目录
1.引言
水下无人航行器(Unmanned Underwater Vehicle, UUV)的三维路径规划与避障是海洋工程领域的核心问题,其目标是在复杂水下环境(含礁石、沉船等静态障碍物及洋流等动态干扰)中,自主生成一条从起点到目标点的最优路径(满足最短距离、最低能耗等约束),并实时避开障碍物。强化学习(Reinforcement Learning, RL)中的Q-learning算法因无需预先建模环境动态特性、具备自主学习能力,成为解决该问题的有效方法。
2.算法仿真效果演示
软件运行版本:
matlab2024b
仿真结果如下(仿真操作步骤可参考程序配套的操作视频,完整代码运行后无水印):
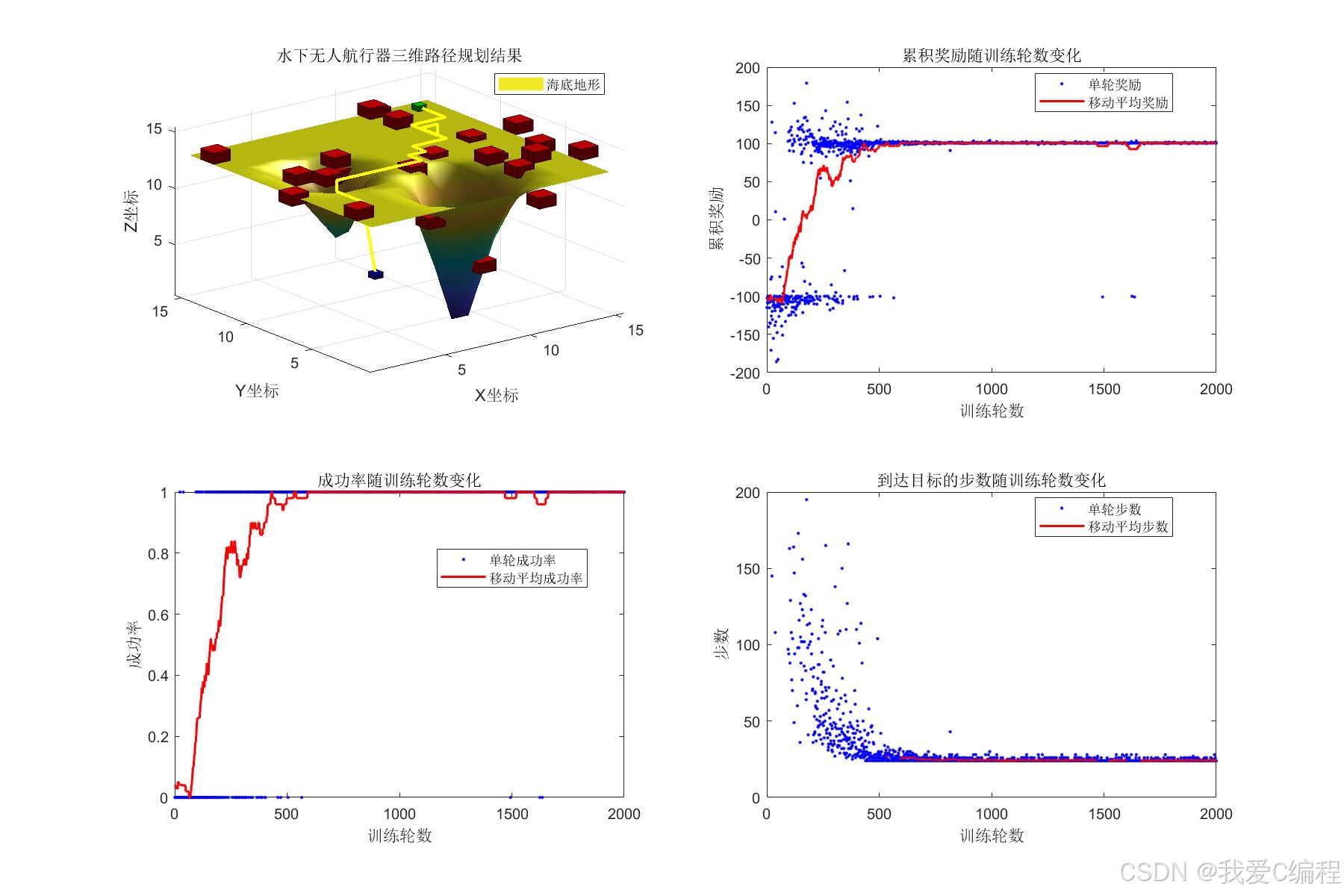
3.数据集格式或算法参数简介
gridSize = 15; % 环境网格大小(三维)
startPos = [2, 2, 8]; % 起始位置 [x,y,z]
goalPos = [13, 13, 14]; % 目标位置 [x,y,z]
numObstacles = 30; % 障碍物数量
maxEpisodes = 2000; % 训练轮数
maxSteps = 200; % 每轮最大步数
learningRate = 0.1; % 学习率
discountFactor = 0.99; % 折扣因子
explorationRate = 1.0; % 探索率
minExplorationRate = 0.01; % 最小探索率
explorationDecay = 0.995; % 探索率衰减率
collisionPenalty = -100; % 碰撞惩罚
goalReward = 100; % 到达目标奖励
distanceWeight = 0.05; % 距离奖励权重4.算法涉及理论知识概要
4.1 强化学习基本框架
强化学习的核心是智能体(Agent)与环境(Environment)的交互学习。在UUV路径规划中:
智能体:UUV 本身,负责感知环境状态并执行动作;
环境:三维水下空间,包含起点、目标点、静态/动态障碍物、洋流等;
状态(State, s):UUV在环境中的位置、姿态、与障碍物的相对距离等信息;
动作(Action, a):UUV的运动决策(如前进、后退、上升、下降等);
奖励(Reward, r):环境对动作的反馈(如靠近目标得正奖、碰撞障碍物得负奖);
策略(Policy, π):智能体从状态到动作的映射(即 “在状态s下选择动作a的概率”)。
UUV的目标是通过不断与环境交互,学习到最优策略π*,使从起点到目标点的累积奖励最大化。
4.2 Q-learning算法
Q-Learning是一种无模型的强化学习算法,通过学习状态 - 动作对的价值函数Q(s,a)来确定最优策略。Q(s,a)表示在状态s下执行动作a后获得的期望累积奖励。Q-Learning的核心更新公式为:

