发现,OmniH2O的前身H2O发布的更早(24年5月7日):Learning Human-to-Humanoid Real-Time Whole-Body Teleoperation,和此文第一部分中介绍的AnyTeleop发布时间差不多(24年5.16)』
之前 一直没来得及解读,准备也解读下,😆 - 我再问他,你们是在仿真环境中 复现了下,是不
他回答道:“他们最近开源了代码,有新的改进,目前我在仿真中试了下,后续可以尝试迁移”
考虑到OmniH2O及其前身H2O是之前的工作,在字节机器人大模型GR2之前,故本文先解读这个OmniH2O及其前身H2O
update:后续大的修订记录
- 25年5.13日,因为一B端集团客户的需求,需要在宇树G1上二次开发其跳舞的能力,故解读ASAP,而在解读ASAP的过程中,回顾到本文所介绍的H2O,故全面修订了本文的第一部分 H2O
- 25年5.18-19日,把『第二部分 OmniH2O——通用灵巧且可全身远程操作并学习的人形机器人』也修订了下
以让大家花最少的时间 最快理解每一个模型、每一篇论文- 25年6.16日,再次全面修订本文的第一部分 H2O
第一部分 H2O:从人类到人形机器人实时全身摇操的学习
24年5月7日,来自CMU的研究者Tairan He, Zhengyi Luo, Wenli Xiao, Chong Zhang, Kris Kitani, Changliu Liu, Guanya Shi,发布了这篇论文《Learning Human-to-Humanoid Real-Time Whole-Body Teleoperation》
- 如下图所示,该人形机器人由人类操作员通过RGB摄像头进行实时远程操控

- 这个H2O人形机器人在我熟知的几大开源人形机器人里——比如humanplus television,算是发布的最早的了,比如其便是humanplus的第31篇参考文献

1.1 背景及相关工作:第一个实现基于学习的全身远程操作的方法
1.1.1 提出背景:数据集的问题
全尺寸人形机器人整体身体控制一直是机器人领域的一个长期难题 [5],其复杂性在实时控制仿人机器人复制自由形式的人类动作时,复杂性会增加[1]
- 现有关于全身仿人机器人遥操作的研究通过基于模型的控制器取得了显著成果
6-On real-time whole-body human to humanoid motion transfer
7-High speed whole body dynamic motion experiment with real time master-slave humanoid robot system
8-Humanoid dynamic synchronization through whole-body bilateral feedback teleoperation
9-Bilateral humanoid teleoperation system using whole-body exoskeleton cockpit tablis
但由于对系统全动态建模的计算成本极高
10-Controlling humanoid robots with human motion data: Experimental validation
11-Slomo: A general system for legged robot motion imitation from casual videos
这些方法都采用了简化模型,这限制了其对动态动作的可扩展性
此外,这些工作高度依赖于接触测量
12-Multi-contact motion retargeting from human to humanoid robot
13-Adaptive whole-body manipulation in human-to-humanoid multi-contact motion retargeting
导致在遥操作时需要依赖外部设备,如外骨骼
9-Bilateral humanoid teleoperation system using whole-body exoskeleton cockpit tablis
和力传感器
8-Humanoid dynamic synchronization through whole-body bilateral feedback teleoperation
14-Dynamic locomotion synchronization of bipedal robot and human operator via bilateral feedback teleoperation - 近年来,强化学习RL在仿人机器人控制方面的进展为此提供了有前景的替代方案
首先,在图形学领域,RL已被用于生成复杂的人体动作
15-Deepmimic: Example-guided deep reinforcement learning of physics-based character skills
16-A scalable approach to control diverse behaviors for physically simulated characters
执行多种任务
17-Ase: Large-scale reusable adversarial skill embeddings for physically simulated characters
并在仿真中跟踪通过网络摄像头捕捉的实时人体动作
18-Perpetual humanoid control for real-time simulated avatars
然而,由于状态空间设计不切实际且部分忽略了硬件限制(如扭矩/关节限制),这些方法能否应用于全尺寸仿人机器人仍是一个问题
另一方面,RL已在现实世界中实现了稳健且灵活的双足行走
19-Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control
20-Learning humanoid locomotion with transformers
21-Blind bipedal stair traversal via sim-to-real reinforcement learning
但迄今为止,还没有基于RL的全身仿人机器人遥操作相关研究 - 最相关的尝试是一项同期研究[22-Expressive whole-body control for humanoid robots,即Exbody]
其重点是学习复制上半身动作,并对下半身采用根速度跟踪,且基于离线人体动作而非实时遥操作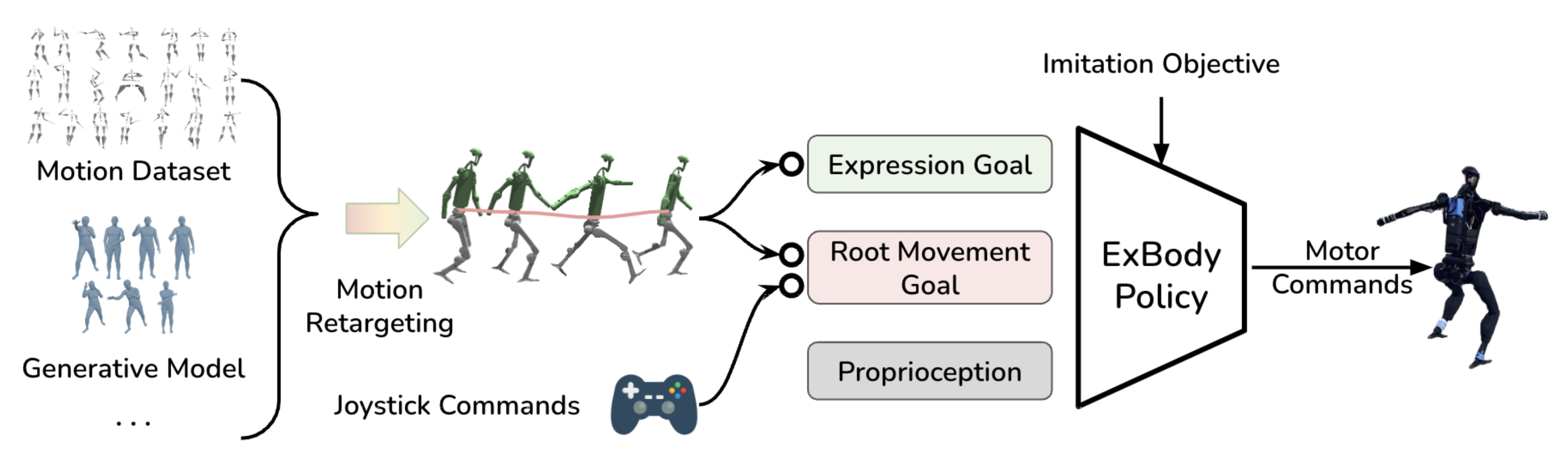
总之,作者指出,整个人形机器人全身远程操作的主要挑战之一,是缺乏专门针对人形机器人、具备可行动作的数据集,而这对于训练能够跟踪多样化动作的控制器至关重要
尽管以往针对运动控制的研究中已探索了从人到人形机器人的直接动作重定向
- 23-Whole-body geometric retargeting for humanoid robots
- 24-A cybernetic avatar system to embody human telepresence for connectivity,exploration, and skill transfer
- 25-Humanoid locomotion as next token prediction
但将大规模人体动作数据集重定向到人形机器人仍面临新的挑战
也就是说,人类与人形机器人之间存在显著的动力学差异,导致某些人体动作对人形机器人来说可能不可行(例如侧手翻、步幅大于人形机器人腿长的步伐)
鉴于此,他们提出了一种自动化的“仿真到数据(sim-to-data)”流程,将大规模人体动作数据集 [26-Amass,关于,在此文HumanPlus的1.1.2 训练用于全身控制的low-level policy:Humanoid Shadowing Transformer中有介绍] 重定向并优化为适合真实世界人形机器人执行的动作
- 具体来说,他们首先通过逆向运动学将人体动作重定向到人形机器人,并利用可访问特权状态信息的控制器[18-Perpetual humanoid control for real-time simulated avatars]
在仿真中模仿未经滤波的人体动作 - 随后,移除那些特权模仿者无法跟踪的动作序列(we remove the motion sequences that the privileged imitator fails to track)
通过这种方式,他们构建了一个大规模、兼容人形机器人的动作数据集
在获得可行动作的数据集后,他们为现实世界动作模仿器开发了一套可扩展的训练流程,该流程结合了大量的领域随机化,以弥合仿真到现实的差距
对了,所谓域随机化是在机器人视觉和仿真领域中使用的技术,其核心思想是在训练过程中对模拟环境中的各种参数进行随机化,以便模型能够在不同的外部条件下学习,从而提高模型在现实环境中的泛化能力 - 为了实现实时遥操作,他们设计了一个状态空间,优先考虑现实世界中通过RGB相机可获取的输入,例如关键点位置
在推理过程中,他们使用现成的人体姿态估计器[27-Hybrik: A hybrid analytical-neural inverse kinematics solution for 3d human pose and shape estimation]来提供全局人体位置
1.1.2 相关工作:基于物理的人体动作动画、将人类动作转移到人形机器人上、人形的远程操作
第一,基于物理的人体动作动画
- 基于物理的仿真已被用于生成逼真且自然的虚拟人动作
[15–18,28–33]
以动作捕捉为主要的人体动作数据来源
26
强化学习RL常被用来学习能够模仿这些动作的虚拟人控制器,从而实现
独特风格[15,31]
可扩展性 [16,18,34]
和可复用性 [17,32] - 然而,基于物理的仿真器中的逼真动画并不保证在现实世界中的适用性,尤其是对于人形机器人
仿真的人形化身通常具有高自由度和较大的关节扭矩[35],有时还需要非物理的辅助外力[36]
在本工作中,他们展示了通过精心设计的仿真到现实训练,人形动画领域的方法可以应用于现实世界的人形机器人
第二,将人类动作迁移到现实世界的人形机器人
在基于强化学习的人形机器人控制器出现之前,传统方法通常采用基于模型的优化来跟踪重定目标动作,同时保持稳定性 [1-Teleoperation of humanoid robots:A survey]
- 为此,这些方法在稳定性和接触约束下最小化跟踪误差,需要预定义的接触状态 [6,10,12,13,37–40]
或来自传感器的接触估计
[7,9,14,41,42]
这限制了在实验室外的大规模部署 - Zhang 等人[11-Slomo: A general system for legged robot motion imitation from casual videos]
使用隐式接触模型预测控制MPC来跟踪从视频中提取的动作,但轨迹必须先离线优化以确保动力学可行性
此外,由于计算负担,MPC中使用的模型需要简化 [6,11,14],这限制了可跟踪动作的能力。基于强化学习的控制器可能提供一种不需要明确接触信息的替代方案 - 一些研究
43-Imitate and repurpose: Learning reusable robot movement skills from human and animal behaviors
44-Humanmimic: Learning natural locomotion and transitions for humanoid robot via wasserstein adversarial imitation
使用模仿学习将人类风格的动作转移到控制器上,但不能准确跟踪人类动作
Cheng等人[22-Expressive whole-body control for humanoid robots,即Exbody]训练了全身类人控制器,可以从离线的人类动作中复制上半身动作,但下半身依赖于根部速度跟踪,并未跟踪精确的下半身动作
相比之下,CMU的工作实现了人类动作的全身实时跟踪
第三,人形机器人远程操控
人形机器人遥操作可以分为三种类型:
- 任务空间远程操作
45-Deep imitation learning for humanoid loco-manipulation through human teleoperation
46-Icub3 avatar system: Enabling remote fully immersive embodiment of humanoidrobots - 上半身重定向远程操作
47-Humanoid loco-manipulation of pushed carts utilizing virtual reality teleoperation
48-Telexistence and teleoperation for walking humanoid robots - 全身远程操作
6-On real-time whole-body human to humanoid motion transfer
7-High speed whole body dynamic motion experiment with real time master-slave humanoid robot system
13-Adaptive whole-body manipulation in human-to-humanoid multi-contact motion retargeting
42-Online human walking imitation in task and joint space based on quadraticprogramming49-Telesar vi: Telexistence surrogate anthropomorphic robot vi
对于第一种和第二种类型,人类与人形机器人之间的形态特征并未得到充分利用,因此必须以任务特定的方式解决全身控制问题
这也引发了一个担忧,即如果不需要跟踪下半身的运动,机器人可以选择更具稳定性的设计,例如四足 [50] 或轮式结构 [51]
CMU的这个H2O属于第三类,并且是首个实现基于学习的全身远程操作的方法。此外,他们的方法无需在人体操作者上安装捕捉标记或力传感器,因为他们直接使用RGB相机捕捉人体动作进行跟踪,这有望为收集大规模类人数据以训练自主智能体铺平道路(所以后来的humanplus也是用的这个RGB摄像头的方式捕捉人类动作进行跟踪)
1.2 第一步 预备知识:人形的RL控制与参数化人体模型SMPL
1.2.1 基于目标的强化学习用于人形机器人控制
首先,将全身实时仿人远程操作被表述为一个以目标为条件的RL问题
作为符号约定,使用![]() 表示来自姿态估计器/关键点检测器的运动学量(不包含物理仿真),用
表示来自姿态估计器/关键点检测器的运动学量(不包含物理仿真),用![]() 表示来自动作捕捉(MoCap)的真实值,而使用没有重音符号的普通符号表示来自物理仿真的数值
表示来自动作捕捉(MoCap)的真实值,而使用没有重音符号的普通符号表示来自物理仿真的数值
为了将问题表述为目标条件强化学习,其中策略π被训练用于跟踪实时的人体动作
- 将学习任务表述为一个由状态集S、动作集A、转移动态T、奖励函数R和折扣因子γ组成的马尔可夫决策过程(MDP):
其中,状态、动作
,
代表轨迹、
代表奖励函数
且状态包含本体感受
,和目标状态
——人类远程操作者全身运动的统一表示
- 基于本体感觉
和目标状态
,可以为策略训练定义奖励
动作指定了 PD 控制器将用于驱动自由度的关节目标位置
然后,应用近端策略梯度优化(PPO)[52] 来最大化累积折扣奖励
从而将远程操作任务表述为运动模仿/跟踪/模仿任务,训练类人机器人在每一帧跟踪参考运动
1.2.2 参数化人体模型SMPL与人体运动数据集AMASS
其次,需要参数化人体模型与人体运动数据集
在视觉和图形学界,参数化人体模型『 如 SMPL[53,相当于是人形机器人的运动建模方法,可以代表人形机器人,在我解读的humanplus一文中的此节“1.1.2 训练用于全身控制的low-level policy:Humanoid Shadowing Transformer”也有相关介绍] 』因其易于处理的人体形状和动作表示而广受欢迎
- SMPL 将人体表示为身体形状参数
,姿态参数
,以及根部平移
- 给定
、
和
,
表示 SMPL 函数,其中
将参数映射到一个包含 6890 个顶点的人体三角网格的顶点位置
- AMASS [26] 数据集包含40 小时以SMPL 参数表达的动作捕捉数据
1.3 第二步 Retargeting:面向人形机器人的人类动作重定向
- 为了使人形机器人能够模仿非脚本化的人类动作,需要大量的全身动作数据来训练一个鲁棒的动作模仿策略
下文1.3.1节 详述 - 但由于人类和人形机器人在身体结构、形状和动力学方面存在显著差异,直接从人类动作数据集中重定向的动作可能会导致大量人形机器人无法执行的动作
这些不可行的动作序列会妨碍模仿训练,正如先前的研究[32-Universal humanoid motion representations for physics-based control] 所观察到的
为了解决这些问题,作者设计了一种“从仿真到数据(sim-to-data)”的方法,以补充传统的重定向,将大规模人类动作数据集转换为人形机器人可行的动作
下文1.3.2节 详述
1.3.1 动作重定向:通过SMPL数据集建模人形以逼近人类动作(13K到10K)
由于SMPL运动结构与人形运动之间存在不少的差异,作者针对初始重定向执行了一个两步过程
- 首先,由于SMPL身体模型可以表示不同的身体比例,故需要在SMPL中找到一个最接近人形结构的身体形状
First,since the SMPL body model can represent different body proportions,we first find a body shape β′ closest to the humanoid structure.
即选择12个在人类和人形之间具有对应关系的关节(We choose 12 joints that have a cor-respondence between humans and humanoids)
如下图图2所示『将SMPL身体拟合到H1人形模型。(a) 人形模型关键点的可视化(红点),(b) 红色的人形模型关键点 分别与 SMPL关键点(绿色点和网格)在拟合SMPL形状之前和之后的对比,(c) 拟合前后的对应12个关节位置』
并在一个通用的静止姿态下,对形状参数
进行梯度下降,以最小化关节之间的距离(perform gradient descents on the shape parameters to minimize the joint distances using a common rest pose)
在找到最优的后,给定以SMPL参数表示的一系列动作,使用原始的平移
After finding the optimal β′, given a sequence of motions ex-pressed in SMPL parameters, we use the original translationp and pose θ, but the fitted shape β′ to obtain the set of body keypoint positions. - 然后,通过最小化12个关节位置的差异,利用Adam优化器[54],将动作从人类重定向到人形
Then we retarget motion from human tohumanoid by minimizing the 12 joint position differencesusing Adam optimizer [54].
请注意,该重定向过程试图匹配人类与人形的末端执行器(例如脚踝、肘部、手腕),以保持整体运动模式
Notice that our retargeting process try to match the end effectors of the human to the humanoid (e.g. ankles, elbows, wrists) to preserve the overallmotion pattern.
当然,还有另一种方法是将人类的局部关节角度复制到类人模型,但这种方法由于运动学树的巨大差异,可能导致末端执行器位置出现较大偏差
Another approach is direct copying the localjoint angles from human to humanoid, but that approach can lead to large differences in end-effector positions due to the large difference in kinematic trees. - 在整个过程中,作者还添加了一些基于启发式的过滤,以去除不安全的序列,例如坐在地上
在重定向之前寻找
使用
最终,在拟合过程中使用
从而把AMASS数据集中的13K运动序列
,经过计算,得到10k重新定向的运动序列
关于重定向的更多细节,还可以看下此文《HumanPlus——斯坦福ALOHA团队开源的人形机器人:融合影子学习技术、RL、模仿学习》中的1.1.2节:训练用于全身控制的low-level policy:Humanoid Shadowing Transformer(含重定位)

