ollama 运行gpt-oss 系列教程
启动ollama
docker run -d --gpus '"device=4"' --restart=always -v /data/linnannan/ollama:/root/.ollama -p 9089:11434 --name ollama ollama/ollama
进入容器
exec -it cec866ab58e8e9365 bash
下载模型
如果出现下载速度突然变慢的情况,直接ctrl c 退出重新pull,ollama有断点续传的功能
ollama pull gpt-oss:20b
ollama pull gpt-oss:120b
启动模型
ollama run gpt-oss:20b
导出模型配置文件
ollama show --modelfile gpt-oss:20b > model_config/gpt-oss-20b-Modelfile
修改配置文件
注意:如果上下文长度设置过大,会自动把超过的部分加载到CPU中,导致推理速度非常慢。
- FROM gpt-oss:20b

- PARAMETER num_ctx 48000

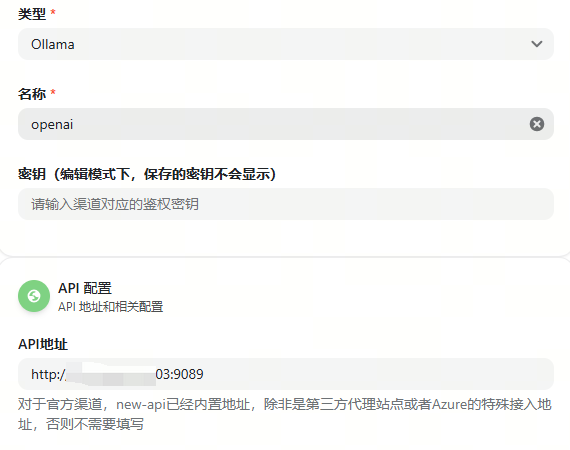
CONTEXT = 32K

CONTEXT = 56K

CONTEXT = 64K

创建新模型
ollama create gpt_oss_20b:v1 -f model_config/gpt-oss-20b-Modelfile

调用接口
1. POST /api/generate
功能:使用指定模型对给定的 prompt 生成响应。该端点默认 流式 返回(stream),最终会收到一个包含统计信息等的完整响应对象。
1.1 基本参数
| 参数 | 必填 | 类型 | 说明 |
|---|---|---|---|
model |
✅ | string |
模型名称 |
prompt |
✅ | string |
用于生成响应的提示文本 |
suffix |
❌ | string |
响应结束后要追加的文本 |
images |
❌ | string[] |
base64 编码的图像列表(仅对多模态模型如 llava 有效) |
think |
❌ | boolean |
对于思维模型,是否在生成前进行“思考” |
1.2 高级可选参数
| 参数 | 必填 | 类型 | 说明 |
|---|---|---|---|
format |
❌ | string |
返回数据的格式。可选 json(JSON 模式) |
options |
❌ | object |
Modelfile 中定义的其它模型参数,例如 temperature、top_p 等 |
system |
❌ | string |
覆盖 Modelfile 中的系统消息 |
template |
❌ | string |
覆盖 Modelfile 中的提示模板 |
stream |
❌ | boolean |
false 时返回单个完整响应对象;true(默认)返回对象流 |
raw |
❌ | boolean |
true 时不做任何格式化;若请求已包含完整模板化提示,可使用此参数 |
keep_alive |
❌ | string |
控制模型在请求结束后保持在内存中的时长(默认 5m) |
提示:如果
stream为true,服务器会逐块推送响应;若想一次性获取全部结果,请将stream设置为false。
2. POST /api/chat
功能:使用指定模型生成聊天对话中的下一条消息。默认 流式 返回(stream),可通过 stream:false 改为单次返回。
2.1 基本参数
| 参数 | 必填 | 类型 | 说明 |
|---|---|---|---|
model |
✅ | string |
模型名称 |
messages |