4.3 三维水下环境的特殊性
与陆地机器人的二维路径规划不同,UUV的三维路径规划需考虑:
空间连续性:水下环境是连续的三维空间(x,y,z),需将连续状态离散化以适配Q-learning的离散状态要求;
避障复杂性:障碍物可能是不规则几何体(如礁石),需精确计算UUV与障碍物的相对距离;
动力学约束:UUV 的运动受水阻力、浮力影响,动作执行存在延迟或误差,需在奖励函数中体现;
信息不完全性:水下传感器(如声呐)存在探测范围限制,UUV无法感知全局环境,需依赖局部状态决策。
4.4 系统实现步骤
动作空间
UUV的动作定义为在三维空间中的运动方向,考虑其动力学特性(如无法瞬间转向),设计7种基本动作:

奖励函数
奖励函数是Q-learning的“指挥棒”,直接决定学习效果。需同时鼓励UUV向目标移动、避开障碍物,并惩罚无效动作。
Q值更新

基于Q-learning的UUV三维路径规划与避障系统通过环境离散化-状态动作设计-奖励函数引导-迭代学习-路径优化的流程,实现了复杂水下环境中的自主导航。
5.参考文献
[1]徐莉.Q-learning研究及其在AUV局部路径规划中的应用[D].哈尔滨工程大学,2004.DOI:10.7666/d.y670628.
[2]王立勇,王弘轩,苏清华,等.基于改进Q-Learning的移动机器人路径规划算法[J].电子测量技术, 2024, 47(9):85-92.
6.完整算法代码文件获得
完整程序见博客首页左侧或者打开本文底部
V