1.3.2 基于仿真的数据清洗sim-to-data:训练动作模仿器(从本体状态到目标状态,10K到8.5K)
由于人类与电机驱动的人形机器人之间能力的显著差距,即便把AMASS数据集中的13K运动序列,经过上一节1.3.1节所述的计算,得到10k重新定向的运动序列
,依然包含大量在人形上无法实现或不现实的运动(比如里面可能有倒立的运动,而人形在目前情况下 很难倒立)
考虑到从大规模数据集中人工筛选这些数据序列是一个相当繁琐的过程
- 因此,作者提出了一种“sim-to-data”的流程,即训练一个动作模仿器
其类似于PHC [18-Perpetual humanoid control for real-time simulated avatars]
该模仿器可以访问特权信息privileged information,且没有域随机化domain randomization,以模仿所有未被进一步清洗的数据
Thus, we propose a “sim-to-data” procedure, where we train a motion imitator πprivileged (similar to PHC [18]) with accessto privileged information and no domain randomization toimitate all uncleaned data ˆQretarget. - 在没有领域随机化的情况下,
能够很好地完成动作模仿,但并不适合迁移到真实的人形机器人上
Without domain random-ization, πprivileged can perform well in motion imitation, butis not suitable for transfer to the real humanoid.
然而,
具体来说,按照PULSE [32-Universal humanoid motion representations for physics-based control]
中提出的相同状态空间、控制参数和hard-negative mining 流程训练
训练完成后,AMASS的10k个动作序列中约有8.5k被证明对H1人形机器人是合理的,将获得的干净数据集称为
那具体是怎么训练的呢
简言之,如上面所述,遵循PULSE [32],训练一个具有“人形机器人的完整刚体状态访问权限”的动作模仿器「To train πprivileged, wefollow PULSE [32] and train a motion imitator with access to the full rigid body state of the humanoid」
具体来说,如下图b所示
- 对于特权策略——privileged policy
其中包含了人形机器人的所有刚体的全局三维位置、姿态orientation
、线速度
和角速度
- 目标状态定义为
其中包含了人形机器人中所有刚体的当前仿真结果与参考结果之间的一帧帧差异(which contains the one-frame difference between the reference and current simulation result for all rigid bodies on the humanoid)
它还包含了下一帧的参考刚体姿态orientation和位置,所有值都被归一化到人形机器人的坐标系中
注意,所有值都是全局的,像全局刚体线速度和角速度
,这样的值在现实世界中难以准确获取
整体训练流程图:包含Retargeting、Sim-to-Real、Real-time遥控
有了上述的Retargeting和Sim-to-Real的训练,可知整个训练过程前两部分如下图所示(建议好好品味下图,流程画的非常清晰)
- 重定向:H2O首先通过优化形状参数将SMPL身体模型对齐到类人结构
即AMASS数据集中的13K运动序列
然后,H2O使用训练好的特权模仿策略重新定向并去除不可行的动作,从而生成一个干净的动作数据集
即AMASS的10k个动作序列中约有8.5k被证明对H1人形机器人是合理的,将获得的干净数据集称为- 仿真到现实训练:通过从清理后的数据集中采样的动作目标来训练模仿策略
- 实时遥操作部署:实时遥操作部署通过RGB摄像头和姿态估计器捕捉人类动作,然后人形机器人使用训练好的Sim-to-Real模仿策略进行模仿
接下来,咱们考虑全身遥操作下的策略训练
1.4 第三步 全身实时遥操策略训练
1.4.1 状态空间
为了实现人形机器人实时遥操作,强化学习策略的状态空间必须仅包含在现实世界中可获得的量
这与仅基于仿真的方法不同,后者(仿真)可以获得所有物理信息(例如足部接触力)。但在现实世界中,由于缺乏IMU,无法获得每个关节精确的全局角速度,但特权策略却需要这些信息
- 故在状态空间设计中,本体感受定义为
其中
关节位置——相当于自由度(DoF)位置
关节速度——相当于DoF速度
根部线速度,根部角速度
,根部投影重力
以及上一次动作 - 目标状态是
表示八个选定的参考身体位置的位置(肩膀、肘部、手、脚踝)
指参考关节与人形机器人自身关节之间的位置差异;
是参考关节的线速度
所有数值均归一化到人形机器人的自身坐标系 - 作为对比,还考虑一个简化的目标状态
其中仅包含参考位置,而不包含位置差异
灵巧策略的动作空间由19维关节目标组成,一个PD控制器通过将这些关节目标转换为关节力矩来跟踪它们
1.4.2 奖励的设计
作者将奖励函数表述为三个部分的总和:1)惩罚;2)正则项;以及 3)任务奖励,详细总结见下表表I:奖励组件及权重(包括防止不良行为以实现仿真到现实迁移的惩罚奖励、用于精细化动作的正则化项,以及实现实时全身跟踪的任务奖励)

请注意,虽然这个状态空间中只有八个选定的身体位置 ,但作者为模仿任务提供了六个全身奖励项(自由度位置、自由度速度、身体位置、身体旋转、身体速度、身体角速度),相当于这些丰富的奖励为高效的强化学习训练提供了更密集的奖励信号
1.4.3 域随机化Domain Randomization(阐述细致)
域随机化已被证明是实现sim-to-real迁移[19-Reinforcement learning for versatile, dynamic, and robust bipedal locomotion control,58-Sim-to-real transfer of robotic control with dynamics randomization]成功的鲁棒性和泛化能力的关键来源
在H2O中使用的所有域随机化列在下表表II中