✅ | object[] |
聊天历史(每条消息对象,详见下表) |
tools |
❌ | object[] |
若模型支持,列出模型可调用的工具(JSON 格式) |
think |
❌ | boolean |
对于思维模型,是否在生成前进行“思考” |
messages 中的单条消息对象结构
| 字段 | 必填 | 类型 | 说明 |
|---|---|---|---|
role |
✅ | string |
消息角色:system、user、assistant、tool |
content |
✅ | string |
消息内容 |
thinking |
❌ | string |
(思维模型专用)模型的思考过程 |
images |
❌ | string[] |
base64 编码的图像列表(仅对多模态模型如 llava 有效) |
tool_calls |
❌ | object[] |
模型想要调用的工具列表(JSON 格式) |
tool_name |
❌ | string |
若已执行工具,返回的工具名称(用于告知模型结果) |
2.2 高级可选参数
| 参数 | 必填 | 类型 | 说明 |
|---|---|---|---|
format |
❌ | string |
返回数据的格式。可选 json(JSON 模式) |
options |
❌ | object |
Modelfile 中定义的其它模型参数,例如 temperature |
stream |
❌ | boolean |
false 时返回单个完整响应对象;true(默认)返回对象流 |
keep_alive |
❌ | string |
控制模型在请求结束后保持在内存中的时长(默认 5m) |
提示:在使用多模态模型时,可在
messages或generate请求中通过images字段传入 Base64 编码的图片;若模型不支持图片,则会返回错误。
🛠 常用示例(cURL)
# 1️⃣ generate(流式)
curl -X POST "http://127.0.0.1:9089/api/generate" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt_oss_20b:v1",
"prompt": "请用中文解释量子纠缠的概念。",
"stream": true
}'
# 2️⃣ chat(一次性返回)
curl -X POST "http://127.0.0.1:9089/api/chat" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt_oss_20b:v1",
"messages": [
{"role":"system","content":"你是一个乐于助人的助手"},
{"role":"user","content":"请帮我写一段 Python 代码实现快速排序。"}
],
"stream": false
}'
📌 注意事项
- 必填参数 必须完整,否则会返回
400 Bad Request。 - 流式(stream) 返回时,响应体使用 Server‑Sent Events(SSE) 或类似的分块传输方式。
keep_alive的时间格式支持s(秒)、m(分钟)、h(小时),如10m、2h。- 如需 原始(未格式化)输出,请将
raw: true与自定义模板一起使用。
持久化API
curl -X POST http://127.0.0.1:9089/api/generate \
-H "Content-Type: application/json" \
-d '{"model": "gpt_oss_20b:v1", "keep_alive": -1}'
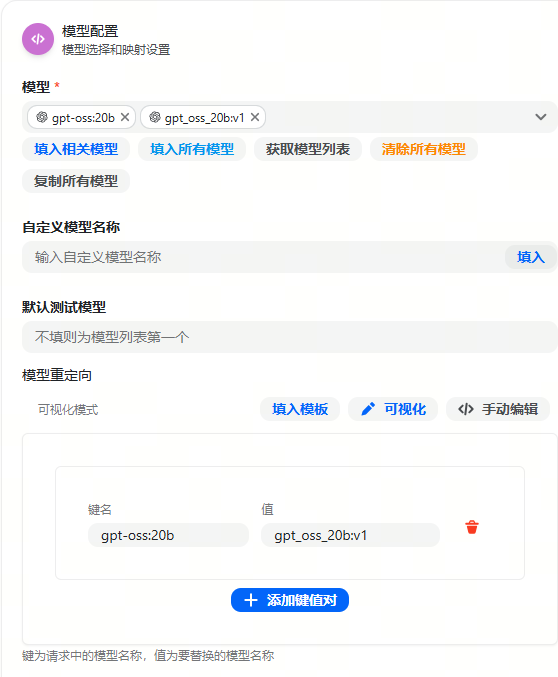
Openai 格式(配置到new_api中)