包括地面摩擦系数、连杆质量、躯干连杆的质心位置、PD控制器的PD增益、每个关节实际施加扭矩的力矩噪声、控制延迟、地形类型
连杆质量和PD增益对于每个连杆和关节是独立随机化的,其余则是回合随机化,这些域随机化能够有效促进现实世界动力学与硬件差异下的sim-to-real迁移
如Xue Bin(Jason)Peng所说
- 现实中的动力学系统并不是静态的(non-stationary)。在仿真中,系统的动力学几乎是固定不变的。这意味着你可以很容易地复现实验:一个控制器只要成功运行一次,基本上就可以无数次重复,每次的行为表现都非常一致
但在真实机器人上,动力学系统是持续变化的。一个控制器今天可能运行得很好,但过一段时间,它的表现就可能完全不同。举个例子,机器人使用时间长了以后,电机发热,就会导致系统动力学发生变化。所以,一个10分钟前还能正常运行的控制器,可能在你再次运行时就不再有效了- 那如何应对 sim-to-real 转移中的挑战的?
他认为,在进行 sim-to-real 转移(即从仿真到真实环境迁移)过程中,主要面临的挑战包括:部分可观测性、系统不确定性,以及现实中机器人动力学的非静态性
Xue Bin(Jason)Peng说,他们目前应对这些挑战的核心方法是使用域随机化(domain randomization)。在大多数研究中,会在仿真环境中训练控制器,然后将其直接部署到真实机器人上
而为了缩小仿真与现实之间的“现实差距(reality gap)”,会在训练时会对仿真中的物理参数进行大量随机扰动,比如质量、摩擦、延迟和传感器噪声等。这种方法可以促使控制器学习到更强健、适应性更强的策略,从而更好地泛化到真实环境中的不确定性
所以到目前为止,域随机化仍然是他们在 sim-to-real 转移中使用的最主要的工具
1.4.4 提前终止条件
作者引入了三个提前终止条件,以提高强化学习训练过程的样本效率:
- 高度过低:基础高度低于0.3米
- 姿态:重力在x或y轴上的投影超过0.7
- 远程操作容忍度:机器人与参考动作之间的平均连杆距离超过0.5米
1.5 实验:仿真实验、真实场景演示
1.5.1 仿真实验
首先,对于基线
为了揭示不同重定向方法、状态空间设计以及仿真到现实训练技术对全身远程操作性能的影响,他们考虑了4种基线方法
- 特权策略
- H2O-w/o-sim2data:不包含”sim-to-data” 重定向的H2O,训练于
- H2O-reduced:目标状态状态空间仅包含选定身体位置
的H2O
- H2O:他们的完整H2O 系统,包含第1.3节介绍的全部重定向过程和第1.4.1节介绍的状态空间设计,训练于
其次,对于评估指标
他们在未清洗的重定向AMASS 数据集(10k序列)上对这些基线进行了仿真评估。评估指标如下:
- 成功率:成功率(Succ)与PHC [18] 中的定义相同,当在模仿过程中任意时刻,身体距离的平均差异平均超过0.5 m 时,认为模仿不成功
Succ 衡量类人模型是否能够在不失去平衡或显著落后的情况下跟踪参考动作 和
前者是全局MPJPE
(单位为mm)
用于衡量他们的模仿者在全局和局部(以根节点为基准)模仿参考动作的能力- Eacc和Evel :为了展示物理真实感,他们还比较了加速度
(mm/frame2)和速度
(mm/frame)的差异
最后,对于实验结果
首先,实验结果总结于表III

- 其中H2O 在很大程度上显著优于H2O-w/o-sim2data 和H2O-reduced,证明了”sim-to-data” 过程以及针对RL 的运动目标状态空间设计的重要性
需要注意的是,privileged policy 和H2O-w/o-sim2data 是在整个重定向AMASS 数据集上训练的,而H2O 和H2O-reduced 是在过滤后的数据集
上训练的
- H2O 和privileged policy 之间的成功率差距主要来自两个因素:
1 与privileged policy 相比,H2O 采用了更加实用但信息量更少的观测空间策略
2 H2O经过所有仿真到现实的正则化处理和域随机化训练——这两个因素都会导致仿真性能下降
这表明,尽管基于强化学习的虚拟人控制框架在仿真中取得了令人印象深刻的成果,但将其迁移到现实世界仍需要更高的鲁棒性和稳定性,说白了,就是虽在sim中表现很好,但real中会有所损失——正常现象
通过精心选择的数据集和状态空间,他们能够使H2O相比H2O-w/o-sim2data和H2O-reduced获得更高的成功率,具体而言
- 关于数据集
通过比较H2O与H2O-w/o-sim2data,可以看到他们的“sim-to-data”流程在获得更高成功率方面是有效的,即使RL策略是在更少的数据上训练的
直观上,不合理的动作可能导致策略浪费资源去尝试实现它们,而将这些动作过滤掉可以带来更好的整体性能,这一点在PULSE [32]中也有观察到 - 关于状态空间
对比H2O与H2O-reduced,唯一的区别在于目标的状态空间设计,这表明包含更多关于动作的物理信息有助于强化学习在大规模动作模仿中实现更好的泛化能力
其次,作者还进行了运动数据集规模消融实验。为了展示运动跟踪性能如何随运动数据集规模变化而变化,作者通过随机选择1 %, 10 % 的 ,在不同规模的
上测试H2O
结果总结在表IV 中,其中在更大运动数据集上训练的策略持续提升了跟踪性能
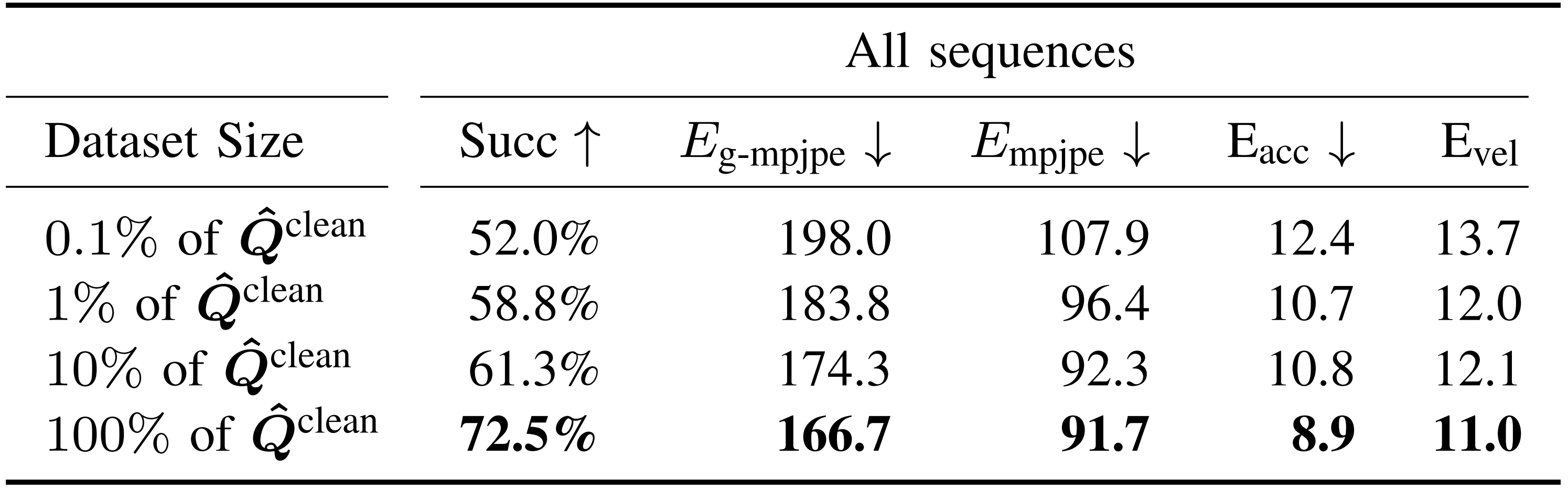
需要注意的是,仅用0.1 % 数据训练的策略也能取得令人惊讶的高成功率,这很可能得益于对人形机器人施加了大量领域随机化,例如推机器人显著扩展了人形机器人遇到的状态空间,从而提升了其泛化能力
// 待更
1.5.2 真实场景演示:部署细节、真实世界远程操作结果
首先,对于部署细节
对于真实场景的部署测试,作者使用一台标准的1080P网络摄像头作为RGB相机,并采用HybrIK [27] 作为3D人体姿态估计算法,运行频率为30Hz
对于机器人的线速度估计,作者利用动作捕捉系统(50Hz),其余所有本体感知信息均通过Unitree H1人形机器人内置传感器(200Hz)获取。线速度状态估计可以通过机载视觉/激光雷达里程计方法替代,然而本研究出于简化考虑,选择使用动作捕捉系统
其次,对于真实世界远程操作结果
对于实时远程操作,来自RGB摄像头的三维姿态估计存在噪声,并且可能受到视角偏差的影响,但他们的H2O策略在面对真实世界实时估算的运动目标时展现出很强的泛化能力
真实世界远程操作如图1、图5和图6所示,H2O使得仿人机器人能够精确地进行实时全身动态动作控制,如踢球、行走和后空翻

1.6 总结与局限性:迈向通用、实时、全身
1.6.1 迈向通用人形机器人远程操作
作者的最终目标是使人形机器人能够尽可能多地模仿人类演示的动作。他们强调未来可以改进的三个关键因素
- 缩小表示差距:如第VI-A节(即1.5.1节)所示,动作目标的状态表示对于强化学习在更丰富动作上的可扩展性具有关键影响,这导致了权衡。虽然在状态空间中引入更具表现力的动作表示可以容纳更细粒度和更多样化的动作,但维度的增加会导致可扩展强化学习中的样本效率问题
- 缩小体现差距:如第VI-A节(即1.5.1节)及以往研究所示[32]指出,在不可行或损坏的动作上进行训练可能会极大地损害性能。由于硬件限制,不同机器人对动作的可行性存在差异,目前还缺乏系统性算法来识别可行动作。因此,需要更多努力来缩小这种体现差距:
一方面,更类人的人形机器人将有所帮助;
另一方面,更多的远程操作研究有望提升人类动作的可学习性 - 缩小仿真到现实的差距:为了实现成功的仿真到现实迁移,需要进行正则化(如奖励正则化)和领域随机化
然而,过度正则化和过度随机化也会阻碍策略对动作的学习。目前尚不清楚如何在动作模仿学习和仿真到现实迁移之间实现最佳权衡,从而形成通用的人形机器人控制策略
1.6.2 迈向实时人形机器人远程操作
在本研究中,作者利用RGB和三维姿态估计算法,将人类远程操作员的动作转化为人形机器人的动作。RGB相机和姿态估计所带来的延迟与误差,也导致了远程操作中效率与精度之间不可避免的权衡
此外,在本研究中,人类远程操作员仅通过视觉感知从人形机器人获得反馈。因此,关于人机交互的研究仍需深入,特别是针对这种新兴的多模态交互『例如,力反馈[59-Touch and go: Learning from human-collected vision and touch]、语言和对话反馈[60-Language to action: Towards interactive task learning with physical agents]』,这些方式有望进一步提升人形机器人远程操作的能力
1.6.3 迈向全身类人机器人远程操作
人们可能会疑惑下半身追踪是否必要,因为人类与类人机器人之间的主要体现差异在于下半身能力。人类大量高超的动作(如体育运动、舞蹈)都需要多样且灵活的下半身运动
作者特别强调在腿式机器人相较于轮式机器人具有优势的场景中,下半身追踪对于跟随人类下半身动作(包括踩石、踢腿、劈腿等)是必不可少的。展望未来,能够在稳健行走与高超下半身追踪之间切换的远程操作类人机器人系统,将成为一个极具前景的研究方向
总之,在本研究中
- 作者提出了人类到类人机器人(H2O)这一可扩展的基于学习的框架,实现了仅使用RGB相机即可对类人机器人进行实时全身遥操作
- 他们的方法利用强化学习和创新的“sim-to-data”流程,解决了将人类动作转换为类人机器人可执行动作的复杂难题
通过全面的仿真和实际测试,H2O展现了其以高保真度和极低硬件需求完成多种动态任务的能力
第二部分 OmniH2O——通用灵巧且可全身远程操作并学习的人形机器人
2.1 整体概览OmniH2O
2.1.1 OmniH2O的特点
24年6.13日(humanplus是24年6.15,television则是24年7月初),来自CMU、上交的研究者们「Tairan He, Zhengyi Luo, Xialin He, Wenli Xiao, Chong Zhang, Weinan Zhang, Kris Kitani, Changliu Liu, Guanya Shi(标粗的标识也是H2O的作者)」,在上文H2O的基础上,推出OmniH2O

- 其论文地址为:《OmniH2O: Universal and Dexterous Human-to-Humanoid Whole-Body Teleoperation and Learning》
- 其项目地址为:omni.human2humanoid.com
- 其GitHub地址为:LeCAR-Lab/human2humanoid
初看,代码貌似是齐全的——包括重定向的代码,关于机器 作者用的H1上
OmniH2O以运动学姿态作为通用控制接口,使人类能够通过多种方式控制具备灵巧手的全尺寸人形机器人,包括通过VR头显进行实时远程操作、语音指令以及RGB摄像头
OmniH2O还可通过学习远程操作演示或与前沿模型(如GPT-4o)集成,实现完全自主
2.1.2 其与前身H2O、其他机器人的对比
与它的前身H20、以及与之前一些带虚拟现实的人形机器人有何异同呢
- H2O [3] 提出了一种基于强化学习的全身远程操作框架,该框架使用第三人称RGB摄像头获取人类远程操作者的全身关键点
然而,由于基于RGB的姿态估计存在延迟和不准确性,并且需要全局线速度估计,H2O [3] 在测试时需要使用动作捕捉(MoCap),仅支持简单的移动任务,并且在精细操作任务中缺乏精度
相比之下,OmniH2O 能够在室内和野外实现高精度的灵巧运动-操作 - 为了控制全尺寸类人机器人,提出了多种接口,如外骨骼[31]、动作捕捉(MoCap)[32,33]和虚拟现实(VR)[34,35]
近年来,基于VR的类人控制[36,37,38,39]因其能够利用稀疏输入实现全身动作生成,在图形学社区受到关注。然而,这些基于VR的方法仅关注于动画中的类人控制,并不支持移动操作。相比之下,OmniH2O能够控制真实的类人机器人完成现实世界的操作任务 - 此外,机器人领域面临的一个主要挑战是公开可用的数据集数量远少于语言和视觉任务的数据集 [40]
近期的研究工作[40,41,42,43,44,45,46,47]致力于通过不同的体型收集用于不同任务的机器人数据。然而,这些数据集大多数是采用固定基座的机械臂平台采集的。即使是目前最全面的数据集之一 Open X-Embodiment [40],也未包含人形机器人的数据
故,作者宣称,他们是首个发布全尺寸人形机器人全身运动-操作数据集的团队
2.2 由浅入深:问题定义与运动重定向
2.2.1 问题定义:针对马尔可夫决策过程(MDP)的目标条件强化学习
与H2O类似,OmniH2O也将学习问题表述为针对马尔可夫决策过程(MDP)的目标条件强化学习goal-conditioned RL
- 其由元组
定义,包括状态
、动作
、转移
状态和目标状态
目标状态包括来自人类遥操作员或自主智能体的运动目标
- 基于本体感知
和动作
,定义奖励
其中,动作
且应用近端策略优化算法PPO来最大化累积折扣奖励
- 在这项工作中,作者研究运动模仿任务,其中策略
被训练用于跟踪下图 所示的实时运动输入

此任务为人形机器人控制提供了通用接口,因为运动姿态可以由许多不同的来源提供
且,将运动姿态定义为,由人形机器人所有关节的三维关节旋转
和位置
组成
另,为了定义速度,有
,其中
为角速度,
为线速度
且作为符号惯例,使用表示来自 VR 头显或姿态生成器的运动学量,使用
表示来自 MoCap 数据集的真实值,而不带重音的符号表示来自物理仿真或真实机器人的数值
2.2.2 人体运动重定向与奖励与域随机化
2.2.2.1 人体运动重定向
类似H2O的重定向过程,OmniH2O也使用来自AMASS [49]数据集的重定向动作训练OmniH2O的动作模仿策略
- 但H2O 的一个主要缺点是仿人机器人倾向于采取小的调整步伐,而不是静止站立。为了增强稳定站立和下蹲的能力,作者通过添加包含固定下肢动作的序列来对训练数据进行偏置
- 具体来说,对于数据集中的每个动作序列
,通过固定根部位置和下半身于站立或下蹲姿势,如图2所示,创建了一个“稳定”的版本

2.2.2.2 奖励与域随机化
为了训练适合作为现实世界中可部署的学生策略的教师的,OmniH2O采用了模仿奖励和正则化奖励
- 以往的研究
18-Expressive whole-body control for humanoid robots,即Exbody
3-Learning human-to-humanoid real-time whole-body teleoperation,即H2O
通常使用如双脚悬空时间或双脚高度等正则化奖励来塑造下肢动作。然而,这些奖励导致人形机器人为了保持平衡而跺脚,而不是静止站立 - 为了鼓励静止站立和在行走过程中迈大步,OmniH2O提出了一个关键奖励函数:每一步的最大双脚高度
他们发现,这一奖励结合精心设计的curriculum应用时,能够有效帮助强化学习决定何时站立或行走
2.3 深入细节:师生学习与策略蒸馏详解
2.3.1 教师:特权模仿策略
如作者之一罗正宜所说
- OmniH2O中加入了一个策略蒸馏过程,即从一个完整输入的教师模型中提取知识,再教给只拥有部分输入的学生模型
- 具体而言,PHC 的控制器使用的是全身的动作信息输入,但在蒸馏过程中,只提供给学生模型少量的关键点输入,例如三个点位,通过模仿教师模型的行为来学习完整的控制策略
在人形机器人实际远程操作过程中,许多在仿真中可获得的信息(例如,每个刚体连杆的全局线性/角速度)在现实中并不可用
此外,远程操作系统的输入可能非常稀疏(例如,对于基于VR 的远程操作,仅已知手和头部的位姿),这使得强化学习优化变得具有挑战性
- 为了解决这个问题,OmniH2O首先训练一个利用特权状态信息的教师策略,然后将其蒸馏到一个状态空间受限的学生策略中
下表表4,便是特权策略设置下的状态空间信息
相当于如下图所示,sim-to-real 策略通过有监督学习从使用特权信息训练的 RL 教师策略中提炼而来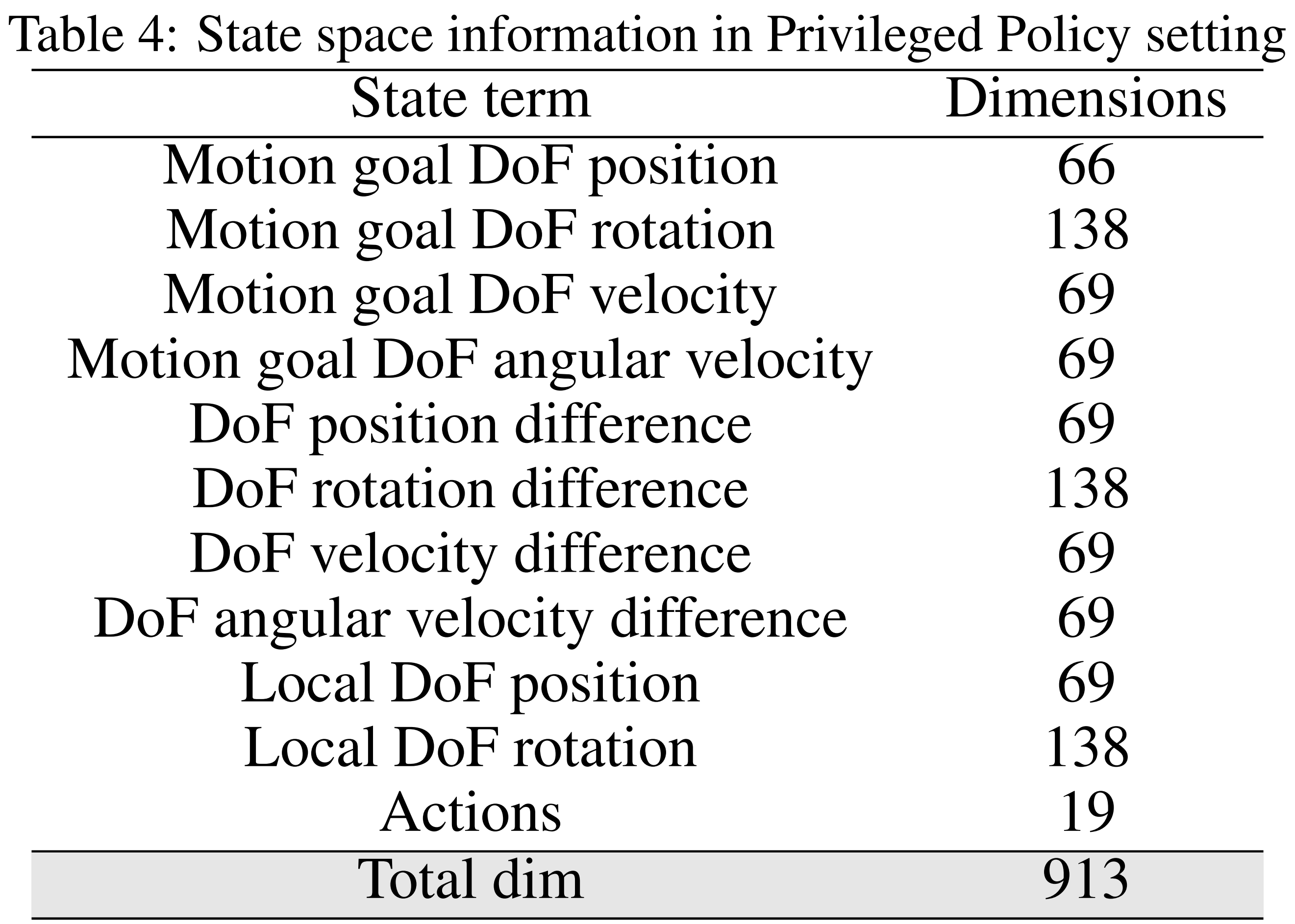
总之,获得特权状态的访问权限可以帮助强化学习找到更优的解,正如之前的研究[50-Learning quadrupedal locomotion over challenging terrain]和OmniH2O的实验所示 - 故OmniH2O训练一个特权动作模仿器
本体感知被定义为
其中包含人形机器人刚体的位置、角速度
目标状态被定义为
其中包含参考位姿,以及所有刚体的参考状态与当前状态之间的单帧差异
2.3.2 学生:具有历史记录的Sim-to-Real模仿策略
作者通过使用运动学参考动作作为中间表示,设计了兼容多种输入源的控制策略。由于估计全身运动(包括旋转和位移)较为困难——尤其是在使用VR头显时,故选择仅通过位置
来控制人形机器人进行远程操作
具体而言
- 对于真实的操控, 目标状态是
上标“真实”表示使用来自VR头显的3个可用点(头部和双手)。对于其他控制界面(例如RGB、语言),他们使用相同的3点输入以保持一致性,尽管可以轻松扩展到更多关键点以减少歧义
那为何使用3点输入呢,原因在于他们测试了从最小(3个)到全身动作目标(22个)的配置,发现3点追踪可以在性能上与更多输入关键点相媲美。如他们所预料到的,3点策略在某种程度上牺牲了全身动作追踪的精确性,但在适用于市售设备方面具有更大的实用性
说白了,牺牲一定的准确性以换取更大的实用性 - 对于本体感知,学生策略
使用在现实世界中易于获取的值,包括
顺带解释一下,为何是25步呢?原因在于作者在不同的历史步骤(0, 5, 25, 50)都进行了实验,他们发现25步在性能和学习效率之间达到了最佳平衡
历史数据的使用有助于通过师生监督学习提升策略的鲁棒性。需要注意的是,观测中并未包含全局线速度
2.3.3(上) 策略蒸馏:学生策略向老师策略的逼近与学习
接下来,按照DAgger[51]框架训练可部署的远程操作策略
DAgger对应的paper为:A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
算法按如下方式进行
- 第一次迭代时,它使用专家的策略收集轨迹数据集
,并训练一个能够最好地模仿专家在这些轨迹上的策略
- 然后在第
次迭代时,使用
收集更多的轨迹,并将这些轨迹添加到数据集
下一个策略是在整个数据集
- 对于每个回合,在仿真simulation中执行学生策略——上图b中 上面是当前姿态 下面是参考姿态(目标姿态),目标是从上面姿态到下面姿态
来获得
的轨迹
即for each episode,we roll out the student policy πOmniH2O(at|sp-realt, sg-realt) in simulation to obtain trajectories of (sp-real1:T , sg-real1:T ). - 通过使用仿真中的人形状态
,和参考姿态
即Using the ref-erence pose ˆq1:T and simulated humanoid states sp1:T , we can compute the privileged states sg-privilegedt, sp-privilegedt←(spt, ˆqt+1).
然后,使用对——进行查询
即Then, using the pair (sp-privilegedt, sg-privilegedt), we query the teacher πprivileged(atprivileged|sp-privilegedt, sg-privilegedt) to calculate the reference action atprivileged.
即向教师
请求计算参考动作——即目标动作
- 为了更新
,损失函数为
最终,实验表明,可部署的学生策略在动作模仿方面显著优于之前的研究[3-即H2O,Learning human-to-humanoid real-time whole-body teleoperation],并且达到了与教师策略相似的成功率
2.3.3(下) 补充阅读:如何更好的理解师生网络学习
如Open Television的作者所说,Teacher和Student在强化学习中的角色不同
- Teacher通常能够获取更多的Privileged information,就像不论是跑酷还是盲走,Teacher能够获得更多的信息,这是强化学习中的一种普遍现象
- 如果强化学习中的探索不足,就很难训练出最优的行为。因此,一般希望尽可能为老师提供更多的信息
毕竟在仿真环境中,可以获取到各种奇怪的信息,全喂给它。例如在训练机器狗时,直接告诉它你背负了多重的东西,这样教师可以更好地、更快地学习
而学生需要在现实世界中适应环境
- 不能仅仅依赖仿真环境中的Privileged information来训练学生,学生的训练需要使用现实世界中可用的数据和信息
- 总体思路是,在仿真环境中,Teacher的训练是怎么能够更快更好的训练出来一个能work的东西,然后再把它distill成现实世界中可以用的东西
对于机器人运动训练Locomotion,目前在这方面最流行的RL方法就是仿真到现实强化学习(Sim2Real RL),就是先在虚拟仿真(Simulated)环境里,运用近端策略优化算法(PPO)或者其他类似的算法去训练出一个策略,之后再把这个策略部署到现实世界当中去
作者石冠亚在一次访谈中提到
- 我认为 Sim2Real RL是一种基于模型的方法
比如,首先得有一个你比较信赖的模型,比如仿真器(Simulator),然后在这个仿真器里训练出一个策略(Policy),之后再把这个策略部署到现实(Real world)当中- 作者认为Sim2Real RL在一定程度上绕开了状态估计(State estimation)的问题
在传统的控制里,一般遵循分离原则(Separate principle),比如说要用模型预测控制(MPC)去控制一个人形机器人,在这之前,大概率得先搞一个状态估计器(State estimator),去估计机器人自身的速度、角速度等物理量
从某种程度上,在传统控制里,状态估计(Estimation)其实和Control一样,都是要面对的问题
说到底,你得清楚机器人所处的状态、得知道机器人此时此刻在什么位置
进一步而言,如Xue Bin(Jason)Peng所说,状态估计(state estimation)在真实机器人中比想象的要难得多
而强化学习RL在一定程度上能绕开这个问题,因为它可以同时学习策略(Policy)和状态估计器(State estimator)- 即拿目前在 Locomotion方面最成功、最流行的逻辑来说:师生网络学习(Teacher Student Learning)——参见Science Robotics发布论文“Learning quadrupedal locomotion over challenging terrain”
所谓师生网络学习是指先在仿真环境(Simulator)里训练出一个所谓的“教师策略(Teacher Policy)”,这个“教师策略”知晓一切,比如它知道仿真器里的所有信息,像地面的各种情况、机器人的速度等等,这些称之为特权状态(Privilege state)
然后,这个“教师策略”(Policy)是没办法直接部署到真机上的,因为在现实中,你没办法知晓地面情况,也不清楚机器人的绝对速度等信息
不过在RL里,利用这个“教师策略”后,可以将它提炼到一个叫“学生策略”(Student policy)的东西里,这个“学生策略”的输入是你所能观测到信息的历史记录,也就是“过去n步”的相关情况
就是因为有这种师生学习框架,所以绕开了状态估计(State estimation)这个问题。相当于在实际应用中,你不需要获取真实的状态,可以直接利用感知信息的历史记录就可以进行控制了。 我觉得这两点就是强化学习RL最大的优势
附录 灵巧的手部控制
如下图3(c)所示「OmniH2O的通用设计支持多种人类控制接口,包括VR头显、RGB摄像头、语言等,且还支持通过自主代理进行控制,如GPT-4o或使用通过远程操作收集的数据集训练的模仿学习策略」

他们使用VR [52, 53] 估计的手部姿态,并基于逆运动学直接计算现成的低级手部控制器的关节目标
在这项工作中,他们采用VR进行灵巧手控制,但手部姿态估算也可以被其他接口(如MoCap手套[54]或RGB相机[55])替代
2.4 实验:全身运动追踪、语音控制机器人、通过前沿模型或IL实现自主性
2.4.1 全身运动追踪:仿真运动追踪结果、真实世界运动跟踪结果
为了确定OmniH2O能否在仿真和现实世界中准确追踪运动,作者在仿真环境和真实环境中对OmniH2O 的运动跟踪能力进行评估
- 在仿真中,作者在重定向的AMASS 数据集及其增强运动
- 在真实环境中,由于物理实验室空间有限且在真实环境下评估大规模数据集较为困难,作者仅在20 个站立序列上进行测试
对于评估指标,作者使用姿态和基于物理的指标来评估运动跟踪性能
- 作者报告与PHC [56] 一致的成功率(Succ),当任何时刻与参考的平均偏差超过0.5 m 时,即判定为模仿失败
- Succ衡量人形是否能够在不失去平衡或落后的情况下跟踪参考运动
- 全局MPJPE
和以躯干为参考的平均关节位置误差(MPJPE)
分别衡量作者的策略在全局和局部(以躯干为参考)模仿参考运动的能力
- 为展示物理真实性,作者还报告平均关节加速度
和速度
误差
2.4.1.1 仿真运动追踪结果
在下表表1的前三行中,可以看到他们的可部署学生策略在动作模仿方面显著优于已有方法[3],并且达到了与教师策略相似的成功率(不用担心 一下子这么多信息 觉得会看得眼花缭乱,我july会帮你梳理清晰的,不急)
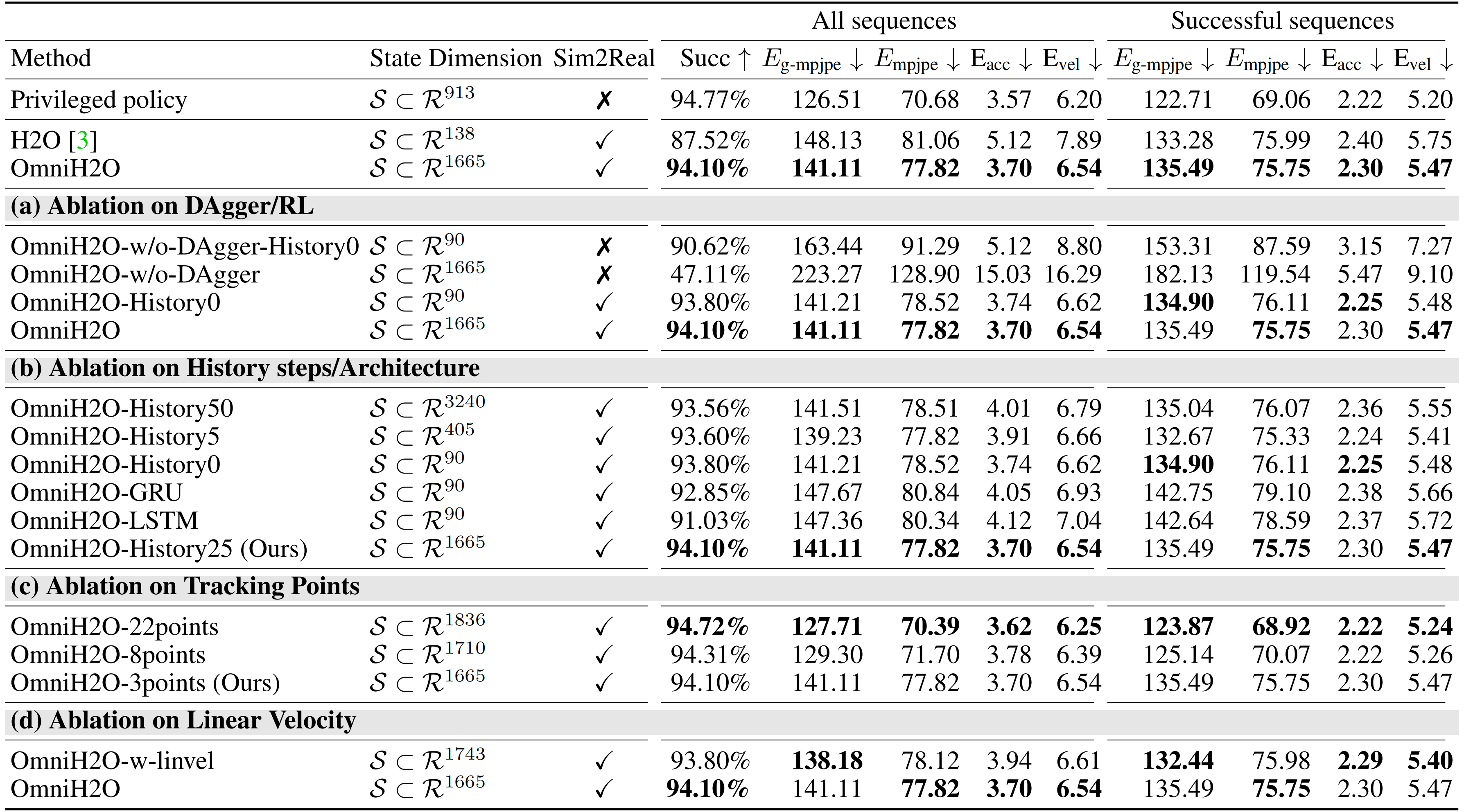
首先,关于DAgger/RL 的消融实验
作者测试了在没有DAgger 的情况下(即直接使用RL 来训练学生策略)OmniH2O 的性能
- 从表1(a) 可以看出,DAgger 整体上提升了性能,尤其是在输入包含历史信息的策略上
下面的4种情况,从上至下,逐步增加更有利的条件——我特意用删除线 表示对应的该情况不包含对应的部分
DAgger-History0:该变体的OmniH2O仅使用强化学习进行训练,且在观测中不包含历史信息。状态空间组成详情见表7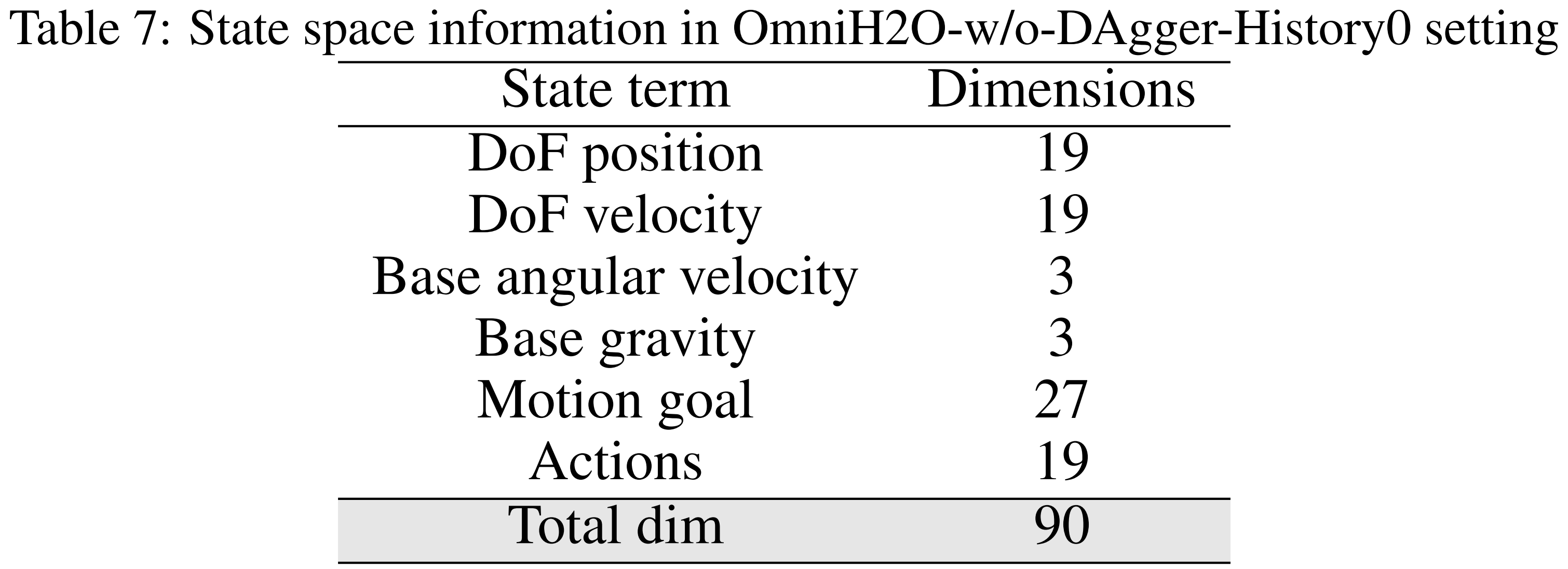
DAgger:该模型采用强化学习训练,不包含DAgger,但在观测中包含最近25步的历史信息。状态空间组成详情见表8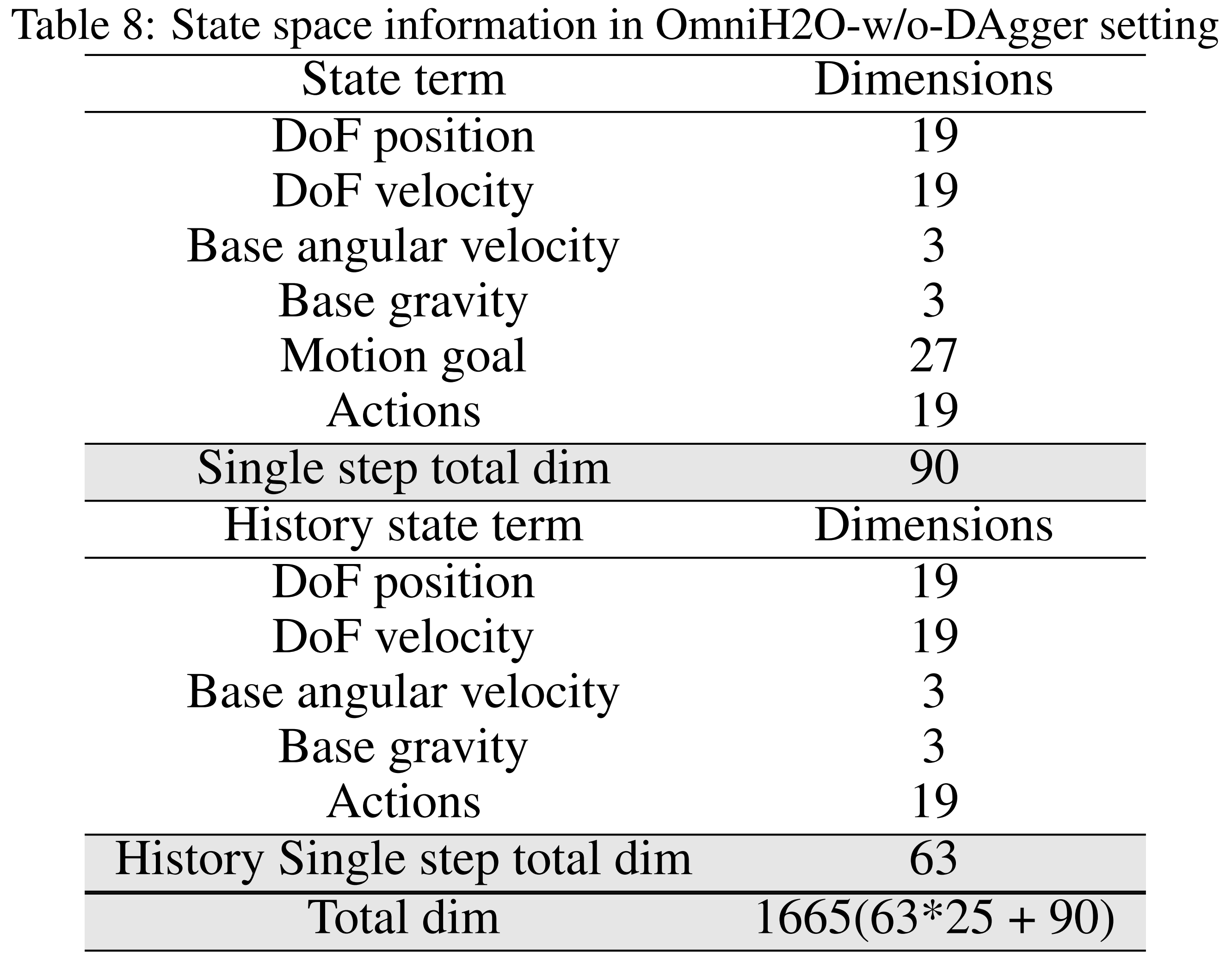
History0:该模型采用DAgger进行训练,但在观测中排除了最近25步的历史信息。状态空间组成详见表9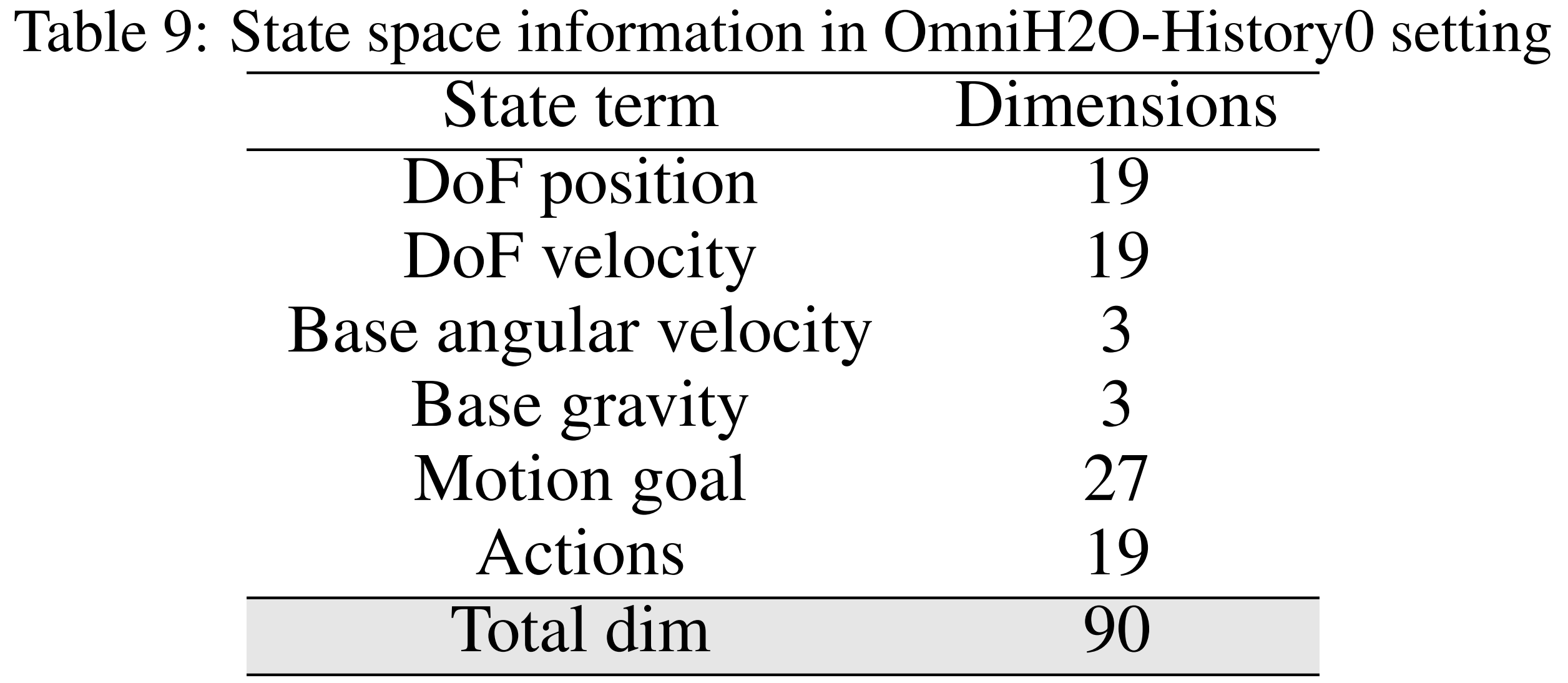
- 如果没有 DAgger,当提供给它很长的历史记录时,该策略就难以学习到连贯一致的策略
这是因为强化学习无法处理输入复杂度的指数级增长
然而,历史信息对于在真实世界中学习可部署策略是必要的,它提供了鲁棒性和隐式的全局速度信息
总之,通过DAgger进行的监督学习能够有效利用历史输入,并取得更好的性能
第二,历史步数/架构消融实验
首先,如下图所示

- OmniH2O-History50/25/5/0:这是OmniH2O的一种变体,在观测中包含50、25、5或0步的历史信息
状态空间组成的详细信息见表10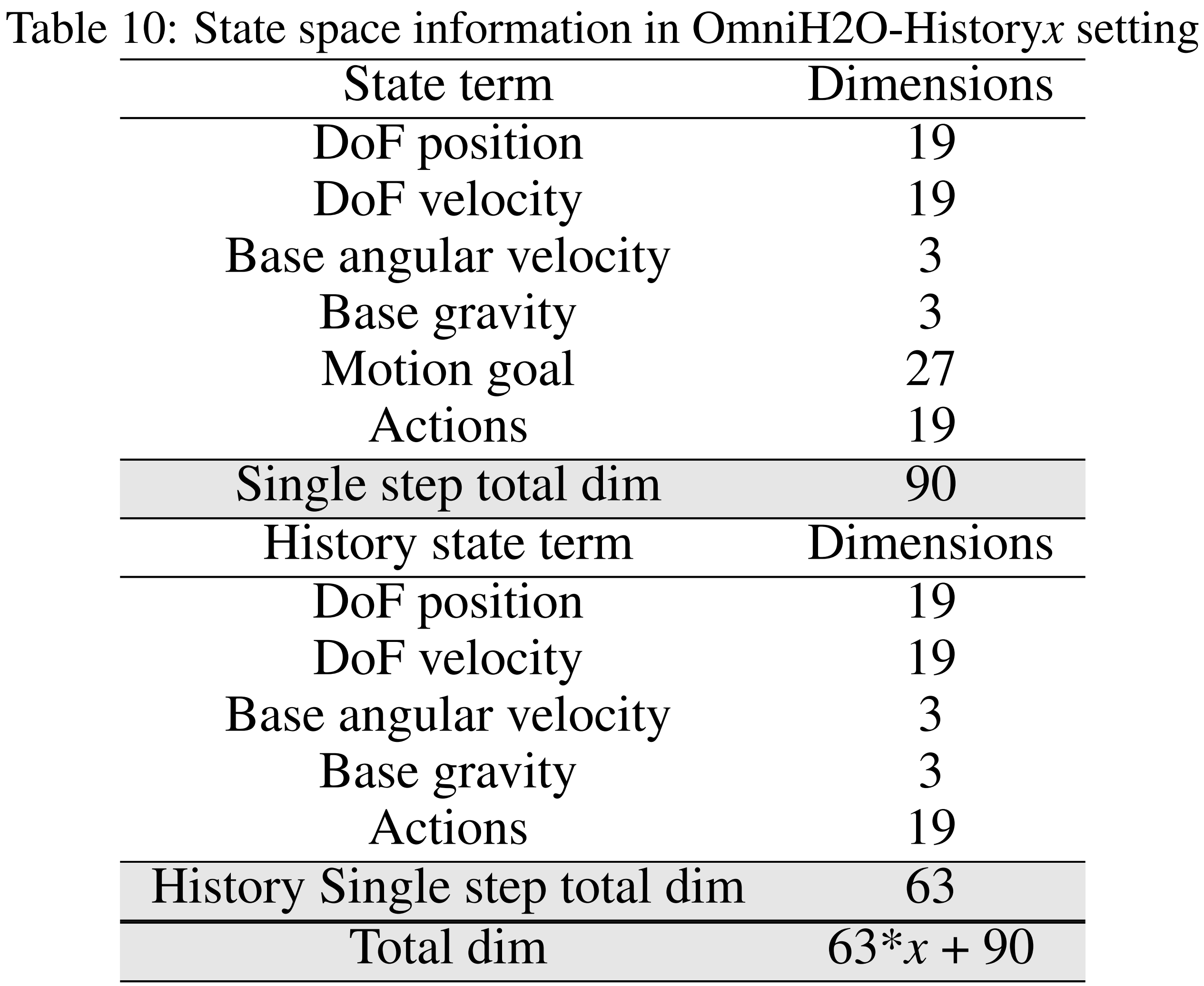
- OmniH2O-GRU/LSTM:该版本将策略网络中的MLP替换为GRU或LSTM,从而内在地融入了历史观测信息
状态空间组成的详细信息见表1
其次
- 在表1(b)中,作者对不同的历史步数(0、5、25、50)进行了实验,发现25步在性能与学习效率之间达到了最佳平衡
- 此外,他们还评估了用于历史信息利用的不同神经网络架构:MLP、LSTM、GRU,并确定基于MLP的OmniH2O表现最佳
第三,稀疏输入消融实验
为了支持基于VR的远程操作,仅追踪3个点(头部和双手)以生成全身动作
- 表1(c)中分析了追踪点数量的影响。作者测试了从最小(3个)到全身动作目标(22个)的不同配置,发现3点追踪能够获得与更多输入关键点相当的性能

- 即如预期,3点策略在全身动作追踪精度上有所牺牲,但获得了对市售设备更强的适用性
第四,全局线速度消融实验
- 鉴于在实际应用中全局速度估计存在的挑战,作者对比了在有无显式速度信息下训练的策略
- 如表1(d)所示,线速度信息在仿真中并未提升性能,但在实际部署中带来了显著挑战(详细内容见原论文的第4.1.2节)
因此作者开发了一种不依赖于线速度作为本体感知的状态空间策略,以避免这些问题
2.4.1.2 真实世界运动跟踪结果
- 作者在状态空间设计中排除了线速度,因为由视觉惯性里程计(VIO)等算法获得的全局线速度可能非常嘈杂,如附录G所示
- 作者的消融研究(表2(a))还显示
不使用速度输入的策略相比于使用VIO或MLP/GRU神经估算器(实现细节见附录G)估算速度的策略表现更好,这表明该策略利用历史记录可以在没有显式线速度输入的情况下有效跟踪运动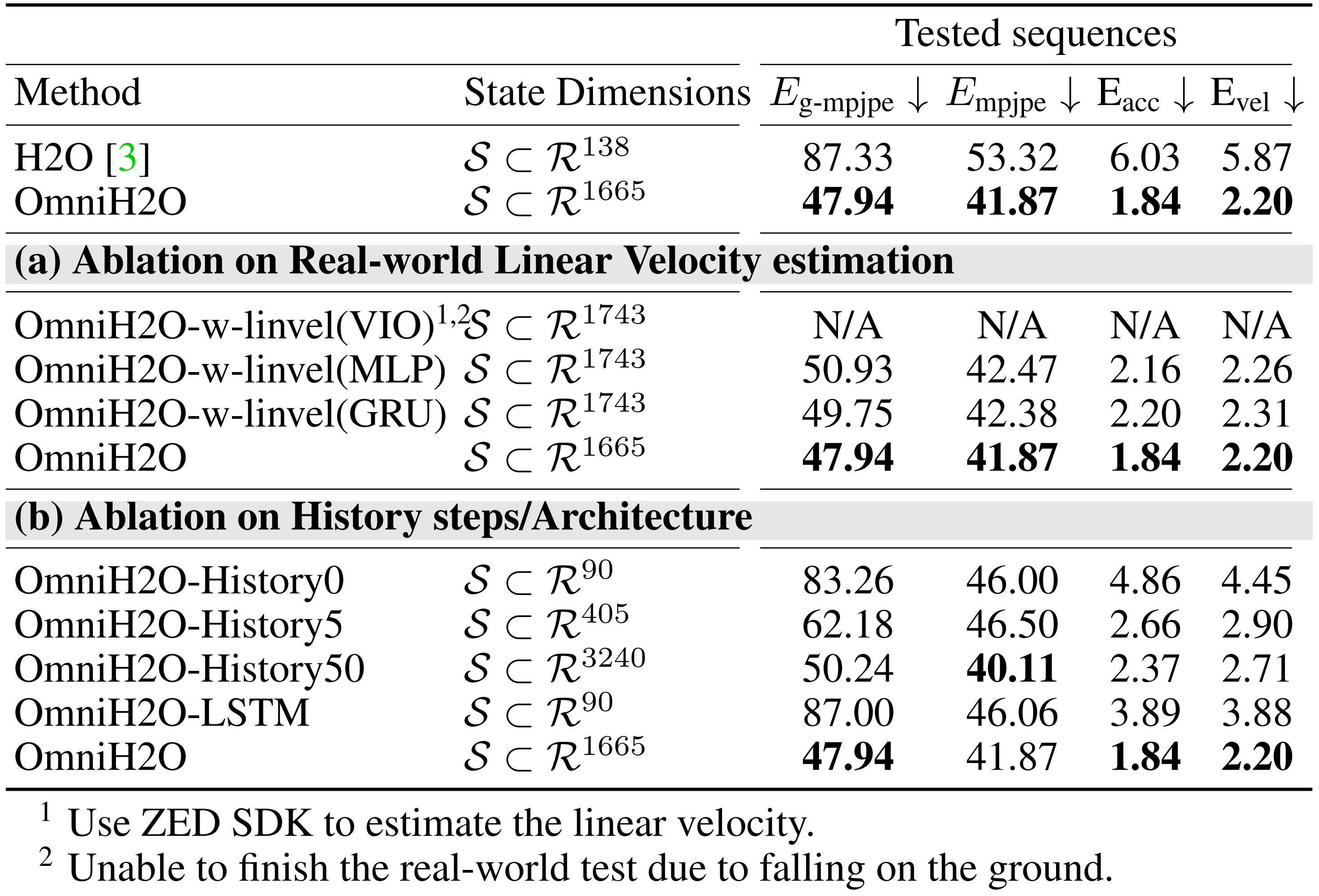
2.4.2 通过通用接口实现人类控制——语音指令控制机器人干活
通过将与预训练的文本到动作生成模型MDM[57-Human motion diffusion model]连接,可以通过口头指令控制人形机器人
如下图所示

人类可以描述所需的动作,例如“举起你的右手”,然后MDM生成相应的动作目标,由OmniH2O进行跟踪「with humans describing desired motions, such as “raise your right hand”. MDM generatesthe corresponding motion goals that are tracked by the OmniH2O」
我个人感觉到很amazing,毕竟确实挺酷的,直接口头让机器人干活
- 语音模型根据人类语音转换成文本
- 然后类似MDM、Momask这样的模型再根据文本生成3D骨骼动画,作为机器人的动作目标
- 然后用训练好的策略
且在遭受来自各个角度的人为击打和踢踹时,机器人无需外部辅助,能够自主保持稳定。
另,还在多种户外地形上对OmniH2O进行了测试,包括草地、坡地、碎石等。OmniH2O在扰动和非结构化地形下表现出极佳的鲁棒性

2.4.3 通过前沿模型或模仿学习实现自主性:GPT-4o自主控制、OmniH2O-6数据集(包含机器人本身的设置)、从演示中学习
2.4.3.1 GPT-4o自主控制
作者将系统OmniH2O与GPT-4o集成,在仿人机器人头部安装摄像头,用于捕捉图像并传递给GPT-4o

供给GPT-4o的prompt (详见原论文附录M)包含多个运动基元,GPT-4o可根据当前视觉环境进行选择
以下是用于自主拳击任务的示例提示:
- 你是一台人形机器人,头部配有一台略微向下倾斜的摄像头,提供第一人称视角
我现在给你分配一个任务:当你面前出现蓝色目标时,伸出并收回你的左拳;
当出现红色目标时,同样操作你的右拳。如果你面前没有目标,则保持静止
每次我会为你提供三个选项:左手前伸、右手前伸或保持不动。你应根据当前图像,直接用对应选项A, B 或C 进行回答。注意,你自己也戴着蓝色左拳击手套和红色右拳击手套,请不要将它们识别为拳击目标
现在,请根据当前图像,给我A, B, C 的答案
对于使用HumanTask实现自主问候,给的提示是:
- 你是一台配备有略微向下倾斜摄像头的仿人机器人,摄像头位于你的头部,提供第一人称视角
我现在给你分配一个新任务:对你面前的人类手势作出回应。请记住,此人正面朝向你,因此要注意他们的手势
如果此人伸出右手与你握手,请用你的右手与其右手握手(选项A)
如果此人张开双臂准备拥抱,请张开双臂回应拥抱(选项B)
如果你看到此人挥手告别,请挥手回应(选项C)
如果没有明显的手势,请保持静止(选项D)
请根据当前图像和观察到的手势,直接用对应的选项A、B、C或D作答。仅回复A、B、C或D,不要添加任何其他字符
之所以选择运动原语而不是直接生成运动目标,是因为GPT-4o的响应时间相对较长。如上图所示,机器人能够根据目标的颜色给出正确的出拳,并根据人类姿势所表明的意图成功地与人类打招呼
2.4.3.2 OmniH2O-6数据集(包含机器人本身的设置)
作者通过基于VR的远程操作收集演示数据
- 他们考虑了六项任务:接-放、下蹲、剪刀石头布、锤击-接球、拳击和篮筐拾取-放置
- 且该数据集包含来自头戴式摄像头的配对RGBD图像,H1头部和手相对于根部的运动目标,以及用于电机驱动的关节目标,这些数据以30Hz的频率记录
- 对于诸如接-放、下蹲和剪刀石头布等简单任务,每个任务大约录制5分钟的数据
对于如Hammer-Catch和Basket-Pick-Place等任务,作者大约收集10分钟,总计40分钟的真实世界仿人机器人远程操作演示。六个开源数据集的详细任务描述见原论文附录J
对于真实机器人系统设置
真实机器人采用了Unitree H1平台[61],配备了大妙DM-J4310-2EC电机[62]和Inspire手[63]以实现操作能力
且有两种版本的真实机器人计算配置
- 第一种配置是在H1机器人背部安装了两台16GB Orin NX计算机
第一台Orin NX连接到安装在H1腰部的ZED相机,用于执行定位运算以确定H1自身的位置。该相机以60 Hz帧率运行
此外,这台Orin NX通过Wi-Fi连接到作者的Vision Pro设备,以持续接收来自人类操作者的运动目标信息
第二台OrinNX作为主控制中心。它接收运动目标信息,并将其作为控制策略的输入。该策略随后输出每个机器人电机的力矩信息,并将这些命令发送给机器人
由于机器人的手指和手腕控制不需要推理,因此直接将Vision Pro数据映射到机器人对应的关节上。该策略的计算频率设定为50 Hz
两台Orin NX通过以太网连接,通过通用的ROS(机器人操作系统)网络共享信息
最终对H1的命令由第二台Orin NX整合并下发
整个系统延迟仅为20毫秒。值得注意的是,之所以这样设计系统,部分原因是ZED相机需要大量的计算资源
通过将第一块 Orin NX 专用于 ZED 相机,第二块用于策略推理,确保每个组件都能以最佳性能运行- 在第二种设置中,一台笔记本电脑『13 代 i9-13900HX 和 NVIDIA RTX4090,32GB 内存』作为计算和通信设备
所有设备,包括 ZED 相机、控制策略和 Vision Pro,都通过这台笔记本电脑上的 ROS 系统进行通信,实现了数据的集中处理和指令分发这两种设置在性能上表现相近,他们在实验中交替使用它们
2.4.3.3 从演示中学习:相当于从人类视频中定义动作目标,最后执行RL中训练好的学生动作策略
- 作者设计的从演示中学习(即learning from demonstration,简称LfD)的策略为
其中在给定图像输入
的情况下输出
帧的运动目标
在这里,还在中包含了灵巧手的指令
训练的超参数见原论文的附录L,即如下表表19所示『为了使机器人实现自主性,作者开发了一种基于示范学习(LfD)的方法,利用扩散策略从他们收集的数据集进行学习。默认的训练超参数如表19所示』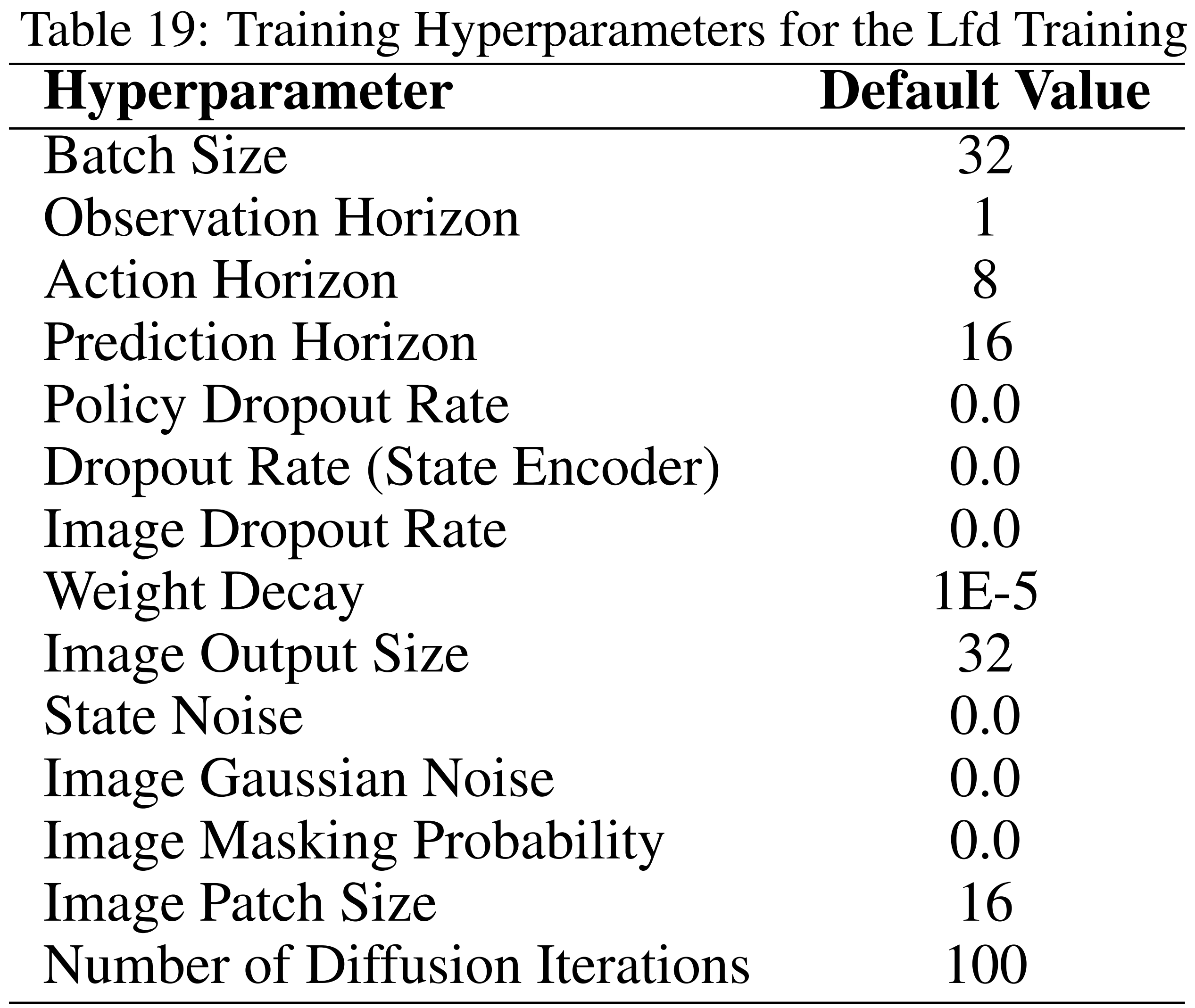
- 然后,
作为低层策略『来源于2.2.5(上) 策略蒸馏:学生策略向老师策略的逼近与学习的开头』,用于计算人形全身控制的关节驱动
且与直接使用 输出关节驱动相比,作者利用了在
中训练好的运动技能,这大大减少了LfD所需的演示次数
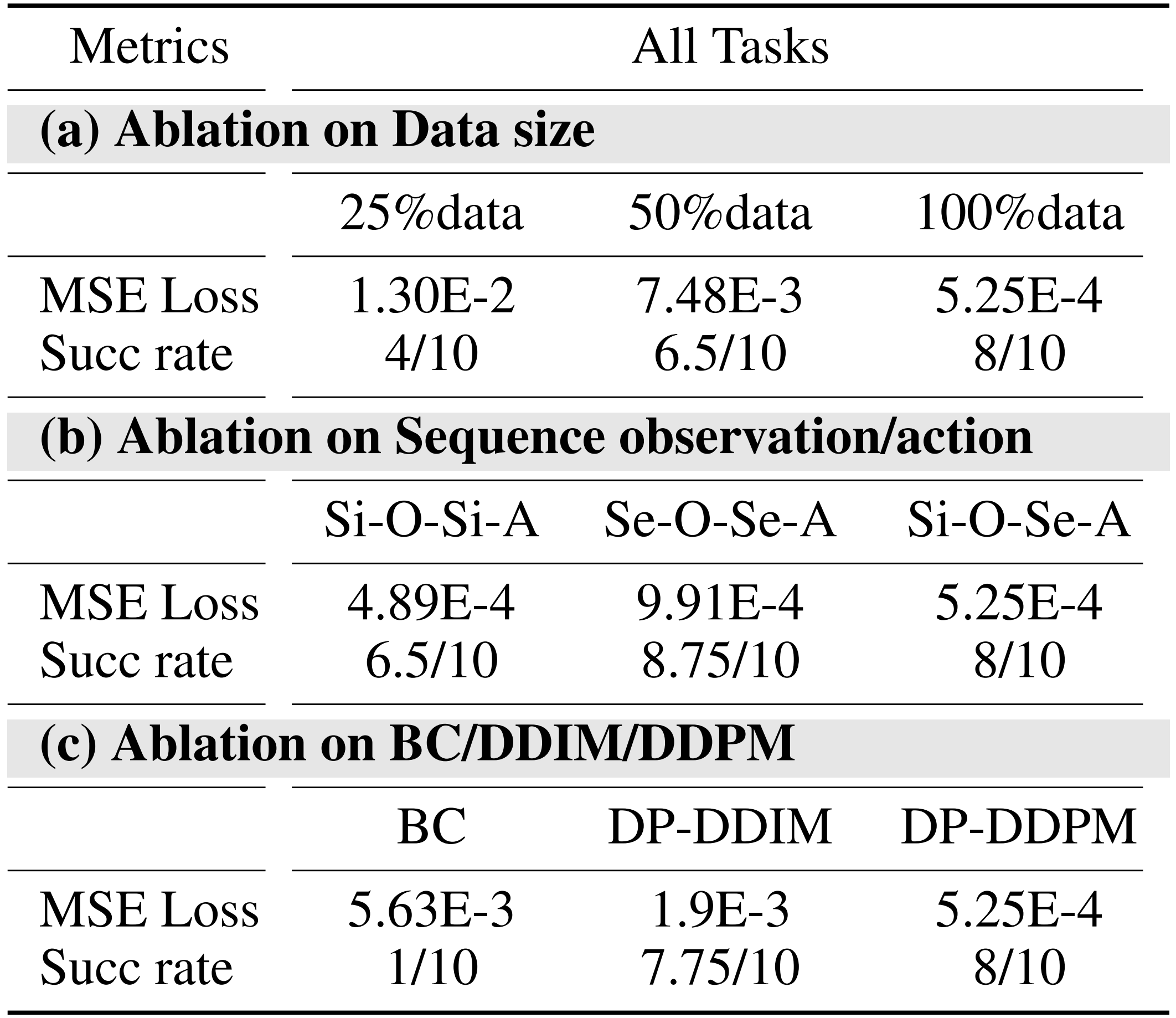
对于上面第一点中的从演示中学习,作者在所收集的数据集中的4项任务上对多种模仿学习算法进行了基准测试(如图7 所示),包括
- 带有去噪扩散的Diffusion Policy [58]
- 融合概率模型[59](DP-DDPM)
- 去噪扩散隐式模型[60](DP-DDIM)
- 采用ResNet架构的普通行为克隆(BC)
为了评估
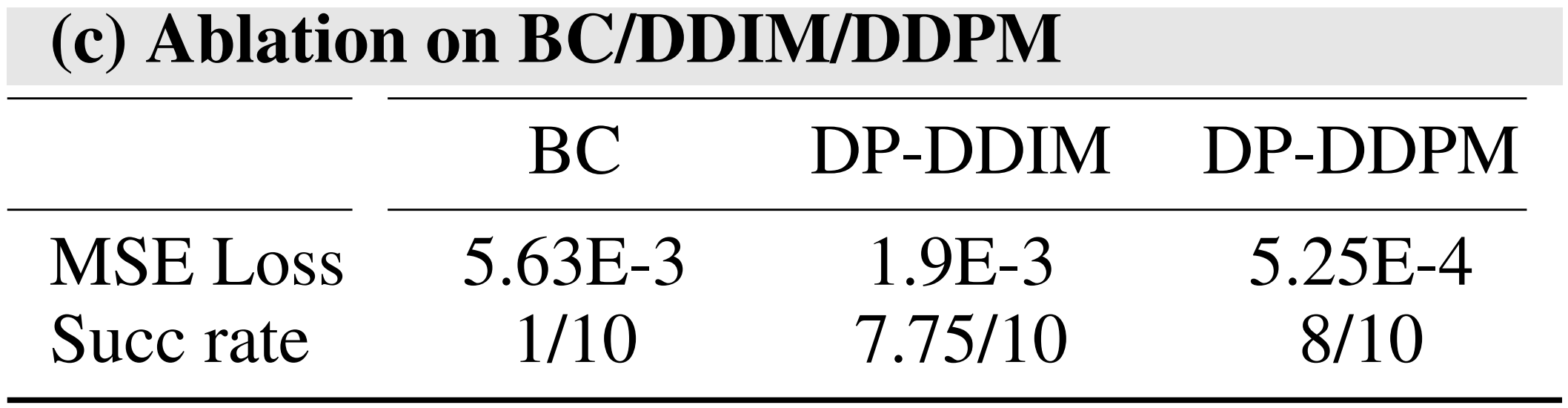
简言之,作者宣称他们,得出两个关键结论:
- 扩散策略显著优于采用ResNet 的普通行为克隆
- 在LfD 训练中,预测一系列动作至关重要,因为这使机器人能够有效地学习和复现实轨迹
具体而言,其中
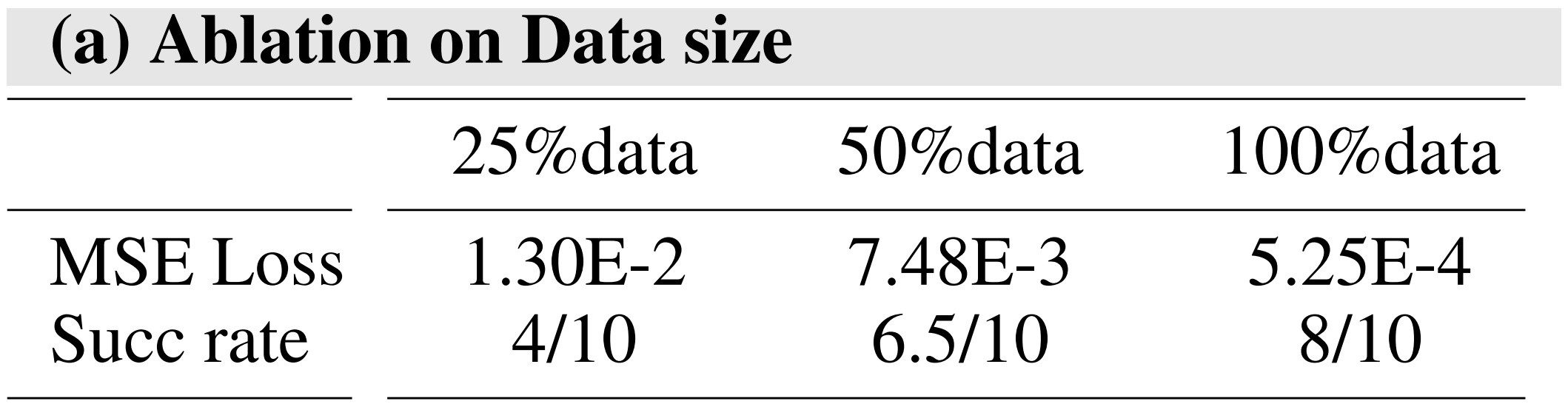
- 关于数据集规模的消融
25/50/100%数据:在该任务中,使用数据集的25/50/100%作为训练集。所用算法为DDPM,其输入为单步图像,输出为8步动作
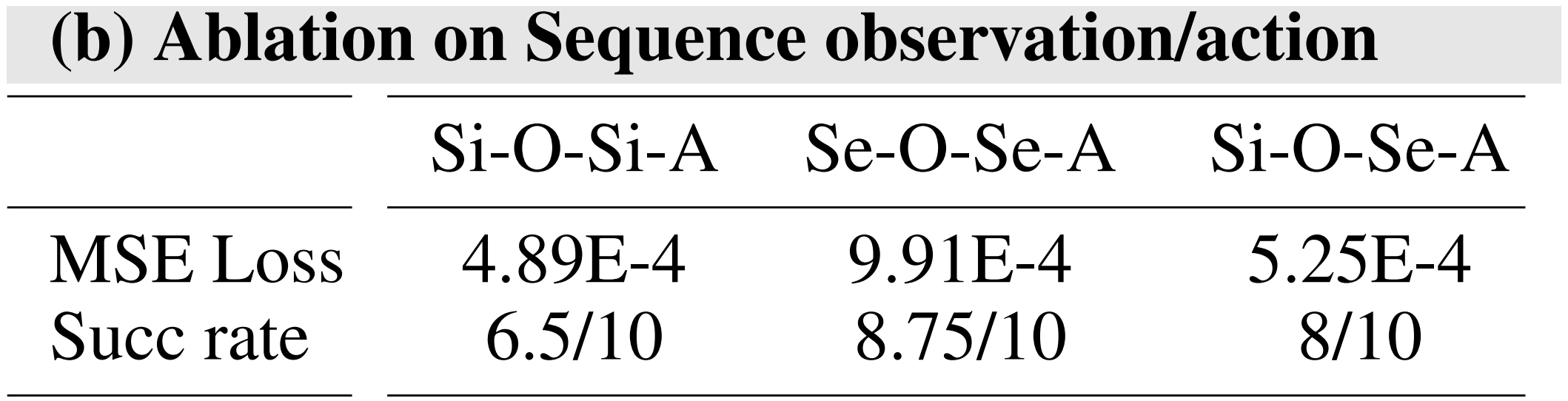
- 单步/序列观测与动作输入/输出的消融实验
- 训练架构消融实验

// 待更